基于大语言模型知识问答应用落地实践 – 知识库构建(上)

01
背景介绍
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)+知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通用大语言模型的一些短板,解决通用大语言模型在专业领域回答缺乏依据、存在幻觉等问题。其基本思路是把私域知识文档进行切片,然后向量化后续通过向量检索进行召回,再作为上下文输入到大语言模型进行归纳总结。
在这个技术方向的具体实践中,知识库可以采取基于倒排和基于向量的两种索引方式进行构建,它对于知识问答流程中的知识召回这步起关键作用,和普通的文档索引或日志索引不同,知识的向量化需要借助深度模型的语义化能力、存在文档切分、向量模型部署&推理等额外步骤。知识向量化建库过程中,不仅仅需要考虑原始的文档量级,还需要考虑切分粒度,向量维度等因素,最终被向量数据库索引的知识条数可能达到一个非常大的量级,可能由以下两方面的原因引起:
各个行业的既有文档量很高,如金融、医药、法律领域等,新增量也很大。
为了召回效果的追求,对文档的切分常常会采用按句或者按段进行多粒度的冗余存贮。
这些细节对知识向量数据库的写入和查询性能带来一定的挑战,为了优化向量化知识库的构建和管理,本文基于亚马逊云科技的服务,构建了如下图的知识库构建流程:
通过 S3 Bucket 的 Handler 实时触发 Amazon Lambda 启动对应知识文件入库的 Amazon Glue job;
Glue Job 中会进行文档解析和拆分,并调用 Amazon Sagemaker 的 Embedding 模型进行向量化;
通过 Bulk 方式注入到 Amazon OpenSearch 中去。
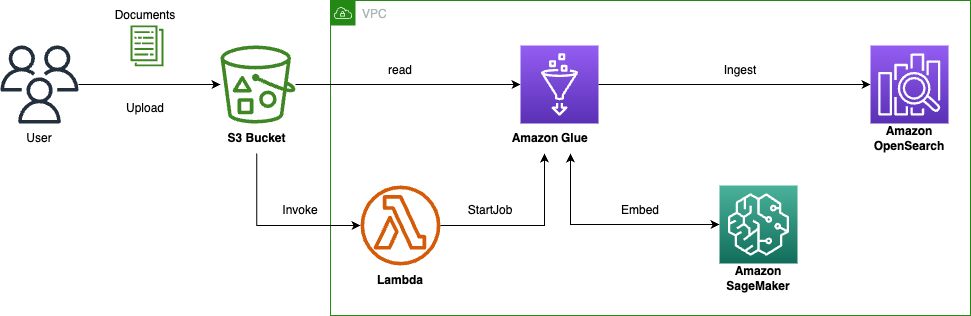
并对整个流程中涉及的多个方面,包括如何进行知识向量化、向量数据库调优总结了一些最佳实践和心得。
02
知识向量化
2.1 文档拆分
知识向量化的前置步骤是进行知识的拆分,语义完整性的保持是最重要的考量。分两个方面展开讨论。该如何选用以下两个关注点分别总结了一些经验:
a. 拆分片段的方法
关于这部分的工作,Langchain 作为一种流行的大语言模型集成框架,提供了非常多的 Document Loader 和 Text Spiltters,其中的一些实现具有借鉴意义,但也有不少实现效果是重复的。
目前使用较多的基础方式是采用 Langchain 中的 RecursiveCharacterTextSplitter,属于是 Langchain 的默认拆分器。它采用这个多级分隔字符列表 – [“\n\n”, “\n”, ” “, “”] 来进行拆分,默认先按照段落做拆分,如果拆分结果的 chunk_size 超出,再继续利用下一级分隔字符继续拆分,直到满足 chunk_size 的要求。
但这种做法相对来说还是比较粗糙,还是可能会造成一些关键内容会被拆开。对于一些其他的文档格式可以有一些更细致的做法。
FAQ 文件,必须按照一问一答粒度拆分,后续向量化的输入可以仅仅使用问题,也可以使用问题+答案(本系列 blog 的后续文章会进一步讨论)
Markdown 文件,”#”是用于标识标题的特殊字符,可以采用 MarkdownHeaderTextSplitter 作为分割器,它能更好的保证内容和标题对应的被提取出来。
PDF 文件,会包含更丰富的格式信息。Langchain 里面提供了非常多的 Loader,但 Langchain 中的 PDFMinerPDFasHTMLLoader 的切分效果上会更好,它把 PDF 转换成 HTML,通过 HTML 的 <div> 块进行切分,这种方式能保留每个块的字号信息,从而可以推导出每块内容的隶属关系,把一个段落的标题和上一级父标题关联上,使得信息更加完整。类似下面这种效果。

b. 模型对片段长度的支持
由于拆分的片段后续需要通过向量化模型进行推理,所以必须考虑向量化模型的 Max_seq_length 的限制,超出这个限制可能会导致出现截断,导致语义不完整。从支持的 Max_seq_length 来划分,目前主要有两类 Embedding 模型,如下表所示(这四个是有过实践经验的模型)。
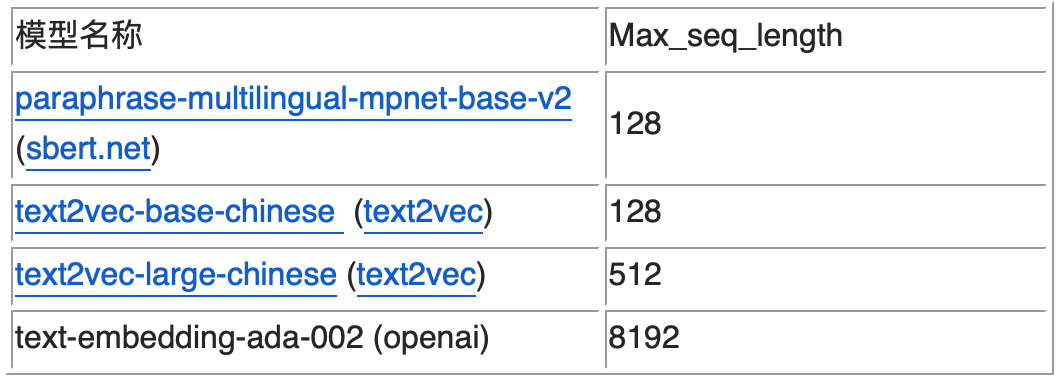
这里的 Max_seq_length 是指 Token 数,和字符数并不等价。依据之前的测试经验,前三个模型一个 token 约为 1.5 个汉字字符左右。而对于大语言模型,如 chatglm,一个 token 一般为 2 个字符左右。如果在切分时不方便计算 token 数,也可以简单按照这个比例来简单换算,保证不出现截断的情况。
前三个模型属于基于 Bert 的 Embedding 模型,OpenAI 的 text-embedding-ada-002 模型是基于 GPT3 的模型。前者适合句或者短段落的向量化,后者 OpenAI 的 SAAS 化接口,适合长文本的向量化,但不能私有化部署。
可以根据召回效果进行验证选择。从目前的实践经验上看 text-embedding-ada-002 对于中文的相似性打分排序性可以,但区分度不够(集中 0.7 左右),不太利于直接通过阈值判断是否有相似知识召回。
另外,对于长度限制的问题也有另外一种改善方法,可以对拆分的片段进行编号,相邻的片段编号也临近,当召回其中一个片段时,可以通过向量数据库的 range search 把附近的片段也召回回来,也能保证召回内容的语意完整性。
2.2 向量化模型选择
上节提到四个模型只是提到了模型对于文本长度的支持差异,效果方面目前并没有非常权威的结论。可以通过 leaderboard 来了解各个模型的性能,榜上的大多数的模型的评测还是基于公开数据集的 benchmark,对于真实生产中的场景 benchmark 结论是否成立还需要 case by case 地来看。但原则上有以下几方面的经验可以分享:
经过垂直领域 Finetune 的模型比原始向量模型有明显优势;
目前的向量化模型分为两类,对称和非对称。未进行微调的情况下,对于 FAQ 建议走对称召回,也就是 Query 到 Question 的召回。对于文档片段知识,建议使用非对称召回模型,也就是 Query 到 Answer(文档片段)的召回;
没有效果上的明显的差异的情况下,尽量选择向量维度短的模型,高维向量(如 openai 的 text-embedding-ada-002)会给向量数据库造成检索性能和成本两方面的压力。
更多的内容会在本系列的召回优化部分进行深入讨论。
2.3 向量化并行
真实的业务场景中,文档的规模在百到百万这个数量级之间。按照冗余的多级召回方式,对应的知识条目最高可能达到亿的规模。由于整个离线计算的规模很大,所以必须并发进行,否则无法满足知识新增和向量检索效果迭代的要求。步骤上主要分为以下三个计算阶段。

文档切分并行
计算的并发粒度是文件级别的,处理的文件格式也是多样的,如 TXT 纯文本、Markdown、PDF 等,其对应的切分逻辑也有差异。而使用 Spark 这种大数据框架来并行处理过重,并不合适。使用多核实例进行多进程并发处理则过于原始,任务的观测追踪上不太方便。所以可以选用 Amazon Glue 的 Python shell 引擎进行处理。主要有如下好处:
方便的按照文件粒度进行并发,并发度简单可控。具有重试、超时等机制,方便任务的追踪和观察,日志直接对接到 Amazon CloudWatch;
方便的构建运行依赖包,通过参数–additional-python-modules 指定即可,同时 Glue Python 的运行环境中已经自带了 opensearch_py 等依赖。
可参考如下代码:
glue = boto3.client('glue')
def start_job(glue_client, job_name, bucket, prefix): response = glue.start_job_run(JobName=job_name,Arguments={'--additional-python-modules': 'pdfminer.six==20221105,gremlinpython==3.6.3,langchain==0.0.162,beautifulsoup4==4.12.2','--doc_dir': f'{prefix}','--REGION': 'us-west-2','--doc_bucket' : f'{bucket}','--AOS_ENDPOINT': 'vpc-aos-endpoint','--EMB_MODEL_ENDPOINT': 'emb-model-endpoint'}) return response['JobRunId']左滑查看更多
注意:Amazon Glue 每个账户默认的最大并发运行的 Job 数为 200 个,如果需要更大的并发数,需要申请提高对应的 Service Quota,可以通过后台或联系客户经理。
向量化推理并行
由于切分的段落和句子相对于文档数量也膨胀了很多倍,向量模型的推理吞吐能力决定了整个流程的吞吐能力。这里采用 SageMaker Endpoint 来部署向量化模型,一般来说为了提供模型的吞吐能力,可以采用 GPU 实例推理,以及多节点 Endpoint/Endpoint 弹性伸缩能力,Server-Side/Client-Side Batch 推理能力这些都是一些有效措施。具体到离线向量知识库构建这个场景,可以采用如下几种策略:
GPU 实例部署
向量化模型 CPU 实例是可以推理的。但离线场景下,推理并发度高,GPU 相对于 CPU 可以达到 20 倍左右的吞吐量提升。所以离线场景可以采用 GPU 推理,在线场景 CPU 推理的策略。
多节点 Endpoint
对于临时的大并发向量生成,通过部署多节点 Endpoint 进行处理,处理完毕后可以关闭(注意:离线生成的请求量是突然增加的,Auto Scaling 冷启动时间 5-6 分钟,会导致前期的请求出现错误)
利用 Client-Side Batch 推理
离线推理时,Client-side batch 构造十分容易。无需开启 Server-side Batch 推理,一般来说 Sever-side batch 都会有个等待时间,如 50ms 或 100ms,对于推理延迟比较高的大语言模型比较有效,对于向量化推理则不太适用。可以参考如下代码:
import hashlib
import itertools
import reBATCH_SIZE = 30
paragraph_content='sentence1。sentence2。sentence3。sentence4。sentence5。sentence6.'def sentence_generator(paragraph_content):sentences = re.split('[。??.!!]', paragraph_content)for sent in sentences:yield sentdef batch_generator(generator, batch_size):while True:batch = list(itertools.islice(generator, batch_size))if not batch:breakyield batchg = sentence_generator(paragraph_content)
sentence_batches = batch_generator(g, batch_size=BATCH_SIZE)# iterate batch to infer
for idx, batch in enumerate(sentence_batches):# client-side batch inferenceembeddings = get_embedding(smr_client, batch, endpoint_name)for sent_id, sent in enumerate(batch):document = { "publish_date": publish_date, "idx":idx, "doc" : sent, "doc_type" : "Sentence", "content" : paragraph_content, "doc_title": header, "doc_category": "", "embedding" : embeddings[sent_id]}yield {"_index": index_name, "_source": document, "_id": hashlib.md5(str(document).encode('utf-8')).hexdigest()}左滑查看更多
OpenSearch 批量注入
Amazon OpenSearch 的写入操作,在实现上可以通过 bulk 批量进行,比单条写入有很大优势。参考如下代码:
from opensearchpy import OpenSearch, RequestsHttpConnection,helperscredentials = boto3.Session().get_credentials()
auth = AWSV4SignerAuth(credentials, region)client = OpenSearch(hosts = [{'host': aos_endpoint, 'port': 443}],http_auth = auth,use_ssl = True,verify_certs = True,connection_class = RequestsHttpConnection
)gen_aos_record_func = None
if content_type == "faq":gen_aos_record_func = iterate_QA(file_content, smr_client, index_name, EMB_MODEL_ENDPOINT)
elif content_type in ['txt', 'pdf', 'json']:gen_aos_record_func = iterate_paragraph(file_content, smr_client, index_name, EMB_MODEL_ENDPOINT)
else:raise RuntimeError('No Such Content type supported') response = helpers.bulk(client, gen_aos_record_func)
return response左滑查看更多
03
向量数据库优化
向量数据库选择哪种近似搜索算法,选择合适的集群规模以及集群设置调优对于知识库的读写性能也十分关键,主要需要考虑以下几个方面:
3.1 算法选择
在 OpenSearch 里,提供了两种 k-NN 的算法:HNSW (Hierarchical Navigable Small World) 和 IVF (Inverted File) 。
在选择 k-NN 搜索算法时,需要考虑多个因素。如果内存不是限制因素,建议优先考虑使用 HNSW 算法,因为 HNSW 算法可以同时保证 latency 和 recall。如果内存使用量需要控制,可以考虑使用 IVF 算法,它可以在保持类似 HNSW 的查询速度和质量的同时,减少内存使用量。但是,如果内存是较大的限制因素,可以考虑为 HNSW 或 IVF 算法添加 PQ 编码,以进一步减少内存使用量。需要注意的是,添加 PQ 编码可能会降低准确率。因此,在选择算法和优化方法时,需要综合考虑多个因素,以满足具体的应用需求。
3.2 集群规模预估
选定了算法后,我们就可以根据公式,计算所需的内存进而推导出 k-NN 集群大小, 以 HNSW 算法为例:
占用内存 = 1.1 * (4*d + 8*m) * num_vectors * (number_of_replicas + 1)
其中 d:vector 的维度,比如 768;m:控制层每个节点的连接数;num_vectors:索引中的向量 doc 数
3.3 批量注入优化
在向知识向量库中注入大量数据时,我们需要关注一些关键的性能优化,以下是一些主要的优化策略:
Disable refresh interval
在首次摄入大量数据时,为了避免生成较多的小型 segment,我们可以增大刷新的间隔,或者直接在摄入阶段关闭 refresh_interval(设置成 -1)。等到数据加载结束后,再重新启用 refresh_interval。
PUT /my_index/_settings
{"index": {"refresh_interval": "-1"}
}Disable Replicas
同样,在首次加载大量数据时,我们可以暂时禁用 replica 以提升摄入速度。需要注意的是,这样做可能会带来丢失数据的风险,因此,在数据加载结束后,我们需要再次启用 replica。
PUT /my_index/_settings
{"index": {"number_of_replicas": 0}
}增加 indexing 线程
处理 knn 的线程由 knn.algo_param.index_thread_qty 指定,默认为 1。如果你的设备有足够的 CPU 资源,可以尝试调高这个参数,会加快 k-NN 索引的构建速度。但是,这可能会增加 CPU 的压力,因此,建议先按节点 vcore 的一半进行配置,并观察 cpu 负载情况。
PUT /_cluster/settings
{"transient": {"knn.algo_param.index_thread_qty": 8 // c6g.4x的vcore为16, 给到 knn 一半}
}左滑查看更多
增加 knn 内存占比
knn.memory.circuit_breaker.limit 是一个关于内存使用的参数,默认值为 50%。如果需要,我们可以将其改成 70%。以这个默认值为例,如果一台机器有 100GB 的内存,由于程序寻址的限制,一般最多分配 JVM 的堆内存为 32GB,则 k-NN 插件会使用剩余的 68GB 中的一半,即 34GB 作为 k-NN 的索引缓存。如果内存使用超过这个值,k-NN 将会删除最近使用最少的向量。该参数在集群规模不变的情况下,提高 k-NN 的缓存命中率,有助于降低成本并提高检索效率。
PUT /_cluster/settings
{"transient": {"knn.memory.circuit_breaker.limit": "70%"}
}左滑查看更多
04
结语
本文《基于大语言模型知识问答应用落地实践-知识库构建(上)》对于知识库构建部分展开了初步的讨论,基于实践经验对于知识库构建中的一些文档拆分方法,向量模型选择,向量数据库调优等一些主要步骤分享了一些心得,但相对来说比较抽象,具体实践细节请关注下篇。
另外,本文提到的代码细节可以参考配套资料:
代码库 aws-samples/private-llm-qa-bot
https://github.com/aws-samples/private-llm-qa-bot
Workshop <基于Amazon Open Search+大语言模型的智能问答系统>(中英文版本)
https://catalog.us-east-1.prod.workshops.aws/workshops/158a2497-7cbe-4ba4-8bee-2307cb01c08a/
本篇作者

李元博
亚马逊云科技 Analytic 与 AI/ML 方面的解决方案架构师,专注于 AI/ML 场景的落地的端到端架构设计和业务优化,同时负责数据分析方面的 Amazon Clean Rooms 产品服务。在互联网行业工作多年,对用户画像,精细化运营,推荐系统,大数据处理方面有丰富的实战经验。

孙健
亚马逊云科技大数据解决方案架构师,负责基于亚马逊云科技的大数据解决方案的咨询与架构设计,同时致力于大数据方面的研究和推广。在大数据运维调优、容器解决方案,湖仓一体以及大数据企业应用等方面有着丰富的经验。

汤市建
亚马逊云科技数据分析解决方案架构师,负责客户大数据解决方案的咨询与架构设计。

郭韧
亚马逊云科技 AI 和机器学习方向解决方案架构师,负责基于亚马逊云科技的机器学习方案架构咨询和设计,致力于游戏、电商、互联网媒体等多个行业的机器学习方案实施和推广。在加入亚马逊云科技之前,从事数据智能化相关技术的开源及标准化工作,具有丰富的设计与实践经验。


听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
基于大语言模型知识问答应用落地实践 – 知识库构建(上)
01 背景介绍 随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以…...
一文1500字从0到1搭建 Jenkins 自动化测试平台
Jenkins 自动化测试平台的作用 自动化构建平台的执行流程(目标)是: 我们将代码提交到代码托管工具上,如github、gitlab、gitee等。 1、Jenkins要能够检测到我们的提交。 2、Jenkins检测到提交后,要自动拉取代码&#x…...

前端面试:【实际项目经验】团队协作、代码管理和Git命令梳理
在现代软件开发中,团队协作、代码管理和版本控制是至关重要的方面。本文将分享一些实际项目经验,重点关注团队协作、代码管理,以及Git版本控制的关键命令和最佳实践。 团队协作: 明确角色和责任: 在项目开始阶段&#…...

关于异数OS服务器CPU效能分析工具
该工具发布背景 近年来,国产服务器CPU产业的逐渐发展,但由于专业性较差,与国外存在40年以上技术差距,一些服务器CPU厂商利用信息差来制造一些非专业的数据夸大并虚假宣传混淆视听,成功达到劣币驱良币的目标࿰…...

十四、pikachu之XSS
文章目录 1、XSS概述2、实战2.1 反射型XSS(get)2.2 反射型XSS(POST型)2.3 存储型XSS2.4 DOM型XSS2.5 DOM型XSS-X2.6 XSS之盲打2.7 XSS之过滤2.8 XSS之htmlspecialchars2.9 XSS之href输出2.10 XSS之JS输出 1、XSS概述 Cross-Site S…...

五分钟了解最短路径寻路算法:Dijkstra 迪杰斯特拉
最短路径查找算法 寻路算法在生活中应用十分常见。本文实现的是关于图的最短路径查找算法。 该算法比较常见于游戏和室内地图导航。 实现 例子:几个节点之间,相连接的线段有固定长度,该长度决就是通过代价。查找到花费最少的路径。该图结构…...
【ARM】Day8 中断
1. 思维导图 2. 实验要求: 实现KEY1/LEY2/KE3三个按键,中断触发打印一句话,并且灯的状态取反 key1 ----> LED3灯状态取反 key2 ----> LED2灯状态取反 key3 ----> LED1灯状态取反 key3.h #ifndef __KEY3_H__ #define __KEY3_H__#in…...

大数据Flink(六十八):SQL Table 的基本概念及常用 API
文章目录 SQL & Table 的基本概念及常用 API 一、一个 Table API\SQL任务的代码结构...

算法练习- 其他算法练习6
文章目录 数字序列比大小最佳植树距离文艺汇演计算误码率二维伞的雨滴效应阿里巴巴找黄金宝箱4 数字序列比大小 A、B两人一人一个整数数组,长度相等,元素随即;两人随便拿出一个元素(弹出),比较大小&#x…...

ModaHub魔搭社区:WinPlan经营大脑管理中心
角色权限 展示设置的角色,及对应的成员及权限点。角色、成员、权限点可自由配置;管理员的角色不可删除、权限点默认全部不可更改。 WinPlan决策系统 算力 阿里云 腾讯云 AWS亚马逊 框架 业务数据基座 WinPlan垂直大模型 模型 分...
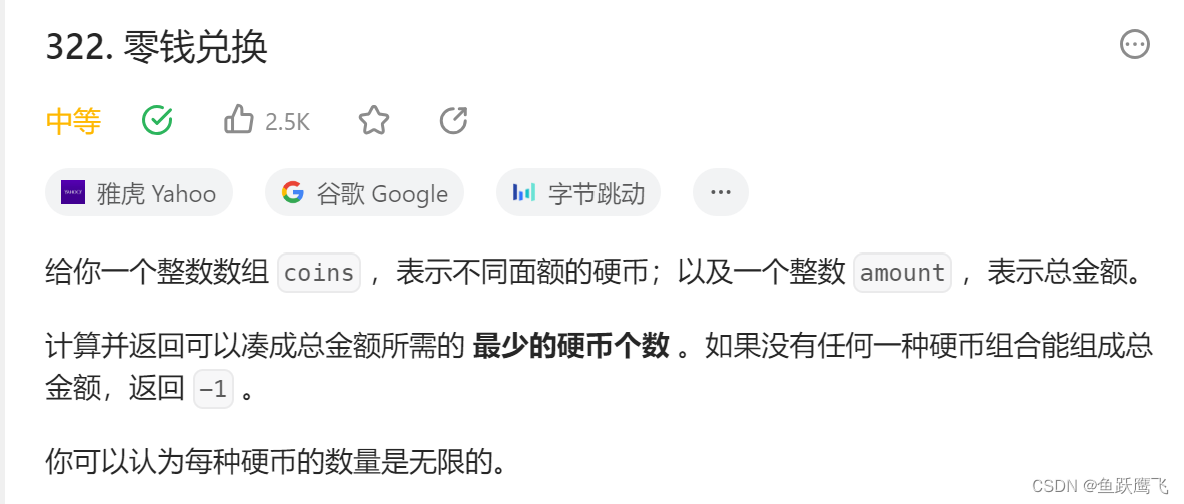
滑动窗口系列4-Leetcode322题零钱兑换-限制张数-暴力递归到动态规划再到滑动窗口
这个题目是Leecode322的变种,322原题如下: 我们这里的变化是把硬币变成可以重复的,并且只有coins数组中给出的这么多的金币,也就是说有数量限制: package dataStructure.leecode.practice;import java.util.Arrays; i…...
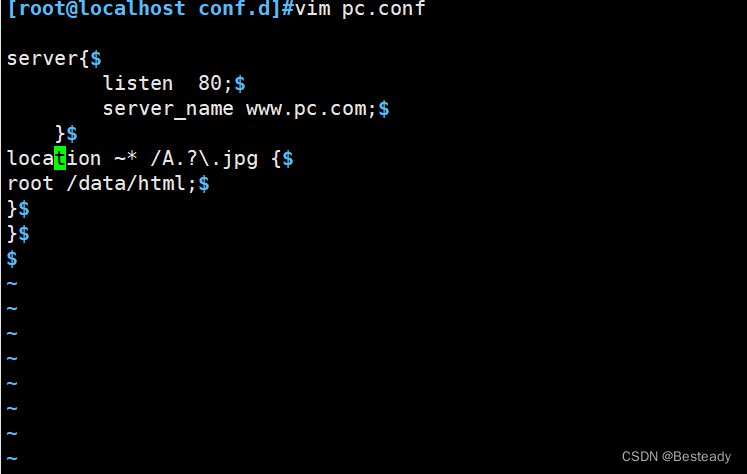
Nginx全局配置
一、修改启动进程数 worker_processes 1; #允许的启动工作进程数数量,和你真实的cpu数量有关 1 worker_processes auto; #如果设置为auto 就是你真实的cpu数量 ps axo pid,cmd,psr,ni|grep nginx #可以看到 nginx的 worker数量 二、日制分割 [rootyuji ~]#…...

VUE笔记(四)vue的组件
一、组件的介绍 1、组件的作用 整个项目都是由组件组成 可以让代码复用:相似结构代码可以做成一个组件,直接进行调用就可以使用,提高代码复用性 可以让代码具有可维护性(只要改一处,整个引用的部分全部都变…...

菜鸟教程《Python 3 教程》笔记
菜鸟教程《Python 3 教程》笔记 0 写在前面1 基本数据类型1.1 Number(数字)1.2 String(字符串)1.3 bool(布尔类型)1.4 List(列表)1.5 Tuple(元组)1.6 Set&…...

JAVA学习-愚见
JAVA学习-愚见 分享一下Java的学习路线,仅供参考【本人亲测,真实有效】 1、尽可能推荐较新的课程 2、大部分视频在B站上直接搜关键词就行【自学,B大的学生】 文章目录 JAVA学习-愚见前期准备Java基础课程练手项目 数据库JavaWeb前端基础 Vue…...

Watch数据监听详解
一、Vue2写法 1、watch使用的几种方法 1、通过 watch 监听 data 数据的变化,数据发生变化时,就会打印当前的值 watch: {data(val, value) {console.log(val)console.log(value)}} 2、通过 watch 监听 list 数据的变化,数据发生变化时&…...
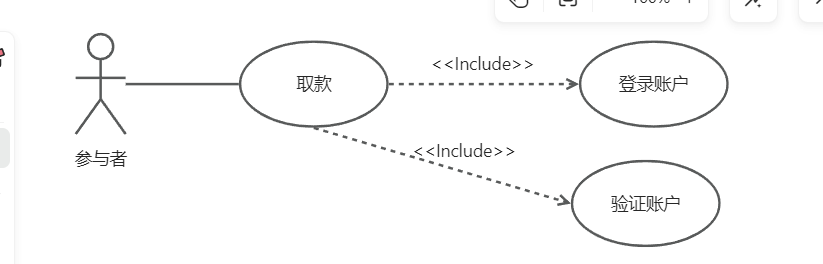
UML建模以及几种类图的理解
文章目录 前言1.用例与用例图1.1 参与者1.2 用例之间的关系1.3 用例图1.4 用例的描述 2.交互图2.1 顺序图2.2 协作图 3.类图和对象图3.1 关联关系3.2 聚合和组合3.3 泛化关系3.4 依赖关系 4.状态图与活动图4.1 状态图4.2 活动图 5.构件图 前言 UML通过图形化的表示机制从多个侧…...
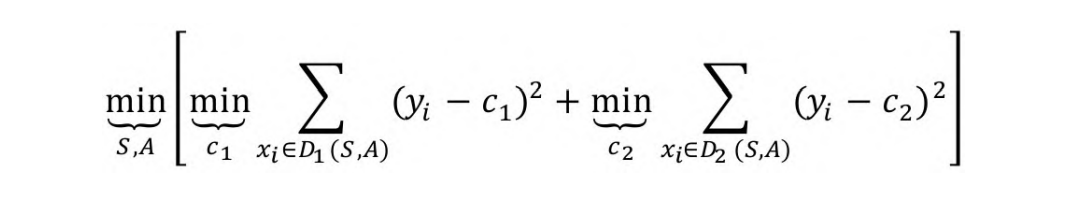
opencv进阶18-基于opencv 决策树导论
1. 什么是决策树? 决策树是最早的机器学习算法之一,起源于对人类某些决策过程 的模仿,属于监督学习算法。 决策树的优点是易于理解,有些决策树既可以做分类,也可以做回归。在排名前十的数据挖掘算法中有两种是决策树[1…...

13.4 目标检测锚框标注 非极大值抑制
锚框的形状计算公式 假设原图的高为H,宽为W 锚框形状详细公式推导 以每个像素为中心生成不同形状的锚框 # s是缩放比,ratio是宽高比 def multibox_prior(data, sizes, ratios):"""生成以每个像素为中心具有不同形状的锚框"""in_he…...
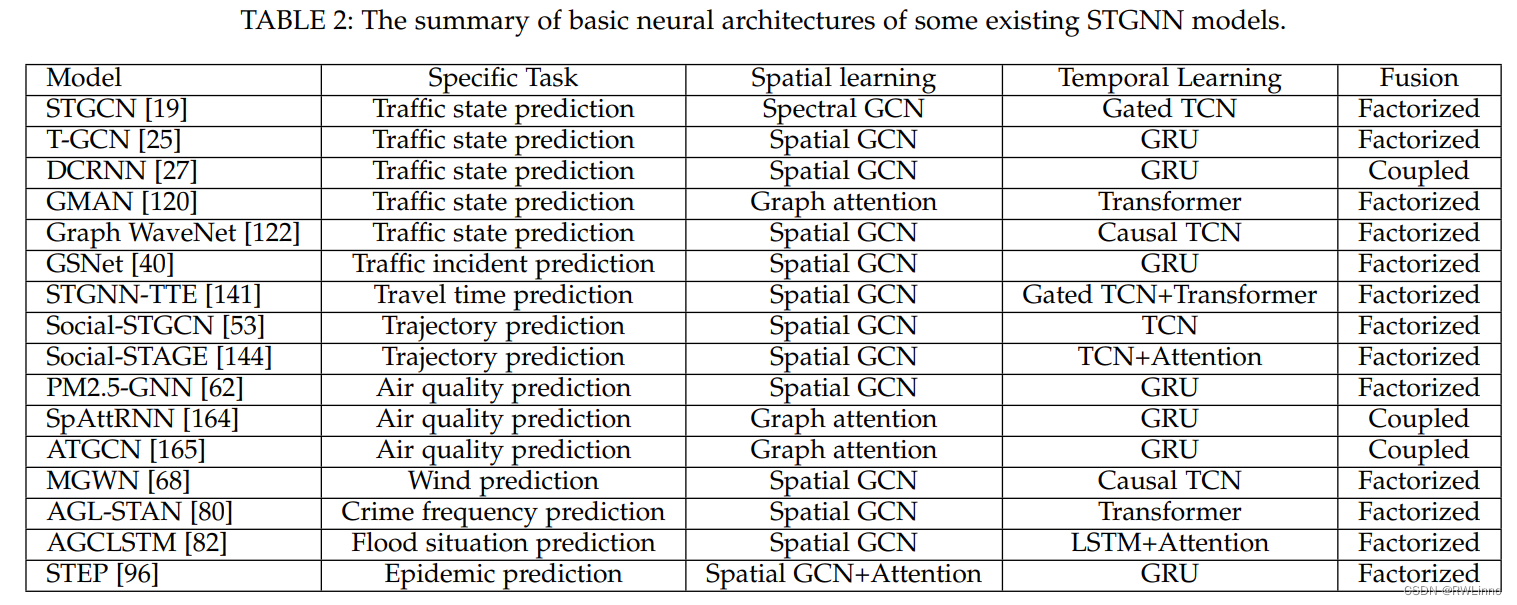
【论文笔记】最近看的时空数据挖掘综述整理8.27
Deep Learning for Spatio-Temporal Data Mining: A Survey 被引用次数:392 [Submitted on 11 Jun 2019 (v1), last revised 24 Jun 2019 (this version, v2)] 主要内容: 该论文是一篇关于深度学习在时空数据挖掘中的应用的综述。论文首先介绍了时空数…...

千问 LeetCode 2561. 重排水果 Python3实现
这道题的核心是贪心 利用全局最小值做中介交换。下面给出Python3实现,附带详细注释。from typing import List from collections import Counterclass Solution:def minCost(self, basket1: List[int], basket2: List[int]) -> int:# 1. 统计每个水果在两个篮子…...

DeepSeek LeetCode 2561. 重排水果 Java实现
LeetCode 2561. 重排水果题目分析有两个长度为 n 的数组 basket1 和 basket2,每个数组包含若干水果。每次操作可以交换两个数组中的任意水果,花费为这两个水果中较小的那个值。目标是使两个数组中的水果种类和数量完全相同(即两个数组重排后相…...

免费文档下载终极方案:如何优雅获取百度文库等30+平台资源
免费文档下载终极方案:如何优雅获取百度文库等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为…...

别再走弯路!2026亲测靠谱的AI论文写作工具|安心版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

AI工程师必备:可验证、可执行、可落地的AI资讯简报
1. 这是一份真正“能用”的AI资讯简报,不是信息噪音收集器 “ This AI newsletter is all you need #40 ”——看到这个标题,你大概率会下意识划走:又一个AI资讯邮件?每天几十封,点开三秒就关掉,标题党、…...

taotoken多模型聚合平台为matlab开发者提供稳定ai能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken多模型聚合平台为matlab开发者提供稳定ai能力 对于使用MATLAB进行数据分析、仿真建模或算法开发的工程师和研究人员而言&a…...

网络设备27MHz差分时钟选型与设计实战:从HCSL接口到低抖动布局
1. 项目概述:为什么网络设备的“心跳”如此挑剔?干了十几年硬件设计,从早期的百兆交换机做到现在的万兆、25G甚至更高速率的设备,我越来越深刻地体会到,一个稳定、干净的时钟信号,对于网络设备而言…...

课堂教学质量评估系统:基于加权欧氏距离的评分实现
在教育数字化转型的背景下,课堂教学质量的量化评估成为提升教学水平的关键环节。本文将分享一套基于加权欧氏距离算法的课堂教学质量评分系统实现方案,该方案通过多维度数据采集与权重计算,实现对课堂教学质量的客观、精准评估。一、核心设计…...
)
web服务器的实验(RHCE)
web服务器的实验(RHCE) 实验目录 实验1:快速搭建一个网站 实验2:替换网页目录 实验3:搭建网站使用内网穿透 实验4:搭建密码验证功能来访问网站数据 实验5:新建文件目录列表的网站…...

146台储罐+10台喷淋塔,新能源项目为什么认准PPH?
在新能源材料项目的设备选型中,PPH正逐渐变成大多数厂家选择的一种材质。 最近美联新材料的新能源产业化项目,一口气向吉庆订了146台PPH贮罐、10台PPH喷淋塔,今天就借着这个真实项目,来聊一聊,PPH为什么能成成新能源项…...