菜鸟教程《Python 3 教程》笔记
菜鸟教程《Python 3 教程》笔记
- 0 写在前面
- 1 基本数据类型
- 1.1 Number(数字)
- 1.2 String(字符串)
- 1.3 bool(布尔类型)
- 1.4 List(列表)
- 1.5 Tuple(元组)
- 1.6 Set(集合)
- 1.7 Dictionary(字典)
- 1.8 bytes 类型
- 2 数据类型转换
- 2.1 隐式类型转换
- 2.2 显式类型转换
- 2.2.1 int() 函数
- 2.2.2 repr() 函数
- 2.2.3 frozenset ()函数
- 3 Python 3 运算符
- 3.1 赋值运算符
- 3.2 位运算符
- 3.3 逻辑运算符
- 3.4 身份运算符
- 3.5 运算符优先级
- 4 数字
- 4.1 Python 数字运算
- 4.2 数字函数
- 4.2.1 abs() 函数
- 4.2.2 ceil() 函数
- 4.2.3 cmp() 函数(Python 3 已废弃)
- 4.2.4 floor() 函数
- 4.2.5 max() 函数
- 4.2.6 modf() 函数
- 4.2.7 pow() 函数
- 4.2.8 round() 函数
- 4.3 随机数函数
- 4.3.1 choice() 函数
- 4.3.2 randrange() 函数
- 4.3.3 shuffle() 函数
- 4.3.4 uniform() 函数
- 5 字符串
- 5.1 Python 转义字符
- 5.2 Python 字符串格式化
- 5.3 f-string
- 5.4 Unicode 字符串
- 5.5 Python 的字符串方法
- 5.5.1 capitalize()
- 5.5.2 center()、ljust()、rjust()、zfill()
- 5.5.3 count()
- 5.5.4 endswith()、startswith()
- 5.5.5 expandtabs()
- 5.5.6 find()、rfind()、index()和rindex()
- 5.5.7 isalnum() 等方法
- 5.5.8 maketrans()、translate()
- 5.5.9 rstrip()、lstrip()、strip()
- 5.5.10 split()
- 5.5.11 splitlines()
- 5.5.12 title()
- 6 列表
- 6.1 删除列表元素
- 6.2 列表函数和方法
- 6.2.1 max()、min()
- 6.2.2 reverse()
- 6.2.3 sort()
- 7 元组
- 8 字典
- 8.1 字典内置函数和方法
- 8.1.1 fromkeys()
- 8.1.2 get()、setdefault()
- 8.1.3 popitem()
- 9 集合
- 9.1 集合的基本操作
- 9.2 集合内置方法
- 9.2.1 add()、update()
- 9.2.2 pop()、remove()、discard()
- 9.2.3 difference()、differece_update()等
- 9.2.4 isdisjoint()
- 9.2.5 issubset()、issuperset()
0 写在前面
笔记带有个人侧重点,不追求面面俱到。
1 基本数据类型
出处: 菜鸟教程 - Python3 基本数据类型
Python 3 的六个标准数据类型中:
- 不可变数据(3 个): Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个): List(列表)、Dictionary(字典)、Set(集合)。
此外还有一些高级的数据类型,如: 字节数组类型(bytes)。
1.1 Number(数字)
注意:Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加,
True==1、False==0会返回 True,但可以通过 is 来判断类型。
>>> issubclass(bool, int)
True
>>> True==1
True
>>> False==0
True
>>> True+1
2
>>> False+1
1
>>> 1 is True
False
>>> 0 is False
False
1.2 String(字符串)
Python 使用反斜杠 \转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
>>> print('Ru\noob')
Ru
oob
>>> print(r'Ru\noob')
Ru\noob
1.3 bool(布尔类型)
- 布尔类型可以和其他数据类型进行比较,比如数字、字符串等。在比较时,Python 会将 True 视为 1,False 视为 0。
- 布尔类型也可以被转换成其他数据类型,比如整数、浮点数和字符串。在转换时,True 会被转换成 1,False 会被转换成 0。
a = True
b = False# 比较运算符
print(2 < 3) # True
print(2 == 3) # False# 逻辑运算符
print(a and b) # False
print(a or b) # True
print(not a) # False# 类型转换
print(int(a)) # 1
print(float(b)) # 0.0
print(str(a)) # "True"
1.4 List(列表)
list1 = [x for x in range(9)]print(list1[-1::-2]) # [9]
print(list1[-1:-4]) # []
1.5 Tuple(元组)
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
1.6 Set(集合)
注意: 创建一个空集合必须用
set()而不是{},因为{}是用来创建一个空字典。
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')print(a)
print(a - b) # a 和 b 的差集
print(b - a)
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素{'d', 'c', 'r', 'a', 'b'}
{'r', 'd', 'b'}
{'m', 'z', 'l'}
{'m', 'd', 'c', 'r', 'a', 'z', 'b', 'l'}
{'a', 'c'}
{'m', 'r', 'd', 'z', 'b', 'l'}
1.7 Dictionary(字典)
键(key)必须使用不可变类型。在同一个字典中,键(key)必须是唯一的。
构造函数 dict() 可以直接从键值对序列中构建字典如下:
>>> dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>> dict(Runoob=1, Google=2, Taobao=3)
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
1.8 bytes 类型
什么是 bytes 类型:
- 在 Python3 中,bytes 类型表示的是不可变的二进制序列(byte sequence)。
- 与字符串类型不同的是,bytes 类型中的元素是整数值(0 到 255 之间的整数),而不是 Unicode 字符。
怎么创建 bytes 类型:
- 使用 b 前缀;
- 可以使用
bytes()函数将其他类型的对象转换为 bytes 类型。
x = bytes("hello", encoding="utf-8")
注意: bytes 类型中的元素是整数值,因此在进行比较操作时需要使用相应的整数值。
x = b"hello"
if x[0] == ord("h"):print("The first element is 'h'")
2 数据类型转换
出处:菜鸟教程 - Python3 数据类型转换
Python 数据类型转换可以分为2种:
- 隐式类型转换 - 自动完成;
- 显式类型转换 - 需要使用类型函数来转换。
2.1 隐式类型转换
对两种不同类型的数据进行运算,较低数据类型(整数)就会转换为较高数据类型(浮点数)以避免数据丢失。
2.2 显式类型转换
| Column 1 | Column 2 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
2.2.1 int() 函数
语法:
class int(x, base=10)
参数:
- x – 字符串或数字。
- base – 进制数,默认十进制。
返回值:
返回整型数据。
实例:
>>>int() # 不传入参数时,得到结果0
0
>>> int(3)
3
>>> int(3.6)
3
>>> int('12', 16) # 如果是带参数base的话,12要以字符串的形式进行输入,12 为 16进制
18
>>> int('0xa', 16)
10
>>> int('10', 8)
8
int(float("2.3"))
2.2.2 repr() 函数
语法:
repr(object)
参数:
- object – 对象。
返回值:
返回一个对象的 string 格式。
实例:
>>> s = 'RUNOOB'
>>> repr(s)
"'RUNOOB'"
>>> dict = {'runoob': 'runoob.com', 'google': 'google.com'};
>>> repr(dict)
"{'google': 'google.com', 'runoob': 'runoob.com'}"
>>>
str()和repr()的区别:
出处:python3编程基础:str()、repr()的区别
区别 1:字符串再转换为字符串
>>> repr('abd') #repr转换后是在'abd'的外层又加了一层引号
"'abd'"
>>> str('abd') #str转换后还是原来的值
'abd'
>>> str('abd') == 'abd'
True
>>> repr('abd') == 'abd'
False
>>> len(repr('abd')) #repr转换后的字符串和str转换后的字符串个数都是不一样的
5
>>> len(str('abd'))
3
区别 2:命令行下print和直接输出的对比
>>> class A():
... def __repr__(self):
... return 'repr'
... def __str__(self):
... return 'str'
...
>>> a = A()
>>> a #直接输出调用的是repr方法
repr
>>> print(a) #print调用的是str方法
str
repr的使用场景:
>>> s = 'abdcf'
>>> eval('['+','.join([repr(i) for i in s])+']')
['a', 'b', 'd', 'c', 'f']
>>> eval('['+','.join([str(i) for i in s])+']') #str报错
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<string>", line 1, in <module>
NameError: name 'b' is not defined
2.2.3 frozenset ()函数
语法:
class frozenset([iterable])
参数:
- iterable – 可迭代的对象,比如列表、字典、元组等等。
返回值:
返回新的 frozenset 对象,如果不提供任何参数,默认会生成空集合。
为什么需要冻结的集合(即不可变的集合)呢?因为在集合的关系中,有集合的中的元素是另一个集合的情况,但是普通集合(set)本身是可变的,那么它的实例就不能放在另一个集合中(set中的元素必须是不可变类型)。
所以,frozenset提供了不可变的集合的功能,当集合不可变时,它就满足了作为集合中的元素的要求,就可以放在另一个集合中了。
3 Python 3 运算符
出处:菜鸟教程 - Python3 运算符
Python 语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 位运算符
- 成员运算符
- 身份运算符
3.1 赋值运算符
Python 3.8 新增了,海象运算符 := ,可在表达式内部为变量赋值,目的是避免重复调用,提高运行时间。
示例:
if (n := len(a)) > 10:print(f"List is too long ({n} elements, expected <= 10)")
上述代码,避免2次调用 len(),也省去使用中间变量。
扩展阅读:
Python :=海象运算符最简单的解释
What’s New In Python 3.8
3.2 位运算符
#!/usr/bin/python3a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
# 按位与运算符
c = a & b # 12 = 0000 1100
print ("1 - c 的值为:", c)
# 按位或运算符
c = a | b # 61 = 0011 1101
print ("2 - c 的值为:", c)
# 按位异或运算符
c = a ^ b # 49 = 0011 0001
print ("3 - c 的值为:", c)
# 按位取反运算符
c = ~a # -61 = 1100 0011
print ("4 - c 的值为:", c)
# 左移动运算符
c = a << 2 # 240 = 1111 0000
print ("5 - c 的值为:", c)
# 右移动运算符
c = a >> 2 # 15 = 0000 1111
print ("6 - c 的值为:", c)
3.3 逻辑运算符
| 运算符 | 逻辑表达式 | 描述 |
|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 |
| or | x or y | 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 |
实例:
print(10 and 20) # 20
print(0 and 20) # 0
print(10 or 20) # 10
print(0 or 20) # 20
print(0 or True) # True
print(not 0) # True
print(not True) # False
3.4 身份运算符
is 与 == 的区别:is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值(子对象)是否相等。
补充:
is判断两个对象是否为同一对象,是通过 id 来判断的;当两个基本类型数据(或元组)内容相同时,id 会相同,但并不代表 a 会随 b 的改变而改变。
==判断两个对象的内容是否相同,是通过调用__eq__()来判断的。
实例:
>>>a = [1, 2, 3]
>>> b = a
>>> b is a
True
>>> b == a
True
>>> b = a[:]
>>> b is a
False
>>> b == a
True
上述代码,b = a 中 b 是 a 的引用,指向同一个内存地址;b = a[:] 中 b 是 a 的浅拷贝,共用相同的子对象。可以参考:Python中直接赋值、浅拷贝和深拷贝的区别
补充内容:
a = 100
b = 100
print(a is b) # True
print(a == b) # True
上述代码中,a 和 b 指向了同一个内存地址。这是 Python 的特性,变量以内容为基准。这个特性决定了在 Python 中,数字类型的值是不可变的。当 a 的值改变时,是 a 指向了新的内存地址,而不是内存地址中的值改变了。
3.5 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符, 相同单元格内的运算符具有相同优先级。 运算符均指二元运算,除非特别指出。 相同单元格内的运算符从左至右分组(除了幂运算是从右至左分组):
| 运算符 | 描述 |
|---|---|
| (expressions…), [expressions…], {key: value…}, {expressions…} | 圆括号的表达式 |
| x[index], x[index: index], x(arguments…), x.attribute | 读取,切片,调用,属性引用 |
| await x | await 表达式 |
| ** | 乘方(指数) |
| +x, -x, ~x | 正,负,按位非 NOT |
| *, @, /, //, % | 乘,矩阵乘,除,整除,取余 |
| +, - | 加和减 |
| <<, >> | 移位 |
| & | 按位与 AND |
| ^ | 按位异或 XOR |
| | | 按位或 OR |
| in,not in, is,is not, <, <=, >, >=, !=, == | 比较运算,包括成员检测和标识号检测 |
| not x | 逻辑非 NOT |
| and | 逻辑与 AND |
| or | 逻辑或 OR |
| if – else | 条件表达式 |
| lambda | lambda 表达式 |
| := | 赋值表达式 |
注意:
and的优先级比or高。
4 数字
出处:菜鸟教程 - Python3 数字(Number)
数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。
4.1 Python 数字运算
注意:
//得到的并不一定是整数类型的数,它与分母分子的数据类型有关系。
实例:
>>> 7//2
3
>>> 7.0//2
3.0
>>> 7//2.0
3.0
4.2 数字函数
4.2.1 abs() 函数
描述:
abs() 函数返回数字的绝对值。
语法:
abs(x)
参数:
- x – 数值表达式,可以是整数,浮点数,复数。
返回值:
函数返回 x(数字)的绝对值,如果参数是一个复数,则返回它的大小。
>>>v = Vecter(3, 4)
>>>abs(v)
5.0
fabs() 与 abs() 的区别:
abs()是一个内置函数,而 fabs() 在 math 模块中定义的;fabs()函数只适用于 float 和 integer 类型,而 abs() 也适用于复数;abs()的返回值可以是整数也可以是浮点数,视输入而定,fabs()的返回值总是浮点数。
4.2.2 ceil() 函数
描述:
ceil() 函数返回一个大于或等于 x 的的最小整数。(向上取整)
语法:
import math
math.ceil(x)
参数:
- x – 数值表达式。
返回值:
返回一个大于或等于 x 的的最小整数。
4.2.3 cmp() 函数(Python 3 已废弃)
描述:
如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
注意: Python 3 已废弃,使用 (x>y)-(x<y) 替换。
4.2.4 floor() 函数
描述:
floor() 返回数字的下舍整数,小于或等于 x。(向下取整)
语法:
import math
math.floor(x)
参数:
- x – 数值表达式。
返回值:
返回小于或等于 x 的整数。
4.2.5 max() 函数
描述:
max() 方法返回给定参数的最大值,参数可以为序列。
注意: 入参类型不能混入,要么全是数字,要么全是序列。入参是序列的话: 单序列入参,返回序列中最大的一个数值。多序列入参, 按索引顺序,逐一对比各序列的当前索引位的 “值”,直到遇见最大值立即停止对比,并返回最大值所在的序列
>>> max(0, True)
True
>>> max([1,2,3])
3
>>> max([2,4], [3,6])
[3, 6]
>>> max([2,4], [1,5])
[2, 4]
>>> max((1,-1,0), (True,False,2,0),(1, 0, 0, 2))
(True, False, 2, 0)
>>> max((1,-1,0), (True,),(1,))
(1, -1, 0)
>>> max([1,3,2],3,4) #非法入参
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: '>' not supported between instances of 'int' and 'list'
>>> max((1,2,3), [2,4,1]) #非法入参
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: '>' not supported between instances of 'list' and 'tuple'
4.2.6 modf() 函数
描述:
modf() 方法返回 x 的整数部分与小数部分,两部分的数值符号与 x 相同,整数部分以浮点型表示。
语法:
import math
math.modf(x)
参数:
- x – 数值表达式。
返回值:
返回x的整数部分与小数部分。
实例:
>>> import math
>>> math.modf(3.2)
(0.20000000000000018, 3.0)
>>> math.modf(-0.01)
(-0.01, -0.0)
>>> type(math.modf(-3.2))
<class 'tuple'>
4.2.7 pow() 函数
描述:
pow() 方法返回 xy(x的y次方) 的值。
语法:
import math
math.pow(x, y)
pow(x, y[, z])
注意:
pow()通过内置的方法直接调用,内置方法会把参数作为整型,而 math 模块则会把参数转换为 float。
参数:
- x – 数值表达式。
- y – 数值表达式。
- z – 数值表达式。
返回值:
返回 xy(x的y次方) 的值。
4.2.8 round() 函数
描述:
round() 方法返回浮点数 x 的四舍五入值,准确的说保留值将保留到离上一位更近的一端(四舍六入)。精度要求高的,不建议使用该函数。
语法:
round( x [, n] )
参数:
- x – 数字表达式。
- n – 表示从小数点位数,其中 x 需要四舍五入,默认值为 0。
返回值:
返回浮点数x的四舍五入值。
注意:
round()保留值将保留到离上一位更近的一端(四舍六入)。如果距离两边一样远,会保留到偶数的一边。比如 round(0.5) 和 round(-0.5) 都会保留到 0,而 round(1.5) 会保留到 2。同时,受浮点数精度影响,结果不一定复合预期。
参考:python中关于round函数的小坑
4.3 随机数函数
4.3.1 choice() 函数
描述:
choice() 方法返回一个列表,元组或字符串的随机项。
语法:
import random
random.choice(seq)
参数:
- seq – 可以是一个列表,元组或字符串。
返回值:
返回随机项。
实例:
random.choice(range(100))
random.choice([1, 2, 3, 5, 9])
random.choice('Runoob')
4.3.2 randrange() 函数
描述:
randrange() 方法返回指定递增基数集合中的一个随机数,基数默认值为1。
语法:
import random
random.randrange ([start,] stop [,step])
参数:
- start – 指定范围内的开始值,包含在范围内;
- stop – 指定范围内的结束值,不包含在范围内;
- step – 指定递增基数。
返回值:
从给定的范围返回随机项。
实例:
random.randrange(1, 100, 2)
random.randrange(100)
4.3.3 shuffle() 函数
描述:
shuffle() 方法将序列的所有元素随机排序。
语法:
import random
random.shuffle(lst)
参数:
- lst – 列表。
返回值:
返回 None。
4.3.4 uniform() 函数
描述:
uniform() 方法将随机生成下一个实数,它在 [x,y] 范围内。
语法:
import random
random.uniform(x, y)
参数:
- x – 随机数的最小值,包含该值;
- y – 随机数的最大值,包含该值。
返回值:
返回一个浮点数 N,取值范围为如果 x<y 则 x <= N <= y,如果 y<x 则y <= N <= x。
5 字符串
出处:菜鸟教程 - Python3 字符串
5.1 Python 转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 |
| \f | 换页 |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行。 |
| \other | 其它的字符以普通格式输出 |
实例:
>>> print("line1 \
... line2 \
... line3")
line1 line2 line3
>>> print("\\")
\
>>> print('\'')
'
>>> print("\"")
"
>>> print("\a")
# 执行后电脑有响声。
>>> print("Hello \b World!")
Hello World!
>>> print("\000")>>> print("\n")>>> print("Hello \v World!")
Hello World!
>>> print("Hello\rWorld!")
World!
>>> print('google runoob taobao\r123456')
123456 runoob taobao
>>> print("Hello \f World!")
Hello World!
>>> print("\110\145\154\154\157\40\127\157\162\154\144\41")
Hello World!
>>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21")
Hello World!
一段有趣的代码:
import timefor i in range(101):print("\r{:3}%".format(i),end=' ')time.sleep(0.05)
5.2 Python 字符串格式化
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
| 符号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %0 | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%‘输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
5.3 f-string
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果:
>>> x = 1
>>> print(f'{x+1}') # Python 3.6
2>>> x = 1
>>> print(f'{x+1=}') # Python 3.8
x+1=2
5.4 Unicode 字符串
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串。
5.5 Python 的字符串方法
5.5.1 capitalize()
描述:
capitalize() 将字符串的第一个字母变成大写,其他字母变小写。
语法:
str.capitalize()
5.5.2 center()、ljust()、rjust()、zfill()
描述:
center() 方法返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
rjust() 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0。zfill(width) 作用同 rjust(width, "0")。
语法:
str.center(width[, fillchar])
参数:
- width – 字符串的总宽度。
- fillchar – 填充字符。
返回值:
返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
实例:
str = "[runoob]"
print ("str.center(40, '*') : ", str.center(40, '*'))
print ("str.center(40, '*') : ", str.ljust(40, '*'))
print ("str.center(40, '*') : ", str.rjust(40, '*'))str.center(40, '*') : ****************[runoob]****************
str.center(40, '*') : [runoob]********************************
str.center(40, '*') : ********************************[runoob]
注意:
width小于字符串长度时,返回字符串,不会截断;fillchar只能接收单个字符;- 奇数个字符时,优先补充右边;偶数个字符时,优先补充左边。
>>> str = "[www.runoob.com]"
>>> print ("str.center(4, '*') : ", str.center(4, '*'))
str.center(4, '*') : [www.runoob.com] // width 小于字符串宽度>>> str = "[www.runoob.com]"
>>> print ("str.center(40, '?!') : ", str.center(40, '?!'))
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: The fill character must be exactly one character long>>> print('123'.center(4, '*')) # 奇数个字符时优先向右边补*
123*
>>> print('1234'.center(5, '*')) # 偶数个字符时优先向左边补*
*1234
>>> print('1234'.center(7, '*'))
**1234*
5.5.3 count()
描述:
count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法:
str.count(sub, start= 0,end=len(string))
参数:
- sub – 搜索的子字符串;
- start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0;
- end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
返回值:
该方法返回子字符串在字符串中出现的次数。
实例:
str="www.runoob.com"
sub='o'
print ("str.count('o') : ", str.count(sub))
sub='run'
print ("str.count('run', 0, 10) : ", str.count(sub,0,10))
# 输出
str.count('o') : 3
str.count('run', 0, 10) : 1
注意: 已统计过的字符不重复统计。
>>> str1,str2,str3 = 'aaaa','aaaaa','aaaaaa'
>>> print(str2.count('aa'))
2
>>> print(str2.count('aa'))
2
>>> print(str3.count('aa'))
3
5.5.4 endswith()、startswith()
描述:
endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回 True,否则返回 False。可选参数 “start” 与 “end” 为检索字符串的开始与结束位置。
语法:
str.endswith(suffix[, start[, end]])
参数:
- suffix – 该参数可以是一个字符串或者是一个元素;
- start – 字符串中的开始位置;
- end – 字符中结束位置。
返回值:
如果字符串含有指定的后缀返回 True,否则返回 False。
注意: 判断范围为 [start, end) 。
5.5.5 expandtabs()
描述:
expandtabs() 方法把字符串中的 tab 符号 \t 转为空格,tab 符号 \t 默认的空格数是 8,在第 0、8、16…等处给出制表符位置,如果当前位置到开始位置或上一个制表符位置的字符数不足 8 的倍数则以空格代替。
语法:
str.expandtabs(tabsize=8)
参数:
- tabsize – 指定转换字符串中的 tab 符号
\t转为空格的字符数。
返回值:
该方法返回字符串中的 tab 符号 \t 转为空格后生成的新字符串。
实例:
str = "this is\tstring example....wow!!!" # \t 前面的字符串长度为 7print("替换 \\t 符号: " + str.expandtabs(0)) # 删除\t
print("替换 \\t 符号: " + str.expandtabs(1)) # 补充1个
print("替换 \\t 符号: " + str.expandtabs(2)) # 补充1个
print("替换 \\t 符号: " + str.expandtabs(3)) # 补充2个
print("替换 \\t 符号: " + str.expandtabs(7)) # 补充7个
# 输出
替换 \t 符号: this isstring example....wow!!!
替换 \t 符号: this is string example....wow!!!
替换 \t 符号: this is string example....wow!!!
替换 \t 符号: this is string example....wow!!!
替换 \t 符号: this is string example....wow!!!
5.5.6 find()、rfind()、index()和rindex()
语法:
str.find(str, beg=0, end=len(string))
str.index(str, beg=0, end=len(string))
注意: 寻值范围为 [beg, end) 。
两者的区别:
未找到子字符串时,find() 返回 -1,index() 抛出异常。
5.5.7 isalnum() 等方法
| 方法 | 描述 | True | False |
|---|---|---|---|
| isalnum() | 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False | a-z,A-Z,0-9,中文 | 标点符号 |
| isalpha() | 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False | a-z,A-Z,中文 | 0-9,标点符号 |
| isdigit() | 如果字符串只包含数字则返回 True 否则返回 False | 0-9,byte数字(单字节),全角数字(双字节) | 汉字数字,罗马数字 |
| isnumeric() | 如果字符串中只包含数字字符,则返回 True,否则返回 False | Unicode 数字,全角数字(双字节),汉字数字 | 罗马数字 |
| isdecimal() | 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false | 0-9,全角数字(双字节) | 罗马数字,汉字数字 |
| isspace() | 如果字符串中只包含空白,则返回 True,否则返回 False | 空格、制表符(\t)、换行(\n)、回车(\r) | |
| isupper() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False | A-Z + 其他 | a-z + 其他 |
| islower() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False | a-z + 其他 | A-Z + 其他 |
| istitle() | 如果字符串是标题化的(见 5.5.12 title())则返回 True,否则返回 False | 大写字母开头,后接小写字母或中文 |
实例:
num = "\u0030" #unicode 0
num.isdigit() # True
num.isdecimal() # True
num.isnumeric() # Truenum = "\u00B2" #unicode ²
num.isdigit() # True
num.isdecimal() # False
num.isnumeric() # Truenum = "\u00B2" #unicode ½
num.isdigit() # False
num.isdecimal() # False
num.isnumeric() # Truenum = "1" # 全角
num.isdigit() # True
num.isdecimal() # True
num.isnumeric() # Truenum = b"1" # byte
num.isdigit() # True
num.isdecimal() # AttributeError 'bytes' object has no attribute 'isdecimal'
num.isnumeric() # AttributeError 'bytes' object has no attribute 'isnumeric'num = "IV" # 罗马数字
num.isdigit() # False
num.isdecimal() # False
num.isnumeric() # Falsenum = "四" # 汉字
num.isdigit() # False
num.isdecimal() # False
num.isnumeric() # True
5.5.8 maketrans()、translate()
描述:
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系。
注意: Python3.4 已经没有 string.maketrans() 了,取而代之的是内建函数: bytearray.maketrans()、bytes.maketrans()、str.maketrans() 。
语法:
string.maketrans(x[, y[, z]])
参数:
- x – 必需,字符串中要替代的字符组成的字符串;
- y – 可选,相应的映射字符的字符串;
- z – 可选,要删除的字符。
返回值:
返回字符串转换后生成的新字符串。
实例:
# 一个参数,该参数必须为字典
>>> d = {'a':'1','b':'2','c':'3','d':'4','e':'5','s':'6'}
>>> trantab = str.maketrans(d)
>>> st='just do it'
>>> print(st.translate(trantab))
ju6t 4o it# 两个参数 x 和 y,x、y 必须是长度相等的字符串,并且 x 中每个字符映射到 y 中相同位置的字符
>>> x = 'abcdefs'
>>> y = '1234567'
>>> st='just do it'
>>> trantab = str.maketrans(x,y)
>>> print(st.translate(trantab))
ju7t 4o it# 三个参数 x、y、z,第三个参数 z 必须是字符串,先删除,再替换
>>> x = 'abcdefs'
>>> y='1234567'
>>> z='ot'
>>> st='just do it'
>>> trantab = str.maketrans(x,y,z)
>>> print(st.translate(trantab))
ju7 4 i
5.5.9 rstrip()、lstrip()、strip()
描述:
rstrip() 删除 string 字符串末尾的指定字符,默认为空白符,包括空格、换行符、回车符、制表符。
语法:
str.rstrip([chars])
注意:
chars是一个包含需要删除的字符的字符串。从str的末尾开始删除,直到末尾的字符不在chars中。
参数:
- chars – 指定删除的字符(默认为空白符)
返回值:
返回删除 string 字符串末尾的指定字符后生成的新字符串。
实例:
>>> random_string = "this is good "
# 字符串末尾的空格会被删除
>>> print(random_string.rstrip())
this is good
# 'si oo' 不是尾随字符,因此不会删除任何内容
>>> print(random_string.rstrip('si oo'))
this is good
# 在 'sid oo' 中 'd oo' 是尾随字符,'ood' 从字符串中删除
>>> print(random_string.rstrip('sid oo'))
this is g
# 移除逗号(,)、点号(.)、字母 s、q 或 w,这几个都是尾随字符
>>> txt = "banana,,,,,ssqqqww....."
>>> print(txt.rstrip(",.qsw"))
banana
5.5.10 split()
描述:
split() 方法通过指定分隔符对字符串进行切片,该方法将字符串分割成子字符串并返回一个由这些子字符串组成的列表。
语法:
str.split(str="", num=string.count(str))
参数:
- str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等;
- num – 分割次数,如果设置了这个参数,则最多分割成 maxsplit+1 个子字符串。默认为 -1, 即分隔所有。
返回值:
返回分割后的字符串列表。
5.5.11 splitlines()
描述:
splitlines() 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
语法:
str.splitlines([keepends])
参数:
- keepends – 在输出结果里是否去掉换行符(‘\r’, ‘\r\n’, \n’),默认为 False,不包含换行符,如果为 True,则保留换行符。
返回值:
返回一个包含各行作为元素的列表。
实例:
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines()
['ab c', '', 'de fg', 'kl']
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines(True)
['ab c\n', '\n', 'de fg\r', 'kl\r\n']
5.5.12 title()
描述:
title() 方法返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写。
注意: 单词是指以a-zA-Z之外符号分割的字母。例如:ab12cd中ab、cd是单词。
语法:
str.title()
参数:
- NA
返回值:
返回"标题化"的字符串,就是说所有单词的首字母都转化为大写。
实例:
>>> txt = "hello b2b2b2 and 3g3g3g"
>>> print(txt.title())
Hello B2B2B2 And 3G3G3G
6 列表
出处: 菜鸟教程 - Python3 列表
6.1 删除列表元素
>>> list = ['Google', 'Runoob', 1997, 2000]
>>> print ("原始列表 : ", list)
原始列表 : ['Google', 'Runoob', 1997, 2000]
>>> del list[2]
>>> print ("删除第三个元素 : ", list)
删除第三个元素 : ['Google', 'Runoob', 2000]
6.2 列表函数和方法
6.2.1 max()、min()
注意:
- 使用
max()和min()时,列表中的元素需要是同一种类型,否则无法比较;- 当列表的元素为
list[int]整型列表时,优先比较整型列表第一个元素,如果相同会继续比较下去;- 当列表的元素为
string字符串时,会比较每个字符串元素的第一个字符的 ASCII 的大小。
实例:
>>> list1 = [[1, 4], [2, 3], [1, 5]]
>>> max(list1)
[2, 3]
>>> list1 = [[1, 4], [1, 3], [1, 5]]
>>> max(list1)
[1, 5]>>> list1 = ['我最', '爱学习', 'python']
>>> max(list1)
'爱学习'
# ord('我') >>> 25105
# ord('爱') >>> 29233
# ord('p') >>> 112
6.2.2 reverse()
描述:
reverse() 函数用于反向列表中元素。
语法:
list.reverse()
6.2.3 sort()
描述:
sort() 函数用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
语法:
list.sort(key=None, reverse=False)
参数:
- key – 一个函数,入参为可迭代对象的元素,根据函数的返回值继续排序;
- reverse – 排序规则,reverse = True 降序, reverse = False 升序(默认)。
返回值:
该方法没有返回值,但是会对列表的对象进行排序。
实例:
>>> list1 = ["apple", "watermelon", "banana"]
>>> list1.sort(key = lambda ele: len(ele))
>>> list1
['apple', 'banana', 'watermelon']
7 元组
出处: 菜鸟教程 - Python3 元组
注意: tuple1 = (50,) 带
,是元组,否则是整型。
8 字典
出处: 菜鸟教程 - Python3 字典
8.1 字典内置函数和方法
8.1.1 fromkeys()
描述:
fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
语法:
dict.fromkeys(seq[, value])
参数:
- seq – 字典键值列表;
- value – 可选参数, 设置键序列(seq)对应的值,默认为 None。
返回值:
该方法返回一个新字典。
实例:
>>> seq = ('name', 'age', 'sex')
>>> dict.fromkeys(seq)
{'age': None, 'name': None, 'sex': None}
>>> dict.fromkeys(seq, 10)
{'age': 10, 'name': 10, 'sex': 10}
8.1.2 get()、setdefault()
描述:
get() 函数返回指定键的值。
setdefault() 方法和 get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
语法:
dict.get(key[, value])
dict.setdefault(key, default=None)
参数:
- key – 字典中要查找的键;
- value – 可选,如果指定键的值不存在时,返回该默认值;
- default – 键不存在时,设置的默认键值。
返回值:
返回指定键的值,如果键不在字典中返回默认值,如果不指定默认值,则返回 None。
如果 key 在 字典中,返回对应的值。如果不在字典中,则插入 key 及设置的默认值 default,并返回 default ,default 默认值为 None。
8.1.3 popitem()
描述:
popitem() 方法随机返回并删除字典中的最后一对键和值。如果字典已经为空,却调用了此方法,就报出 KeyError 异常。
9 集合
出处: 菜鸟教程 - Python3 集合
集合是一组无序排列的可哈希的值。
9.1 集合的基本操作
# 集合间的运算
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
9.2 集合内置方法
9.2.1 add()、update()
add() 只接受可哈希的值,即不可变数据,数、字符串、元组。
update 可以接受数、字符串、元组、列表、集合。
9.2.2 pop()、remove()、discard()
pop 不具名地移除集合中的元素;
remove 移除集合中的指定元素,如果元素不存在,则会发生错误 KeyError;
discard 移除集合中的指定元素,如果元素不存在也不会报错。
9.2.3 difference()、differece_update()等
>>> x = {"apple", "banana", "cherry"}
>>> y = {"google", "microsoft", "apple"}
>>> x.difference(y)
{'cherry', 'banana'} # 返回值 x - y
>>> x.intersection(y)
{'apple'} # 返回值 x & y
>>> x.symmetric_difference(y)
{'microsoft', 'google', 'cherry', 'banana'} # 返回值 x ^ y
>>> x.union(y) # 返回值 a | b
{'microsoft', 'google', 'cherry', 'banana', 'apple'}>>> x.difference_update(y) # 没有返回值
>>> x
{'banana', 'cherry'}
>>> x.add('apple')
>>> x.intersection_update(y) # 没有返回值
>>> x
{'apple'}
>>> x.add({'banana', 'cherry'})
>>> x.symmetric_difference_update(y) # 没有返回值
>>> x
{'microsoft', 'google', 'cherry', 'banana'}
>>> x.update({apple}) # 没有返回值
>>> x
{'microsoft', 'google', 'cherry', 'banana', 'apple'}
9.2.4 isdisjoint()
描述:
isdisjoint() 方法用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。即两者是否有交集。
9.2.5 issubset()、issuperset()
issubset() 方法用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。即:A ⊆ B。
issuperset() 方法用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。即:A ⊇ B。
========== 更新日期 2023年8月27日 ==========
相关文章:

菜鸟教程《Python 3 教程》笔记
菜鸟教程《Python 3 教程》笔记 0 写在前面1 基本数据类型1.1 Number(数字)1.2 String(字符串)1.3 bool(布尔类型)1.4 List(列表)1.5 Tuple(元组)1.6 Set&…...

JAVA学习-愚见
JAVA学习-愚见 分享一下Java的学习路线,仅供参考【本人亲测,真实有效】 1、尽可能推荐较新的课程 2、大部分视频在B站上直接搜关键词就行【自学,B大的学生】 文章目录 JAVA学习-愚见前期准备Java基础课程练手项目 数据库JavaWeb前端基础 Vue…...

Watch数据监听详解
一、Vue2写法 1、watch使用的几种方法 1、通过 watch 监听 data 数据的变化,数据发生变化时,就会打印当前的值 watch: {data(val, value) {console.log(val)console.log(value)}} 2、通过 watch 监听 list 数据的变化,数据发生变化时&…...
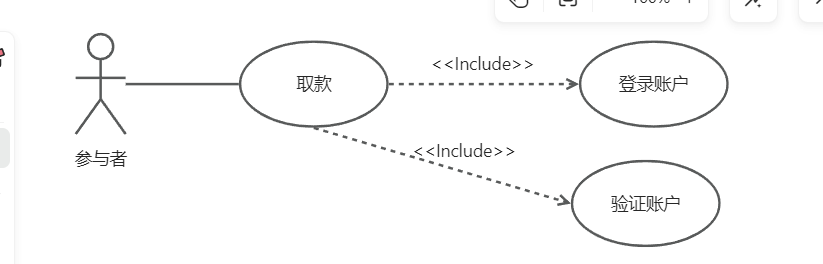
UML建模以及几种类图的理解
文章目录 前言1.用例与用例图1.1 参与者1.2 用例之间的关系1.3 用例图1.4 用例的描述 2.交互图2.1 顺序图2.2 协作图 3.类图和对象图3.1 关联关系3.2 聚合和组合3.3 泛化关系3.4 依赖关系 4.状态图与活动图4.1 状态图4.2 活动图 5.构件图 前言 UML通过图形化的表示机制从多个侧…...
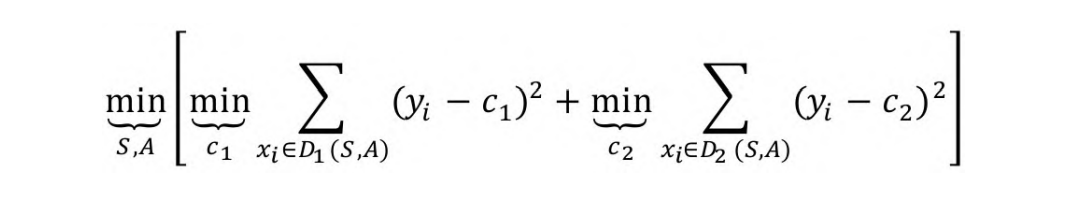
opencv进阶18-基于opencv 决策树导论
1. 什么是决策树? 决策树是最早的机器学习算法之一,起源于对人类某些决策过程 的模仿,属于监督学习算法。 决策树的优点是易于理解,有些决策树既可以做分类,也可以做回归。在排名前十的数据挖掘算法中有两种是决策树[1…...

13.4 目标检测锚框标注 非极大值抑制
锚框的形状计算公式 假设原图的高为H,宽为W 锚框形状详细公式推导 以每个像素为中心生成不同形状的锚框 # s是缩放比,ratio是宽高比 def multibox_prior(data, sizes, ratios):"""生成以每个像素为中心具有不同形状的锚框"""in_he…...
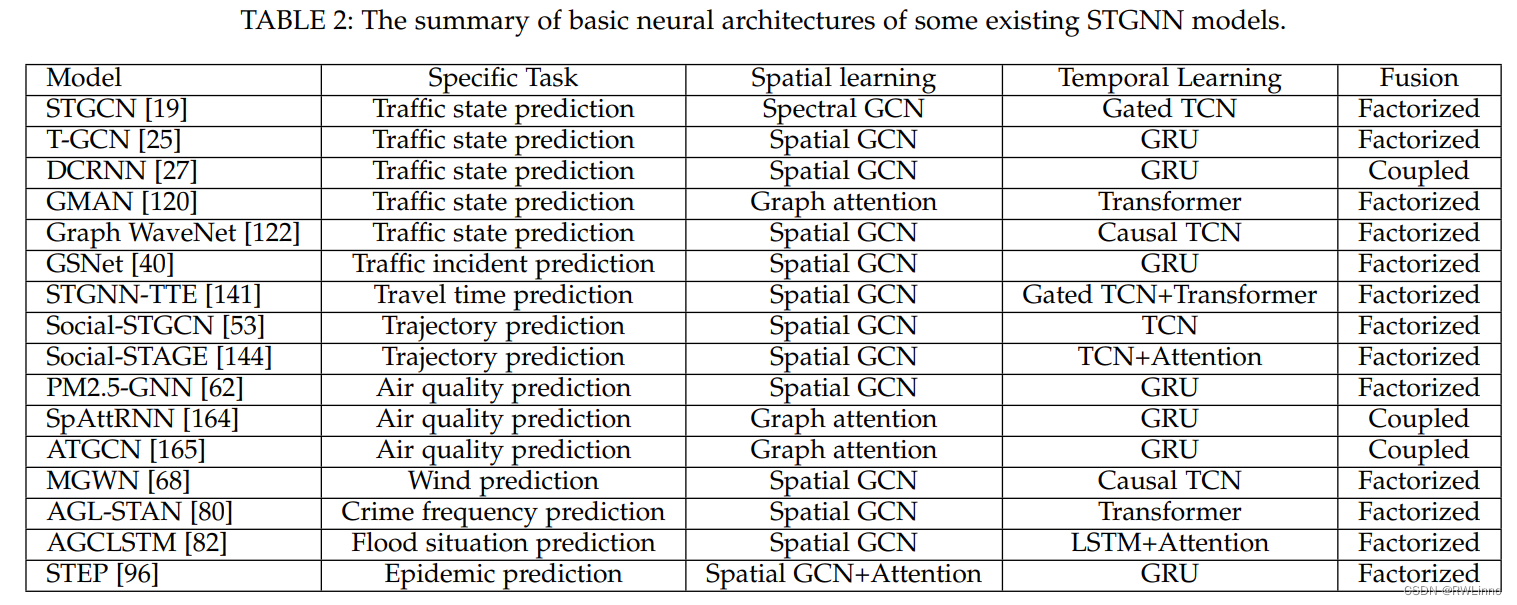
【论文笔记】最近看的时空数据挖掘综述整理8.27
Deep Learning for Spatio-Temporal Data Mining: A Survey 被引用次数:392 [Submitted on 11 Jun 2019 (v1), last revised 24 Jun 2019 (this version, v2)] 主要内容: 该论文是一篇关于深度学习在时空数据挖掘中的应用的综述。论文首先介绍了时空数…...

【大模型】基于 LlaMA2 的高 star 的 GitHub 开源项目汇总
【大模型】基于 LlaMA2 的高 star 的 GitHub 开源项目汇总 Llama2 简介开源项目汇总NO1. FlagAlpha/Llama2-ChineseNO2. hiyouga/LLaMA-Efficient-TuningNO3. yangjianxin1/FireflyNO4. LinkSoul-AI/Chinese-Llama-2-7bNO5. wenge-research/YaYiNO6. michael-wzhu/Chinese-LlaM…...
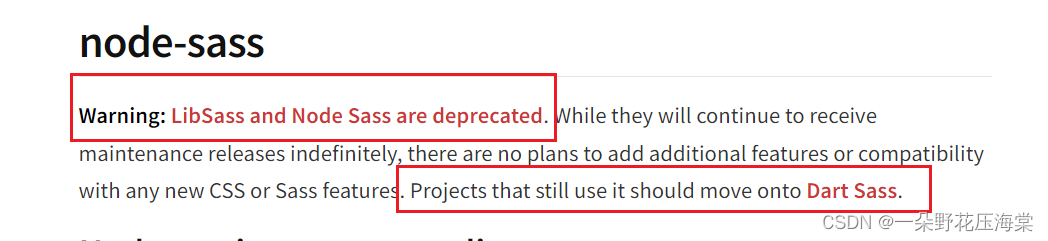
解决elementUI打包上线后icon图标偶尔乱码的问题
解决vue-elementUI打包后icon图标偶尔乱码的问题 一、背景二、现象三、原因四、处理方法方式1:使用css-unicode-loader方式2:升高 sass版本到1.39.0方式3:替换element-ui的样式文件方式4:更换打包压缩方式知识扩展:方式…...

yolov3加上迁移学习和适度的数据增强形成的网络应用在输电线异物检测
Neural Detection of Foreign Objects for Transmission Lines in Power Systems Abstract. 输电线路为电能从一个地方输送到另一个地方提供了一条路径,确保输电线路的正常运行是向城市和企业供电的先决条件。主要威胁来自外来物,可能导致电力传输中断。…...

香橙派OrangePi zero H2+ 驱动移远EC200A
1 系统内核: Linux orangepizero 5.4.65-sunxi #2.2.2 SMP Tue Aug 15 17:45:28 CST 2023 armv7l armv7l armv7l GNU/Linux 1.1 下载内核头安装 下载:orangepi800 内核头rk3399链接https://download.csdn.net/download/weixin_37613240/87635781 1.1.1…...
)
写一个java中如何用JSch来连接sftp的类并做测试?(亲测)
当使用JSch连接SFTP服务器的类,并进行测试时,可以按照以下步骤操作: 添加JSch库的依赖项。在你的项目中添加JSch库的Maven依赖项(如前面所述)或下载JAR文件并将其包含在项目中。 <dependency> <groupId&…...

【沐风老师】如何在3dMax中将3D物体转化为样条线构成的对象?
在3dMax中如何把三维物体转化为由样条线构成的对象?通常这样的场景会出现在科研绘图或一些艺术创作当中,下面给大家详细讲解一种3dmax三维物体转样条线的方法。 第一部分:用粒子填充3D对象: 1.创建一个三维对象(本例…...

2023国赛数学建模思路 - 案例:随机森林
文章目录 1 什么是随机森林?2 随机深林构造流程3 随机森林的优缺点3.1 优点3.2 缺点 4 随机深林算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是随机森林ÿ…...
wxpython:wx.html2 是好用的 WebView 组件
wxpython : wx.html2 是好用的 WebView 组件。 pip install wxpython4.2 wxPython-4.2.0-cp37-cp37m-win_amd64.whl (18.0 MB) Successfully installed wxpython-4.2.0 cd \Python37\Scripts wxdemo.exe 取得 wxPython-demo-4.2.0.tar.gz wxdocs.exe 取得 wxPython-docs-4.…...
《QT+PCL 第五章》点云特征-PFH
QT增加点云特征PFH 代码用法代码 #include <pcl/io/pcd_io.h> #include <pcl/features/normal_3d.h> #include <pcl/features/pfh.h>int main...
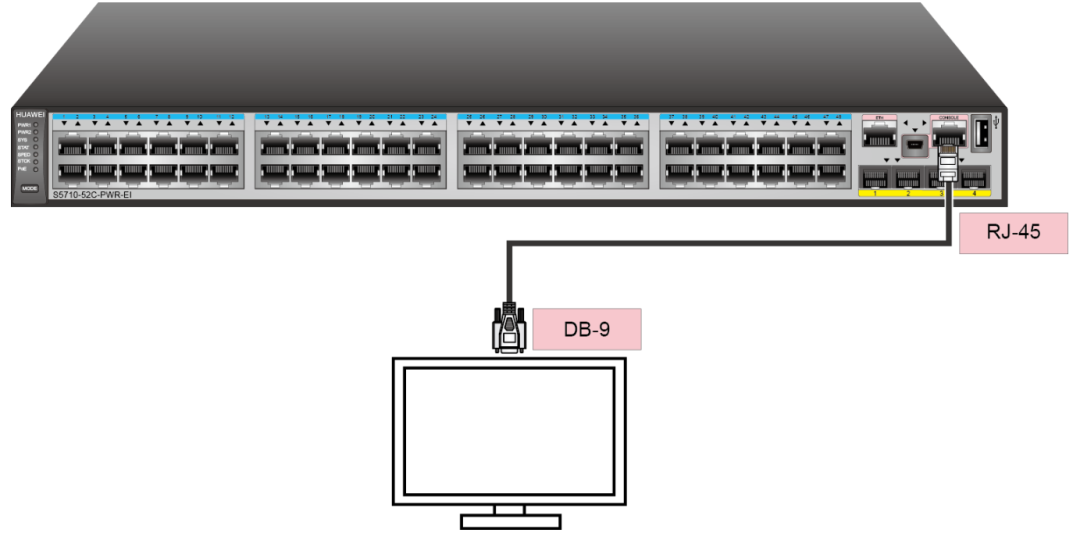
【分享】小型园区组网场景
小型园区组网图 在小型园区中,S2700&S3700通常部署在网络的接入层,S5700&S6700通常部署在网络的核心,出口路由器一般选用AR系列路由器。 接入交换机与核心交换机通过Eth-Trunk组网保证可靠性。 每个部门业务划分到一个VLAN中&#…...
LeetCode 1267. 统计参与通信的服务器
【LetMeFly】1267.统计参与通信的服务器 力扣题目链接:https://leetcode.cn/problems/count-servers-that-communicate/ 这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表…...
)
169. 多数元素(哈希表)
169. 多数元素 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 class Solution { public:int majorityElement(vector<int&…...
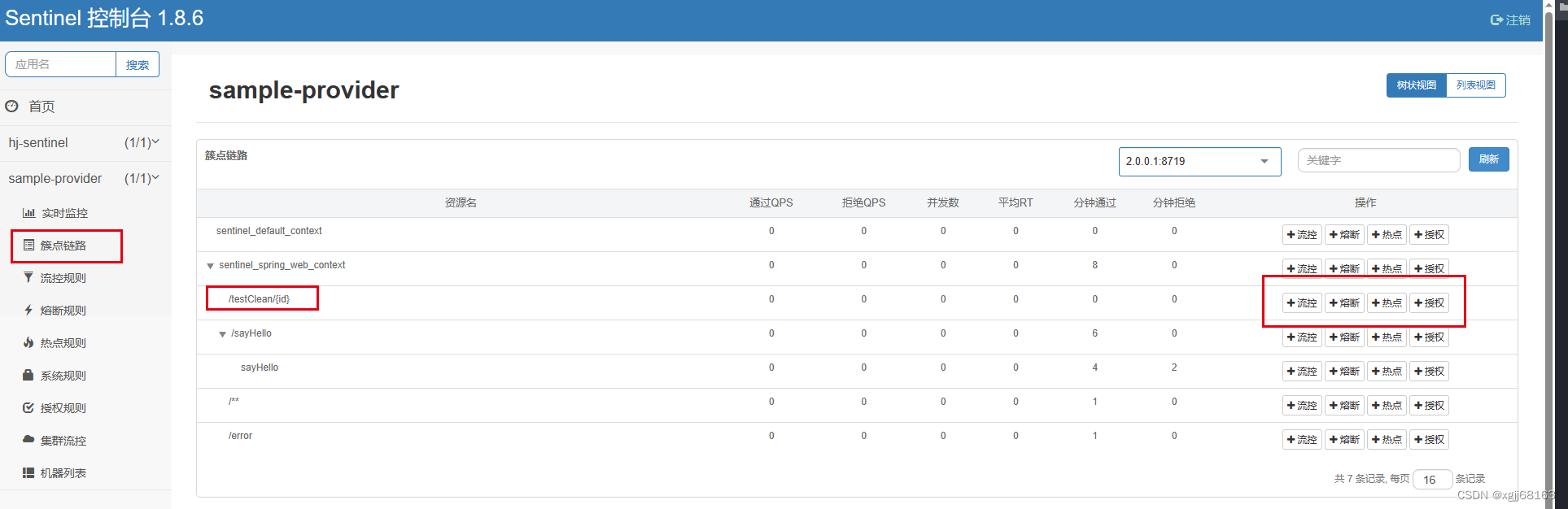
微服务集成spring cloud sentinel
目录 1. sentinel使用场景 2. sentinel组成 3. sentinel dashboard搭建 4. sentinel客户端详细使用 4.1 引入依赖 4.2 application.properties增加dashboard注册地址 4.3 手动增加限流配置类 4.4 rest接口及service类 4.5 通过dashboard动态配置限流规则 1. sentinel使…...

Vue-Tree-List 实战指南:构建现代化树形结构的终极方案
Vue-Tree-List 实战指南:构建现代化树形结构的终极方案 【免费下载链接】vue-tree-list 🌲A vue component for tree structure 项目地址: https://gitcode.com/gh_mirrors/vu/vue-tree-list 在现代前端开发中,树形结构是处理层级数据…...
用C++实现信奥题 P8976 「DTOI-4」排列)
打卡信奥刷题(3292)用C++实现信奥题 P8976 「DTOI-4」排列
P8976 「DTOI-4」排列 题目背景 Update on 2023.2.1:新增一组针对 yuanjiabao 的 Hack 数据,放置于 #21。 Update on 2023.2.2:新增一组针对 CourtesyWei 和 bizhidaojiaosha 的 Hack 数据,放置于 #22。 构造一个排列 ppp&…...
亲测好用的AI写作辅助平台,毕业生收藏备用)
(良心整理)亲测好用的AI写作辅助平台,毕业生收藏备用
毕业季论文写作真的这么难吗?选题方向模糊、文献资料繁杂、写作进度缓慢、查重修改头疼、格式规范混乱…… 这份亲测好用的AI论文工具清单,涵盖中英文写作、全流程支持、专项功能、免费与高性价比选项,从开题构思到最终定稿全程护航ÿ…...

Monk AI小样本分类实战:用几十张图快速构建可用AI模型
1. 项目概述:用 Monk AI 做分类,但只喂它一小块数据——这到底在解决什么问题?“Classification Using Monk AI by Using a Slice of the Dataset”这个标题乍看平平无奇,甚至有点拗口,但如果你在工业质检、医疗影像初…...

python旅游分享点评网系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈扩展功能建议项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python旅游分…...

MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案
MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 在Minecraft模组生态系统中,MASA系列模组以其强大的…...

从 2.5 亿到 30 亿!2026AI搜索行业爆发,API接口+优质资源双驱动,GEO媒介资源平台选型指南
2026年,生成式引擎优化(GEO)行业已迈入关键发展期,API接口规模化落地与优质资源竞争成为行业核心焦点。当前,AI搜索流量占比已突破52%,企业对GEO服务商的需求不再局限于简单的内容优化,而是升级…...

Temu 运营进阶之路 工具选型与凌风体系分析
TEMU商家体量持续扩张,平台规则与收费体系愈发复杂,纯人工运营耗时费力,核算误差、合规疏漏问题频发。市面上运营工具繁杂,商家难以甄别适配工具。本文以行业实操角度,客观拆解凌风工具箱的适配能力与实用价值…...

NotebookLM显著性判断失效真相:92%用户忽略的3个统计学前提及实时校验脚本
更多请点击: https://codechina.net 第一章:NotebookLM显著性判断失效的典型现象与影响评估 NotebookLM 在处理多源异构文档时,其内置的“显著性判断”模块(Significance Scorer)常因语义稀疏、上下文截断或引用锚点偏…...

AspectCore-Framework高级特性:参数拦截、异步切面、作用域管理
AspectCore-Framework高级特性:参数拦截、异步切面、作用域管理 【免费下载链接】AspectCore-Framework AspectCore is an AOP-based cross platform framework for .NET Standard. 项目地址: https://gitcode.com/gh_mirrors/as/AspectCore-Framework Aspec…...