Focal Loss-解决样本标签分布不平衡问题
文章目录
- 背景
- 交叉熵损失函数
- 平衡交叉熵函数
- Focal Loss损失函数
- Focal Loss vs Balanced Cross Entropy
- Why does Focal Loss work?
- 针对VidHOI数据集
- Reference
背景
Focal Loss由何凯明提出,最初用于图像领域解决数据不平衡造成的模型性能问题。
交叉熵损失函数
L o s s = L ( y , p ^ ) = − y l o g ( p ^ ) − ( 1 − y ) l o g ( 1 − p ^ ) Loss=L(y,\hat{p})=-ylog(\hat{p})-(1-y)log(1-\hat{p}) Loss=L(y,p^)=−ylog(p^)−(1−y)log(1−p^)
其中, p ^ \hat{p} p^为预测概率大小。y为label,二分类中对应0和1。
L c e ( y , p ^ ) = { − l o g ( p ^ ) , if y = 1 − l o g ( 1 − p ^ ) , if y = 0 L_{ce}(y,\hat{p})= \left\{ \begin{array}{ll} -log(\hat{p}), & \text{if } y = 1 \\ -log(1-\hat{p}), & \text{if }y=0 \end{array} \right. Lce(y,p^)={−log(p^),−log(1−p^),if y=1if y=0
对于所有样本,需要求平均作为最终的结果:
L = 1 N ∑ i = 1 N l ( y i , p ^ i ) L=\frac{1}{N}\sum_{i=1}^{N}l(y_i,\hat{p}_i) L=N1i=1∑Nl(yi,p^i)
对于二分类问题,可以改写成:
L = 1 N ( ∑ y i = 1 m − l o g ( p ^ ) + ∑ y i = 0 n − l o g ( 1 − p ^ ) ) L=\frac{1}{N}(\sum_{y_i=1}^{m}-log(\hat{p})+\sum_{y_i=0}^{n}-log(1-\hat{p})) L=N1(yi=1∑m−log(p^)+yi=0∑n−log(1−p^))
其中,N为样本总数,m和n为正、负样本数, m + n = N m+n=N m+n=N
当样本分布不平衡时,损失函数L的分布也会发生倾斜,若m>>n时,正样本就会在损失函数中占据主导地位,由于损失函数的倾斜,训练的模型会倾向于样本较多的类别,导致对较少样本类别的性能较差。
平衡交叉熵函数
对于样本不平衡造成的损失函数倾斜,最直接的方法就是添加权重因子,提高少数类别在损失函数中的权重,从而平衡损失函数的分布。还是以之前的二分类问题为例,我们添加权重参数 α ∈ [ 0 , 1 ] \alpha∈[0,1] α∈[0,1]
L = 1 N ( ∑ y i = 1 m − α l o g ( p ^ ) + ∑ y i = 0 n − ( 1 − α ) l o g ( 1 − p ^ ) ) L=\frac{1}{N}(\sum_{y_i=1}^{m}-\alpha log(\hat{p})+\sum_{y_i=0}^{n}-(1-\alpha)log(1-\hat{p})) L=N1(yi=1∑m−αlog(p^)+yi=0∑n−(1−α)log(1−p^))
其中, α 1 − α = n m \frac{\alpha}{1-\alpha}=\frac{n}{m} 1−αα=mn,权重大小由正负样本数量比来设置。
Focal Loss损失函数
Focal Loss从loss角度提供了一种样本不均衡的解决方案:
L f o c a l ( y , p ^ ) = { − ( 1 − p ^ ) γ l o g ( p ^ ) , if y = 1 − p ^ γ l o g ( 1 − p ^ ) , if y = 0 L_{focal}(y,\hat{p})= \left\{ \begin{array}{ll} -(1-\hat{p})^\gamma log(\hat{p}), & \text{if } y = 1 \\ -\hat{p}^\gamma log(1-\hat{p}), & \text{if }y=0 \end{array} \right. Lfocal(y,p^)={−(1−p^)γlog(p^),−p^γlog(1−p^),if y=1if y=0
令 p t = { p ^ , if y = 1 1 − p ^ , otherwise. p_t= \left\{ \begin{array}{ll} \hat{p}, & \text{if } y = 1 \\ 1-\hat{p}, & \text{otherwise. } \end{array} \right. pt={p^,1−p^,if y=1otherwise.
则表达式统一为:
L f o c a l = − ( 1 − p t ) γ l o g ( p t ) L_{focal}=-(1-p_t)^\gamma log(p_t) Lfocal=−(1−pt)γlog(pt)
与交叉熵表达式对照: L c e = − l o g ( p t ) L_{ce}=-log(p_t) Lce=−log(pt),仅仅多了一个可变系数 ( 1 − p t ) γ (1-p_t)^\gamma (1−pt)γ.
其中, p t p_t pt反应了与ground truth的接近程度,越大表示分类越准。 γ > 0 \gamma>0 γ>0为调节因子。
对于分类不准确的样本, p t → 0 p_t→0 pt→0, ( 1 − p t ) γ → 1 (1-p_t)^\gamma→1 (1−pt)γ→1, L f o c a l → L c e L_{focal}→L_{ce} Lfocal→Lce;对于分类准确的样本, p t → 1 p_t→1 pt→1, ( 1 − p t ) γ → 0 (1-p_t)^\gamma→0 (1−pt)γ→0, L f o c a l → 0 L_{focal}→0 Lfocal→0;因此,Focal Loss对于分类不准确的样本,损失没有改变;对于分类准确的样本,损失会变小。整体来看,Focal Loss增加了分类不准确样本在损失函数中的权重。
如下是不同调节因子 γ \gamma γ对应的Loss-proba分布图,可以看出Cross Entropy(CE)和Focal Loss(FL)之间的区别,Focal Loss使损失函数更倾向于难分的样本。

Focal Loss vs Balanced Cross Entropy
- Focal Loss是从样本分类难易程度出发,让Loss聚焦于难分类的样本;
- Balanced Cross Entropy是从样本分布角度对Loss添加权重因子。
- 缺点:仅仅考虑样本分布,有些难以区分的类别的样本数可能也比较多,此时被BCE赋予了较低的权重,会导致模型很难识别该类别!
Why does Focal Loss work?
Focal Loss从样本难易分类的角度出发,解决了样本不平衡导致模型性能较低的问题。
WHY?
样本不平衡造成的问题就是,样本数少的类别分类难度大,因此Focal Loss聚焦于难分样本,解决了样本少的类别分类精度不高的问题,对于难分样本中样本多的类别,也会被Focal Loss聚焦。因此,它不仅解决了样本不平衡问题,还提升了模型整体性能。
但是,要使模型训练过程中聚焦于难分类样本,仅仅将Loss倾向于难分类样本是不够的,因为模型参数更新取决于Loss的梯度:
w = w − α ∂ L ∂ w w=w-\alpha\frac{\partial L}{\partial w} w=w−α∂w∂L
若Loss中难分类样本的权重较高,但是难分类样本的Loss梯度为0,难分类样本就不会影响到模型的参数更新。对于梯度问题,Focal Loss中的梯度与 x t x_t xt的关系如下所示,其中 x t = y x x_t=yx xt=yx, y ∈ { − 1 , 1 } y∈\{-1,1\} y∈{−1,1}为类别, p t = σ ( x t ) p_t=\sigma(x_t) pt=σ(xt),对于易分样本, x t > 0 x_t>0 xt>0,即 p t > 0.5 p_t>0.5 pt>0.5,由下图可知,此时的导数趋于0。对于难分样本,导数数值较大,因此,学习过程中更聚焦于难分样本。

难易分类样本是动态的, p t p_t pt在训练的过程中,可能会在难易之间相互转换。
在Loss梯度中,难训练样本起主导作用,参数朝着优化难训练样本的方向改变,变化之后可能会导致原本易训练的样本 p t p_t pt变化,即变成难训练样本。若发生了这种情况会导致模型收敛速度较慢。
为了防止这种难易样本的频繁变化,应该选择较小的学习率。
针对VidHOI数据集
因为VidHOI数据集中的一个人-物对会被多个交互标签同时标注,如< human,next to & watch & hold, cup >,所以会面临multi-class multi-label的分类问题。以往常常使用Binary cross-entropy,能够计算每个交互类别独立于其他类别的损失。但是,VidHOI数据集分布不均且具有长尾分布,为了解决这个不均衡问题同时避免过分强调最频繁类别的重要性,我们采用class-balanced Focal loss:
C B f o c a l ( p i , y i ) = − 1 − β 1 − β n i ( 1 − p y i ) γ l o g ( p y i ) w i t h p y i = { p i , if y i = 1 1 − p i , otherwise. CB_{focal}(p_i,y_i)=-\frac{1-\beta}{1-\beta^{n_i}}(1-p_{y_i})^{\gamma}log(p_{y_i}) \\ with \ p_{y_i} = \left\{ \begin{array}{ll} p_i, & \text{if } y_i = 1 \\ 1-p_i, & \text{otherwise.} \end{array} \right. CBfocal(pi,yi)=−1−βni1−β(1−pyi)γlog(pyi)with pyi={pi,1−pi,if yi=1otherwise.
其中的 − ( 1 − p y i ) γ l o g ( p y i ) -(1-p_{y_i})^{\gamma}log(p_{y_i}) −(1−pyi)γlog(pyi)是Lin提出的Focal loss, p i p_i pi表示预估为第i个类别的可能性, y i ∈ { 0 , 1 } y_i∈\{0,1\} yi∈{0,1}表示Ground Truth的label。变量 n i n_i ni表示第i个类别在Ground Truth下的样本量, β ∈ [ 0 , 1 ) \beta∈[0,1) β∈[0,1)是可调节参数。所有类别的平均损失作为一个预测的损失。
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Optionalclass FocalBCEWithLogitLoss(nn.modules.loss._Loss):"""Focal Loss with binary cross-entropyImplement the focal loss with class-balanced loss, using binary cross-entropy as criterionFollowing paper "Class-Balanced Loss Based on Effective Number of Samples" (CVPR2019)Args:gamma (int, optional): modulation factor gamma in focal loss. Defaults to 2.alpha (int, optional): modulation factor alpha in focal loss. If a integer, apply to all;if a list or array or tensor, regard as alpha for each class; if none, no alpha. Defaults to None.weight (Optional[torch.Tensor], optional): weight to each class, !not the same as alpha. Defaults to None.size_average (_type_, optional): _description_. Defaults to None.reduce (_type_, optional): _description_. Defaults to None.reduction (str, optional): _description_. Defaults to "mean"."""def __init__(self,gamma=2,alpha=None,weight: Optional[torch.Tensor] = None,size_average=None,reduce=None,reduction: str = "mean",pos_weight: Optional[torch.Tensor] = None,):super(FocalBCEWithLogitLoss, self).__init__(size_average, reduce, reduction)self.gamma = gamma# a number for all, or a Tensor with the same num_classes as inputif isinstance(alpha, (list, np.ndarray)):self.alpha = torch.Tensor(alpha)else:self.alpha = alphaself.register_buffer("weight", weight)self.register_buffer("pos_weight", pos_weight)self.weight: Optional[torch.Tensor]self.pos_weight: Optional[torch.Tensor]def forward(self, input: torch.Tensor, target: torch.Tensor):if self.alpha is not None:if isinstance(self.alpha, torch.Tensor):alpha_t = self.alpha.repeat(input.shape[0], 1)else:alpha_t = torch.ones_like(input) * self.alphaelse:alpha_t = None# 二元交叉熵ce = F.binary_cross_entropy_with_logits(input, target, reduction="none")# pt = torch.exp(-ce)# modulator = ((1 - pt) ** self.gamma)# following author's repo https://github.com/richardaecn/class-balanced-loss/blob/master/src/cifar_main.py#L226-L266# explaination https://github.com/richardaecn/class-balanced-loss/issues/1# A numerically stable implementation of modulator.if self.gamma == 0.0:modulator = 1.0else:# e^(-gamma*target*input - gamma*log(1+e^(-input)))modulator = torch.exp(-self.gamma * target * input - self.gamma * torch.log1p(torch.exp(-input)))# focal lossfl_loss = modulator * ce# alphaif alpha_t is not None:alpha_t = alpha_t * target + (1 - alpha_t) * (1 - target)fl_loss = alpha_t * fl_loss# pos weightif self.pos_weight is not None:fl_loss = self.pos_weight * fl_loss# reductionif self.reduction == "mean":return fl_loss.mean()elif self.reduction == "sum":return fl_loss.sum()else:return fl_loss
C B f o c a l ( p i , y i ) = − 1 − β 1 − β n i ( 1 − p y i ) γ l o g ( p y i ) w i t h p y i = { p i , if y i = 1 1 − p i , otherwise. CB_{focal}(p_i,y_i)=-\frac{1-\beta}{1-\beta^{n_i}}(1-p_{y_i})^{\gamma}log(p_{y_i}) \\ with \ p_{y_i} = \left\{ \begin{array}{ll} p_i, & \text{if } y_i = 1 \\ 1-p_i, & \text{otherwise.} \end{array} \right. CBfocal(pi,yi)=−1−βni1−β(1−pyi)γlog(pyi)with pyi={pi,1−pi,if yi=1otherwise.
原始版本的代码:
def focal_loss(labels, logits, alpha, gamma):"""Compute the focal loss between `logits` and the ground truth `labels`.Focal loss = -alpha_t * (1-pt)^gamma * log(pt)where pt is the probability of being classified to the true class.pt = p (if true class), otherwise pt = 1 - p. p = sigmoid(logit).Args:labels: A float32 tensor of size [batch, num_classes].logits: A float32 tensor of size [batch, num_classes].alpha: A float32 tensor of size [batch_size]specifying per-example weight for balanced cross entropy.gamma: A float32 scalar modulating loss from hard and easy examples.Returns:focal_loss: A float32 scalar representing normalized total loss."""with tf.name_scope('focal_loss'):logits = tf.cast(logits, dtype=tf.float32)cross_entropy = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits)# positive_label_mask = tf.equal(labels, 1.0)# probs = tf.sigmoid(logits)# probs_gt = tf.where(positive_label_mask, probs, 1.0 - probs)# # With gamma < 1, the implementation could produce NaN during back prop.# modulator = tf.pow(1.0 - probs_gt, gamma)# A numerically stable implementation of modulator.if gamma == 0.0:modulator = 1.0else:modulator = tf.exp(-gamma * labels * logits - gamma * tf.log1p(tf.exp(-1.0 * logits)))loss = modulator * cross_entropyweighted_loss = alpha * lossfocal_loss = tf.reduce_sum(weighted_loss)# Normalize by the total number of positive samples.focal_loss /= tf.reduce_sum(labels)return focal_loss
Reference
- https://zhuanlan.zhihu.com/p/266023273
- https://github.com/nizhf/hoi-prediction-gaze-transformer
- https://github.com/richardaecn/class-balanced-loss/blob/master/src/cifar_main.py#L226-L266
相关文章:
Focal Loss-解决样本标签分布不平衡问题
文章目录 背景交叉熵损失函数平衡交叉熵函数 Focal Loss损失函数Focal Loss vs Balanced Cross EntropyWhy does Focal Loss work? 针对VidHOI数据集Reference 背景 Focal Loss由何凯明提出,最初用于图像领域解决数据不平衡造成的模型性能问题。 交叉熵损失函数 …...

运算符(个人学习笔记黑马学习)
算数运算符 加减乘除 #include <iostream> using namespace std;int main() {int a1 10;int a2 20;cout << a1 a2 << endl;cout << a1 - a2 << endl;cout << a1 * a2 << endl;cout << a1 / a2 << endl;/*double a3 …...

开源与专有软件:比较与对比
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

openResty+lua+redis实现接口访问频率限制
openResty简介: OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。 OpenResty 通过汇聚各种设…...
自动化测试(三):接口自动化pytest测试框架
文章目录 1. 接口自动化的实现2. 知识要点及实践2.1 requests.post传递的参数本质2.2 pytest单元测试框架2.2.1 pytest框架简介2.2.2 pytest装饰器2.2.3 断言、allure测试报告2.2.4 接口关联、封装改进YAML动态传参(热加载) 2.3 pytest接口封装ÿ…...

Python --datetime模块
目录 1, 获取datetime时间 2, datetime与timestamp转换 2-1, datetime转timestamp 2-2, timestamp转datetime 3, str格式与datetime转换 3-1, datetime转str格式 3-2, str格式转datetime…...
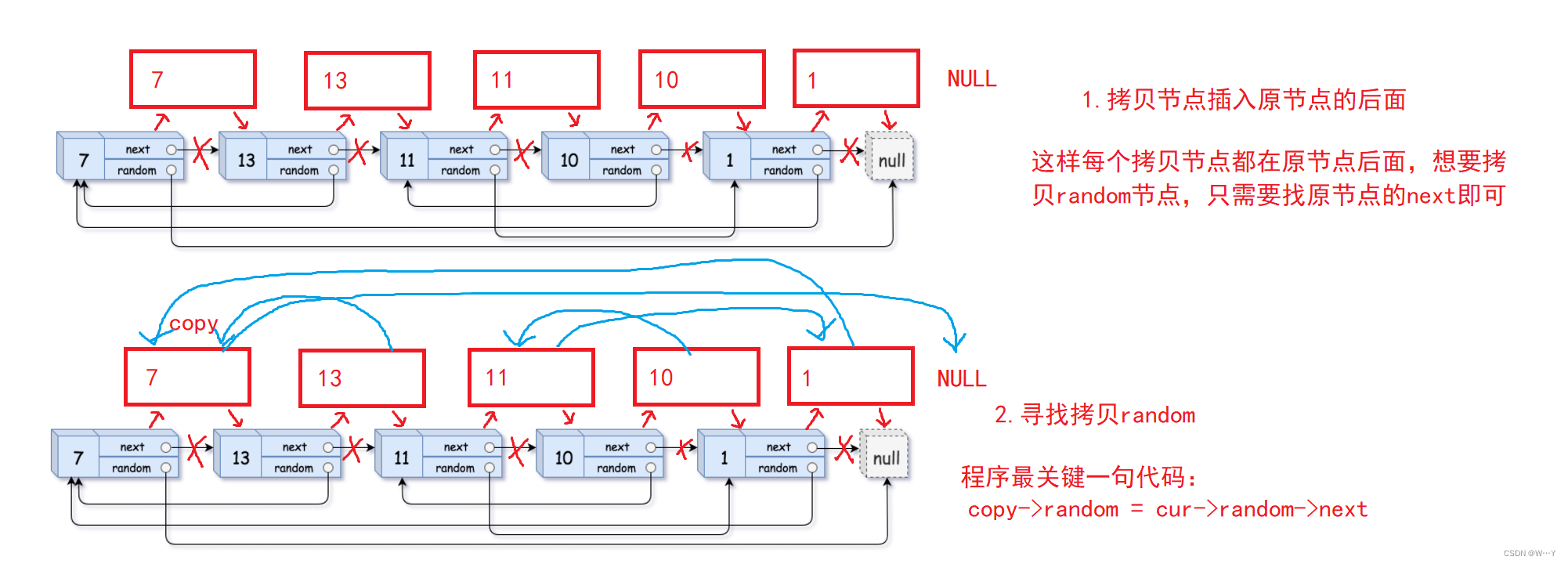
顺序表链表OJ题(3)——【数据结构】
W...Y的主页 😊 代码仓库分享 💕 前言: 今天是链表顺序表OJ练习题最后一次分享,每一次的分享题目的难度也再有所提高,但是我相信大家都是非常机智的,希望看到博主文章能学到东西的可以一键三连关注一下博主…...

【Azure】Virtual Hub vWAN
虚拟 WAN 文档 Azure 虚拟 WAN 是一个网络服务,其中整合了多种网络、安全和路由功能,提供单一操作界面。 我们主要讨论两种连接情况: 通过一个 vWAN 来连接不通的 vNET 和本地网络。以下是一个扩展的拓扑 结合 vhub,可以把两个中…...

React Navigation 使用导航
在 Web 浏览器中,您可以使用锚标记链接到不同的页面。当用户单击链接时,URL 会被推送到浏览器历史记录堆栈中。当用户按下后退按钮时,浏览器会从历史堆栈顶部弹出该项目,因此活动页面现在是以前访问过的页面。React Native 不像 W…...
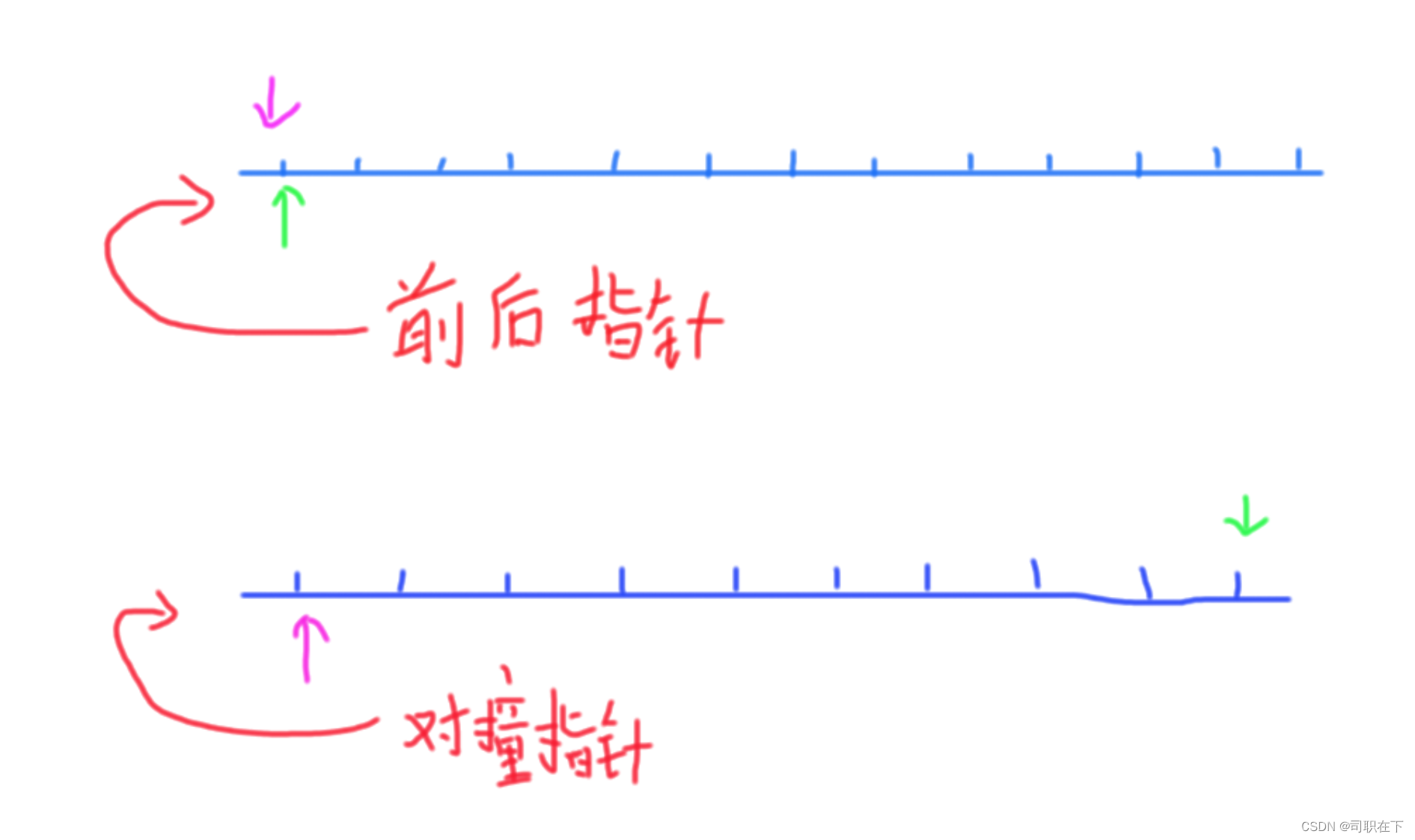
双指针算法,基础算法实践,基本的算法的思想,双指针算法的实现
一,定义 双指针算法是一种常用于解决数组和链表问题的算法技巧。它的核心思想是使用两个指针在数据结构中按照一定的规则移动,从而达到快速搜索或处理数据的目的。这个技巧通常用于优化算法,降低时间复杂度,提高程序的执行效率。…...
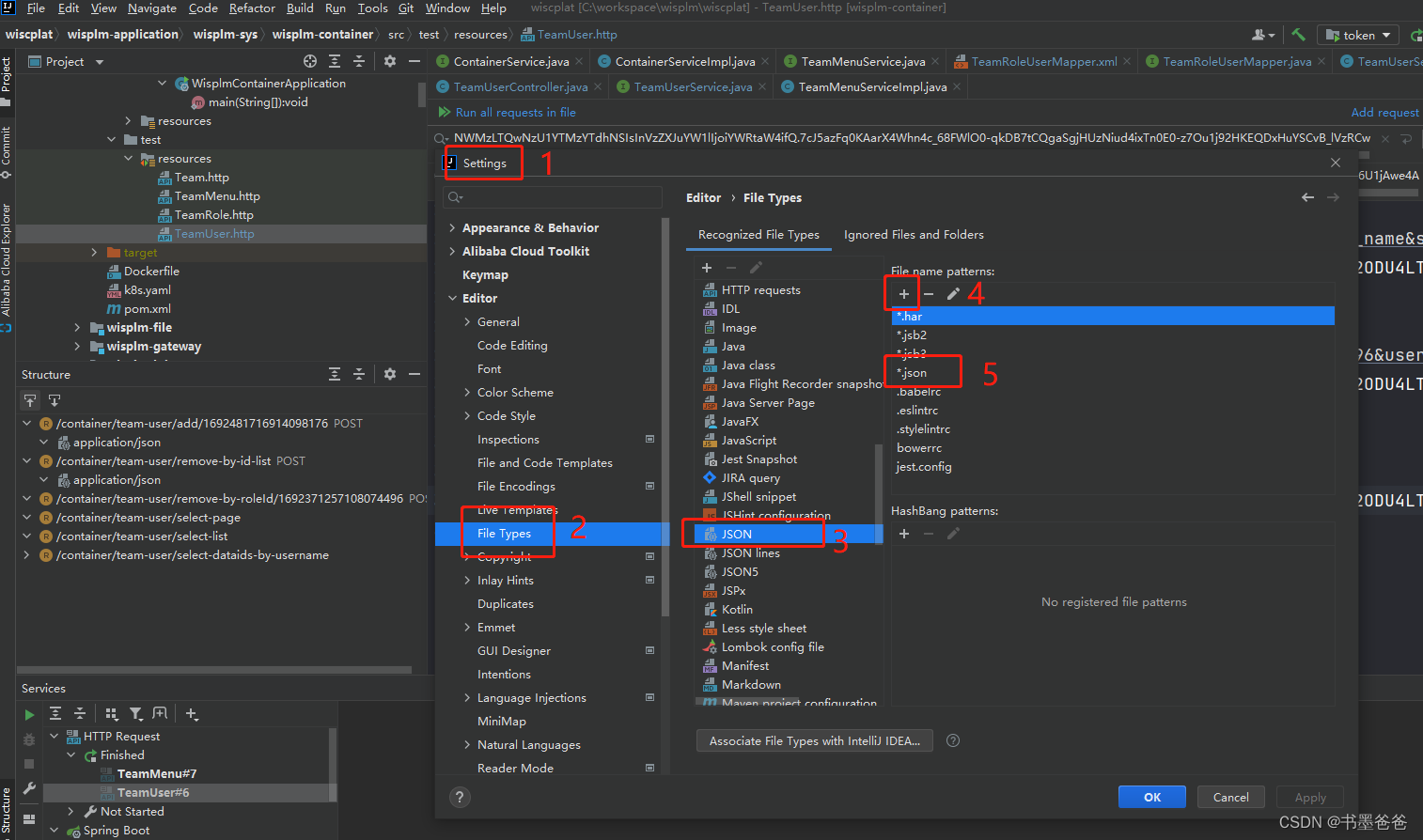
idea http request无法识别环境变量
问题描述 创建了环境变量文件 http-client.env.json,然后在*.http 文件中引用环境变量,运行 HTTP 请求无法读取环境变量文件中定义的变量。 事故现场 IDEA 版本:2020.2 2021.2 解决步骤 2020.2 版本环境变量无法读取 2021.2 版本从 2020.…...

性能测试常见的测试指标
一、什么是性能测试 先看下百度百科对它的定义 性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。我们可以认为性能测试是:通过在测试环境下对系统或构件的性能进行探测,用以验证在生产环境下系统性能…...
并发 04(Callable,CountDownLatch)详细讲解
并发 Callable 1 可以返回值 2可以抛出异常 泛型指的是返回值的类型 public class Send {public static void main(String[] args) {//怎么启动Callable//new Thread().start();Aaa threadnew Aaa();FutureTask futureTasknew FutureTask(thread);new Thread(futureTask,&qu…...

Json路径表达式
原json路径 {"timeStamp": "20220801110008","transIDO": "6ba9088c981b407fb38feasdf09","version": "1.0.0","signMethod": "md5","content": "{\"companyName\&quo…...

【uniapp 上传图片示例】
以下是 uniapp 上传图片的详细步骤示例: 定义一个方法,用于选择图片并上传: methods: {chooseImage() {uni.chooseImage({count: 1, // 最多选择的图片数量sizeType: [original, compressed], // 可以指定原图或压缩图sourceType: [album, …...

apache2配置文件 Require all granted是什么意思
修改apache2的配置文件 /etc/apache2/apache2.conf,需要增加网站代码的路径,下列配置是什么意思呢 <Directory "/var/www/html">Options FollowSymLinksAllowOverride AllRequire all granted </Directory> 1. Options Options …...

c/c++ 的一些知识
c 面向对象是一种思想,通常情况下都是以组合为主,也就是在子类里定义一个基类struct base_t {void (*method)(base_t *base_p); };struct children_t {int a;int b;base_t base;void (*method)(children_t *children_p); };children_t children_creat(i…...

Rancher上的应用服务报错:413 Request Entity Too Large
UI->rancher的ingress->UI前端(在nginx里面)->zuul->server 也就是说没经过一次http servlet 都要设置一下大小 1.rancher的ingress 当出现Request Entity Too Large时,是由于传输流超过1M。 1、需要在rancher的ingress中设置参数解决。 配置注释&a…...
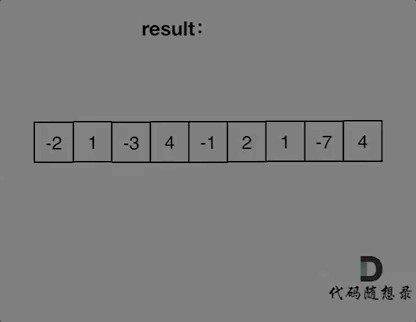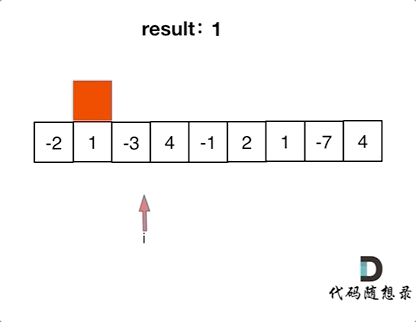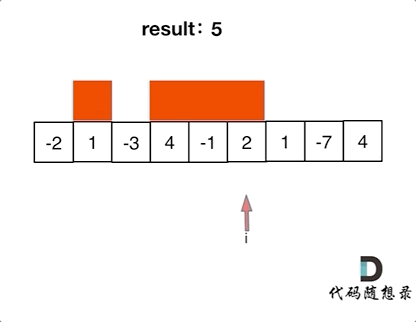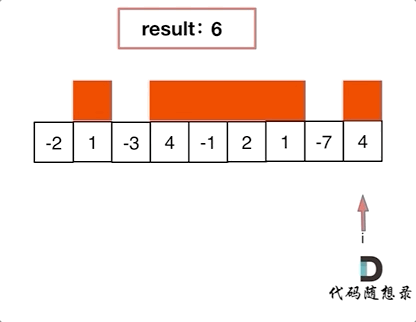
【LeetCode题目详解】第八章 贪心算法 part01 理论基础 455.分发饼干 376. 摆动序列 53. 最大子序和 day31补
贪心算法理论基础 关于贪心算法,你该了解这些! 题目分类大纲如下: # 什么是贪心 贪心的本质是选择每一阶段的局部最优,从而达到全局最优。 这么说有点抽象,来举一个例子: 例如,有一堆钞票&…...
ssm+vue中国咖啡文化宣传网站源码和论文
ssmvue中国咖啡文化宣传网站源码和论文078 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 课题背景 随着时代的发展和人们生活理念的进一步改变,咖啡业已经成为了全球经济中发展最迅猛的产业之一。…...

论文创新点像挤牙膏?导师强推这几个AI论文平台
想写论文又快又好,关键是用对 AI 工具、走对流程——资深教授普遍推荐:千笔AI(中文全流程首选) 豆包学术版(轻量高效) DeepSeek 学术版(理工 / 长文本) Grammarly Academicÿ…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

Arduino土壤湿度监测仪制作:从传感器原理到自动灌溉实现
1. 项目概述:用Arduino Uno和LCD屏打造你的土壤湿度监测仪作为一个喜欢在阳台种点番茄、辣椒的业余园丁,我经常为浇水这事儿头疼。浇多了怕烂根,浇少了又怕旱着,光靠手指插土里感觉,实在是不准。后来玩上了Arduino&…...
)
【独家首发】Sora 2 AVI支持并非“开箱即用”:3层封装校验机制详解(RIFF→AVI→OpenCV Mat内存映射链路图解)
更多请点击: https://codechina.net 第一章:Sora 2 AVI支持并非“开箱即用”:核心矛盾与技术定位 Sora 2 的官方文档与发布说明中明确将 AVI 视为“实验性容器支持”,而非默认启用的输入格式。其底层解码栈基于 FFmpeg 5.1 构建&…...

MNE-Python 第9天学习笔记:源定位基础
一、什么是源定位? 1.1 通俗理解 到目前为止,我们分析的是"头皮上的脑电":头皮电极 → 记录头皮表面的电位↓这就像在地球表面测量地震波我们想知道的是:震源在哪里?多深?源定位 从头皮电位反推…...

3步解决英雄联盟回放难题:ROFL-Player终极使用指南
3步解决英雄联盟回放难题:ROFL-Player终极使用指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 你是否曾经遇到过这样的烦…...

Video2X专业级AI视频增强实战指南:GPU加速无损放大的深度技术解析
Video2X专业级AI视频增强实战指南:GPU加速无损放大的深度技术解析 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trendi…...