2023年高教社杯 国赛数学建模思路 - 复盘:校园消费行为分析
文章目录
- 0 赛题思路
- 1 赛题背景
- 2 分析目标
- 3 数据说明
- 4 数据预处理
- 5 数据分析
- 5.1 食堂就餐行为分析
- 5.2 学生消费行为分析
- 建模资料
0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到 11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3 数据说明
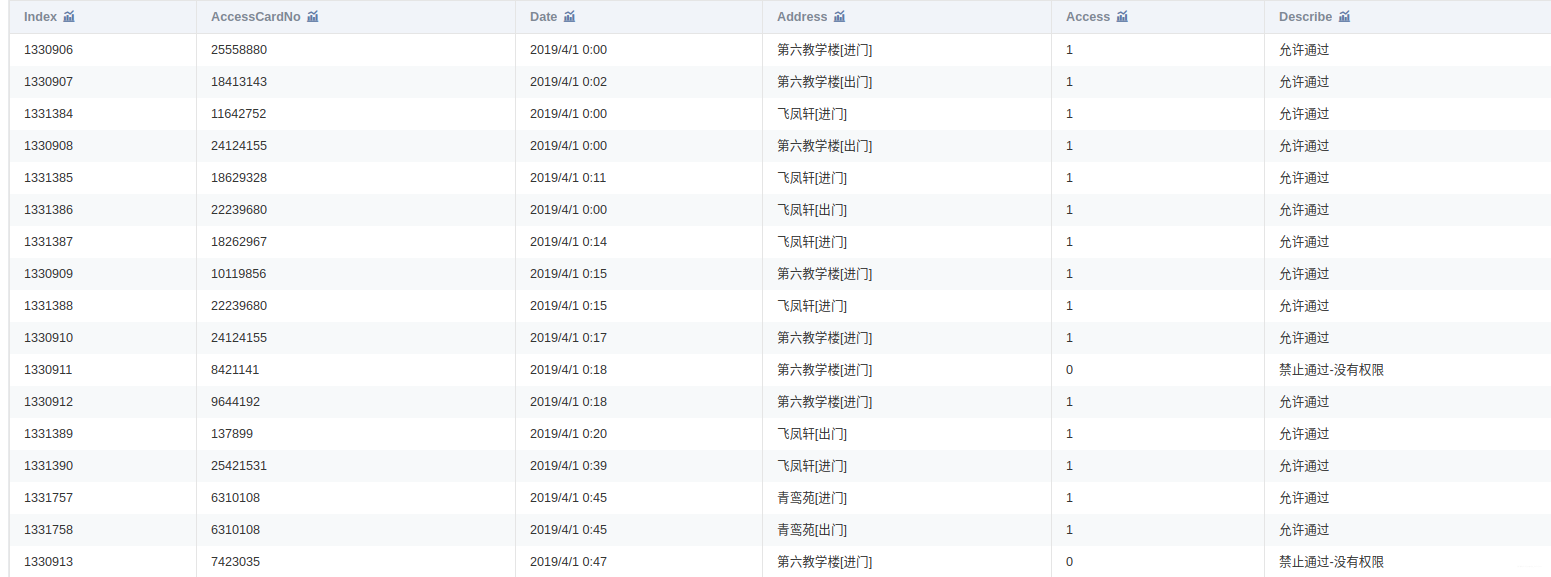
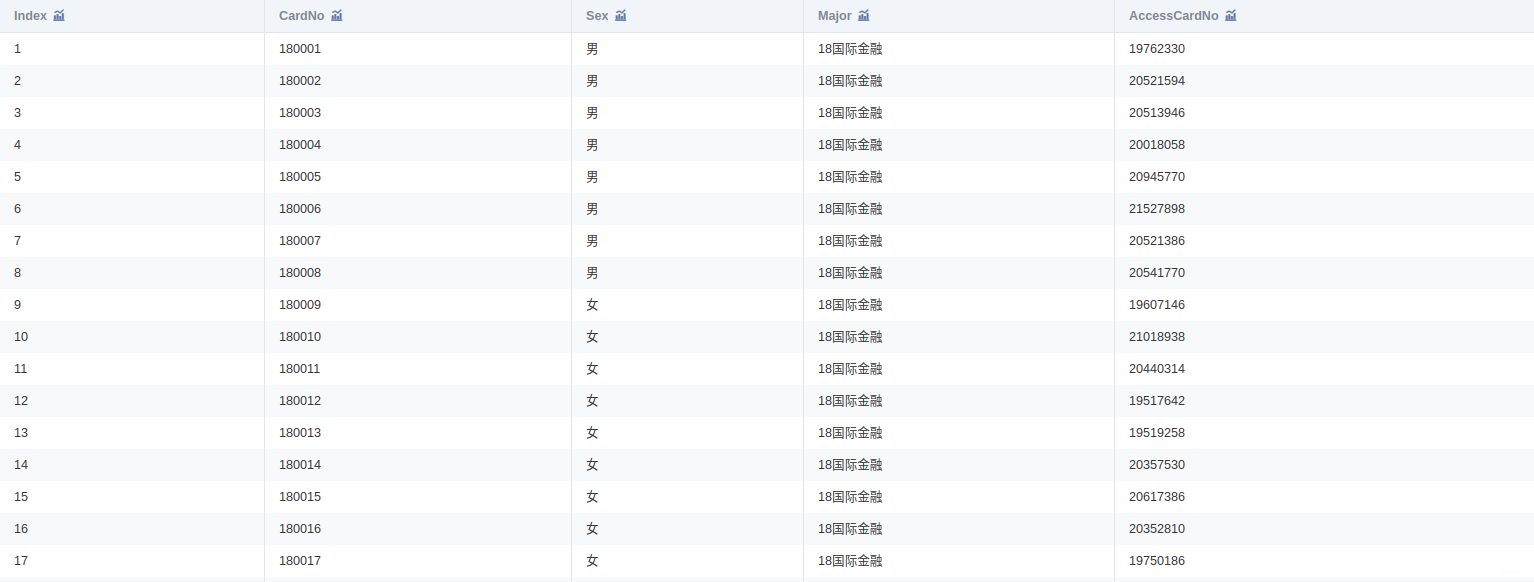
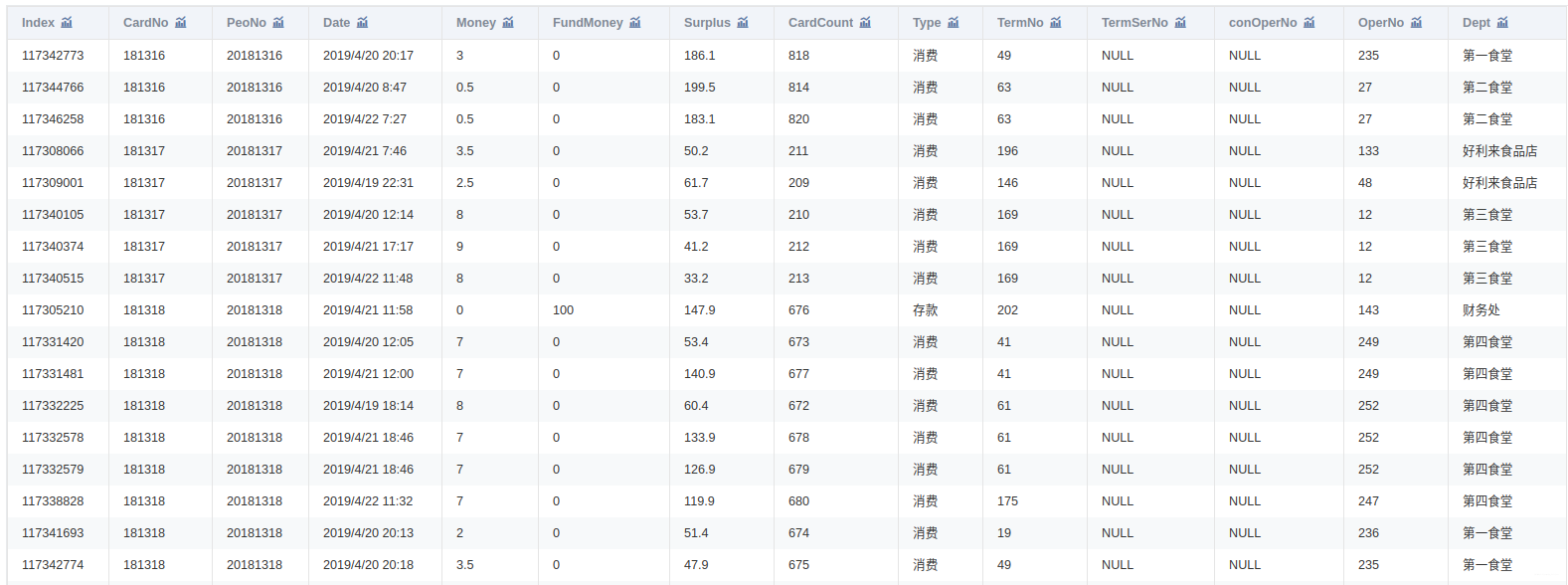
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
4 数据预处理
将附件中的 data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从 1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
data1.head(3)
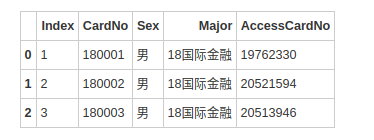
data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']
data1.dtypes

data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)

将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5 数据分析
5.1 食堂就餐行为分析
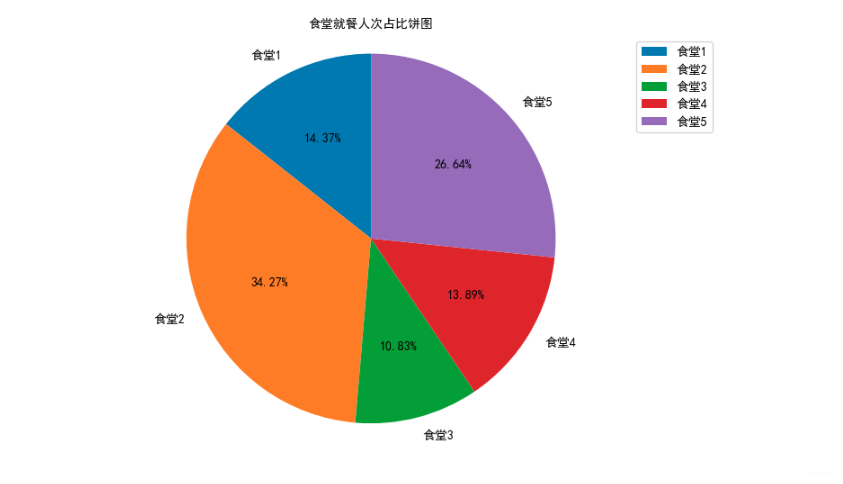
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消费地点'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消费地点'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消费地点'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消费地点'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消费地点'].apply(str).str.contains('第五食堂').sum()
# 绘制饼图
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
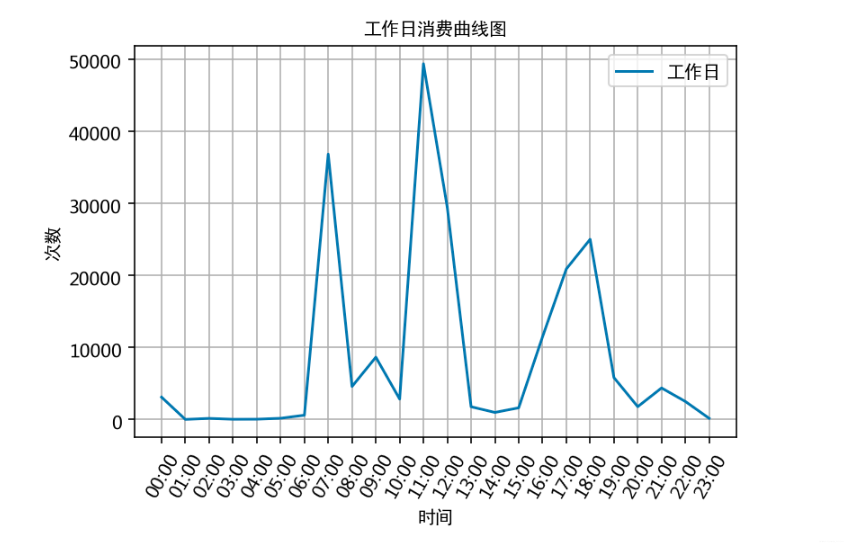
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。

# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,'消费时间'] = pd.to_datetime(data.loc[:,'消费时间'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data['消费星期'] = data['消费时间'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,'消费星期'] <= 5
unwork_day_query = data.loc[:,'消费星期'] > 5work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):work_day_times.append(work_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):x.append('{:02d}:00'.format(i))
# 绘图
plt.plot(x, work_day_times, label='工作日')
# x,y轴标签
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
# 标题
plt.title('工作日消费曲线图', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):unwork_day_times.append(unwork_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24): x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
plt.title('非工作日消费曲线图', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
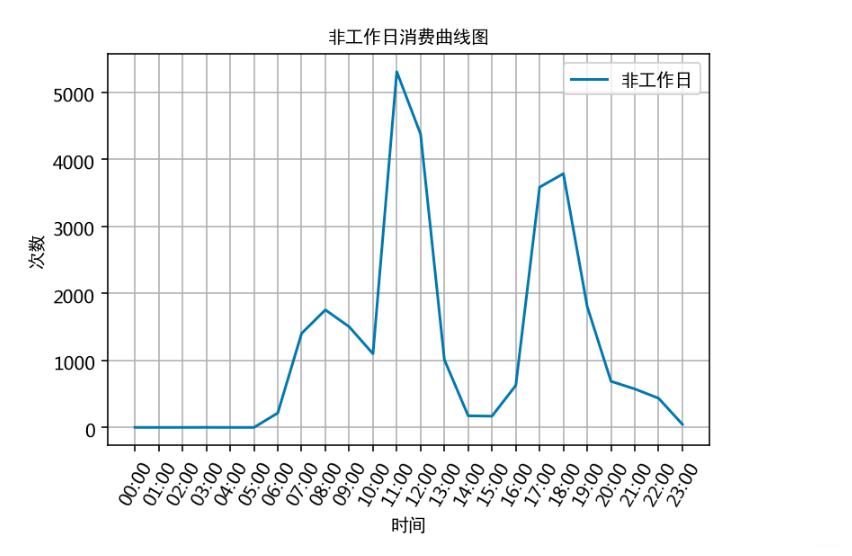
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data['消费时间'].count()
student_count = data['校园卡号'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data['消费金额'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money# 选择消费次数最多的3个专业进行分析
data['专业名称'].value_counts(dropna=False)
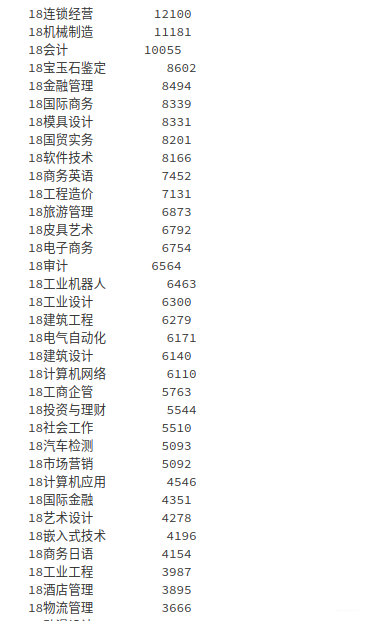
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data['专业名称'].apply(str).str.contains('18连锁经营')
major2 = data['专业名称'].apply(str).str.contains('18机械制造')
major3 = data['专业名称'].apply(str).str.contains('18会计')
major4 = data['专业名称'].apply(str).str.contains('18机械制造(学徒)')data_new = data[(major1 | major2 | major3) ^ major4]
data_new['专业名称'].value_counts(dropna=False)分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new['性别'] == '男']
data_female = data_new[data_new['性别'] == '女']
data_female.head()
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data['专业名称'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[['校园卡号','性别']].drop_duplicates().reset_index(drop=True)
data_1['性别'] = data_1['性别'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校园卡号'], inplace=True)
data_2 = data.groupby('校园卡号').sum()[['消费金额']]
data_2.columns = ['总消费金额']
data_3 = data.groupby('校园卡号').count()[['消费时间']]
data_3.columns = ['总消费次数']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + ['类别数目']# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby('校园卡号').sum()[['消费金额']]
data_500.sort_values(by=['消费金额'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校园卡号'].isin(data_500_index)]
data_500.head(10)
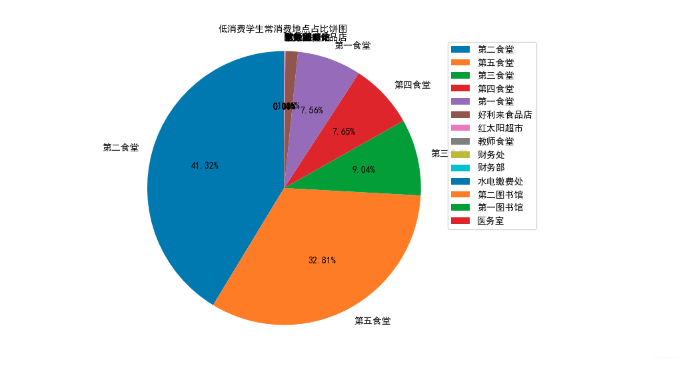
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
建模资料
资料分享: 最强建模资料


相关文章:
2023年高教社杯 国赛数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

7.Oracle视图创建与使用
1、视图的创建与使用 在所有进行的SQL语句之中,查询是最复杂的操作,而且查询还和具体的开发要求有关,那么在开发过程之中,程序员完成的并不是是和数据库的所有内容,而更多的是应该考虑到程序的设计结构。可以没有一个项…...

rust学习-不安全操作
在 Rust 中,不安全代码块用于避开编译器的保护策略 四种不安全操作 解引用裸指针通过 FFI (Foreign Function Interface,外部语言函数接口)调用函数调用不安全的函数内联汇编(inline assembly)解引用裸指针 原始指针(raw pointer,裸指针)* 和引用 &T 有类似的功…...
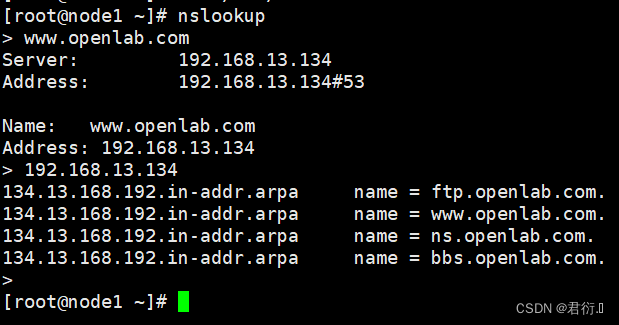
RHCE——八、DNS域名解析服务器
RHCE 一、概述1、产生原因2、作用3、连接方式4、因特网的域名结构4.1 拓扑4.2 分类4.3 域名服务器类型划分 二、DNS域名解析过程1、分类2、解析图:2.1 图:2.2 过程分析 三、搭建DNS域名解析服务器1、概述2、安装软件3、/bind服务中三个关键文件4、配置文…...

flink cdc初始全量速度很慢原因和优化点
link cdc初始全量速度很慢的原因之一是,它需要先读取所有的数据,然后再写入到目标端,这样可以保证数据的一致性和顺序。但是这样也会导致数据的延迟和资源的浪费。flink cdc初始全量速度很慢的原因之二是,它使用了Debezium作为捕获…...
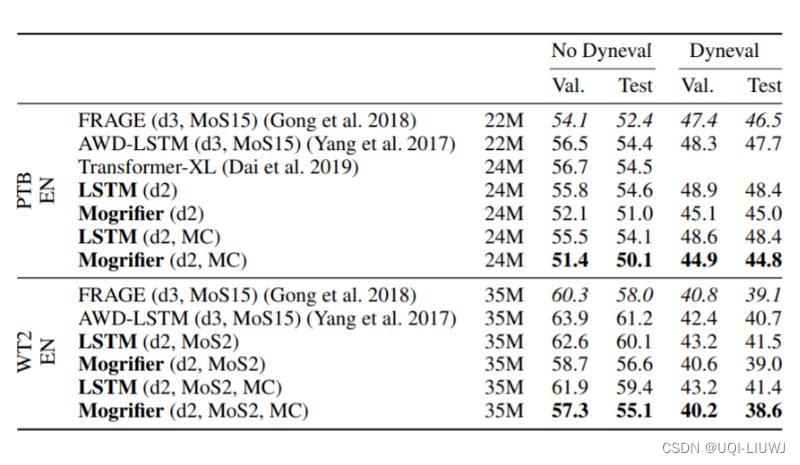
论文笔记: MOGRIFIER LSTM
2020 ICLR 修改传统LSTM 当前输入和隐藏状态充分交互,从而获得更佳的上下文相关表达 1 Mogrifier LSTM LSTM的输入X和隐藏状态H是完全独立的 机器学习笔记:GRU_gruc_UQI-LIUWJ的博客-CSDN博客这篇论文想探索,如果在输入LSTM之前…...

Angular中使用drag and drop实现文件拖拽上传,及flask后端接收
效果:拖拽文件到组件上面时 边框变大变红 松手后发送到服务器(或者点击蓝字手动选择文件)并且把文件名显示在框内,美化还没做 html <div class"drapBox"><div id"drop" (dragenter)"dragenter($event)" (dragov…...

Spring Authorization Server入门 (十六) Spring Cloud Gateway对接认证服务
前言 之前虽然单独讲过Security Client和Resource Server的对接,但是都是基于Spring webmvc的,Gateway这种非阻塞式的网关是基于webflux的,对于集成Security相关内容略有不同,且涉及到代理其它微服务,所以会稍微比较麻…...
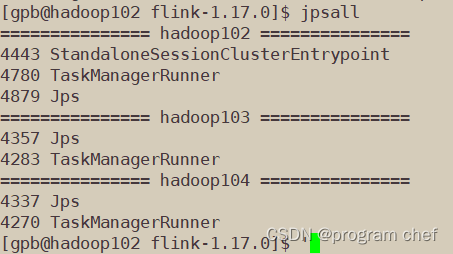
配置Flink
配置flink_1.17.0 1.Flink集群搭建1.1解压安装包1.2修改集群配置1.3分发安装目录1.4启动集群、访问Web UI 2.Standalone运行模式3.YARN运行模式4.K8S运行模式 1.Flink集群搭建 1.1解压安装包 链接: 下载Flink安装包 解压文件 [gpbhadoop102 software]$ tar -zxvf flink-1.1…...
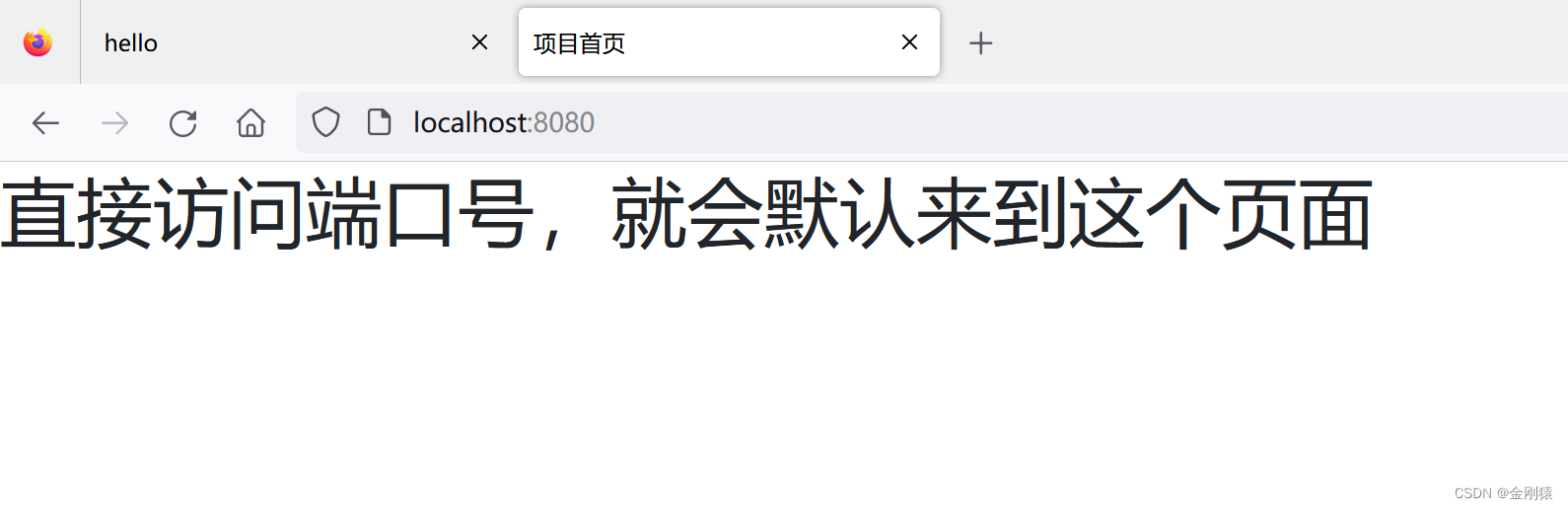
39、springboot的前端静态资源的WebJar支持(bootstrap、jquery等)及自定义图标和首页
★ WebJar支持 Spring Boot支持加载WebJar包中的静态资源(图片、JS、CSS), WebJar包中的静态资源都会映射到/webjars/**路径。——这种方式下,完全不需要将静态资源复制到应用的静态资源目录下。只要添加webjar即可。假如在应用的…...

【图论】缩点的综合应用(一)
一.缩点的概念 缩点,也称为点缩法(Vertex Contraction),是图论中的一种操作,通常用于缩小图的规模,同时保持了图的某些性质。这个操作的目标是将图中的一些节点合并为一个超级节点,同时调整相关…...

C++—纯虚函数
一、前言 定义一个函数为虚函数,不代表函数为不被实现的函数。 定义函数为虚函数是为了允许用基类的指针来调用子类的这个函数。 定义一个函数为纯虚函数,才代表函数没有被实现。 定义纯虚函数是为了实现一个接口,起到一个规范的作用&…...

经过卷积神经网络之后的图片的尺寸如何计算
经过卷积神经网络(Convolutional Neural Network,CNN)处理后,图片的尺寸会发生变化,这是由于卷积层、池化层等操作引起的。计算图片经过卷积神经网络后的尺寸变化通常需要考虑卷积核大小、步幅(stride&…...
,修改maven)
Java升级JDK17(更高版本同理),修改maven
记住三个网址就行:下面这个是oracle的 Java Platform, Standard Edition 17 ReferenceImplementations https://www.oracle.com/java/technologies/downloads/#jdk17-windows 另外一个 redhat旗下的:这个是开源的(推荐这个!&am…...
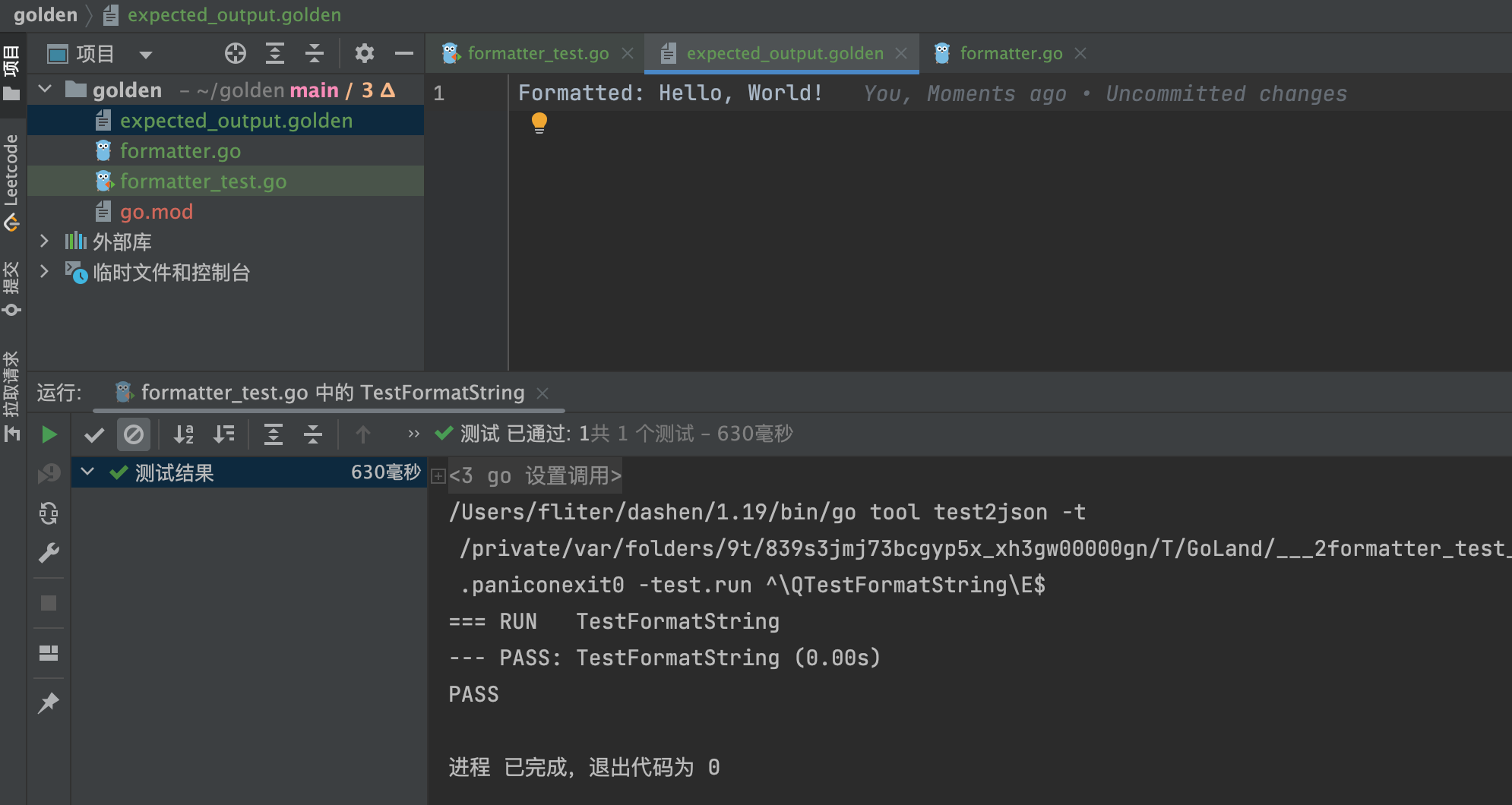
Go测试之.golden 文件
Go测试中的.golden 文件是干什么用的?请举例说明 在Go语言中,.golden文件通常用于测试中的黄金文件(golden files)。黄金文件是在测试期间记录预期输出结果的文件。测试用例运行时,黄金文件用于比较实际输出与预期输出…...

回归预测 | MATLAB实现GA-RF遗传算法优化随机森林算法多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现GA-RF遗传算法优化随机森林算法多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现GA-RF遗传算法优化随机森林算法多输入单输出回归预测(多指标,多图)效果一览基本介绍程…...
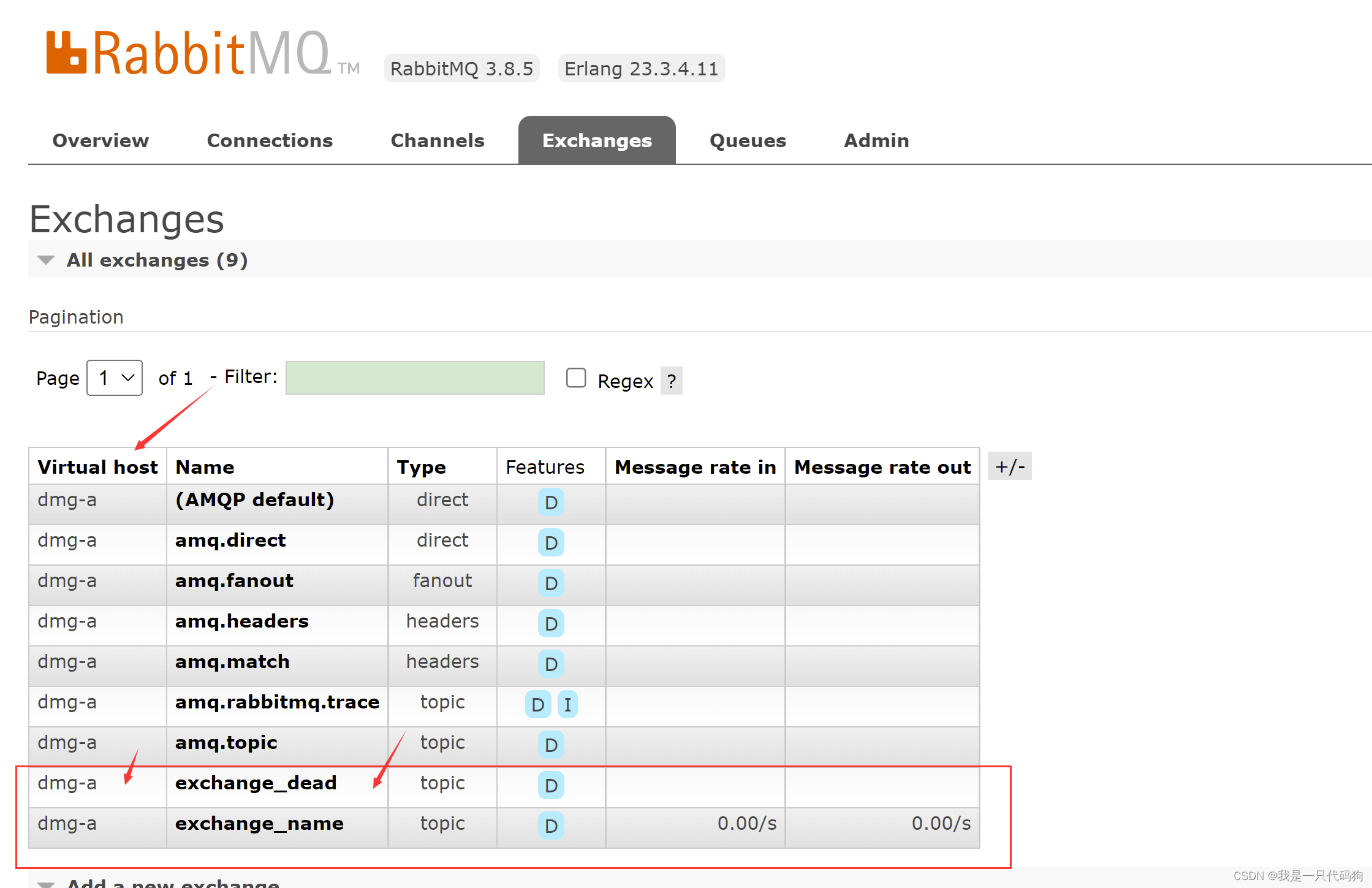
springboot整合rabbitmq死信队列
springboot整合rabbitmq死信队列 什么是死信 说道死信,可能大部分观众大姥爷会有懵逼的想法,什么是死信?死信队列,俗称DLX,翻译过来的名称为Dead Letter Exchange 死信交换机。当消息限定时间内未被消费,…...
高中信息技术教资考试模拟卷(22下)
2022 年下半年全国教师资格考试模考卷一 (高中信息技术) 一、单项选择题(本大题共 15 小题,每小题 3 分,共 45 分) 1.2006 年 10 月 25 日,深圳警方成功解救出一名被网络骗子孙某…...

Linux中shadow及passwd格式内容解析
/etc/passwd文件包括Linux账号信息,示例如下: root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin 具体格式 用户名࿱…...

计算机视觉 – Computer Vision | CV
计算机视觉为什么重要? 人的大脑皮层, 有差不多 70% 都是在处理视觉信息。 是人类获取信息最主要的渠道,没有之一。 在网络世界,照片和视频(图像的集合)也正在发生爆炸式的增长! 下图是网络上…...

5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南
5分钟快速上手PptxGenJS:用JavaScript轻松生成专业PPT的完整指南 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 你…...

构建毫秒级实时传输系统:基于flv.js的低延迟架构优化方案
构建毫秒级实时传输系统:基于flv.js的低延迟架构优化方案 【免费下载链接】flv.js HTML5 FLV Player 项目地址: https://gitcode.com/gh_mirrors/fl/flv.js flv.js作为HTML5 FLV播放器的核心技术方案,通过Media Source Extensions实现浏览器端FLV…...

Loop习惯追踪:从零开始构建你的长期习惯养成系统
Loop习惯追踪:从零开始构建你的长期习惯养成系统 【免费下载链接】uhabits Loop Habit Tracker, a mobile app for creating and maintaining long-term positive habits 项目地址: https://gitcode.com/gh_mirrors/uh/uhabits 你是否曾下定决心培养一个好习…...

“面”之跃升:系统化协同的演进与企业级智能体
展望2026 年,AI 能力的演进或将正式迈入“面”的维度。这是一种“系统化协同”,意味着AI 与企业核心IT 系统、组织架构以及外部生态实现了深度融合。 系统化协同的特征,从 “面”的层级看,AI 不再是一个外挂的工具或独立的流程&am…...

MTKClient实用指南:三步解锁联发科设备的终极解决方案
MTKClient实用指南:三步解锁联发科设备的终极解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科芯片设备设计的开源逆向工程与刷机工具&#x…...

从“能用”到“可靠”:基于SonarQube与Jenkins的代码质量防线构建实战
当测试覆盖率不再只是一串数字,而是合并代码前的“一票否决权” 1. 为什么你的“质量门禁”只是个摆设? 在很多团队的CI/CD流水线中,SonarQube的集成往往停留在“能跑就行”的阶段。流水线里确实有代码扫描这一步,日志里也打印出…...

2026年市面上的培训机构管理系统对比,谁才是性价比之王
教务是培训机构的 “心脏”,而排课是教务最核心、最耗时、最容易出错的环节。传统人工排课:打开 Excel,手动填教师、教室、学员、时间,反复核对冲突,排一周课表要 1–3 天,还经常出现:老师时间撞…...

基于MCP协议的Kubernetes智能运维助手:lazymac-k-mcp项目详解
1. 项目概述:一个为Kubernetes而生的MCP服务器如果你和我一样,日常工作中有一大半时间都在和Kubernetes集群打交道,那么你肯定对kubectl命令行工具又爱又恨。爱的是它功能强大,是操作K8s的瑞士军刀;恨的是它命令繁多&a…...
)
DeepSeek Mesh可观测性体系构建:1个Prometheus+3类自定义指标+7类黄金信号告警模板(附YAML源码)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Mesh可观测性体系全景概览 DeepSeek Mesh 是面向大规模 AI 模型推理服务的云原生服务网格,其可观测性体系并非简单叠加监控指标,而是围绕模型生命周期、推理链路与资源…...

Fooocus终极指南:零门槛AI图像生成神器,5分钟从安装到创作
Fooocus终极指南:零门槛AI图像生成神器,5分钟从安装到创作 【免费下载链接】Fooocus Focus on prompting and generating 项目地址: https://gitcode.com/GitHub_Trending/fo/Fooocus 在AI图像生成领域,复杂的技术参数和繁琐的调整过程…...