Java并发编程第6讲——线程池(万字详解)
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池,本篇文章就详细介绍一下。
一、什么是线程池
定义:线程池是一种用于管理和重用线程的技术(池化技术),它主要用于提高多线程应用程序的性能和效率。
ps:线程池、连接池、内存池和对象池等都是编程领域中典型的池化技术。
首先有关线程的使用会出现两个问题:
- 线程是宝贵的内存资源、单个线程约占1MB空间,过多分配易造成内存溢出。
- 频繁的创建及销毁线程会增加虚拟机回收频率、资源开销,造成性能下降。
基于如上问题,出现了线程池:
- 线程容器,可设定线程分配的数量。
- 将预先创建的线程对象存入池中,并重用线程池中的线程对象。
- 避免频繁的创建和销毁。
Java中线程池的继承关系如下:

二、ThreadPoolExecutor
Executor框架最核心的类是ThreadPoolExecutor,我们可以通过ThreadPoolExecutor类来创建一个线程池。
2.1 ThreadPoolExecutor构造函数
ThreadPoolExecutor继承自AbstractExecutorService,而AbstractExecutorService实现了ExecutorService接口。

2.2 线程池的7个核心参数
从ThreadPoolExecutor的构造函数可以看出,创建一个线程池需要7个核心参数,下面我们介绍一下这7个参数的含义:
核心线程数数量(corePoolSize):当线程池被创建时,在你池子中初始化多少个线程。
最大线程数(maximumPoolSize):当我的所有核心线程数都去干活时,又来了一个任务,如果我的当前线程数小于我最大线程数,这时候可以再帮你创建一个线程去指定你的任务。
线程闲置时间(keepAliveTime):额外线程完成任务后,存活的时间。
限制时间的单位(unit):存活时间单位。
工作队列(workQueue):当没核心线程去处理任务时,会把任务放在工作队列中,当有闲下来的线程时再去执行队列的任务,常见的工作队列有以下几种,前三种用的最多:
ArrayBlockingQueue:列表形式的工作队列,必须要有初始队列大小,有界队列,先进先出(FIFO)。
LinkedBlockingQueue:链表形式的工作队列,可以选择设置初始队列大小,有界(设置了初始大小)/无界队列(没设置) ,先进先出(FIFO)。
SynchronousQueue:这不是一个真正的队列,而是一种在线程之间移交的机制。要将一个元素放入SynchronousQueue中,必须有另一个线程正在等待接受这个元素。如果没有线程等待,并且线程池的当前大小小于最大值,那么ThreadPoolExecutor将创建一个线程,否则根据拒绝策略,这个任务将被拒绝。使用直接移交更高效,因为任务会直接移交给执行它的线程,而不是被首先放在队列中,然后由工作者线程从队列中提取任务。只有当线程是无界的或者可以拒绝任务时,SynchronousQueue才有价值。
PriorityBlockingQueue:优先级队列,有界队列,根据优先级来安排任务,任务的优先级是通过自然顺序或Comparator来定义的。
DelayedWorkQueue:延迟的工作队列,无界队列。
创建线程的工厂(threadFactory):线程池不会帮你创建线程,这时候就要用到线程工厂:
DefaultThreadFactory:默认线程工厂,创建一个新的、非守护的线程,并且不包括特殊的配置信息。
PrivilegedThreadFactory:通过这种方式创建出来的线程,将与创建privilegedThreadFactory的线程拥有相同的访问权限、AccessControlContext、ContextClassLoader。如果不使用privilegedThreadFactory,线程池创建的线程将从在需要新线程时调用execute或submit的客户程序中继承访问权限。
自定义线程工厂:可以自己实现ThreadFactory接口来自定义线程工厂。
拒绝策略(handler):当你的线程数达到最大,工作队列任务也满了,就执行拒绝策略:
AbortPolicy:抛出异常!(RejectedExecutionException),默认的拒绝策略。(调用者可以将异常进行捕获,然后根据需求处理代码)
CallerRunsPolicy:调用者自己处理任务!(要把任务派发给我的线程池,要有一个线程执行操作,如果没有闲置的线程,由调用者自己处理任务)
DiscardOldestPolicy:丢弃任务队列中最老的任务,把自己放进去!
DiscardPolicy:丢弃掉当前任务!
2.3 线程池Demo
我们可以使用ThreadExecutor创建一个线程池,然后调用execute()或submit()的方法来向线程池中提交任务。
2.3.1 execute()方法(自己的方法)
public void execute(Runnable command)
execute()方法没有返回值,所以它适用于不需要返回值的任务,当然也无法判断任务是否被线程池执行成功。
public class ThreadPoolExecutorTest {public static void main(String[] args) {//1.创建线程池ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(2,3, 60L, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardOldestPolicy());//2.创建任务Runnable runnable = () -> {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + "执行了。。。");};//3.提交任务for (int i = 0; i < 5; i++) {poolExecutor.execute(runnable);}//4.关闭线程池poolExecutor.shutdown();}
}上述例子我们创建了一个核心线程数为2、最大线程数为3的线程池,然后通过execute方法提交了5个线程给线程池执行。
2.3.2 submit()方法(AbstractExecutorService父类的方法)
public Future<?> submit(Runnable task)
public <T> Future<T> submit(Runnable task,T result)
public <T> Future<T> submit(Callable<T> task)
sublmit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个对象可以判断任务是否执行成功,并且可以通过get()方法以阻塞的方式来获取返回值。
public class ThreadPoolExecutorTest {public static void main(String[] args) throws ExecutionException, InterruptedException {//1.创建线程池ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(1,1, 60L, TimeUnit.SECONDS,new LinkedBlockingQueue<>(1),Executors.defaultThreadFactory(),new ThreadPoolExecutor.DiscardOldestPolicy());//2.提交任务,Future标识将要执行任务的结果,submit可以传入一个Callable<T>对象Future<Integer> future = poolExecutor.submit(new Callable<Integer>() {private int sum = 0;@Overridepublic Integer call() throws Exception {for (int i = 0; i < 100; i++) {sum += i;Thread.sleep(10);}return sum;}});//3.获取任务的结果(等待任务执行完毕才返回,阻塞)System.out.println(future.get());//4.关闭线程池poolExecutor.shutdown();}
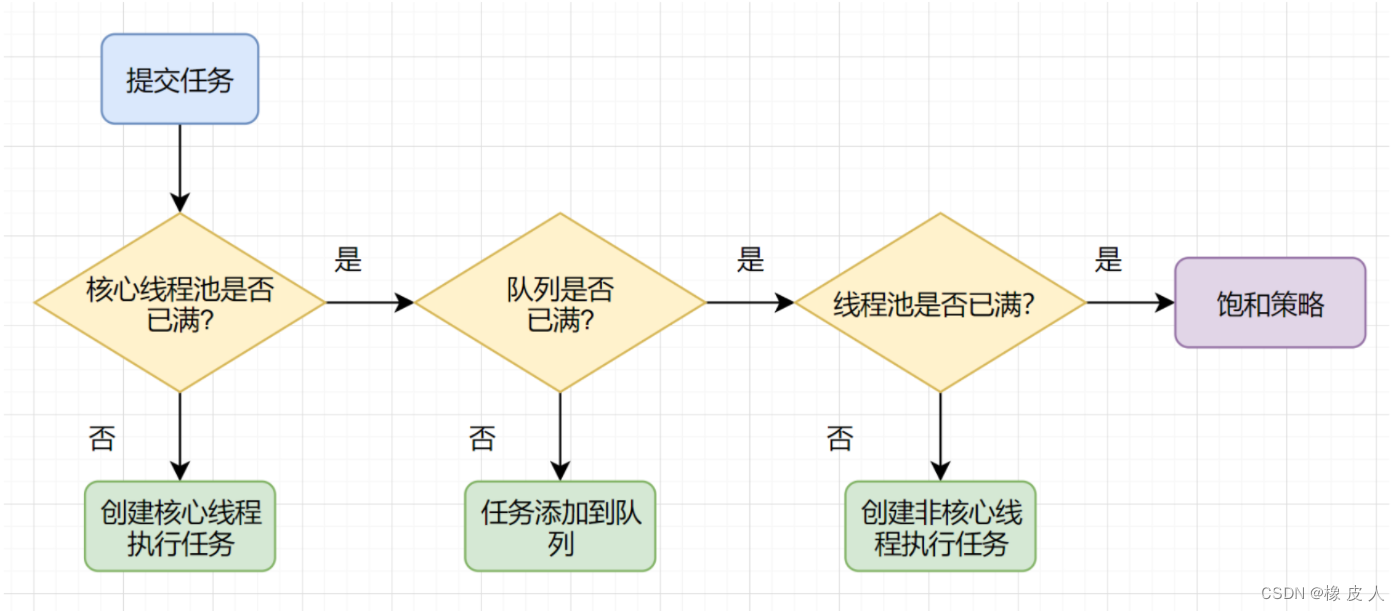
}2.4 当一个任务提交到线程池后
首先查看核心线程数是否达到最大
否:利用线程工厂创建核心线程直接执行任务
是:尝试将任务放到工作队列中
查看工作队列是否已满
否:将任务放入到工作队列。
是:尝试创建非核心线程(最大线程数-核心线程数)。
查看非核心线程数是否达到最大
否:利用线程工厂创建非核心线程执行任务
是:执行拒绝策略
2.5 常用方法
除了在创建线程池时指定上述参数值外,还可在线程池创建后通过如下方法进行设置:

此外还有一些方法:
- getCorePoolSize():返回线程池的核心线程数,这个值是一直不变的,返回在构造函数中设置的coreSize大小;
- getMaximumPoolSize():返回线程池的最大线程数,这个值是一直不变的,返回在构造函数中设置的coreSize大小;
- getLargestPoolSize():记录了曾经出现的最大线程个数(水位线);
- getPoolSize():线程池中当前线程的数量;
- getActiveCount():Returns the approximate(近似) number of threads that are actively executing tasks;
- prestartAllCoreThreads():会启动所有核心线程,无论是否有待执行的任务,线程池都会创建新的线程,直到池中线程数量达到 corePoolSize;
- prestartCoreThread():会启动一个核心线程(同上);
- allowCoreThreadTimeOut(true):允许核心线程在KeepAliveTime时间后,退出;
2.6 线程数设定多少合适
这个是个高频的面试点,至于设定多少,流传最多的就是“公式”,所谓的公式,一般情况下,需要根据你的任务情况来设置线程数,任务可能分为两种类型——CPU密集型和IO密集型:
- CPU密集型:则线程池大小设置为N+1。
- IO密集型:则线程池大小设置为2N+1。
上面的N为CPU总核数,但在实际场景下,公式只能是当作一个参考。
很多时候,我们应用部署在云服务器上,有时候我们的机器显示是8核的,但实际上适用的只是虚拟机而已,并不是物理机,这就导致大多数情况下发挥不出8核的作用来。
而且,上面的公式中,前提要求是知道你的应用是IO密集型还是CPU密集型,那么,评判一个应用是CPU密集型还是IO密集型的标准是什么?真的能明确区分出来吗?
还有一点就是,现在很多CPU都采用了超线程技术,也就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能适用线程级并行计算。所以我们可以看到“4核8线程的CPU”,也就是物理内核有4个,逻辑内核有8个,如果用上述的公式,貌似按照4和8配置都不合理,因为超线程技术的性能提升也并不是100%的。
所以在设定线程数的时候,要考虑什么业务场景、什么机器配置、多大的并发量、一次业务处理整体耗时是多少,最后在上线的时候可以根据公式大致设置一个数值,然后再根据你自己的实际业务情况,以及不断的压测结果,再不断调整,最终达到一个相对合理的值。
三、线程池的实现原理(源码分析)
下面我们通过源码来分析一下ThreadPoolExecutor类中三个比较核心的方法。
3.1 添加一个任务(execute()方法)
首先我们看一下线程池中的execute()方法,该方法用于向线程池中添加一个任务。
源码:

分析:
第一个红框:先检查是否有空闲的核心线程
workCountOf(c)方法根据ctl的低29位来得到有效的线程数。
判断有效的线程数是否小于核心线程数。
如果是是。则创建一个线程来处理任务(核心线程)。
第二个红框:走到这,说明核心线程数已满了
isRunning(c)方法判断当前是否是运行状态,如果是,则尝试能否将任务放入工作队列(work.offer(command)方法)。
如果也添加成功了。则再次拿到ctl值,再次检查状态,如果不再运行,并且移除添加的任务成功,则抛出拒绝策略。
如果在运行,则检查有效线程数是否为0,如果是,则新建一个线程(非核心线程)。
第三个红框:这里说明工作队列也满了
addwork(command,flase)方法尝试新建一个线程来处理任务(非核心)。
如果失败,则调用拒绝策略。
3.2 添加work线程(addworker())
从方法execute的实现可以看出:addWorker主要负责创建新的线程并执行任务。
这块代码比较长,所以我们把它分成两段来介绍,先看第一段。
源码:

分析:
第一个红框:做是否能够添加工作线程条件过滤,这里的情况比较多,仅进行关键代码的解释
rs为运行状态,源码中频繁适用大小关系来作为条件判断,大小关系:RUNNING(运行)<SHUTDOWN(关闭)<STOP(停止)<TIDYING(整理)<TERMINATED(终止)。
firstTask判断提交的任务是否为空。
return false表示不处理提交的任务,直接返回。第二个红框:做自旋,更新创建线程数量
第一个if:校验有效线程数是否超过阈值,如果超过则不处理提交的任务。
第二个if:适用CAS讲workerCount+1,修改成功则跳出循环。
第三个if:重新读取ctl,判断当前运行状态,如果不等于上面获取的运行状态rs,说明rs被其它线程修改了,跳到retry重新校验线程池的状态。
ps:retry是java中的goto语法,只能运行在break和cotinue后面。
接着看后面的代码。
源码:

分析:先说下两个变量 workerStarted——Worker线程是否启动,workerAdded——Worker线程是否成功增加。
第一个红框:获取线程池主锁
用firstTask和当前线程创建一个Worker。
拿到Worker对应的线程t。
如果t不为空,获取线程池主锁,通过ReentrantLock锁来保证线程安全。
第二个红框:添加线程到workers中(线程池中)。
第三个红框:如果woker添加成功,则启动新建的线程执行。
我们看看这个wokers是什么:
一个HashSet,所以,线程池的存储结构其实就是一个HashSet。
3.3 worker线程处理队列任务(runWorker())
上文addWorker()方法里提到,当Worker里的线程启动时,就会调用该方法。
源码:
分析:
第一个红框:取任务执行(如果是第一次执行任务或者能从队列中取到任务)。
第二个红框:获取到任务后,执行任务开始前操作钩子。
第三个红框:执行任务。
第四个红框:执行任务后钩子
ps:这两个钩子(beforeExecute、afterExecute)允许我们自己继承线程池,也就是我们自己可以重写这两个方法,做任务执行前、后的处理。


四、Java中自带的5种线程池
这五种线程池都是由Executors工具类提供,该类看起来功能还是比较强大的,又用到了工厂模式,扩展性很强,重要的是用起来还特别方便,如:
//创建一个固定大小的线程池
ExecutorService executorService = Executors.newFixedThreadPool(1);接下来我们详细分析一下Java自带的五种线程池。
4.1 newFixedThreadPool
FixedThreadPool被称为可重用固定线程数的线程池,源码如下:
可以看到,核心线程数(corePoolSize)和最大线程数(maximumPoolSize)都是传进来的nThreads,这就意味着这个数量在其生命周期内不会变化,当线程池中的线程都在工作时,新提交的任务会被放置到一个无界队列中(没有设置初始大小)等待被执行。
4.2 newWorkStealingPool
用来执行大任务的线程池,WorkStealingPool可以自适应地调整线程池大小,它会根据处理器核数创建相应数量的线程池。源码如下:
可以看出,ForkJoinPool的构造函数被调用来创建WorkStealingPool线程池,Runtime.getRuntime().availableProcessors()来获取处理器的核心数量,来作为线程池的大小:
为什么说它是执行大任务的线程池呢?因为它本质是一个ForkJoinPool,而ForkJoinPool有一个工作窃取的概念:
工作窃取:当我去执行一个特别大的任务时,感觉我用一个线程去执行的时候周期会很长,那么我可以通过自己的业务去把他拆分成很多很多个小的业务,比如我的任务需要5分钟,那么我把它拆分成10个,可能就半分种就搞定了,然后再把这10个任务交给newWorkStealingPool线程池,找一些没事干的线程去帮我干这个任务
4.3 newSingleThreadExecutor
这是一个使用单个worker线程的Executor,下面是它的源码:
可以看到它的核心线程数和最大线程数都是1,其它参数都和FixedThreadPool相同,既然它是单线程,那么就可以保证任务的顺序执行。
4.4 newCachedThreadPool
这是一个会根据需要创建新线程的线程池,也就是大小可变的线程池,下面是它的源码:
可以看到,核心线程数为0,最大线程数为Integer的最大值(可以理解为无界),CachedThreadPool使用没有容量的SynchronousQueue(上面有提到过)作为线程池的工作队列,但最大线程数是无界的,这就意味着:如果主线程提交任务的速度高于CachedThreadPool线程处理任务的速度时,CachedThreadPool会不断地创建新线程。
ps:极端情况下,Cached会因为创建过多的线程而耗尽CPU和内存资源。
4.5 newScheduledThreadPool
它是可以执行定时任务的线程池,用ScheduledThreadPoolExecutor的构造函数来创建,而ScheduledThreadPoolExecutor继承自ThreadPoolExecutor,源码如下:
可以看到核心线程数是传进来的,最大线程数为Integer的最大值,工作队列用的是DelayWorkQueue延迟队列、无界。
ScheduledThreadPoolExecutor的实现:
ScheduledThreadPoolExecutor会把待调度的任务(ScheduledFutureTask:下面都简化为task)放到一个DelayQueue中。
task主要包含3个变量:
long time:表示这个任务将要被执行的具体时间。
long sequenceNumber:表示这个任务被添加到ScheduledThreadPoolExecutor中的序号。
long period:表示任务执行的间隔周期。
DelayQueue封装了一个PriorityQueue,这个PriorityQueue会对队列中的task进行排序。排序时,time小的排在前面(时间早的任务先执行),如果两个time相同,就比较sequenceNumber,小的排在前面。
代码Demo:
public class ScheduleDemo {public static void main(String[] args) {//创建ScheduledExecutorService线程池ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);//延迟5秒执行任务executor.schedule(() -> {//要执行的任务}, 5, TimeUnit.SECONDS);
//定时执行任务(延迟5秒开始,每隔10秒执行一次)executor.schedule(() -> {//要执行的任务}, 5, 10, TimeUnit.SECONDS);
// 定时执行任务(延迟 5 秒开始,每隔10秒执行一次,上一次任务执行完成后再延迟 10 秒)executor.scheduleWithFixedDelay(() -> {// 要执行的任务}, 5, 10, TimeUnit.SECONDS);}
}4.6 为什么不推荐通过Executors构建线程池
上述五种线程池,都可以通过Executors工具类来创建出来,使用起来也很方便,但是在阿里巴巴开发手册中也明确指出,不允许使用Executors创建线程池,并且指出了存在的弊端:
还有一点就是当你通过Executors创建线程池的时候,它创建的线程池大多都是已经帮你设置好了的参数,很多选项是没办法自定义的,在特殊的业务场景下,Executors工具类下的线程池也并不是“万能的”。
正确的做法就是通过ThreadPoolExecutor的构造函数来自己定义线程池。
除此之外,还可以通过一些开源类库,比如apache和guava等,笔者推荐使用guava提供的ThreadFactoryBuilder来创建线程池:
public class ThreadFactoryDemo {public static void main(String[] args) {//线程工厂ThreadFactory factory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 0L,TimeUnit.SECONDS, new LinkedBlockingQueue<>(2048),factory, new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 100; i++) {executor.execute(() -> {//业务代码});}}
}上述方式可以自定义线程名称,更方便出错时的溯源。
五、总结
- 线程池是一种用于管理和复用线程的机制。通过线程池,我们可以创建一组可用的线程,并且可以根据需要执行任务,避免频繁地创建和销毁线程,提高系统的性能和稳定性。
- 使用ThreadPoolExcutor类可以自定义线程池(也是创建线程池的正确做法),通过构造函数的7个核心参数,我们可以找到自己合适的线程池。
- 任务提交有两种方式,一种是execute():适用于没有返回值的情况,ThreadPoolExecutor自己的方法,第二种是submit():适用于需要返回值的情况,ThreadPoolExecutor父类的方法。
- ThreadPoolExecutor类的三个核心方法:execute()、addWorker()和runWorker(),了解其源码,才更有助于我们使用和调优线程池。
- Java中自带的5种线程池,通过Executors工具类创建,虽说用起来很方便,但并不推荐使用此方法来创建线程池。
End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教🙋。
相关文章:
Java并发编程第6讲——线程池(万字详解)
Java中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池,本篇文章就详细介绍一下。 一、什么是线程池 定义:线程池是一种用于管理和重用线程的技术(池化技术),它主…...

AI + Milvus:将时尚应用搭建进行到底
在上一篇文章中,我们学习了如何利用人工智能技术(例如开源 AI 向量数据库 Milvus 和 Hugging Face 模型)寻找与自己穿搭风格相似的明星。在这篇文章中,我们将进一步介绍如何通过对上篇文章中的项目代码稍作修改,获得更…...
归并排序(Java 实例代码)
目录 归并排序 一、概念及其介绍 二、适用说明 三、过程图示 四、Java 实例代码 MergeSort.java 文件代码: 归并排序 一、概念及其介绍 归并排序(Merge sort)是建立在归并操作上的一种有效、稳定的排序算法,该算法是采用分…...

【VUE】数字动态变化到目标值-vue-count-to
vue-count-to是一个Vue组件,用于实现数字动画效果。它可以用于显示从一个数字到另一个数字的过渡动画。 插件名:vue-count-to 官方仓库地址:GitHub - PanJiaChen/vue-countTo: Its a vue component that will count to a target number at a…...
)
Mysql /etc/my.cnf参数详解(二)
#buffer相关 #buffer pool根据实际内存大小调整,标准为物理内存的50% innodb_buffer_pool_size15996M //默认值128M,innodb_buffer_pool_size | 134217728 key_buffer_size 33554432 #根据物理内存大小设置 确保每个instance内的内存2G左右 <5000 1,>5000 &…...
6.10AUTOSAR操作系统概念与配置方法介绍(下))
AUTOSAR规范与ECU软件开发(实践篇)6.10AUTOSAR操作系统概念与配置方法介绍(下)
目录 2、 RTA-OS工程创建 3、 AUTOSAR操作系统配置方法 (1) 描述文件导入 (2) Counter配置...

蓝牙 - 经典蓝牙物理信道介绍
物理信道有多种类型。所有蓝牙物理信道的特点都是一组物理层的频率与时间参数相结合,并受到空间因素的限制。对于基本的和经过调整的蓝牙组网(piconet)所用物理信道,跳频用于定期改变频率,以减少干扰影响,同时也是出于监管原因。 …...

性能测试中未做集群时,在登入中已经保存了登入的session,但可能会出现在不同的服务器上显示登入失败
Session未进行集群共享时,则会出现服务器2,未登录...

Python环境下载安装使用
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...

图像扭曲之波浪扭曲
源码: void wave_sine(cv::Mat& src,cv::Mat& dst,double amplitude,double wavelength) {dst.create(src.rows, src.cols, CV_8UC3);dst.setTo(0);double xAmplitude amplitude;double yAmplitude amplitude;double xWavelength wavelength;double yWa…...

《自动驾驶与机器人中的SLAM技术》之GNSS相关基础知识总结
简介 本篇基于对《自动驾驶与机器人中的SLAM技术》中的GNSS定位相关基础知识进行总结用于备忘 知识点整理 GNSS(全球卫星导航系统)定位原理 GNSS 通过测量自身与地球周围各卫星的距离来确定自身的位置 , 而与卫星的距离主要是通过测量时间间隔来确定的 GNSS与GPS的关系 GPS(…...
【前端|CSS系列第4篇】面试官:你了解居中布局吗?
欢迎来到前端CSS系列的第4篇教程!如果你正在寻找一种简单而又强大的前端技术,以使你的网页和应用程序看起来更加专业和美观,那么居中布局绝对是你不能错过的重要知识。 在前端开发中,实现居中布局是一项必备技能,无论…...

安全物理环境技术测评要求项
1.物理选择-保证等级保护对象物理安全的前提和基础 1-0/2-2/3-2/4-2(级别-要求项数量) a)具备防震、防风、防雨能力 b)避免顶层或地下室,否则应加强防水、防潮措施 测评实施重点: 1)机房场地所在…...
SAP MTS案例教程PP生产前台操作
目录 本章介绍 2 生产订单相关操作 3 批量查询生产订单 3 单个显示生产任务单 5 生产订单批量可用性检查 6 显示短缺部件信息 8 修改生产订单 9 重读工单计划主数据 11 单个下达生产订单 12 批量下达生产订单 13 非倒冲生产方式操作过程 15 多个工单批量发料 15 单个工单发料 1…...

Celery task 执行报错 TypeError: Object of type set is not JSON serializable 问题分析处理
情况描述: 定义了新的shared_task推送到生产环境后,发现无法执行,会报错set对象无法序列化,报错内容如下: Traceback (most recent call last):File "/tmp/venv/lib64/python3.6/site-packages/kombu/serializati…...

【大魔王送书第一期】《一名阿里服务端开发工程师的进阶之路》
一、前言 目前,资讯、社交、游戏、消费、出行等丰富多彩的互联网应用已经渗透到了人们生活和工作的方方面面,正深刻改变着信息时代。随着用户规模的增长和应用复杂度的上升,服务端面临的技术挑战越来越严峻。在头部互联网企业,服…...

[FPGA IP系列] BRAM IP参数配置与使用示例
FPGA开发中使用频率非常高的两个IP就是FIFO和BRAM,上一篇文章中已经详细介绍了Vivado FIFO IP,今天我们来聊一聊BRAM IP。 本文将详细介绍Vivado中BRAM IP的配置方式和使用技巧。 一、BRAM IP核的配置 1、打开BRAM IP核 在Vivado的IP Catalog中找到B…...

react ts
一、项目搭建 1、创建项目 使用vite生成项目 npx create-react-app react-ts-project --template typescript 启动项目 yarn start 删除无用组件 2、设计目录结构 资源说明http网络请求assets公共资源components组件router路由配置utils工具模块store状态机App.tsx应用…...

配置MySQL
配置MySQL_5.7.16 一级目录2.1.1 安装包准备2.1.2 安装MySQL2.1.3 配置MySQL 一级目录 2.1.1 安装包准备 1)将安装包和JDBC驱动上传到/opt/software,共计6个 01_mysql-community-common-5.7.16-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.16-1.el…...
GFPGAN 集成Flask 接口化改造
GFPGAN是一款腾讯开源的人脸高清修复模型,基于github上提供的demo,可以简单的集成Flask以实现功能接口化。 GFPGAN的安装,Flask的安装请参见其他文章。 如若使用POSTMAN进行测试,需使用POST方式,form-data的请求体&am…...

如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验?
如何通过Jellyfin Android TV客户端打造家庭影院级媒体体验? 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv 想要在智能电视上享受专业的媒体管理体验吗?…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

XHS-Downloader:小红书内容采集与管理的全栈解决方案
XHS-Downloader:小红书内容采集与管理的全栈解决方案 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...

ComfyUI-Manager终极指南:3步掌握AI绘画插件管理技巧
ComfyUI-Manager终极指南:3步掌握AI绘画插件管理技巧 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custom…...

量子最优控制中的iLQR算法实践与优化
1. 量子最优控制基础与挑战量子最优控制(Quantum Optimal Control, QOC)是现代量子计算中的核心技术,其核心目标是通过精心设计的控制脉冲序列,实现对量子系统状态演化的精确操控。在超导量子计算体系中,这一技术尤为重…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...

量子纠错程序的形式化验证方法与工程实践
1. 量子纠错程序验证的核心挑战量子纠错(Quantum Error Correction, QEC)是量子计算实现实用化的关键技术屏障。与传统经典计算不同,量子系统面临着更为复杂的噪声环境:退相干、门操作误差、测量错误等量子特异性噪声会迅速破坏脆…...

Verilog时钟分频实战:从偶数、奇数到小数分频的设计与实现
1. 项目概述:从零开始掌握Verilog时钟分频 在数字电路和FPGA设计中,时钟信号是驱动整个系统同步运行的“心跳”。然而,一个系统往往需要多种不同频率的时钟来驱动不同的模块,比如高速的处理器核心和低速的外设接口。直接使用多个外…...