0201hdfs集群部署-hadoop-大数据学习
文章目录
- 1 前言
- 2 集群规划
- 3 hadoop安装包上传与安装
- 3.1 上传解压
- 4 hadoop配置
- 5 从节点同步和环境变量配置
- 6 创建用户
- 7 集群启动
- 8 问题集
- 8.1 Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority.
- 结语
1 前言
下面我们配置下单namenode节点hadoop集群,使用vmware虚拟机环境搭建。vmware虚拟机的配置,在下面链接2有,或者自行查阅文档。hadoop安装包可到官网下载,当前相关软件环境如下:
| 软件 | 版本 | 说明 |
|---|---|---|
| hadoop | 3.3.4 | jar包 |
| vmware | 15.5 | 虚拟机 |
| centos | 7.6 | 服务器操作系统 |
| xshell | 6 | 远程连接 |
| jdk | 1.8 | java运行环境 |
2 集群规划
在前面的准备章节,我们准备了基于vmware的三台虚拟机,现服务规划如下:
| 节点 | 服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
Hadoop HDFS的角色包含:
- NameNode:主节点管理者
- DataNode:从节点工作者
- SecondaryNameNode:主节点辅助
3 hadoop安装包上传与安装
3.1 上传解压
- 上传hadoop安装包到node节点中,如下图3.1-1所示

-
解压缩安装包到
/export/server中tar -zxvf hadoop-3.3.4.tar.gz -C /export/server -
构建软连接
cd /export/server ln -s /export/server/hadoop-3.3.4 hadoop
4 hadoop配置
配置HDFS集群,主要涉及以下文件的修改:
- workers:配置从节点(DataNode)有哪些
- hadoop-env.sh:配置hadoop的相关变量
- core-site.xml:hadoop的核心配置文件
- hadfs-site.xml:HDFS核心配置文件
这些文件在$HADOOP_HOME/etc/hadoop文件夹中
ps:$HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/export/server/hadoop
-
配置workers
# 进入配置文件目录 cd etc/hadoop # 编辑workers文件 vim workers # 填入如下内容 node1 node2 node3- 记录node1,node2,node3三个从节点
-
配置hadoop-en.sh
# 填入如下内容 export JAVA_HOME=/export/server/jdk export HADOOP_HOME=/export/server/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR=$HADOOP_HOME/logs- JAVA_HOME:jdk安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop配置文件目录
- HADOOP_LOG_DIR:hadoop日志存放目录
-
配置
core-site.xml,此处配置NameNode会报错,后面问题集我们在分析在文件内部填入如下内容 <configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property> </configuration>- key:fs.defaultFS;含义:HDFS文件系统的网络通讯路径;值:hdfs://node1:8020
- 协议为hdfs://
- namenode为node1
- namenode通讯端口为8020
- key:io.file.buffer.size含义:io操作文件缓冲区大小值:131072 bit
- hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器此配置固定了node1必须启动NameNode进程
- key:fs.defaultFS;含义:HDFS文件系统的网络通讯路径;值:hdfs://node1:8020
-
配置hdfs-site.xml
# 在文件内部填入如下内容 <configuration><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property> </configuration>- key:dfs.datanode.data.dir.perm;含义:hdfs文件系统,默认创建的文件权限设置值:700,即:rwx------
- key:dfs.namenode.name.dir;含义:NameNode元数据的存储位置值:/data/nn,在node1节点的/data/nn目录下
- key:dfs.namenode.hosts含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)值:node1、node2、node3,这三台服务器被授权
- key:dfs.blocksize含义:hdfs默认块大小值:268435456(256MB)
- key:dfs.namenode.handler.count;含义:namenode处理的并发线程数;值:100,以100个并行度处理文件系统的管理任务
- key:dfs.datanode.data.dir;含义:从节点DataNode的数据存储目录;值:/data/dn,即数据存放在node1、node2、node3,三台机器的/data/dn内
根据上面配置的NameNode和DataNode数据存放位置
-
namenode数据存放node1的/data/nn
-
datanode数据存放node1、node2、node3的/data/dn
-
在node1节点:
mkdir -p /data/nn mkdir /data/dn -
在node2和node3节点:
mkdir -p /data/dn
5 从节点同步和环境变量配置
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3
-
分发
# 在node1执行如下命令 cd /export/server scp -r hadoop-3.3.4 node2:`pwd`/ scp -r hadoop-3.3.4 node3:`pwd`/ -
在node2执行,为hadoop配置软链接
# 在node2执行如下命令 ln -s /export/server/hadoop-3.3.4 /export/server/hadoop -
在node3执行,为hadoop配置软链接
# 在node3执行如下命令 ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
一步一步配置相对清晰,但是也繁琐,xshell有如下功能,可以在所有会话窗口执行相同的操作


配置环境变量:
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量
-
vim /etc/profile,node1,node2,node3执行相同操作
# 在/etc/profile文件底部追加如下内容 export HADOOP_HOME=/export/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6 创建用户
hadoop部署的准备工作基本完成为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务所以,现在需要对文件权限进行授权。
ps:请确保已经提前创建好了hadoop用户(前置准备章节中有讲述),并配置好了hadoop用户之间的免密登录以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
7 集群启动
前期准备全部完成,现在对整个文件系统执行初始化,在node1节点上操作
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
启动完成后,可以在浏览器打开:http://node1:9870,即可查看到hdfs文件系统的管理网页,如下图6-1所示

8 问题集
出了问题首先,查看日志,在配置文件$HADOOP_home/logs下面记录日志。
一些常见的报错,比如命令不存在,或者因为粗心单词写错,这里不再分析,可以去链接1视频P23-24查看原因或者自行查阅相关文档。下面主要分析一些本人遇到的非常见错误
8.1 Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority.
-
日志报错内容
2023-08-27 11:40:09,808 ERROR org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Failed to start secondary namenode java.lang.IllegalArgumentException: Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority.at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:781)at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddressCheckLogical(DFSUtilClient.java:810)at org.apache.hadoop.hdfs.DFSUtilClient.getNNAddress(DFSUtilClient.java:772)at org.apache.hadoop.hdfs.server.namenode.NameNode.getServiceAddress(NameNode.java:534)at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.initialize(SecondaryNameNode.java:231)at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.<init>(SecondaryNameNode.java:194)at org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode.main(SecondaryNameNode.java:690)-
报错NameNode URI配置有问题,这个配置我们是按照视频做了,配置如下
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property>
-
-
解决方案:修改配置如下
<property><name>fs.default.name</name><value>hdfs://node1:8020</value></property> -
具体原理可以查看官方文档解释或者下面链接3
结语
如果小伙伴什么问题或者指教,欢迎交流。
❓QQ:806797785
参考链接:
[1]大数据视频[CP/OL].2020-04-16.p14-p24.
[2]0101前期准备-大数据学习[CP/OL].
[3]Hadoop的core-site.xml配置文件里的fs.default.name和fs.defaultFS[CP/OL].
相关文章:
0201hdfs集群部署-hadoop-大数据学习
文章目录 1 前言2 集群规划3 hadoop安装包上传与安装3.1 上传解压 4 hadoop配置5 从节点同步和环境变量配置6 创建用户7 集群启动8 问题集8.1 Invalid URI for NameNode address (check fs.defaultFS): file:/// has no authority. 结语 1 前言 下面我们配置下单namenode节点h…...

DevOps中的持续测试优势和工具
持续测试 DevOps中的持续测试是一种软件测试类型,它涉及在软件开发生命周期的每个阶段测试软件。持续测试的目标是通过早期测试和经常测试来评估持续交付过程的每一步的软件质量。 DevOps中的持续测试流程涉及开发人员、DevOps、QA和操作系统等利益相关者。 持续…...
)
函数-C语言(初阶)
目录 一、什么是函数 二、函数的分类 2.1 库函数 2.2 自定义函数 三、函数的参数 3.1 实际参数(实参) 3.2 形式参数(形参) 四、函数的调用 4.1 传值调用 4.2 传址调用 五、函数的嵌套调用和链式访问 5.1 嵌套调用 5.2 链式访问…...

elementuiplus设置scroll-to-error之后 提示被遮挡的解决方案
项目场景: 普通的头部固定,中间滑动的布局,中间内容有表单,提交校验不通过时滚动到第一个错误项 问题描述 elementuiplus的scroll-to-error设置之后是局部滚动 当头部内容层级高于中间表单的时候,错误会被遮挡。 ---…...

vue中将新添加的div标签自动定位到可视区域内
可以结合使用Vue的ref和scrollIntoView()方法来实现 <template><div><button click"addDiv">添加新的<div>标签</button><div ref"container" class"container"><div v-for"(item,inde…...
)
Vue3笔记——(尚硅谷张天禹Vue笔记)
Vue3 Vue3简介 1.Vue3简介 .2020年9月18日,Vue.js发布3.0版本,代号: One Piece(海贼王)。耗时2年多、2600次提交、30个RFC、600次PR、99位贡献者 . github上的tags地址: https://github.com/vuejs/vue-next/releases/tag/v3.0.0 2.Vue3带来了什么 .性能…...
正则表达式一小时学完
闯关式学习Regex 正则表达式,我感觉挺不错的,记录一下。 遇到不会的题,可以评论交流。 真的很不错 链接 Regex Learn - Step by step, from zero to advanced....
上门服务系统|上门服务小程序如何提升生活质量?
上门服务其实就是本地生活服务的升级,上门服务包含很多行业可以做的。例如:厨师上门、上门家电维修、跑腿等等。如今各类本地化生活服务越来越受大家的喜爱。基于此市场愿景,我们来谈谈上门服务系统功能。 一、上门服务系统功能 1、预约服务…...

系统报错msvcp120.dll丢失的解决方法,常见的三种解决方法
今天为大家讲述关于系统报错msvcp120.dll丢失的解决方法。在这个信息爆炸的时代,我们每个人都可能遇到各种各样的问题,而这些问题往往需要我们去探索、去解决。今天,我将带领大家走进这个神秘的世界,一起寻找解决msvcp120.dll丢失…...

数据库备份工具有哪些
本文主要介绍下数据库备份工具。 数据库备份工具有很多种,以下是一些常见的数据库备份工具: mysqldump:MySQL官方提供的命令行备份工具,适用于MySQL和MariaDB数据库。它可以将数据库导出为SQL文件,方便进行备份和恢复…...

Sentinel流量控制与熔断降级
📝 学技术、更要掌握学习的方法,一起学习,让进步发生 👩🏻 作者:一只IT攻城狮 ,关注我,不迷路 。 💐学习建议:1、养成习惯,学习java的任何一个技术…...

The Connector 周刊#10:你真的知道什么是DevOps文化吗?
AI 探索 用 LLM 构建企业专属的用户助手:很好的 LLM 应用工程实践,主要介绍了 PingCAP 如何使用大型语言模型(Large Language Model,LLM)构建一个搭载企业专属知识库的智能客服机器人。除了采用行业内通行的基于知识库…...

leetcode438. 找到字符串中所有字母异位词(java)
滑动窗口 找到字符串中所有字母异位词滑动窗口数组优化 上期经典 找到字符串中所有字母异位词 难度 - 中等 Leetcode 438 - 找到字符串中所有字母异位词 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出…...
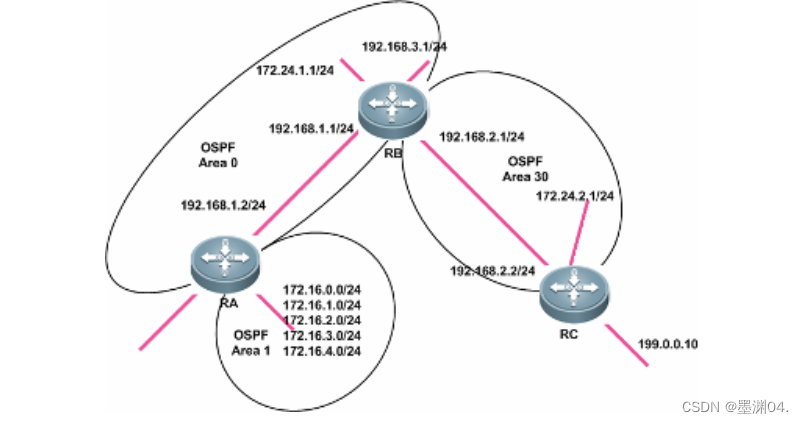
【锐捷】OSPF 多区域配置
【实验名称】 配置 OSPF 多区域。 【实验目的】 配置 OSPF 多区域,理解 OSPF 层次型网络的特点。 【背景描述】 本实验拓扑图中有 3 台路由器,路由器在区域 0 和区域 1 中,路由器 B 在区域 0 和区域 30, 路由器 C 在区域 30。 【需…...

Linux常用命令_权限管理命令
文章目录 1. 权限管理命令: chmod2. 其他权限管理命令2.1 权限管理命令: chown2.2 权限管理命令: chgrp2.3 权限管理命令: umask 1. 权限管理命令: chmod {ugoa}中分别为:u-user、g-group、a-all;谁创建文件,谁是所有者;所属组为所…...
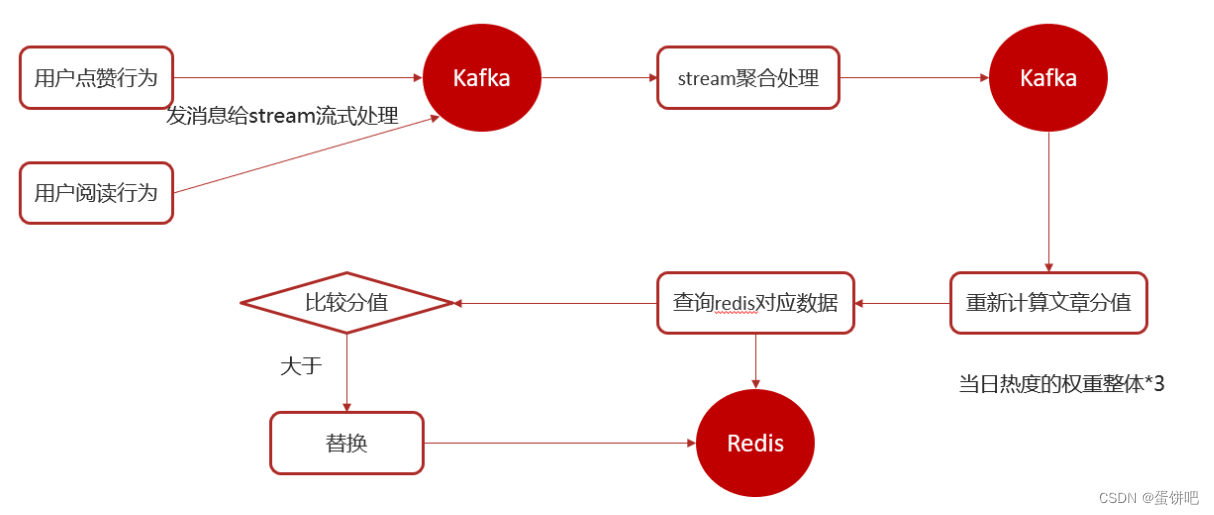
【黑马头条之热点文章kafkaStream】
本笔记内容为黑马头条项目的热点文章-实时计算部分 目录 一、实时流式计算 1、概念 2、应用场景 3、技术方案选型 二、Kafka Stream 1、概述 2、Kafka Streams的关键概念 3、KStream 4、Kafka Stream入门案例编写 5、SpringBoot集成Kafka Stream 三、app端热点文章…...

【SpringSecurity】三、访问授权
文章目录 1、配置用户权限2、针对URL授权3、针对方法的授权 1、配置用户权限 继续上一章,给在内存中创建两个用户配置权限。配置权限有两种方式: 配置roles配置authorities //哪个写在后面哪个起作用 //角色变成权限后会加一个ROLE_前缀,比…...

你对SPA单页面的理解,它的优缺点分别是什么?如何实现SPA应用呢?
一、什么是SPA SPA(single-page application),翻译过来就是单页应用SPA是一种网络应用程序或网站的模型,它通过动态重写当前页面来与用户交互,这种方法避免了页面之间切换打断用户体验在单页应用中,所有必…...

【LeetCode75】第三十七题 二叉树中的最长交错路径
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 给我们一棵二叉树,问我们在这棵树里能找到的最长交错路径。最长交错路径就是在二叉树里一左一右一左一右这样走,最…...

百度Apollo学习心得:探索自动驾驶技术的前沿之旅
文章目录 前言一、理论学习与实践结合二、多方资源的整合利用三、团队合作与交流分享四、持续学习与创新思维总结 前言 百度Apollo是一项引领自动驾驶技术发展的开放平台,通过深度学习、感知与决策、定位与控制等关键技术,为开发者提供了丰富的工具和资…...

3步快速掌握罗技鼠标宏:PUBG压枪新手完全指南
3步快速掌握罗技鼠标宏:PUBG压枪新手完全指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中难以控制的武器后…...

Dism++:Windows系统维护的终极免费工具,一键解决卡顿和更新问题
Dism:Windows系统维护的终极免费工具,一键解决卡顿和更新问题 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language 你是否曾为Windows系统运行…...

苏州晟雅泰电子:关于长鑫存储与兆易创新的关系
长鑫存储(及其母公司长鑫科技)与兆易创新的关系极为紧密,是由一位核心人物——董事长朱一明联结而成的深度战略联盟。这两家公司在股权、人事和业务等多个层面相互绑定,形成了“一个核心、两个支点”的独特格局。以下是其关系的具…...

ML模型服务化落地实战:从Notebook到高稳定生产环境
1. 项目概述:这不是一次“部署上线”演示,而是一场真实世界的ML交付实战复盘“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着三个关键信号:Notebook是起点,不是终点;Produ…...

避坑指南:在Ubuntu 20.04上配置VNC远程桌面,为什么我推荐UltraVNC Viewer而不是TigerVNC?
Ubuntu 20.04远程桌面配置:为什么UltraVNC Viewer成为技术中坚的首选? 在Linux桌面环境远程管理的世界里,VNC协议就像一位历经沧桑的老兵,依然活跃在企业运维、远程开发和混合办公的第一线。Ubuntu 20.04 LTS作为长期支持版本&…...

微信好友关系检测:如何发现那些悄悄离开的“单向好友“
微信好友关系检测:如何发现那些悄悄离开的"单向好友" 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFr…...

蚂蚁面试实录:手撕多头注意力到LoRA配置的九个坑
面试开场:写代码,别背公式蚂蚁AI应用开发岗面试一开始,面试官没有让我复述Transformer定义,而是直接说:“用PyTorch手写一个Multi-Head Attention,讲清楚Q、K、V的维度变化。”这种考察方式在蚂蚁很常见&am…...

终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案
终极指南:ViGEmBus虚拟游戏控制器驱动,Windows游戏输入革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows…...

驱动教学模式革新:广凌智慧教学融合平台如何实现个性化教学?
随着高等教育从“知识为主”向“能力为先”深刻转型,千人千面的个性化学习已成为未来教育的核心诉求。传统的统一内容、统一路径的教学模式,已难以满足学生差异化的发展需要。如何借助技术手段实现真正的因材施教?广凌智慧教学融合平台以人工…...

盐印相不是滤镜,是光学物理建模!:深度解析Midjourney --sref 与 --style raw 联动实现银盐晶体模拟原理
更多请点击: https://codechina.net 第一章:盐印相不是滤镜,是光学物理建模! 盐印相(Salt Print)作为一种19世纪诞生的早期摄影工艺,其成像本质并非数字图像处理中的风格化滤镜,而是…...