百度工程师浅析解码策略

作者 | Jane
导读
生成式模型的解码方法主要有2类:确定性方法(如贪心搜索和波束搜索)和随机方法。确定性方法生成的文本通常会不够自然,可能存在重复或过于简单的表达。而随机方法在解码过程中引入了随机性,以便生成更多样化、更自然的文本。两种常见的随机方法是:
1、Top-k 采样:在每个解码步骤中,模型会选择可能性排名在前的前 k 个单词,然后从这些单词中随机选择一个作为下一个生成的单词。这样可以增加文本的多样性,但仍然保持一定的可控性。
2、核采样(Top-p 采样):在这种方法中,模型会根据累积概率从词汇表中选择下一个单词。累积概率是指按照概率从高到低排列的单词概率之和。这可以减少重复性,并且相对于固定的 k 值,它可以自适应地选择更少或更多的候选词。
虽然核采样可以生成(缓解)没有重复的文本,但生成文本的语义一致性并不是很好,这种语义不一致的问题可以通过降低温度 (temperature) 来部分解决。降低温度是一个可以影响随机性的参数。较高的温度会导致更均匀的分布,使得生成的文本更多样化,而较低的温度会使分布更集中,更接近于确定性。这就引入了一个权衡,因为较高的温度可能会导致文本语义不一致,而较低的温度可能会失去一些多样性。
在实际应用中,要根据任务和期望的文本输出特性来选择合适的解码方法、随机性参数和温度值。不同的方法和参数组合可能适用于不同的情况,以平衡生成文本的多样性、准确性和一致性。
全文3646字,预计阅读时间10分钟。
01 对比搜索(contrastive_search)
对比搜索给定前缀文本 x < t x_{< t} x<t,按如下公式输出token x t x_{t} xt:
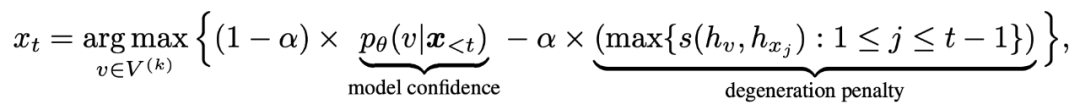
语言模型输出的概率分布 p θ ( v ∣ x < t ) p_{\theta}(v|x_{< t}) pθ(v∣x<t)表示下一个可能的token的预测概率,上式中 V ( k ) V^{(k)} V(k)表示概率分布中 k 个概率最大的候选token的集合。
-
第一项,即 模型置信度 (model confidence),是语言模型预测的每个候选词元 v 的概率。
-
第二项, 退化惩罚 (degeneration penalty),用于度量候选token v 与上文 x < t x{< t} x<t中每个token的相似性, v 的向量表征 h v h_{v} hv与其上文 x < t x {< t} x<t中每个token的向量表征计算余弦相似度,相似度最大值被用作退化惩罚。直观上理解,如果 v 的退化惩罚较大意味着它与上文更相似 (在表示空间中),因此更有可能导致模型退化问题。超参数 α \alpha α用于在这两项中折衷。当时 α = 0 \alpha=0 α=0,对比搜索退化为纯贪心搜索。
总结来说,对比搜索在生成输出时会同时考虑:
-
语言模型预测的概率,以保持生成文本和前缀文本之间的语义连贯性。
-
与上文的相似性以避免模型退化。
# generate the result with contrastive search
output = model.generate(input_ids, penalty_alpha=0.6, # 对比搜索中的超参 $\alpha$top_k=4, # 对比搜索中的超参 $k$。max_length=512)02 贪心搜索(greedy_search)**
贪心搜索在每个时间步 都简单地选择概率最高的词作为当前输出词: w t = a r g m a x w P ( w ∣ w 1 : t − 1 ) w_t = argmax_{w}P(w | w_{1:t-1}) wt=argmaxwP(w∣w1:t−1)
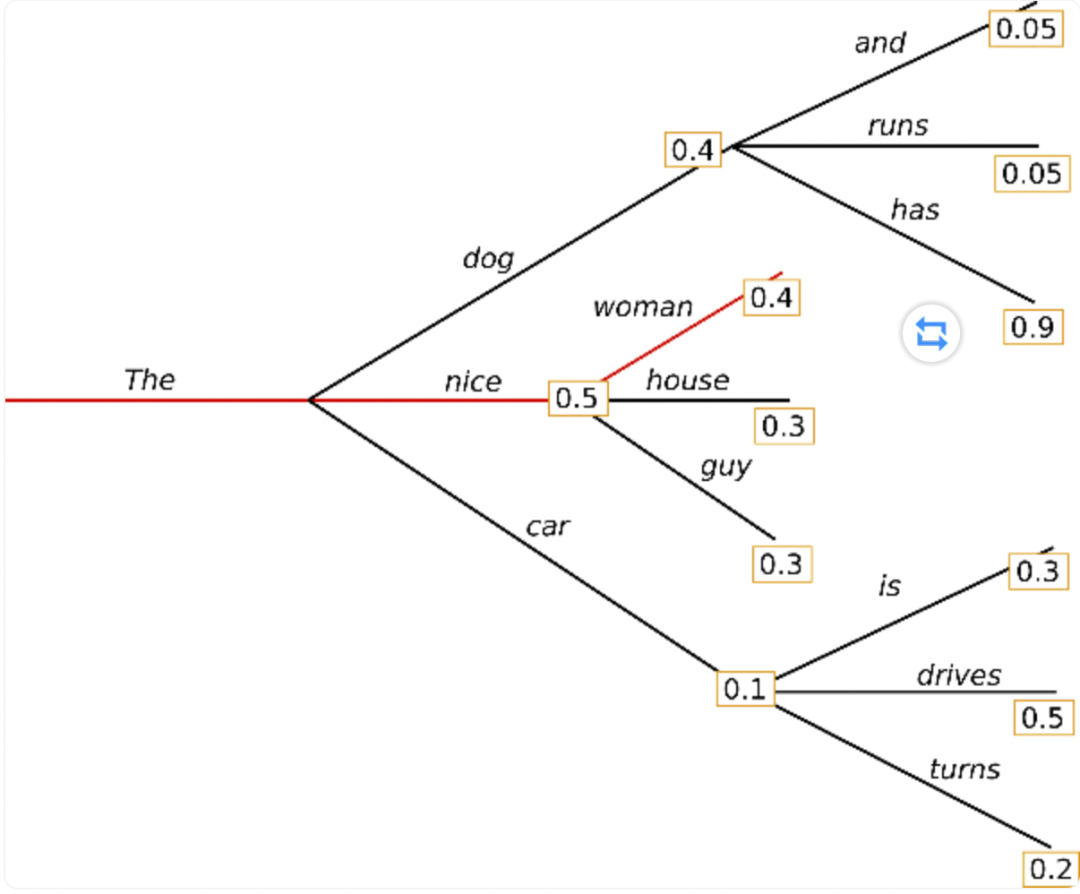
△贪心搜索
问题:
-
容易输出重复的文本,这在语言生成中是一个非常普遍的问题,在贪心搜索和波束搜索中似乎更是如此
-
主要缺点是它错过了隐藏在低概率词后面的高概率词:The -> dog -> has (0.4*0.9=0.36),The -> nice -> wman (0.5*0.4=0.20),波束搜索可以缓解此类问题
03 波束搜索(beam_search)
波束搜索整个过程可以总结为: 分叉、排序、剪枝,如此往复。波束搜索通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。
下图示例 num_beams=2:
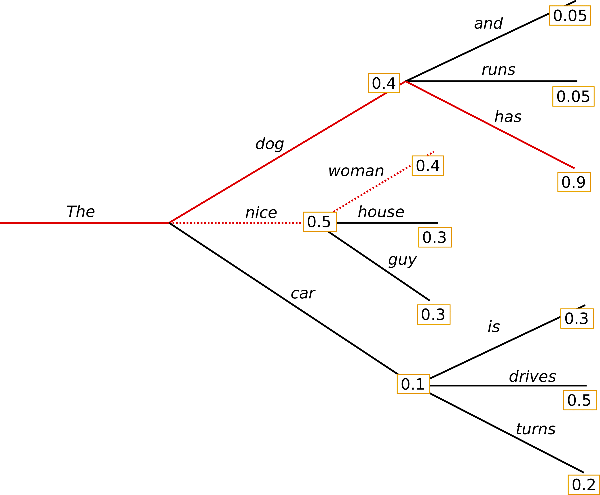
△波束搜索 num_beams=2
波束搜索一般都会找到比贪心搜索概率更高的输出序列,但仍不保证找到全局最优解。
虽然结果比贪心搜索更流畅,但输出中仍然包含重复。一个简单的补救措施是引入 n-grams (即连续 n 个词的词序列) 惩罚:最常见的 n-grams 惩罚是确保每个 n-gram 都只出现一次,方法是如果看到当前候选词与其上文所组成的 n-gram 已经出现过了,就将该候选词的概率设置为 0。通过设置 no_repeat_ngram_size=2 来试试,这样任意 2-gram 不会出现两次:
beam_output = model.generate(input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, # n-gramsearly_stopping=True
)但是,n-gram 惩罚使用时必须谨慎,如一篇关于纽约这个城市的文章就不应使用 2-gram 惩罚,否则,城市名称在整个文本中将只出现一次!
波束搜索已被证明依然会存在重复生成的问题。在『故事生成』这样的场景中,很难用 n-gram 或其他惩罚来控制,因为在“不重复”和最大可重复 n-grams 之间找到一个好的折衷需要大量的微调。正如 Ari Holtzman 等人 (2019) (https://arxiv.org/abs/1904.09751) 所论证的那样,高质量的人类语言并不遵循最大概率法则。这是因为人类语言具有创造性和惊喜性,而不仅仅是简单的预测性。
因此,引入随机性和创造性元素是生成更有趣和多样性文本的关键。
04 采样(sampling)
4.1 采样
使用采样方法时文本生成本身不再是确定性的(do_sample=True)。
# activate sampling and deactivate top_k by setting top_k sampling to 0
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=0
)对单词序列进行采样时的问题:模型通常会产生不连贯的乱码,缓解这一问题的一个技巧是通过降低 softmax的“温度”使分布 P ( w ∣ w 1 : t − 1 ) P(w|w_{1:t-1}) P(w∣w1:t−1)更陡峭。而降低“温度”,本质上是增加高概率单词的似然并降低低概率单词的似然。
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_k=0, temperature=0.7
)虽然温度可以使分布的随机性降低,但极限条件下,当“温度”设置为 0 时,温度缩放采样就退化成贪心解码了,因此会遇到与贪心解码相同的问题。
4.2 Top-k 采样
在 Top-K 采样中,概率最大的 K 个词会被选出,然后这 K 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 K 个词中采样。GPT2 采用了这种采样方案,这也是它在故事生成这样的任务上取得成功的原因之一。
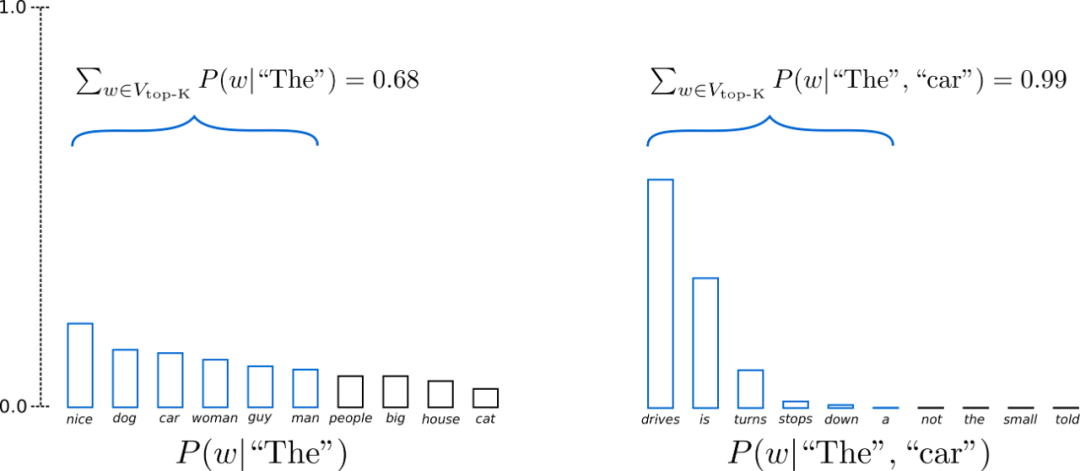
假设 p=0.92,Top-p 采样对单词概率进行降序排列并累加,然后选择概率和首次超过 p=92% 的单词集作为采样池,定义为 V top-p V_{\text{top-p}} Vtop-p。在 t=1 时 V top-p V_{\text{top-p}} Vtop-p有 9 个词,而在 t=2 时它只需要选择前 3 个词就超过了 92%。
可以看出,在单词比较不可预测时(例如更平坦的左图),它保留了更多的候选词,如 P ( w ∣ “The” ) P(w | \text{“The”}) P(w∣“The”),而当单词似乎更容易预测时(例如更尖锐的右图),只保留了几个候选词,如 P ( w ∣ “The” , “car” ) P(w | \text{“The”}, \text{“car”}) P(w∣“The”,“car”)。
# deactivate top_k sampling and sample only from 92% most likely words
sample_output = model.generate(input_ids, do_sample=True, max_length=50, top_p=0.92, top_k=0
)虽然从理论上讲, Top-p 似乎比 Top-K 更优雅,但这两种方法在实践中都很有效。Top-p 也可以与 Top-K 结合使用,这样可以避免排名非常低的词,同时允许进行一些动态选择。如果 k 和 p 都启用,则 p 在 k 之后起作用。
# 配置 top_k = 50 、 top_p = 0.95 、 num_return_sequences = 3
sample_outputs = model.generate(input_ids,do_sample=True, max_length=50, top_k=50, top_p=0.95, num_return_sequences=3
)——END——
参考资料:
[1]一种简单有效的解码策略:Contrastive Search
[2]HF:如何生成文本: 通过 Transformers 用不同的解码方法生成文本
[3]https://docs.cohere.ai/docs/controlling-generation-with-top-k-top-p
[4]https://docs.cohere.ai/docs/temperature
推荐阅读:
百度工程师浅析强化学习
浅谈统一权限管理服务的设计与开发
百度APP iOS端包体积50M优化实践(五) HEIC图片和无用类优化实践
百度知道上云与架构演进
百度APP iOS端包体积50M优化实践(四)代码优化
百度App启动性能优化实践篇
相关文章:
百度工程师浅析解码策略
作者 | Jane 导读 生成式模型的解码方法主要有2类:确定性方法(如贪心搜索和波束搜索)和随机方法。确定性方法生成的文本通常会不够自然,可能存在重复或过于简单的表达。而随机方法在解码过程中引入了随机性,以便生成更…...

windows下实现查看软件请求ip地址的方法
一、关于wmic和nestat wmic是Windows Management Instrumentation的缩写,是一款非常常用的用于Windows系统管理的命令行实用程序。wmic可以通过命令行操作,获取系统信息、安装软件、启动服务、管理进程等操作。 netstat命令是一个监控TCP/IP网络的非常有…...

【JAVA】String 类
⭐ 作者:小胡_不糊涂 🌱 作者主页:小胡_不糊涂的个人主页 📀 收录专栏:浅谈Java 💖 持续更文,关注博主少走弯路,谢谢大家支持 💖 String 1. 字符串构造2. String对象的比…...
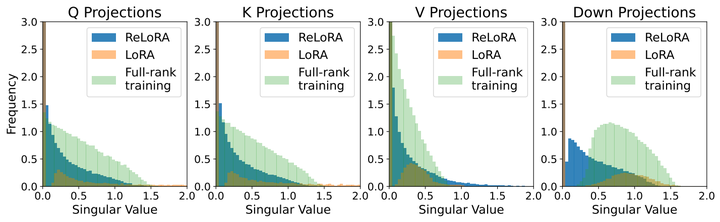
LoRA继任者ReLoRA登场,通过叠加多个低秩更新矩阵实现更高效大模型训练效果
论文链接: https://arxiv.org/abs/2307.05695 代码仓库: https://github.com/guitaricet/peft_pretraining 一段时间以来,大模型(LLMs)社区的研究人员开始关注于如何降低训练、微调和推理LLMs所需要的庞大算力…...

Elasticsearch 8.X reindex 源码剖析及提速指南
1、reindex 源码在线地址 为方便大家验证,这里给出 reindex github 源码地址。 https://github.com/elastic/elasticsearch/blob/001fcfb931454d760dbccff9f4d1b8d113f8708c/server/src/main/java/org/elasticsearch/index/reindex/ReindexRequest.java reindex 常见…...

前端组件库造轮子——Input组件开发教程
前端组件库造轮子——Input组件开发教程 前言 本系列旨在记录前端组件库开发经验,我们的组件库项目目前已在Github开源,下面是项目的部分组件。文章会详细介绍一些造组件库轮子的技巧并且最后会给出完整的演示demo。 文章旨在总结经验,开源…...

Day04-Vue基础-监听器-双向绑定-组件通信
Day04-Vue基础-监听器-双向绑定-组件通信 一 侦听器 语法一 <template><div>{{name}}<br><button @click="update1">修改1</button><...

Java小白基础自学阶段(持续更新...)
引言 Java作为一门广泛应用于企业级开发的编程语言,对初学者来说可能会感到有些复杂。然而,通过适当的学习方法和资源,即使是小白也可以轻松掌握Java的基础知识。本文将提供一些有用的建议和资源,帮助小白自学Java基础。 学习步骤…...

Vue自定义指令- v-loading封装
Vue自定义指令- v-loading封装 文章目录 Vue自定义指令- v-loading封装01-自定义指令自定义指令的两种注册语法: 02自定义指令的值03-自定义指令- v-loading指令封装 01-自定义指令 什么是自定义指令? 自定义指令:自己定义的指令,…...

C++中提供的一些关于查找元素的函数
C中提供的所有关于查找的函数 std::find(begin(), end(), key) std::find(begin(), end(), key):这个函数用于在一个范围内查找一个等于给定值的元素,返回一个指向该元素的迭代器,如果没有找到则返回范围的结束迭代器。 1.1 例如ÿ…...
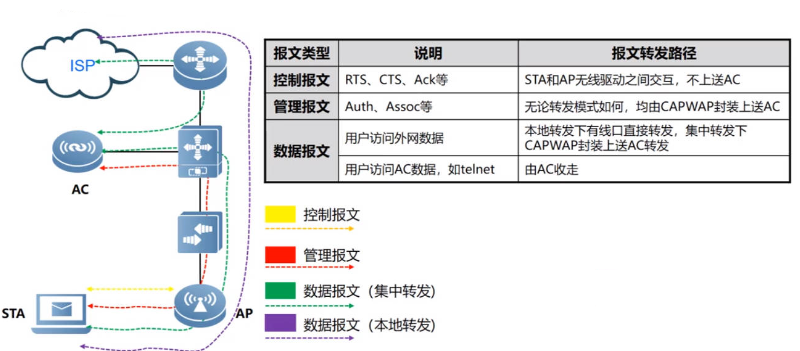
Wlan——STA上线流程与802.11MAC帧讲解以及报文转发路径
目录 802.11MAC帧基本概念 802.11帧结构 802.11MAC帧的分类 管理帧 控制帧 数据帧 STA接入无线网络流程 信号扫描—管理帧 链路认证—管理帧 用户关联—管理帧 用户上线 不同802.11帧的转发路径 802.11MAC帧基本概念 802.11协议在802家族中的角色位置 其中802.3标…...
Python|爬虫和测试|selenium框架模拟登录示例(一)
前言: 上一篇文章Python|爬虫和测试|selenium框架的安装和初步使用(一)_晚风_END的博客-CSDN博客 大概介绍了一下selenium的安装和初步使用,主要是打开某个网站的主页,基本是最基础的东西,那么,…...

QT的概述
什么是QT Qt是一个跨平台的C图形用户界面应用程序框架。它为应用程序开发者提供建立艺术级图形界面所需的所有功能。它是完全面向对象的,很容易扩展,并且允许真正的组件编程。 QT项目的创建 .pro文件 .pro 文件是一个Qt项目文件,用于定义…...

Hive 导入csv文件,数据中包含逗号的问题
问题 今天 Hive 导入 csv 文件时,开始时建表语句如下: CREATE TABLE IF NOT EXISTS test.student (name STRING COMMENT 姓名,age STRING COMMENT 年龄,gender STRING COMMENT 性别,other_info STRING COMMENT 其他信息 ) COMMENT 学生信息表 ROW FORM…...

1、Odoo开发起点
1.1.odoo的模块组成 init.py将一个文件夹编程python包manifestpyodoo模块定义的清单文件,用于对odoo模块管理详见model模型类文件,存放py文件security表级别权限管理static静态文件views视图文件。wizard瞬态模型向导文件位置 1.2.odoo的开发规范 非强…...

Ubuntu22.04 交叉编译树莓派CM4 kernel
通过这个文章记录一下如何在Ubuntu22.04编译树莓派CM4的kernel。 主要参考树莓派官网的方法,也总结了一些关于SD卡分区的知识。 1,虚拟机安装Ubuntu 22.04,就不介绍了。 2,先将树莓派官方系统烧录倒SD卡中,设备能正…...
)
稀疏矩阵搜索(两种方法解决:1.暴力+哈希 2.二分法)
题目: 有个排好序的字符串数组,其中散布着一些空字符串,编写一种方法,找出给定字符串的位置。 示例: 输入: words ["at", "", "", "", "ball", "", &…...

NodeJS系列教程、笔记
NodeJS系列教程、笔记 点我进入专栏 Node.js安装与基本使用 NodeJS的Web框架Express入门 Node.js的sha1加密 Nodejs热更新 Nodejs配置文件 Nodejs的字节操作(Buffer) Node.js之TCP(net) Node.js使用axios进行web接口调用 …...

4.4TCP半连接队列和全连接队列
目录 什么是 TCP 半连接队列和全连接队列? TCP 全连接队列溢出 如何知道应用程序的 TCP 全连接队列大小? 如何模拟 TCP 全连接队列溢出的场景? 全连接队列溢出会发生什么 ? 如何增大全连接队列呢 ? TCP 半连接队列溢出 如何查看 TC…...
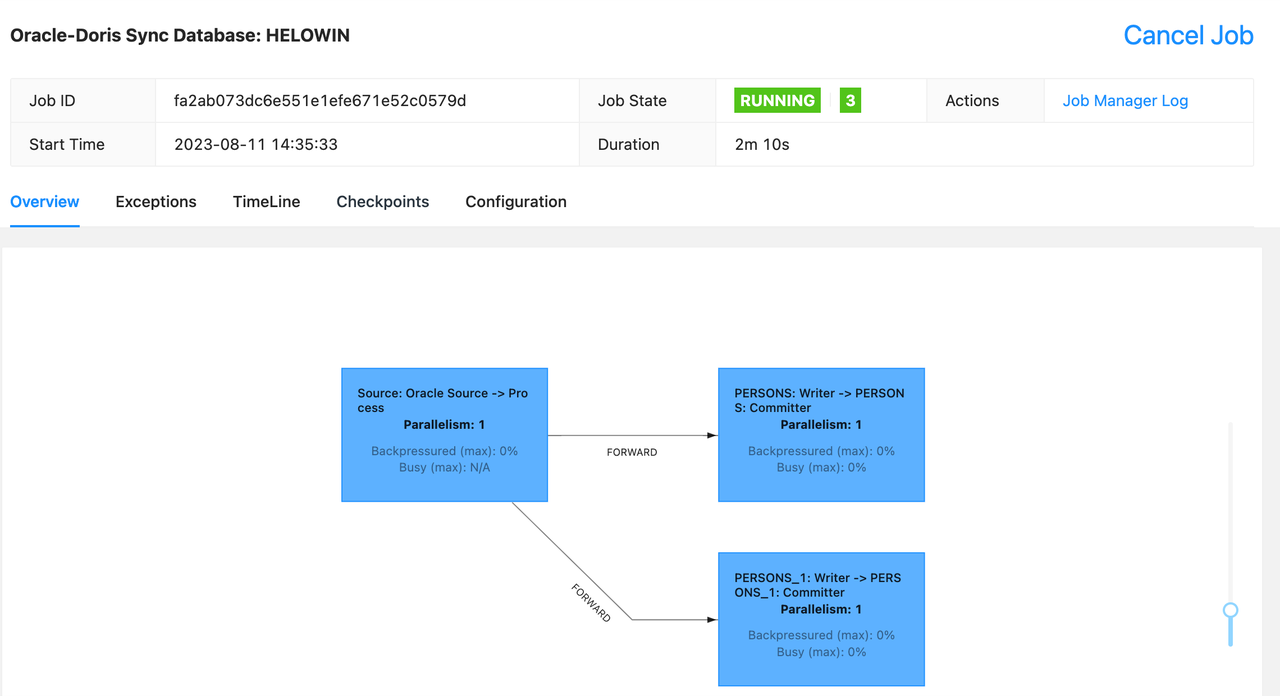
一键实现 Oracle 数据整库同步至 Apache Doris
在实时数据仓库建设或迁移的过程中,用户必须考虑如何高效便捷将关系数据库数据同步到实时数仓中来,Apache Doris 用户也面临这样的挑战。而对于从 Oracle 到 Doris 的数据同步,通常会用到以下两种常见的同步方式: OGG/XStream/Lo…...

Z-Image-Turbo_Sugar脸部Lora效果增强:ControlNet+Lora联合调控Sugar脸部结构
Z-Image-Turbo_Sugar脸部Lora效果增强:ControlNetLora联合调控Sugar脸部结构 想生成那种又纯又欲、甜度爆表的Sugar风格脸部图片吗?是不是经常遇到模型生成的脸型不够精致、五官比例失调,或者风格不够统一的问题?今天,…...

【Serverless架构生死线】:Java函数冷启动超时率>17%?2024最新CNCF基准测试下的3层防御体系构建
第一章:Serverless架构下Java函数冷启动的生死挑战在Serverless平台(如AWS Lambda、阿里云函数计算、腾讯云SCF)中,Java函数因JVM初始化、类加载、字节码验证及Spring等框架启动开销,常面临数百毫秒至数秒级的冷启动延…...
)
别再说‘差不多’了!搞懂PPM,你的数字电路时钟才算真的稳了(附计算器)
别再说‘差不多’了!搞懂PPM,你的数字电路时钟才算真的稳了(附计算器) 在数字电路设计中,时钟信号如同人体的心跳,其稳定性直接决定了整个系统的可靠性。然而,许多工程师在面对"PPM"这…...

Flutter Gradle插件迁移指南:从apply script到声明式plugins的实践
1. 为什么需要迁移到声明式plugins块 最近在维护一个Flutter项目时,我发现每次构建Android端都会弹出一个黄色警告:"You are applying Flutters app_plugin_loader Gradle plugin imperatively using the apply script method..."。这个警告看…...

元素偏析系数计算:从概念到实际应用
元素偏析系数计算(Pandat代算或自己操作) 实例32: 偏析系数k是指在熔体凝固过程中,溶质元素在固相和液相中浓度的比值。 通过计算偏析系数,可以预测在凝固过程中某一溶质元素的分布情况,从而帮助设计合金的微观组织结构。 偏析系数 k1 则倾向…...

墨语灵犀效果展示:康沃尔语复兴运动口号→中文新文化运动风格译文
墨语灵犀效果展示:康沃尔语复兴运动口号→中文新文化运动风格译文 1. 翻译效果惊艳呈现 墨语灵犀作为一款融合古典美学与现代AI技术的深度翻译工具,在语言转换过程中展现出令人惊叹的文化适应能力。本次展示以康沃尔语复兴运动口号为源文本,…...

三步打造清爽Mac菜单栏:Dozer终极隐藏方案
三步打造清爽Mac菜单栏:Dozer终极隐藏方案 【免费下载链接】Dozer Hide menu bar icons on macOS 项目地址: https://gitcode.com/gh_mirrors/do/Dozer 还在为Mac菜单栏上拥挤不堪的图标感到困扰吗?想要一个简洁高效的工作界面?Dozer正…...
)
从51到STM32:手把手教你用STM32CubeMX和PWM驱动智能小车电机(附代码避坑)
从51到STM32:智能小车电机控制的进阶实战指南 十年前用51单片机做智能小车时,PWM配置需要手动计算定时器重装载值,而今天在STM32CubeMX里勾选几下就能生成精准的PWM信号——这就像从手动挡升级到了自动驾驶。作为过来人,我完整记…...

保姆级教程:深求·墨鉴Podman部署全流程,小白也能轻松搞定
保姆级教程:深求墨鉴Podman部署全流程,小白也能轻松搞定 1. 为什么选择Podman部署深求墨鉴? 传统Docker部署方式虽然常见,但对于深求墨鉴这样的轻量级OCR工具来说,Podman提供了更优雅的解决方案。Podman是一款无需守…...

深度图还能这样用?Metashape导出数据在Unity3D/B3DM格式转换中的妙用
深度图跨界应用:从Metashape到Unity3D的B3DM格式转换实战指南 当摄影测量遇上游戏开发,深度图的价值远不止于三维重建。在Metashape中生成的深度图数据,经过巧妙转换后能在Unity3D中实现令人惊艳的效果。本文将带你探索这条从专业建模软件到…...