计算机竞赛 基于GRU的 电影评论情感分析 - python 深度学习 情感分类
文章目录
- 1 前言
- 1.1 项目介绍
- 2 情感分类介绍
- 3 数据集
- 4 实现
- 4.1 数据预处理
- 4.2 构建网络
- 4.3 训练模型
- 4.4 模型评估
- 4.5 模型预测
- 5 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
基于GRU的 电影评论情感分析
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1.1 项目介绍
其实,很明显这个项目和微博谣言检测是一样的,也是个二分类的问题,因此,我们可以用到学长之前提到的各种方法,即:
朴素贝叶斯或者逻辑回归以及支持向量机都可以解决这个问题。
另外在深度学习中,我们可以用CNN-Text或者RNN以及LSTM等模型最好。
当然在构建网络中也相对简单,相对而言,LSTM就比较复杂了,为了让不同层次的同学们可以接受,学长就用了相对简单的GRU模型。
如果大家想了解LSTM。以后,学长会给大家详细介绍。
2 情感分类介绍
其实情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。一般而言:情绪类别:正面/负面。当然,这就是为什么本人在前面提到情感分析实际上也是二分类问题的原因。
3 数据集
学长本次使用的是非常典型的IMDB数据集。
该数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
查看其数据集的文件夹:这是train和test文件夹。
接下来就是以train文件夹介绍里面的内容
然后就是以neg文件夹介绍里面的内容,里面会有若干的text文件:
4 实现
4.1 数据预处理
#导入必要的包import zipfileimport osimport ioimport randomimport jsonimport matplotlib.pyplot as pltimport numpy as npimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear, Embeddingfrom paddle.fluid.dygraph.base import to_variablefrom paddle.fluid.dygraph import GRUUnitimport paddle.dataset.imdb as imdb#加载字典def load_vocab():vocab = imdb.word_dict()return vocab#定义数据生成器class SentaProcessor(object):def __init__(self):self.vocab = load_vocab()def data_generator(self, batch_size, phase='train'):if phase == "train":return paddle.batch(paddle.reader.shuffle(imdb.train(self.vocab),25000), batch_size, drop_last=True)elif phase == "eval":return paddle.batch(imdb.test(self.vocab), batch_size,drop_last=True)else:raise ValueError("Unknown phase, which should be in ['train', 'eval']")步骤
-
首先导入必要的第三方库
-
接下来就是数据预处理,需要注意的是:数据是以数据标签的方式表示一个句子,因此,每个句子都是以一串整数来表示的,每个数字都是对应一个单词。当然,数据集就会有一个数据集字典,这个字典是训练数据中出现单词对应的数字标签。
4.2 构建网络
这次的GRU模型分为以下的几个步骤
- 定义网络
- 定义损失函数
- 定义优化算法
具体实现如下
#定义动态GRU
class DynamicGRU(fluid.dygraph.Layer):
def init(self,
size,
param_attr=None,
bias_attr=None,
is_reverse=False,
gate_activation=‘sigmoid’,
candidate_activation=‘relu’,
h_0=None,
origin_mode=False,
):
super(DynamicGRU, self).init()
self.gru_unit = GRUUnit(
size * 3,
param_attr=param_attr,
bias_attr=bias_attr,
activation=candidate_activation,
gate_activation=gate_activation,
origin_mode=origin_mode)
self.size = size
self.h_0 = h_0
self.is_reverse = is_reverse
def forward(self, inputs):
hidden = self.h_0
res = []
for i in range(inputs.shape[1]):
if self.is_reverse:
i = inputs.shape[1] - 1 - i
input_ = inputs[ :, i:i+1, :]
input_ = fluid.layers.reshape(input_, [-1, input_.shape[2]], inplace=False)
hidden, reset, gate = self.gru_unit(input_, hidden)
hidden_ = fluid.layers.reshape(hidden, [-1, 1, hidden.shape[1]], inplace=False)
res.append(hidden_)
if self.is_reverse:
res = res[::-1]
res = fluid.layers.concat(res, axis=1)
return res
class GRU(fluid.dygraph.Layer):def __init__(self):super(GRU, self).__init__()self.dict_dim = train_parameters["vocab_size"]self.emb_dim = 128self.hid_dim = 128self.fc_hid_dim = 96self.class_dim = 2self.batch_size = train_parameters["batch_size"]self.seq_len = train_parameters["padding_size"]self.embedding = Embedding(size=[self.dict_dim + 1, self.emb_dim],dtype='float32',param_attr=fluid.ParamAttr(learning_rate=30),is_sparse=False)h_0 = np.zeros((self.batch_size, self.hid_dim), dtype="float32")h_0 = to_variable(h_0)self._fc1 = Linear(input_dim=self.hid_dim, output_dim=self.hid_dim*3)self._fc2 = Linear(input_dim=self.hid_dim, output_dim=self.fc_hid_dim, act="relu")self._fc_prediction = Linear(input_dim=self.fc_hid_dim,output_dim=self.class_dim,act="softmax")self._gru = DynamicGRU(size=self.hid_dim, h_0=h_0)def forward(self, inputs, label=None):emb = self.embedding(inputs)o_np_mask =to_variable(inputs.numpy().reshape(-1,1) != self.dict_dim).astype('float32')mask_emb = fluid.layers.expand(to_variable(o_np_mask), [1, self.hid_dim])emb = emb * mask_embemb = fluid.layers.reshape(emb, shape=[self.batch_size, -1, self.hid_dim])fc_1 = self._fc1(emb)gru_hidden = self._gru(fc_1)gru_hidden = fluid.layers.reduce_max(gru_hidden, dim=1)tanh_1 = fluid.layers.tanh(gru_hidden)fc_2 = self._fc2(tanh_1)prediction = self._fc_prediction(fc_2)if label is not None:acc = fluid.layers.accuracy(prediction, label=label)return prediction, accelse:return prediction
4.3 训练模型
def train():
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)): # # 因为要进行很大规模的训练,因此我们用的是GPU,如果没有安装GPU的可以使用下面一句,把这句代码注释掉即可
# with fluid.dygraph.guard(place = fluid.CPUPlace()):
processor = SentaProcessor()train_data_generator = processor.data_generator(batch_size=train_parameters["batch_size"], phase='train')model = GRU()sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=train_parameters["lr"],parameter_list=model.parameters())steps = 0Iters, total_loss, total_acc = [], [], []for eop in range(train_parameters["epoch"]):for batch_id, data in enumerate(train_data_generator()):steps += 1doc = to_variable(np.array([np.pad(x[0][0:train_parameters["padding_size"]], (0, train_parameters["padding_size"] - len(x[0][0:train_parameters["padding_size"]])),'constant',constant_values=(train_parameters["vocab_size"]))for x in data]).astype('int64').reshape(-1))label = to_variable(np.array([x[1] for x in data]).astype('int64').reshape(train_parameters["batch_size"], 1))model.train()prediction, acc = model(doc, label)loss = fluid.layers.cross_entropy(prediction, label)avg_loss = fluid.layers.mean(loss)avg_loss.backward()sgd_optimizer.minimize(avg_loss)model.clear_gradients()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(avg_loss.numpy()[0])total_acc.append(acc.numpy()[0])print("step: %d, ave loss: %f, ave acc: %f" %(steps,avg_loss.numpy(),acc.numpy()))if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps)print('save model to: ' + save_path)fluid.dygraph.save_dygraph(model.state_dict(),save_path)draw_train_process(Iters, total_loss, total_acc)

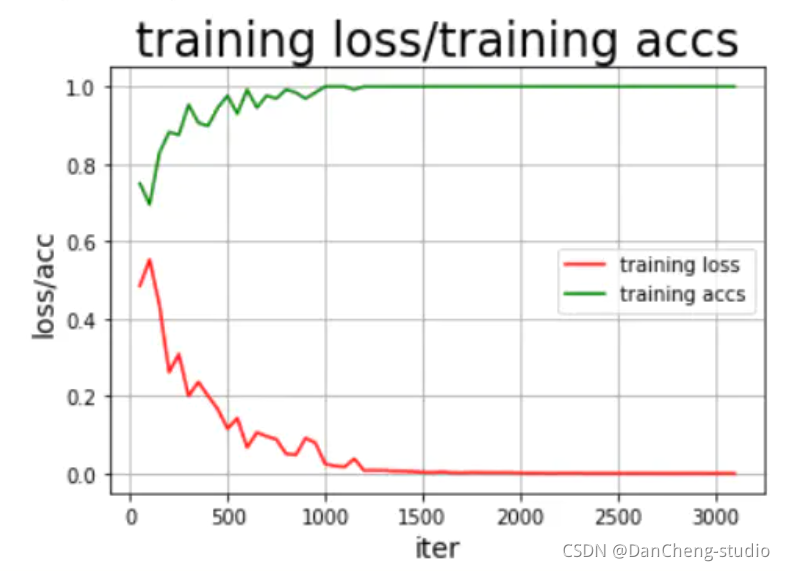
4.4 模型评估

结果还可以,这里说明的是,刚开始的模型训练评估不可能这么好,很明显是过拟合的问题,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将GRU模型换为更为合适的RNN中的LSTM以及bi-
LSTM模型会好很多。
4.5 模型预测
train_parameters[“batch_size”] = 1
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):sentences = 'this is a great movie'data = load_data(sentences)print(sentences)print(data)data_np = np.array(data)data_np = np.array(np.pad(data_np,(0,150-len(data_np)),"constant",constant_values =train_parameters["vocab_size"])).astype('int64').reshape(-1)infer_np_doc = to_variable(data_np)model_infer = GRU()model, _ = fluid.load_dygraph("data/save_dir_750.pdparams")model_infer.load_dict(model)model_infer.eval()result = model_infer(infer_np_doc)print('预测结果为:正面概率为:%0.5f,负面概率为:%0.5f' % (result.numpy()[0][0],result.numpy()[0][1]))

训练的结果还是挺满意的,到此为止,我们的本次项目实验到此结束。
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 基于GRU的 电影评论情感分析 - python 深度学习 情感分类
文章目录 1 前言1.1 项目介绍 2 情感分类介绍3 数据集4 实现4.1 数据预处理4.2 构建网络4.3 训练模型4.4 模型评估4.5 模型预测 5 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于GRU的 电影评论情感分析 该项目较为新颖,适合作为竞…...
android logcat问题 怎么换成旧版
参考 如果想切换回旧版LOGCAT,按照下方步骤设置即可 File->Settings->Expermental->Logcat->Enable new Logcat tool window:取消勾选 设置好后上方会有一个Toast,询问你是否使用新版logcat,关掉即可 最新测试版移…...

监听的用法watch
1、当想停止某页面定时刷新(监听路由的变化) /**组件被移除时调用 */deactivated() {clearInterval(this.timer);this.timer null;},/**监听路由变化是否刷新 */watch: {// 方法1 //监听路由是否变化$route(to, from) {if (to.name "xxx") {…...
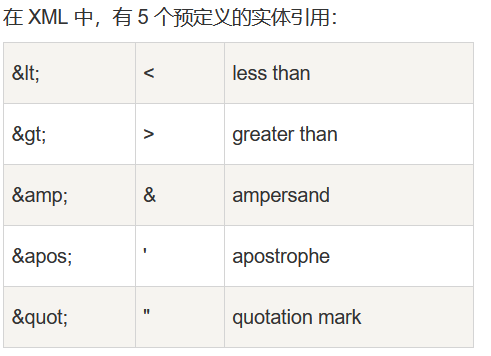
XML—标记语言
什么是XML? Extensible Markup Language,可扩展标记语言。 那标记语言是什么? 用文字做标记表达一些效果或携带一些数据。比如:HTML、XML 我的理解:用倾盆大雨表达雨很大 那XML为什么说是可扩展的呢? 还…...
图数据库Neo4j学习五渲染图数据库neo4jd3
文章目录 1.现成的工具2.Neo4j JavaScript Driver3.neovis4.neo4jd34.1neo4jd3和neovis对比4.2获取neo4jd34.3neo4jd3的数据结构4.4Spring data neo4.4.1 定义返回数据格式4.4.1.1NeoResults4.4.1.2GraphVO4.4.1.3NodeVO4.4.1.4ShipVO 4.4.2 SDN查询解析4.4.2.1 Repo查询语句4.…...

AI增强的社交网络·导师·电话客服……
本月共更新80条知识, 智能时代,人与人之间的差距,体现在前沿知识的整合上。 # BeFake AI AI-augmented social network AI增强的社交网络,用户使用文本提示来生成图像,拍摄自己的“AI”版本。任何人都可以创建全新的虚…...

c# Task异步使用
描述 Task出现之前,微软的多线程处理方式有:Thread→ThreadPool→委托的异步调用,虽然可以满足基本业务场景,但它们在多个线程的等待处理方面、资源占用方面、延续和阻塞方面都显得比较笨拙,在面对复杂的业务场景下&am…...

QuickLook概述和使用以及常用插件
1、QuickLook概述 QuickLook: 是可以快速预览的工具,开源、免费。通过空格键即可快速查看文件内容。 文件无需打开就可以用QuickLook一键快速预览。 说明文档:https://en.wikipedia.org/wiki/Quick_Look github地址:https://git…...

1A快恢复整流二极管型号汇总
快恢复整流二极管是二极管中的一种,开关特性好、反向恢复时间短,在开关电源、PWM脉宽调制器、变频器等电子电路中经常能看到它的身影。快恢复整流二极管的内部结构与普通PN结二极管不同,它属于PIN结型二极管,即在P型硅材料与N型硅…...

【element-ui】el-dialog改变宽度
dialog默认宽度为父元素的50%,这就导致在移动端会非常的窄,如图1,需要限定宽度。 解决方法:添加custom-class属性,然后在style中编写样式,注意,如果有scoped限定,需要加::v-deep &l…...

第三讲,实践编程 Eigen
目录 1.实践 Eigen1.1 Eigen的简介1.2 Eigen 向量和矩阵的 声明1.3 Eigen的输出操作1.4 矩阵和向量相乘 要注意数据类型 矩阵纬度1.5 矩阵的四则运算1.6 矩阵求解特征向量和特征值1.7 解方程 求逆 1.实践 Eigen 1.1 Eigen的简介 Eigen是一个 C 开源线性代数库。它提供了快…...

POI实现百万数据导出
1、概述 我们都知道Excel可以分为早期的Excel2003版本(使用POI的HSSF对象操作)和Excel2007版本(使用POI的XSSF操作),两者对百万数据的支持如下: Excel 2003:在POI中使用HSSF对象时&#…...

如何制作党建专题汇报片
通过展示党组织的凝聚力和战斗力,增强党员的组织归属感和团结合作意识。通过宣传片,可以加强党组织的凝聚力,推动党的事业发展。制作党建专题汇报片需要一定的前期准备和后期制作技巧。下面是由深圳党建专题汇报片制作公司老友记小编为您整理…...

沉浸式VR虚拟实景样板间降低了看房购房的难度
720 全景是一种以全景视角为特点的虚拟现实展示方式,它通过全景图像和虚拟现实技术,将用户带入一个仿佛置身其中的沉浸式体验中。720 全景可以应用于旅游、房地产、展览等多个领域,为用户提供更为直观、真实的体验。 在房地产领域,…...

如何在Linux环境下给Web应用配置HTTPS证书
如何在Linux环境下给Web应用配置HTTPS证书 在当今互联网时代,保护用户数据的安全性至关重要。为你的Web应用启用HTTPS协议是确保数据传输加密和身份验证的一种有效方式。本文将指导你如何在Linux环境下为Web应用程序配置HTTPS证书。 1. 获取SSL证书 首先…...

面试题-React(七):React组件通信
在React开发中,组件通信是一个核心概念,它使得不同组件能够协同工作,实现更复杂的交互和数据传递。常见的组件通信方式:父传子和子传父 一、父传子通信方式 父组件向子组件传递数据是React中最常见的一种通信方式。这种方式适用…...
MASM32编程调用 API函数RtlIpv6AddressToString,Windows 10 容易,Windows 7 折腾
一、需求分析 最近用MASM32编程更新SysInfo,增加对IPv6连接信息的收集功能,其中涉及到 MIB_TCP6ROW_OWNER_MODULE 结构体: ;typedef struct _MIB_TCP6ROW_OWNER_MODULE { ; UCHAR ucLocalAddr[16]; ; DWORD dwLocalScope…...
为什么使用Nacos而不是Eureka(Nacos和Eureka的区别)
文章目录 前言一、Eureka是什么?二、Nacos是什么?三、Nacos和Eureka的区别3.1 支持的CAP3.2连接方式3.3 服务异常剔除3.4 操作实例方式 总结 前言 为什么如今微服务注册中心用Nacos相对比用Eureka的多了?本文章将介绍他们之间的区别和优缺点…...

Python作业一
目录 1、用循环语句求122333444455555的和 2、求出2000-2100的所有闰年,条件是四年一闰,百年不闰,四百年再闰 3、输入两个正整数,并求出它们的最大公约数和最小公倍数 4、求出100以内的所有质数 5、求100以内最大的10个质数的…...

protobuf概览
protobuf protobuf是由谷歌推出的二进制序列化与反序列化库对象。也是著名GRPC的底层依赖,它独立于平台及语言的序列化与反序列化标准库。 相关网址 protobuf IDL描述protobuf 开源库grpc-知乎grpc官方示例 安装protobuf可以使用vcpkg进行简易安装依赖ÿ…...

AI驱动编辑预设生成:从风格迁移到创意工作流的自动化实践
1. 项目概述:AI驱动的编辑预设库最近在折腾视频和图片后期,发现一个挺有意思的项目,叫kaushalrao/ai-editor-presets。这名字听起来有点技术范儿,但说白了,它就是一个用人工智能技术来生成和优化各类编辑软件预设文件的…...

12 - AI Native“基因测序法”:你的产品是“数字生命”还是“行尸走肉”?
本专题系列文章共 28 篇 01 - 眩晕时代的定海神针:大模型落地的“第一性原理”与算力丰裕悖论 02 - 95%的AI投资打了水漂:五大错配如何扼杀你的“第二增长曲线”...

RPG Maker插件如何让你零代码创建专业级游戏地图?
RPG Maker插件如何让你零代码创建专业级游戏地图? 【免费下载链接】RPGMakerMV RPGツクールMV、MZで動作するプラグインです。 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerMV 你是否曾为RPG Maker游戏地图缺乏深度和立体感而烦恼?是否…...

2026 国产桌面 AI 智能体横向评测:博云 BoClaw vs AutoClaw vs QClaw vs MaxClaw vs WorkBuddy
一、引言2026 年初,一款名为 OpenClaw 的开源 AI 智能体框架以创纪录的速度蹿红全球——短短数月突破 30 万 GitHub Star,Token 使用量一度占据 OpenRouter 平台总量的约 13%。它之所以引发轰动,核心在于首次让 AI 真正实现从“动口”到“动手…...

开源机械爪资源库指南:从入门到ROS集成与自主抓取
1. 项目概述:一个开源“机械爪”的宝藏资源库如果你对机器人、自动化或者DIY硬件感兴趣,最近又在琢磨着给自己的项目加一个“手”,那么你很可能已经听说过“机械爪”这个概念。无论是想做一个自动抓取小物件的桌面机器人,还是为你…...

JAVA练习:单一职责原则重构
问题背景原始Login类同时承担界面展示、登录校验、数据库连接、用户查询、程序入口多重职责,功能高度耦合,违反单一职责原则(一个类只负责一类功能),修改某部分功能易影响其他模块。重构思路按职责拆分,分为…...

中文文本人性化:从NLP原理到cn-humanizer工程实践
1. 项目概述:为什么我们需要一个中文“人性化”工具?在数字时代,我们与机器生成的文本打交道的机会越来越多。无论是AI助手生成的回复、自动化脚本输出的日志,还是数据清洗后得到的报告,这些文本常常带着一种难以言喻的…...

VMware Workstation 17 Pro 保姆级教程:5分钟搞定Win11虚拟机TPM 2.0和安全启动配置
VMware Workstation 17 Pro 极速配置指南:Win11虚拟机TPM 2.0与安全启动实战 在虚拟化技术领域,VMware Workstation一直保持着领先地位。随着Windows 11的发布,许多开发者和技术爱好者都希望在虚拟机中体验这个新系统,却频繁遭遇T…...

Godot 4视觉特效速写本:开源粒子与着色器实例库实战指南
1. 项目概述:一个为创作者准备的视觉特效“速写本”如果你是一位游戏开发者、独立创作者,或者对实时视觉特效(VFX)充满热情,那么你很可能和我一样,在寻找灵感和实现效果之间反复横跳。我们常常在社交媒体上…...

3分钟为Windows 11 LTSC恢复微软商店的完整指南:解决精简版系统应用生态缺失问题
3分钟为Windows 11 LTSC恢复微软商店的完整指南:解决精简版系统应用生态缺失问题 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore Windows …...