顺序表链表OJ题(3)——【数据结构】

W...Y的主页 😊
代码仓库分享 💕
前言:
今天是链表顺序表OJ练习题最后一次分享,每一次的分享题目的难度也再有所提高,但是我相信大家都是非常机智的,希望看到博主文章能学到东西的可以一键三连关注一下博主。
话不多说,我们来看今天的OJ习题.。
【leetcode 142.环形链表II】
OJ链接
给定一个链表的头节点
head,返回链表开始入环的第一个节点。 如果链表无环,则返回null。如果链表中有某个节点,可以通过连续跟踪
next指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从 0 开始)。如果pos是-1,则在该链表中没有环。注意:pos不作为参数进行传递,仅仅是为了标识链表的实际情况。不允许修改 链表。
示例 1:
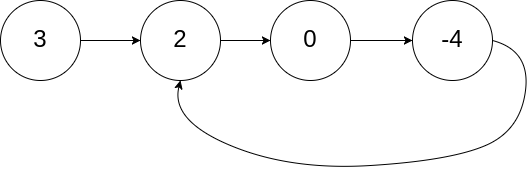
输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。示例 2:
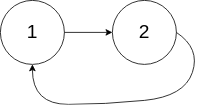
输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。示例 3:
输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。题目函数接口:
head:目标链表
分析:在上一篇博客中,我们讲述了如何寻找相遇点,创建两个指针slow与fast,fast的速度为slow的两倍,最终会在环中追及到。
下面讲述的方法与昨天的有关联:
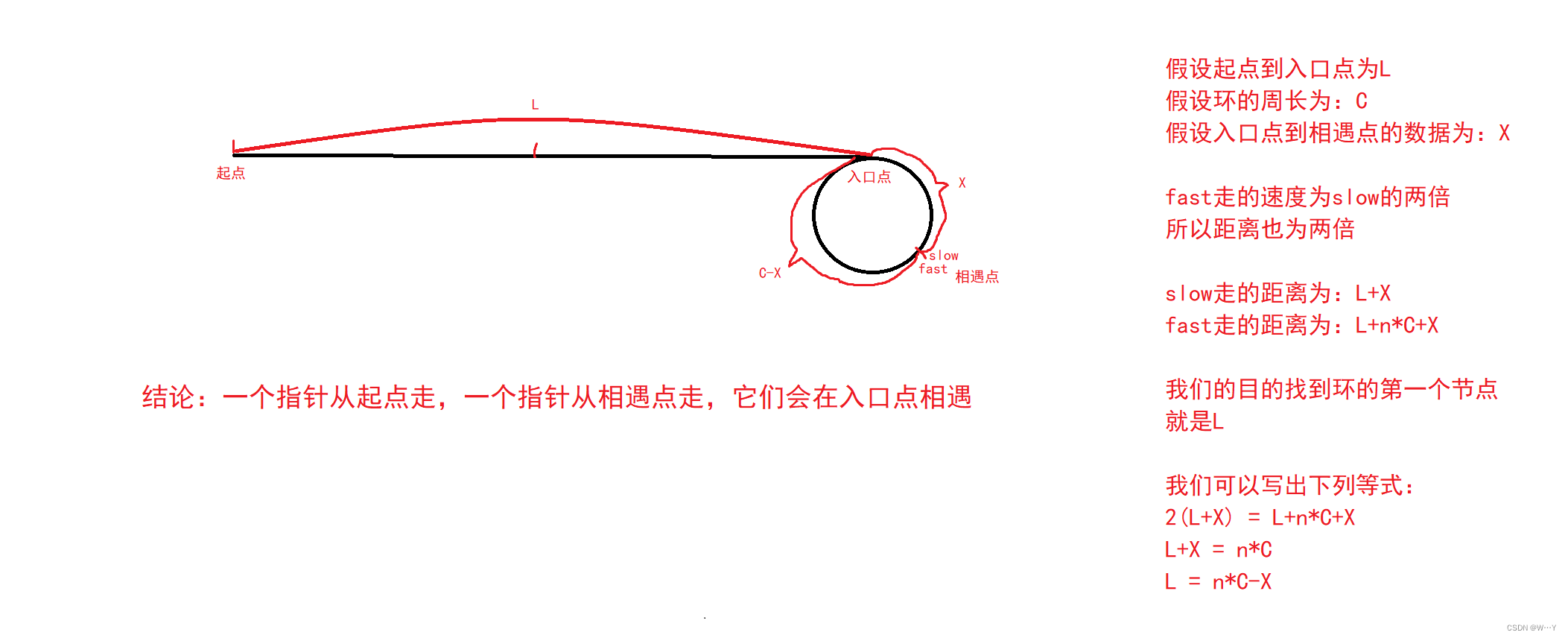
slow进入环后只会走不到一圈就会被fast追上,如果L足够长,环足够小fast会在环中走n圈(n>=1)。
我们分析完,题目就会迎刃而解。我们只需要先找到相遇点,然后一个指针从起点走,一个指针从相遇点走,它们相遇后的地址就是我们要的答案!!!
代码演示:
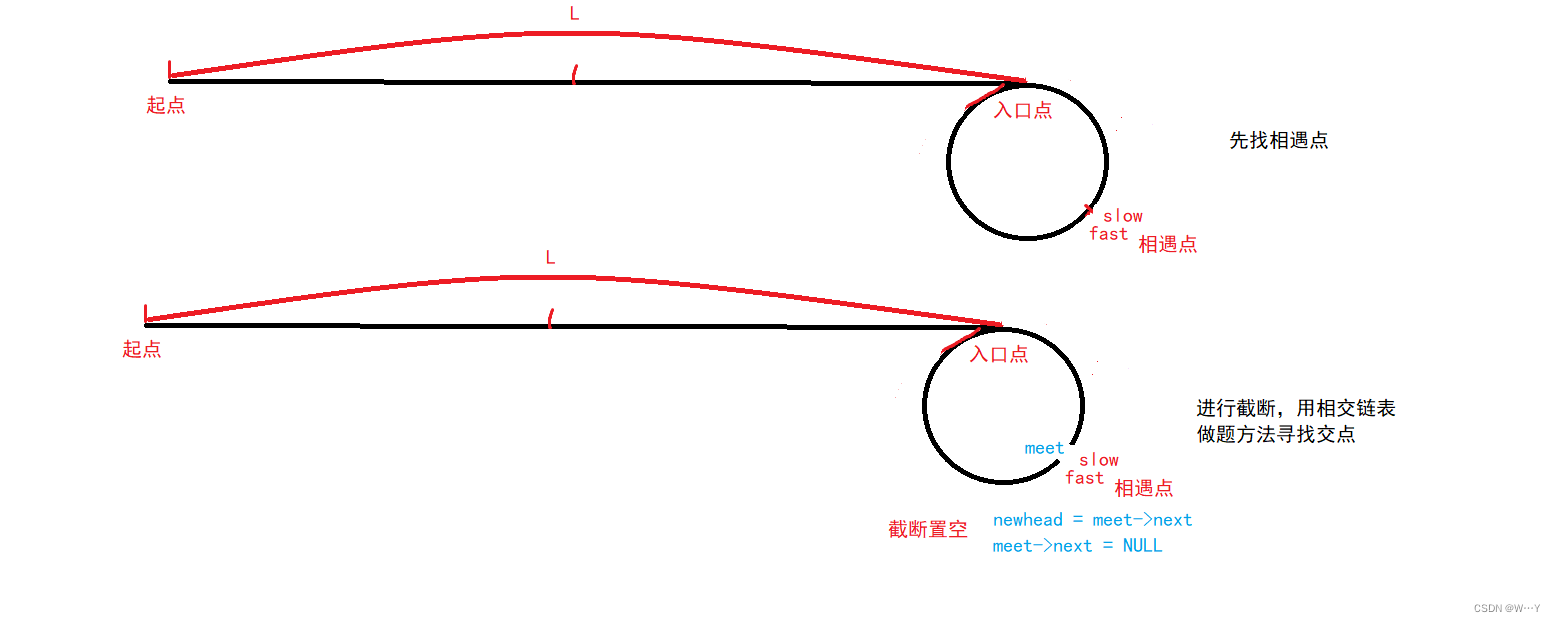
struct ListNode *detectCycle(struct ListNode *head) {struct ListNode *fast = head;struct ListNode *slow = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;if(fast == slow ){struct ListNode *cur = head;while(cur != slow){cur = cur->next;slow = slow->next;}return slow;}}return NULL; }再给大家提供一种思路!!!
思路二:我们可以先找到相遇点,然后将环从相遇点截断,这个链表就变成了相交链表,然后找到相交链表的相交点即可。
这个想法很简便也很大胆,不知道相交链表已经做题方法的可以在顺序表链表OJ题(2)->【数据结构】中找到相交链表的介绍以及相关题型。
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {int lena = 1;int lenb = 1;struct ListNode *cura = headA;struct ListNode *curb = headB;while(cura->next){cura = cura->next;lena++;}while(curb->next){curb = curb->next;lenb++;}if(cura != curb){return NULL;}int gap = abs(lena-lenb);struct ListNode *llist = headA;struct ListNode *slist = headB;if(lena > lenb){;}else{llist = headB;slist = headA;}while(gap--){llist = llist->next;}while(llist != slist){llist = llist->next;slist = slist->next;}return llist; } struct ListNode *detectCycle(struct ListNode *head) {struct ListNode *fast = head;struct ListNode *slow = head;while(fast && fast->next){fast = fast->next->next;slow = slow->next;if(fast == slow){struct ListNode *meet = slow;struct ListNode *newhead = meet->next;meet->next = NULL;return getIntersectionNode(newhead, head);}} return NULL; }

【leetcode 138.复制带随机指针的链表】
OJ链接
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝。 深拷贝应该正好由
n个全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个[val, random_index]表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。你的代码只接受原链表的头节点
head作为传入参数。示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]示例 3:
输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]题目函数接口:
head:目标链表
这道题比较复杂,拷贝一般链表非常简单,但是这个链表比较特殊,在结构体中加入了随机指针,如果我们先将无random指针链表拷贝一份,再去寻找random指针在链表中指向的位置,会非常麻烦,我们必须不停遍历链表,时间复杂度就非常高O(n^2)。而且代码也会非常的复杂,不建议使用暴力解法。
现在唯一难点就是如何找到新链表中random对应的位置,因为创建新链表与目标链表的地址是没有任何关联的。
但是接下来的方法相对于暴力解法会非常轻松,这个想法也是非常新颖的!!
思路:
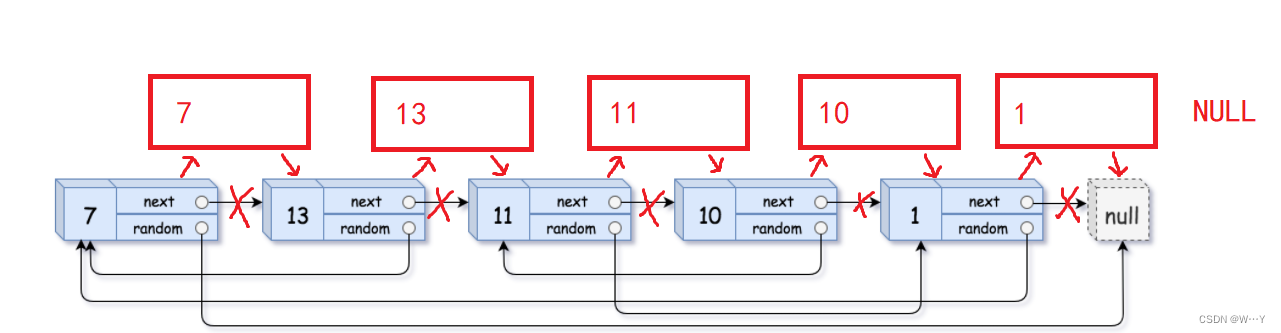
我们在原链表中每个结构体的后面插入新的结构体,将对应的内容拷贝到插入的新结构体中,就是这样:
这样我们就可以很方便的寻找random,创建一个指针copy,就比如上图中的13节点,我们需要拷贝13中的random到后面连接的新结构体中,只需要找到旧结构体中random指向的内容,让旧结构体的next的next->random等于copy指向的random即可。
最后一步只需要将完全拷贝好的新结构体拿下来尾插,组成一个新链表即可完成!!!
理论形成,时间开始:
struct Node* copyRandomList(struct Node* head) {struct Node*cur = head;while(cur){struct Node*next = cur->next;struct Node*copy = (struct Node*)malloc(sizeof(struct Node));copy->val = cur->val;cur->next = copy;copy->next = next;cur = next;}cur = head;while(cur){struct Node*copy = cur->next;if(cur->random == NULL){copy->random = NULL;}else{copy->random = cur->random->next;}cur = copy->next;}cur = head;struct Node*copyhead = NULL;struct Node*copytail = NULL;while(cur){struct Node* copy = cur->next;struct Node* next = copy->next;if(copytail == NULL){copyhead = copytail = copy;}else{copytail->next = copy;copytail = copytail->next;}cur->next = next;cur = next;}return copyhead; }新节点插入老节点中、copy指针的寻找新链表……都需要我们画图更好的理解。




这两道题都是想法比较前卫,一般方法比较困难的题,虽然用c语言比较麻烦,但是等到后面我们掌握了map以及哈希结构就会非常简单。
以上就是本次OJ题目的全部内容,希望大家看完有收获,一键三连支持一下博主吧!!!😘😘
相关文章:
顺序表链表OJ题(3)——【数据结构】
W...Y的主页 😊 代码仓库分享 💕 前言: 今天是链表顺序表OJ练习题最后一次分享,每一次的分享题目的难度也再有所提高,但是我相信大家都是非常机智的,希望看到博主文章能学到东西的可以一键三连关注一下博主…...

【Azure】Virtual Hub vWAN
虚拟 WAN 文档 Azure 虚拟 WAN 是一个网络服务,其中整合了多种网络、安全和路由功能,提供单一操作界面。 我们主要讨论两种连接情况: 通过一个 vWAN 来连接不通的 vNET 和本地网络。以下是一个扩展的拓扑 结合 vhub,可以把两个中…...

React Navigation 使用导航
在 Web 浏览器中,您可以使用锚标记链接到不同的页面。当用户单击链接时,URL 会被推送到浏览器历史记录堆栈中。当用户按下后退按钮时,浏览器会从历史堆栈顶部弹出该项目,因此活动页面现在是以前访问过的页面。React Native 不像 W…...
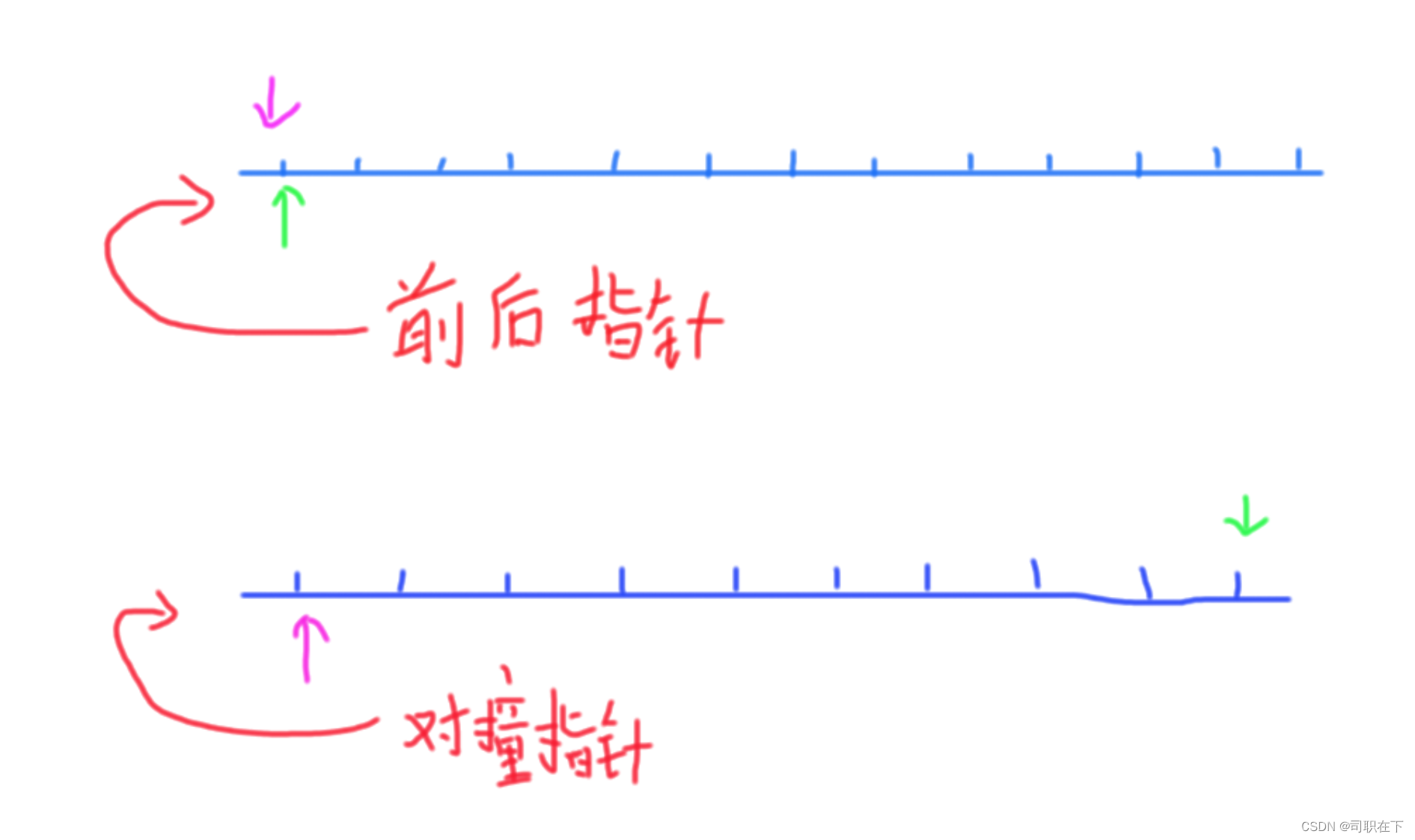
双指针算法,基础算法实践,基本的算法的思想,双指针算法的实现
一,定义 双指针算法是一种常用于解决数组和链表问题的算法技巧。它的核心思想是使用两个指针在数据结构中按照一定的规则移动,从而达到快速搜索或处理数据的目的。这个技巧通常用于优化算法,降低时间复杂度,提高程序的执行效率。…...
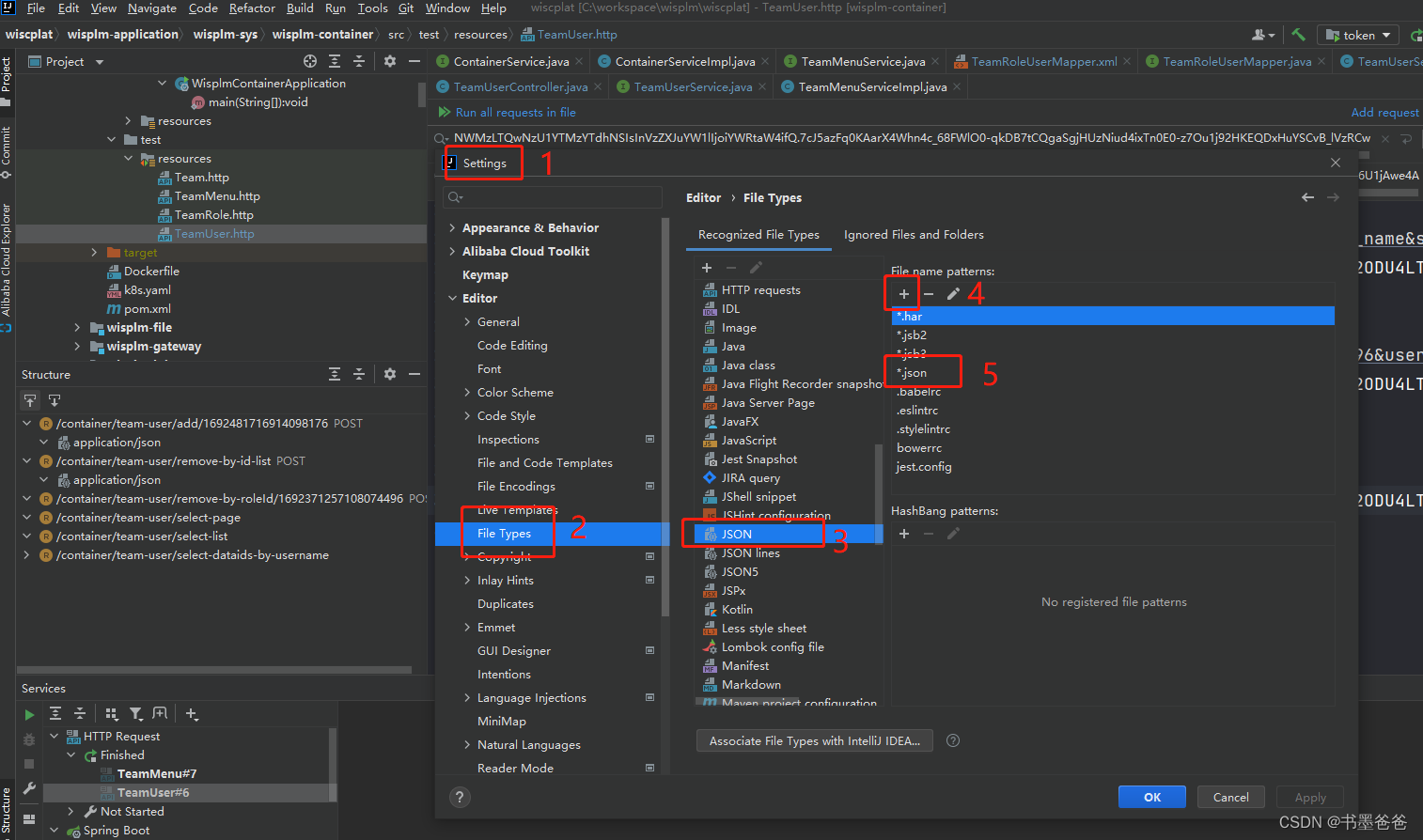
idea http request无法识别环境变量
问题描述 创建了环境变量文件 http-client.env.json,然后在*.http 文件中引用环境变量,运行 HTTP 请求无法读取环境变量文件中定义的变量。 事故现场 IDEA 版本:2020.2 2021.2 解决步骤 2020.2 版本环境变量无法读取 2021.2 版本从 2020.…...

性能测试常见的测试指标
一、什么是性能测试 先看下百度百科对它的定义 性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。我们可以认为性能测试是:通过在测试环境下对系统或构件的性能进行探测,用以验证在生产环境下系统性能…...
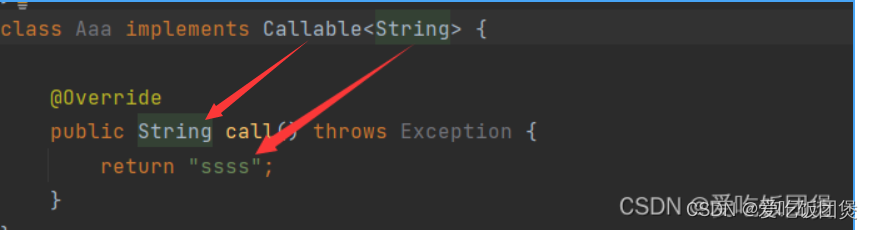
并发 04(Callable,CountDownLatch)详细讲解
并发 Callable 1 可以返回值 2可以抛出异常 泛型指的是返回值的类型 public class Send {public static void main(String[] args) {//怎么启动Callable//new Thread().start();Aaa threadnew Aaa();FutureTask futureTasknew FutureTask(thread);new Thread(futureTask,&qu…...

Json路径表达式
原json路径 {"timeStamp": "20220801110008","transIDO": "6ba9088c981b407fb38feasdf09","version": "1.0.0","signMethod": "md5","content": "{\"companyName\&quo…...

【uniapp 上传图片示例】
以下是 uniapp 上传图片的详细步骤示例: 定义一个方法,用于选择图片并上传: methods: {chooseImage() {uni.chooseImage({count: 1, // 最多选择的图片数量sizeType: [original, compressed], // 可以指定原图或压缩图sourceType: [album, …...

apache2配置文件 Require all granted是什么意思
修改apache2的配置文件 /etc/apache2/apache2.conf,需要增加网站代码的路径,下列配置是什么意思呢 <Directory "/var/www/html">Options FollowSymLinksAllowOverride AllRequire all granted </Directory> 1. Options Options …...

c/c++ 的一些知识
c 面向对象是一种思想,通常情况下都是以组合为主,也就是在子类里定义一个基类struct base_t {void (*method)(base_t *base_p); };struct children_t {int a;int b;base_t base;void (*method)(children_t *children_p); };children_t children_creat(i…...

Rancher上的应用服务报错:413 Request Entity Too Large
UI->rancher的ingress->UI前端(在nginx里面)->zuul->server 也就是说没经过一次http servlet 都要设置一下大小 1.rancher的ingress 当出现Request Entity Too Large时,是由于传输流超过1M。 1、需要在rancher的ingress中设置参数解决。 配置注释&a…...
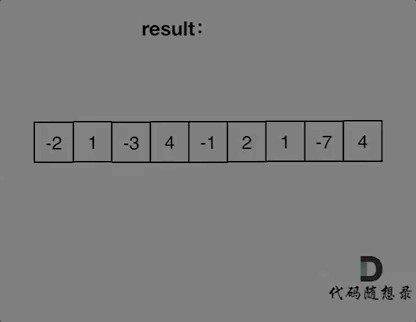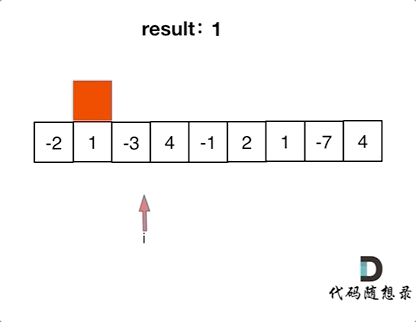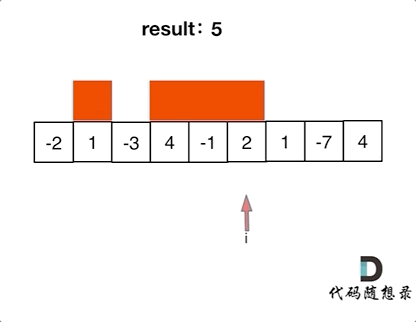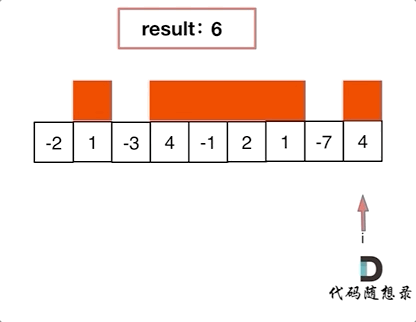
【LeetCode题目详解】第八章 贪心算法 part01 理论基础 455.分发饼干 376. 摆动序列 53. 最大子序和 day31补
贪心算法理论基础 关于贪心算法,你该了解这些! 题目分类大纲如下: # 什么是贪心 贪心的本质是选择每一阶段的局部最优,从而达到全局最优。 这么说有点抽象,来举一个例子: 例如,有一堆钞票&…...
ssm+vue中国咖啡文化宣传网站源码和论文
ssmvue中国咖啡文化宣传网站源码和论文078 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 课题背景 随着时代的发展和人们生活理念的进一步改变,咖啡业已经成为了全球经济中发展最迅猛的产业之一。…...
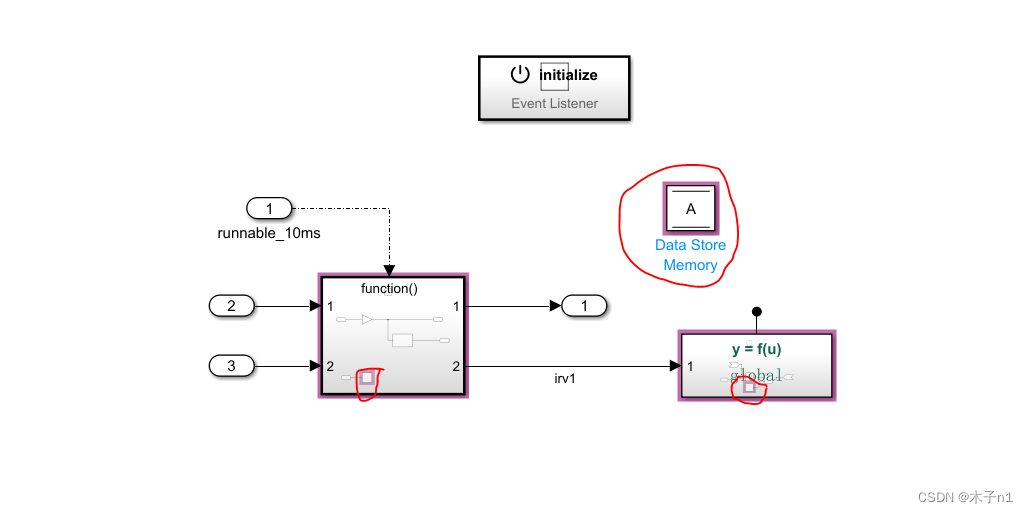
基于MATLAB开发AUTOSAR软件应用层Code mapping专题-part 4 Data store标签页介绍
这篇文章我们继续讲解code-mapping的Data stores页,这个页的内容对应的SIMULINK中的模块是Data store memory。 我们首先在模型中创建一个Data store memory模块,如图: Data store memory模块的作用相当于一个全局变量,我们可以在模型的功能逻辑里将一个信号存进去,在另…...

区间型动态规划典型题目:lintcode 476 · 石子归并【中等,免费】lintcode 593 · 石头游戏 II【中等 vip】
题目lintcode476 链接,描述 https://www.lintcode.com/problem/476/description 有一个石子归并的游戏。最开始的时候,有n堆石子排成一列,目标是要将所有的石子合并成一堆。合并规则如下:每一次可以合并相邻位置的两堆石子 每次…...
4. 池化层相关概念
4.1 池化层原理 ① 最大池化层有时也被称为下采样。 ② dilation为空洞卷积,如下图所示。 ③ Ceil_model为当超出区域时,只取最左上角的值。 ④ 池化使得数据由5 * 5 变为3 * 3,甚至1 * 1的,这样导致计算的参数会大大减小。例如1080P的电…...
ChatGPT Prompting开发实战(一)
一、关于ChatGPT Prompting概述 当我们使用ChatGPT或者调用OpenAI的API时,就是在使用prompt进行交互,用户在对话过程中输入的一切信息都是prompt(提示词),当然工业级的prompt与人们通常理解的prompt可能不太一样。下面…...

VB车辆管理系统SQL设计与实现
摘 要 随着信息时代的到来,信息高速公路的兴起,全球信息化进入了一个新的发展时期。人们越来越认识到计算机强大的信息模块处理功能,使之成为信息产业的基础和支柱。 我国经济的快速发展,汽车已经成为人们不可缺少的交通工具。对于拥有大量车辆的机关企事业来说,车辆的…...

java 泛型
概述 泛型在java中有很重要的地位,在面向对象编程及各种设计模式中有非常广泛的应用。 泛型,就是类型参数。 一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。 那么类型参数理解呢? 顾名思义&…...

魔兽世界BBC周年纪念版即将上线!UU远程,让你出门在外也能组队开荒!
各位勇士,战鼓已经擂响!《魔兽世界》BCC周年纪念版——外域的霸主(Overlords of Outland)将在5月15日正式上线! 外域之战全面升级!挑战伊利丹怒风的副官,攻略两座全新团队副本,投身竞…...

胶片颗粒≠随机噪点,35mm风格出图翻车全解析,深度拆解ISO模拟、过期胶卷色偏与显影液残留建模逻辑
更多请点击: https://intelliparadigm.com 第一章:胶片颗粒≠随机噪点,35mm风格出图翻车全解析 胶片摄影的颗粒感(Grain)是银盐晶体在显影过程中形成的物理性、非均匀、结构化纹理,而数字图像中常见的“噪…...
)
保姆级教程:在Ubuntu 22.04上为LAMMPS编译ReaxFF+Kokkos+OpenMP混合加速包(含GPU/CPU架构识别)
在Ubuntu 22.04上为LAMMPS编译ReaxFFKokkosOpenMP混合加速包的完整指南 对于计算材料科学和分子动力学模拟的研究者来说,LAMMPS是一个不可或缺的工具。然而,当模拟系统变得复杂时,计算效率往往成为瓶颈。本文将详细介绍如何在Ubuntu 22.04系统…...
)
保姆级教程:用Python搞定安居客滑块验证码(附AES加密与轨迹生成源码)
Python实战:破解安居客滑块验证码的完整技术方案 滑块验证码已经成为现代网站反爬机制的重要组成部分。对于开发者而言,理解其工作原理并实现自动化解决方案,不仅能提升爬虫效率,也是技术能力的体现。本文将深入解析安居客滑块验证…...

答辩前别慌!Paperxie AI PPT,把你的毕业论文一键变成 “答辩通关券”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 距离毕业答辩只剩一周,你的论文终稿已经反复修改了十几遍,可电脑桌面上的答辩 PPT 文件夹࿰…...

Umami MCP服务器:连接网站分析与AI工作流的标准化桥梁
1. 项目概述:一个为Umami量身定制的MCP服务器如果你正在使用Umami这个开源的网站分析工具,并且希望它能与你日常开发工作流中的其他工具(比如代码编辑器、CLI工具、自动化脚本)更紧密地结合,那么Macawls/umami-mcp-ser…...

day15 C语言 指针3
13.字符指针的常见错误#include<stdio.h>#if 0int main(int argc, char **argv){//char *p"hello"; //error,会发生段错误 hello在内存中只有一份,只能读取不能修改char p[]"hello"; //char [] 开辟空间,会把hello复制一份给…...

深度解析开源小红书采集工具:XHS-Downloader技术架构与实战应用指南
深度解析开源小红书采集工具:XHS-Downloader技术架构与实战应用指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、…...

基于SSH与rsync构建跨平台远程开发环境:remote2mac实战指南
1. 项目概述与核心价值最近在折腾跨平台开发环境,特别是需要在Windows或Linux机器上,无缝地操作和编译运行macOS上的代码。如果你也遇到过类似场景——比如主力开发机是Windows笔记本,但项目最终部署或测试环境是macOS服务器;或者…...

国产多模态新星MiniGPT-4:从原理到落地,一篇讲透
国产多模态新星MiniGPT-4:从原理到落地,一篇讲透 引言 在ChatGPT点燃的AI浪潮中,多模态大模型被视为下一个关键赛点。当业界目光聚焦于GPT-4V等巨头产品时,一款名为 MiniGPT-4 的国产开源模型以其清晰的架构、惊艳的效果和极致的…...