Java常见的排序算法
排序分为内部排序和外部排序(外部存储)
常见的七大排序,这些都是内部排序 。

1、插入排序:直接插入排序
1、插入排序:每次将一个待排序的记录,按其关键字的大小插入到前面已排序好的记录序列 中的适当位置,直到全部记录插入完成为止。稳定排序算法
一个排序算法的稳定性与不稳定性是通过排序后相同元素的先后顺序 来判断的。
稳定性:如果排序前后,具有相同关键字的元素的相对顺序没有改变,则排序算法被认为是稳定的。
不稳定性:如果排序前后,具有相同关键字的元素的相对顺序发生了改变,则排序算法被认为是不稳定的。
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后往前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后(这就保证了相同元素的顺序和排序前一样,所以是稳定排序 )
- 重复扫描
2、代码
public class InsertSort {
/**
* <>
* @method: insertSort
* @Param: [arr]
* @Return: void
* @exception:
* @Author: fsy
* @Date: 19-5-29 下午3:50
* @description:
*
*/
public void insertSort(int[] arr){//需要插入的数int insertNum;for (int i=1; i <arr.length ; i++) {insertNum=arr[i];//序列元素个数int j=i-1;//将大于insertNum的元素往后移动while (j>=0&&arr[j]>insertNum){arr[j+1]=arr[j];j--;}//找到位置,插入当前元素arr[j+1]=insertNum;}}
3、复杂度分析
时间复杂度:
- O(n²)
空间复杂度:
- O(1)
4、总结:
插入排序所需的时间取决于输入元素的初始顺序 。对于一个很大且其中的元素已经有序(或接近有序)的数组进行排序将会比随机顺序的数据或是逆序数据进行排序要快的多
2、插入排序:希尔排序
1、希尔排序:希尔排序的本质就是分组插入排序 ,又称缩小增量法。将整个无序序列分割成若干个子序列(由相隔某个“增量”的元素组成)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序时,再对全体元素进行一次直接插入排序 。因为进行直接插入排序时元素基本有序,所以效率是很高的,因此希尔排序在时间效率上有很大提高。希尔排序是不稳定排序算法
2、代码
public void shellSort(int[] d) { //d[]为增量数组RecordNode temp;int i, j;System.out.println("希尔排序");//控制增量,增量减半,若干趟扫描for (int k = 0; k < d.length; k++) {//一趟中若干子表,每个记录在自己所属子表内进行直接插入排序int dk = d[k];for (i = dk; i < this.curlen; i++) {temp = r[i];for (j = i - dk; j >= 0 && temp.key.compareTo(r[j].key) < 0; j -= dk) {r[j + dk] = r[j];}r[j + dk] = temp;}System.out.print("增量dk=" + dk + " ");}
}
3、复杂度分析
时间复杂度:
- O(nlog2 n)
空间复杂度:
- O(1)
4、总结
希尔排序更高效是因为它权衡了子数组的规模和有序性。排序之初,各个子数组都很短,排序之后子数组都是部分有序的,这两种情况都很适合插入排序
3、选择排序:简单选择排序
1、选择排序:工作原理如下。首先在未排序序列中找到最小(大)元素,存放在排序序列的初始位置。然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序列的末尾,以此类推,直到所有元素排序完毕。选择排序的主要优点是与数据移动有关,如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序最多n-1次交换。不稳定排序
2、代码:
public static void sort(int[] a) {for (int i = 0; i < a.length; i++) {int min = i;//选出之后待排序中值最小的位置for (int j = i + 1; j < a.length; j++) {if (a[j] < a[min]) {min = j;}}//最小值不等于当前值时进行交换if (min != i) {int temp = a[i];a[i] = a[min];a[min] = temp;}}
}
3、复杂度分析
时间复杂度:
- O(n²)
空间复杂度:
- O(1)
4、总结
选择排序非常简单和直观,但是也非常慢。无论是哪种情况,哪怕原数组已经排序完成,它也将花费将近n²/2次遍历来确认一遍。它的排序结果也是不稳定的。不耗费额外的内存空间
4、选择排序:堆排序
1、堆的定义如下:n个元素的序列(k1,k2,… ,kn)
当且仅当满足下列关系时,称之为堆
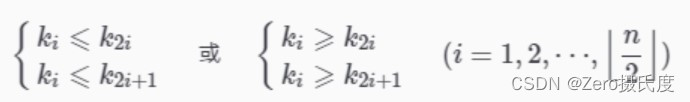
把此序列对应的二维数组看成是一个完全二叉树,那么堆的含义就是:完全二叉树中任何一个非叶子节点的值均不大于(或不小于)其左、右孩子节点的值 。由上述性质可知,大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。因此我们可以使用大顶堆进行升序排序,使用小顶堆进行降序排序。不稳定排序
基本思想:以大顶堆为例,堆排序的过程就是将待排序的序列构造成一个堆,选出堆中最大的移走,再把剩余的元素调整成堆,找出最大的再移走,重复直至有序
2、代码
/*** @param a*/
public static void sort(int[] a) {for (int i = a.length - 1; i > 0; i--) {max_heapify(a, i);//堆顶元素(第一个元素)与Kn交换int temp = a[0];a[0] = a[i];a[i] = temp;}
}/***** 将数组堆化* i = 第一个非叶子节点。* 从第一个非叶子节点开始即可。无需从最后一个叶子节点开始。* 叶子节点可以看作已符合堆要求的节点,根节点就是它自己且自己以下值为最大。** @param a* @param n*/
public static void max_heapify(int[] a, int n) {int child;for (int i = (n - 1) / 2; i >= 0; i--) {//左子节点位置child = 2 * i + 1;//右子节点存在且大于左子节点,child变成右子节点if (child != n && a[child] < a[child + 1]) {child++;}//交换父节点与左右子节点中的最大值if (a[i] < a[child]) {int temp = a[i];a[i] = a[child];a[child] = temp;}}
}3、复杂度分析
时间复杂度:O(nlog₂ n)
空间复杂度:O(1)
4、总结
由于堆排序中初始化堆的过程比较次数较多,因此不太使用于小序列 。由于多次任意下标相互交换位置,相同元素之间原本相对的顺序被破坏了,是不稳定排序。
5、交换排序:冒泡排序
1、冒泡排序:是一种简单排序。重复地走访过要排序的元素,一次比较两个元素,如果他们的顺序错误就把他们交换过来,走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。只在顺序不符合大小要求时交换,所以不会破坏相同元素间的顺序,因此是稳定排序
- 比较相邻的元素,如果第一个比第二个大,就交换他们两个
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对,这步做完,最后的元素会是最大的数
- 针对所有的元素重复以上的步骤,除了最后一个
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
2、代码
public static void sort(int[] a) {//外层循环控制比较的次数for (int i = 0; i < a.length - 1; i++) {//内层循环控制到达位置for (int j = 0; j < a.length - i - 1; j++) {//前面的元素比后面大就交换if (a[j] > a[j + 1]) {int temp = a[j];a[j] = a[j + 1];a[j + 1] = temp;}}}
}3、复杂度分析
时间复杂度:
- 最好:O(n)
- 最坏:O(n²)
- 平均时间复杂度:O(n²)
空间复杂度:O(1)
4、总结:
是稳定的排序算法。
6、交换排序:快速排序
1、快速排序:使用分治法策略来把一个串行分为两个子串行。通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。不稳定排序算法
2、代码
public static void sortByStack(int[] a) {Stack<Integer> stack = new Stack<Integer>();//初始状态的左右指针入栈stack.push(0);stack.push(a.length - 1);while (!stack.isEmpty()) {//出栈进行划分int high = stack.pop();int low = stack.pop();int pivotIndex = partition(a, low, high);//保存中间变量if (pivotIndex > low) {stack.push(low);stack.push(pivotIndex - 1);}if (pivotIndex < high && pivotIndex >= 0) {stack.push(pivotIndex + 1);stack.push(high);}}
}private static int partition(int[] a, int low, int high) {if (low >= high) return -1;int left = low;int right = high;//保存基准的值int pivot = a[left];while (left < right) {//从后向前找到比基准小的元素,插入到基准位置中while (left < right && a[right] >= pivot) {right--;}a[left] = a[right];//从前往后找到比基准大的元素while (left < right && a[left] <= pivot) {left++;}a[right] = a[left];}//放置基准值,准备分治递归快排a[left] = pivot;return left;
}3、复杂度分析
时间复杂度:
- 最好:O(nlog₂ n)
- 最坏:O(n²)
- 平均时间复杂度:O(nlog₂ n)
空间复杂度:O(1)
7、归并排序
1、归并排序:归并排序算法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的,然后再把有序子序列合并为整体有序序列。稳定排序算法
归并排序可通过两种方式实现:
- 自上而下的递归
- 自下而上的迭代
2、(递归的方法)代码
public class Merge {//归并所需的辅助数组private static int[] aux;public static void sort(int[] a) {//一次性分配空间aux = new int[a.length];sort(a, 0, a.length - 1);}public static void sort(int[] a, int low, int high) {if (low >= high) {return;}int mid = (low + high) / 2;//将左半边排序sort(a, low, mid);//将右半边排序sort(a, mid + 1, high);merge(a, low, mid, high);}/*** 该方法先将所有元素复制到aux[]中,然后在归并会a[]中。方法咋归并时(第二个for循环)* 进行了4个条件判断:* - 左半边用尽(取右半边的元素)* - 右半边用尽(取左半边的元素)* - 右半边的当前元素小于左半边的当前元素(取右半边的元素)* - 右半边的当前元素大于等于左半边的当前元素(取左半边的元素)*/public static void merge(int[] a, int low, int mid, int high) {//将a[low..mid]和a[mid+1..high]归并int i = low, j = mid + 1;for (int k = low; k <= high; k++) {aux[k] = a[k];}for (int k = low; k <= high; k++) {if (i > mid) {a[k] = aux[j++];} else if (j > high) {a[k] = aux[i++];} else if (aux[j] < aux[i]) {a[k] = aux[j++];} else {a[k] = aux[i++];}}}}3、复杂度分析
时间复杂度:O(nlog₂n)
空间复杂度:O(n)
4、总结:主要缺点是所需的额外空间和N成正比(N为待排序数组的长度)
8、总结
各种排序性能对比:
| 排序类型 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 |
| 直接插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 折半插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 希尔排序 | O(nlog2 n) | O(nlog2 n) | O(nlog2 n) | O(1) | 不稳定 |
| 归并排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(n) | 稳定 |
| 快速排序 | O(nlog₂n) | O(nlog₂n) | O(n²) | O(nlog₂n) | 不稳定 |
| 堆排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(1) | 不稳定 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 稳定 |
| 桶排序 | O(n+k) | O(n+k) | O(n²) | O(n+k) | (不)稳定 |
| 基数排序 | O(d(n+k)) | O(d(n+k)) | O(d(n+kd)) | O(n+kd) | 稳定 |
稳定:冒泡排序、直接插入排序、归并排序
不稳定:选择排序、希尔排序、快速排序、堆排序
相关文章:
Java常见的排序算法
排序分为内部排序和外部排序(外部存储) 常见的七大排序,这些都是内部排序 。 1、插入排序:直接插入排序 1、插入排序:每次将一个待排序的记录,按其关键字的大小插入到前面已排序好的记录序列 中的适当位置…...

【C++】5、构建:CMake
文章目录 一、概述二、实战2.1 内部构建、外部构建2.2 CLion Cmake 一、概述 CMake 是跨平台构建工具,其通过 CMakeLists.txt 描述,并生成 native 编译配置文件: 在 Linux/Unix 平台,生成 makefile在苹果平台,可以生…...
【ARP欺骗】嗅探流量、限速、断网操作
【ARP欺骗】 什么是ARP什么是ARP欺骗ARP欺骗实现ARP断网限制网速嗅探流量 什么是ARP ARP(Address Resolution Protocol,地址解析协议)是一个TCP/IP协议,用于根据IP地址获取物理地址。在计算机网络中,当一个主机需要发…...

初步认识OSPF的大致内容(第三课)
1 路由的分类 直连路由(Directly Connected Route)是指网络拓扑结构中相邻两个网络设备直接相连的路由,也称为直接路由。如果两个设备属于同一IP网络地址,那么它们就是直连设备。直连路由表是指由计算机系统生成的一种用于路由选择的表格,其中记录着直连路由的信息。直连…...
CSDN编程题-每日一练(2023-08-27)
CSDN编程题-每日一练(2023-08-27) 一、题目名称:异或和二、题目名称:生命进化书三、题目名称:熊孩子拜访 一、题目名称:异或和 时间限制:1000ms内存限制:256M 题目描述: …...

机器视觉之平面物体检测
平面物体检测是计算机视觉中的一个重要任务,它通常涉及检测和识别在图像或视频中出现的平面物体,如纸张、标志、屏幕、牌子等。下面是一个使用C和OpenCV进行平面物体检测的简单示例,使用了图像中的矩形轮廓检测方法: #include &l…...
C#开发WinForm之DataGridView开发
前言 DataGridView是开发Winform的一个列表展示,类似于表格。学会下面的基本特征用法,再辅以经验,基本功能开发没问题。 1.设置 DataGridView表格行首为序号索引, //设置 DataGridView表格行首为序号索引private void dataGridView1_RowPost…...
PDFPrinting.Net Crack
PDFPrinting.Net Crack 它能够轻松灵活地预测完美的打印结果以及用户文件的示例性显示。在.NET的PDF打印中,可以快速浏览最关键的元素。如果用户需要获得更详细的概述,那么他可以查看快速入门手册,甚至现有文档的详细概述参考。 在这种情况下…...
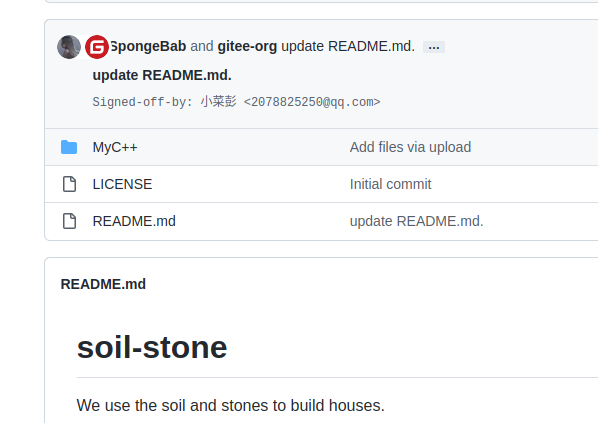
git操作:将一个仓库的分支提交到另外一个仓库分支
这个操作,一般是同步不同网站的同个仓库,比如说gitee 和github。某个网站更新了,你想同步他的分支过来。然后基于分支开发或者其它。 操作步骤 1.本地先clone 你自己的仓库。也就是要push 分支的仓库。比如A仓库,把B仓库分支&am…...
基于Java+SpringBoot+Vue前后端分离医院资源管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
Android——基本控件下(十七)
1. 文本切换:TextSwitcher 1.1 知识点 (1)理解TextSwitcher和ViewFactory的使用。 1.2 具体内容 范例:切换显示当前时间 <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"xmlns:tools&…...
HCIP-HCS华为私有云
1、概述 HCS(HuaweiCoudStack)华为私有云:6.3 之前叫FusionSphere OpenStack,6.3.1 版本开始叫FusionCloud,6.5.1 版本开始叫HuaweiCloud Stack (HCS)华为私有云软件。 开源openstack,发放云主机的流程&am…...

docker下载github项目失败
Docker 在构建过程中直接从 GitHub 下载项目时超时,可能是由于网络问题、GitHub 访问限制或其他原因导致的。以下是一些建议和解决方法: 预先下载项目: 在构建 Docker 镜像之前,首先在宿主机上手动克隆 GitHub 项目,然后使用 COPY…...
【CSS】网站 网格商品展示 模块制作 ( 清除浮动需求 | 没有设置高度的盒子且内部设置了浮动 | 使用双伪元素清除浮动 )
一、清除浮动需求 ( 没有设置高度的盒子且内部设置了浮动 ) 绘制的如下模块 : 在上面的盒子中 , 没有设置高度 , 只设置了一个 1215px 的宽度 ; 在列表中每个列表项都设置了 浮动 ; /* 网格商品展示 */ .box-bd {/* 处理列表间隙导致意外换行问题一排有 5 个 228x270 的盒子…...

文本分类任务
文章目录 引言1. 文本分类-使用场景2. 自定义类别任务3. 贝叶斯算法3.1 预备知识3.2 贝叶斯公式3.3 贝叶斯公式的应用3.4 贝叶斯公式在NLP中的应用3.5 贝叶斯公式-文本分类3.6 代码实现3.7 贝叶斯算法的优缺点 4. 支持向量机4.1 支持向量机-核函数4.2 支持向量机-解决多分类4.3…...
:Python中的pyecharts库绘制3D曲面图)
Pyecharts教程(一):Python中的pyecharts库绘制3D曲面图
Pyecharts教程(一):Python中的pyecharts库绘制3D曲面图 作者:安静到无声 个人主页 目录 Pyecharts教程(一):Python中的pyecharts库绘制3D曲面图实验结果推荐专栏在Python中,我们可以使用pyecharts库来绘制各种图表,如柱状图、折线图、饼图等。最近,我在学习如何使用pyec…...

Unity音频基础概念
一、音源与音频侦听器 游戏画面能够被观众看到,是因为有渲染器和摄像机,同样音频能够被听到,也要有声音的发出者与声音的接收者。声音的发出者叫做音源,接收者叫做音频侦听器。Audio Source与Audio Listener都是组件,…...

sklearn Preprocessing 数据预处理功能
scikit-learn(或sklearn)的数据预处理模块提供了一系列用于处理和准备数据的工具。这些工具可以帮助你在将数据输入到机器学习模型之前对其进行预处理、清洗和转换。以下是一些常用的sklearn.preprocessing模块中的类和功能: 1. 数据缩放和中…...
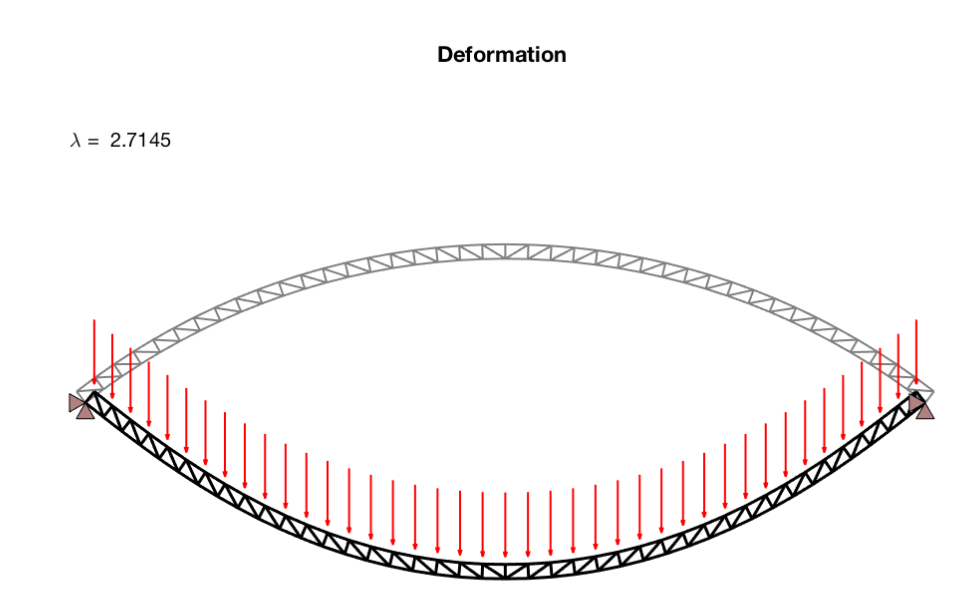
创建和分析二维桁架和梁结构研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
SpringBoot实现文件上传和下载笔记分享(提供Gitee源码)
前言:这边汇总了一下目前SpringBoot项目当中常见文件上传和下载的功能,一共三种常见的下载方式和一种上传方式,特此做一个笔记分享。 目录 一、pom依赖 二、yml配置文件 三、文件下载 3.1、使用Spring框架提供的下载方式 3.2、通过IOUti…...

OptiLLM性能基准测试:在AIME、IMO、LiveCodeBench上的惊人表现
OptiLLM性能基准测试:在AIME、IMO、LiveCodeBench上的惊人表现 【免费下载链接】optillm Optimizing inference proxy for LLMs 项目地址: https://gitcode.com/gh_mirrors/op/optillm OptiLLM是一款强大的AI推理优化代理工具,能够在零训练的情况…...

OpenClaw隐私增强:nanobot本地模型处理敏感财务数据
OpenClaw隐私增强:nanobot本地模型处理敏感财务数据 1. 为什么选择本地模型处理财务数据 去年我在帮朋友的小公司整理年度财报时,遇到了一个棘手的问题:他们使用的在线财务分析工具要求上传完整的Excel报表到云端服务器。虽然服务商承诺数据…...
)
LangChain详解:大模型应用开发框架(通俗理解+专业解析+Python实战)
LangChain详解:大模型应用开发框架(通俗理解专业解析Python实战) 摘要:随着大语言模型(LLM)的普及,单纯调用模型API已无法满足复杂业务需求——如何让大模型“记住”对话历史、“调用”外部工具…...

生成式 AI 赋能下钓鱼攻击的技术异化与防御体系构建
摘要 生成式人工智能在文本创作、语义理解与内容生成领域的快速落地,在提升生产效率的同时,也被不法分子用于网络钓鱼攻击的智能化升级。路透社与哈佛大学联合测试显示,主流大语言模型在特定提示词绕过机制下可生成高仿真钓鱼邮件,…...
多人对话录音整理神器:ClearerVoice-Studio语音分离功能详细教程
多人对话录音整理神器:ClearerVoice-Studio语音分离功能详细教程 1. 引言:告别混乱的多人录音 你是否经常需要整理会议录音、访谈记录或多人讨论内容?传统的录音文件往往混杂着多个人的声音,背景噪音干扰严重,整理起…...
)
Windows系统管理员必备:LastActivityView详细使用指南(含数据导出技巧)
Windows系统管理员必备:LastActivityView深度实战手册 作为Windows系统管理员,我们常常需要追踪用户活动、排查异常行为或进行合规审计。市面上虽然有不少商业监控工具,但NirSoft出品的LastActivityView以其轻量高效、数据全面且完全免费的特…...

电动汽车车队虚拟发电厂的强化学习控制策略探索
电动汽车车队虚拟发电厂的强化学习控制策略 本论文基于 RL 代理的开发,该代理通过家庭环境中的电动汽车充电站管理 VPP。 VPP 的主要优化目标是:填谷、削峰和随时间推移实现零负荷(供需负荷平衡)。 为实现目标而采取的主要行动是&…...

华为交换机-跨Vlan通信的实战配置指南
1. 华为交换机跨VLAN通信的核心原理 第一次接触跨VLAN通信时,我也被那些专业术语搞得一头雾水。直到把整个流程拆解成生活场景,才真正理解其中的奥妙。想象一下,VLAN就像公司里的不同部门,财务部、技术部、市场部各自在独立的办公…...

硬件医生养成记:用SMUDebugTool守护AMD Ryzen系统健康
硬件医生养成记:用SMUDebugTool守护AMD Ryzen系统健康 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

程序员成长之路:从技术热爱到工程艺术
1. 程序人生:从技术热爱到工程艺术1.1 技术启蒙与早期实践1987年进入武汉大学计算机系标志着一段技术人生的开始。最初接触的是Motorola 68000处理器系统,配置540KB内存,运行UNIX操作系统。这种八人共享的计算环境成为编程技术的第一课堂。大…...