HiveSQL刷题
41、同时在线人数问题
现有各直播间的用户访问记录表(live_events)如下,表中每行数据表达的信息为,一个用户何时进入了一个直播间,又在何时离开了该直播间。
| user_id (用户id) | live_id (直播间id) | in_datetime (进入直播间的时间) | out_datetime (离开直播间的时间) |
|---|---|---|---|
| 100 | 1 | 2021-12-1 19:30:00 | 2021-12-1 19:53:00 |
| 100 | 2 | 2021-12-1 21:01:00 | 2021-12-1 22:00:00 |
| 101 | 1 | 2021-12-1 19:05:00 | 2021-12-1 20:55:00 |
现要求统计各直播间最大同时在线人数,期望结果如下:
| live_id <int> (直播id) | max_user_count <int> (最大人数) |
|---|---|
| 1 | 4 |
| 2 | 3 |
| 3 | 2 |
select live_id,max(sum) max_user_count
from (select *,sum(user_change) over (partition bylive_idorder bytime1) sumfrom (select user_id,live_id,in_datetime time1,1 user_changefrom live_eventsunion allselect user_id,live_id,out_datetime time1,-1 user_changefrom live_events) t1) t2
group by live_id;42、会话划分问题
现有页面浏览记录表(page_view_events)如下,表中有每个用户的每次页面访问记录。
| user_id | page_id | view_timestamp |
|---|---|---|
| 100 | home | 1659950435 |
| 100 | good_search | 1659950446 |
| 100 | good_list | 1659950457 |
| 100 | home | 1659950541 |
| 100 | good_detail | 1659950552 |
| 100 | cart | 1659950563 |
| 101 | home | 1659950435 |
| 101 | good_search | 1659950446 |
| 101 | good_list | 1659950457 |
| 101 | home | 1659950541 |
| 101 | good_detail | 1659950552 |
| 101 | cart | 1659950563 |
| 102 | home | 1659950435 |
| 102 | good_search | 1659950446 |
| 102 | good_list | 1659950457 |
| 103 | home | 1659950541 |
| 103 | good_detail | 1659950552 |
| 103 | cart | 1659950563 |
规定若同一用户的相邻两次访问记录时间间隔小于60s,则认为两次浏览记录属于同一会话。现有如下需求,为属于同一会话的访问记录增加一个相同的会话id字段,会话id格式为"user_id-number",其中number从1开始,用于区分同一用户的不同会话,期望结果如下:
| user_id <int> (用户id) | page_id <string> (页面id) | view_timestamp <bigint> (浏览时间戳) | session_id <string> (会话id) |
|---|---|---|---|
| 100 | home | 1659950435 | 100-1 |
| 100 | good_search | 1659950446 | 100-1 |
| 100 | good_list | 1659950457 | 100-1 |
| 100 | home | 1659950541 | 100-2 |
| 100 | good_detail | 1659950552 | 100-2 |
| 100 | cart | 1659950563 | 100-2 |
| 101 | home | 1659950435 | 101-1 |
| 101 | good_search | 1659950446 | 101-1 |
| 101 | good_list | 1659950457 | 101-1 |
| 101 | home | 1659950541 | 101-2 |
| 101 | good_detail | 1659950552 | 101-2 |
| 101 | cart | 1659950563 | 101-2 |
| 102 | home | 1659950435 | 102-1 |
| 102 | good_search | 1659950446 | 102-1 |
| 102 | good_list | 1659950457 | 102-1 |
| 103 | home | 1659950541 | 103-1 |
| 103 | good_detail | 1659950552 | 103-1 |
select user_id,page_id,view_timestamp,concat(user_id,'-',sum(flag) over (partition byuser_idorder byview_timestamp)) session_id
from (select *,`if`(view_timestamp - lag < 60, 0, 1) flagfrom (select *,lag(view_timestamp, 1, 0) over (partition byuser_idorder byview_timestamp) lagfrom page_view_events) t1) t2;43、间断连续登录用户问题
现有各用户的登录记录表(login_events)如下,表中每行数据表达的信息是一个用户何时登录了平台。
| user_id | login_datetime |
|---|---|
| 100 | 2021-12-01 19:00:00 |
| 100 | 2021-12-01 19:30:00 |
| 100 | 2021-12-02 21:01:00 |
现要求统计各用户最长的连续登录天数,间断一天也算作连续,例如:一个用户在1,3,5,6登录,则视为连续6天登录。期望结果如下:
| user_id <int> (用户id) | max_day_count <int> (最大连续天数) |
|---|---|
| 100 | 3 |
| 101 | 6 |
| 102 | 3 |
| 104 | 3 |
| 105 | 1 |
select user_id,max(datediff) max_day_count
from (select user_id,sum,datediff(max(login_date), min(login_date)) + 1 datedifffrom (select *,sum(flag) over (partition byuser_idorder bylogin_date) sumfrom (select *,`if`(datediff(login_date, laglogin_date) > 2, 1, 0) flagfrom (select *,lag(login_date, 1, '1970-01-01') over (partition byuser_idorder bylogin_date) laglogin_datefrom (select user_id,date_format(login_datetime, 'yyyy-MM-dd') login_datefrom login_eventsgroup by user_id,date_format(login_datetime, 'yyyy-MM-dd')) t1) t2) t3) t4group by user_id,sum) t5
group by user_id;44、日期交叉问题
现有各品牌优惠周期表(promotion_info)如下,其记录了每个品牌的每个优惠活动的周期,其中同一品牌的不同优惠活动的周期可能会有交叉。
| promotion_id | brand | start_date | end_date |
|---|---|---|---|
| 1 | oppo | 2021-06-05 | 2021-06-09 |
| 2 | oppo | 2021-06-11 | 2021-06-21 |
| 3 | vivo | 2021-06-05 | 2021-06-15 |
现要求统计每个品牌的优惠总天数,若某个品牌在同一天有多个优惠活动,则只按一天计算。期望结果如下:
| brand <string> (品牌) | promotion_day_count <int> (优惠天数) |
|---|---|
| vivo | 17 |
| oppo | 16 |
| redmi | 22 |
| huawei | 22 |
select brand,sum(day_count) promotion_day_count
from (select *,casewhen start_date > maxend_date then datediff(end_date, start_date) + 1when end_date > maxend_date then datediff(end_date, maxend_date)else 0end day_countfrom (select *,nvl(max(end_date) over (partition bybrandorder bystart_date rows between unbounded precedingand 1 preceding),'1970-01-01') maxend_datefrom promotion_info) t1) t2
group by brand;45、复购率问题
现有电商订单表(order_detail)如下。
| order_id (订单id) | user_id (用户id) | product_id (商品id) | price (售价) | cnt (数量) | order_date (下单时间) |
|---|---|---|---|---|---|
| 1 | 1 | 1 | 5000 | 1 | 2022-01-01 |
| 2 | 1 | 3 | 5500 | 1 | 2022-01-02 |
| 3 | 1 | 7 | 35 | 2 | 2022-02-01 |
| 4 | 2 | 2 | 3800 | 3 | 2022-03-03 |
注:复购率指用户在一段时间内对某商品的重复购买比例,复购率越大,则反映出消费者对品牌的忠诚度就越高,也叫回头率
此处我们定义:某商品复购率 = 近90天内购买它至少两次的人数 ÷ 购买它的总人数
近90天指包含最大日期(以订单详情表(order_detail)中最后的日期)在内的近90天。结果中复购率保留2位小数,并按复购率倒序、商品ID升序排序。
期望结果如下:
| product_id <int> (商品id) | crp <decimal(16,2)> (复购率) |
|---|---|
| 3 | 1.00 |
| 9 | 1.00 |
| 8 | 0.50 |
| 5 | 0.33 |
| 7 | 0.25 |
| 1 | 0.00 |
| 2 | 0.00 |
| 6 | 0.00 |
select product_id,cast(count(`if`(user_count >= 2, 1, null)) / count(1) as decimal(16, 2)) cpr
from (select product_id,user_id,count(1) user_countfrom (select *,max(order_date) over () max_order_datefrom order_detail) t1where order_date >= date_sub(max_order_date, 90)group by product_id, user_id) t2
group by product_id
order by cpr desc, product_id;46、出勤率问题
现有用户出勤表(user_login)如下。
| user_id (用户id) | course_id (课程id) | login_in (登录时间) | login_out (登出时间) |
|---|---|---|---|
| 1 | 1 | 2022-06-02 09:08:24 | 2022-06-02 10:09:36 |
| 1 | 1 | 2022-06-02 11:07:24 | 2022-06-02 11:44:21 |
| 1 | 2 | 2022-06-02 13:50:24 | 2022-06-02 14:21:50 |
| 2 | 2 | 2022-06-02 13:50:10 | 2022-06-02 15:30:20 |
课程报名表(course_apply)如下。
| course_id (课程id) | course_name (课程名称) | user_id (用户id) |
|---|---|---|
| 1 | java | [1,2,3,4,5,6] |
| 2 | 大数据 | [1,2,3,6] |
| 3 | 前端 | [2,3,4,5] |
注:出勤率指用户看直播时间超过40分钟,求出每个课程的出勤率(结果保留两位小数)。
期望结果如下:
| course_id <int> (课程id) | adr <decimal(16,2)> (出勤率) |
|---|---|
| 1 | 0.33 |
| 2 | 0.50 |
| 3 | 0.25 |
select t3.course_id,cast(user_count / size(ca.user_id) as decimal(16, 2)) adr
from (select course_id,count(1) user_countfrom (select course_id,user_id,sum(time1) sum_timefrom (select user_id, course_id, unix_timestamp(login_out) - unix_timestamp(login_in) time1from user_login) t1group by course_id, user_id) t2where sum_time > 40 * 60group by course_id) t3join course_apply caon ca.course_id = t3.course_id;47、打车问题
现有用户下单表(get_car_record)如下。
| uid (用户id) | city (城市) | event_time (下单时间) | end_time (结束时间:取消或者接单) | order_id (订单id) |
|---|---|---|---|---|
| 107 | 北京 | 2021-09-20 11:00:00 | 2021-09-20 11:00:30 | 9017 |
| 108 | 北京 | 2021-09-20 21:00:00 | 2021-09-20 21:00:40 | 9008 |
| 108 | 北京 | 2021-09-20 18:59:30 | 2021-09-20 19:01:00 | 9018 |
| 102 | 北京 | 2021-09-21 08:59:00 | 2021-09-21 09:01:00 | 9002 |
司机订单信息表(get_car_order)如下。
| order_id (课程id) | uid (用户id) | driver_id (用户id) | order_time (接单时间) | start_time (开始时间) | finish_time (结束时间) | fare (费用) | grade (评分) |
|---|---|---|---|---|---|---|---|
| 9017 | 107 | 213 | 2021-09-20 11:00:30 | 2021-09-20 11:02:10 | 2021-09-20 11:31:00 | 38 | 5 |
| 9008 | 108 | 204 | 2021-09-20 21:00:40 | 2021-09-20 21:03:00 | 2021-09-20 21:31:00 | 38 | 4 |
| 9018 | 108 | 214 | 2021-09-20 19:01:00 | 2021-09-20 19:04:50 | 2021-09-20 19:21:00 | 38 | 5 |
统计周一到周五各时段的叫车量、平均等待接单时间和平均调度时间。全部以event_time-开始打车时间为时段划分依据,平均等待接单时间和平均调度时间均保留2位小数,平均调度时间仅计算完成了的订单,结果按叫车量升序排序。
注:不同时段定义:早高峰 [07:00:00 , 09:00:00)、工作时间 [09:00:00 , 17:00:00)、晚高峰 [17:00:00 ,20:00:00)、休息时间 [20:00:00 , 07:00:00) 时间区间左闭右开(即7:00:00算作早高峰,而9:00:00不算做早高峰)
从开始打车到司机接单为等待接单时间,从司机接单到上车为调度时间
期望结果如下:
| period <string> (时段) | get_car_num <int> (叫车量) | wait_time <decimal(16,2)> (等待时长) | dispatch_time <decimal(16,2)> (调度时长) |
|---|---|---|---|
| 工作时间 | 1 | 0.50 | 1.67 |
| 休息时间 | 1 | 0.67 | 2.33 |
| 晚高峰 | 3 | 2.06 | 7.28 |
| 早高峰 | 4 | 2.21 | 8.00 |
select period,count(1) get_car_num,cast(avg(end_time - event_time) / 60 as decimal(16, 2)) wait_time,cast(avg(start_time - order_time) / 60 as decimal(16, 2)) dispatch_time
from (select unix_timestamp(event_time) event_time,unix_timestamp(end_time) end_time,unix_timestamp(order_time) order_time,unix_timestamp(start_time) start_time,casewhen hour(event_time) between 7 and 8 then '早高峰'when hour(event_time) between 9 and 16 then '工作时间'when hour(event_time) between 17 and 19 then '晚高峰'else '休息时间'end periodfrom get_car_record gcrleft join get_car_order gcoon gcr.order_id = gco.order_idwhere `dayofweek`(event_time) between 2 and 6) t1
group by period;48、排列问题
现有球队表(team)如下。
| team_name (球队名称) |
|---|
| 湖人 |
| 骑士 |
| 灰熊 |
| 勇士 |
拿到所有球队比赛的组合 每个队只比一次
期望结果如下:
| team_name_1 <string> (队名) | team_name_2 <string> (队名) |
|---|---|
| 勇士 | 湖人 |
| 湖人 | 骑士 |
| 灰熊 | 骑士 |
| 勇士 | 骑士 |
| 湖人 | 灰熊 |
| 勇士 | 灰熊 |
select t1.team_name team_name_1, t2.team_name team_name_2
from team t1join team t2
where t1.team_name < t2.team_name;49、视频热度问题
现有用户视频表(user_video_log)如下。
| uid (球队名称) | video_id (视频id) | start_time (开始时间) | end_time (结束时间) | if_like (是否点赞) | if_retweet (是否喜欢) | comment_id (评论id) |
|---|---|---|---|---|---|---|
| 101 | 2001 | 2021-09-24 10:00:00 | 2021-09-24 10:00:20 | 1 | 0 | null |
| 105 | 2002 | 2021-09-25 11:00:00 | 2021-09-25 11:00:30 | 0 | 1 | null |
| 102 | 2002 | 2021-09-25 11:00:00 | 2021-09-25 11:00:30 | 1 | 1 | null |
| 101 | 2002 | 2021-09-26 11:00:00 | 2021-09-26 11:00:30 | 0 | 1 | null |
视频信息表(video_info) 如下:
| video_id (视频id) | author (作者id) | tag (标签) | duration (视频时长) |
|---|---|---|---|
| 2001 | 901 | 旅游 | 30 |
| 2002 | 901 | 旅游 | 60 |
| 2003 | 902 | 影视 | 90 |
| 2004 | 902 | 美女 | 90 |
找出近一个月发布的视频中热度最高的top3视频。
注:热度=(a*视频完播率+b*点赞数+c*评论数+d*转发数)*新鲜度;
新鲜度=1/(最近无播放天数+1);
当前配置的参数a,b,c,d分别为100、5、3、2。
最近播放日期以 end_time-结束观看时间 为准,假设为T,则最近一个月按 [T-29, T] 闭区间统计。
当天日期使用视频中最大的end_time
结果中热度保留为整数,并按热度降序排序。
期望结果如下:
| video_id <int> (视频id) | heat <decimal(16,2)> (热度) |
|---|---|
| 2002 | 80.36 |
| 2001 | 20.33 |
select video_id,cast(ceil((100 * wb + 5 * dz + 3 * pl + 2 * zf) * 1) as decimal(16, 1)) heat
from (select video_id,sum(wanbo) / count(1) wb,sum(if_like) dz,count(comment_id) pl,sum(if_retweet) zf,min(datediff_time) zjfrom (select uvl.video_id,if_like,comment_id,if_retweet,datediff(max(end_time) over (), end_time) datediff_time,`if`(unix_timestamp(end_time) - unix_timestamp(start_time) >= duration, 1, 0) wanbofrom user_video_log uvljoin video_info vion uvl.video_id = vi.video_id) t1group by video_id) t2;50、员工在职人数问题
现有用户表(emp)如下。
| id (员工id) | en_dt (入职日期) | start_time (离职日期) |
|---|---|---|
| 1001 | 2020-01-02 | null |
| 1002 | 2020-01-02 | 2020-03-05 |
| 1003 | 2020-02-02 | 2020-02-15 |
| 1004 | 2020-02-12 | 2020-03-08 |
日历表(cal) 如下:
| dt (日期) |
|---|
| 2020-01-01 |
| 2020-01-02 |
| 2020-01-03 |
| 2020-01-04 |
统计2020年每个月实际在职员工数量(只统计2020-03-31之前),如果1个月在职天数只有1天,数量计算方式:1/当月天数。
如果一个月只有一天的话,只算30分之1个人
期望结果如下:
| mnt <int> (月份) | ps <decimal(16,2)> (在职人数) |
|---|---|
| 1 | 1.94 |
| 2 | 3.62 |
| 3 | 2.23 |
with t1 as (select id,en_dt,nvl(le_dt, '2020-03-31') le_dt,month(en_dt) + pos monfrom emplateral view posexplode(split(repeat('a', month(nvl(le_dt, '2020-03-31')) - month(en_dt)),'a')) tbl as pos, val),t2 as (select month(dt) mon,max(dt) max_date,min(dt) min_datefrom calgroup by month(dt))
select mon mth,cast(sum(zai) as decimal(16, 2)) ps
from (select t1.mon,(datediff(`if`(le_dt > max_date, max_date, le_dt), `if`(en_dt > min_date, en_dt, min_date)) + 1) /(datediff(max_date, min_date) + 1) zaifrom t1join t2on t1.mon = t2.mon) t3
group by mon;
相关文章:

HiveSQL刷题
41、同时在线人数问题 现有各直播间的用户访问记录表(live_events)如下,表中每行数据表达的信息为,一个用户何时进入了一个直播间,又在何时离开了该直播间。 user_id (用户id)live_id (直播间id)in_datetime (进入直…...

path路径模块
path模块是Node.js官方提供的、用来处理路径的模块。它提供了一系列的方法和属性,用来满足用户对路径的处理需求。 path.join( )用来将多个路径片段拼接成一个完整的路径字符串 ../会抵消前面的路径 const path require(path) const pathStr path.join(/a,/b,../,/d) conso…...
1.文章复现《热电联产系统在区域综合能源系统中的定容选址研究》(附matlab程序)
0.代码链接 文章复现《热电联产系统在区域综合能源系统中的定容选址研究》(matlab程序)-Matlab文档类资源-CSDN文库 1.简述 本文采用遗传算法的方式进行了下述文章的复现并采用电-热节点的方式进行了潮流计算以降低电网的网络损耗 分析了电网的基本数…...
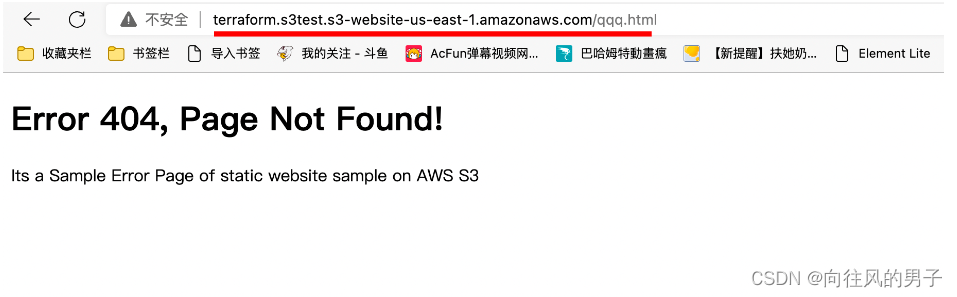
【Terraform学习】使用 Terraform 托管 S3 静态网站(Terraform-AWS最佳实战学习)
使用 Terraform 托管 S3 静态网站 实验步骤 前提条件 安装 Terraform: 地址 下载仓库代码模版 本实验代码位于 task_s3 文件夹中。 变量文件 variables.tf 在上面的代码中,您将声明,aws_access_key,aws_secret_key和区域变量…...

触发JVM fatal error并配置相关JVM参数
1. 絮絮叨叨 工作中,Java服务因为fatal error(致命错误,笔者称其为jvm crash),在服务运行日志中出现了致命错误的概要信息: # # A fatal error has been detected by the Java Runtime Environment: # # S…...

爬虫(bilibili热门课程记录)
什么是爬虫?程序蜘蛛,沿着互联网获取相关信息,收集目标信息。 一、python环境安装 1、先从Download Python | Python.org中下载最新版本的python解释器 2、再从Download PyCharm: Python IDE for Professional Developers by JetBrains中下…...
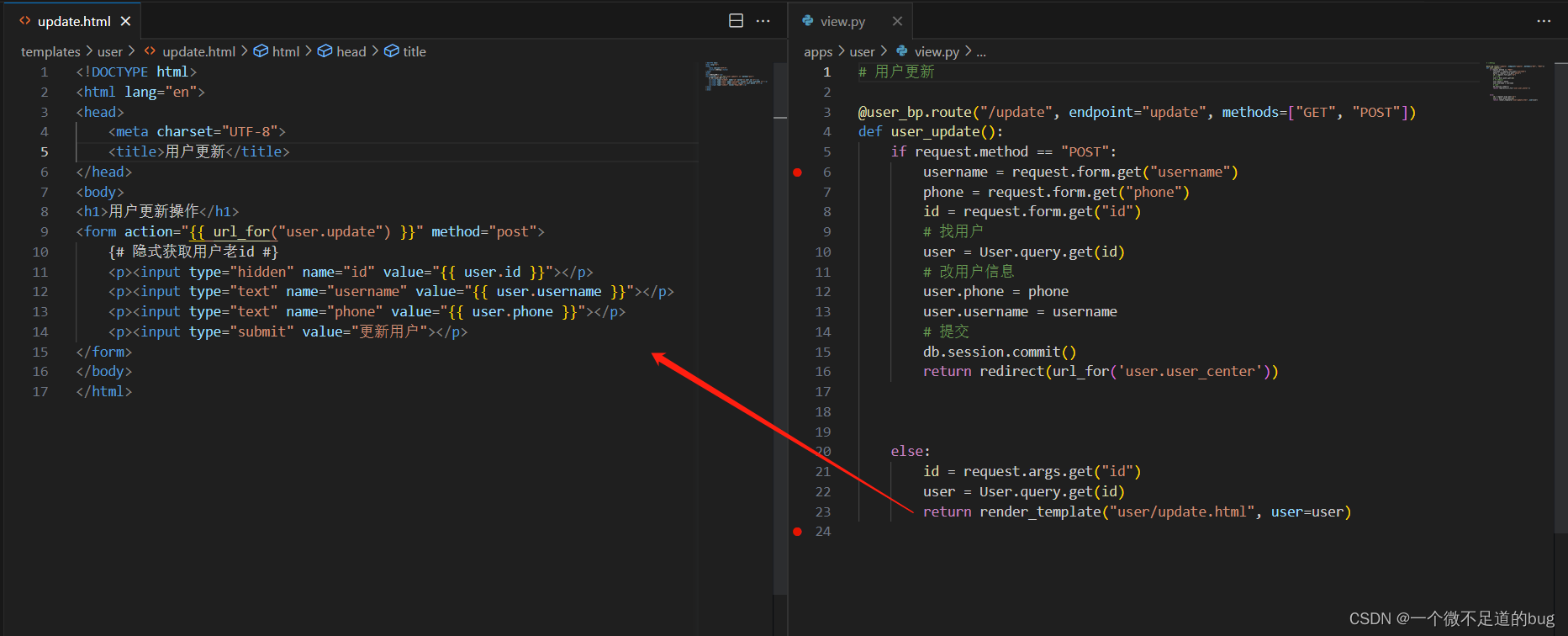
14-模型 - 增删改查
增: # 1. 找到模型类并创建对象 user User() # 2. 给对象的属性赋值 user.username username user.password password user.phone phone # 3. 将user对象添加到session中 (类似缓存) db.session.add(user) # 4. 提交数据 db.session.commit() 删: # 两种删除:# 1. 逻辑删…...

C#与西门子PLC1500的ModbusTcp服务器通信3--搭建ModbusTcp服务器
1、打开仿真工具,创建PLC,注意创建完成后不要关闭 注意,这个IP地址必须与西门子虚拟网卡的IP地址及虚拟机的网卡IP地址同一网段 2、打开博途V15,创建项目,命名为Lan项目 3、添加1500系列CPU1513 4、设置设置IP地址及属…...
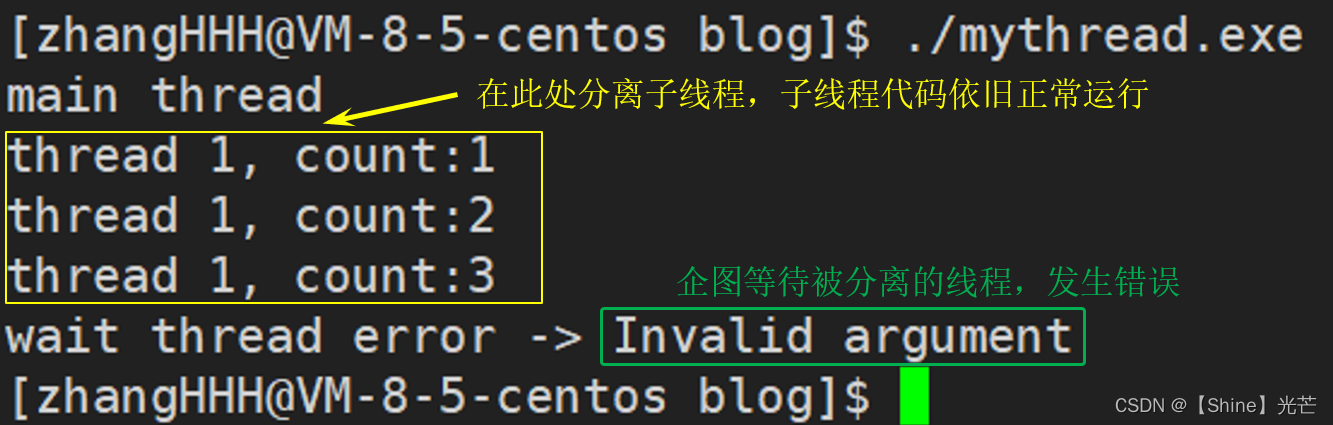
Linux系统编程:线程控制
目录 一. 线程的创建 1.1 pthread_create函数 1.2 线程id的本质 二. 多线程中的异常和程序替换 2.1 多线程程序异常 2.2 多线程中的程序替换 三. 线程等待 四. 线程的终止和分离 4.1 线程函数return 4.2 线程取消 pthread_cancel 4.3 线程退出 pthread_exit 4.4 线程…...
基于Java+SpringBoot+Vue前后端分离纺织品企业财务管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

搭建开发环境-Windows
写C# 的请出去。 然后,Windows 是最好的Linux发行版。搭建开发环境-WSLUbuntu...
【 Python 全栈开发 - 人工智能篇 - 45 】集成算法与聚类算法
文章目录 一、集成算法1.1 概念1.2 常用集成算法1.2.1 Bagging1.2.2 Boosting1.2.2.1 AdaBoost1.2.2.2 GBDT1.2.2.3 XgBoost 1.2.3 Stacking 二、聚类算法2.1 概念2.2 常用聚类算法2.2.1 K-means2.2.2 层次聚类2.2.3 DBSCAN算法2.2.4 AP聚类算法2.2.5 高斯混合模型聚类算法 一、…...

SSM商城项目实战:账户充值功能实现
SSM商城项目实战:账户充值功能实现 在一个电商平台中,用户账户充值是一个非常重要的功能。本文将介绍如何在SSM(SpringSpringMVCMyBatis)商城项目中实现账户充值功能。通过本文的指导,你将学会如何在项目中添加账户充…...

wireshark工具pcap文件转换
pcap详解_pcap_loop_小虎随笔的博客-CSDN博客 分析802.11无线报文hexdump内容:利用wireshark自带二进制工具text2pcap将hexdump内容转换为pcap文件..._weixin_30835933的博客-CSDN博客 text2pcap: 将hex转储文本转换为Wireshark可打开的pcap文件(wireshark,数据) …...

Python+TinyPNG熊猫网站自动化的压缩图片
前言 本篇在讲什么 PythonTinyPNG自动化处理图片 本篇需要什么 对Python语法有简单认知 依赖Python2.7环境 依赖TinyPNG工具 本篇的特色 具有全流程的图文教学 重实践,轻理论,快速上手 提供全流程的源码内容 ★提高阅读体验★ 👉…...
【Linux】socket 编程基础
文章目录 📕 网络间的通信📕 socket 是什么1. socket 套接字2. 套接字描述符3. 基本的 socket 接口函数3.1 头文件3.2 socket() 函数3.3 bind() 函数struct sockaddr主机序列与网络序列 3.4 listen() 函数3.5 connect() 函数3.6 accept() 函数IP 地址风格…...

openGauss学习笔记-51 openGauss 高级特性-列存储
文章目录 openGauss学习笔记-51 openGauss 高级特性-列存储51.1 语法格式51.2 参数说明51.3 示例 openGauss学习笔记-51 openGauss 高级特性-列存储 openGauss支持行列混合存储。行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。 行、列…...

ReactNative 密码生成器实战
效果展示图 使用插件 Formik 负责表单校验、监听表单提交、数据校验错误信息展示 Yup 负责表单校验规则 分析页面 从上述的展示图我们可以看到的主要元素有:输入框、单选按钮和按钮。其中生成的密码长度不可能很大也不可能为负数和 0,所以我们可以限…...
开始MySQL之路——外键关联和多表联合查询详细概述
多表查询和外键关联 实际开发中,一个项目通常需要很多张表才能完成。例如,一个商城项目就需要分类表,商品表,订单表等多张表。且这些表的数据之间存在一定的关系,接下来我们将在单表的基础上,一起学习多表…...

无涯教程-PHP - intval() 函数
PHP 7引入了一个新函数 intdiv(),该函数对其操作数执行整数除法并将该除法返回为int。 <?php$valueintdiv(10,3);var_dump($value);print(" ");print($value); ?> 它产生以下浏览器输出- int(3) 3 PHP - intval() 函数 - 无涯教程网无涯教程网…...
)
护士执业资格考试历年真题及答案解析电子版PDF(2011-2025年)
2026年护士执业资格考试时间为2026年4月11-12日。为助力广大考生高效备考,小编精心整理了涵盖2011年至2025年的护士执业资格考试真题试卷及详细答案解析,包含《专业实务》和《实践能力》,高清PDF电子版,可打印,方便…...
)
【office2pdf】PPTX 字体解析与文本样式继承(PPTX_FONT_RESOLUTION.md)
摘要 本文档记录了 PPTX 保真度问题,该问题最初看起来像是布局错误, 但实际上是由不完整的字体和文本样式解析引起的。 可见的症状是多个幻灯片上的文本块,尤其是幻灯片 4 的"SKILLS"区域, 与 PowerPoint 不匹配&#x…...

图图的嗨丝造相-Z-Image-Turbo效果对比:8bit vs 16bit精度推理对渔网袜边缘锐度的影响
图图的嗨丝造相-Z-Image-Turbo效果对比:8bit vs 16bit精度推理对渔网袜边缘锐度的影响 1. 引言:当AI绘画遇上“渔网袜”细节 最近在玩一个挺有意思的AI绘画模型——图图的嗨丝造相-Z-Image-Turbo。这个模型专门针对“大网渔网袜”这种特定服饰的生成做…...

Windows 11 离线部署 WSL2 与 Ubuntu:绕过商店限制的完整实战
1. 为什么需要离线部署 WSL2 与 Ubuntu 很多开发者在 Windows 11 上使用 WSL2 时都会遇到一个头疼的问题:微软商店经常无法正常访问或下载速度极慢。我自己就遇到过好几次,明明网络连接正常,但就是卡在下载环节,进度条一动不动。这…...

【DeepSeek-R1背后的技术】系列七:冷启动——从“零”到“一”的智能启蒙
1. 冷启动:AI模型的"启蒙教育" 想象一下,你面前站着一个刚出生的婴儿,他对这个世界一无所知。如果你直接把他扔进大学课堂,会发生什么?他可能会哭闹、听不懂任何内容,甚至产生恐惧心理。这就是一…...

Kimi-VL-A3B-Thinking图文问答实操手册:从镜像拉取到Chainlit交互验证
Kimi-VL-A3B-Thinking图文问答实操手册:从镜像拉取到Chainlit交互验证 1. 引言:为什么你需要关注这个图文对话模型? 想象一下,你手头有一张复杂的图表,或者一份满是文字的截图,你想快速知道里面的关键信息…...

QWEN-AUDIO开箱即用指南:无需conda/pip,纯Docker镜像启动
QWEN-AUDIO开箱即用指南:无需conda/pip,纯Docker镜像启动 想体验一下“有温度”的AI语音合成吗?以前你可能需要折腾Python环境、安装各种依赖、处理版本冲突,光是配置环境就能劝退一大半人。今天,我要分享一个完全不同…...
对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/)
《QGIS快速入门与应用基础》248:对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/居中对齐/右对齐)对齐工具(左对齐/
作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具…...

Kali Linux 2026.1 重磅发布,内核升至6.18
作为全球最受欢迎的渗透测试与安全审计Linux发行版,Kali Linux在2026年迎来了年度首发版本——Kali Linux 2026.1。这次更新不仅延续了每年“.1”版本的视觉刷新传统,更特别致敬BackTrack Linux 20周年,引入“BackTrack模式”,同时升级内核至6.18,并新增8款实用工具。无论…...

XUnity.AutoTranslator:如何为Unity游戏构建高效的多语言本地化系统
XUnity.AutoTranslator:如何为Unity游戏构建高效的多语言本地化系统 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator XUnity.AutoTranslator是一个专为Unity游戏设计的自动翻译插件,…...