《Flink学习笔记》——第九章 多流转换
无论是基本的简单转换和聚合,还是基于窗口的计算,我们都是针对一条流上的数据进行处理的。而在实际应用中,可能需要将不同来源的数据连接合并在一起处理,也有可能需要将一条流拆分开,所以经常会有对多条流进行处理的场景
简单划分(两大类):
- 分流——把一条数据流拆分成完全独立的两条或多条,一般通过侧输出流来实现
- 合流——多条数据流合并为一条数据流,如union,connect,join,coGroup
9.1 分流
9.1.1 简单实现
其实根据条件筛选数据的需求,本身非常容易实现:只要针对同一条流多次独立调用.filter()方法进行筛选,就可以得到拆分之后的流
例子:根据用户进行划分
public class SplitStreamByFilter {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.addSource(new ClickSource());SingleOutputStreamOperator<Event> maryStream = stream.filter(new FilterFunction<Event>() {@Overridepublic boolean filter(Event value) throws Exception {return value.getUser().equals("Mary");}});SingleOutputStreamOperator<Event> bobStream = stream.filter(new FilterFunction<Event>() {@Overridepublic boolean filter(Event value) throws Exception {return value.getUser().equals("Bob");}});SingleOutputStreamOperator<Event> otherStream = stream.filter(new FilterFunction<Event>() {@Overridepublic boolean filter(Event value) throws Exception {return !value.getUser().equals("Mary") && !value.getUser().equals("Bob");}});maryStream.print("Mary");bobStream.print("Bob");otherStream.print("other");env.execute();}
}9.1.2 使用侧输出流
public class SplitStreamByOutputTag {private static OutputTag<Tuple3<String, String, Long>> MaryTag = new OutputTag<Tuple3<String, String, Long>>("Mary-pv") {};private static OutputTag<Tuple3<String, String, Long>> BobTag = new OutputTag<Tuple3<String, String, Long>>("Bob-pv") {};public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<Event> stream = env.addSource(new ClickSource());SingleOutputStreamOperator<Event> processStream = stream.process(new ProcessFunction<Event, Event>() {@Overridepublic void processElement(Event event, Context context, Collector<Event> collector) throws Exception {if (event.getUser().equals("Mary")) {context.output(MaryTag, new Tuple3<>(event.getUser(), event.getUrl(), event.getTimestamp()));} else if (event.getUser().equals("Bob")) {context.output(BobTag, new Tuple3<>(event.getUser(), event.getUrl(), event.getTimestamp()));} else {collector.collect(event);}}});processStream.getSideOutput(MaryTag).print("Mary");processStream.getSideOutput(BobTag).print("Bob");processStream.print("other");env.execute();}
}
9.2 基本合流操作
9.2.1 联合(union)
将多条流合在一起
要求:要联合的流的数据类型必须相同
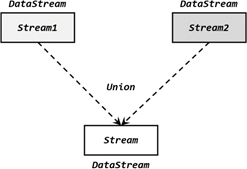
返回的是DataStream
使用方法:
stream1.union(stream2, stream3, ...)
在事件时间语义下:不同流的水位线快慢不同,如果合并在一起,水位线该以哪个为准呢?
答:多流合并时的水位线以最小的那个为准,和之前介绍的并行任务水位线的传递规则完全一致。
代码略
9.2.2 连接(connect)
流的联合union虽然简单,但是受限于数据类型不能改变。Flink提供了另一种合流操作——连接,它允许不同数据类型的流进行合并
1、连接流
连接流是多条流形式上的“合并”,虽然被放在了同一个流中,但内部仍保持各自的数据形式不变,彼此之间是相互独立的。
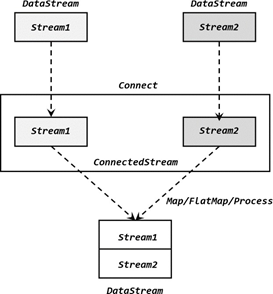
stream1.connect(stream2)
返回的是ConnectedStreams
ConnectedStreams在调用.map()方法时,传入的不再是一个简单的 MapFunction, 而是一个 CoMapFunction
ConnectedStreams.map(new CoMapFunction())
2、CoProcessFunction
ConnectedStreams在调用.process()时,需要传入CoProcessFunction
对于连接流 ConnectedStreams 的处理操作,需要分别定义对两条流的处理转换
public abstract class CoProcessFunction<IN1, IN2, OUT> extends AbstractRichFunction {...public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) public void onTimer(long timestamp, OnTimerContext ctx, Collector<OUT> out) public abstract class Context {...}...
}例子:略
代码略
9.3 基于时间的合流——双流联结(Join)
对于两条流的合并,很多情况我们并不是简单地将所有数据放在一起,而是希望根据某个字段的值将它们联结起来,“配对”去做处理。例如用传感器监控火情时,我们需要将大量温度传感器和烟雾传感器采集到的信息,按照传感器 ID 分组、再将两条流中数据合并起来,如果同时超过设定阈值就要报警。
我们发现,这种需求与关系型数据库中表的 join 操作非常相近。事实上,Flink 中两条流的 connect 操作,就可以通过 keyBy 指定键进行分组后合并,实现了类似于 SQL 中的 join 操作;另外 connect 支持处理函数,可以使用自定义状态和 TimerService 灵活实现各种需求,其实已经能够处理双流合并的大多数场景。
不过处理函数是底层接口,所以尽管 connect 能做的事情多,但在一些具体应用场景下还是显得太过抽象了。比如,如果我们希望统计固定时间内两条流数据的匹配情况,那就需要设置定时器、自定义触发逻辑来实现——其实这完全可以用窗口(window)来表示。为了更方便地实现基于时间的合流操作,Flink 的 DataStrema API 提供了两种内置的 join 算子,以及
coGroup 算子。本节我们就来做一个详细的讲解。
注:SQL 中 join 一般会翻译为“连接”;我们这里为了区分不同的算子,一般的合流操作
connect 翻译为“连接”,而把 join 翻译为“联结”。
9.3.1 窗口联结
如果我们希望将两条流的数据进行合并、且同样针对某段时间进行处理和统计,又该怎么做呢?
Flink 为这种场景专门提供了一个窗口联结(window join)算子,可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理
1、窗口联结的调用
窗口联结在代码中的实现,首先需要调用 DataStream 的.join()方法来合并两条流,得到一个 JoinedStreams ;接着通过.where() 和.equalTo() 方法指定两条流中联结的 key ; 然后通过.window()开窗口,并调用.apply()传入联结窗口函数进行处理计算
stream1.join(stream2).where(<KeySelector>).equalTo(<KeySelector>).window(<WindowAssigner>).apply(<JoinFunction>)
上面代码中.where()的参数是键选择器(KeySelector),用来指定第一条流中的 key;而.equalTo()传入的 KeySelector 则指定了第二条流中的 key。两者相同的元素,如果在同一窗口中,就可以匹配起来,并通过一个“联结函数”(JoinFunction)进行处理了。
这里.window()传入的就是窗口分配器,之前讲到的三种时间窗口都可以用在这里:滚动窗口(tumbling window)、滑动窗口(sliding window)和会话窗口(session window)。
而后面调用.apply()可以看作实现了一个特殊的窗口函数。注意这里只能调用.apply(),没有其他替代的方法。
传入的 JoinFunction 也是一个函数类接口,使用时需要实现内部的.join()方法。这个方法有两个参数,分别表示两条流中成对匹配的数据
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable { OUT join(IN1 first, IN2 second) throws Exception;
}
这里需要注意,JoinFunciton 并不是真正的“窗口函数”,它只是定义了窗口函数在调用时对匹配数据的具体处理逻辑。
当然,既然是窗口计算,在.window()和.apply()之间也可以调用可选 API 去做一些自定义, 比如用.trigger()定义触发器,用.allowedLateness()定义允许延迟时间,等等
2、窗口联结的处理流程
JoinFunction 中的两个参数,分别代表了两条流中的匹配的数据。这里就会有一个问题: 什么时候就会匹配好数据,调用.join()方法呢?接下来我们就来介绍一下窗口 join 的具体处理流程。
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数
(first,second)传入 JoinFunction 的.join()方法进行计算处理,得到的结果直接输出如图 8-8 所示。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果。
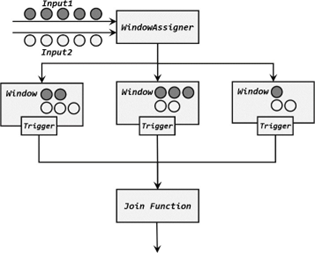
3、窗口联结实例
在电商网站中,往往需要统计用户不同行为之间的转化,这就需要对不同的行为数据流, 按照用户 ID 进行分组后再合并,以分析它们之间的关联。如果这些是以固定时间周期(比如1 小时)来统计的,那我们就可以使用窗口 join 来实现这样的需求
代码略
9.3.2 间隔联结
在有些场景下,我们要处理的时间间隔可能并不是固定的。比如,在交易系统中,需要实时地对每一笔交易进行核验,保证两个账户转入转出数额相等,也就是所谓的“实时对账”。两次转账的数据可能写入了不同的日志流,它们的时间戳应该相差不大,所以我们可以考虑只统计一段时间内是否有出账入账的数据匹配。这时显然不应该用滚动窗口或滑动窗口来处理——因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧,于是窗口内就都没有匹配了;会话窗口虽然时间不固定,但也明显不适合这个场景。 基于时间的窗口联结已经无能为力了。
为了应对这样的需求,Flink 提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔, 看这期间是否有来自另一条流的数据匹配。
1、间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作 A)中的任意一个数据元素 a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流 A 和 B,也必须基于相同的 key;下界 lowerBound
应该小于等于上界 upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。
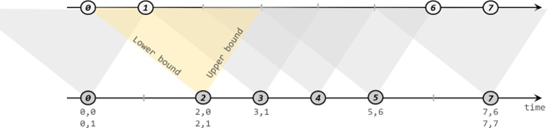
下方的流 A 去间隔联结上方的流 B,所以基于 A 的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2 毫秒,上界为 1 毫秒。于是对于时间戳为 2 的 A 中元素,它的可匹配区间就是[0, 3],流 B 中有时间戳为 0、1 的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A 中时间戳为 3 的元素,可匹配区间为[1, 4],B 中只有时间戳为 1 的一个数据可以匹配,于是得到匹配数据对(3, 1)。
所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,interval
join 做匹配的时间段是基于流中数据的,所以并不确定;而且流 B 中的数据可以不只在一个区间内被匹配。
2、间隔联结的调用
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction());
3、间隔联结实例
在电商网站中,某些用户行为往往会有短时间内的强关联。我们这里举一个例子,我们有两条流,一条是下订单的流,一条是浏览数据的流。我们可以针对同一个用户,来做这样一个联结。也就是使用一个用户的下订单的事件和这个用户的最近十分钟的浏览数据进行一个联结查询
代码略
9.3.3 窗口同组联结
除窗口联结和间隔联结之外,Flink 还提供了一个“窗口同组联结”(window coGroup)操作。它的用法跟 window join 非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将.join()换为.coGroup()就可以了.
内部的.coGroup()方法,有些类似于 FlatJoinFunction 中.join()的形式,同样有三个参数, 分别代表两条流中的数据以及用于输出的收集器(Collector)。不同的是,这里的前两个参数不再是单独的每一组“配对”数据了,而是传入了可遍历的数据集合。也就是说,现在不会再去计算窗口中两条流数据集的笛卡尔积,而是直接把收集到的所有数据一次性传入,至于要怎样配对完全是自定义的。这样.coGroup()方法只会被调用一次,而且即使一条流的数据没有任何另一条流的数据匹配,也可以出现在集合中、当然也可以定义输出结果了。
所以能够看出,coGroup 操作比窗口的 join 更加通用,不仅可以实现类似 SQL 中的“内连接”(inner join),也可以实现左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join)。事实上,窗口 join 的底层,也是通过 coGroup 来实现的
代码略
相关文章:
《Flink学习笔记》——第九章 多流转换
无论是基本的简单转换和聚合,还是基于窗口的计算,我们都是针对一条流上的数据进行处理的。而在实际应用中,可能需要将不同来源的数据连接合并在一起处理,也有可能需要将一条流拆分开,所以经常会有对多条流进行处理的场…...

openmmlab出现KeyError: ‘xxx is not in the model registry....‘
问题描述 在复现基于mmpose框架的算法时,运行程序出现KeyError: xxx is not in the model registry....的问题,报错原因是自定义的backbone等结构或者某些当前代码使用的方法没有注册到现有的包中, 导致在import的时候无法导入该方法。 解决方案 找到…...

错误代码0x80131500要怎么解决?快速修复方法
错误代码0x80131500通常与.NET Framework 相关的问题有关。它可能表示.NET Framework的安装损坏、版本冲突或系统文件缺失等。下面我们一起来探讨一下解决错误代码0x80131500有哪些。 以下是一些解决方法 安装最新的.NET Framework版本:访问Microsoft官方网站&…...
)
PMO(Project Management Office)
PMO 是项目管理办公室(Project Management Office)的缩写。它是组织内的一个部门或团队,负责支持和促进项目管理活动,以确保项目按时、按预算、按要求完成。 PMO 的职责和角色可以因组织的性质和需求而有所不同,但通常…...
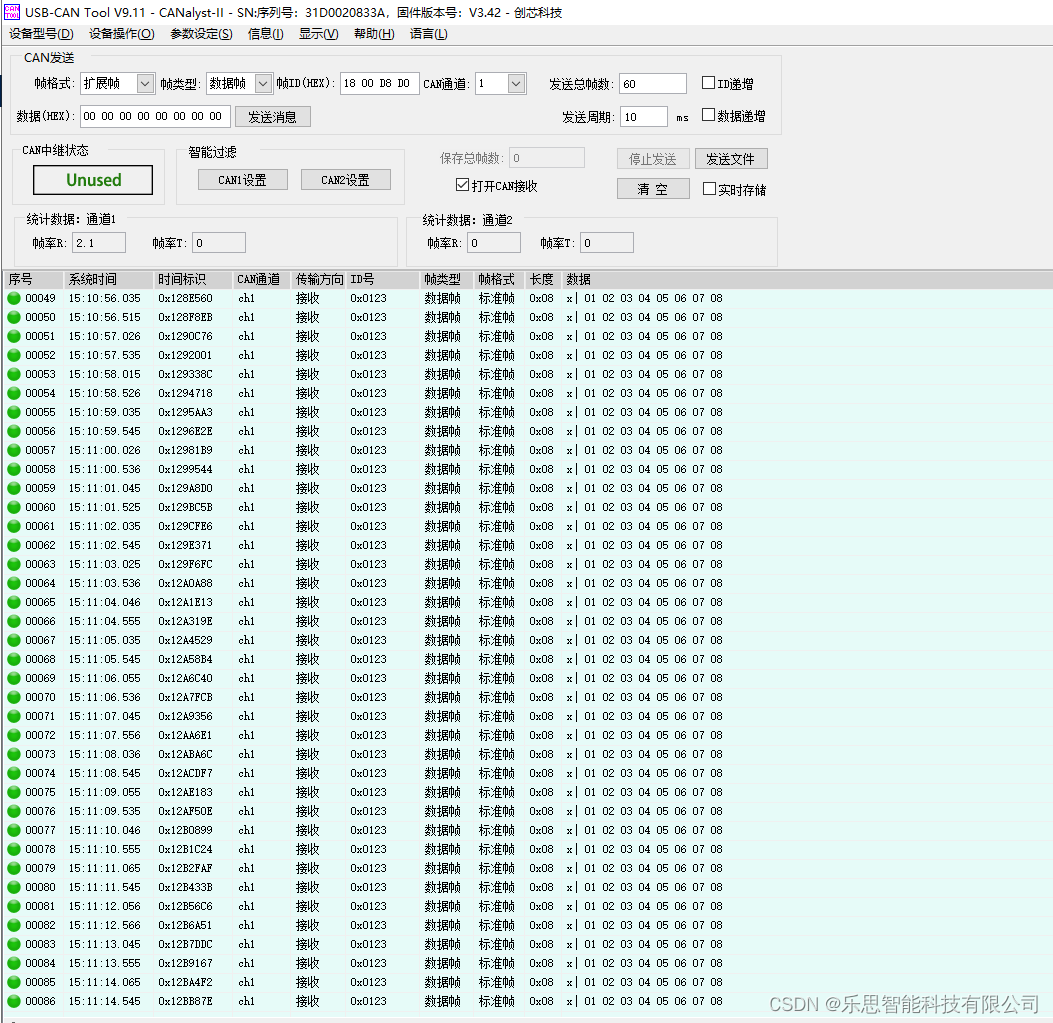
STM32 CUBEMX CAN通信数据发送失败原因分析
CAN通信是一种数据通信协议,用于在不同设备之间进行通信。它是一种高效的、实时的、可靠的、多主机的、串行通信系统,通常用于汽车电子、工业自动化等领域。CAN通信协议是由德国BOSCH公司于1986年引入,并在欧洲和日本广泛使用。CAN通信具有独…...

长安链并行调度机制(2):DAG构建和从节点执行流程
长安链采用高效的并行调度方式执行交易,了解长安链交易调度、冲突检测和DAG构建流程有助于开发者更好地理解长安链并行调度的运行机制,帮助开发者编写高质量、低冲突的智能合约,更好地构建区块链应用。 上一篇内容我们说明了长安链交易调度、…...

leetcode做题笔记110. 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。 思路一:递归 int height(struct TreeNode* root) {if (root NULL) {return…...

iOS开发Swift-字符串与字符
1.字符串的定义 let someString "some string value"2.多行字符串的定义(""") let quotation """ 有一个人前来买瓜。 "这瓜甜吗?"他问。 """前一个"""前和后一个""&…...

Linux Kernel:syscall之fork与exec
环境: Kernel Version:Linux-5.10 ARCH:ARM64 一:前言 上一节我们提到了进程的产生方式fork,exec与clone,本节将详细分析fork和exec族系统调用的具体实现。通常这些调用不是由应用程序直接发出的,而是通过一个中间层调用,即负责与内核通信的C标准库。从用户状态切换到…...

CentOS 修改MySQL密码
CentOS 修改MySQL密码 1.登录MySQL 2.执行如下命令 update user set passwordpassword(mivbAs7Awc) where userroot;报错如下: Unknown column ‘password’ in ‘field list’ 3.执行如下命令 update user set passwordpassword(mivbAs7Awc) where userroot碰到…...

Android通过setaffinity实现绑核
有时候为了降低App算力占用,会把关键的线程绑定到大核中,下面介绍一种绑核的方式 查看绑核 查看pid :/ # ps -A | grep test u0_a15 25178 405 15950272 176544 do_epoll_wait 0 S com.test.jnites查看线程号 top -H -p 25178 25224 u0_…...
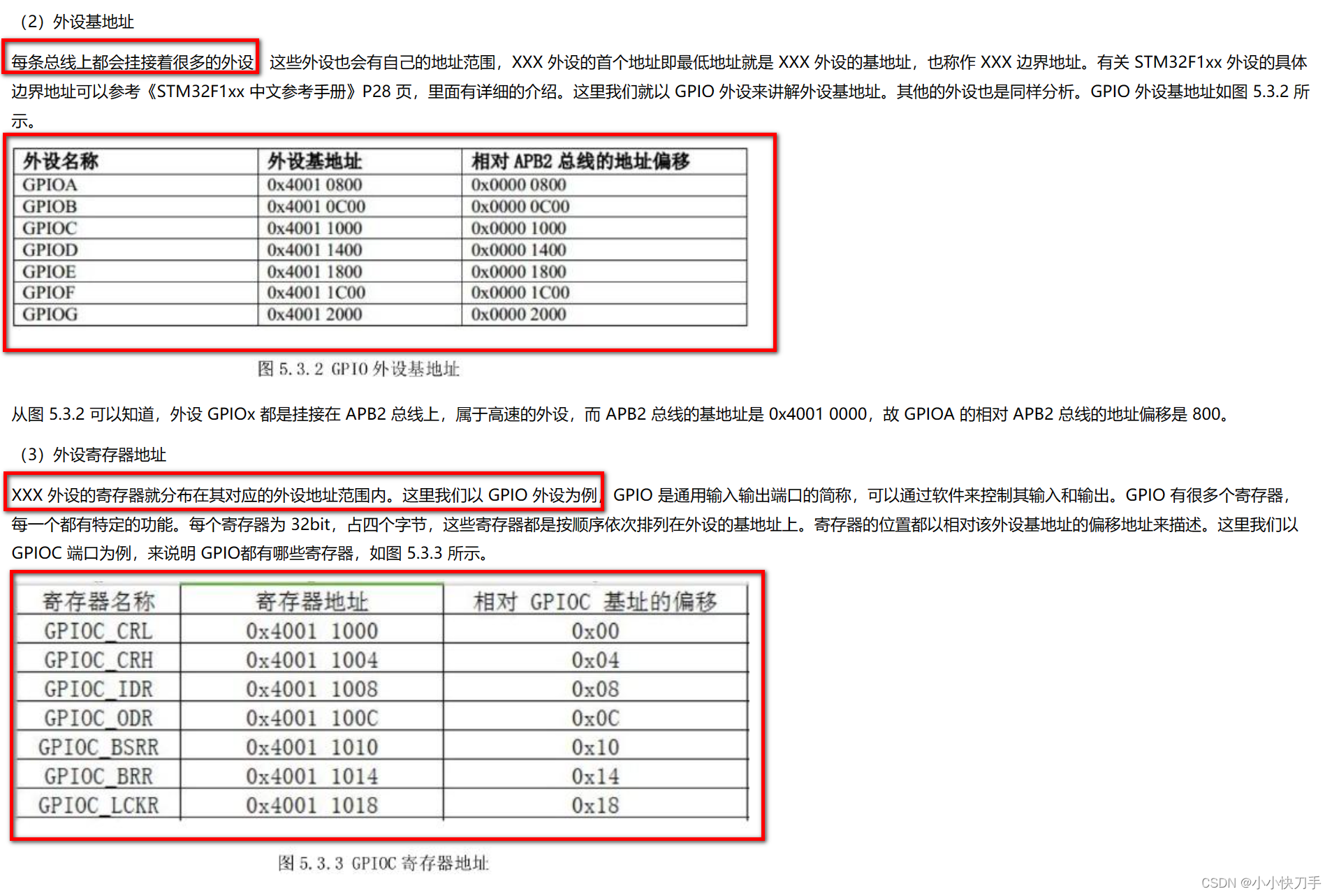
stm32的位带操作
在51单片机中,我们可以使用P2^1来对单片机的某一位进行操作,到了stm32,我们通过位带操作,将寄存器的每一位映射到一个32位的地址。如下是我查资料摘录的一些图片。 映射方式 SRAM: AliasAddr 0x22000000 (A-0X20000000)*8*4n*4…...
Java 电子招标采购系统源码:营造全面规范安全的电子招投标环境,促进招投标市场健康可持续发展
营造全面规范安全的电子招投标环境,促进招投标市场健康可持续发展 传统采购模式面临的挑战 一、立项管理 1、招标立项申请 功能点:招标类项目立项申请入口,用户可以保存为草稿,提交。 2、非招标立项申请 功能点:非招标…...

https协议经过SpringMVC重定向之后变成http协议
之前项目的协议还是http,当改为https之后,就出现了这个问题。 服务访问地址:https://wuxinke.demo.com 访问某个页面的地址:https://wuxinke.demo.com/aps/judgeProviderOrCtenant.ht 经SpringMVC重定向之后,地址变…...
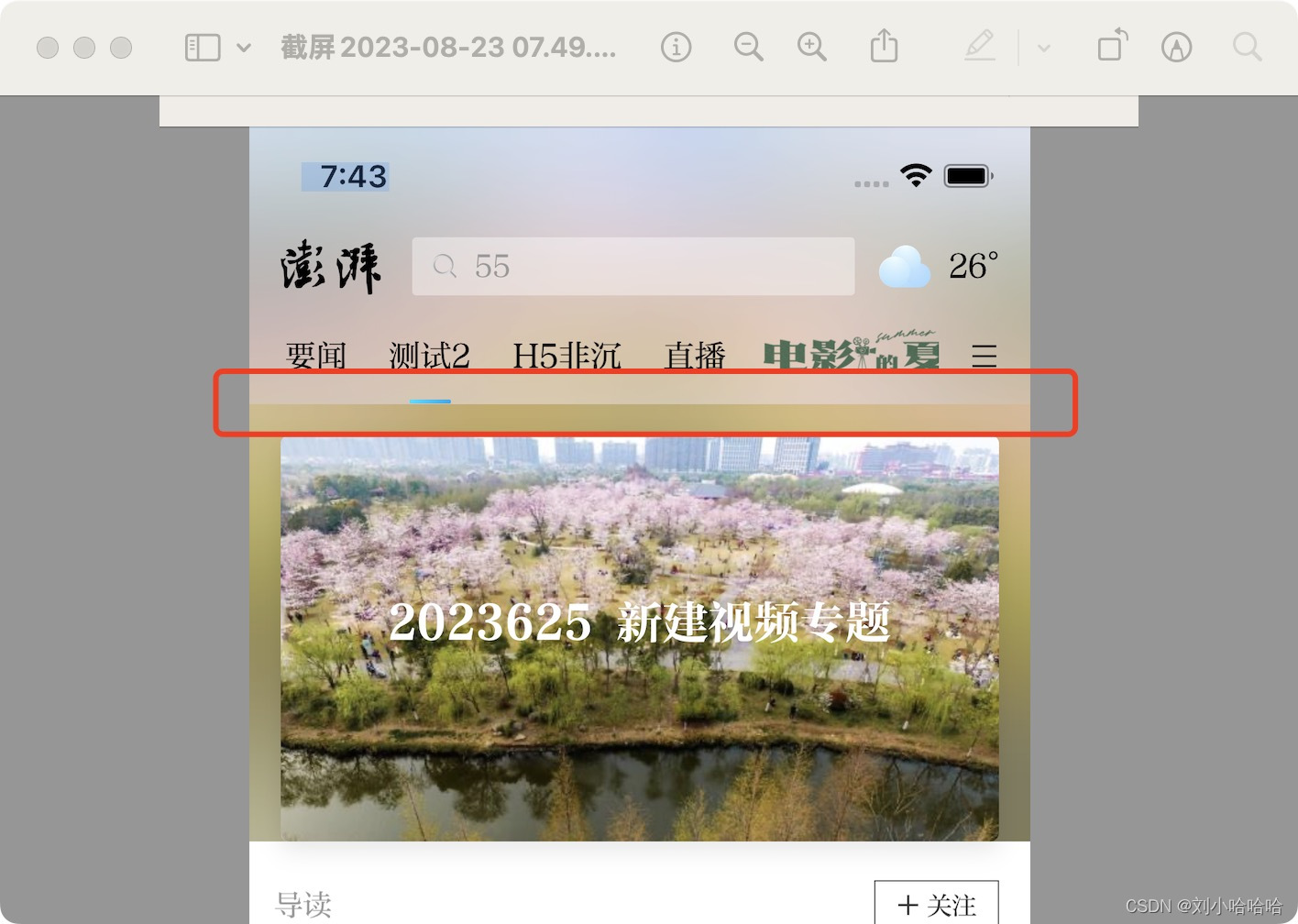
iOS 分别对一张图的局部进行磨砂,拼接起来不能贴合
效果图 需求,由于视图层级的原因,需要对图片分开进行磨砂, 然后组合在一起 如图,上下两部分,上下两个UIImageVIew大小相同,都是和图片同样的大小,只是上面的UIimageVIew 只展示上半部份 &#…...

与面试官互动:建立积极的技术讨论氛围
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
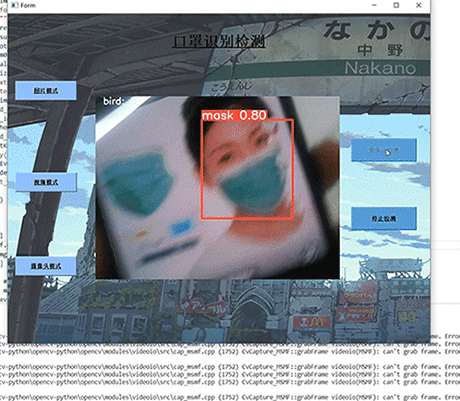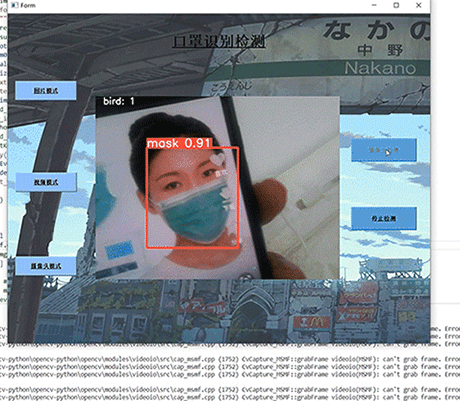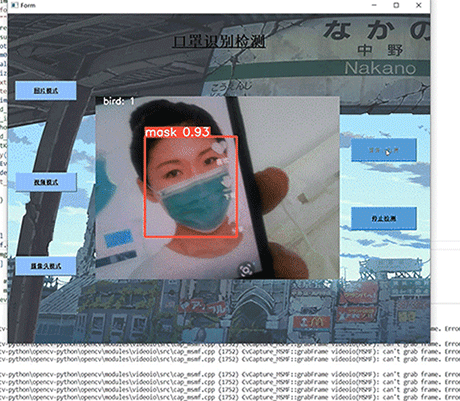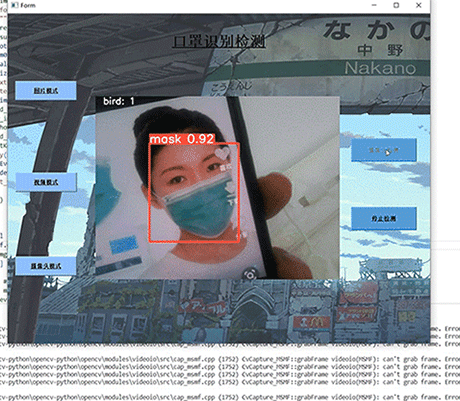
计算机竞赛 基于YOLO实现的口罩佩戴检测 - python opemcv 深度学习
文章目录 0 前言1 课题介绍2 算法原理2.1 算法简介2.2 网络架构 3 关键代码4 数据集4.1 安装4.2 打开4.3 选择yolo标注格式4.4 打标签4.5 保存 5 训练6 实现效果6.1 pyqt实现简单GUI6.3 视频识别效果6.4 摄像头实时识别 7 最后 0 前言 🔥 优质竞赛项目系列…...
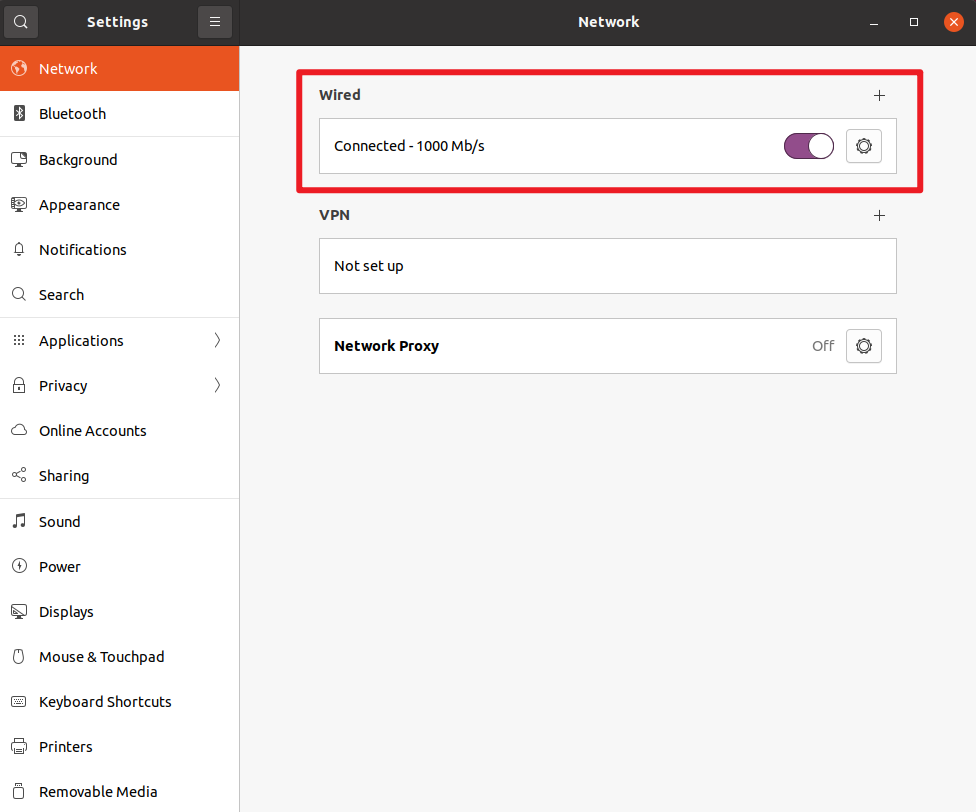
完美解决Ubuntu网络故障,连接异常,IP地址一直显示127.0.0.1
终端输入ifconfig显示虚拟机IP地址为127.0.0.1,具体输出内容如下: wxyubuntu:~$ ifconfig lo: flags73<UP,LOOPBACK,RUNNING> mtu 65536inet 127.0.0.1 netmask 255.0.0.0inet6 ::1 prefixlen 128 scopeid 0x10<host>loop txqueuelen …...
手机无人直播软件有哪些,又有哪些优势?
如今,随着智能手机的普及和移动互联网的发展,手机无人直播成为了一个炙手可热的领域。手机无人直播软件为用户提供了便捷、灵活的直播方式,让更多商家人能够实现自己的直播带货的梦想。接下来,我们将探讨手机无人直播软件有哪些&a…...
解密算法与数据结构面试:程序员如何应对挑战
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
)
2026年山东大学软件学院创新项目实训博客(五)
2026年山东大学软件学院创新项目实训博客(五) 一、工作进展 本阶段 Agent 架构模块的核心推进是将父级编排从「单次补全加强制工具调用」升级为有界多轮循环,并同步完成系统提示词的多步能力声明、意图分类器的域关键词防误路由、以及 SSE 事…...

高性能计算终极指南:使用LIKWID工具套件进行性能分析与优化
高性能计算终极指南:使用LIKWID工具套件进行性能分析与优化 【免费下载链接】likwid Performance monitoring and benchmarking suite 项目地址: https://gitcode.com/gh_mirrors/li/likwid 在当今的高性能计算(HPC)领域,性能监控与分析是提升计算…...

UltraScale架构FPGA功耗优化技术与工程实践
1. UltraScale架构的功耗优化技术全景解析在当今高性能计算和通信领域,功耗已成为FPGA选型的决定性因素之一。Xilinx UltraScale架构通过多层次的创新,在20nm工艺节点上实现了显著的功耗降低。作为深耕FPGA设计十余年的工程师,我将从实际应用…...

免费电商平台批量下载图片方法,好用的让你不敢相信
pc+浏览器方法,批量快速下载淘宝、拼多多、抖音等常用电商均满足。 全程不花一分钱,所有资源都免费。 方法简单,操作方便。 只需在浏览其中增加 (downpictures) 当图扩展即可。 一、操作方法如下: 1、如使用edge浏览器,访问这个网址:当图 ,然后点击按钮“获取”,…...

接入Taotoken后感受到的API调用延迟降低与错误率改善
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 接入Taotoken后感受到的API调用延迟降低与错误率改善 1. 背景与切换契机 作为一名长期在项目中集成大模型能力的开发者࿰…...

Yii2开启URI伪静态的相关配置
Yii2 开启URI伪静态的相关配置 Yii2支持url伪静态链接转换,在配置文件config/web.php中加入 # config/web.php $config [components > [// URI伪静态化配置urlManager > [enablePrettyUrl > true, // 启用美化 URL(隐藏 index.php)…...

在OpenClaw中快速接入Taotoken实现AI助手功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中快速接入Taotoken实现AI助手功能 OpenClaw是一款功能强大的AI助手工具,能够帮助开发者进行代码生成、问题…...

基于USB HID与CircuitPython的交互式硬件开发实战
1. 项目概述:一个需要你“手摇发电”才能保持屏幕亮度的硬件装置如果你觉得每天盯着手机屏幕的时间太长,想找个物理方式来“惩罚”一下自己的拖延症,或者单纯想体验一下用硬件直接“操控”手机的感觉,那么这个项目正对你的胃口。这…...

明日方舟游戏资源库:2000+高清素材的完整获取与应用指南
明日方舟游戏资源库:2000高清素材的完整获取与应用指南 【免费下载链接】ArknightsGameResource 明日方舟客户端素材 项目地址: https://gitcode.com/gh_mirrors/ar/ArknightsGameResource 还在为寻找高质量的明日方舟游戏素材而烦恼吗?无论是创作…...

STM32H743 FDCAN实战:手把手教你调试CAN节点错误计数器与Bus_Off状态
STM32H743 FDCAN实战:从寄存器到代码的Bus_Off恢复指南 当你的STM32H743项目突然出现CAN通信中断,调试器里FDCAN_PSR寄存器的BOFF位亮起红灯时,真正的挑战才刚刚开始。这不是普通的通信故障,而是触发了CAN协议中最严厉的惩罚机制—…...