AI + Milvus:将时尚应用搭建进行到底
在上一篇文章中,我们学习了如何利用人工智能技术(例如开源 AI 向量数据库 Milvus 和 Hugging Face 模型)寻找与自己穿搭风格相似的明星。在这篇文章中,我们将进一步介绍如何通过对上篇文章中的项目代码稍作修改,获得更详细和准确的结果,文末附赠彩蛋。
注:试用此项目应用,需要点击下载并使用 notebook
01.回顾前文
在深入探讨前,先简要回顾一下前一篇教程文章。
导入所需的图像处理库和工具
首先导入所有必要的图像处理库,包括用于特征提取的 torch、transformers 中的 segformer 对象、matplotlib 和 torchvision 中的 Resize、masks_to_boxes和crop 等。
import torch
from torch import nn, tensor
from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation
import matplotlib.pyplot as plt
from torchvision.transforms import Resize
import torchvision.transforms as T
from torchvision.ops import masks_to_boxes
from torchvision.transforms.functional import crop
预处理明星照片
在导入所有必要的图像处理库和工具后,就可以开始处理图像。以下三个函数 get_segmentation、get_masks 和 crop_images 用于分割并裁剪图片中的时尚单品,以供后续使用。
import torch
def get_segmentation(extractor, model, image):inputs = extractor(images=image, return_tensors="pt")outputs = model(**inputs)logits = outputs.logits.cpu()upsampled_logits = nn.functional.interpolate(logits,size=image.size[::-1],mode="bilinear",align_corners=False,)pred_seg = upsampled_logits.argmax(dim=1)[0]return pred_seg# 返回两个 masks(tensor)列表和 obj_ids(int)
# 来自 Hugging Face 的 mattmdjaga/segformer_b2_clothes 模型
def get_masks(segmentation):obj_ids = torch.unique(segmentation)obj_ids = obj_ids[1:]masks = segmentation == obj_ids[:, None, None]return masks, obj_idsdef crop_images(masks, obj_ids, img):boxes = masks_to_boxes(masks)crop_boxes = []for box in boxes:crop_box = tensor([box[0], box[1], box[2]-box[0], box[3]-box[1]])crop_boxes.append(crop_box)preprocess = T.Compose([T.Resize(size=(256, 256)),T.ToTensor()])cropped_images = {}for i in range(len(crop_boxes)):crop_box = crop_boxes[i]cropped = crop(img, crop_box[1].item(), crop_box[0].item(), crop_box[3].item(), crop_box[2].item())cropped_images[obj_ids[i].item()] = preprocess(cropped)return cropped_images
将图像数据存储到向量数据库中
选择开源向量数据库 Milvus 来存储图像数据。开始前,需要先解压包含照片的 zip 文件,并在 notebook 相同的根目录中创建照片文件夹。完成后,可以运行以下代码来将图像数据存储在 Milvus 中。
import os
image_paths = []
for celeb in os.listdir("./photos"):for image in os.listdir(f"./photos/{celeb}/"):image_paths.append(f"./photos/{celeb}/{image}")from milvus import default_server
from pymilvus import utility, connections
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
DIMENSION = 2048
BATCH_SIZE = 128
COLLECTION_NAME = "fashion"
TOP_K = 3
from pymilvus import FieldSchema, CollectionSchema, Collection, DataTypefields = [FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),FieldSchema(name='filepath', dtype=DataType.VARCHAR, max_length=200),FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=200),FieldSchema(name="seg_id", dtype=DataType.INT64),FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {"index_type": "IVF_FLAT","metric_type": "L2","params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
接着,运行以下代码,使用来自 Hugging Face 的 Nvidia ResNet 50 模型生成 embedding 向量。
# 如遇 SSL 证书 URL 错误,请在导入 resnet50 模型前运行此步骤
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 并删除最后一层模型输出
embeddings_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_resnet50', pretrained=True)
embeddings_model = torch.nn.Sequential(*(list(embeddings_model.children())[:-1]))
embeddings_model.eval()
以下函数定义了如何将图像转换为向量并插入到 Milvus 向量数据库中。代码会循环遍历所有图像。(注意:如果需要开启 Milvus 全新特性动态 Schema,需要修改代码。)
def embed_insert(data, collection, model):with torch.no_grad():output = model(torch.stack(data[0])).squeeze()collection.insert([data[1], data[2], data[3], output.tolist()])
from PIL import Image
data_batch = [[], [], [], []]for path in image_paths:image = Image.open(path)path_split = path.split("/")name = " ".join(path_split[2].split("_"))segmentation = get_segmentation(extractor, model, image)masks, ids = get_masks(segmentation)cropped_images = crop_images(masks, ids, image)for key, image in cropped_images.items():data_batch[0].append(image)data_batch[1].append(path)data_batch[2].append(name)data_batch[3].append(key)if len(data_batch[0]) % BATCH_SIZE == 0:embed_insert(data_batch, collection, embeddings_model)data_batch = [[], [], [], []]if len(data_batch[0]) != 0:embed_insert(data_batch, collection, embeddings_model)collection.flush()
查询向量数据库
以下代码演示了如何使用输入图像查询 Milvus 向量数据库,以检索和上传衣服图像最相似的的前三个结果。
def embed_search_images(data, model):with torch.no_grad():output = model(torch.stack(data))if len(output) > 1:return output.squeeze().tolist()else:return torch.flatten(output, start_dim=1).tolist()
# data_batch[0]是 tensor 列表
# data_batch[1]是图像文件的文件路径(字符串)
# data_batch[2]是图像中人物的名称列表(字符串)
# data_batch[3]是分割键值列表(int)
data_batch = [[], [], [], []]search_paths = ["./photos/Taylor_Swift/Taylor_Swift_3.jpg", "./photos/Taylor_Swift/Taylor_Swift_8.jpg"]for path in search_paths:image = Image.open(path)path_split = path.split("/")name = " ".join(path_split[2].split("_"))segmentation = get_segmentation(extractor, model, image)masks, ids = get_masks(segmentation)cropped_images = crop_images(masks, ids, image)for key, image in cropped_images.items():data_batch[0].append(image)data_batch[1].append(path)data_batch[2].append(name)data_batch[3].append(key)embeds = embed_search_images(data_batch[0], embeddings_model)
import time
start = time.time()
res = collection.search(embeds,anns_field='embedding',param={"metric_type": "L2","params": {"nprobe": 10}},limit=TOP_K,output_fields=['filepath'])
finish = time.time()
print(finish - start)
for index, result in enumerate(res):print(index)print(result)
02.匹配更多风格:标示每张图像中的时尚单品
除了直接使用上述代码,查找与你着装风格最相似的 3 位明星以外,我们还可以稍微修改一下代码,拓展项目的应用场景。可以修改代码获取如下所示,不包含边界框的图像。

接下来,将为大家介绍如何修改上述代码寻找更多匹配的穿衣风格。
导入所需的图像处理库和工具
同样,需要先导入所有必要的图像处理库。如果已经完成导入,请跳过此步骤。
import torch
from torch import nn, tensor
from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation
import matplotlib.pyplot as plt
from torchvision.transforms import Resize
import torchvision.transforms as T
from torchvision.ops import masks_to_boxes
from torchvision.transforms.functional import crop
预处理图像
这个步骤涉及三个函数:get_segmentation、get_masks 和 crop_images。
无需修改 get_segmentation 函数部分的代码。
对于 get_masks 函数,只需要获取与 wanted 列表中的分割 ID 相对应的分割图像即可。
对 crop_image 函数做出更改。在前一篇文的教程中,此函数返回裁剪图像的列表。这里,我们进行一些调整,使函返回三个对象:裁剪图像对应的 embedding 向量、边界框在原始图像上的坐标列表,以及分割 ID 列表。这一改动将转化 embedding 向量的步骤提前了。
wanted = [1, 3, 4, 5, 6, 7, 8, 9, 10, 16, 17]
def get_segmentation(image):inputs = extractor(images=image, return_tensors="pt")outputs = segmentation_model(**inputs)logits = outputs.logits.cpu()upsampled_logits = nn.functional.interpolate(logits,size=image.size[::-1],mode="bilinear",align_corners=False,)pred_seg = upsampled_logits.argmax(dim=1)[0]return pred_seg# returns two lists masks (tensor) and obj_ids (int)
# "mattmdjaga/segformer_b2_clothes" from hugging face
def get_masks(segmentation):obj_ids = torch.unique(segmentation)obj_ids = obj_ids[1:]wanted_ids = [x.item() for x in obj_ids if x in wanted]wanted_ids = torch.Tensor(wanted_ids)masks = segmentation == wanted_ids[:, None, None]return masks, obj_idsdef crop_images(masks, obj_ids, img):boxes = masks_to_boxes(masks)crop_boxes = []for box in boxes:crop_box = tensor([box[0], box[1], box[2]-box[0], box[3]-box[1]])crop_boxes.append(crop_box)preprocess = T.Compose([T.Resize(size=(256, 256)),T.ToTensor()])cropped_images = []seg_ids = []for i in range(len(crop_boxes)):crop_box = crop_boxes[i]cropped = crop(img, crop_box[1].item(), crop_box[0].item(), crop_box[3].item(), crop_box[2].item())cropped_images.append(preprocess(cropped))seg_ids.append(obj_ids[i].item())with torch.no_grad():embeddings = embeddings_model(torch.stack(cropped_images)).squeeze().tolist()return embeddings, boxes.tolist(), seg_ids
有了图像数据之后,就可以加载数据了。这一步骤需要使用到批量插入功能,上篇文章的教程中也有涉及,但不同点在于,本文的教程中将数据作为 dictionary 列表一次性插入。这种插入方式更简洁,同时还允许我们在插入数据时动态新增 Schema 字段。
for path in image_paths:image = Image.open(path)path_split = path.split("/")name = " ".join(path_split[2].split("_"))segmentation = get_segmentation(image)masks, ids = get_masks(segmentation)embeddings, crop_corners, seg_ids = crop_images(masks, ids, image)inserts = [{"embedding": embeddings[x], "seg_id": seg_ids[x], "name": name, "filepath": path, "crop_corner": crop_corners[x]} for x in range(len(embeddings))]collection.insert(inserts)collection.flush()
查询向量数据库
现在可以开始在向量数据库 Milvus 中查询数据了。本文与上篇文章的教程有以下几点区别:
-
将一张图像中匹配的时尚单品数量限制到 5 件。
-
指定查询返回最相似的 3 张图像。
-
添加函数获取图片的色彩图。
随后,在 matplotlib 中设置 figures 和 axes ,代码会循环遍历所有图像,将上文的 3 个函数应用到所有图像上,以获取分割结果和边界框。
查询数据时,可以根据每张图像中匹配的时尚单品数量来获得最相似的 3 张图像。
最终返回的结果图像中会带有标示出匹配单品的边界框。
from pprint import pprint
from PIL import ImageDraw
from collections import Counter
import matplotlib.patches as patchesLIMIT = 5 # 每张图像中匹配的时尚单品件数
CLOSEST = 3 # 返回的最相似图像数量。CLOSEST <= Limitsearch_paths = ["./photos/Taylor_Swift/Taylor_Swift_2.jpg", "./photos/Jenna_Ortega/Jenna_Ortega_6.jpg"] # Images to search fordef get_cmap(n, name='hsv'):'''Returns a function that maps each index in 0, 1, ..., n-1 to a distinctRGB color; the keyword argument name must be a standard mpl colormap name.Sourced from <https://stackoverflow.com/questions/14720331/how-to-generate-random-colors-in-matplotlib>'''return plt.cm.get_cmap(name, n)# 创建结果 subplot
f, axarr = plt.subplots(max(len(search_paths), 2), CLOSEST + 1)for search_i, path in enumerate(search_paths):# Generate crops and embeddings for all items foundimage = Image.open(path)segmentation = get_segmentation(image)masks, ids = get_masks(segmentation)embeddings, crop_corners, _ = crop_images(masks, ids, image)# 生成色彩图cmap = get_cmap(len(crop_corners))# Display the first box with image being searched foraxarr[search_i][0].imshow(image)axarr[search_i][0].set_title('Search Image')axarr[search_i][0].axis('off')for i, (x0, y0, x1, y1) in enumerate(crop_corners):rect = patches.Rectangle((x0, y0), x1-x0, y1-y0, linewidth=1, edgecolor=cmap(i), facecolor='none')axarr[search_i][0].add_patch(rect)# 查询向量数据库start = time.time()res = collection.search(embeddings,anns_field='embedding',param={"metric_type": "L2","params": {"nprobe": 10}, "offset": 0},limit=LIMIT,output_fields=['filepath', 'crop_corner'])finish = time.time()print("Total Search Time: ", finish - start)# 根据位置给查询结果增加不同的权重filepaths = []for hits in res:seen = set()for i, hit in enumerate(hits):if hit.entity.get("filepath") not in seen:seen.add(hit.entity.get("filepath"))filepaths.extend([hit.entity.get("filepath") for _ in range(len(hits) - i)])# 查找排名最高的图像counts = Counter(filepaths)most_common = [path for path, _ in counts.most_common(CLOSEST)]# 提取每张图像中与查询图像相关的时尚单品matches = {}for i, hits in enumerate(res):matches[i] = {}tracker = set(most_common)for hit in hits:if hit.entity.get("filepath") in tracker:matches[i][hit.entity.get("filepath")] = hit.entity.get("crop_corner")tracker.remove( hit.entity.get("filepath"))# 返回最相似图像:# 返回与查询图像临近的图像image = Image.open(res_path)axarr[search_i][res_i+1].imshow(image)axarr[search_i][res_i+1].set_title(" ".join(res_path.split("/")[2].split("_")))axarr[search_i][res_i+1].axis('off')
# 为匹配单品添加边界框if res_path in value:x0, y0, x1, y1 = value[res_path]rect = patches.Rectangle((x0, y0), x1-x0, y1-y0, linewidth=1, edgecolor=cmap(key), facecolor='none')axarr[search_i][res_i+1].add_patch(rect)
运行上述步骤后,结果如下所示:

03.项目后续:探索更多应用场景
欢迎大家基于本项目拓展更多、更丰富的应用场景,例如:
-
进一步延伸对比功能,例如将不同的单品归类到一起。同样,也可以上传更多图像到数据库中,丰富查询结果。
-
将本项目转变为时尚探测仪或者时尚推荐系统。例如,将明星图像替换成可购买的衣服图像。这样一来,用户上传照片后,可以查询与他的衣服风格相似的其他衣服。
-
还可以基于本项目搭建一个穿搭生成系统,很多方法都可以实现这个应用,但这个应用的搭建相对而言更有难度!本文提供了一种思路,系统可以根据用户上传的多张照片相应推荐穿搭。这里需要用到生成式图像模型,从而提供穿搭建议。
总之,不要限制你的想象力,搭建更丰富的应用。Milvus 之类的向量数据库为相似性搜索应用提供了无限可能。
04.总结
本文教程中,我们进一步拓展了时尚 AI 项目的应用场景。
本次教程使用了 Milvus 全新的 动态 Schema 功能,筛选了分割 ID,在返回图像中保留了边界框。同时,我们在查询中指定 Milvus 根据每张图像中匹配的时尚单品件数返回最相似的 3 张图像。Milvus 全新的动态 Schema 功能支持在上传数据时添加新的字段,改变了我们批量上传数据的方式。使用这个功能后,在上传数据时,无需改动 Schema 即可添加裁剪。在图像预处理步骤中,剔除了一些识别到的非着装类元素。同时,本教程保留了边界框,将转化向量的步骤提前至了裁剪图片的步骤。
当然,通过进一步调整代码,我们还可以搭建更多相关应用,例如:时尚推荐系统、帮助用户搭配着装的系统,甚至是生成式的时尚 AI 应用!
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
本文由 mdnice 多平台发布
相关文章:
AI + Milvus:将时尚应用搭建进行到底
在上一篇文章中,我们学习了如何利用人工智能技术(例如开源 AI 向量数据库 Milvus 和 Hugging Face 模型)寻找与自己穿搭风格相似的明星。在这篇文章中,我们将进一步介绍如何通过对上篇文章中的项目代码稍作修改,获得更…...
归并排序(Java 实例代码)
目录 归并排序 一、概念及其介绍 二、适用说明 三、过程图示 四、Java 实例代码 MergeSort.java 文件代码: 归并排序 一、概念及其介绍 归并排序(Merge sort)是建立在归并操作上的一种有效、稳定的排序算法,该算法是采用分…...

【VUE】数字动态变化到目标值-vue-count-to
vue-count-to是一个Vue组件,用于实现数字动画效果。它可以用于显示从一个数字到另一个数字的过渡动画。 插件名:vue-count-to 官方仓库地址:GitHub - PanJiaChen/vue-countTo: Its a vue component that will count to a target number at a…...
)
Mysql /etc/my.cnf参数详解(二)
#buffer相关 #buffer pool根据实际内存大小调整,标准为物理内存的50% innodb_buffer_pool_size15996M //默认值128M,innodb_buffer_pool_size | 134217728 key_buffer_size 33554432 #根据物理内存大小设置 确保每个instance内的内存2G左右 <5000 1,>5000 &…...
6.10AUTOSAR操作系统概念与配置方法介绍(下))
AUTOSAR规范与ECU软件开发(实践篇)6.10AUTOSAR操作系统概念与配置方法介绍(下)
目录 2、 RTA-OS工程创建 3、 AUTOSAR操作系统配置方法 (1) 描述文件导入 (2) Counter配置...

蓝牙 - 经典蓝牙物理信道介绍
物理信道有多种类型。所有蓝牙物理信道的特点都是一组物理层的频率与时间参数相结合,并受到空间因素的限制。对于基本的和经过调整的蓝牙组网(piconet)所用物理信道,跳频用于定期改变频率,以减少干扰影响,同时也是出于监管原因。 …...

性能测试中未做集群时,在登入中已经保存了登入的session,但可能会出现在不同的服务器上显示登入失败
Session未进行集群共享时,则会出现服务器2,未登录...

Python环境下载安装使用
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

图像扭曲之波浪扭曲
源码: void wave_sine(cv::Mat& src,cv::Mat& dst,double amplitude,double wavelength) {dst.create(src.rows, src.cols, CV_8UC3);dst.setTo(0);double xAmplitude amplitude;double yAmplitude amplitude;double xWavelength wavelength;double yWa…...

《自动驾驶与机器人中的SLAM技术》之GNSS相关基础知识总结
简介 本篇基于对《自动驾驶与机器人中的SLAM技术》中的GNSS定位相关基础知识进行总结用于备忘 知识点整理 GNSS(全球卫星导航系统)定位原理 GNSS 通过测量自身与地球周围各卫星的距离来确定自身的位置 , 而与卫星的距离主要是通过测量时间间隔来确定的 GNSS与GPS的关系 GPS(…...
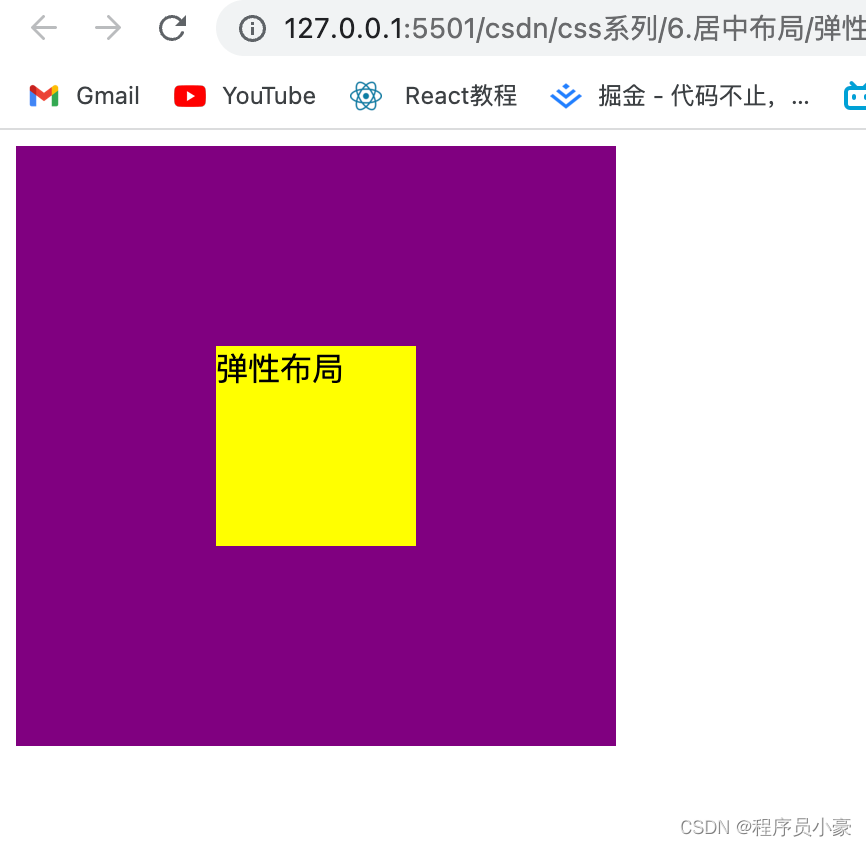
【前端|CSS系列第4篇】面试官:你了解居中布局吗?
欢迎来到前端CSS系列的第4篇教程!如果你正在寻找一种简单而又强大的前端技术,以使你的网页和应用程序看起来更加专业和美观,那么居中布局绝对是你不能错过的重要知识。 在前端开发中,实现居中布局是一项必备技能,无论…...

安全物理环境技术测评要求项
1.物理选择-保证等级保护对象物理安全的前提和基础 1-0/2-2/3-2/4-2(级别-要求项数量) a)具备防震、防风、防雨能力 b)避免顶层或地下室,否则应加强防水、防潮措施 测评实施重点: 1)机房场地所在…...
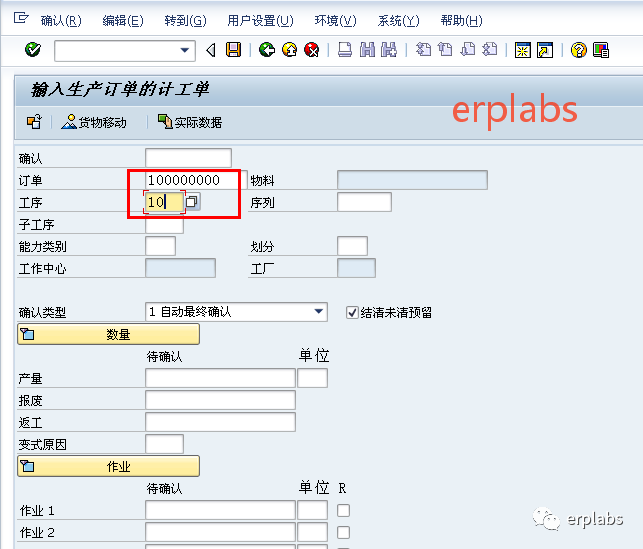
SAP MTS案例教程PP生产前台操作
目录 本章介绍 2 生产订单相关操作 3 批量查询生产订单 3 单个显示生产任务单 5 生产订单批量可用性检查 6 显示短缺部件信息 8 修改生产订单 9 重读工单计划主数据 11 单个下达生产订单 12 批量下达生产订单 13 非倒冲生产方式操作过程 15 多个工单批量发料 15 单个工单发料 1…...

Celery task 执行报错 TypeError: Object of type set is not JSON serializable 问题分析处理
情况描述: 定义了新的shared_task推送到生产环境后,发现无法执行,会报错set对象无法序列化,报错内容如下: Traceback (most recent call last):File "/tmp/venv/lib64/python3.6/site-packages/kombu/serializati…...

【大魔王送书第一期】《一名阿里服务端开发工程师的进阶之路》
一、前言 目前,资讯、社交、游戏、消费、出行等丰富多彩的互联网应用已经渗透到了人们生活和工作的方方面面,正深刻改变着信息时代。随着用户规模的增长和应用复杂度的上升,服务端面临的技术挑战越来越严峻。在头部互联网企业,服…...

[FPGA IP系列] BRAM IP参数配置与使用示例
FPGA开发中使用频率非常高的两个IP就是FIFO和BRAM,上一篇文章中已经详细介绍了Vivado FIFO IP,今天我们来聊一聊BRAM IP。 本文将详细介绍Vivado中BRAM IP的配置方式和使用技巧。 一、BRAM IP核的配置 1、打开BRAM IP核 在Vivado的IP Catalog中找到B…...

react ts
一、项目搭建 1、创建项目 使用vite生成项目 npx create-react-app react-ts-project --template typescript 启动项目 yarn start 删除无用组件 2、设计目录结构 资源说明http网络请求assets公共资源components组件router路由配置utils工具模块store状态机App.tsx应用…...

配置MySQL
配置MySQL_5.7.16 一级目录2.1.1 安装包准备2.1.2 安装MySQL2.1.3 配置MySQL 一级目录 2.1.1 安装包准备 1)将安装包和JDBC驱动上传到/opt/software,共计6个 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.16-1.el…...
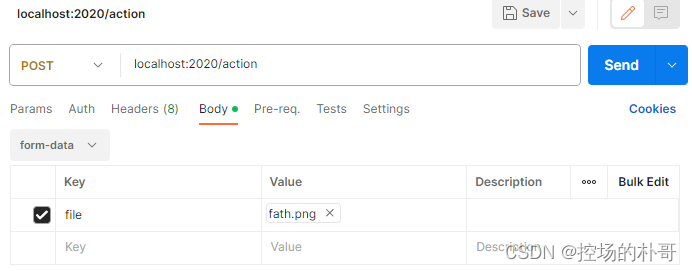
GFPGAN 集成Flask 接口化改造
GFPGAN是一款腾讯开源的人脸高清修复模型,基于github上提供的demo,可以简单的集成Flask以实现功能接口化。 GFPGAN的安装,Flask的安装请参见其他文章。 如若使用POSTMAN进行测试,需使用POST方式,form-data的请求体&am…...
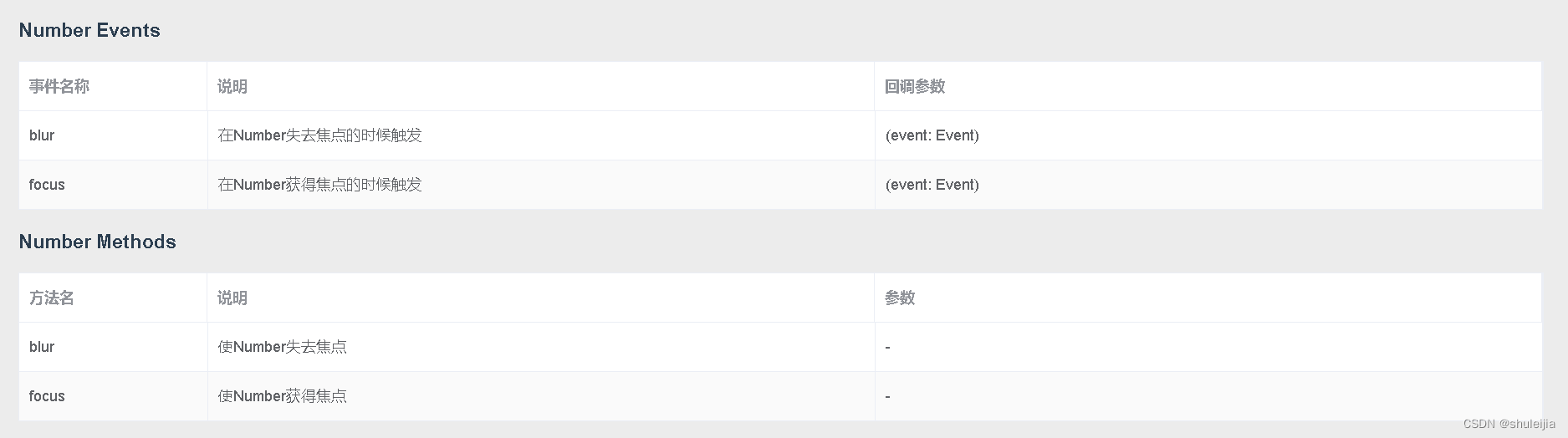
vue数字输入框
目录 1.emitter.JS function broadcast (componentName, eventName, params) {this.$children.forEach(child > {var name child.$options.componentNameif (name componentName) {child.$emit.apply(child, [eventName].concat(params))} else {broadcast.apply(child, …...

低温预警!固化慢、易开裂……密封胶冬季施工手册
低温预警!固化慢、易开裂……密封胶冬季施工手册 硅酮耐候密封胶主要作用是保障幕墙的气密性、水密性。其出现问题,可能会导致耐候密封失效,从而造成幕墙漏水漏气,影响幕墙的正常使用。耐候密封胶由于考虑到现场施工,几乎都是单组分硅酮密封胶产品。进入冬季,气候变化明…...

PowerInfer:基于热点神经元预测的LLM高性能推理引擎部署指南
1. 项目概述:当推理速度成为AI落地的瓶颈最近在折腾本地大模型推理的朋友,估计都绕不开一个核心痛点:速度。模型效果再好,生成一句话要等上十几秒,那种“卡顿感”足以劝退绝大多数想把它集成到实际应用里的开发者。我自…...

Nixtla时间序列预测库实战:从统计模型到深度学习的一站式解决方案
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理销售预测、服务器负载监控或者任何与时间相关的数据预测问题,并且厌倦了在复杂的模型库和繁琐的预处理步骤之间反复横跳,那么 Nixtla 这个开源项目很可能就是你一直在找的“瑞士军刀”。…...

mg3640s,ts8080,ts8100,g5080,g3800,g4800,ix6780,ts8180报错5B00,P07,E08,5b02,1704,1700,5b04佳能V6.200,亲测有用
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

g1810,g3810,ip2700,g5080,g1800,ts3380,TS8380,ts6480报错5B00,P07,E08,5b02,1704,1700,5b04,佳能v6.200,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...
基于PWM舵机与NeoPixel的万圣节互动蝙蝠制作全解析
1. 项目概述:一个会动的万圣节蝙蝠又快到万圣节了,想给家里的装饰来点不一样的“活物”吗?每年都摆静态的南瓜灯和蜘蛛网,总觉得少了点气氛。今年我琢磨着,不如自己动手做一个能扑腾翅膀、眼睛还会发光的机械蝙蝠&…...

Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案
Mod Engine 2完全指南:告别游戏模组安装烦恼的终极解决方案 【免费下载链接】ModEngine2 Runtime injection library for modding Souls games. WIP 项目地址: https://gitcode.com/gh_mirrors/mo/ModEngine2 还在为传统游戏模组安装的繁琐流程而烦恼吗&…...

AI攻防时间差:当漏洞发现速度碾压修复速度— 聚焦技术核心
AI攻防时间差:当漏洞发现速度碾压修复速度 — 聚焦技术核心 引言:当两个世界碰撞 2026年5月,对于网络安全领域而言,是一个具有分水岭意义的月份。 一边是360人工智能安全研究院在5月12日发布的重磅报告,首次提出**“AI…...

嵌入式开发革命:LuatOS云编译实战指南与效率提升
1. 项目概述:为什么我们需要云编译?作为一名在嵌入式领域摸爬滚打了十多年的老鸟,我太懂那种“买板一时爽,环境火葬场”的痛了。尤其是这几年,合宙、乐鑫、兆易这些厂商的产品线越来越丰富,Air780E、ESP32-…...

2026年冰袋吸水粉厂家大揭秘:选择指南与行业趋势题
随着冷链物流行业的快速发展,冰袋吸水粉作为冷链运输中不可或缺的保冷材料,其市场需求持续增长。然而,市场上冰袋吸水粉的质量参差不齐,如何选择一家值得信赖的厂家成为许多采购商关注的重点。本文将从行业背景、技术特点及市场趋…...