GaussDB技术解读系列:高级压缩之OLTP表压缩
8月16日,第14届中国数据库技术大会(DTCC2023)在北京国际会议中心顺利举行。在GaussDB“五高两易”核心技术,给世界一个更优选择的专场,华为云数据库GaussDB首席架构师冯柯对华为云GaussDB数据库的高级压缩技术进行了详细的解读。
GaussDB高级压缩全景
高级压缩是面向业务全场景的数据库压缩解决方案,适用的场景主要分两类。第一类是存储类,主要为业务提供容量控制,减少业务扩容的概率和成本;第二类是传输类,主要是面向跨Region、跨AZ的业务场景如何去匹配业务的网络带宽的现实条件,为业务提供更稳定的SLA保证。这里面又有很多细分的场景,TP、AP都有。
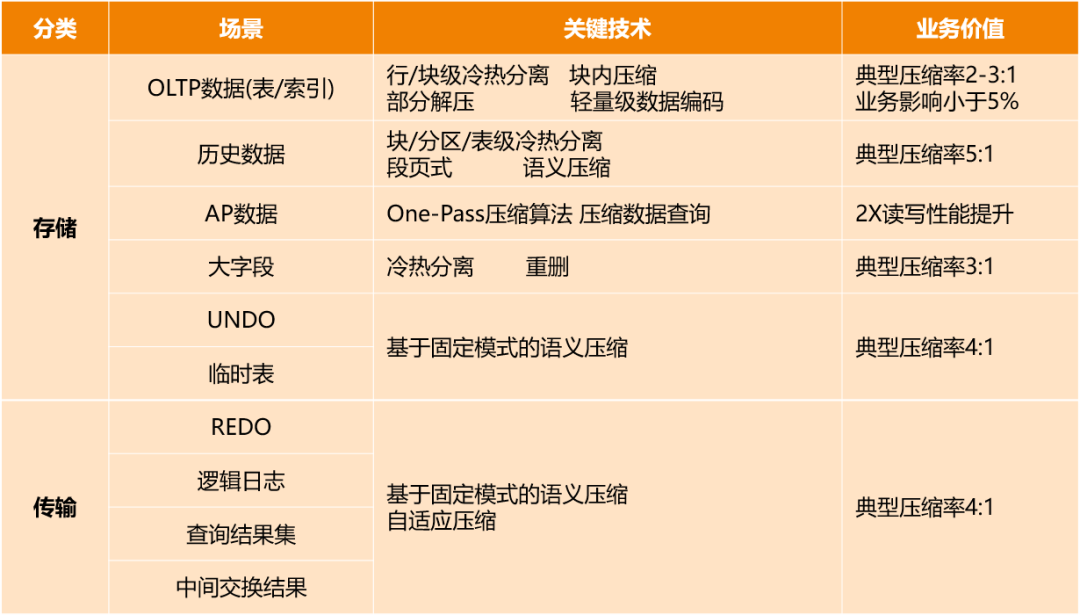
这里面有非常多的挑战,一是压缩算法怎么设计,二是怎么做冷热判定。我们在整个存储类的压缩里用的都是选择性压缩,基于系统自动发现数据的冷热,只压缩业务中相对比较冷的数据,不去碰相对热的数据。包括实现业务的零侵入、和存储引擎的结合,有很多技术挑战。
典型场景和目标设计
不同的场景对于压缩算法,包括压缩率、业务影响、业务侵入容忍度是不一样的。这里要介绍的,是我们第一个发布的OLTP表压缩的技术细节。讲这个之前,先讲一下OLTP表压缩究竟解决的是什么样的客户场景,这决定了我们整个技术目标。
有两个典型场景是我们在真实业务中碰到的。第一个场景,客户的业务来自于IBM小机,整个单库容量达到几十个TB,容量比较大。业务如果迁移到开放平台,比较大的问题是单体容量太大,整个运维窗口的时间比较长。我们有不同的选择,可以选择大家说的拆库,也就是分表分库,但拆库意味着需要做整个分布式改造,对有些业务来讲是很多年的存量的关键业务,这种改造方式整个风险是非常高的。第二个选择可以用压缩,压缩可以减少容量,但客户在业务设计的开始并没有做冷热分离,比如没有把用户的数据基于时间维度做分片,如果用压缩,客户首要的诉求是能否做到压缩对业务的影响足够低,其次才是压缩率,这是第一个典型场景。
第二个典型场景,客户业务基于分布式集群部署,容量增长得非常快,已经超过一个PB,并且还在不断增长。对于客户来讲,这是非常大的问题,需要定期做扩容。使用压缩同样可以帮助客户减少扩容的频率、变更的风险。但问题是一样的,客户数据同样没有做冷热分离,是面向扩展性来设计的,比如基于用户ID号进行分片,让不同用户的负载能够平均分配给不同的数据节点。由于没有做冷热分离,如果要用压缩,能否做到压缩对于业务的影响足够低,其次才是压缩率。这也是我们看到的非常典型的OLTP压缩的场景。
我们对这两个场景进行了分析,推导出三个基本的设计目标。首先,整个压缩方案必须是零侵入的,不能假设业务的已有数据分布,不能说建一个分区,数据一定能区分冷热,因为业务没有这样的条件。不能对业务的数据分布、逻辑模型有任何的假设,方案必须是零侵入的。第二,如果业务开启压缩,对业务的影响应该是极低的,我们定义至少10%,甚至5%,这是非常重要的。第三才是合理的压缩率,2:1或3:1,如果没有压缩率,做这些事情的价值就不存在了。这三个基本目标也决定了我们后面整个技术方案的设计和工程落地。
关键挑战一:如何判定业务的冷热数据?
确定完目标,有三个比较关键的问题需要解决。一是怎么判定业务的冷热数据,二是判定完之后怎么和现有的压缩引擎结合,对压缩后的数据有效地存储,第三点才是怎么实现有竞争力的压缩算法。
我们做冷热判定,首先是确定判定的粒度。可以按照表、分区、块来判定,也可以按照行来判定。判定的粒度越细,意味着对业务的侵入越低,对业务整个数据分布没有任何假设,当然实现的挑战也越大。基于我们定义的技术目标,在做OLTP表压缩时,第一个目标就是冷热判定必须是行级别的,这样对业务的侵入是最小的。
我们利用了GaussDB现有存储引擎已有的机制。GaussDB现在的存储引擎和其他引擎一样,在整个数据上除了存放用户数据之外还存放元数据,元数据里有事务信息,这个事务信息通常是用来实现事务的可见性,里面记录了最后一次修改的事务ID号。当这个事务ID号足够老,对于当前所有事务都可见,这个时候我们把事务ID号替换成物理时间戳,这个物理时间戳可以用来表达这行数据最后一次修改的时间是什么时候,如果这个时间足够早、足够老,真正达到了冷的条件,那么我们就可以对它进行压缩,用户可以用非常简单的逻辑实现冷热的判定。
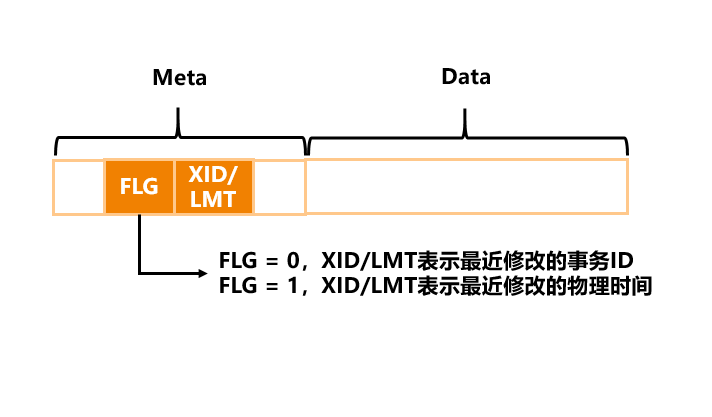
第二个例子是,用户可以自定义冷热条件,这个行如果长时间没有做任何修改,系统就可以把它压缩掉,否则不要碰,这是一个非常简单的策略。如果客户业务中有一些字段有非常清楚的冷热属性,比如交易的时间、交易的完成状态,那可以指定这个字段进行冷热判定。或者客户大部分的交易数据都满足3个月前的交易是冷数据,但其中某些特殊类型的交易,像担保交易,可能没有办法满足这个约束,这时候也可以自定义冷热条件。比如交易状态必须是完结的,或者交易类型不能是特定类型,通过自定义条件和最近修改时间的组合,可以灵活地定义什么样的数据应该压缩。这是第一点,怎么做冷热判定。
关键挑战二:如何对压缩后的数据有效地存储?
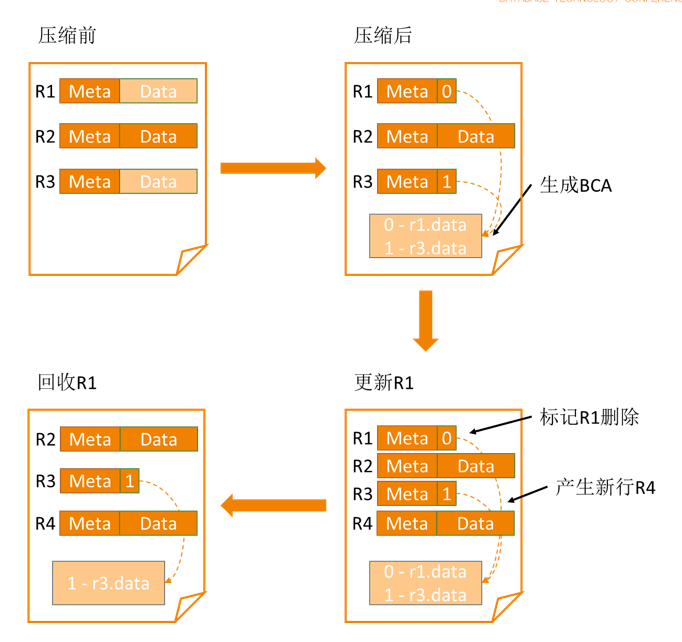
第二点,压缩后的目标数据怎么存。根据总体设计目标,我们希望做到对业务的侵入越低越好。我们选择了直接做块内的压缩:把一个块内所有满足冷热判定的行一次性压缩完,把压缩后的数据包就存放在当前数据块内。这样做从压缩率上讲并不是最优选择,但从对业务的影响上讲是一个更好的选择。因为业务即使定义了冷热判定条件,我们仍有一定的概率会访问冷数据,我们希望通过块内压缩的实现来保证访问冷数据的代价有一个确定性的上限,这是块内压缩的基本思考。
关键挑战三:如何实现有竞争力的压缩算法?
为什么做选择性压缩?很简单,没有任何一个压缩算法能做到数据压缩之后对业务没有影响,今天没有这样的黑科技,这是我们基本的技术判断,所以要去平衡压缩率和对业务的影响。我们首先做的是选择性压缩,业务数据分布满足典型的80-20分布政策,80%的数据占有80%的存储容量,但只消耗了20%的算力。比如银行交易,随着时间的推移,整个订单的访问频率会迅速降低,这是非常典型的满足冷热特征的业务。
如果做选择性压缩,那么只压缩那些占用80%存储容量,但只消耗20%算力的冷数据,就意味着我们在节省存储成本方面达成了80%的目标;而不去压缩那些只占用20%的存储容量,但却消耗80%算力的热数据,就意味着我们在降低对用户的业务影响方面达成了80%的目标,这是非常简单的技术选择。
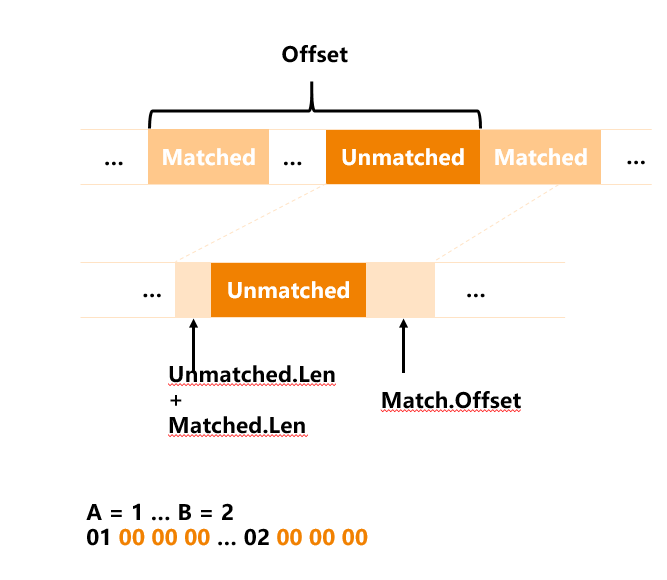
压缩算法我们也看了一些,比如LZ4是现在性能最好的算法,我们一开始用的就是这个算法,但比较大的问题是压缩率相对较低。如果仔细去分析算法原理,LZ4是基于LZ77算法的一种实现,是把压缩的数据看成一个连续的字节流,从当前开始寻找匹配的字符串,找到字符串长度和偏移进行编码来代替被匹配的字符串,从而实现压缩的效果。LZ77算法从原理上讲非常适合于长文本,相对不太适合像结构化数据这样的,里面有大量的数值类型和短文本,这是数据库的特征。
我们做了很多优化,比如对数值类型做了差值编码,所以压缩框架实际上有两层,第一层对数据做编码,第二层用LZ77算法。原生LZ77算法有很多优化是面向长文本的,包括3字节的编码,我们做了非常多的工程优化,使它更容易面向短文本,比如两字节短编码,包括内置行边界。这里我们无法给出很多细节,主要的优化背景其实就两个:一个是通用压缩算法并不特别适合于关系型数据库结构化数据的场景,二是我们所做的这些工程优化,从通用的压缩场景来讲,并不一定是最优的,但它们是特别适合关系型数据的。
竞争力评估
最后有一个简单的评估,是通过TPCC和TPCH测试对目前的商用数据库O*进行的压缩率评估。O*和我们的GaussDB一样,也提供了完整的冷热判定能力,但由于发展原因,它实际上先做了数据压缩,再做冷热判定,所以整个压缩算法的压缩率是比较低的;我们使用了标准的TPCH的数据,测试表明我们的压缩率相对于O*平均提高了50%,这些数据可以被直接验证。

其他的一些厂商,像开源数据库,还有国内的厂商都提供了压缩的解决方案,但共同问题是没有做冷热判定,对用户来讲可以指定一个表或一个分区,里面的数据要么都被压缩,要么都不压缩。压缩意味着存储成本节省,但性能会下降,不压缩则是另外一个选择。这个看上去简单的选择对客户来讲反而是最难的,这也是为什么我们看到今天有很多压缩的解决方案,但用户却不会去用,因为谁也不知道开启压缩之后有什么后果,这是比较大的问题。
这里我们也做了一个标准的TPCC的测试评估,基于GaussDB单机版本进行选择性压缩。根据TPCC的语义,所有已经配送完成的订单就不会再变更,但仍有一定的概率被访问到,这是非常贴近于真实业务场景的访问模型。所以,我们的压缩算法选择了压缩流水类数据,比如订单数据,而一些状态类的数据,比如库存、账户等没有去压缩,在流水数据里,我们也只压缩已经配送完成的订单,不压缩没有配送完成的订单。从最后的结果看,整个压缩之后对于业务的影响在1.5%左右。我们相信我们是业内第一个在150万tpmC性能峰值仍然能够开启压缩并且性能基本不下降的产品。
下一步计划:语义压缩
我们已经打破了数据编码和压缩算法的边界,但对压缩算法的使用本质上没有变化,即把整个数据看成是一维的字节流。但关系数据是两维的、结构化的数据,所以在数据的行与行之间、列与列之间存在非常丰富的关联。这种关联主要来自两种场景,一种是业务本身在做建模时引入的关联,比如为了消除连接,数据模型设计成扁平化或低范式化,这会引入非常常见的关联。第二种是业务服务化改造进行服务的分层,数据在不同的服务分层之间被不断传递而造成的一种关联。我们通过一些算法自动发现这种结构化数据之间的关联,发现这些关联不是用于商品推荐或者服务治理,而是希望通过消除这些关联达到压缩的目的。在很多场景里,这种基于语义的关联消除技术会比通用算法提供更好的压缩效能,这是我们后面会重点去构建竞争力的地方。
小结
为什么做高级压缩的特性?因为我们希望在三个领域实现业内领先。
第一、是在性能敏感场景,在提供合理的压缩率的前提下,对业务的影响(越小越好)实现业内领先。
第二、是在成本敏感的场景,在提供合理的压缩解压性能的前提下,压缩率(越高越好)实现业内领先。
第三、大家可能注意到,冷热判定本身不仅可以做数据压缩,还可以做很多别的工作,比如多存储介质、负载的感知,我们希望对于整个冷热判定,包括模型及方法,在能够支持的业务领域的广度方面,能够做到业内领先,这是我们做高级压缩特性的一个基本目的。
相关文章:
GaussDB技术解读系列:高级压缩之OLTP表压缩
8月16日,第14届中国数据库技术大会(DTCC2023)在北京国际会议中心顺利举行。在GaussDB“五高两易”核心技术,给世界一个更优选择的专场,华为云数据库GaussDB首席架构师冯柯对华为云GaussDB数据库的高级压缩技术进行了详…...

管理类联考——英语二——实战篇——大作文——图表——静态图表——第一段
第一句:What is clearly presented in the above 图表类型 is the statistics of 主题词 1. 翻译:从上述图表类型中我们能够清晰地得知有关主题词1的数据。 [备注1]:本句对图表进行整体描述,无需描述具体各项内容所占比例,只需提出主题词的哪方面的有关数据…...
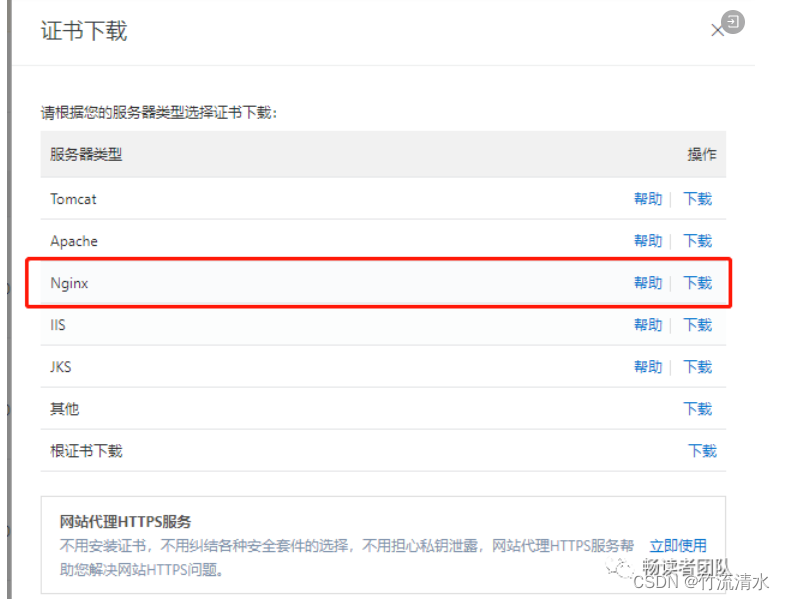
https 的ssl证书过期处理解决方案(lighthttpd)
更换证书:lighthttpd 配置文件位置:/opt/vmware/etc/lighttpd/lighttpd.conf (配置文件的最底部 G快速来到底部) 方案一:阿里云申请免费的证书 这里公司内网环境没有配置域名,可以创建一个临时域名&…...
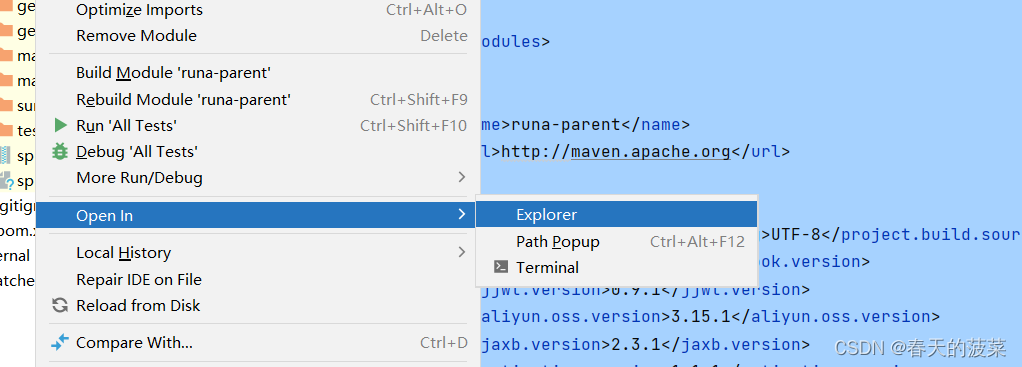
【java】【idea2023版】Springboot模块没有.iml文件的问题
目录 方法一: 1、首先鼠标选中对应的对应的模块 ,按两下Ctrl键 2、project中选择对应的模块 3、运行mvn idea:module 命令编辑 方法二: 1、可以右键点击open Terminal 2、然后在打开的Terminal里输入 方法一: 1、首先鼠…...

Qt QScrollArea使用
在使用QScrollArea时,有几个注意事项需要考虑: 设置合适的小部件(widget)大小策略: 确保将要放置在QScrollArea中的小部件设置为合适的大小策略。这将确保小部件可以根据需要进行扩展,以适应滚动区域的大小…...
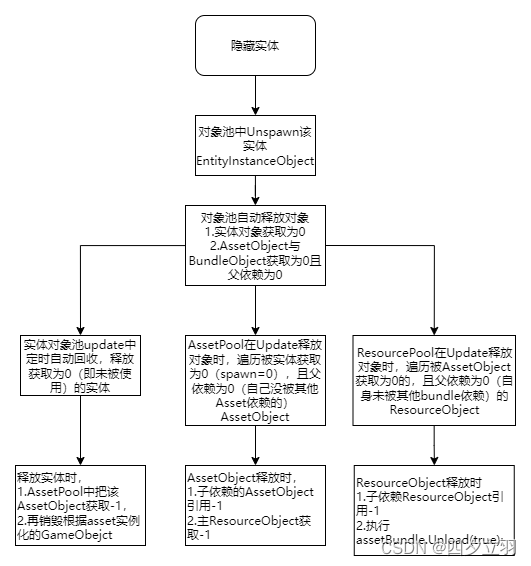
Unity3d:GameFramework解析:实体,对象池,资源管理,获取计数,引用计数,自动释放
基本概念 1.GF万物基于引用池IReference 2.ObjectBase : IReference类的m_Target持有unity中Mono,资源,GameObejct 3.AssetObject : ObjectBase类m_Target持有Assetbundle中的Asset,具有获取,引用两个计数管理释放 4.ResourceObj…...
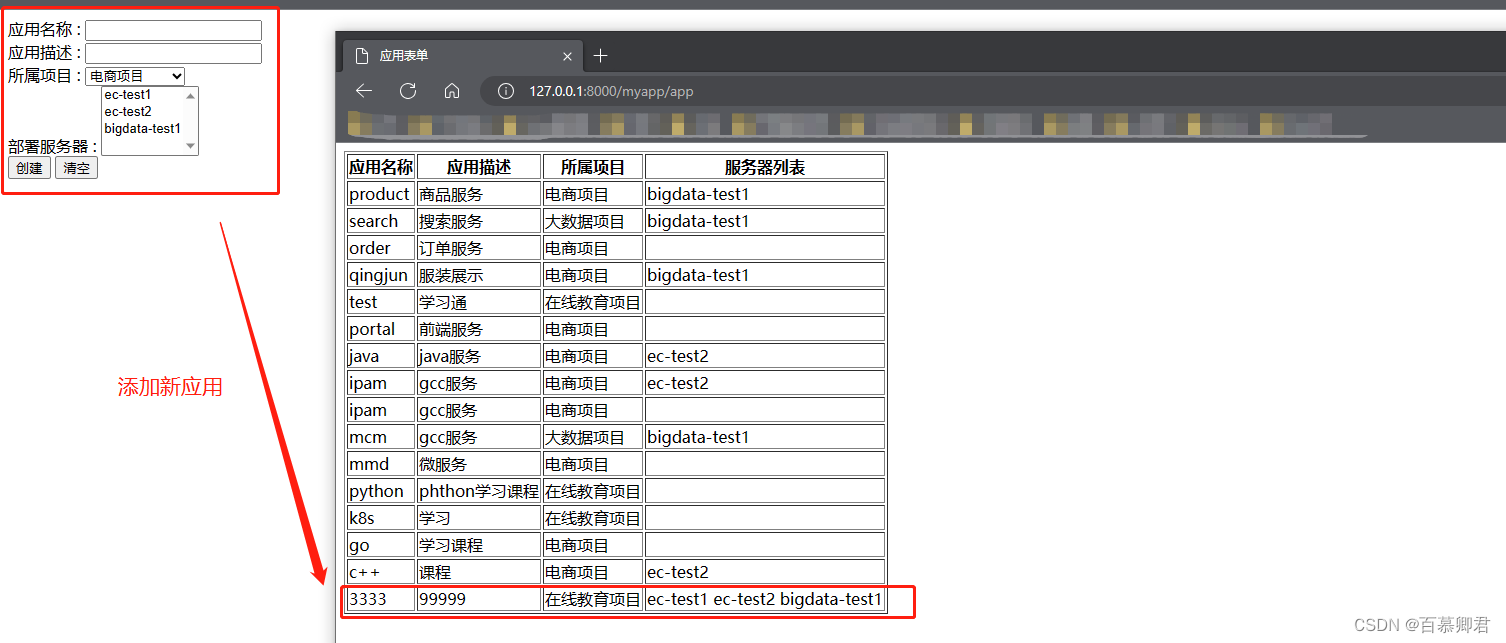
Django基础6——数据模型关系
文章目录 一、基本了解二、一对一关系三、一对多关系3.1 增删改查3.2 案例:应用详情页3.2 案例:新建应用页 四、多对多关系4.1 增删改查4.2 案例:应用详情页4.3 案例:部署应用页 一、基本了解 常见数据模型关系: 一对一…...

【chrome扩展开发】如何在项目中判断插件是否已安装
由于安全限制,本文采取间接的方式实现 1、项目部分 比如通过cookie、localStorage等进行状态存储 1.1、初始化判断 function getCookie(name){let arr document.cookie.match(new RegExp("(^| )"name"([^;]*)(;|$)"))if(arr ! null){return u…...
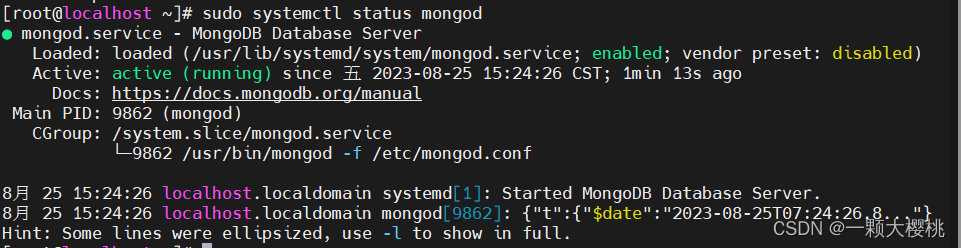
Centos 7.6 安装mongodb
以下是在CentOS 7.6上安装MongoDB的步骤: 打开终端并以root用户身份登录系统。 创建一个新的MongoDB存储库文件 /etc/yum.repos.d/mongodb-org-4.4.repo 并编辑它。 sudo vi /etc/yum.repos.d/mongodb-org-4.4.repo在编辑器中,添加下面的内容到文件中并…...
Ubuntu下安装nginx服务,实现通过URL读取ubuntu下图片
1.安装nginx包 sudo apt update sudo apt install nginx 2.安装完成后系统自动启动nginx sudo systemctl status nginx 查看nginx服务的状态 3.开启防火墙上的HTTP服务端口80 sudo ufw allow ‘Nginx HTTP’ 4.在浏览器输入 http://localhost 看到nginx的欢迎界面,…...

本地部署 Stable Diffusion(Mac 系统)
在 Mac 系统本地部署 Stable Diffusion 与在 Windows 系统下本地部署的方法本质上是差不多的。 一、安装 Homebrew Homebrew 是一个流行的 macOS (或 Linux)软件包管理器,用于自动下载、编译和安装各种命令行工具和应用程序。有关说明请访问官…...
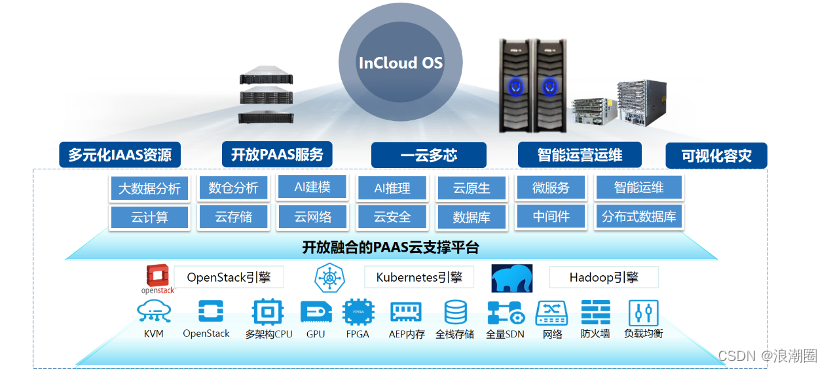
浪潮云海护航省联社金融上云,“一云多芯”赋能数字农业
农村金融是现代金融体系的重要组成部分,是农业农村发展的重要支撑力量,而统管全省农商行及农信社的省级农村信用社联合社(以下简称:省联社)在我国金融系统中占据着举足轻重的地位。省联社通常采用“大平台小法人”的发…...

MyCat的XA事务研究及字符集问题
MyCAT 1.4 开发版,初步实现了XA事务,关注这个高级技术的同学可以编译代码并测试其正确性。。 在手动事务模式下,可以执行 set xaon开启XA事务支持 目前实现了不跨分片的SQL的XA事务,测试过程如下 mysql> set autocommit0; Qu…...
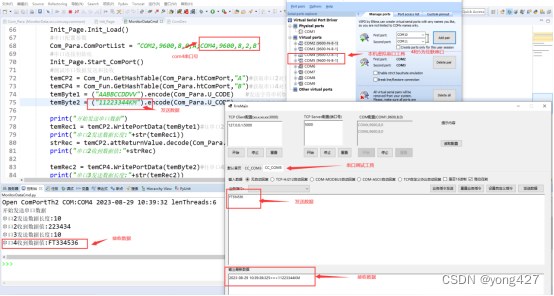
9、监测数据采集物联网应用开发步骤(7)
监测数据采集物联网应用开发步骤(6) 串口(COM)通讯开发 本章节测试使用了 Configure Virtual Serial Port Driver虚拟串口工具和本人自写的串口调试工具,请自行baidu下载对应工具 在com.zxy.common.Com_Para.py中添加如下内容 #RS232串口通讯列表 串口号,波特率,…...
- 小程序页面优化)
微信小程序开发教学系列(9)- 小程序页面优化
第9章 小程序页面优化 在开发小程序时,页面性能优化是非常重要的一项任务。优化页面性能可以提升用户体验,使小程序更加流畅和高效。本章将介绍一些常见的页面优化方法和技巧,帮助您提升小程序的性能。 9.1 页面性能优化的基本原则 页面性…...
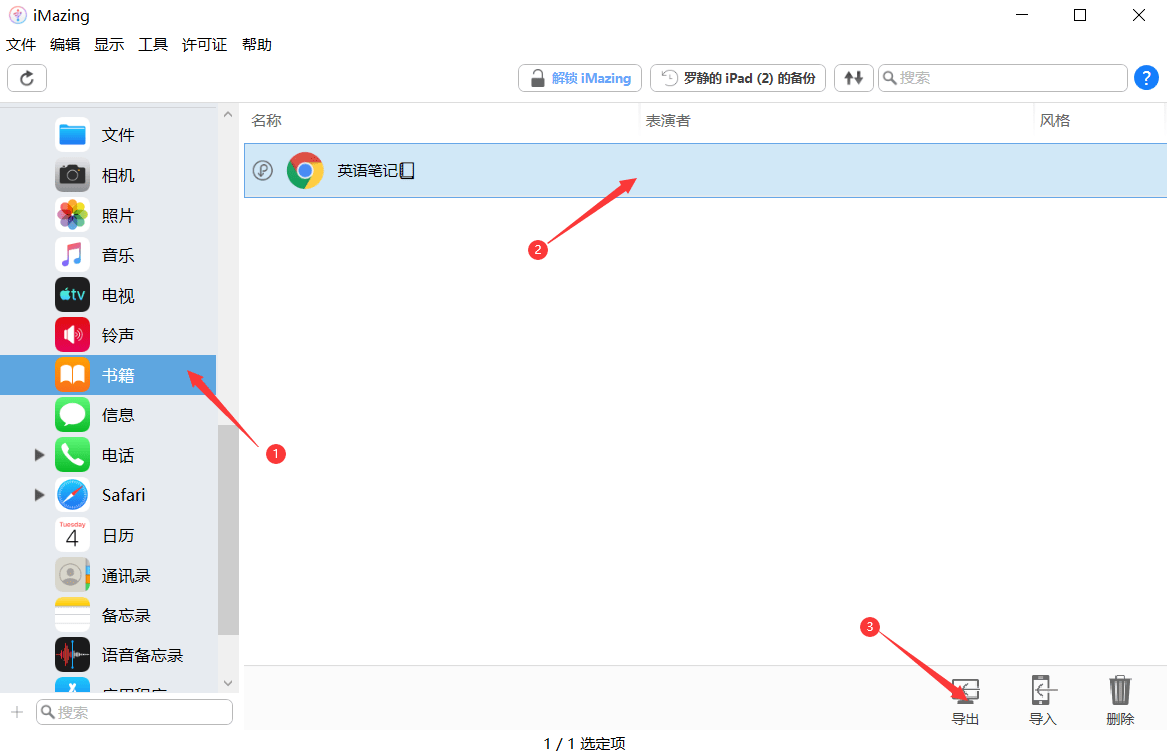
如何将储存在Mac或PC端的PDF文件传输到移动设备呢?
iMazing是一款iOS设备管理软件,用户借助它可以将iPad或iPhone上的文件备份到PC或Mac上,还能实现不同设备之间的文件传输,能很大程度上方便用户进行文件管理。 在阅读方面,iPad和iPhone是阅读PDF的优秀选择,相较于Mac或…...

一图看懂架构划分原则:技术划分 OR 领域划分?
架构划分原则 技术划分 描述: 按技术用途组织系统组件典型示例: 分层(多层)架构 组件按技术层组织 用户界面: 与用户直接交互的部分业务规则和核心处理: 逻辑和算法与数据库交互: 数据存取和查询数据库层: 数据存储和管理 优点: 当大部分更改与技术层次对齐时适用 缺点: 域更…...

从零开始的Hadoop学习(二)| Hadoop介绍、优势、组成、HDFS架构
1. Hadoop 是什么 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通常是指一个更广泛的概念—Hadoop生态圈。 2. Hadoop 的优势 高可靠性:Hadoop底层维护多…...

问道管理:逾4600股飘红!汽车板块爆了,多股冲击涨停!
A股商场今天上午全体低开,但其后逐级上行,创业板指数上午收盘大涨超越3%,北向资金也完成净买入38亿元。 别的,A股商场半年报成绩发表如火如荼进行中,多家公司发表半年报后股价应声大涨,部分公司股价冲击涨停…...

Java 语言实现选择排序算法
【引言】 选择排序算法是一种简单但有效的排序算法。它的原理是每次从未排序的元素中选择最小(或最大)的元素,放在已排序的末尾(或开头),逐渐形成有序序列。本文将使用Java语言实现选择排序算法,…...

ARM Cortex-A72 GICv3中断处理机制与优化实践
1. ARM Cortex-A72 GIC CPU接口架构概述在ARMv8-A架构中,通用中断控制器(GIC)作为中断管理的核心组件,其CPU接口承担着处理器核心与中断源之间的桥梁作用。Cortex-A72处理器实现了GICv3架构规范,相较于前代GICv2,主要引入了以下关…...

Termux零门槛部署Kali:从命令行到可视化桌面的完整实践
1. 为什么要在手机上部署Kali Linux? 几年前我第一次听说能在手机上运行Kali Linux时,第一反应是"这玩意儿能用吗?"。但当我真正尝试后才发现,这种便携式的渗透测试环境简直太香了!想象一下,在地…...

PromptFlow:企业级AI应用编排与全生命周期管理工具详解
1. 项目概述:PromptFlow,一个被低估的AI应用编排利器如果你最近在折腾大语言模型应用,从简单的聊天机器人到复杂的多步推理工作流,大概率会听到“LangChain”、“LlamaIndex”这些名字。它们确实火,社区活跃࿰…...

终极指南:如何用开源缠论量化工具实现专业级交易可视化
终极指南:如何用开源缠论量化工具实现专业级交易可视化 【免费下载链接】chanvis 基于TradingView本地SDK的可视化前后端代码,适用于缠论量化研究,和其他的基于几何交易的量化研究。 缠论量化 摩尔缠论 缠论可视化 TradingView TV-SDK 项目…...

RPFM:重新定义全面战争MOD开发的工作流革命
RPFM:重新定义全面战争MOD开发的工作流革命 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://gitcode.com/g…...

ARM TLB机制与虚拟化加速:TLBIP指令与TLBID域深度解析
1. ARM TLB机制与虚拟化加速 在现代ARM架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,其性能直接影响虚拟地址转换效率。随着虚拟化技术的普及,ARMv8/v9架构引入了…...

CST实战指南 | 场路协同仿真中的元器件模型导入与验证
1. 场路协同仿真中的元器件模型导入基础 我第一次接触CST场路协同仿真时,最头疼的就是如何把各种元器件模型正确导入到仿真环境中。经过多次项目实践,我发现这其实是个系统性工程,需要根据不同的仿真场景和元器件类型采取不同的处理策略。 在…...
)
别再手动整理停用词了!分享我私藏的NLP中英文停用词库(含哈工大、百度、川大版)
NLP停用词库实战指南:如何科学选择与高效应用 在自然语言处理项目中,数据预处理环节往往消耗开发者60%以上的时间,而停用词处理又是其中最基础却最容易出错的步骤。我曾见过团队因为使用不恰当的停用词表,导致情感分析模型将&quo…...

ARM Cortex-A72浮点与SIMD寄存器架构详解
1. ARM Cortex-A72高级SIMD与浮点寄存器架构解析在嵌入式系统和高性能计算领域,ARM Cortex-A72处理器以其卓越的能效比和计算性能著称。作为其核心功能模块之一,高级SIMD(单指令多数据)和浮点运算单元为现代计算密集型应用提供了关…...

本地AI对话伴侣实战:Electron+llama.cpp部署与调优指南
1. 项目概述:一个桌面端的本地AI对话伴侣最近在折腾本地大语言模型(LLM)的时候,发现了一个挺有意思的项目:ItsPi3141/alpaca-electron。简单来说,这是一个用 Electron 框架打包的桌面应用程序,它…...