kafka学习笔记
1、kafka是什么?
kafka是一个高吞吐,分布式,基于发布/订阅的消息系统,最大的特性就是可以实时的处理大量的数据以满足各种需求场景:日志收集,离线和在线的消息消费,等等
2、kakfa的基础架构?
topic 主题:kafka根据topic对消息进行分类,发布到kafka上的每一条消息都要指定一个topic
producer 生产者: 向kafka主题发布消息的客户端
consumer 消费者: 订阅topic主题,读取消息的客户端
broker : 消息处理中间件,在kafka集群上,一个服务器就是一个broker
partition 分区: 为了实现拓展性,一个大的topic可以分布在多个broker上,也就是一个topic分为多个partition,每个partition的内部消息有序的
一些其他的定义:
consumer group:消费者组 ,多个consumer组成,消费者组中每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,消费者组之间的消费互不影响。
replica 副本:提升可用性,为每个partition增加若干个副本,分布在不同的broker上,避免某个broker不可用的时候,读不到消息
leader : 多个副本的主,生产者只会往leader上发送数据,消费者也只会从leader上读取数据,
follower: 多个副本的从,从leader中同步数据,当leader发生故障时,某个follower会成为新的leader。
offset 偏移量: 可以唯一的标识一条消息,消费者通过控制偏移量来决定下次去读的消息,消息被消费后,不会立刻被删除,这样,多个业务就可以重复的消费kafka的消息。

3、为什么要使用kafka,或者为什么要使用消息队列?
缓冲和削峰:某一时候,上游数据有突发流量,下游服务器没有足够的性能来保证性能,kafka在中间就可以起到一个缓冲的作用,把消息暂存在kafka中,即便某一时刻数据激增,下游的服务器也可以按照自己的节奏慢慢处理。
解耦增加拓展性:消息队列可以作为一个接口层,解耦业务流程(kafka想象成一个菜鸟驿站?)
一对多:一个生产者发布的消息,可以被多个消费者消费,供一些没有关联的业务同时使用
增强健壮性:消息队列可以堆积请求,因此即便消费端业务短时间内挂掉,也不会影响主要业务
异步通信:消息队列提供了异步处理机制,允许用户将一些消息放入队列,然后在合适的时间去处理。
4、数据传输的事务定义有那三种?
数据传输的事务定义有三种级别:
1、最多一次,消息不回重复发送,最多被传输一次,但也有可能一次不传输
2、最少一次,消息不会漏发,但是可能会被重复传输
3、精确的一次(exactly one):不会漏传,但是也不会重复传输,是大家所期望的。
5、kafka如何判断节点是否存活?
2.8.0一起,kafka是依赖zk的,因此判断是否存活的条件:
1、节点可以维护和zk的链接,这个是zk通过心跳机制来检查
2、如果节点是个follower,必须能够及时的同步leader的写操作,延时不能太久。
2.8.0版本以后,kafka移除了zk: 待补充
6、kafka消息是采用pull模式,还是push模式?
producer将消息推送到broker,consumer从broker上拉取消息。
好处是consumer可以自主决定从broker上拉取数据的速率。缺点是如果broker中没有可以供消费的消息,consumer就会不断的轮询,为了避免这点,kafka有个参数可以让consumer阻塞,直到消息到达。
7、kafka中的ISR, AR都是什么意思?ISR的伸缩是什么意思?
ISR:In-Sync Replicas 副本同步队列
AR: Assigned Replicas 已分配的副本,即所有副本
OSR:outof-Sync Replicas 表示follower与leader副本同步的时候,延迟过多的副本
ISR是由leader进行维护,follower从leader上同步数据会有一定的延迟,如果follower长时间未向leader发送通信请求同步数据,(延迟时间replica.lag.time.max.ms参数设定,默认30s)就会把follower从ISR中剔除,存入OSR列表,新加入的follower也会存在OSR中,即 AR = ISR + OSR
8、leader的选举流程?
kafka的broker启动后首先在在zk上注册controller节点,利用zk的强一直性,一个节点只能被一个客户端创建,该节点中写入当前broker的信息,创建成功的controller来决定leader的选举
选举出来的controller会监听集群broker节点的变化,然后决定选举leader:
partition的leader选举规则是:在ISR中存活为前提,按照AR中排在前面的优先。例如:ISR【1,0,2】,AR【1,0,2】,那么leader就会按照1,0,2轮询,此时leader就是broker1,
controller此时就会将节点信息上传到ZK,其他controller去ZK上同步节点的信息
假设某一时刻broker1 挂了,controller监听到节点的变化,就会更新ISR, 选举新的leader,然后将信息同步到ZK上

9、Leader 和 Follower 故障处理?
LEO(Log End Offset):每个副本的最后一个offset,LEO其实就是最新的offset + 1。HW(High Watermark):所有副本中最小的LEO 。

follower故障处理(如图):
- 某一时刻,三个broker的数据如上,高水位线HW为5,此时broker发生故障,follower2被踢出ISR
- 之后,leader和follower1并不受影响,因此可以继续接收并同步数据
- broker2恢复后,follower2会读取本地磁盘记录的上次的HW,也就是5,并将高于HW部门截取掉(删除,kafka认为这段数据未经过校验,不可信),然后开始向leader进行同步。
- 当follower2的同步的水平到了当前的水位线,就可以从新加入ISR了。
leader故障:
- leader发生故障,会从ISR中重新选出一个leader,
- 为了保证多个副本之间数据一致性,其他的follower会将高于leader的部分截掉,然后从新的leader同步数据。
可以看出,故障处理只能保证副本之间数据的一致性,但是不能保证数据不丢失,或者不重复。
10、kafka的文件存储机制:
topic是逻辑上的概念,partition是物理上的概念。
一个topic可以分成多个partition,每个partition对应一个log文件,log文件中存储的就是生产者生产的数据,每次producer生产新的数据,就会追加到log文件末端。
为了保证定位效率,kafka采用了分片和索引的机制:即每个partition又分为多个segment,每个segment包括 .log , .index,.timeindex等文件,一个segment默认是1G,超过1G就会生成一个新的segment。
.log 文件,记录生产信息
.index 记录偏移量,用于快速定位 (index是稀疏索引,每往log日志中记录4Kb数据,会记录一条索引,index文件中记录的offset为相对offset,参数log.index.interval,bytes=4kb, )
.timeindex 记录时间信息,kafka默认是数据保留7天,超过的会清理

11、kafka的文件清理策略:
kafka默认是数据保留7天,可以通过如下参数修改保存时间:
- log.retention.hours,最低优先级小时,默认 7 天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
日志一旦超过了设置的保留时间,将怎么清理呢?
1、delete删除:默认值。就是将过期日志直接删除:log.cleanup.policy = delete
以segment中所有记录中最大的时间戳作为该文件的时间戳。因此,如果一个segment中一部分数据过期,一部分数据没过期,那么是不会删除的。
2、compact 压缩:log.cleanup.policy = compact,相同key的不同value值,只保留最后一个版本(压缩后的offset不一定是连续的,只适用于特殊场景,如消息的key也是实际数据的key,一般不用。)
12、leader partition的负载平衡:
因为生产者和消费者操作的都是leader partition,如果集群出现了leader partition不平衡,就会导致broker压力太大。
一般情况下,kafka本身会自动把leader均匀分散在各个机器上,来保证每台机器的吞吐量都是均匀的,但是,如果某些broker宕机,leader重新选举,就可能导致leader partition过于集中在少部分broker上,这样一来,少数几台broker读写请求压力过高,造成了集群的负载不均衡。
auto.leader.rebalance.enable,默认是true,说明自动启用leader 再平衡
leader.imbalance.per.broker.percentage,默认是10%,每个broker允许的不平衡的leader的比率。如果某个broker超过了这个值,控制器会触发leader的平衡
leader.imbalance.check.interval.seconds,默认值300秒。检查leader负载是否平衡的间隔时间。

针对broker3节点,分区3的AR优先副本是3节点,但是3节点却不是Leader节点,所以不平衡数加1,AR副本总数是4
所以broker3节点不平衡率为1/4>10%,需要再平衡。
broker2和broker3节点不平衡率一样,需要再平衡。
broker0和broker1的不平衡数为0,不需要再平衡。
生产环境中,建议不要将自动再平衡打开,即便打开,也要将再平衡因子设置的大一些。
13、分区好处以及生产者发送消息的分区策略?
分区好处:
1、便于合理使用存储资源,每个partition在一个broker上存储,可以将海量数据按照分区切割成一块块数据,存储在多台broker上,合理控制分区的任务,实现负载均衡
2、提高并行度,生产者可以以分区为单位发送数据,消费者也可以以分区问单位消费数据。
生产者发送消息的分区策略:
1、如果指明了partition,直接将数据写入指明的分区
2、如果没有指明partition,但是有key的情况下,将key的hash值与该topic中partition的数量取余,存入对应的分区
3、既没有指定partition,也没有key的情况,kafka会采用粘性分区,即随机选取一个分区,并尽可能的一直使用该分区,如果该分区batch已满或者已经完成,则在随机选一个不同的分区。
14、生产者发送消息的流程?
在消息发送的过程,涉及到两个线程,一个main线程,一个是sender线程
- main线程创建了双端队列RecordAccumulator(消息累加器),消息经过拦截器,序列化器,分区器等,然后先存在 RecordAccumulator中 (每个分区都会创建一个双端队列,消息发送到哪个队列中参考13题)
- RecordAccumulator默认大小是32M(在内存中),RecordAccumulator包含多个双端队列,其实每个partition有一个双端队列,双端队列中有一个概念叫producerBatch,通过参数batch.size控制大小,默认大小是16k
- sender线程用来将队列中金的消息发往kafka集群,发送是以producerbatch为单位的,只有当数据累计到batch.size时,sender才会发送数据,如果数据量迟迟没有到batch.size,会有一个超时时间 linger.ms(默认值是0,表示没有延迟,需要修改),到达这个时间后也会发送数据。
- sender线程从 recordAccumulator 中拉取的 batch 先保存到 InFlightRequests 中,默认发往每个broker节点最多缓存5个请求(5个batch),sender线程发往kafka集群的broker时,可能会失败,而重试(重试次数默认是integer的最大值),由于失败重试原因,可能会存在消息乱序的风险。
- 数据成功发送到kafka集群后,会清理掉请求,清理掉消息累加器中对应的数据。

15、kafka中producer发消息到broker的应答原理,如何解决数据丢失问题?

ack应答原理:支持配置三种参数
- 0:生产者发送过来的数据,不需要等待数据落盘应答 ---- 可靠性差,效率高
- 1:生成者发送过来的数据,leader收到数据后应答 ---- 可靠性中等,效率中等
- -1:生成者发送过来的数据,leader和ISR队列里面的follower都收集数据后应答。 --- 可靠性最高,效率低
15.1:如果ack=-1, 但是有一个follower因为故障迟迟无法同步,这个问题怎么解决?
----还是靠ISR队列,如果follower长时间未向leader发送通信请求或者同步数据,就会被提出ISR,而ack=-1时只需要ISR队列中的所有节点响应即可。
数据完全可靠的条件是(解决数据丢失):ack=-1 + 分区副本大于等于2 + ISR应答最小副本数大于等于2
生产环境中,ack=0的基本很少用,ack=1的一般用于传输普通日志,允许个别数据的丢失,而ack=-1 一般用于对可靠性要求比较高的场景(如和钱有关)
如何解决数据丢失问题?
1、producer到kafka端:保证数据完全可靠,即ack=-1 + 分区副本大于等于2 + ISR应答最小副本数大于等于2
2、consumer消费端:业务端数据处理成功后,手动提交offset
16, kafka的幂等性,重复消费?
幂等性是指producer不论向broker发送多少次重复数据,broker端都只会持久化一条,保证了数据不重复。
精确一次 = 幂等性 + ack=-1 + 分区副本大于等于2 + ISR应答最小副本数大于等于2
幂等性判断数据重复性的一个标准是: PID + Partition + SeqNumber ,相同的主键消息提交时,broker只会持久化一条。
- PID:kafka每次重启就会分配一个新的PID(每个producer在初始化的时候都会分配一个唯一的PID,这个PID对用户不可见)
- partition:分区号
- Sequence Number: 单调递增的一个值,针对每个producer,发送到指定主体分区的消息都对应一个从0递增的Sequence Number
---- 所以可以知道,幂等性只能保证的是在但分区单会话内不重复,消费端消费的时候,也要利用幂等性原理解决,给每条数据加一个唯一标识,保证数据不会被重复消费。
----kafka开启事务必须要开启幂等性。
17、kafka数据乱序?
为什么会乱序?
kafka的sender线程是先将数据请求放到一个in Flight requests 队列里面,这个队列最大允许放置5个请求,每个请求发送到kafka的broker上时,允许在未响应的前提下发送后一个请求,这就有可能导致了乱序(比如1,2,请求发送成功并应答,发送3的时候没有应答就发送了4,结果3发送失败,4发送成功,这就导致了顺序是1,2,4)
如何有序?
- 在1.x版本之前:
- max.in.flight.requests.per.connection=1(不考虑幂等性),阻塞之前,客户端在单个连接上发送的未确认最大请求是1,即每发送一个请求,都要得到成功响应之后在发送第二个。这就保证了有序性
- 在1.x版本之后:
- 未开启幂等性,max.in.flight.requests.per.connection=1
- 开启幂等性,max.in.flight.requests.per.connection 要小于等于5,kafka服务端会缓存5个请求的元数据,根据SeqNumber是否递增来判断,还是上面的情况,1,2发送成功会先落盘,3失败了需要重试,4,5成功了,但是因为SeqNumber是从4开始的,因此会被先缓存起来,等到3发送到kafka时,才会排序之后落盘。
但是需要注意的是,kafka只是保证了单分区内有序,多个分区是不保证的。
为什么多分区有序不保证?
如果kafka保证多个partition内的消息也是有序的,不仅broker保存的数据要有序,消费者消费时的也要按照顺序消费,假设partition1阻塞了,其他分区的消息也不能被消费了,这种情况,kafka就退化成了单一队列,失去了并发性和性能。
有没有办法保证整个topic级别的消息顺序性?
可以在业务层面解决:
- 通过message key 来保证需要顺序性消费的数据发送到同一个partition(单分区有序)
- 消费端消费前先把多个partition内的消息缓存下来,全部拿到后重排序,保证顺序性消费
但是上述操作其实降低了性能,不如就只创建一个分区。
18、消费者的总体工作流程?
- 一个消费者可以消费多个分区,
- 一个分区也可以被多个消费者消费
- 一个分区只能够被一个消费者组中的一个消费者消费(消费者组看成是一个消费者)

消费者组:
consumer group:消费者组,由多个consumer组成,形成一个消费者组的条件,是消费者的group id相同。(一个consumer也可以是一个消费者组)
- 消费者组内每个消费者负责消费不同的分区数据,一个分区只能由一个组内的消费者消费
- 消费者组之间互不影响
- 如果消费者组内消费者超过主体分区数量,那么就会有一部分消费者闲置,不会接收任何消息(消费者组从逻辑上,就是一个消费者)。
19、消费者组的初始化流程?
- 消费者组的初始化和分区分配是 由coordinator辅助实现的,每个broker节点都会有一个coordinator,kafka会根据group id 计算出一个节点的coordinator来作为该消费者组的老大。消费者组下面所有消费者提交的offset都会往该节点去提交
- 选举出来的coordinator会在消费者组中随机选一个consumer作为消费者组的leader
- 然后coordinator会把要消费的topic情况发给这个消费者组的leader
- 消费者leader会通过一些规则定制消费方案
- 定制好消费方案后,将该消费方案发回给选出的coordinator
- coordinator吧消费方案下发给消费者组的各个消费者
- 每个消费者都会和coordinator保持心跳(默认3s),超时(45s)或者处理消息时间过长(5min),都会移除该消费者,触发再平衡。

20、消费者组详细消费流程?
-
消费者发送消费请求 ,通过sendFetches方法, 做一个抓取数据的初始化,准备一些数据
- Fetch.min,bytes 每批次最小抓取数据,默认1字节,小于这个值不抓取
- fetch.max.waits.ms 每次抓取超时时间,默认500ms,如果迟迟不到1字节,这个就触发抓取
- fetch.max.bytes 每批次抓取最大数量,默认50m
- 准备好后就调用send方法,发送消费请求,通过回调方法onSuccess拉取对应的数据
- 拉取到的数据放到一个消息队列里面
- 消费者会从队列中一批次的拉取数据进行数据处理,默认一次500条(Max.poll.records设置)
- 数据处理就包括了数据的反序列化,拦截器,以及业务处理。

21、消费者的分区分配策略(再平衡机制)?
kafka的消费者再平衡,指kafka consumer订阅的topic发生变化时,一种分区重分配机制。
一般如下三种情况会触发consumer的分区分配策略(再平衡机制):
- consumer group中删除了某个consumer(离线),导致所消费的分区需要重新分配到组内其他consumer上
- consumer订阅的topic主题发生了变化,比如订阅的topic是按照正则配置的,如果新增了一个topic,新topic的分区怎么分配给当前consumer
- 已经订阅的topic新增了分区,新增的分区怎么分配到consumer
消费者分区分配策略实现的方法有以下四种机制:
- RangeAssignor 范围分区策略
- RoundRobinAssignor 轮询分区策略
- StickyAssignor 粘性分区策略
- CooperativeStickyAssignor 协作粘性分区策略
通过consumer配置项partition.assignment.strtegy指定分区分配策略类,kafka可以同时使用多个分区分配策略。
kafka默认就是使用range+CooperativeStucky策略。同时,也支持自定义策略,重写ConsumerPartitionAssignor接口。
RangeAssignor 范围分区分配策略:
解释:是按照单个topic为一个维度来计算分配的,负责将每一个的topic尽可能的均衡分配给其他的消费者
- 给消费者组里面所有消费者按照字母进行排序,给topic中的分区按照分区号排序
- 计算每个消费者最少平均分配多少个分区数,然后剩下的按照消费者顺序逐个分。
示例:
一个topic有四个分区,消费者组中有三个消费者,那么就先进行排序,计算,发现每个消费者最少一个分区,还多了一个分区,那么就分给consumer1
缺点:
range方法虽然针对单个topic情况下比较均衡,但是如果topic很多,consumer排序靠前的消费者负载会变多。
RoundRobinAssignor 轮询分区策略:
解释:轮询针对的是所有的topic分区,他把所有的partition、所有的consumer列举出来进行排序,然后通过轮询策略分配给每个消费者(如果该消费者没有订阅该主题,就跳到下一个消费者)
示例:
1、如果消费者订阅的主题是一样的:

2、如果消费者订阅的主题不一样:

缺点:
就如示例2的情况,消费者分区分配很不平衡,因此consumer group订阅消息不一致的情况下,不太适用于轮询机制。
StickyAssignor 粘性分区策略:
- 粘性分区策略,分区的分配要尽可能的均匀,分配给消费者的主题分区数最多相差一个
- 分区的分配会尽可能与上次分配保持相同,
- 两个有冲突的时候,第一个目标优先于第二个目标。
例如:三个consumers(C0、C1、C2),四个Topics(T0、T1、T2、T3)。
则RoundRobinAssignor和StickyAssignor分区分配方案均为:
C0 T0P0、T1P1、T3P0
C1 T0P1、T2P0、T3P1
C2 T1P0、T2P1
现在,假设C1被移除,将触发分区重分配:
RoundRobinAssignor分区分配方案将变为:
C0 T0P0、T1P0、T2P0、T3P0
C2 T0P1、T1P1、T2P1、T3P1
保留之前的分区分配方案的3个分区不变。
StickyAssignor分区分配方案将变为:
C0 T0P0、T1P1、T3P0、T2P0
C2 T1P0、T2P1、T0P1、T3P1
可以看到StickyAssignor尽量保存之前的分区分配方案,分区重分配变动更小。
CooperativeStickyAssignor策略:
CooperativeStickyAssignor其实也是一种粘性分配策略,但是有一定的区别:
- StickyAssignor仍然是基于eager协议,分区重分配时候,都需要consumers先放弃当前持有的分区,重新加入consumer group;
- 而CooperativeStickyAssignor基于cooperative协议,该协议将原来的一次全局分区重平衡,改成多次小规模分区重平衡。渐进式的重平衡。
示例:
一个Topic(T0,三个分区),两个consumers(consumer1、consumer2)均订阅Topic(T0)。那么分配完成的订阅信息就是:
| consumer1 | T0P0、T0P2 |
|---|---|
| consumer2 | T0P1 |
此时,如果一个新的consumer3加入消费者组,就会触发再平衡:
基于eager协议的 粘性分区策略:
1、consumer1、 consumer2正常发送心跳信息到Group Coordinator。
2、随着consumer3加入,Group Coordinator收到对应的Join Group请求,Group Coordinator确认有新成员需要加入消费者组。
3、Group Coordinator 通知consumer1和consumer2,需要rebalance(再平衡)了。
4、consumer1和consumer2放弃(revoke)当前各自持有的已有分区,重新发送Join Group请求到Group Coordinator。
5、Group Coordinator依据指定的分区分配策略的处理逻辑,生成新的分区分配方案,然后通过Sync Group请求,将新的分区分配方案发送给consumer1、consumer2、consumer3。
6、所有consumers按照新的分区分配,重新开始消费数据。
基于cooperative协议的粘性分区策略:
1、consumer1、 consumer2正常发送心跳信息到Group Coordinator。
2、随着consumer3加入,Group Coordinator收到对应的Join Group请求,Group Coordinator确认有新成员需要加入消费者组。
3、Group Coordinator 通知consumer1和consumer2,需要rebalance了。
4、consumer1、consumer2通过Join Group请求将已经持有的分区发送给Group Coordinator。注意:并没有放弃(revoke)已有分区。
5、Group Coordinator取消consumer1对分区p2的消费,然后发送sync group请求给consumer1、consumer2。
6、consumer1、consumer2接收到分区分配方案,重新开始消费。至此,一次Rebalance完成。
7、当前p2也没有被消费,再次触发下一轮rebalance,将p2分配给consumer3消费。
可以看到,上述两个协议的区别在于:
- EAGER :重新平衡协议要求消费者在参与重新平衡事件之前始终撤销其拥有的所有分区。因此,它允许完全改组分配。
- COOPERATIVE:协议允许消费者在参与再平衡事件之前保留其当前拥有的分区。分配者不应该立即重新分配任何拥有的分区,而是可以指示消费者需要撤销分区,以便可以在下一次重新平衡事件中将被撤销的分区重新分配给其他消费者。
COOPERATIVE协议将全局重平衡,改成了每次小规模的重平衡,从而达到最终的平衡,这样做的好处就是所选了STW时间。
22、offset位移 是什么?维护的位置?
offset 位移就是consumer记录的已经消费数据的位置。在0.9版本以前是保存在zookeeper中的,从0.9版本之后,默认将offset保存在kafka一个内置的topic日志文件后,该topic名称为:__consumer_offsets
__consumer_offsets 主题里面采用 key 和 value 的方式存储数据:
- key: group.id+topic+分区号
- value: 当前offset的值
每隔一段时间,kafka会对这个topic进行压缩,也就是每个key只保留最新数据。
22.1 为什么消费者需要使用50个文件记录消费者的offset呢?
如果消费者比较多,都记录在同一个记录中,那么读写的操作就比较麻烦
22.2 消费者怎么知道应该从哪个日志文件中读取数据?
key%50(文件数量),然后就可以到对应的文件夹中去取值。
23、kafka中consumer offset的提交?
- 自动提交:
- 默认开启,enable.auto.commit=true,
- 提交时间间隔,默认5s:auto.commit.interval.ms
- 手动提交:
- 同步提交:必须等offset提交完毕,再去消费下一批数据(存在提交失败的场景,会不断重试)
- 异步提交:发送完offset请求后,就开始消费下一批数据了(生产环境用的比较多)
24、kafka指定offset的消费:
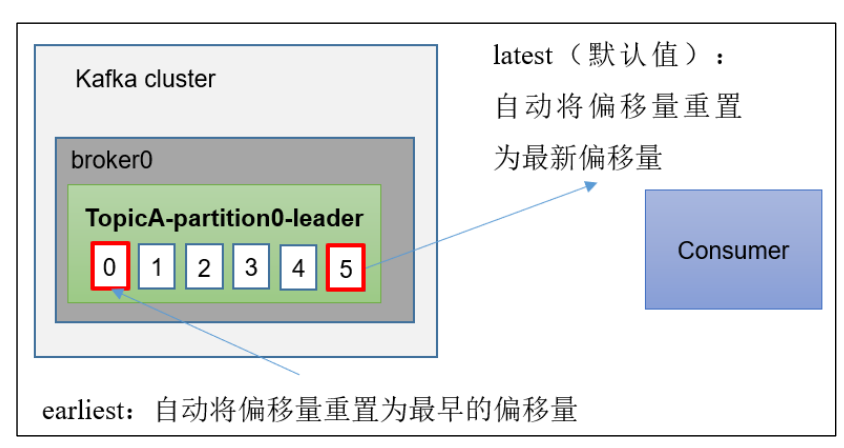
当kafka中没有初始偏移量(消费者组第一次消费),或者服务器上没有存在偏移量(数据被删除),应该怎么消费呢?kafka提供了三种消费方式:
- earliest:自动将偏移量重置为最早的偏移量
- latest:自动将偏移量重置为最新偏移量(以前没消费到的也不管了) --- 默认值
- none:如果没有找到消费者组的先前偏移量,那么就向消费者抛出异常。
25、kafka按照指定时间消费:
在生产环境中,会遇到最近消费的几个小时数据异常,想重新按照时间消费。例如要求按照时间消费前一天的数据,怎么处理?
kafkaConsumer.offsetsForTimes(); 这个API可以将时间转换为offset。
26、kafka数据积压,消费者如何提高吞吐量?
1、如果是kafka消费能力不足,可以考虑增加topic的分区数目,同时增加消费者组的消费者数量,消费者数目= topic的分区数
2、如果是下游数据处理不及时,可以考虑提高每批次拉取消息的数量(同时要注意修改每批次最大拉取大小。)
3、上游消费者也可以提示生产吞吐量来增大整个kafka的吞吐量,如增大发送消息缓冲区的大小以及增大batch.size,避免频繁网络请求
相关文章:
kafka学习笔记
1、kafka是什么? kafka是一个高吞吐,分布式,基于发布/订阅的消息系统,最大的特性就是可以实时的处理大量的数据以满足各种需求场景:日志收集,离线和在线的消息消费,等等 2、kakfa的基础架构&am…...
阀门状态监测和预测性维护的原理和实施步骤
随着制造业数字化转型的推进,预测性维护(Predictive Maintenance,简称PdM)成为提高生产效率和设备可靠性的关键策略之一。在流程工厂中,阀门作为重要的设备之一,起着控制流体流动的关键作用。本文将探讨如何…...
复习之web服务器--apache
PS:Vim复制小技巧 一、实验环境 两台虚拟机 (nodea,nodeb)配置ip搭建软件仓库关闭selinux [rootftp Desktop]# hostnamectl set-hostname nodea.westos.org [rootftp Desktop]# hostname nodea.westos.org [rootftp Desktop]# ifconfig enp1s0: flags4163<UP,B…...

[Unity] 单例设计模式, 可供继承的单例组件模板类
一个可供继承的单例组件模板类: public class SingletonComponent<TComponent> : Componentwhere TComponent : SingletonComponent<TComponent> {static TComponent _instance;private static TComponent GetOrFindOrCreateComponent(){// 双检索if (_instance …...
Linux知识点 -- Linux多线程(三)
Linux知识点 – Linux多线程(三) 文章目录 Linux知识点 -- Linux多线程(三)一、线程同步1.概念理解2.条件变量3.使用条件变量进行线程同步 二、生产者消费者模型1.概念2.基于BlockingQueue的生产者消费者模型3.单生产者单消费者模…...

android java 硬编码保存mp4 jni数据转换
目录 java imagereader编码保存 java NV21toYUV420SemiPlanar 编码保存视频用: imageReader获取nv21 jni NV12toYUV420SemiPlanar函数: 代码来自博客: 【Android Camera2】彻底弄清图像数据YUV420_888转NV21问题/良心教学/避坑必读!_yuv…...

那些你不得不知道的HTML知识点
目录 1、行内元素有哪些?块级元素有哪些? 空(void)元素有哪些?2、页面导入样式时,使用link和import有什么区别?3、title与h1的区别、b与strong的区别、i与em的区别?3.1 title与h1的区别:3.2 b与…...

如何复制主播的性格(此乃广告文)
上面这份ppt写于Fay开源之前。当然,以现在的认知再去评价当时的设计,会发现有诸多的不严谨,甚至缺憾。比如,以单层的网络结构肯定无法拟合人性这个复杂的东西,人性也不是只受已知的几个参数所作用。但我现在想说的是&a…...

【ES6】—【新特性】—Symbol详情
一、一种新的原始数据类型 定义:独一无二的字符串 二、 声明方式 1. 无描述声明 let s1 Symbol() let s2 Symbol() console.log(s1, s2) // Symbol() Symbol() console.log(s1 s2) // falsePS: Symbol 声明的值是独一无二的 2. 有描述的声明 let s1 Symb…...

openresty安装与网站发布
文章目录 安装依赖下载安装包解压安装包安装启动nginx配置环境变量配置开机启动发布静态网站 OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动…...
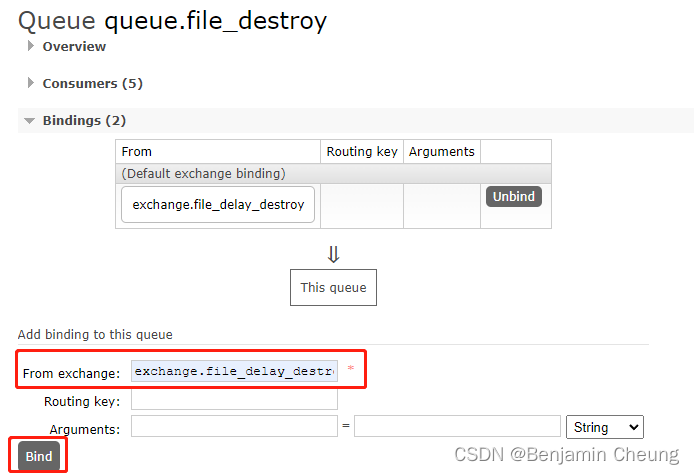
创建延时队列、springboot配置多个rabbitmq
创建延时队列 queue.file_delay_destroy x-dead-letter-exchange: exchange.file_delay_destroy x-message-ttl: 259200000 259200000为3天,1000为1秒创建普通队列 queue.file_destroy创建普通交换机 exchange.file_delay_destroytype选择fanout 交换机绑定普通队列 (图中…...

在kaggle中用GPU使用CGAN生成指定mnist手写数字
文章目录 1项目介绍2参考文章3代码的实现过程及对代码的详细解析独热编码定义生成器定义判别器打印我们的引导信息模型训练迭代过程中生成的图片损失函数的变化 4总结5 模型相关的文件 1项目介绍 在GAN的基础上进行有条件的引导生成图片cgan 2参考文章 GAN实战之Pytorch 使用…...

【NI USRP】哪些 USRP 设备支持全双工,哪些支持半双工?
译者 东枫电子科技 设备构成 NI USRPEttus USRPUSRP-2900B200USRP-2901B210USRP-2920N210 WBXUSRP-2921N210 XCVR 2450USRP-2922N210 SBXUSRP-2930N210 WBX GPSDOUSRP-2932N210 SBX GPSDOUSRP-2940RX310 WBX (x2)USRP-2942RX310 SBX (x2)USRP-2943RX310 CBX (x2)U…...

不拼花哨,只拼实用:unittest指南,干货为王!
Python为开发者提供了内置的单元测试框架 unittest,它是一种强大的工具,能够有效地编写和执行单元测试。unittest 提供了完整的测试结构,支持自动化测试的执行,能够对测试用例进行组织,并且提供了丰富的断言方法。最终…...

mysql 获取json数组中某个字段根据下标
MySQL获取JSON数组中某个字段根据下标 在MySQL中,JSON数据类型可以方便地存储、操作和查询包含复杂结构的数据。当我们需要从JSON数组中获取某个字段时,可以使用MySQL的JSON函数来实现。 1. JSON数据类型简介 JSON(JavaScript Object Nota…...

深入理解Redis缓存穿透、击穿、雪崩及解决方案
深入理解Redis缓存穿透、击穿、雪崩及解决方案 一、简介Redis 简介缓存作用与优化 二、缓存问题的分类缓存穿透缓存击穿缓存雪崩 三、缓存穿透的解决方案布隆过滤器缓存空对象接口层校验 四、缓存击穿的解决方案互斥锁热点数据提前加载 五、缓存雪崩的解决方案增加缓存容错能力…...

java八股文面试[java基础]——字节码
字节码技术应用 字节码技术的应用场景包括但不限于AOP,动态生成代码,接下来讲一下字节码技术相关的第三方类库,第三方框架的讲解是为了帮助大家了解字节码技术的应用方向,文档并没有对框架机制进行详细分析,有兴趣的可…...

新能源汽车技术的最新进展和未来趋势
文章目录 电池技术的进步智能驾驶与自动驾驶技术充电基础设施建设新能源汽车共享和智能交通未来趋势展望结论 🎉欢迎来到AIGC人工智能专栏~探索新能源汽车技术的最新进展和未来趋势 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客…...
知虾shopee数据分析工具:shopee出单的商机利器
当今数字化时代,数据已经成为商业成功的关键要素之一。而Shopee作为东南亚最大的电商平台之一,其强大的数据分析工具正为商家提供了宝贵的市场洞察和决策支持。本文将深入探讨Shopee数据分析工具如何帮助商家抓住商机并取得成功。 洞察消费者需求&#x…...

python——ydata-profiling介绍与使用
ydata-profiling介绍与使用 ydata-profiling的作用ydata-profiling的安装与简单使用ydata-profiling的结果结构 ydata-profiling的实际应用场景1. 数据集比较2. 时间序列报告3. 对大型数据集进行概要分析4. 处理敏感数据5. 自定义报告的外观 ydata-profiling的作用 ydata-prof…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

单元体幕墙计算方法研究
单元体幕墙计算方法研究 一、单元板块计算 选择隔离的单个单元进行计算,不需要考虑周边单元的影响。 单元之间的相互影响,来自于左右立柱的变形不一致,在截面选择上反应的就是左右立柱的截面参数的不同。 所以,单元间的相互影响,可以通过控制左右立柱截面参数的相近而进…...

婚礼技能库:用开源协作与项目管理思维打造个性化婚礼
1. 项目概述:婚礼技能库的诞生与价值婚礼,对大多数人来说,是人生中为数不多的、需要同时扮演项目经理、创意总监、财务主管和情感联络员的高压事件。筹备过程琐碎繁杂,从场地布置、流程设计,到妆发造型、摄影摄像&…...

C++定时器避坑指南:线程安全、资源泄漏与时间轮参数怎么调?一次讲清楚
C定时器避坑指南:线程安全、资源泄漏与时间轮参数调优实战 在分布式系统和高并发场景中,定时器如同系统的心跳机制,其稳定性直接决定服务可靠性。去年某电商平台大促期间,由于定时任务堆积导致的雪崩效应,造成近千万损…...

Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生!
Windows Cleaner终极指南:3步彻底解决C盘爆红问题,让电脑重获新生! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Wind…...

开源银行API模拟器Bankr Buddy:金融科技开发的本地化测试解决方案
1. 项目概述:一个为开发者准备的银行API模拟器如果你正在开发一个需要与银行账户数据打交道的应用,无论是个人财务管理工具、预算分析软件,还是企业级的财务聚合服务,你肯定遇到过同一个难题:如何在不触碰真实用户敏感…...

Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞!
Windows Cleaner终极指南:三步告别C盘爆红,让电脑运行如飞! 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统…...

终极指南:如何为你的Mac鼠标安装强大定制功能
终极指南:如何为你的Mac鼠标安装强大定制功能 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命性的开源工具…...