深入理解Redis缓存穿透、击穿、雪崩及解决方案
深入理解Redis缓存穿透、击穿、雪崩及解决方案
- 一、简介
- Redis 简介
- 缓存作用与优化
- 二、缓存问题的分类
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 三、缓存穿透的解决方案
- 布隆过滤器
- 缓存空对象
- 接口层校验
- 四、缓存击穿的解决方案
- 互斥锁
- 热点数据提前加载
- 五、缓存雪崩的解决方案
- 增加缓存容错能力
- 数据预热
- 六、Redis针对以上问题的解决方案
- 多级缓存策略
- 主从复制与持久化
一、简介
Redis 简介
Redis是一个基于内存的数据结构存储系统,是一个支持键值对、发布/订阅、存储新闻资讯的高性能key-value存储数据库。
缓存作用与优化
缓存技术在Web开发中是比较重要的组成部分,常用于增强Web应用的性能和容错性。缓存通过将计算过的数据或提前读出数据放置在高速缓存中,当请求相同数据时直接从缓存中响应。因此,缓存对于加速应用响应时间、节省处理器资源等方面有着非常显著的作用。
为了更好的利用缓存,需要对缓存问题进行分类和解决方案。
二、缓存问题的分类
缓存穿透
缓存穿透是指查询一个不存在的数据,由于缓存没有数据,请求被透传到数据库,此时如果恶意用户不断发起不存在数据的查询,缓存就无法发挥效果,请求最终压垮数据库。这种情况需要对不存在数据加以处理,如使用Nginx缓存;、使用异常机制处理。
缓存击穿
缓存击穿是指对于一个存在的key,由于并发量大,同时失效,导致多个线程都去查询数据库,造成缓存击穿。为了避免此类情况,可以令所有线程等待第一个查询后再进行操作;或者使用互斥锁等机制限制并发访问。
缓存雪崩
缓存雪崩是指缓存中大量的key在同一时刻失效,导致瞬间有大量的请求直接访问数据库,严重影响数据库的性能和应用的稳定性。为了解决这个问题,可以引入缓存预热、设置不同的过期时间等措施。
三、缓存穿透的解决方案
布隆过滤器
布隆过滤器可以快速判断一个元素是否存在于一个集合中,因此可以用来验证请求的参数或者ID在数据库中是否存在,从而有效防止恶意攻击导致的缓存穿透。
import redis
from bitarray import bitarrayclass BloomFilter:def __init__(self, capacity, error_rate):self.capacity = capacityself.error_rate = error_rateself.redis_client = redis.Redis()self.hash_count = int(-1 * (capacity * math.log(error_rate) / (math.log(2) ** 2)))self.bit_array_length = int(math.ceil((capacity * math.log(error_rate)) / math.log(1.0 / (2 ** math.log(2)))))self.redis_client.setbit('bloom_filter', self.bit_array_length, 0)def exists(self, key):for i in range(self.hash_count):hashed_index = hash(key + str(i)) % self.bit_array_lengthif not self.redis_client.getbit('bloom_filter', hashed_index):return Falsereturn Truedef add(self, key):for i in range(self.hash_count):hashed_index = hash(key + str(i)) % self.bit_array_lengthself.redis_client.setbit('bloom_filter', hashed_index, 1)
缓存空对象
当查询结果为空时,我们也可以将其缓存到Redis中,并给它一个较短的生命周期。这样,下次如果同样的查询请求再次到达时,就可以直接从缓存中返回空结果,而不会穿透到数据库。
def get_user_info(user_id):user_key = f'user:{user_id}'user_info = redis.get(user_key)if not user_info:# 从数据库中查询用户信息,如果查不到标记为空并将结果缓存到Redis中user_info = db.query_user_info(user_id)if not user_info:redis.set(user_key, '', ex=60)else:redis.set(user_key, user_info, ex=3600)return user_info
接口层校验
在应用层或者接口层增加验证机制,对于非法请求进行拦截。可以根据请求的参数特征、请求频率等信息进行识别,从而避免类似SQL注入攻击等请求穿透缓存。
四、缓存击穿的解决方案
互斥锁
在需要大量更新缓存的场景下,我们通常需要使用互斥锁来避免缓存击穿。比如,可以使用Redis的SETNX命令设置标记,当发现缓存过期时,先去获取锁,然后再去加载数据并更新缓存,同时释放该锁。
def get_user_info(user_id):user_key = f'user:{user_id}'user_info = redis.get(user_key)if not user_info:lock_key = f'{user_id}_lock'# 使用SETNX命令尝试获取锁,如果获取成功if redis.setnx(lock_key, 1):# 设置锁的超时时间避免死锁redis.expire(lock_key, 60)user_info = db.query_user_info(user_id)redis.set(user_key, user_info, ex=3600)# 解锁,删除锁标记redis.delete(lock_key)return user_info
热点数据提前加载
在缓存过期前提前加载数据,避免并发请求穿透直接访问数据库导致缓存击穿。可以设置缓存过期时间略长于预加载时间,保证数据一定能够预先加载到缓存中。
def preload_hot_data():hot_data_key = 'hot_data'hot_data = db.query_hot_data()redis.set(hot_data_key, hot_data, ex=600)def get_hot_data():hot_data_key = 'hot_data'hot_data = redis.get(hot_data_key)if not hot_data:# 预加载热点数据到缓存preload_hot_data()hot_data = redis.get(hot_data_key)return hot_data
五、缓存雪崩的解决方案
增加缓存容错能力
当大量缓存同时失效时,可以通过应用多级缓存、加入容错机制等手段防止缓存雪崩。具体实现可以根据业务场景进行选择和调整。
数据预热
尽可能在业务低峰期前将缓存数据全部加载到缓存系统中,从而避免业务高峰期缓存穿透、缓存击穿导致的缓存雪崩。可以使用定时任务或者异步加载方式,将慢查询或热点数据提前加载到缓存中。
def preload_cache():user_keys = db.query_all_user_keys()for user_key in user_keys:user_info = db.query_user_info(user_key)redis.set(user_key, user_info, ex=3600)# 定时任务,每天凌晨1点执行一次数据预热
scheduler.add_job(preload_cache, 'cron', hour='1')
六、Redis针对以上问题的解决方案
Redis是一款高性能的内存数据库,为了解决以上问题,它提出了以下两种解决方案:
多级缓存策略
缓存中间件作为缓存系统的一种,主要用来提高网站并发量、降低网站响应时间、减轻源站数据库的压力等。多级缓存指的是使用两种及以上的缓存技术来加速响应速度。
"""
多级缓存策略示例:
1.使用 Redis 作为一级缓存,存储频繁访问的热数据;
2.使用 Memcached 作为二级缓存,存储冷数据或者业务数据;
3.使用本地缓存作为三级缓存,存储session,减少请求量。
"""
import redis
import memcacheclass Cache:def __init__(self):self.redis = redis.Redis(host='localhost', port=6379)self.memcache = memcache.Client(['127.0.0.1:11211'])def get(self, key):# 尝试从 Redis 中获取数据data = self.redis.get(key)if not data:# Redis 中没有该数据,尝试从 Memcached 中获取data = self.memcache.get(key)if not data:# Memcached 中也没有,则从本地缓存中获取data = self.local_cache.get(key)return datadef set(self, key, data):# 三个缓存都存储数据self.redis.set(key, data)self.memcache.set(key, data)self.local_cache.set(key, data)
主从复制与持久化
为了提高 Redis 的稳定性和可靠性,Redis 提供了主从复制和持久化机制。主从复制指的是数据备份,将 Redis 数据库的数据复制到一台或多台 Redis 实例上,以实现读写分离及容灾恢复;持久化指的是通过 RDB 和 AOF 两种方式把内存中的数据保存到磁盘中,保证数据在 Redis 重启后依旧存在。
"""
主从复制示例:
1.创建一个 Redis 实例,将其设置为主服务器;
2.创建两个 Redis 实例,将其分别设置为从服务器;
3.从主服务器同步数据到两个从服务器。
"""import redis# 创建 Redis 实例,作为主服务器
redis_master = redis.Redis(host='192.168.1.100', port=6379)# 创建两个 Redis 实例,作为从服务器
redis_slave1 = redis.Redis(host='192.168.1.101', port=6379)
redis_slave2 = redis.Redis(host='192.168.1.102', port=6379)# 将从服务器连接到主服务器上,实现主从复制
redis_slave1.slaveof(redis_master.host, redis_master.port)
redis_slave2.slaveof(redis_master.host, redis_master.port)# 可以通过以下命令查看主从状态
# redis-cli info replication
相关文章:

深入理解Redis缓存穿透、击穿、雪崩及解决方案
深入理解Redis缓存穿透、击穿、雪崩及解决方案 一、简介Redis 简介缓存作用与优化 二、缓存问题的分类缓存穿透缓存击穿缓存雪崩 三、缓存穿透的解决方案布隆过滤器缓存空对象接口层校验 四、缓存击穿的解决方案互斥锁热点数据提前加载 五、缓存雪崩的解决方案增加缓存容错能力…...

java八股文面试[java基础]——字节码
字节码技术应用 字节码技术的应用场景包括但不限于AOP,动态生成代码,接下来讲一下字节码技术相关的第三方类库,第三方框架的讲解是为了帮助大家了解字节码技术的应用方向,文档并没有对框架机制进行详细分析,有兴趣的可…...

新能源汽车技术的最新进展和未来趋势
文章目录 电池技术的进步智能驾驶与自动驾驶技术充电基础设施建设新能源汽车共享和智能交通未来趋势展望结论 🎉欢迎来到AIGC人工智能专栏~探索新能源汽车技术的最新进展和未来趋势 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客…...
知虾shopee数据分析工具:shopee出单的商机利器
当今数字化时代,数据已经成为商业成功的关键要素之一。而Shopee作为东南亚最大的电商平台之一,其强大的数据分析工具正为商家提供了宝贵的市场洞察和决策支持。本文将深入探讨Shopee数据分析工具如何帮助商家抓住商机并取得成功。 洞察消费者需求&#x…...

python——ydata-profiling介绍与使用
ydata-profiling介绍与使用 ydata-profiling的作用ydata-profiling的安装与简单使用ydata-profiling的结果结构 ydata-profiling的实际应用场景1. 数据集比较2. 时间序列报告3. 对大型数据集进行概要分析4. 处理敏感数据5. 自定义报告的外观 ydata-profiling的作用 ydata-prof…...

(纯c)数据结构之------>链表(详解)
目录 一. 链表的定义 1.链表的结构. 2.为啥要存在链表及链表的优势. 二. 无头单向链表的常用接口 1.头插\尾插 2.头删\尾删 3.销毁链表/打印链表 4.在pos位置后插入一个值 5.消除pos位置后的值 6.查找链表中的值并且返回它的地址 7.创建一个动态开辟的结点 三.顺序表与链表…...

postman接口自动化测试框架实战!
什么是自动化测试 把人对软件的测试行为转化为由机器执行测试行为的一种实践。 例如GUI自动化测试,模拟人去操作软件界面,把人从简单重复的劳动中解放出来。 本质是用代码去测试另一段代码,属于一种软件开发工作,已经开发完成的用…...

Apache Doris 入门教程35:多源数据目录
概述 多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。 在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接…...

响应式web-PC端web与移动端web(H5)兼容适配 选型方案
背景 项目需要,公司已经有一套PC端web,需要做一套手机端浏览器可用的,但是又想兼容pc端,适配的web项目。 以下是查阅到响应布局现成的开源模版。根据自己技术栈,vue2,js来搜索相关的开源项目。 RuoYi 使用若依快速…...

Redis持久化之RDB解读
目录 什么是RDB 配置位置参数解读 如何使用 自动触发 手动触发 save bgsave RDBRDB持久化文件的恢复 正常恢复 恢复失败处理方法 RDB优势 RDB 缺点 redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘…...

四维图新 minemap实现地图漫游效果
原理就是不断改变地图中心点,改变相机角度方向,明白这一点,其他地图引擎譬如cesium都可效仿,本人就是通过cesium的漫游实现四维图新的漫游,唯一不足的是转弯的时候不能丝滑转向,尝试过应该是四维图新引擎的…...
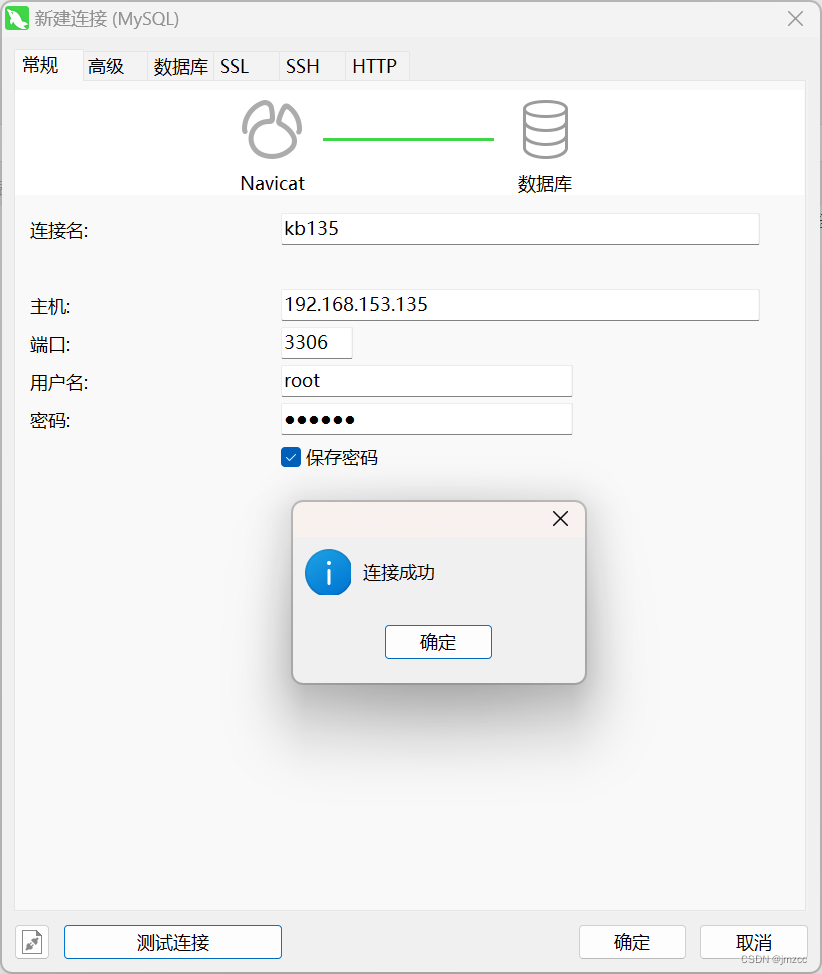
centos7安装MySQL8
Centos7安装MySQL8 MySQL版本:8.0.34 1.安装前准备 (1)查看是否安装mariadb [rootkb135 ~]# rpm -qa|grep mariadb (2)卸载mariadb并检查是否卸干净 [rootkb135 ~]# rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x8…...

【IMX6ULL驱动开发学习】10.Linux I2C驱动实战:AT24C02驱动设计流程
前情回顾:【IMX6ULL驱动开发学习】09.Linux之I2C框架简介和驱动程序模板_阿龙还在写代码的博客-CSDN博客 目录 一、修改设备树(设备树用来指定引脚资源) 二、编写驱动 2.1 i2c_drv_read 2.2 i2c_drv_write 2.3 完整驱动程序 三、上机测…...
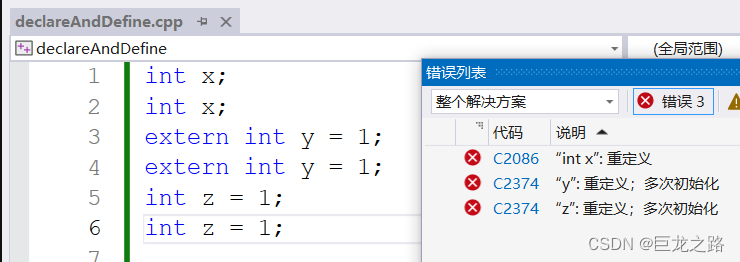
【C++】详解声明和定义
2023年8月28日,周一下午 研究了一个下午才彻底弄明白... 写到晚上才写完这篇博客。 目录 声明和定义的根本区别结构体的声明和定义声明结构体 定义结构体类的声明和定义函数的定义和声明声明函数 定义函数变量声明和定义声明变量定义变量 声明和定义的根本区别 …...

掌握C/C++协程编程,轻松驾驭并发编程世界
一、引言 协程的定义和背景 协程(Coroutine),又称为微线程或者轻量级线程,是一种用户态的、可在单个线程中并发执行的程序组件。协程可以看作是一个更轻量级的线程,由程序员主动控制调度。它们拥有自己的寄存器上下文…...

MyBatis-Plus的分页配置类
文章目录 package com.itheima.reggie.config;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; imp…...
)
排序算法-选择排序(Java)
选择排序 选择排序 (selection sort)的工作原理非常直接:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。 算法原理 排序数组:(2 4 3 1 5 2) …...

SpringBoot 怎么返回html界面
方法一: (1)html文件要放在resource下的static目录下(没有static 自己就创建一个文件夹) (2)在application.yml 中配置视图解析器 spring:mvc:view:prefix: /suffix: .html (3&a…...

watch computed 和 method
在Vue中,watch computed 和 method有啥区别,有啥作用,适用于何种情景并代码举例 在Vue中,watch、computed和methods是三种不同的属性,用于处理不同的场景和需求。 watch:watch用于监听数据的变化并执行相…...

数据结构,线性表有哪些
线性表是一种常见的数据结构,它的特点是数据元素之间存在一对一的线性关系。根据线性表的存储方式和实现方式,线性表主要有以下几种: 1. 顺序表(Sequential List): - 通常使用数组实现。 - 元素在内存中是连续…...

开源首发:DocCenter — 本地 HTML 工作台,治好 AI 时代的文档散落病
Tags:Python aiohttp 开源项目 AI工具 前端工程 全栈 工具分享 一、痛点:AI 时代的文档散落病 (对比传统文档管理 vs AI 生成文档的区别,说明为什么 VSCode/Notion 都不合适) 二、技术选型:为什么是单 Pyth…...

AI圈内两大热词 Agent 和 Skill,一文彻底搞懂它们之间的区别与联系!
本文以餐厅经理和厨师的类比,解释了 Agent 和 Skill 的核心区别:Agent 拥有决策权,决定下一步做什么;Skill 则负责执行具体任务。文章指出,尽管在实际应用中两者界限逐渐模糊,但在构建 AI 系统时࿰…...

记录红米note手机忘记屏幕密码找回过程
手上一台老红米note10忘记了开机密码,但里面还有一些重要资料,今天得到一个软件MOBILedit Forensic ULTRA 9.8.0.34378可以解出屏幕密码,我就拿来试一下,果然解开了,记录一下过程给大家参考。先查这个手机的处理器是天…...

Python一键打包exe
链接:https://pan.quark.cn/s/a5759c489d72...

基于MCP协议构建AI助手与外部应用桥接:以hikerapi-mcp为例的实战指南
1. 项目概述与核心价值最近在折腾一些自动化工作流,发现很多工具之间的数据流转是个大问题。比如,我想把某个文档里的关键信息提取出来,自动生成一个任务列表,再推送到另一个项目管理工具里。这个过程如果手动操作,不仅…...

PX4-Autopilot扩展卡尔曼滤波状态估计系统深度解析与实战调优
PX4-Autopilot扩展卡尔曼滤波状态估计系统深度解析与实战调优 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4-Autopilot作为开源无人机飞控系统的标杆,其核心状态估计模块EKF2&…...

BG3模组管理器版本兼容性终极指南:告别游戏崩溃和模组失效
BG3模组管理器版本兼容性终极指南:告别游戏崩溃和模组失效 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModManager BG3模组管理器是《博德之门3》…...

README工匠技能:从自动化工具到工程化实践,打造项目黄金门面
1. 项目概述:一个为README注入灵魂的“工匠”技能 在开源社区和项目协作中,README文件就是项目的“门面”和“说明书”。一个优秀的README,能瞬间抓住潜在用户或贡献者的眼球,清晰地传达项目价值、快速引导上手,甚至能…...

半导体产业模式之争:IDM与代工在先进制程下的博弈与融合
1. 从代工模式回归IDM?一场半导体产业路线的深度思辨最近在翻看一些老资料,2012年EE Times上的一篇旧文又把我拉回了那个充满争论的十字路口。文章标题直指核心:“代工模式正在向IDM模式逆转吗?” 当时,英特尔的技术大…...

Marchand Balun设计原理与IE3D电磁仿真实践
1. Marchand Balun设计基础与电磁仿真原理在射频和微波电路设计中,平衡-不平衡转换器(Balun)是实现单端信号与差分信号相互转换的关键无源器件。作为从业15年的射频工程师,我经常需要在各类高频电路中使用Balun结构,而…...