在kaggle中用GPU使用CGAN生成指定mnist手写数字
文章目录
- 1项目介绍
- 2参考文章
- 3代码的实现过程及对代码的详细解析
- 独热编码
- 定义生成器
- 定义判别器
- 打印我们的引导信息
- 模型训练
- 迭代过程中生成的图片
- 损失函数的变化
- 4总结
- 5 模型相关的文件
1项目介绍
在GAN的基础上进行有条件的引导生成图片cgan
2参考文章
GAN实战之Pytorch 使用CGAN生成指定MNIST手写数字
GANs系列:CGAN(条件GAN)原理简介以及项目代码实现
3代码的实现过程及对代码的详细解析
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import os
for dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
from torch.utils import data
import os
import glob
from PIL import Image
独热编码
# 输入x代表默认的torchvision返回的类比值,class_count类别值为10
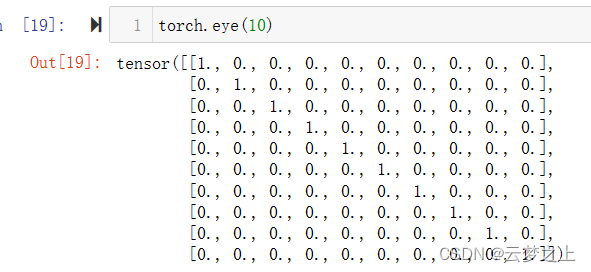
def one_hot(x, class_count=10):return torch.eye(class_count)[x, :] # 切片选取,第一维选取第x个,第二维全要
torch.eye(10)函数的作用是生成一个10*10的对角矩阵
该函数的作用是得到第x个位置为1的独热编码,如果传入为列表,则得到一个矩阵
transform =transforms.Compose([transforms.ToTensor(),transforms.Normalize(0.5, 0.5)])#minist数据集中的图片数据的维度是[batch_size, 1, 28, 28],其中batch_size是每个批次的图像数量。这个数据集中的每个图像都是28x28像素的灰度图像,因此它们只有一个通道
dataset = torchvision.datasets.MNIST('data',train=True,transform=transform,target_transform=one_hot,download=True)
#这里target_transform参数的作用是对标签进行转换。在这个例子中,它的作用是将标签转换为one-hot编码。
dataloader = data.DataLoader(dataset, batch_size=64, shuffle=True)定义生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()#因此,这个函数的输入张量维度为[batch_size, 10]和[batch_size, 100],输出张量维度为[batch_size, 1, 1, 1]。self.linear1 = nn.Linear(10, 128 * 7 * 7)self.bn1 = nn.BatchNorm1d(128 * 7 * 7)self.linear2 = nn.Linear(100, 128 * 7 * 7)self.bn2 = nn.BatchNorm1d(128 * 7 * 7)#这个函数的作用是将一个输入张量进行反卷积操作,得到一个输出张量。#nn.ConvTranspose2d函数的作用是将一个256通道的输入张量转换为一个128通道的输出张量,使用3x3的卷积核进行卷积操作,并在卷积操作后进行1像素的paddingself.deconv1 = nn.ConvTranspose2d(256, 128,kernel_size=(3, 3),padding=1)self.bn3 = nn.BatchNorm2d(128)self.deconv2 = nn.ConvTranspose2d(128, 64,kernel_size=(4, 4),stride=2,padding=1)self.bn4 = nn.BatchNorm2d(64)self.deconv3 = nn.ConvTranspose2d(64, 1,kernel_size=(4, 4),stride=2,padding=1)def forward(self, x1, x2):x1 = F.relu(self.linear1(x1))x1 = self.bn1(x1)x1 = x1.view(-1, 128, 7, 7)x2 = F.relu(self.linear2(x2))x2 = self.bn2(x2)x2 = x2.view(-1, 128, 7, 7)#将两个处理后的结果拼接在一起,得到形状为[64, 256, 7, 7]的张量x = torch.cat([x1, x2], axis=1)x = F.relu(self.deconv1(x))#形状变为为[64, 128, 7, 7]的张量x = self.bn3(x)x = F.relu(self.deconv2(x))#形状变为为[64, 64, 14, 14]的张量x = self.bn4(x)# 形状变为为[64, 1, 28, 28]的张量x = torch.tanh(self.deconv3(x))return x
生成器对数据的处理过程:
这个函数对于输入张量[64, 1, 28, 28]的维度变化过程如下:
输入张量维度为[64, 1, 28, 28]
经过线性变换和ReLU激活函数处理后,得到两个形状为[64, 128 * 7 * 7]的张量
将两个张量分别通过BatchNorm1d进行归一化处理
将两个处理后的结果reshape成形状为[64, 128, 7, 7]的张量
将两个处理后的结果拼接在一起,得到形状为[64, 256, 7, 7]的张量
经过反卷积操作得到输出张量,维度为[64, 1, 28, 28]
定义判别器
# input:1,28,28的图片以及长度为10的condition
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.linear = nn.Linear(10, 1*28*28)self.conv1 = nn.Conv2d(2, 64, kernel_size=3, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=2)self.bn = nn.BatchNorm2d(128)self.fc = nn.Linear(128*6*6, 1) # 输出一个概率值def forward(self, x1, x2):#leak_relu激活函数:它在输入小于0时返回一个小的斜率,而在输入大于等于0时返回输入本身x1 =F.leaky_relu(self.linear(x1))x1 = x1.view(-1, 1, 28, 28)#torch.cat([x1, x2], axis=1)函数将张量x1和张量x2沿着第二个维度(即列)拼接起来x = torch.cat([x1, x2], axis=1)#处理过后变为(64,2,28,28)x = F.dropout2d(F.leaky_relu(self.conv1(x)))#维度变为(64,64,13,13)x = F.dropout2d(F.leaky_relu(self.conv2(x)))#维度变为(64,128,6,6)x = self.bn(x)x = x.view(-1, 128*6*6)#最后键位了64*1(同时把值映射到0~1之间)x = torch.sigmoid(self.fc(x))return x# 初始化模型
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device)
dis = Discriminator().to(device)# 损失计算函数
loss_function = torch.nn.BCELoss()# 定义优化器
d_optim = torch.optim.Adam(dis.parameters(), lr=1e-5)
g_optim = torch.optim.Adam(gen.parameters(), lr=1e-4)# 定义可视化函数
def generate_and_save_images(model, epoch, label_input, noise_input):#生成器生成取片,label_input为输入的引导信息,noise_input为随机的噪声点predictions = np.squeeze(model(label_input, noise_input).cpu().numpy())#numpy.squeeze()函数的作用是去掉矩阵里维度为1的维度。fig = plt.figure(figsize=(4, 4))for i in range(predictions.shape[0]):plt.subplot(4, 4, i + 1)plt.imshow((predictions[i] + 1) / 2, cmap='gray')plt.axis("off")from IPython.display import FileLinkplt.savefig('data/img/image_at_epoch_{:04d}.png'.format(epoch))plt.show()import os
os.makedirs("data/img")
打印我们的引导信息
noise_seed = torch.randn(16, 100, device=device)label_seed = torch.randint(0, 10, size=(16,))
label_seed_onehot = one_hot(label_seed).to(device)print(label_seed)
tensor([1, 3, 5, 4, 9, 3, 0, 0, 1, 3, 4, 5, 9, 2, 3, 7])
模型训练
D_loss = []
G_loss = []
# 训练循环
for epoch in range(150):d_epoch_loss = 0g_epoch_loss = 0count = len(dataloader.dataset)# 对全部的数据集做一次迭代#dataloader中的图像是四维的。在for循环中,每次迭代会返回一个batch_size大小的数据#其中每个数据都是一个四维张量,形状为[batch_size, channels, height, width]for step, (img, label) in enumerate(dataloader):img = img.to(device)label = label.to(device)size = img.shape[0]random_noise = torch.randn(size, 100, device=device)d_optim.zero_grad()real_output = dis(label, img)d_real_loss = loss_function(real_output,torch.ones_like(real_output, device=device))#torch.ones_like(real_output, device=device)函数的作用是生成一个与real_output形状相同的张量,其中所有元素都为1。 d_real_loss.backward() #求解梯度# 得到判别器在生成图像上的损失gen_img = gen(label,random_noise)fake_output = dis(label, gen_img.detach()) # 判别器输入生成的图片,f_o是对生成图片的预测结果d_fake_loss = loss_function(fake_output,torch.zeros_like(fake_output, device=device))d_fake_loss.backward()d_loss = d_real_loss + d_fake_lossd_optim.step() # 优化# 得到生成器的损失g_optim.zero_grad()fake_output = dis(label, gen_img)g_loss = loss_function(fake_output,torch.ones_like(fake_output, device=device))g_loss.backward()g_optim.step()with torch.no_grad():d_epoch_loss += d_loss.item()g_epoch_loss += g_loss.item()with torch.no_grad():d_epoch_loss /= countg_epoch_loss /= countD_loss.append(d_epoch_loss)G_loss.append(g_epoch_loss)if epoch % 10 == 0:print('Epoch:', epoch)generate_and_save_images(gen, epoch, label_seed_onehot, noise_seed)print("epoch:{}/150".format(epoch))plt.plot(D_loss, label='D_loss')
plt.plot(G_loss, label='G_loss')
plt.legend()
plt.show()迭代过程中生成的图片
迭代1次

迭代10次

迭代20次

迭代30次

迭代40次

迭代150次

损失函数的变化

4总结
cGAN相比于GAN而言,将label的信息通过一系列的卷积操作和图像的信息融合在一起,然后放进模型进行训练,让我们的模型能和label相匹配的图像,从而在我们给出制定的数字label时能够生成对应的数字图片,实现了引导的过程。
5 模型相关的文件
模型的相关文件:提取码(ujki)
本模型是放在kaggle中运行的,kaggle的部署流程请参考:在kaggle中用GPU训练模型
相关文章:
在kaggle中用GPU使用CGAN生成指定mnist手写数字
文章目录 1项目介绍2参考文章3代码的实现过程及对代码的详细解析独热编码定义生成器定义判别器打印我们的引导信息模型训练迭代过程中生成的图片损失函数的变化 4总结5 模型相关的文件 1项目介绍 在GAN的基础上进行有条件的引导生成图片cgan 2参考文章 GAN实战之Pytorch 使用…...

【NI USRP】哪些 USRP 设备支持全双工,哪些支持半双工?
译者 东枫电子科技 设备构成 NI USRPEttus USRPUSRP-2900B200USRP-2901B210USRP-2920N210 WBXUSRP-2921N210 XCVR 2450USRP-2922N210 SBXUSRP-2930N210 WBX GPSDOUSRP-2932N210 SBX GPSDOUSRP-2940RX310 WBX (x2)USRP-2942RX310 SBX (x2)USRP-2943RX310 CBX (x2)U…...

不拼花哨,只拼实用:unittest指南,干货为王!
Python为开发者提供了内置的单元测试框架 unittest,它是一种强大的工具,能够有效地编写和执行单元测试。unittest 提供了完整的测试结构,支持自动化测试的执行,能够对测试用例进行组织,并且提供了丰富的断言方法。最终…...

mysql 获取json数组中某个字段根据下标
MySQL获取JSON数组中某个字段根据下标 在MySQL中,JSON数据类型可以方便地存储、操作和查询包含复杂结构的数据。当我们需要从JSON数组中获取某个字段时,可以使用MySQL的JSON函数来实现。 1. JSON数据类型简介 JSON(JavaScript Object Nota…...

深入理解Redis缓存穿透、击穿、雪崩及解决方案
深入理解Redis缓存穿透、击穿、雪崩及解决方案 一、简介Redis 简介缓存作用与优化 二、缓存问题的分类缓存穿透缓存击穿缓存雪崩 三、缓存穿透的解决方案布隆过滤器缓存空对象接口层校验 四、缓存击穿的解决方案互斥锁热点数据提前加载 五、缓存雪崩的解决方案增加缓存容错能力…...

java八股文面试[java基础]——字节码
字节码技术应用 字节码技术的应用场景包括但不限于AOP,动态生成代码,接下来讲一下字节码技术相关的第三方类库,第三方框架的讲解是为了帮助大家了解字节码技术的应用方向,文档并没有对框架机制进行详细分析,有兴趣的可…...

新能源汽车技术的最新进展和未来趋势
文章目录 电池技术的进步智能驾驶与自动驾驶技术充电基础设施建设新能源汽车共享和智能交通未来趋势展望结论 🎉欢迎来到AIGC人工智能专栏~探索新能源汽车技术的最新进展和未来趋势 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客…...
知虾shopee数据分析工具:shopee出单的商机利器
当今数字化时代,数据已经成为商业成功的关键要素之一。而Shopee作为东南亚最大的电商平台之一,其强大的数据分析工具正为商家提供了宝贵的市场洞察和决策支持。本文将深入探讨Shopee数据分析工具如何帮助商家抓住商机并取得成功。 洞察消费者需求&#x…...

python——ydata-profiling介绍与使用
ydata-profiling介绍与使用 ydata-profiling的作用ydata-profiling的安装与简单使用ydata-profiling的结果结构 ydata-profiling的实际应用场景1. 数据集比较2. 时间序列报告3. 对大型数据集进行概要分析4. 处理敏感数据5. 自定义报告的外观 ydata-profiling的作用 ydata-prof…...

(纯c)数据结构之------>链表(详解)
目录 一. 链表的定义 1.链表的结构. 2.为啥要存在链表及链表的优势. 二. 无头单向链表的常用接口 1.头插\尾插 2.头删\尾删 3.销毁链表/打印链表 4.在pos位置后插入一个值 5.消除pos位置后的值 6.查找链表中的值并且返回它的地址 7.创建一个动态开辟的结点 三.顺序表与链表…...

postman接口自动化测试框架实战!
什么是自动化测试 把人对软件的测试行为转化为由机器执行测试行为的一种实践。 例如GUI自动化测试,模拟人去操作软件界面,把人从简单重复的劳动中解放出来。 本质是用代码去测试另一段代码,属于一种软件开发工作,已经开发完成的用…...

Apache Doris 入门教程35:多源数据目录
概述 多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。 在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接…...

响应式web-PC端web与移动端web(H5)兼容适配 选型方案
背景 项目需要,公司已经有一套PC端web,需要做一套手机端浏览器可用的,但是又想兼容pc端,适配的web项目。 以下是查阅到响应布局现成的开源模版。根据自己技术栈,vue2,js来搜索相关的开源项目。 RuoYi 使用若依快速…...

Redis持久化之RDB解读
目录 什么是RDB 配置位置参数解读 如何使用 自动触发 手动触发 save bgsave RDBRDB持久化文件的恢复 正常恢复 恢复失败处理方法 RDB优势 RDB 缺点 redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘…...

四维图新 minemap实现地图漫游效果
原理就是不断改变地图中心点,改变相机角度方向,明白这一点,其他地图引擎譬如cesium都可效仿,本人就是通过cesium的漫游实现四维图新的漫游,唯一不足的是转弯的时候不能丝滑转向,尝试过应该是四维图新引擎的…...
centos7安装MySQL8
Centos7安装MySQL8 MySQL版本:8.0.34 1.安装前准备 (1)查看是否安装mariadb [rootkb135 ~]# rpm -qa|grep mariadb (2)卸载mariadb并检查是否卸干净 [rootkb135 ~]# rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x8…...

【IMX6ULL驱动开发学习】10.Linux I2C驱动实战:AT24C02驱动设计流程
前情回顾:【IMX6ULL驱动开发学习】09.Linux之I2C框架简介和驱动程序模板_阿龙还在写代码的博客-CSDN博客 目录 一、修改设备树(设备树用来指定引脚资源) 二、编写驱动 2.1 i2c_drv_read 2.2 i2c_drv_write 2.3 完整驱动程序 三、上机测…...
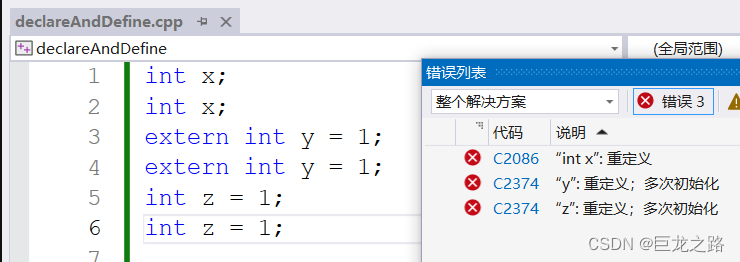
【C++】详解声明和定义
2023年8月28日,周一下午 研究了一个下午才彻底弄明白... 写到晚上才写完这篇博客。 目录 声明和定义的根本区别结构体的声明和定义声明结构体 定义结构体类的声明和定义函数的定义和声明声明函数 定义函数变量声明和定义声明变量定义变量 声明和定义的根本区别 …...

掌握C/C++协程编程,轻松驾驭并发编程世界
一、引言 协程的定义和背景 协程(Coroutine),又称为微线程或者轻量级线程,是一种用户态的、可在单个线程中并发执行的程序组件。协程可以看作是一个更轻量级的线程,由程序员主动控制调度。它们拥有自己的寄存器上下文…...

MyBatis-Plus的分页配置类
文章目录 package com.itheima.reggie.config;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; imp…...

从零构建高性能技术博客:SSG选型、自动化部署与SEO优化实战
1. 项目概述:一个技术博客的诞生与演进“wangtunan/blog”,这看起来只是一个简单的GitHub仓库名,背后却是一个技术人持续输出、构建个人知识体系的完整实践。它不仅仅是一个存放Markdown文件的代码库,更是一个集成了现代前端技术栈…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...

Cursor与Figma通过MCP协议实现AI辅助设计与开发同步
1. 项目概述:当代码编辑器与设计工具“开口说话”最近在开发者社区里,一个名为“cursor-talk-to-figma-mcp”的项目引起了我的注意。这个由开发者“hamadoun1760”开源的仓库,名字直译过来就是“Cursor与Figma对话的MCP”。乍一看,…...

基于RP2040的客制化宏键盘:从硬件设计到KMK固件开发全攻略
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫clawdpad,作者是kudretyilmazz。乍一看这个名字,可能有点摸不着头脑,但如果你对机械键盘、客制化输入设备或者桌面自动化感兴趣,那这个项目绝对值得你花时间…...

基于HalloWing的交互式徽章:传感器融合与事件驱动编程实践
1. 项目概述:当硬件开发遇上节日创意如果你和我一样,是个喜欢在万圣节搞点“技术流”小把戏的硬件爱好者,那么手头有一块Adafruit的HalloWing开发板,绝对能让你的节日装备脱颖而出。这不仅仅是一个简单的微控制器项目,…...

AI Agent无障碍审查:自动化集成WCAG标准与axe-core实践
1. 项目概述:一个为AI助手打造的“无障碍”审查官最近在折腾AI应用开发,特别是那些能自动处理任务的智能体(AI Agent),发现一个挺有意思但容易被忽略的问题:我们费尽心思让AI能写代码、分析数据、生成报告&…...