LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
目录
SQLCoder的简介
1、结果
2、按问题类别的结果
SQLCoder的安装
1、硬件要求
2、下载模型权重
3、使用SQLCoder
4、Colab中运行SQLCoder
第一步,配置环境
第二步,测试
第三步,下载模型
第四步,设置问题和提示并进行标记化
第五步,生成SQL
SQLCoder的使用方法
SQLCoder的简介

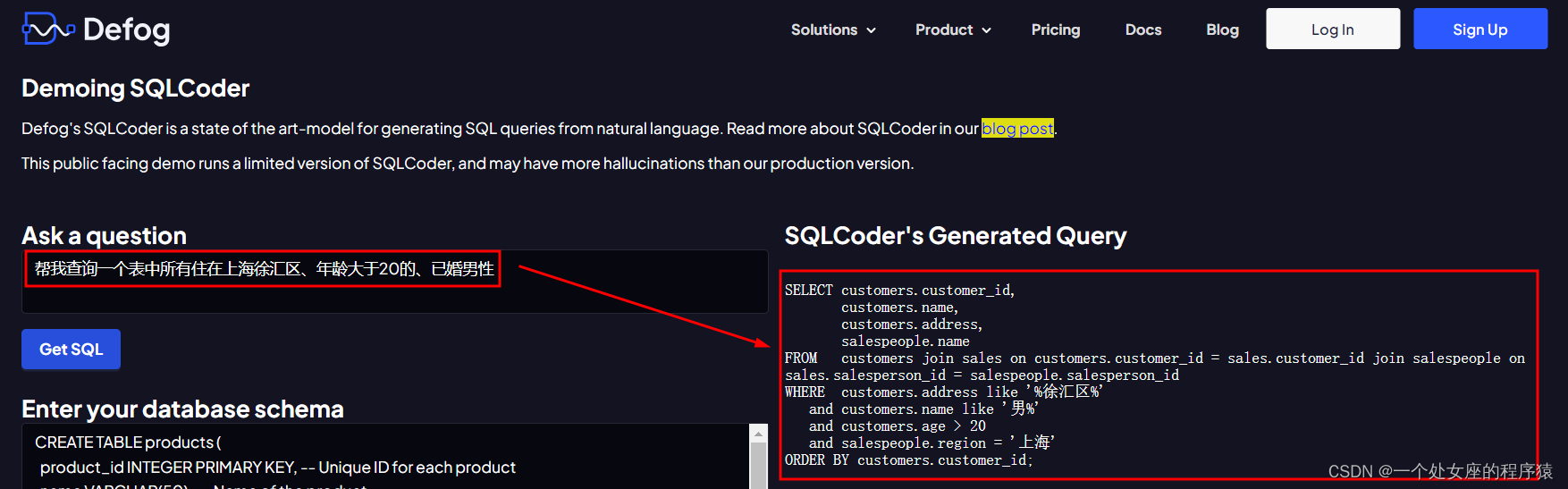
2023年8月,发布了SQLCoder,这是一个先进的LLM,用于将自然语言问题转换为SQL查询。SQLCoder在基础的StarCoder模型上进行了微调。SQLCoder是一个拥有150亿参数的模型,在我们的sql-eval框架上,它在自然语言到SQL生成任务上胜过了gpt-3.5-turbo,并且在所有流行的开源模型中表现显著。它还明显优于大小超过10倍的text-davinci-003模型。
Defog在2个时期内对10537个经过人工筛选的问题进行了训练。这些问题基于10个不同的模式。在训练数据中,没有包括评估框架中的任何模式。
训练分为2个阶段。第一阶段是关于被分类为“容易”或“中等”难度的问题,第二阶段是关于被分类为“困难”或“超级困难”难度的问题。
在easy+medium数据上的训练结果存储在一个名为defog-easy的模型中。我们发现在hard+extra-hard数据上的额外训练导致性能增加了7个百分点。
官网在线测试:https://defog.ai/sqlcoder-demo/
GitHub官网:GitHub - defog-ai/sqlcoder: SoTA LLM for converting natural language questions to SQL queries
1、结果
| model | perc_correct |
| gpt-4 | 74.3 |
| defog-sqlcoder | 64.6 |
| gpt-3.5-turbo | 60.6 |
| defog-easysql | 57.1 |
| text-davinci-003 | 54.3 |
| wizardcoder | 52.0 |
| starcoder | 45.1 |
2、按问题类别的结果
我们将每个生成的问题分类为5个类别之一。该表显示了每个模型按类别细分的正确回答问题的百分比。
| query_category | gpt-4 | defog-sqlcoder | gpt-3.5-turbo | defog-easy | text-davinci-003 | wizard-coder | star-coder |
| group_by | 82.9 | 77.1 | 71.4 | 62.9 | 62.9 | 68.6 | 54.3 |
| order_by | 71.4 | 65.7 | 60.0 | 68.6 | 60.0 | 54.3 | 57.1 |
| ratio | 62.9 | 57.1 | 48.6 | 40.0 | 37.1 | 22.9 | 17.1 |
| table_join | 74.3 | 57.1 | 60.0 | 54.3 | 51.4 | 54.3 | 51.4 |
| where | 80.0 | 65.7 | 62.9 | 60.0 | 60.0 | 60.0 | 45.7 |
SQLCoder的安装
1、硬件要求
SQLCoder已在A100 40GB GPU上进行了测试,使用bfloat16权重。您还可以在具有20GB或更多内存的消费者GPU上加载8位和4位量化版本的模型。例如RTX 4090、RTX 3090以及具有20GB或更多内存的Apple M2 Pro、M2 Max或M2 Ultra芯片。
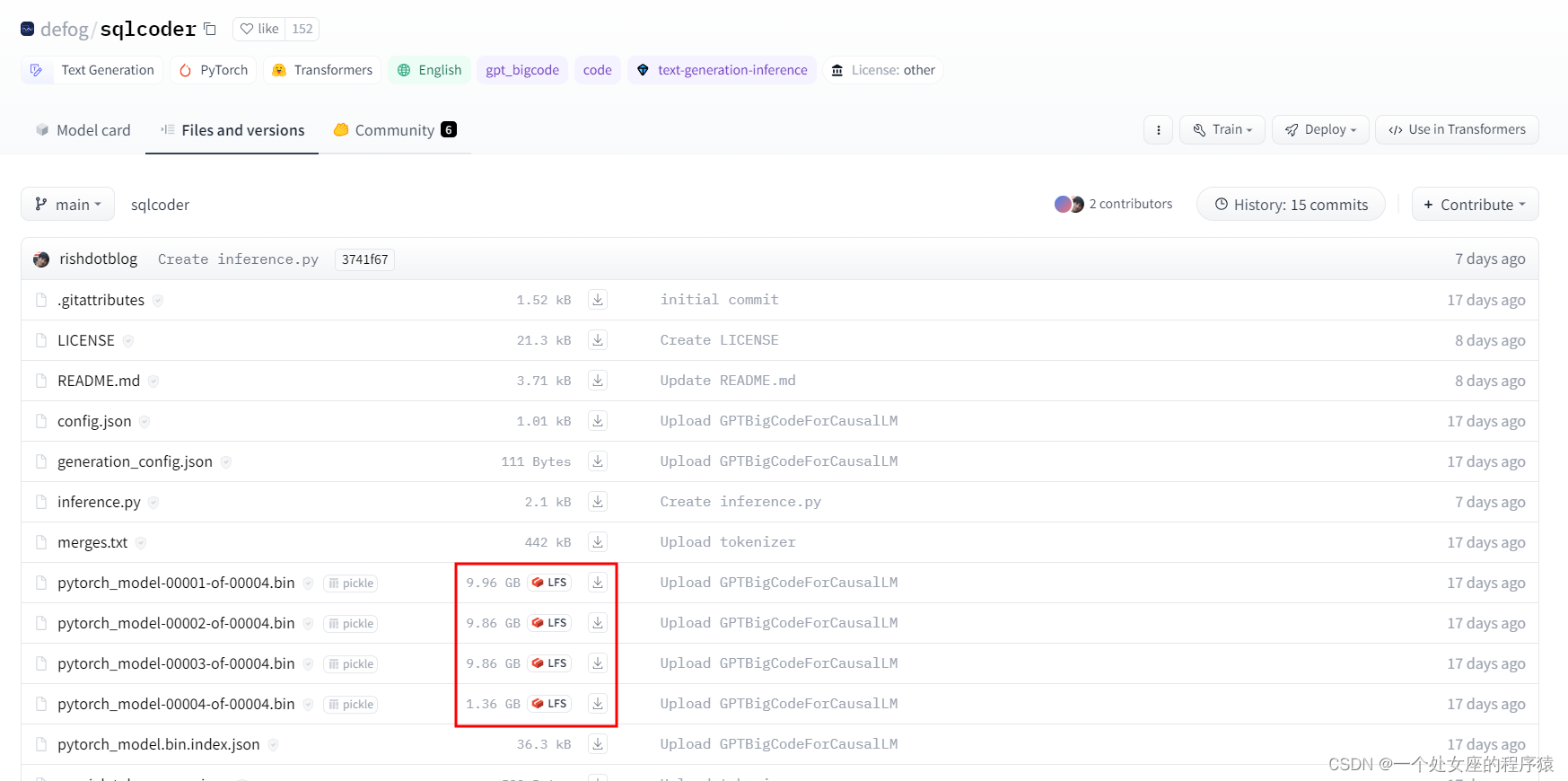
2、下载模型权重
地址:defog/sqlcoder · Hugging Face
3、使用SQLCoder
您可以通过transformers库使用SQLCoder,方法是从Hugging Face存储库中下载我们的模型权重。我们已添加了有关在示例数据库架构上进行推断的示例代码。
python inference.py -q "Question about the sample database goes here"示例问题:我们与纽约的客户相比,从旧金山的客户那里获得更多收入吗?为我提供每个城市的总收入以及两者之间的差异。您还可以在我们的网站上使用演示,或在Colab中运行SQLCoder。
4、Colab中运行SQLCoder
地址:https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7?usp=sharing#scrollTo=MKuocI44V-Bo
第一步,配置环境
!pip install torch transformers bitsandbytes accelerate第二步,测试
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipelinetorch.cuda.is_available()第三步,下载模型
使用Colab Pro上的A100(或具有> 30GB VRAM的任何系统)在bf16中加载它。如果不可用,请使用至少具有20GB VRAM的GPU在8位中加载它,或者至少具有12GB VRAM在4位中加载它。在Colab上,它适用于V100,但在T4上崩溃。
首次下载模型然后将其加载到内存中的步骤大约需要10分钟。所以请耐心等待 :)
model_name = "defog/sqlcoder"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,trust_remote_code=True,# torch_dtype=torch.bfloat16,# load_in_8bit=True,load_in_4bit=True,device_map="auto",use_cache=True,
)第四步,设置问题和提示并进行标记化
随意更改以下问题。如果您想要尝试自己的数据库架构,请在提示中编辑模式。
question = "What product has the biggest fall in sales in 2022 compared to 2021? Give me the product name, the sales amount in both years, and the difference."prompt = """### Instructions:
Your task is to convert a question into a SQL query, given a Postgres database schema.
Adhere to these rules:
- **Deliberately go through the question and database schema word by word** to appropriately answer the question
- **Use Table Aliases** to prevent ambiguity. For example, `SELECT table1.col1, table2.col1 FROM table1 JOIN table2 ON table1.id = table2.id`.
- When creating a ratio, always cast the numerator as float### Input:
Generate a SQL query that answers the question `{question}`.
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (product_id INTEGER PRIMARY KEY, -- Unique ID for each productname VARCHAR(50), -- Name of the productprice DECIMAL(10,2), -- Price of each unit of the productquantity INTEGER -- Current quantity in stock
);CREATE TABLE customers (customer_id INTEGER PRIMARY KEY, -- Unique ID for each customername VARCHAR(50), -- Name of the customeraddress VARCHAR(100) -- Mailing address of the customer
);CREATE TABLE salespeople (salesperson_id INTEGER PRIMARY KEY, -- Unique ID for each salespersonname VARCHAR(50), -- Name of the salespersonregion VARCHAR(50) -- Geographic sales region
);CREATE TABLE sales (sale_id INTEGER PRIMARY KEY, -- Unique ID for each saleproduct_id INTEGER, -- ID of product soldcustomer_id INTEGER, -- ID of customer who made purchasesalesperson_id INTEGER, -- ID of salesperson who made the salesale_date DATE, -- Date the sale occurredquantity INTEGER -- Quantity of product sold
);CREATE TABLE product_suppliers (supplier_id INTEGER PRIMARY KEY, -- Unique ID for each supplierproduct_id INTEGER, -- Product ID suppliedsupply_price DECIMAL(10,2) -- Unit price charged by supplier
);-- sales.product_id can be joined with products.product_id
-- sales.customer_id can be joined with customers.customer_id
-- sales.salesperson_id can be joined with salespeople.salesperson_id
-- product_suppliers.product_id can be joined with products.product_id### Response:
Based on your instructions, here is the SQL query I have generated to answer the question `{question}`:
```sql
""".format(question=question)
eos_token_id = tokenizer.convert_tokens_to_ids(["```"])[0]第五步,生成SQL
在具有4位量化的V100上可能非常缓慢。每个查询可能需要大约1-2分钟。在单个A100 40GB上,需要大约10-20秒。
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
generated_ids = model.generate(**inputs,num_return_sequences=1,eos_token_id=eos_token_id,pad_token_id=eos_token_id,max_new_tokens=400,do_sample=False,num_beams=5
)
outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
torch.cuda.empty_cache()
torch.cuda.synchronize()
# 清空缓存,以便在内存崩溃时可以生成更多结果
# 在Colab上特别重要 - 内存管理要简单得多
# 在运行推断服务时
# 嗯!生成的SQL在这里:
print(outputs[0].split("```sql")[-1].split("```")[0].split(";")[0].strip() + ";")
SQLCoder的使用方法
更新中……
相关文章:
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略 目录 SQLCoder的简介 1、结果 2、按问题类别的结果 SQLCoder的安装 1、硬件要求 2、下载模型权重 3、使用SQLCoder 4、Colab中运行SQLCoder 第一步,配置环境 第二步,测试 第…...

数学建模(四)整数规划—匈牙利算法
目录 一、0-1型整数规划问题 1.1 案例 1.2 指派问题的标准形式 2.2 非标准形式的指派问题 二、指派问题的匈牙利解法 2.1 匈牙利解法的一般步骤 2.2 匈牙利解法的实例 2.3 代码实现 一、0-1型整数规划问题 1.1 案例 投资问题: 有600万元投资5个项目&…...

openGauss学习笔记-47 openGauss 高级数据管理-权限
文章目录 openGauss学习笔记-47 openGauss 高级数据管理-权限47.1 语法格式47.2 参数说明47.3 示例 openGauss学习笔记-47 openGauss 高级数据管理-权限 数据库对象创建后,进行对象创建的用户就是该对象的所有者。数据库安装后的默认情况下,未开启三权分…...
开始MySQL之路——MySQL 事务(详解分析)
MySQL 事务概述 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等…...

注解和class对象和mysql
注解 override 通常是用在方法上的注解表示该方法是有重写的 interface 表示一个注解类 比如 public interface override{} 这就表示是override是一个注解类 target 修饰注解的注解表示元注解 deprecated 修饰某个元素表示该元素已经过时了 1.不代表该元素不能用了&…...
【桌面小屏幕项目】ESP32开发环境搭建
视频教程链接: 【【有手就行系列】嵌入式单片机教程-桌面小屏幕实战教学 从设计、硬件、焊接到代码编写、调试 ESP32 持续更新2022】 https://www.bilibili.com/video/BV1wV4y1G7Vk/?share_sourcecopy_web&vd_source4fa5fad39452b08a8f4aa46532e890a7 一、esp…...

CSS 滚动容器与固定 Tabbar 自适应的几种方式
问题 容器高度使用 px 定高时,随着页面高度发生变化,组件展示的数量不能最大化的铺满,导致出现底部留白。容器高度使用 vw 定高时,随着页面宽度发生变化,组件展示的数量不能最大化的铺满,导致出现底部留白…...

IP 地址追踪工具
IP 地址跟踪工具是一种网络实用程序,允许您扫描、跟踪和获取详细信息,例如 IP 地址的 MAC 和接口 ID。IP 跟踪解决方案通过使用不同的网络扫描协议来检查网络地址空间来收集这些详细信息。一些高级 IP 地址跟踪器软件(如 OpUtils)…...

最新企业网盘产品推荐榜发布
随着数字化发展,传统的文化存储方式已无法跟上企业发展的步伐。云存储的出现为企业提供了新的文件管理存储模式。企业网盘作为云存储的代表性工具,被越来越多的企业所青睐。那么在众多企业网盘产品中,企业该如何找到合适的企业网盘呢…...

实用的面试经验分享:程序员们谈论他们的面试历程
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
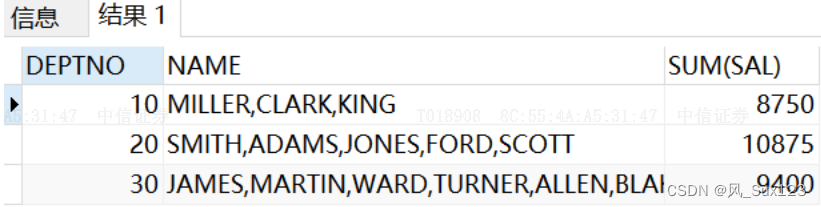
6.oracle中listagg函数使用
1. 作用 可以实现行转列,将多列数据聚合为一列,实现数据的压缩 2. 语法 listagg(measure_expr,delimiter) within group ( order by order_by_clause); 解释: measure_expr可以是基于任何列的表达式 delimiter分隔符,…...

习题练习 C语言(暑期)
编程能力小提升! 前言一、转义字符二、重命名与宏定义三、三目运算符四、计算日期到天数转换五、计算字符串长度六、宏定义应用七、const常量八、C语言基础九、const常量(二)十、符号运算十一、记负均正十二、SWITCH,CASE十三、错…...

C++中虚函数表的概念
当一个类对象指针调用虚函数时,这就涉及到 运行时多态 的概念。这意味着实际调用的函数取决于对象的实际类型,而不仅仅是指针的静态类型。 假设我们有以下的类层次结构: class Base { public:virtual void print() {std::cout << &qu…...
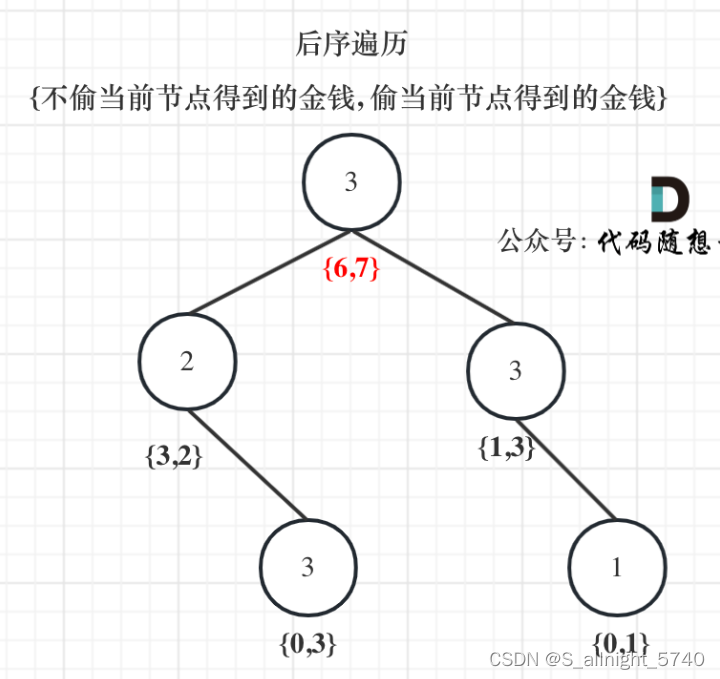
代码随想录算法训练营第四十八天 | 198.打家劫舍,213.打家劫舍II,337.打家劫舍III
代码随想录算法训练营第四十八天 | 198.打家劫舍,213.打家劫舍II,337.打家劫舍III 198.打家劫舍213.打家劫舍II337.打家劫舍III 198.打家劫舍 题目链接 视频讲解 你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金ÿ…...

uniapp项目实战系列(1):导入数据库,启动后端服务,开启代码托管
目录 前言前期准备1.数据库的导入2.运行后端服务2.1数据库的后端配置2.2后端服务下载依赖,第三方库2.3启动后端服务 3.开启gitcode代码托管 ✨ 原创不易,还希望各位大佬支持一下! 👍 点赞,你的认可是我创作的动力&…...
在互联网+的背景下,企业如何创新客户服务?
随着互联网的发展,开始数字化转型的潮流,移动互联网平台为各个行业带来了发展的新方向。企业有了移动互联网的加持,为客户提供了更好的服务。当移动互联网平台能够为客户提供更好的用户体验时,相应地,客户也给企业带来…...

国内的化妆品核辐射检测
化妆品核辐射物质检测是指检测化妆品中的放射性物质,包括放射性核素和放射性同位素。这些放射性物质主要来源于环境中的放射性污染,如空气、水和土壤中的放射性物质,以及化妆品生产过程中的放射性污染,如原料、设备、工艺等。化妆…...

春秋云镜:CVE-2019-9042(Sitemagic CMS v4.4 任意文件上传漏洞)
一、题目 靶标介绍: Sitemagic CMS v4.4 index.php?SMExtSMFiles 存在任意文件上传漏洞,攻击者可上传恶意代码执行系统命令。 进入题目: admin/admin /index.php?SMExtSMFiles&SMTemplateTypeBasic&SMExecModeDedicated&SMFil…...

20230828工作日志:
今天遇到了很多问题,下次可以做得更好更快的几个地方: 1 sql语句的检查 肯定要先在navicate 里执行看,是否有语法错误。即使没有,也还是要注意一些问题:IDEA里换行的时候,“后面要空一格,如果连…...

flink on yarn 部署
需要jars -rwxr-xrwx 3 root supergroup 58284 2022-11-30 03:44 /lib/flink/commons-cli-1.5.0.jar -rw-r--r-- 3 root supergroup 48497 2022-12-10 03:04 /lib/flink/flink-cep-scala_2.12-1.14.3.jar -rw-r--r-- 3 root supergroup 189468 2022-12-10…...
技术演进与物联网应用实践)
蓝牙低功耗(BLE)技术演进与物联网应用实践
1. 蓝牙低功耗技术演进与核心优势蓝牙低功耗(Bluetooth Low Energy,简称BLE)自2010年随蓝牙4.0标准推出以来,已成为物联网设备连接的事实标准。与传统蓝牙技术相比,BLE最显著的特点是采用"间歇性唤醒"的工作…...
)
Trae IDE 实战:打造“创建完美智能体助手”(交互式+自动生成+模板删减,新手无脑上手)
Trae IDE 实战:打造“创建完美智能体助手”(交互式+自动生成+模板删减,新手无脑上手) 前言:在AI研发提效浪潮中,Trae IDE的自定义Agent已成为开发者的核心协作工具。本文聚焦「创建完美智能体助手」的打造,全程贴合Trae原生能力,主打“交互式引导、全自动文件生成、模…...
类型转换的深度避坑指南)
别再让‘01’和‘470.00’坑了你:Python int()类型转换的深度避坑指南
Python类型转换避坑指南:从ValueError到健壮代码的进阶之路 在数据处理和清洗过程中,类型转换是最基础却又最容易出错的环节之一。特别是当面对非标准格式的数字字符串时,即使是经验丰富的开发者也会偶尔掉入int()函数的陷阱。本文将深入剖析…...

手把手教你用Keil调试LVGL的HardFault:从LR=0xFFFFFFF9到找到吃栈的‘元凶’
Cortex-M架构下LVGL的HardFault诊断方法论:从寄存器分析到堆栈优化 当LVGL在Cortex-M微控制器上运行时突然陷入HardFault死循环,许多开发者会条件反射地增大堆栈空间。这种"试错法"虽然可能暂时解决问题,却掩盖了真正的技术债务。本…...

铁路光纤熔接机推荐:鼎讯 TY-30H 性能参数与应用场景
在铁路与高速公路通信建设中,光纤熔接质量直接决定信号传输稳定性。鼎讯 TY-30H 光纤熔接机作为专为野外严苛工况设计的熔接设备,凭借高效、低耗、耐用的综合性能,成为铁路高速通信施工、日常维护及应急抢修的核心设备。一、鼎讯 TY-30H 光纤…...

2010-2024年省级农村居⺠消费价格指数
本数据为国家统计局编制的官方统计数据,具体编制方法参考国家统计局CPI调查方案及《中国统计年鉴》。农村居民消费价格指数(Consumer Price Index for Rural Residents,简称农村CPI)是综合反映农村居民家庭所购买的生活消费品价格…...

pico示波器采集软件SSL1000A在功率器件测试的应用
在新能源汽车电控体系里,IGBT、MOSFET 是电机控制器、OBC、DC-DC 等核心模块的 “功率开关”,它们的开关特性、瞬态响应、稳定可靠性直接影响整车效率与安全。功率器件测试看似简单,实则细节要求极高,因为器件在高频开关中产生的尖…...

基于DNS的TEE认证革新:原理、实现与性能优化
1. 项目概述:基于DNS的TEE认证革新在云计算安全领域,可信执行环境(TEE)技术正经历着从专用场景向通用基础设施的演进。传统TEE认证方案如RA-TLS存在两个根本性缺陷:一是依赖客户端主动验证硬件证明,导致非T…...

2026年AI大模型API中转站深度测评:谁能成为生产环境下的最优解决方案?
2026年,AI模型的迭代速度进一步加快。从年初在技术社区引起轰动的OpenClaw架构,到GPT - 5.4、Claude 4.6等性能领先的通用模型,再到视频生成领域的Sora2与Veo3,模型之间的竞争愈发激烈。然而,国内开发者在调用这些模型…...
中大孙逸仙纪念医院姚和瑞等团队:多模态数据融合AI模型揭示乳腺癌肿瘤微环境免疫分型异质性与增强的风险分层)
MedComm(IF=10.7)中大孙逸仙纪念医院姚和瑞等团队:多模态数据融合AI模型揭示乳腺癌肿瘤微环境免疫分型异质性与增强的风险分层
01文献学习今天分享的文献是由中大孙逸仙纪念医院姚和瑞等团队于2024年12月在《MedComm》(中科院1区top,IF10.7)上发表的研究“Multimodal data fusion AI model uncovers tumor microenvironment immunotyping heterogeneity and enhanced r…...