【LLM】解析pdf文档生成摘要
文章目录
- 一、整体思路
- 二、代码
- 三、小结
- Reference
一、整体思路
- 非常简单的一个v1版本
- 利用langchain和pdfminer切分pdf文档为k块,设置overlap等参数
- 先利用prompt1对每个chunk文本块进行摘要生成,然后利用prompt2对多个摘要进行连贯组合/增删
- 模型可以使用chatglm2-6b或其他大模型
- 评测标准:信息是否涵盖pdf主要主题、分点和pdf一二级标题比大体是否一致、摘要是否连贯、通顺
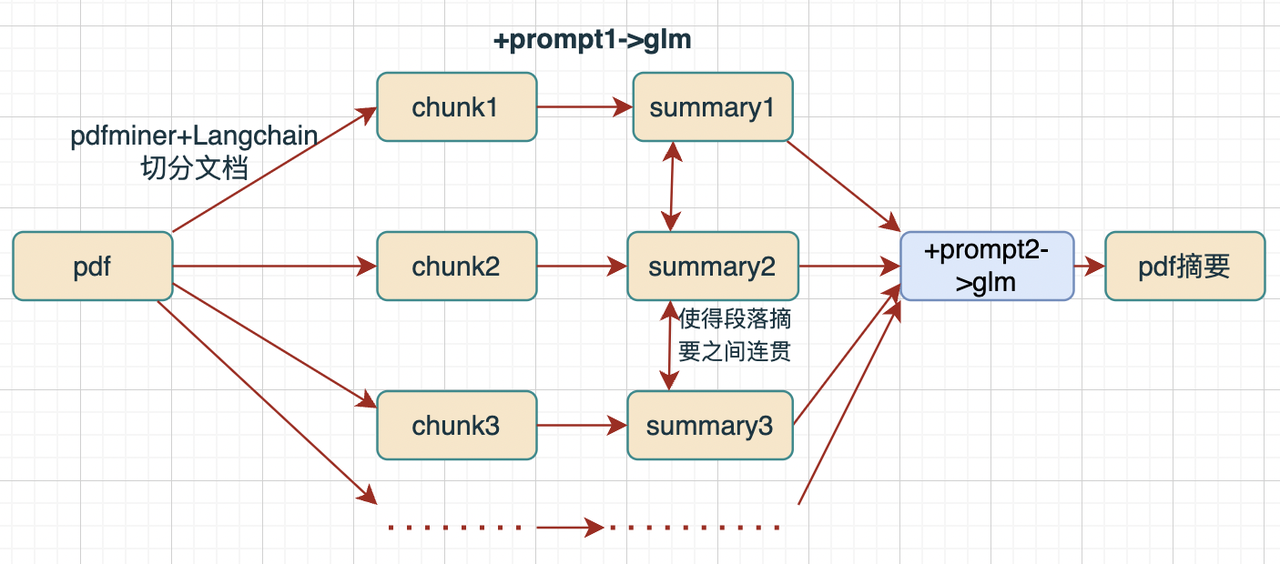
Prompt1:分段总结
prompt1 = '''你是一个摘要生成器。请根据下文进行分段总结,请注意:1.输入数据为从pdf读入的文本,一句话可能存在跨越多行;2.要求每段内容不丢失主要信息, 每段的字数在50字左右;3.每段生成的摘要开头一定不要含有'第几段'的前缀文字;4.对下文进行分段总结:'''
Prompt2:内容整合
prompt2 = '''你是一个文章内容整合器,请注意:1.输入数据中含有多个已经总结好的段落;2.有的段落开头有这是第几段或者摘要的字样;2.请将每段信息进行优化,使得每段之间显得更加连贯,且保留每段的大部分信息;4.输入的的文章如下:'''
二、代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Author : andy
@Date : 2023/8/23 10:09
@Contact: 864934027@qq.com
@File : chunk_summary.py
"""
import json
from langchain.text_splitter import CharacterTextSplitter
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBoxHorizontal
from pdfminer.pdfpage import PDFPage
import os
import pandas as pddef split_document_by_page(pdf_path):resource_manager = PDFResourceManager()codec = 'utf-8'laparams = LAParams()device = PDFPageAggregator(resource_manager, laparams=laparams)interpreter = PDFPageInterpreter(resource_manager, device)split_pages = []with open(pdf_path, 'rb') as file:for page in PDFPage.get_pages(file):interpreter.process_page(page)layout = device.get_result()text_blocks = []for element in layout:if isinstance(element, LTTextBoxHorizontal):text = element.get_text().strip()text_blocks.append(text)page_text = '\n'.join(text_blocks)split_pages.append(page_text)return split_pagesdef callChatGLM6B(prompt):passdef summary(pdf_path, num):# 使用示例# pdf_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/pdf_test.pdf"# pdf_path = 'example.pdf' # 替换为你的 PDF 文件路径one_dict = {}pages = split_document_by_page(pdf_path)add_page_data = ''page_ans = ""print(f"=============这是第{num}个pdf\n")for i, page_text in enumerate(pages):# page_ans = page_ans + f"这是第{i}页pdf:\n" + page_textpage_ans = page_ans + page_textprint(f"Page {i + 1}:", "当前page的字数:", len(page_text))print(page_text)print("--------------------")# 文本分片text_splitter = CharacterTextSplitter(separator="\n",chunk_size=1500,chunk_overlap=150,length_function=len)chunks = text_splitter.split_text(page_ans)# chunksprompt0 = '''请根据下文进行分段总结, 要求每段内容不丢失主要信息, 每段的字数在50字左右:'''prompt = '''你是一个摘要生成器。请根据下文进行分段总结,请注意:1.输入数据为从pdf读入的文本,一句话可能存在跨越多行;2.要求每段内容不丢失主要信息, 每段的字数在50字左右;3.每段生成的摘要开头一定不要含有'第几段'的前缀文字;4.对下文进行分段总结:'''prompt3 = '''你是一个文章内容整合器,请注意:1.输入数据中含有多个已经总结好的段落;2.有的段落开头有这是第几段或者摘要的字样;2.请将每段信息进行优化,使得每段之间显得更加连贯,且保留每段的大部分信息;4.输入的的文章如下:'''ans = ""for i in range(len(chunks)):# response = callChatGLM66B(prompt + chunks[i])response = callChatGLM6B(prompt + chunks[i])if 'data' not in response.keys():print(response.keys(), "\n")print("========this chunk has problem=======\n")continuetemp_ans = response['data']['choices'][0]['content'] + "\n"ans += temp_ansans = ans.replace("\\n", '\n')# save txt# save_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/save_6b_ans3_all"save_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/gpt_diction"with open(save_path + '/ans' + str(num) + '.txt', 'w', encoding='utf-8') as file:file.write(ans)print("======ans========:\n", ans)one_dict = {'input': page_ans, "output": ans}return ans, one_dictdef main():# find 10 filedef find_files_with_prefix(folder_path, prefix):matching_files = []for root, dirs, files in os.walk(folder_path):for file in files:if file.startswith(prefix) and file.endswith('.pdf'):matching_files.append(os.path.join(root, file))return matching_files# 示例用法folder_path = '/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/pdf_data_all' # 替换为你的大文件夹路径# prefixes = ['pdf_0', 'pdf_1', 'pdf_2'] # 替换为你想要匹配的前缀列表prefixes = []for i in range(10):prefixes.append('pdf_' + str(i))matching_files = []for prefix in prefixes:matching_files.extend(find_files_with_prefix(folder_path, prefix))# del matching_files[0]# del matching_files[0]ans_lst = []for i in range(len(matching_files)):one_ans, one_dict = summary(matching_files[i], i)ans_lst.append(one_dict)# pdf_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/pdf_test.pdf"# summary(pdf_path)return ans_lstdef preprocess_data(ans_lst):json_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/summary_ft_data.json"with open(json_path, "w", encoding='utf-8') as fout:for dct in ans_lst:line = json.dumps(dct, ensure_ascii=False)fout.write(line)fout.write("\n")def read_data():json_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/summary_ft_data.json"with open(json_path, "r", encodings='utf-8') as f:lst = [json.loads(line) for line in f]df = pd.json_normalize(lst)if __name__ == '__main__':ans_lst = main()preprocess_data(ans_lst)
随便找了个介绍某个课程内容的pdf,结果如下,概括了课程的三天主题内容,同时也将pdf中的数据湖理念等概念进行分点概括:
" 教育即将推出名为“数据湖,大数据的下一场变革!”的超强干货课程。该课程分为三天,第一天的主题是“数据湖如何助力企业大数据中台架构的升级”,内容包括数据处理流程和大数据平台架构,以及数据湖和数据仓库的理念对比和应用;第二天的主题是“基于 Apache Hudi 构建企业级数据湖”,将介绍三个开源数据湖技术框架比较,Apache Hudi 的核心概念和功能,以及基于 Hudi 构建企业级数据湖的方法;第三天的主题是“基于 Apache Iceberg 打造新一代数据湖”,将深入探讨 Apache Iceberg 的核心思想、特性和实现细节,以及如何基于 Iceberg 构建数据湖分析系统。该课程由前凤凰金融大数据部门负责人王端阳主讲,他具有多年的大数据架构经验,擅长 Hadoop、Spark、Storm、Flink 等大数据生态技术,授课特点为拟物化编程 + 强案例支撑,旨在帮助学生快速建立完备的大数据生态知识体系。课程将在今晚 20:00 准时开课。""
1.开放性:Lakehouse 使用开放式和标准化的存储格式,提供 API 供各类工具和引擎直接访问数据。
2.数据类型支持:Lakehouse 支持从非结构化数据到结构化数据的多种数据类型。
3.BI 支持:Lakehouse 可直接在源数据上使用 BI 工具。
4.工作负载支持:Lakehouse 支持数据科学、机器学习以及 SQL 和分析等多种工作负载。
5.模式实施和治理:Lakehouse 有 Schema enforcement and governance 功能,未来能更好的管理元数据,schema 管理和治理。
6.事务支持:Lakehouse 支持 ACID 事务,确保了多方并发读写数据时的一致性问题。
7.端到端流:Lakehouse 需要一个增量数据处理框架,例如 Apache Hudi。
8.数据湖和数据仓库对比:数据湖采用读时模式,满足上层业务的高效分析需求,且无成本修改 schema。
9.数据湖落地方案:包括基于 Hadoop 生态的大数据方案,基于云平台数据湖方案,基于商业产品的数据湖方案。
10.数据湖助力数仓解决痛点:数据湖可以解决离线数仓和实时数仓的痛点问题,提高数据处理效率。
11.数据湖帮助企业大数据中台升级:数据湖可以实现底层存储标准统一化,构建实时化标准层,提高数据存储的安全性、全面性和可回溯性。
12.大数据中台实时数据建设要求:开源数据湖架构 Day02 基于 Apache Hudi 构建企业级数据湖。"
三、小结
- 之前存在的问题:生成重复、杜撰了事件中的时间、截断现象、每个chunk文本块之间的摘要不太连贯等
- 优化点:使用pdfminer和Langchain切分chunk文本块,对文本块进行摘要生成,然后将分块的摘要结合prompt2进行内容整合,使得语句连贯并且控制字数;top_p=0.5 temperature=0.8等
- 后续可继续优化的点:使用streamlist提取pdf中的表格对象内容、使用篇章分析discourse parsing更加细粒度地切分文档等
Reference
[1] 基于LLM+向量库的文档对话痛点及解决方案
[2] LangChain - 打造自己的GPT(二)simple-chatpdf
[3] 徒手使用LangChain搭建一个ChatGPT PDF知识库
[4] LangChain+ChatGPT三分钟实现基于pdf等文档问答应用
[5] pdfminer: https://euske.github.io/pdfminer/
[6] Python+Streamlit在网页中提取PDF中文字、表格对象
相关文章:
【LLM】解析pdf文档生成摘要
文章目录 一、整体思路二、代码三、小结Reference 一、整体思路 非常简单的一个v1版本 利用langchain和pdfminer切分pdf文档为k块,设置overlap等参数先利用prompt1对每个chunk文本块进行摘要生成,然后利用prompt2对多个摘要进行连贯组合/增删模型可以使…...

方案:AI边缘计算智慧工地解决方案
一、方案背景 在工程项目管理中,工程施工现场涉及面广,多种元素交叉,状况较为复杂,如人员出入、机械运行、物料运输等。特别是传统的现场管理模式依赖于管理人员的现场巡查。当发现安全风险时,需要提前报告࿰…...

【Python】【数据结构和算法】查找最大或最小的N个元素
除了直接排序,还可以利用heaq模块的nlargest()和nsmallest()方法,例如: >>> nums [3, 5, 2, 4, 1] >>> smallest heapq.nsmallest(3, nums) >>> print(smallest) [1, 2, 3] >>> largest heapq.nlarg…...
C++day1(笔记整理)
一、Xmind整理: 二、上课笔记整理: 1.第一个c程序:hello world #include <iostream> //#:预处理标识符 //<iostream>:输入输出流类所在的头文件 //istream:输入流类 //ostream:输出流类using namespace std; //std&#x…...
关于chromedriver.exe一系列问题的解决办法
最新 chromedriver.exe下载地址:https://googlechromelabs.github.io/chrome-for-testing/#stable 下载最新版本的 chromedriver.exe 将其解压在 python.exe 同目录下,以及Chrome 的路径下 例如: C:\Program Files\Google\Chrome\Applicati…...

css-选择器、常见样式、标签分类
CSS CSS简介 层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。CSS不仅可以静态地修饰网页,还可…...

三星申请新商标:未来将应用于智能戒指,作为XR头显延伸设备
三星最近向英国知识产权局提交了名为“Samsung Curio”的新商标,这预示着三星正积极扩展可穿戴设备生态。该商标被分类为“Class 9”,这表明它有可能被用于未来的智能戒指。 据报道,三星计划将智能戒指作为XR头显设备的延伸,与苹果…...

0201hdfs集群部署-hadoop-大数据学习
文章目录 1 前言2 集群规划3 hadoop安装包上传与安装3.1 上传解压 4 hadoop配置5 从节点同步和环境变量配置6 创建用户7 集群启动8 问题集8.1 Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority. 结语 1 前言 下面我们配置下单namenode节点h…...

DevOps中的持续测试优势和工具
持续测试 DevOps中的持续测试是一种软件测试类型,它涉及在软件开发生命周期的每个阶段测试软件。持续测试的目标是通过早期测试和经常测试来评估持续交付过程的每一步的软件质量。 DevOps中的持续测试流程涉及开发人员、DevOps、QA和操作系统等利益相关者。 持续…...
)
函数-C语言(初阶)
目录 一、什么是函数 二、函数的分类 2.1 库函数 2.2 自定义函数 三、函数的参数 3.1 实际参数(实参) 3.2 形式参数(形参) 四、函数的调用 4.1 传值调用 4.2 传址调用 五、函数的嵌套调用和链式访问 5.1 嵌套调用 5.2 链式访问…...

elementuiplus设置scroll-to-error之后 提示被遮挡的解决方案
项目场景: 普通的头部固定,中间滑动的布局,中间内容有表单,提交校验不通过时滚动到第一个错误项 问题描述 elementuiplus的scroll-to-error设置之后是局部滚动 当头部内容层级高于中间表单的时候,错误会被遮挡。 ---…...

vue中将新添加的div标签自动定位到可视区域内
可以结合使用Vue的ref和scrollIntoView()方法来实现 <template><div><button click"addDiv">添加新的<div>标签</button><div ref"container" class"container"><div v-for"(item,inde…...
)
Vue3笔记——(尚硅谷张天禹Vue笔记)
Vue3 Vue3简介 1.Vue3简介 .2020年9月18日,Vue.js发布3.0版本,代号: One Piece(海贼王)。耗时2年多、2600次提交、30个RFC、600次PR、99位贡献者 . github上的tags地址: https://github.com/vuejs/vue-next/releases/tag/v3.0.0 2.Vue3带来了什么 .性能…...
正则表达式一小时学完
闯关式学习Regex 正则表达式,我感觉挺不错的,记录一下。 遇到不会的题,可以评论交流。 真的很不错 链接 Regex Learn - Step by step, from zero to advanced....
上门服务系统|上门服务小程序如何提升生活质量?
上门服务其实就是本地生活服务的升级,上门服务包含很多行业可以做的。例如:厨师上门、上门家电维修、跑腿等等。如今各类本地化生活服务越来越受大家的喜爱。基于此市场愿景,我们来谈谈上门服务系统功能。 一、上门服务系统功能 1、预约服务…...

系统报错msvcp120.dll丢失的解决方法,常见的三种解决方法
今天为大家讲述关于系统报错msvcp120.dll丢失的解决方法。在这个信息爆炸的时代,我们每个人都可能遇到各种各样的问题,而这些问题往往需要我们去探索、去解决。今天,我将带领大家走进这个神秘的世界,一起寻找解决msvcp120.dll丢失…...

数据库备份工具有哪些
本文主要介绍下数据库备份工具。 数据库备份工具有很多种,以下是一些常见的数据库备份工具: mysqldump:MySQL官方提供的命令行备份工具,适用于MySQL和MariaDB数据库。它可以将数据库导出为SQL文件,方便进行备份和恢复…...

Sentinel流量控制与熔断降级
📝 学技术、更要掌握学习的方法,一起学习,让进步发生 👩🏻 作者:一只IT攻城狮 ,关注我,不迷路 。 💐学习建议:1、养成习惯,学习java的任何一个技术…...

The Connector 周刊#10:你真的知道什么是DevOps文化吗?
AI 探索 用 LLM 构建企业专属的用户助手:很好的 LLM 应用工程实践,主要介绍了 PingCAP 如何使用大型语言模型(Large Language Model,LLM)构建一个搭载企业专属知识库的智能客服机器人。除了采用行业内通行的基于知识库…...

leetcode438. 找到字符串中所有字母异位词(java)
滑动窗口 找到字符串中所有字母异位词滑动窗口数组优化 上期经典 找到字符串中所有字母异位词 难度 - 中等 Leetcode 438 - 找到字符串中所有字母异位词 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出…...

PyTorch Vision模型微调终极指南:从零到精通的迁移学习实战
PyTorch Vision模型微调终极指南:从零到精通的迁移学习实战 【免费下载链接】vision pytorch/vision: 一个基于 PyTorch 的计算机视觉库,提供了各种计算机视觉算法和工具,适合用于实现计算机视觉应用程序。 项目地址: https://gitcode.com/…...
)
保姆级教程:从零配置ROS2自定义消息包(含CMake/ament避坑指南)
从零构建ROS2自定义消息包的终极实践指南 在机器人开发领域,ROS2的消息系统是模块间通信的核心枢纽。当标准消息类型无法满足特定需求时,自定义消息包便成为开发者必须掌握的技能。本文将带您从零开始,逐步构建一个完整的ROS2自定义消息包&am…...

小白必看!收藏这份Agent思维链技术指南,轻松入门大模型世界
小白必看!收藏这份Agent思维链技术指南,轻松入门大模型世界 本文深入解析了Agent模型中的思维链技术,介绍了不同模型如Claude、Gemini等对思维链的不同称谓及其核心原理,即通过将思考内容带入上下文来提升多轮推理性能。文章对比了…...

ssm+java2026年毕设私教预约系统【源码+论文】
本系统(程序源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容一、选题背景关于会议管理问题的研究,现有研究主要以传统纸质登记和简单的OA系统为主,专门针对智能化、全流程会议预…...

TestDisk与PhotoRec:专业数据恢复的强力解决方案
TestDisk与PhotoRec:专业数据恢复的强力解决方案 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 当分区表损坏、文件系统崩溃或重要数据意外删除时,专业的数据恢复工具是唯一的救命稻…...

设计师必看:Photoshop混合模式实战指南,5分钟搞定光影合成与氛围感调色
Photoshop混合模式实战指南:5分钟掌握光影合成与氛围调色 当你在深夜赶稿时,突然发现人物照片缺乏立体感,或是产品静物图需要增强戏剧性光影——这就是混合模式大显身手的时刻。不同于繁琐的曲线调整和复杂的蒙版操作,混合模式就像…...

【单片机】内核中断及NVICPending
红色框住的是M3内核中断,青色框住的默认打开,不可关闭中断(除NMI外可屏蔽)。包括SysTick在内无需NVIC_EnableIRQ,也无需在中断处理函数里清标志位。NVIC_SetPendingIRQ和NVIC_ClearPendingIRQ基本用不到,任…...
)
Win32下用libigl+GLFW3渲染3D模型的完整配置指南(附常见错误排查)
Win32下用libiglGLFW3渲染3D模型的完整配置指南(附常见错误排查) 在Windows平台进行3D图形开发时,libigl与GLFW3的组合为开发者提供了强大的工具集。libigl作为一个轻量级的C几何处理库,与GLFW3这一跨平台的OpenGL窗口管理库结合…...

云容笔谈开源镜像优势:免编译、免依赖、BF16原生支持,开箱即生成
云容笔谈开源镜像优势:免编译、免依赖、BF16原生支持,开箱即生成 最近在尝试各种AI图像生成工具时,我发现了一个很有意思的现象:很多工具要么安装配置复杂,要么生成效果不尽如人意,特别是想要生成具有东方…...

OpenClaw硬件监控:nanobot定时报告系统资源使用情况
OpenClaw硬件监控:nanobot定时报告系统资源使用情况 1. 为什么需要自动化硬件监控 去年夏天,我的开发机因为内存泄漏问题突然宕机,导致一个重要的线上演示被迫推迟。当时我就意识到,手动检查系统资源的方式既不及时也不可靠。直…...