提升Java开发效率:掌握HashMap的常见方法与基本原理
文章目录
- 前言
- 一、概述
- 1. 认识HashMap
- 2. HashMap 的作用和重要性
- 3. 简要讲解 HashMap 的基本原理和实现方式
- 二、了解 HashMap 创建及其的常见操作方法
- 1. HashMap的创建
- 2. 添加元素 put()
- 3. 访问元素 get()
- 4. 删除元素 remove()
- 5. 计算大小 size()
- 6. 迭代 HashMap for-each
- 7.判断是否为空 isEmpty()
- 8. 判断 HashMap 中是否存在指定 key containsKey()
- 9. 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 getOrDefault()
- 总结
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
一、概述
1. 认识HashMap
-
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射
-
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步
-
HashMap 是无序的,即不会记录插入的顺序
-
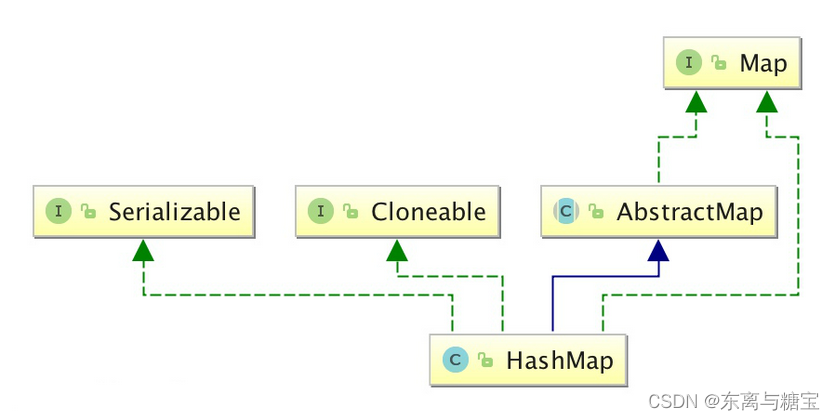
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口
- HashMap 的 key 与 value 类型可以相同也可以不同,可以是字符串(String)类型的 key 和 value,也可以是整型(Integer)的 key 和字符串(String)类型的 value
2. HashMap 的作用和重要性
HashMap是Java中最常用的数据结构之一,它实现了 Map 接口,提供了键值对存储和检索的功能。HashMap 的作用和重要性体现在以下几个方面:
- 存储和检索:HashMap 可以存储大量的键值对数据,并通过键快速检索对应的值。它使用哈希算法将键映射到数组的位置,从而实现高效的查找操作。这使得HashMap在处理大量数据时,可以快速地插入、获取和删除元素。
- 高效性能:由于 HashMap 的内部实现利用了哈希算法,它的查找操作的平均时间复杂度为O(1)(常数时间)。这意味着HashMap 在大多数情况下能够以非常高效的方式执行插入和查找操作,使得它成为处理大规模数据的理想选择。
- 灵活性:HashMap 中的键和值可以是任意类型的对象。这使得我们可以根据具体需求将不同类型的数据存储在 HashMap 中,而不受限于特定的数据类型。
- 唯一键:HashMap 要求键的唯一性,这意味着每个键只能在 HashMap 中出现一次。这对于通过键来查找值的场景非常有用,例如存储用户信息时,可以将用户ID作为键,以便快速地检索该用户的信息。
- 扩展性:HashMap 可以动态地扩展,根据存储数据的增长自动调整容量,从而避免了手动进行容量管理的繁琐操作。
3. 简要讲解 HashMap 的基本原理和实现方式
当使用 HashMap 存储数据时,它会根据键的哈希值将键值对映射到内部的数组中。基本原理可以概括为以下几步:
1. HashMap函数
-
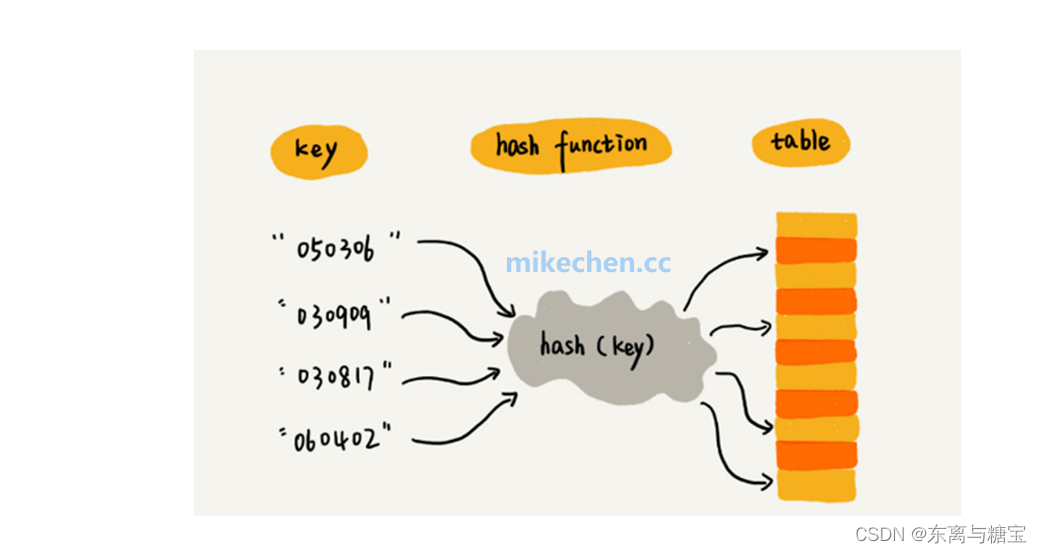
哈希函数:哈希表中元素是由哈希函数确定的,将数据元素的关键字 Key 作为自变量,通过一定的函数关系(称为哈希函数),计算出的值,即为该元素的存储地址。哈希表中哈希函数的设计是相当重要的,这也是建哈希表过程中的关键问题之一
-
哈希函数计算:当我们向HashMap中插入一个键值对时,HashMap会调用键的hashCode()方法来计算其哈希值。哈希值是一个整数,用于将键映射到数组的索引位置
-
哈希值转换:为了确保哈希值适合作为数组的索引,HashMap会对计算得到的哈希值进行一些转换操作。常用的转换方法是使用哈希值与数组长度进行取模运算,得到一个在数组范围内的索引值
2. HashMap存储
-
数组存储:HashMap内部维护了一个数组,每个数组元素对应一个桶(bucket)。每个桶可以存储一个或多个键值对。当插入或查找元素时,HashMap根据计算得到的索引值找到对应的桶,然后在桶中进行相应的操作
-
动态扩容:为了提高HashMap的性能,在存储的键值对数量达到一定阈值后,HashMap会自动进行扩容操作。扩容过程涉及重新计算键的哈希值,并重新分配键值对到更大的数组中。这样可以减少哈希冲突,提高操作效率

3. HashMap冲突处理
-
冲突处理:由于不同的键可能具有相同的哈希值,这就会导致冲突。当发生冲突时,HashMap使用链表或红黑树等数据结构来存储具有相同哈希值的键值对。这些数据结构允许在冲突的位置上存储多个键值对,并通过比较键的equals()方法来区分它们
-
链表:在JDK 8之前,HashMap使用链表来解决冲突。当多个键值对被映射到同一个桶时,它们会形成一个链表。通过遍历链表来查找、插入或删除键值对。但是,当链表长度过长时,会影响HashMap的性能
-
红黑树:从JDK 8开始,当链表长度超过一个阈值(默认为8)时,链表会被自动转换为红黑树,以提高操作效率。红黑树的查找、插入和删除操作具有较低的时间复杂度,可以在平均情况下保持对数时间复杂度

- Entry对象:HashMap使用Entry对象来表示键值对。每个Entry对象包含了键、值以及指向下一个Entry的引用(形成链表或红黑树结构)。在JDK 8之前,每个Entry对象还包含了指向前一个Entry的引用,以支持快速删除操作
总的来说,HashMap 通过哈希函数计算键的哈希值,并将键值对映射到内部数组中的桶中。采用链表或红黑树等数据结构解决哈希冲突,并通过动态扩容来提高性能。这种实现方式使得 HashMap 能够在常数时间复杂度内执行插入、查找和删除操作。
二、了解 HashMap 创建及其的常见操作方法
1. HashMap的创建
1. 关于包装类
HashMap 中的元素实际上是对象,一些常见的基本类型可以使用它的包装类,基本类型对应的包装类表如下:
| 基本类型 | 引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
2. HashMap要使用包装类型而不是基本类型
-
泛型限制:HashMap 是一个泛型类,它可以存储任意类型的键和值。然而,泛型类型参数只能是类而不能是基本类型。因此,如果要将基本类型作为键或值存储在 HashMap 中,就需要将其包装为相应的包装类型,例如 Integer、Double、Boolean 等。
-
空值处理:基本类型是不允许为 null 的,而包装类型可以为 null。在 HashMap 中,键和值都可以为 null。对于基本类型,当我们需要在 HashMap 中存储一个空值时,必须使用对应的包装类型。
3. 创建HashMap的示例
- HashMap 类位于 java.util 包中,使用前需要引入它,语法格式如下:
import java.util.HashMap; // 引入 HashMap 类
- 以下实例我们创建一个 HashMap 对象 Sites, 整型(Integer)的 key 和字符串(String)类型的 value:
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
2. 添加元素 put()
- 要向HashMap添加元素,你可以使用 put() 方法。put() 方法接受两个参数,第一个参数是键(Key),第二个参数是值(Value)。以下是一个添加元素到 HashMap 的示例:
map.put("A", 1);map.put("B", 2);map.put("C", 3);
- 需要注意的是,HashMap 允许将null作为键和值。如果你尝试将null作为键添加到 HashMap 中,它将只有一个键为 null 的键值对。另外,由于 HashMap 不是线程安全的,如果在多线程环境下使用 HashMap,请考虑使用线程安全的 ConcurrentHashMap。
3. 访问元素 get()
- 要访问HashMap中的元素,你可以使用 get() 方法。get() 方法接受一个参数,即要获取的键(Key),并返回与该键关联的值(Value)
int value1 = map.get("A"); // 访问键为"A"的值int value2 = map.get("B"); // 访问键为"B"的值
-
需要注意的是,如果指定的键不存在于 HashMap 中,get() 方法将返回 null。因此,在使用 get() 方法获取值之前,最好先使用containsKey() 方法 检查 HashMap 中是否存在指定的键
-
另外,HashMap还提供了其他方法来访问元素,如keySet()方法可返回所有键的集合,values()方法可返回所有值的集合,entrySet()方法可返回包含键值对的集合。通过使用这些方法,你可以遍历HashMap中的所有键值对并执行相应的操作
4. 删除元素 remove()
- 使用 remove(Object key) 方法:这个方法接受一个键作为参数,并从 HashMap 中删除对应的键值对。例如,如果你要删除键为 “key1” 的元素,可以使用以下代码:
HashMap<String, String> hashMap = new HashMap<>();hashMap.remove("key1");
- 使用迭代器遍历并删除元素:你可以使用 Iterator 来遍历 HashMap 的键值对,并使用 remove() 方法删除元素。这种方法适用于需要按条件删除元素的情况。例如,如果你要删除所有值为"value1"的键值对,可以使用以下代码:
HashMap<String, String> hashMap = new HashMap<>();
Iterator<Map.Entry<String, String>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {Map.Entry<String, String> entry = iterator.next();if (entry.getValue().equals("value1")) {iterator.remove();}
}
- 删除所有键值对 (key-value) 可以使用 clear 方法:
hashMap.clear();
5. 计算大小 size()
- 要计算HashMap的大小(即键值对的数量),你可以使用size()方法。该方法返回HashMap中键值对的数量。
- 以下是使用size()方法计算HashMap大小的示例代码:
int size = hashMap.size();
6. 迭代 HashMap for-each
-
可以使用 for-each 来迭代 HashMap 中的元素
-
如果你只想获取 key,可以使用 keySet() 方法,然后可以通过 get(key) 获取对应的 value,如果你只想获取 value,可以使用 values() 方法
// 引入 HashMap 类
import java.util.HashMap;public class RunoobTest {public static void main(String[] args) {// 创建 HashMap 对象 SitesHashMap<Integer, String> Sites = new HashMap<Integer, String>();// 添加键值对Sites.put(1, "Google");Sites.put(2, "Runoob");Sites.put(3, "Taobao");Sites.put(4, "Zhihu");// 输出 key 和 valuefor (Integer i : Sites.keySet()) {System.out.println("key: " + i + " value: " + Sites.get(i));}// 返回所有 value 值for(String value: Sites.values()) {// 输出每一个valueSystem.out.print(value + ", ");}}
}
- 执行以上代码,输出结果如下:
key: 1 value: Google
key: 2 value: Runoob
key: 3 value: Taobao
key: 4 value: Zhihu
Google, Runoob, Taobao, Zhihu,
7.判断是否为空 isEmpty()
-
要判断HashMap是否为空,你可以使用isEmpty()方法。该方法会返回一个布尔值,表示HashMap是否为空
-
以下是使用isEmpty()方法判断HashMap是否为空的示例代码:
System.out.println("Is HashMap empty? " + hashMap.isEmpty()
8. 判断 HashMap 中是否存在指定 key containsKey()
-
要判断 HashMap 是否包含某个特定的键(key),你可以使用 containsKey(Object key) 方法。该方法接受一个键作为参数,并返回一个布尔值,表示 HashMap 是否包含该键
-
以下是使用 containsKey(Object key) 方法判断 HashMap 是否包含某个键的示例代码:
System.out.println("Does HashMap contain key 'key2'? " + hashMap.containsKey("key1"));
9. 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 getOrDefault()
-
getOrDefault() 方法获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值
-
getOrDefault() 方法的语法为:
hashmap.getOrDefault(Object key, V defaultValue)
- 参数说明:
1. key - 键
2. defaultValue - 当指定的key并不存在映射关系中,则返回的该默认值
- 返回值:返回 key 相映射的的 value,如果给定的 key 在映射关系中找不到,则返回指定的默认值
import java.util.HashMap;class Main {public static void main(String[] args) {// 创建一个 HashMapHashMap<Integer, String> sites = new HashMap<>();// 往 HashMap 添加一些元素sites.put(1, "Google");sites.put(2, "Runoob");sites.put(3, "Taobao");System.out.println("sites HashMap: " + sites);// key 的映射存在于 HashMap 中// Not Found - 如果 HashMap 中没有该 key,则返回默认值String value1 = sites.getOrDefault(1, "Not Found");System.out.println("Value for key 1: " + value1);// key 的映射不存在于 HashMap 中// Not Found - 如果 HashMap 中没有该 key,则返回默认值String value2 = sites.getOrDefault(4, "Not Found");System.out.println("Value for key 4: " + value2);}
}
- 执行以上程序输出结果为:
Value for key 1: Google
Value for key 4: Not Found
总结
欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
相关文章:
提升Java开发效率:掌握HashMap的常见方法与基本原理
文章目录 前言一、概述1. 认识HashMap2. HashMap 的作用和重要性3. 简要讲解 HashMap 的基本原理和实现方式 二、了解 HashMap 创建及其的常见操作方法1. HashMap的创建2. 添加元素 put()3. 访问元素 get()4. 删除元素 remove()5. 计算大小 size()6. 迭代 HashMap for-each7.判…...

PostgreSQL系统概述
目录 写在前面 1.简介 1.1何为关系型数据库 1.2何为对象型数据库 2.特性 3.代码结构 3.1数据库集簇 3.2Parser查询分析流程 3.3内部查询树组成部分 3.3.1目标列表 3.4Optimizer查询优化流程 3.4.1查询计划 3.5非计划查询的SQL命令 写在前面 如有错误请指正…...
在AIGC时代的应用「中篇」)
掌握AI助手的魔法工具:解密Prompt(提示)在AIGC时代的应用「中篇」
文章目录 掌握AI助手的魔法工具:解密Prompt(提示)在AIGC时代的应用「中篇」一、指南原则1: 使用明确和具体的指令原则2: 给模型思考的时间 二、迭代三、总结与提取四、局限与改善五、总结 掌握AI助手的魔法工具:解密Prompt&#x…...

git svn:使用 git 命令来管理 svn 仓库
git-svn 使用教程 参考以下: https://cloud.tencent.com/developer/article/1415892 # 在SVN仓库上使用Git 源 https://blog.csdn.net/jiejie11080/article/details/106917116 # git svn clone速度慢的解决办法 http://blog.chinaunix.net/uid-11639156-id-30774…...

软考高级系统架构设计师系列论文九十一:论分布式数据库的设计与实现
软考高级系统架构设计师系列论文九十一:论分布式数据库的设计与实现 一、分布式数据库相关知识点二、摘要三、正文四、总结一、分布式数据库相关知识点 软考高级系统架构设计师系列之:分布式存储技术...

GeoHash之存储篇
前言: 在上一篇文章GeoHash——滴滴打车如何找出方圆一千米内的乘客主要介绍了GeoHash的应用是如何的,本篇文章我想要带大家探索一下使用什么样的数据结构去存储这些Base32编码的经纬度能够节省内存并且提高查询的效率。 前缀树、跳表介绍: …...
)
后端项目开发:集成接口文档(swagger-ui)
swagger集成文档具有功能丰富、及时更新、整合简单,内嵌于应用的特点。 由于后台管理和前台接口均需要接口文档,所以在工具包构建BaseSwaggerConfig基类。 1.引入依赖 <dependency><groupId>io.springfox</groupId><artifactId>…...

代码随想录训练营29天|●* 491.递增子序列 * 46.全排列 * 47.全排列 II
class Solution {vector<vector<int>>res;vector<int>vec;void backing(vector<int>& nums,int index){if(vec.size()>2&&is(vec)){res.push_back(vec);}unordered_set<int> uset; // 使用set对本层元素进行去重for(int iindex;i…...
uniapp日期选择组件优化
<uni-forms-item label="出生年月" name="birthDate"><view style="display: flex;flex-direction: row;align-items: center;height: 100%;"><view class="" v-...

AI驱动的大数据创新:探索软件开发中的机会和挑战
文章目录 机会数据驱动的决策自动化和效率提升智能预测和优化个性化体验 挑战数据隐私与安全技术复杂性数据质量和清洗伦理和社会问题 案例:智能代码生成工具总结 🎈个人主页:程序员 小侯 🎐CSDN新晋作者 🎉欢迎 &…...
国产化-银河麒麟V10系统及docker的安装
一、最近在研究国产化操作系统,“银河麒麟V10”, 在我电脑本机vmware 15的虚拟机中进行安装测试; 1.点击这里提交产品试用申请,不过只需要随便输入,手机号验证码验证后方可跳转至下载地址产品试用申请国产操作系统、银…...
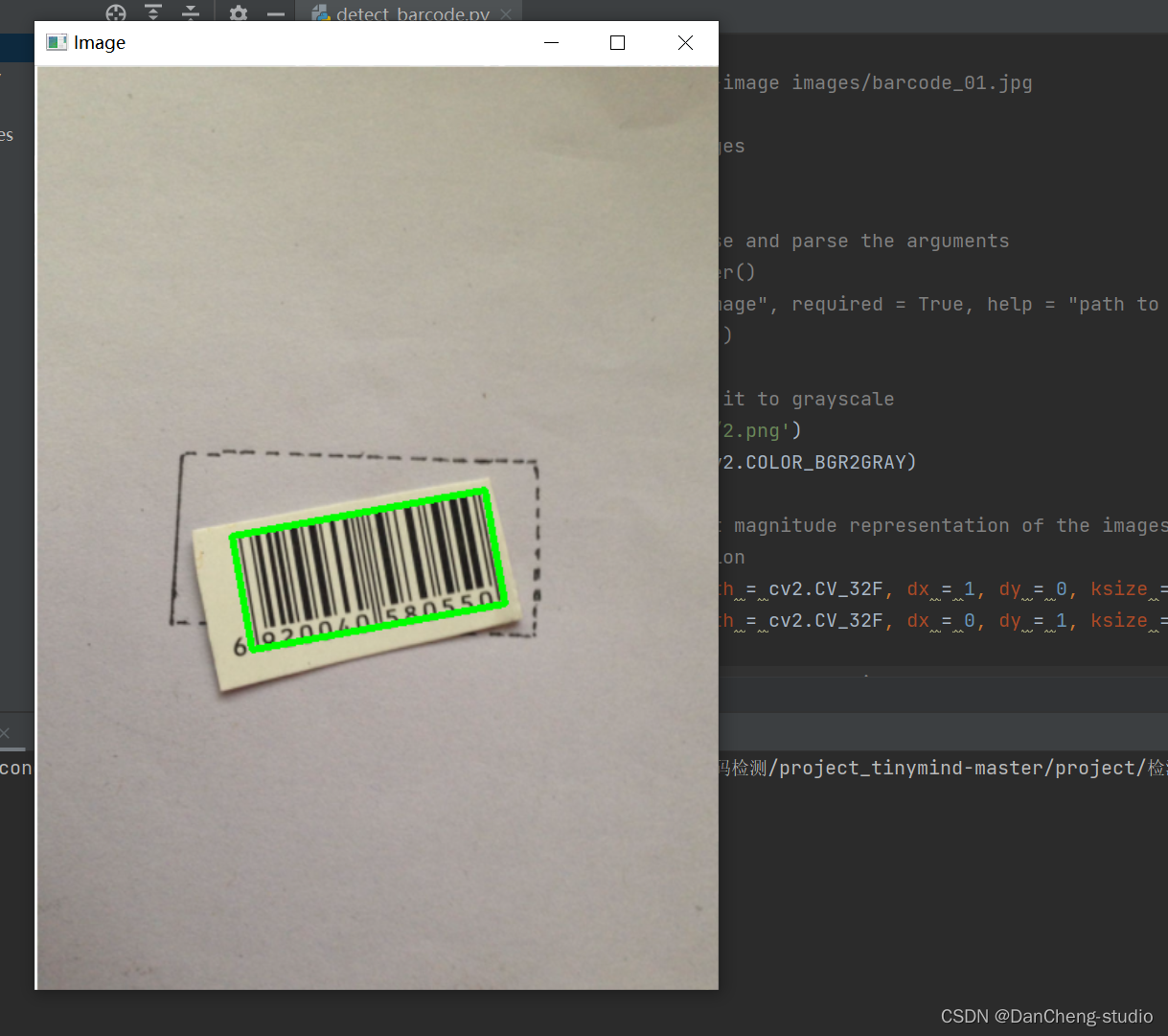
计算机毕设 基于机器视觉的二维码识别检测 - opencv 二维码 识别检测 机器视觉
文章目录 0 简介1 二维码检测2 算法实现流程3 特征提取4 特征分类5 后处理6 代码实现5 最后 0 简介 今天学长向大家介绍一个机器视觉的毕设项目,二维码 / 条形码检测与识别 基于机器学习的二维码识别检测 - opencv 二维码 识别检测 机器视觉 1 二维码检测 物体检…...
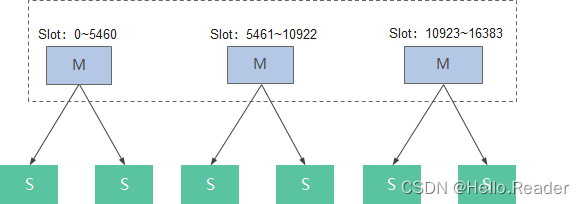
Redis原理剖析
一、Redis简介 Redis是一个开源的,基于网络的,高性能的key-value数据库,弥补了memcached这类key-value存储的不足,在部分场合可以对关系数据库起到很好的补充作用,满足实时的高并发需求。 Redis跟memcached类似&#…...

【送书活动】AI时代,程序员需要焦虑吗?
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...

什么是 JSON:理解和运用 JSON 的基本概念
现在程序员还有谁不知道 JSON 吗?无论对于前端还是后端,JSON 都是一种常见的数据格式。那么 JSON 到底是什么呢? JSON 的定义 JSON (JavaScript Object Notation) ,是一种轻量级的数据交换格式。它的使用…...
CSDN每日一练 |『异或和』『生命进化书』『熊孩子拜访』2023-08-27
CSDN每日一练 |『异或和』『生命进化书』『熊孩子拜访』2023-08-27 一、题目名称:异或和二、题目名称:生命进化书三、题目名称:熊孩子拜访 一、题目名称:异或和 时间限制:1000ms内存限制:256M 题目描述&…...

整数拆分乘积最大
将一个整数拆分为若干个自然数的和,如果要使这些数的乘积最大,应该尽可能的拆分出3。 任意一个数字可以由多个3的n次方的和(差)表示。 import java.util.Scanner; // 1:无需package // 2: 类名必须Main, 不可修改public class M…...
浅谈 Linux 下 vim 的使用
Vim 是从 vi 发展出来的一个文本编辑器,其代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。 Vi 是老式的字处理器,功能虽然已经很齐全了,但还有可以进步的地方。Vim 可以说是程序开发者的一项很好用的工…...

leetcode:只出现一次的数字Ⅲ(详解)
题目: 给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。 你必须设计并实现线性时间复杂度的算法且仅使用常量额外空间来解决此问题。 示例 1&…...

【vue3.0 使用组合式定义组件】
Vue3.0 中通过使用 setup 函数来定义组件。setup 函数接收两个参数,第一个参数是组件的 props,第二个参数是一个上下文对象,可以通过它访问到与组件相关的数据和方法。在 setup 函数中,我们可以使用 Vue3.0 提供的新特性 — 组合式…...

如何高效下载Steam创意工坊模组:WorkshopDL开源工具完整指南
如何高效下载Steam创意工坊模组:WorkshopDL开源工具完整指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Steam创意工坊模组下载而烦恼吗?无论…...

.NET逆向工程新选择:dnSpyEx调试器与程序集编辑全解析
.NET逆向工程新选择:dnSpyEx调试器与程序集编辑全解析 【免费下载链接】dnSpy Unofficial revival of the well known .NET debugger and assembly editor, dnSpy 项目地址: https://gitcode.com/gh_mirrors/dns/dnSpy 你是否曾面对一个没有源代码的.NET程序…...

别再乱收CAN报文了!STM32F407的HAL库CAN过滤器配置保姆级避坑指南
STM32F407 HAL库CAN过滤器配置:从原理到实战的深度解析 在嵌入式系统开发中,CAN总线因其高可靠性和实时性被广泛应用于汽车电子、工业控制等领域。然而,许多开发者在STM32F407上使用HAL库配置CAN过滤器时,常常陷入"能接收数据…...

轨道交通条形屏电源技术分析:超薄化与高可靠性的工程平衡
一、行业背景与技术挑战在智慧城轨建设中,地铁站内条形屏是乘客信息显示系统的核心终端设备。该应用场景对配套电源提出以下技术要求:技术需求具体指标工程挑战超薄化整机厚度3-8mm传统变压器/散热器高度难以压缩高可靠性MTBF≥50000小时轨道交通振动、温…...

基于RP2040与VL53L1X的自动触发空气炮:嵌入式感知-决策-执行系统实践
1. 项目概述:一个会“思考”的自动空气炮如果你玩过或者听说过那些在鬼屋里突然喷气吓人的恶作剧道具,那你大概能想象出这个项目的最终效果。但今天我们要做的,远不止一个简单的“吓人盒子”。这是一个融合了现代嵌入式系统、高精度传感器和气…...

2026 断桥铝系统门窗选购指南:品牌综合实力榜与技术选型要点
2026 断桥铝系统门窗选购指南:品牌综合实力榜与技术选型要点行业发展背景与产品技术迭代中国住宅装饰装修产业正向品质化、精细化与绿色化深度转型,居住者对建筑外围护结构的综合性能要求持续攀升。传统非系统化断桥铝门窗因结构设计单一、性能指标离散、…...

年度名场面!黄仁勋逛胡同被投喂豆汁,眉头紧锁。网友:弥补了没有喝过 XX 的遗憾
5 月 15 日,「黄仁勋 南锣鼓巷」话题突然在多平台引爆热议。谁能想到,手握 5 万亿美刀市值的科技大佬,私下里竟是胡同干饭人。昨天在大会堂还是西装革履,今天老黄换上他的经典皮肤套装,带几名随行人员低调逛南锣鼓巷和…...

如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析
如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

java微服务驱动的社区平台:友猫社区的功能模块与实现逻辑
一、项目概述 友猫社区平台是由宠友信息技术有限公司研发的一体化社区生态系统,结合了内容分享、即时通讯、社交关系链与商城电商等功能。平台采用前后端分离架构,以高可扩展性、灵活配置与多端兼容性为设计核心,能够适应不同类型的企业及创…...

TestDisk与PhotoRec:免费开源的数据恢复双雄终极指南
TestDisk与PhotoRec:免费开源的数据恢复双雄终极指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 在数字时代,数据丢失是每个人都会遇到的噩梦。无论是误删除重要文件、分区表损坏…...