2023年MySQL核心技术面试第一篇
目录
一 . 存储:一个完整的数据存储过程是怎样的?
1.1 数据存储过程
1.1.1 创建MySQl 数据库
1.1.1.1 为什么我们要先创建一个数据库,而不是直接创建数据表?
1.1.1.2基本操作部分
1.2 选择索引问题
二 . 字段:这么多的字段类型,应该如何定义
2.1 简介
2.1.1 例子:
2.1.1.1解释:
2.2 整数类型
2.2.1 如何选择合适的整数类型
2.3 浮点数类型和定点类型
2.3.1 为什么浮点数类型的无符号只有有符号的一半取值范围?
2.3.2 浮点数的精度问题
2.3.2.1 建表:
2.3.2.2 然后插入数据
2.3.2.3 查看表里面的数据
2.3.2.4 利用SQl语句进行价格相加:
2.3.2.4.1 sum:
一 . 存储:一个完整的数据存储过程是怎样的?
1.1 数据存储过程
MySQL是怎么进行数据存储的。
存储数据是处理数据的第一步,对各种繁杂的数据,进行有序和高效地存储起来。
在MySQL中,完整的数据存储过程共有4步,分别是 创建数据库,确认字段,创建数据表,插入数据。
1.1.1 创建MySQl 数据库
数据存储的第一步就是创建数据库。
1.1.1.1 为什么我们要先创建一个数据库,而不是直接创建数据表?
数据库是MySQL里面最大的存储单元,系统架构层次上看,MySQL数据库系统,从小到大依次是数据库服务器,数据库,数据表,数据表的行与列。
没有数据库,数据表就没有载体,就无法存储数据。
1.1.1.2基本操作部分
创建数据库
create database demo;
删除数据库
drop database demo;
查看数据库
show databases;
创建数据表:
create table demo.test
(
barcode text,
goodsname text,
price int
);
查看表结构
describe demo.test;
查看所有表
show tables;
添加主键
alter table demo.test
add column itemnumber int primary key auto_increment
向表添加数据
insert into demo.test
(barcode,goodsname,price)
values('0001','本',3);
1.2 选择索引问题
select count(*) from t; t中有id(主键),name,age,sex4个字段。假设数据10条,对sex添加索引。用explain 查看执行计划发现用了sex索引,为什么不是主键索引呢?主键索引应该更快的.
解答:
MySQL Innodb的主键索引是一个B+树,数据存储在叶子节点上,10条数据,就有10个叶子节点。
1. sex索引是辅助索引,也是一个B+树,不同之处在于,叶子节点存储的是主键值,由于sex只有2个
可能的值:男和女,因此,这个B+树只有2个叶子节点,比主键索引的B+树小的多
2. 这个表有主键,因此不存在所有字段都为空的记录,所以COUNT(*)只要统计所有主键的值就可以
了,不需要回表读取数据
3. SELECT COUNT(*) FROM t,使用sex索引,只需要访问辅助索引的小B+树,而使用主键索引,要
访问主键索引的那个大B+树,明细工作量大,这就是为什么,优化器使用辅助索引的原因
二 . 字段:这么多的字段类型,应该如何定义
2.1 简介
MySQl中有很多字段类型,比如整数,文本,浮点数。
2.1.1 例子:
在销售流水表中,需要定义商品销售的数量。由于有称重
商品,不能用整数,想当然地用了浮点数,为了确保精度,还用了 DOUBLE 类型。
结果却造成了在没有找零的情况下,客人无法结账的重大错误,DOUBLE 类型是不精准的,不能使用。
2.1.1.1解释:
浮点数在计算机中的内部表示是二进制的,而不是十进制的。对于某些常见的十进制小数(如0.1),其在二进制表示中是一个无限循环的小数。这样就存在一些十进制小数无法准确转换为浮点数的二进制表示。
当进行浮点数计算时,舍入误差会逐渐累积。即使看似简单的计算,例如0.1 + 0.1 + 0.1,也可能产生一个微小的舍入误差。这意味着在处理货币或计量单位时,通过浮点数计算得到的结果可能与预期的结果有细微差异。
在结账场景中,如果使用浮点数(DOUBLE)存储商品销售的数量和金额,并进行计算,那么可能会出现舍入误差。例如,如果商品价格是0.1元,数量是3个,正确的总金额应该是0.3元。但由于浮点数的舍入误差,实际计算时可能得到一个接近0.30000000000000004的结果。这样就导致无法准确匹配预期的金额,客人无法正确结账。
因此,在处理与货币或计量单位相关的数据时,浮点数(DOUBLE)类型不是一个理想的选择,因为它可能引发舍入误差和精度问题。更好的选择是使用固定点数类型(如DECIMAL),它可以提供更高的精确度和准确性来处理这些情况,避免结账错误的发生。
2.2 整数类型
整数类型一共5种:tinyint ,smallint,mediumint,int(integer),bigint。
2.2.1 如何选择合适的整数类型
需要考虑存储空间和可靠性的平衡问题:
1.占用字节数少的整数类型可以节省出存储空间,如果太小了,可能会出现超出取值范围的情况,引发系统问题。
例子:
在我们的项目中,商品编号采用的数据类型是 INT。
我们之所以没有采用占用字节更少的 SMALLINT 类型整数,原因就在于,客户门店中流通的
商品种类较多,而且,每天都有旧商品下架,新商品上架,这样不断迭代,日积月累。如果使
用 SMALLINT 类型,虽然占用字节数比 INT 类型的整数少,但是却不能保证数据不会超出范
围 65535。相反,使用 INT,就能确保有足够大的取值范围,不用担心数据超出范围影响可
靠性的问题。
注意:实际工作中,系统故障产生的成本远远超过增加几个字段存储空间所产生的成本,我们应该首先确保数据不会超过取值范围,在这个前提下考虑如何节省存储空间。
2.3 浮点数类型和定点类型
浮点数和定点数的特点是可以处理小数,将整数看成小数的特例。
浮点数类型:float,double,real
float 表示单精度浮点数;4字节
double 表示 双精度浮点数 8字节
real 默认 double,
如果要float:set sql_mode = " real_as_float";
2.3.1 为什么浮点数类型的无符号只有有符号的一半取值范围?
原因是,MySQL 是按照这个格式存储浮点数的:符号(S)、尾数(M)和阶
码(E)。因此,无论有没有符号,MySQL 的浮点数都会存储表示符号的部分。因此,所谓
的无符号数取值范围,其实就是有符号数取值范围大于等于零的部分。
2.3.2 浮点数的精度问题
2.3.2.1 建表:
CREATE TABLE demo.goodsmaster
(
barcode TEXT,
goodsname TEXT,
price DOUBLE,
itemnumber INT PRIMARY KEY AUTO_INCREMENT
);2.3.2.2 然后插入数据
-- 第一条
INSERT INTO demo.goodsmaster
(
barcode,
goodsname,
price
)
VALUES
(
'0001',
'书',
0.47
);
-- 第二条
INSERT INTO demo.goodsmaster
(
barcode,
goodsname,
price
)
VALUES
(
'0002',
'笔',
0.44
);
-- 第三条
INSERT INTO demo.goodsmaster
(
barcode,
goodsname,
price
)
VALUES
(
'0002',
'胶水',
0.19
);2.3.2.3 查看表里面的数据
SELECT * from demo.goodsmaster;结果:
mysql> SELECT *
-> FROM demo.goodsmaster;
+---------+-----------+-------+------------+
| barcode | goodsname | price | itemnumber |
+---------+-----------+-------+------------+
| 0001 | 书 | 0.47 | 1 |
| 0002 | 笔 | 0.44 | 2 |
| 0002 | 胶水 | 0.19 | 3 |
+---------+-----------+-------+------------+
3 rows in set (0.00 sec)2.3.2.4 利用SQl语句进行价格相加:
SELECT SUM(price)
FROM demo.goodsmaster;2.3.2.4.1 sum:
关键字sum,MySQL的求和函数,MySQL聚合函数的一种,知道这个函数表述计算字段值的和就可以了。
我们应该理想的值,0.47+0.44+0.19 =1.1
结果:
mysql> SELECT SUM(price)
-> FROM demo.goodsmaster;
+--------------------+
| SUM(price) |查询结果是 1.0999999999999999
将类型改成float,输出的值为1.0999999940395355,误差更大。
当我们需要进行值对比作为条件进行查询的时候,就会发生误差。
比如:
SELECT *
FROM demo.goodsmaster
WHERE SUM(price)=1.1原因;
相关文章:

2023年MySQL核心技术面试第一篇
目录 一 . 存储:一个完整的数据存储过程是怎样的? 1.1 数据存储过程 1.1.1 创建MySQl 数据库 1.1.1.1 为什么我们要先创建一个数据库,而不是直接创建数据表? 1.1.1.2基本操作部分 1.2 选择索引问题 二 . 字段:这么多的…...

linux启动jar 缺失lib
linux启动jar包时,找不到报错 [rootebs-141185 xl-admin]# java -Djava.library.path/home/kabangke/xl-admin/lib -jar /home/kabangke/xl-admin/xl-admin.jar Exception in thread "main" java.lang.NoClassDefFoundError: org/springframework/web/se…...

【Bash】常用命令总结
文章目录 1. 文件查询1.1 查看文件夹内(包含子文件夹)文件数量1.2 查看文件夹大小 任务简介: 对bash常用命令进行总结。 任务说明: 对平时工作中使用bash的相关命令做一个记录和说明,方便以后查阅。 1. 文件查询 1.…...
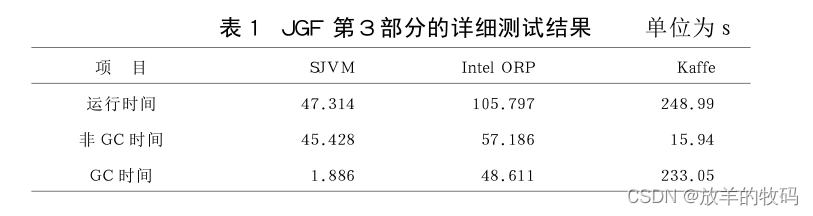
小研究 - Java虚拟机性能及关键技术分析
利用specJVM98和Java Grande Forum Benchmark suite Benchmark集合对SJVM、IntelORP,Kaffe3种Java虚拟机进行系统测试。在对测试结果进行系统分析的基础上,比较了不同JVM实现对性能的影响和JVM中关键模块对JVM性能的影响,并提出了提高JVM性能的一些展望。…...

Repo manifests默认default.xml清单文件中的各个标签详解
Repo简介 “Repo” 是一个用于管理多个Git存储库的工具,通常与Google的Android开发项目一起使用。它允许您在一个命令下轻松地进行多个Git存储库的同步、下载和管理。 repo下载安装 从清华镜像源下载 mkdir ~/bin PATH~/bin:$PATH curl https://mirrors.tun…...
javacv基础02-调用本机摄像头并预览摄像头图像画面视频
引入架包: <dependency><groupId>org.openpnp</groupId><artifactId>opencv</artifactId><version>4.5.5-1</version></dependency><dependency><groupId>org.bytedeco</groupId><artifactId…...
缓冲区与响应头)
【Nginx21】Nginx学习:FastCGI模块(三)缓冲区与响应头
Nginx学习:FastCGI模块(三)缓冲区与响应头 缓存相关的内容占了 FastCGI 模块将近一小半的内容,当然,用过的人可能不多。而今天的内容说实话,我平常也没怎么用过。第一个是缓冲区相关的知识,其实…...
)
正则表达式(常用字符简单版)
量词 字符类 边界匹配 分组和捕获 特殊字符 字符匹配 普通字符:普通字符按照字面意义进行匹配,例如匹配字母 "a" 将匹配到文本中的 "a" 字符。元字符:元字符具有特殊的含义,例如 \d 匹配任意数字字符…...

从零开始学习Python爬虫:详细指南
导言: 随着互联网的迅速发展,大量的数据可供我们利用。而Python作为一种简单易学且功能强大的编程语言,被广泛应用于数据分析和处理。学习Python爬虫技术,能够帮助我们从互联网上获取数据,并进行有效地分析和利用。本文…...
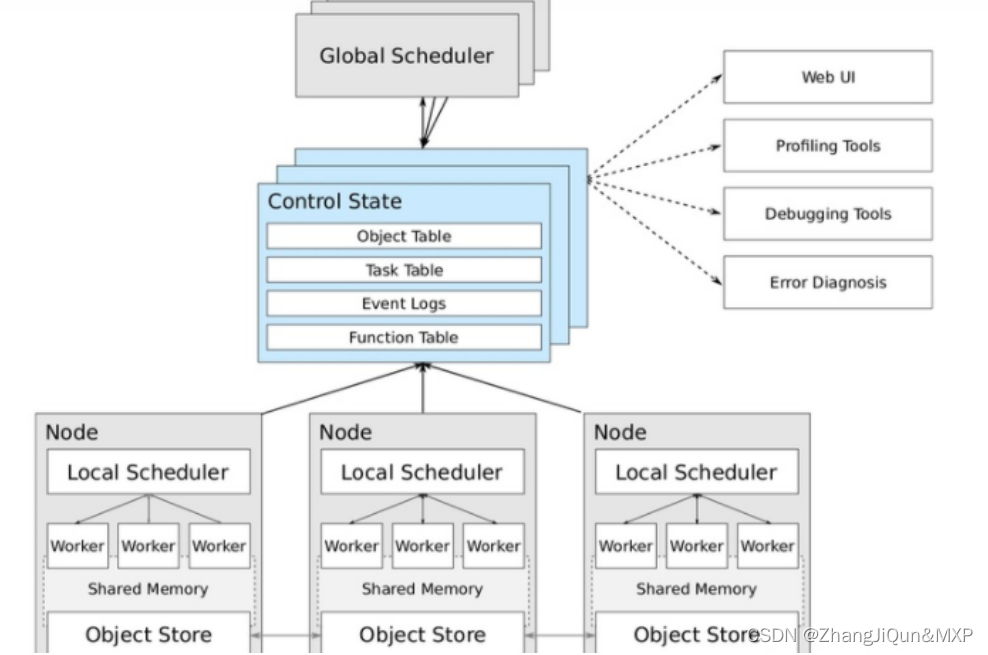
分布式计算框架:Spark、Dask、Ray
目录 什么是分布式计算 分布式计算哪家强:Spark、Dask、Ray 2 选择正确的框架 2.1 Spark 2.2 Dask 2.3 Ray 什么是分布式计算 分布式计算是一种计算方法,和集中式计算是相对的。 随着计算技术的发展,有些应用需要非常巨大的计算能力才…...

什么是伪类链(Pseudo-class Chaining)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ Pseudo-class Chaining⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、刚刚…...

每日一题:leetcode 57 插入区间
给你一个 无重叠的 ,按照区间起始端点排序的区间列表。 在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。 示例 1: 输入:intervals [[1,3…...

第五节:实现自己的第一个environment
本专栏是强化学习运用在买卖股票之上的入门学习内容。 主要解决强化学习代码落地和代码实践,不需要学习相关数学原理,直观简单的带领读者入门强化学习炒股。 查看本专栏完整内容,请访问:https://blog.csdn.net/windanchaos/category_12391143.html 本文发布地址:https://b…...

无套路,财务数据分析-多组织损益表分析分享
在报表众多的财务数据分析中,损益表是老板们最关注的报表,特别是当有多组织时,损益表的分析就变得更加重要了。以前受限于数据分析工具,做损益表分析时很难做到多维度灵活分析,但随着BI数据可视化工具的发展࿰…...

Java并发编程第6讲——线程池(万字详解)
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池,本篇文章就详细介绍一下。 一、什么是线程池 定义:线程池是一种用于管理和重用线程的技术(池化技术),它主…...

AI + Milvus:将时尚应用搭建进行到底
在上一篇文章中,我们学习了如何利用人工智能技术(例如开源 AI 向量数据库 Milvus 和 Hugging Face 模型)寻找与自己穿搭风格相似的明星。在这篇文章中,我们将进一步介绍如何通过对上篇文章中的项目代码稍作修改,获得更…...
归并排序(Java 实例代码)
目录 归并排序 一、概念及其介绍 二、适用说明 三、过程图示 四、Java 实例代码 MergeSort.java 文件代码: 归并排序 一、概念及其介绍 归并排序(Merge sort)是建立在归并操作上的一种有效、稳定的排序算法,该算法是采用分…...

【VUE】数字动态变化到目标值-vue-count-to
vue-count-to是一个Vue组件,用于实现数字动画效果。它可以用于显示从一个数字到另一个数字的过渡动画。 插件名:vue-count-to 官方仓库地址:GitHub - PanJiaChen/vue-countTo: Its a vue component that will count to a target number at a…...
)
Mysql /etc/my.cnf参数详解(二)
#buffer相关 #buffer pool根据实际内存大小调整,标准为物理内存的50% innodb_buffer_pool_size15996M //默认值128M,innodb_buffer_pool_size | 134217728 key_buffer_size 33554432 #根据物理内存大小设置 确保每个instance内的内存2G左右 <5000 1,>5000 &…...
6.10AUTOSAR操作系统概念与配置方法介绍(下))
AUTOSAR规范与ECU软件开发(实践篇)6.10AUTOSAR操作系统概念与配置方法介绍(下)
目录 2、 RTA-OS工程创建 3、 AUTOSAR操作系统配置方法 (1) 描述文件导入 (2) Counter配置...

CircuitPython开发进阶:从库文档解读到内存优化与异步编程实战
1. 从“能用”到“精通”:为什么你需要深入理解CircuitPython库文档刚接触CircuitPython时,我们往往是从复制粘贴示例代码开始的。这没什么问题,快速让一个LED闪烁起来,或者让传感器读出数据,那种即时反馈的成就感是驱…...

避坑指南:在Unity 2022 LTS中配置XCharts插件时遇到的3个常见问题及解决方法
Unity 2022 LTS中XCharts插件实战避坑手册 当数据可视化成为现代应用的核心需求时,Unity开发者常会选择XCharts这类开源图表插件来快速实现专业级图表展示。但在实际项目落地过程中,版本兼容性、环境配置和平台适配等问题往往会让开发进程意外卡壳。本文…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...

从零打造专业GitHub个人资料页:Markdown与动态集成实战指南
1. 项目概述与核心价值 在技术圈子里混了十几年,我越来越觉得,一个开发者的“数字门面”和代码能力同等重要。这个门面,很多时候就是你的GitHub主页。早些年,大家的GitHub个人页面就是个简单的仓库列表,加上一些贡献图…...

量子退火与经典优化结合的金融投资组合优化实践
1. 量子退火与经典优化结合的金融投资组合优化实践在金融投资领域,如何构建最优投资组合一直是核心挑战。传统方法如现代投资组合理论(MPT)和均值-方差优化(MVO)虽然奠定了理论基础,但在处理大规模资产配置时往往面临计算效率瓶颈。近年来,量…...

ARM Cortex-X系列处理器参数配置与性能优化指南
1. ARM Cortex-X系列处理器参数配置概述在移动计算和嵌入式系统领域,ARM Cortex-X系列处理器代表了ARM架构中的高性能核心设计。作为芯片设计工程师,我经常需要对这些处理器的参数进行精细调整,以实现最佳的性能和能效平衡。处理器参数配置本…...

Verilog时钟分频实战:从偶数、奇数到小数分频的设计与实现
1. 项目概述:从零开始掌握Verilog时钟分频 在数字电路和FPGA设计中,时钟信号是驱动整个系统同步运行的“心跳”。然而,一个系统往往需要多种不同频率的时钟来驱动不同的模块,比如高速的处理器核心和低速的外设接口。直接使用多个外…...

Linux系统下Vue开发环境搭建:从Node.js到Vite的完整指南
1. 项目概述:为什么要在Linux上搭建Vue环境?对于前端开发者而言,Vue.js 早已不是陌生的名字。它凭借其渐进式的设计理念、灵活的组件化系统和相对平缓的学习曲线,成为了构建现代Web应用的主流框架之一。然而,很多开发者…...

蓝桥杯EDA赛题深度解析:从客观题看电子设计核心考点
1. 蓝桥杯EDA赛题概述与备赛策略 蓝桥杯EDA设计与开发科目作为电子设计领域的重要赛事,每年吸引着众多高校学子参与。这个比赛最独特的地方在于它全面考察参赛者的电子设计自动化能力,从基础理论到软件操作,从元器件认知到电路分析࿰…...

Arduino蓝牙HID键盘实战:Bluefruit LE模块AT命令与控制器模式详解
1. 项目概述与核心价值如果你正在寻找一种能让你的Arduino项目“开口说话”或者“隔空操作”手机、电脑的方法,那么Adafruit的Bluefruit LE系列蓝牙低功耗模块绝对是一个绕不开的明星选手。它不仅仅是一个简单的蓝牙串口模块,更是一个集成了丰富AT命令集…...