python 模块BeautifulSoup 从HTML或XML文件中提取数据
一、安装
Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
pip install beautifulsoup4
二、使用案例
from bs4 import BeautifulSoup
import requests
import asyncio
import functools
import rehouse_info = []'''异步请求获取链家每页数据'''
async def get_page(page_index):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}request = functools.partial(requests.get, f'https://sh.lianjia.com/ershoufang/pudong/pg{page_index}/',headers=headers)loop = asyncio.get_running_loop()response = await loop.run_in_executor(None, request)return response'''使用xpath获取房屋信息'''
def get_house_info(soup):house_info_list = soup.select('.info') # 房屋titlereg = re.compile(r'\n|\s')for html in house_info_list:house_info.append({'title': re.sub(reg,'',html.select('.title a')[0].getText()),'house_pattern': re.sub(reg,'',html.select('.houseInfo')[0].getText()),'price': re.sub(reg,'',html.select('.unitPrice')[0].getText()),'location': re.sub(reg,'',html.select('.positionInfo')[0].getText()),'total': re.sub(reg,'',html.select('.totalPrice')[0].getText())})'''异步获取第一页数据,拿到第一页房屋信息,并返回分页总数和当前页'''
async def get_first_page():response = await get_page(1)soup = BeautifulSoup(response.text, 'lxml')get_house_info(soup)print(house_info)if __name__ == '__main__':asyncio.run(get_first_page())三、创建soup对象
soup = BeautifulSoup(markup=“”, features=None, builder=None,parse_only=None, from_encoding=None, exclude_encodings=None,element_classes=None)
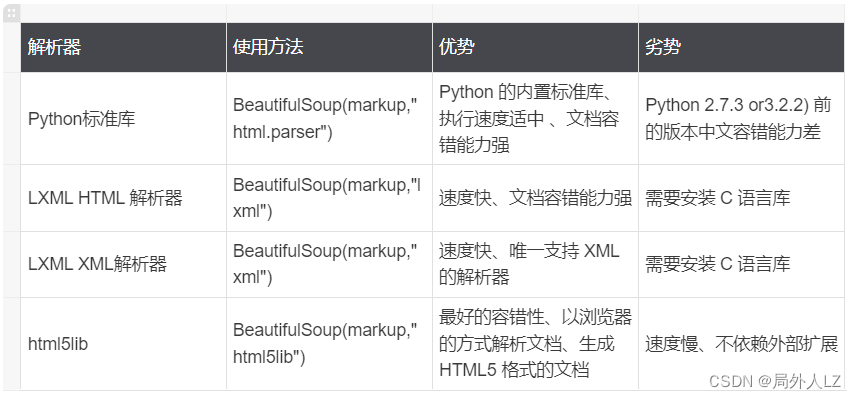
- markup:要解析的HTML或XML文档字符串。可以是一个字符串变量,也可以是一个文件对象(需要指定"html.parser"或"lxml"等解析器)。
- features:指定解析器的名称或类型。默认为"html.parser",可以使用其他解析器如"lxml"、"html5lib"等。
- builder:指定文档树的构建器。默认为None,表示使用默认构建器。可以使用"lxml"或"html5lib"等指定其他构建器。
- parse_only:指定要解析的特定部分。可以传递一个解析器或一个标签名或一个元素的列表。
- from_encoding:指定解析器使用的字符编码。默认为None,表示自动检测编码。
- exclude_encodings:指定要排除的编码列表,用于字符编码自动检测。
- element_classes:指定要用于解析文档的元素类。默认为None,表示使用默认元素类。
四、soup对象
- soup.prettify(encoding=None, formatter=“minimal”):返回格式化后的HTML或XML文档的字符串表示。它将文档内容缩进并使用适当的标签闭合格式,以提高可读性
- soup.title:返回文档的
标签的内容,如果存在的话 - soup.head:返回文档的标签的内容,作为一个BeautifulSoup对象
- soup.body:返回文档的标签的内容,作为一个BeautifulSoup对象
- soup.html:返回文档的标签的内容,作为一个BeautifulSoup对象
- soup.find(name, attrs, recursive, string)):在文档中查找具有指定名称和属性的第一个元素,并返回该元素的BeautifulSoup对象。可以使用name参数指定标签名称,使用attrs参数指定属性字典,使用recursive参数指定是否递归搜索子元素,使用string参数指定元素的文本内容,还可以使用其他关键字参数指定其他属性条件
- soup.find_all(name, attrs, recursive, string, limit)):在文档中查找具有指定名称和属性的所有元素,并返回这些元素的列表。参数和用法与find()方法相似,但它会返回所有匹配的元素
- soup.select(selector)):使用CSS选择器语法在文档中查找元素,并返回匹配的元素列表。选择器可以是标签名、类名、id、属性等。返回的是一个BeautifulSoup对象的列表
- soup.get_text():获取文档中所有元素的文本内容,并将它们连接成一个字符串返回
- soup.get(attrName):获取属性值
- soup.find_parents(name, attrs, recursive, string)):在文档中查找具有指定名称和属性的所有父元素,并返回这些父元素的列表
- soup.find_next_sibling(name, attrs, string)):在文档中查找具有指定名称和属性的下一个同级元素,并返回该元素的BeautifulSoup对象
- soup.find_previous_sibling(name, attrs, string)):在文档中查找具有指定名称和属性的上一个同级元素,并返回该元素的BeautifulSoup对象
- soup.find_next(name, attrs, string)):在文档中查找具有指定名称和属性的下一个元素,并返回该元素的BeautifulSoup对象
- soup.find_previous(name, attrs, string)):在文档中查找具有指定名称和属性的上一个元素,并返回该元素的BeautifulSoup对象
- soup.decompose(): 从文档中移除当前元素,并清理其占用的内存。
- soup.encode(formatter=None): 将解析后的文档编码为字节字符串。
- soup.decode(encoding=“utf-8”, errors=“strict”): 将字节字符串解码为Unicode字符串。
- soup.new_tag(name, namespace=None, attrs={}, **kwargs)
- soup.new_string(s, parent=None): 创建一个新的字符串对象。
- soup.replace_with(replacement): 将当前元素替换为指定的元素或字符串。
- soup.wrap(wrapper): 将当前元素包装在指定的包装器标签中。
from bs4 import BeautifulSouphtml_str = '<html><head><title>我是标题</title></head><body><div><div class="div1">我是div1</div><div class="div2">我是div2</div><div class="div3">我是div3</div></div></body</html>'soup = BeautifulSoup(html_str, 'lxml')
print('title:',soup.title)
print('head:', soup.head)
print('body:', soup.body)
print('html:', soup.html)
print('find:', soup.find('div',attrs={'class':'div1'}))
print('find_all:', soup.find_all('div'))
print('select:', soup.select('.div1'))
print('get_text:', soup.select('.div1')[0].get_text())
print('get:', soup.select('.div1')[0].get('class'))
div1 = soup.select('.div1')[0]
print('find_parents:', div1.find_parents('div'))
print('find_next_sibling:', div1.find_next_sibling())
print('find_previous_sibling:', div1.find_previous_sibling())
print('find_next:', div1.find_next())
print('find_previous:', div1.find_previous())
相关文章:
python 模块BeautifulSoup 从HTML或XML文件中提取数据
一、安装 Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。 lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多…...

VS Code插件汇总
插件 Basic Chinese(Simplified) Language Pack C/C C/C CMake Tools C/C Extension Pack Web Open in browser Microsoft Edge Tool Linux WSL Tool AWS Toolkit Bito AI Code Assistant CursorCode TabNine IntelliCode Kite...

QWidget
文章目录 QWidget是Qt中用于创建用户界面的基类之一,其拥有许多成员函数、槽函数、信号、静态函数和枚举。虽然无法在此提供所有的函数和枚举,但以下是一些常用的例子: 成员函数: 设置父窗口的函数: void setParent(…...

【大数据】Linkis:打通上层应用与底层计算引擎的数据中间件
Linkis:打通上层应用与底层计算引擎的数据中间件 1.引言2.背景3.设计初衷4.技术架构5.业务架构6.处理流程7.如何支撑高并发8.用户级隔离度和调度时效性9.总结 Linkis 是微众银行开源的一款 数据中间件,用于解决前台各种工具、应用,和后台各种…...
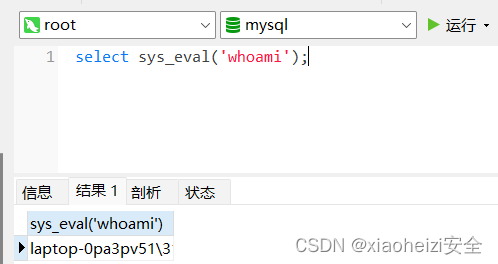
权限提升-数据库提权-MSF-UDF提权
权限提升基础信息 1、具体有哪些权限需要我们了解掌握的? 后台权限,网站权限,数据库权限,接口权限,系统权限,域控权限等 2、以上常见权限获取方法简要归类说明? 后台权限:SQL注入,数…...

基于XL32F003单片机的可控硅调光方案
可控硅调光是一种用于调节电源输出电压的技术,被广泛应用于各种场景。它主要通过改变波形的导通角度来调节输出电压的大小,从而实现对照明设备亮度的控制。在照明市场占据了很大的调光市场。 可控硅调光的兼容性强,应用范围广。例如ÿ…...
【ag-grid-vue】列定义(Updating Column Definitions)
列定义一节解释了如何配置列。可以在初始设置列之后更改列的配置。本节介绍如何更新列定义。 添加和删除列 可以通过更新提供给网格的列定义列表来添加和删除列。当设置新列时,网格将与当前列进行比较,并计算出哪些列是旧的(要删除)、哪些列是新的(创建…...
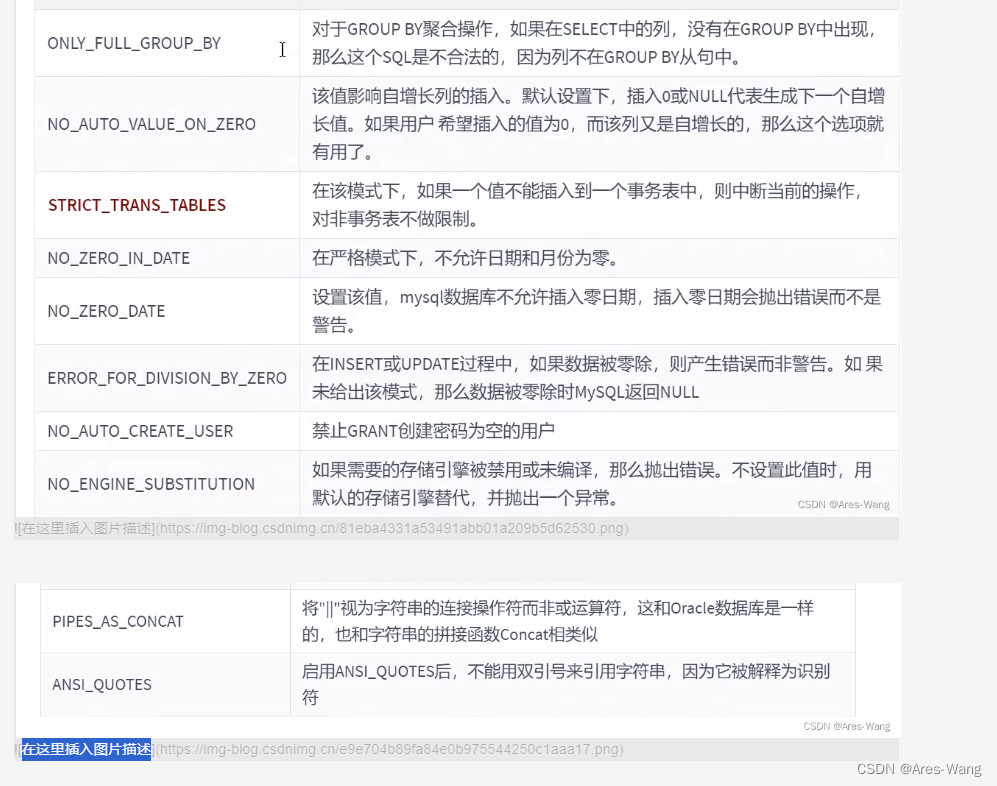
mysql sql_mode数据验证检查
sql_mode 功能 sql_mode 会影响MySQL支持的sql语法以及执行的数据验证检查。通过设置sql_mode ,可以完成不同严格程度的数据校验,有效地保障数据准确性 sql_mode 严格模式 VS 宽松模式 宽松模式 比如,插入的数据不满足 表的数据类型,也可能…...

Prompt召唤 AI “生成”生产力,未来已来
如果说 2023 年的 AI 为世界带来了怎样的改变,那么大模型的狂飙发展, 无疑一马当先。以人机交互为例,“提示词工程师”(又称“AI 召唤师”)成为 21 世纪最脑洞大开的新兴职业,用自然语言写代码、召唤计算机…...

【0day】复现时空智友企业流程化管控系统SQL注入漏洞
目录 一、漏洞描述 二、影响版本 三、资产测绘 四、漏洞复现 一、漏洞描述 时空智友企业流程化管控系统是一个用于企业流程管理和控制的软件系统。它旨在帮助企业实现流程的规范化、自动化和优化,从而提高工作效率、降低成本并提升管理水平。时空智友企业流程化管控系统存…...
)
python编程中fft的优缺点,以及如何使用cuda编程,cuda并行运算,信号处理(推荐)
A.python中cuda编程的库主要有: cupy、pycuda 1,区别如下: 支持的GPU平台: PyCUDA:PyCUDA是一个用于在Python中编写CUDA代码的库。它支持NVIDIA的CUDA平台,并提供了与CUDA C/C++接口相似的功能。因此,PyCUDA主要用于与NVIDIA GPU交互的应用。 CuPy:CuPy是一个用于在P…...
)
统计学补充概念-16-支持向量机 (SVM)
概念 支持向量机(Support Vector Machine,SVM)是一种用于分类和回归的机器学习算法。SVM的主要目标是找到一个最优的超平面,可以将不同类别的数据样本分开,同时使得支持向量(离超平面最近的样本点…...
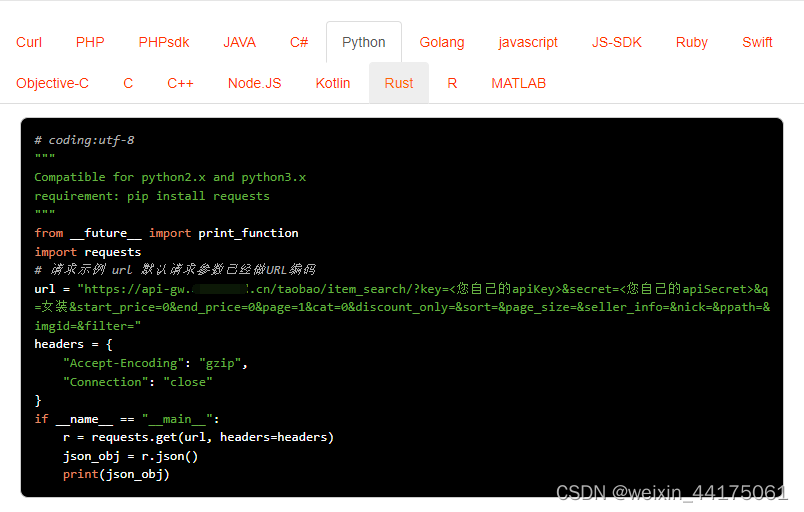
Python“牵手”天猫商品列表数据,关键词搜索天猫API接口数据,天猫API接口申请指南
天猫平台API接口是为开发电商类应用程序而设计的一套完整的、跨浏览器、跨平台的接口规范,天猫API接口是指通过编程的方式,让开发者能够通过HTTP协议直接访问天猫平台的数据,包括商品信息、店铺信息、物流信息等,从而实现天猫平台…...

SQL 错误 [22007]: ERROR: invalid input syntax for type date: ““
0. 背景 PG数据库一张表有这样一个varchar类型的字段end_date,存储的值是格式化后的年月日日期如 2024-08-10 现在我需要根据当前日期与end_date的差值作为where条件过滤,我的写法 select …… from my_table_name where current_date - cast (end_date as date) >100报错…...
SpringBootWeb案例 Part 2
目录 3. 员工管理 3.1 分页查询 3.1.1 基础分页 3.1.1.1 需求分析 3.1.1.2 接口文档 3.1.1.3 思路分析 3.1.1.4 功能开发 PageBean 3.1.1.5 功能测试 3.1.1.6 前后端联调 3.1.2 分页插件{分页查询-PageHelper插件} 3.1.2.1 介绍 官网: 3.1.2.2 代码实…...
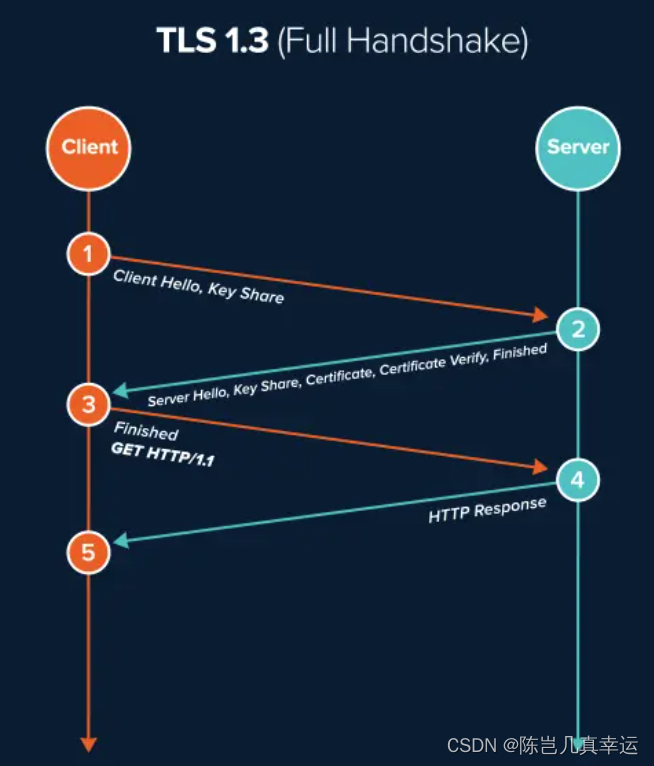
4.14 HTTPS 中 TLS 和 TCP 能同时握手吗?
目录 实现HTTPS中TLS和TCP同时握手的前提: 什么是TCP Fast Open? TLS v1.3 TCP Fast Open TLSv1.3 HTTPS都是基于TCP传输协议实现的,得先建立完可靠得TCP连接才能做TLS握手的事情。 实现HTTPS中TLS和TCP同时握手的前提: 1、…...

游戏开发服务器选型的横向对比
来源一个某乎的作者,貌似来自台湾 上篇介绍了go版本的游戏服务器,这篇介绍下其它语言版本: SkynetkbengineNoahGameFramePomeloPinusET使用的语言C/LuaCCNodejsTypeScriptC#概述云风前辈开源的框架mmo框架server一个快速的、可扩展的、分布…...
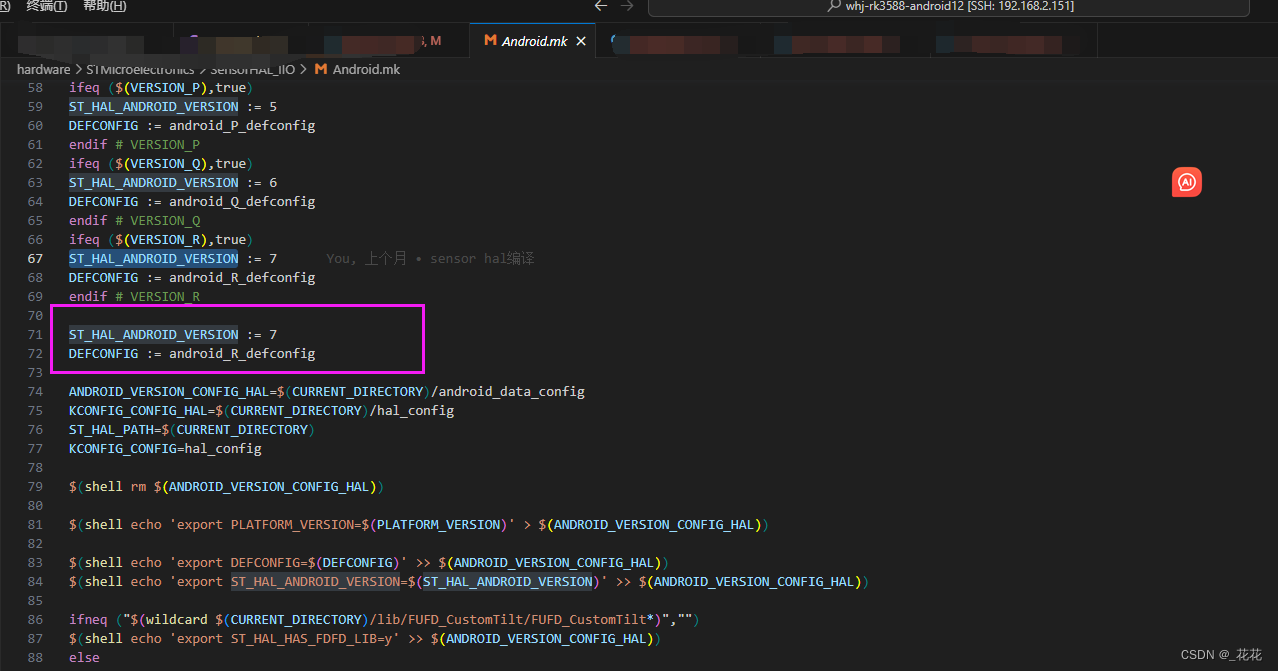
【android12-linux-5.1】【ST芯片】HAL移植后配置文件生成报错
根据ST官方源码移植HAL源码后,执行readme指示中的生成配置文件指令时报错ST_HAL_ANDROID_VERSION未定义之类,应该是编译环境参数问题。makefile文件中是自动识别配置的,参数不祥就会报错,这里最快的解决方案是查询确定自己android…...

基于深度神经网络的分类--实现与方法说明
1、分类系统的设计 采用神经网络进行分类需要考虑以下几个步骤: 数据预处理: 将数据特征参数和目标数据整理成合适的输入和输出形式,可以使用过去一段时间的数据作为特征,然后将未来的数据作为输出标签,进行分类问题的…...
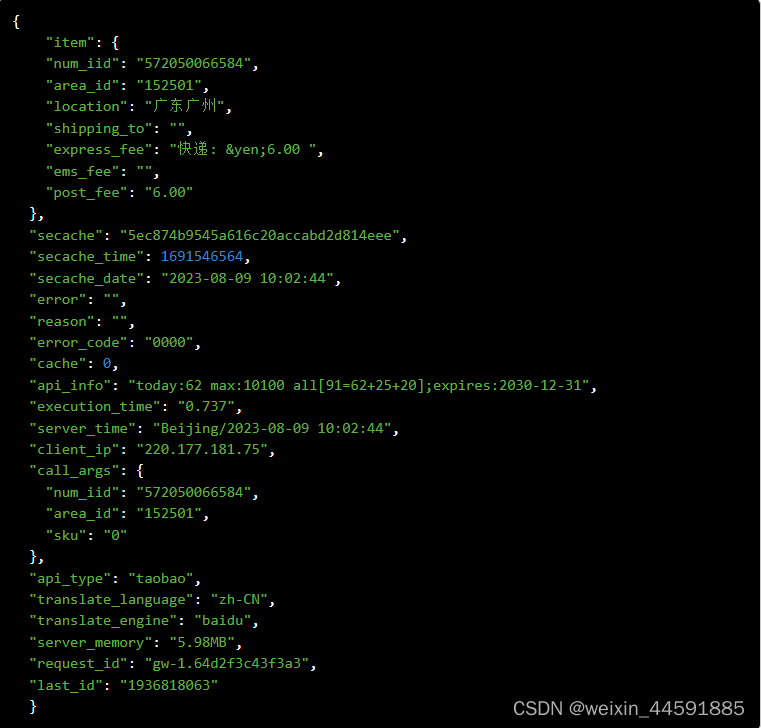
Java“牵手”天猫商品快递费用API接口数据,天猫API接口申请指南
天猫平台商品快递费用接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取天猫商品的标题、价格、库存、商品快递费用,宝贝ID,发货地,区域ID,快递费用,月销量、总销量、库存、详情…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

NCM格式转换实战指南:ncmdumpGUI全面解析
NCM格式转换实战指南:ncmdumpGUI全面解析 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾为网易云音乐下载的NCM格式音乐无法在其他设备播…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

脉冲神经网络与神经形态计算的能效优化实践
1. 脉冲神经网络与神经形态计算基础脉冲神经网络(SNN)作为第三代神经网络模型,其核心在于模拟生物神经系统的信息处理机制。与传统人工神经网络(ANN)相比,SNN具有三个本质区别:首先,…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...

FPGA与GPU在OSOS-ELM算法中的性能对比与优化
1. 项目概述在边缘计算和实时信号处理领域,极端学习机(ELM)因其独特的训练机制和高效的计算性能而备受关注。OSOS-ELM作为ELM的一种变体,通过在线顺序学习机制进一步提升了算法的实用性。这项研究聚焦于FPGA和GPU两种硬件平台在执行OSOS-ELM算法时的性能…...

从单体智能到组织智能:AgentOrg多智能体系统架构与实战
1. 项目概述:从单体智能到组织智能的范式跃迁最近在AI Agent领域,一个名为“AgentOrg”的开源项目引起了我的注意。这个由Angelopvtac发起的项目,其核心思想非常吸引人:它不再将AI Agent视为一个孤立的、执行单一任务的智能体&…...

BeagleBone Black设备树覆盖层实战:从原理到自定义SPI/UART配置
1. 项目概述:为什么BeagleBone Black开发者必须掌握设备树?如果你正在使用BeagleBone Black(BBB)进行嵌入式开发,并且已经不止一次地困惑于为什么某个外设(比如UART、SPI或者某个GPIO)无法按预期…...

Node.js性能预测工具nodestradamus:从监控到预警的实践指南
1. 项目概述与核心价值最近在折腾一些服务器监控和性能预测的活儿,偶然间在GitHub上发现了一个叫nodestradamus的项目,作者是ChristosGrigoras。这个名字挺有意思,结合了“Node.js”和“诺查丹玛斯”(那位著名的预言家)…...