史上最全AP、mAP详解与代码实现
文章目录
- 前言
- 一、mAP原理
- 1、mAP概念
- 2、准确率
- 3、精确率
- 4、召回率
- 5、AP: Average Precision
- 二、mAP0.5与mAP0.5:0.95
- 1、mAP0.5
- 2、mAP0.5:0.95
- 三、mAP代码实现
- 1、真实标签json文件格式
- 2、模型预测标签json文件格式
- 3、mAP代码实现
- 4、mAP结果显示
- 四、模型集成mAP代码
- 1、模型main函数
- 2、模型mAP计算代码
前言
我们在深度学习的论文经常看到实验对比指标mAP,比较mAP@0.5与mAP@0.5:0.95指标。然,又有很多博客并未完全说明清楚,特别说结合代码解释该指标。为此,本文章将梳理mAP指标,主要内容分为mAP原理解释,如何使用代码获得mAP指标,进一步探讨如何结合模型而获得mAP指标。
一、mAP原理
1、mAP概念
mAP,其中代表P(Precision)精确率。AP(Average precision)单类标签平均(各个召回率中最大精确率的平均数)的精确率,mAP(Mean Average Precision)所有类标签的平均精确率。
2、准确率
准确率=预测正确的样本数/所有样本数,即预测正确的样本比例(包括预测正确的正样本和预测正确的负样本,不过在目标检测领域,没有预测正确的负样本这一说法,所以目标检测里面没有用Accuracy的)。
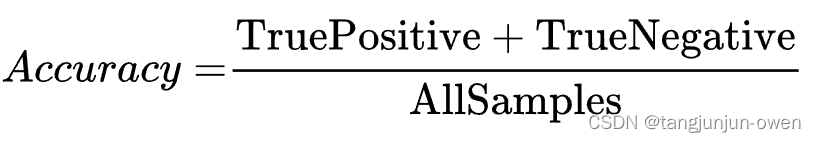
3、精确率
精确率也称查准率,Precision针对的是某一类样本,如果没有说明类别,那么Precision是毫无意义的(有些地方不说明类别,直接说Precision,是因为二分类问题通常说的Precision都是正样本的Precision)。
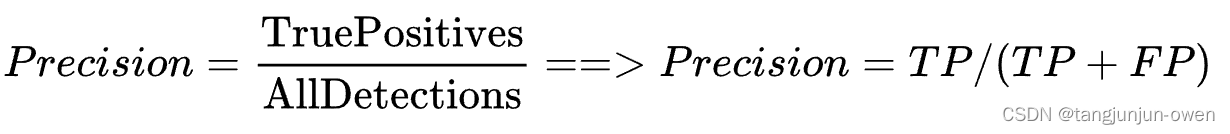
4、召回率
Recall和Precision一样,脱离类别是没有意义的。说道Recall,一定指的是某个类别的Recall。Recall表示某一类样本,预测正确的与所有Ground Truth的比例。
Recall计算的时候,分母是Ground Truth中某一类样本的数量,而Precision计算的时候,是预测出来的某一类样本数。
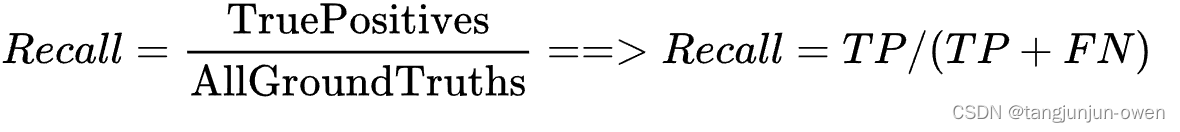
5、AP: Average Precision
AP指单个类别平均精确度,而mAP是所有类别的平均精确度,AP是Precision-Recall Curve曲线下面的面积,以Recall为横轴,Precision为纵轴,就可以画出一条PR曲线,PR曲线下的面积就定义为AP,如下。
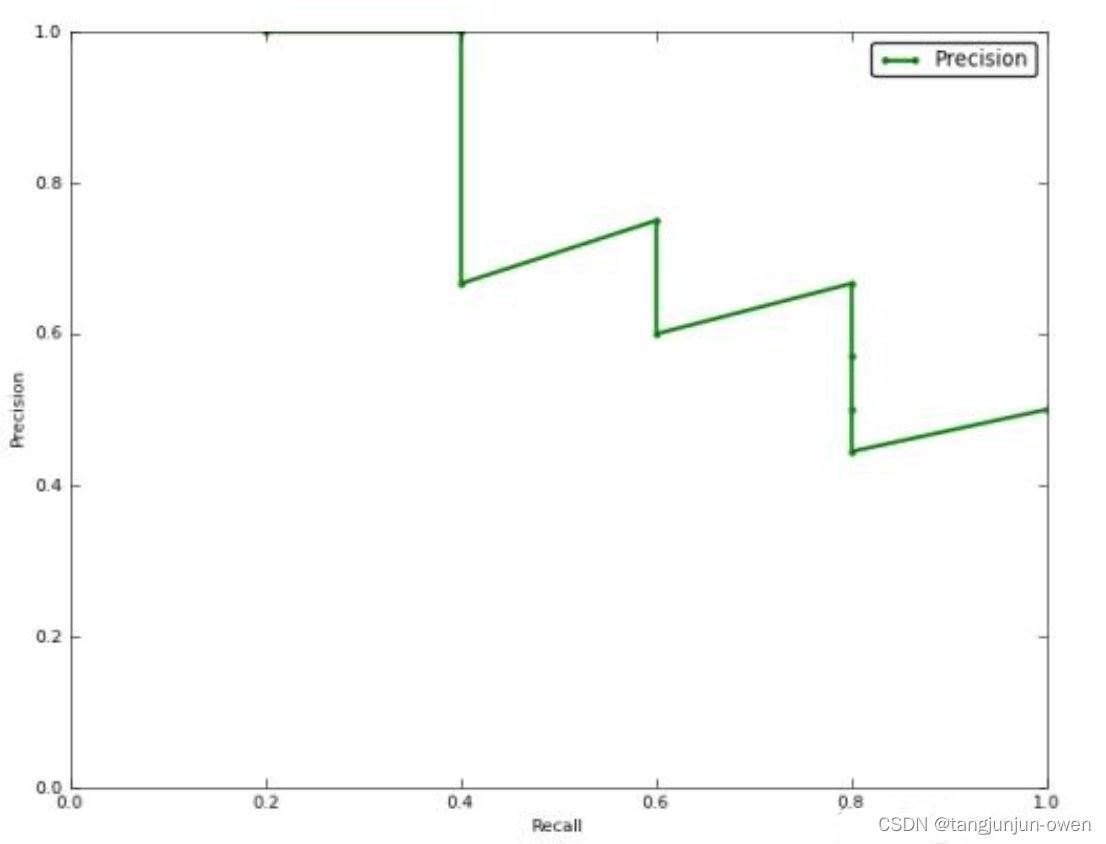
由于计算积分相对困难,因此引入插值法,计算AP公式如下:
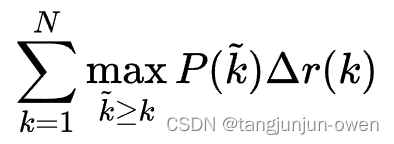
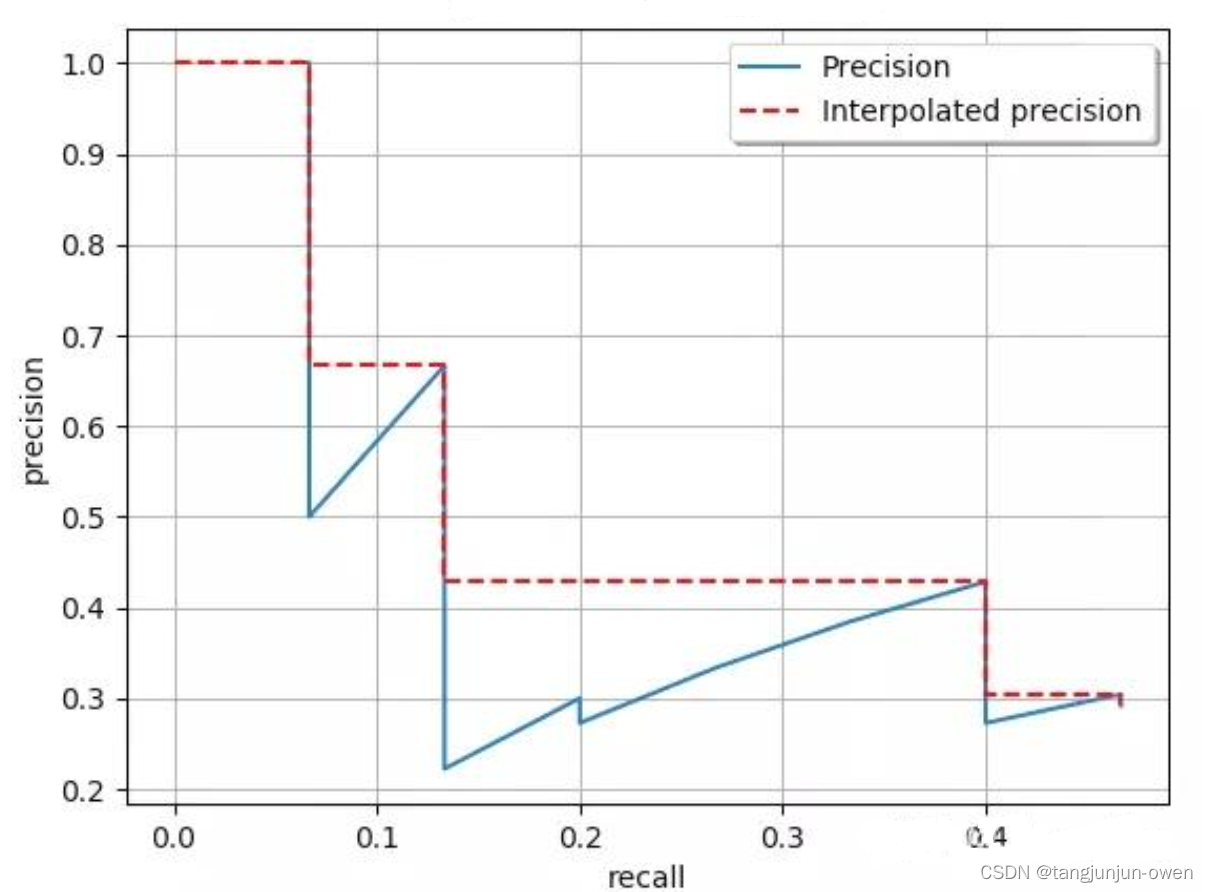
计算面积:
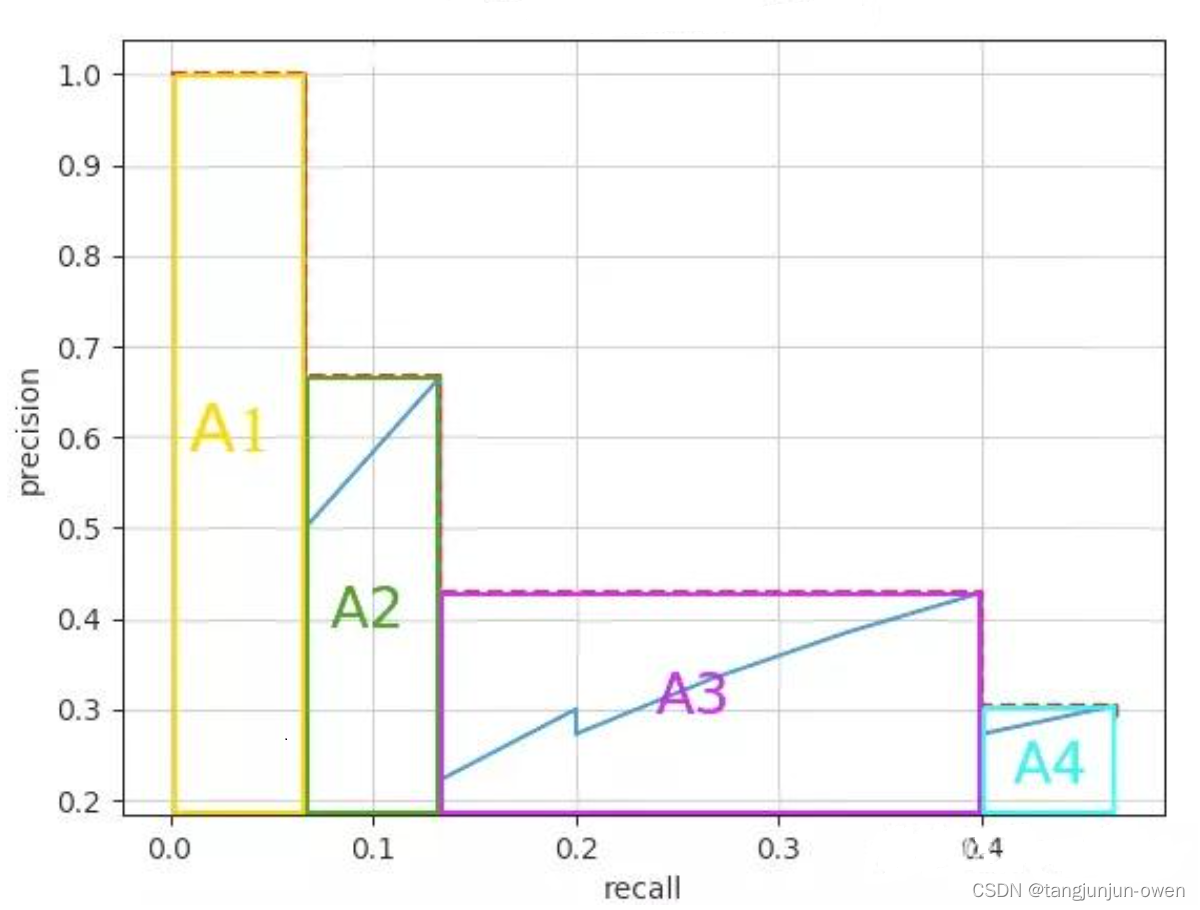
计算方法如下:

二、mAP0.5与mAP0.5:0.95
1、mAP0.5
mAP@0.5: mean Average Precision(IoU=0.5)
即将IoU设为0.5时,计算每一类的所有图片的AP,然后所有类别求平均,即mAP。
2、mAP0.5:0.95
mAP@.5:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
三、mAP代码实现
实现mAP计算,我们需要有已知真实标签与模型预测标签,我将介绍2部分,第一部分如何使用有标记的真实数据产生coco json格式与如何使用模型预测结果产生预测json格式,第二部分如何使用代码计算map。
1、真实标签json文件格式
真实数据json格式实际是coco json 格式,我将以图方式说明。
整体json格式内容,包含images、type、annotations、categories,如下图:

images内容如下图:
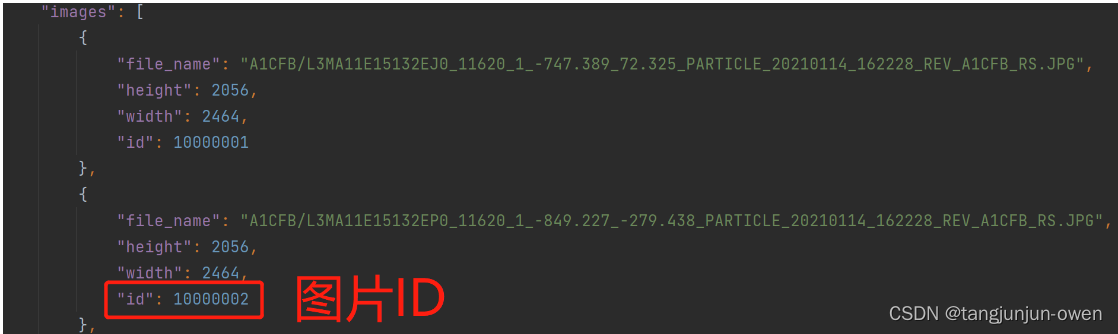
annotations内容如下图:
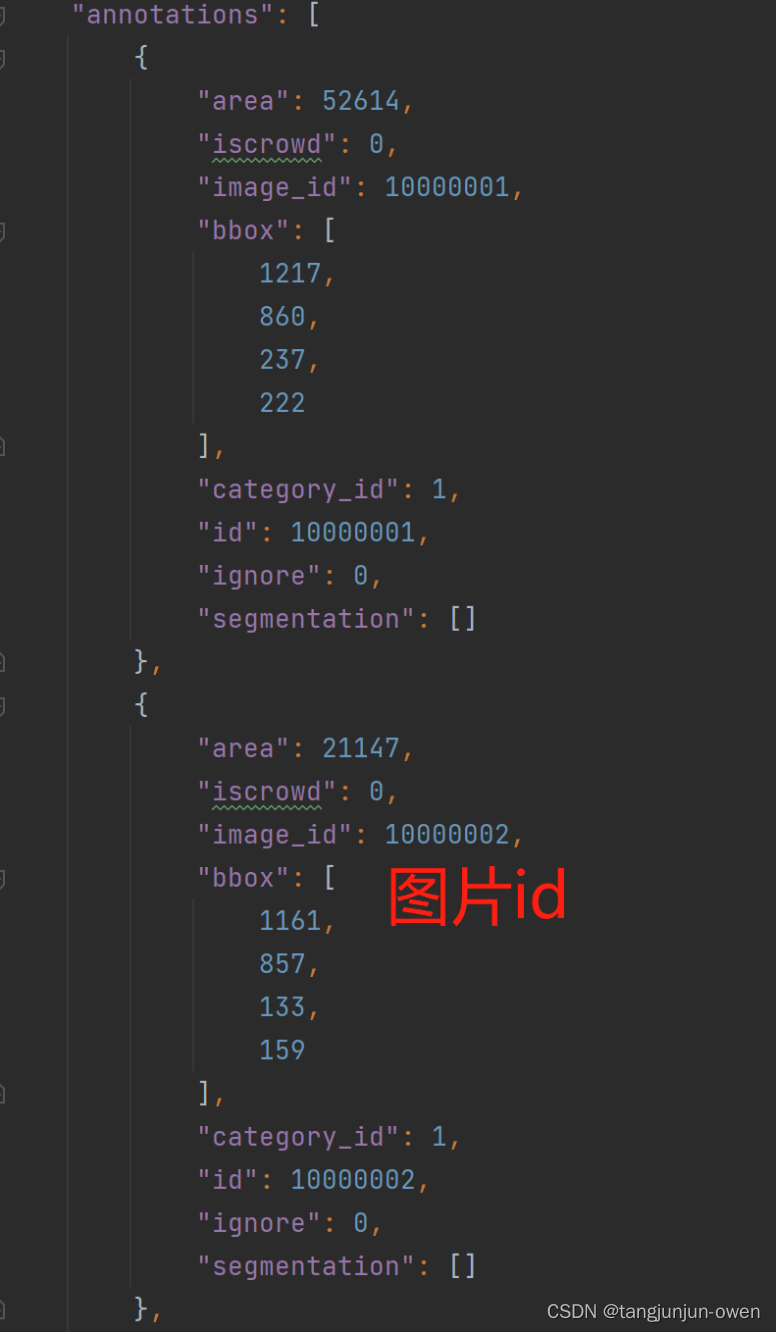
categories格式为:
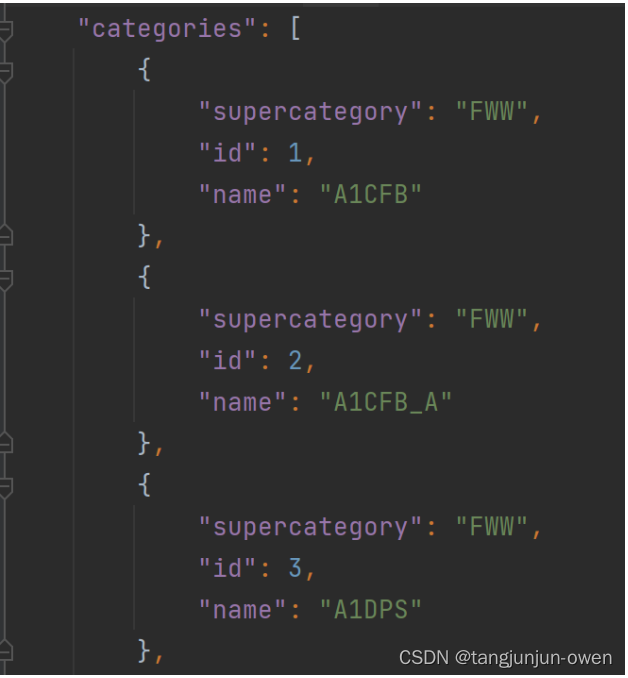
以上为真实数据转换为json的格式。
2、模型预测标签json文件格式
预测结果数据json为列表,列表保存为字典,一个字典记录一个目标,整体json格式如下图:
列表中字典内容如下图显示:
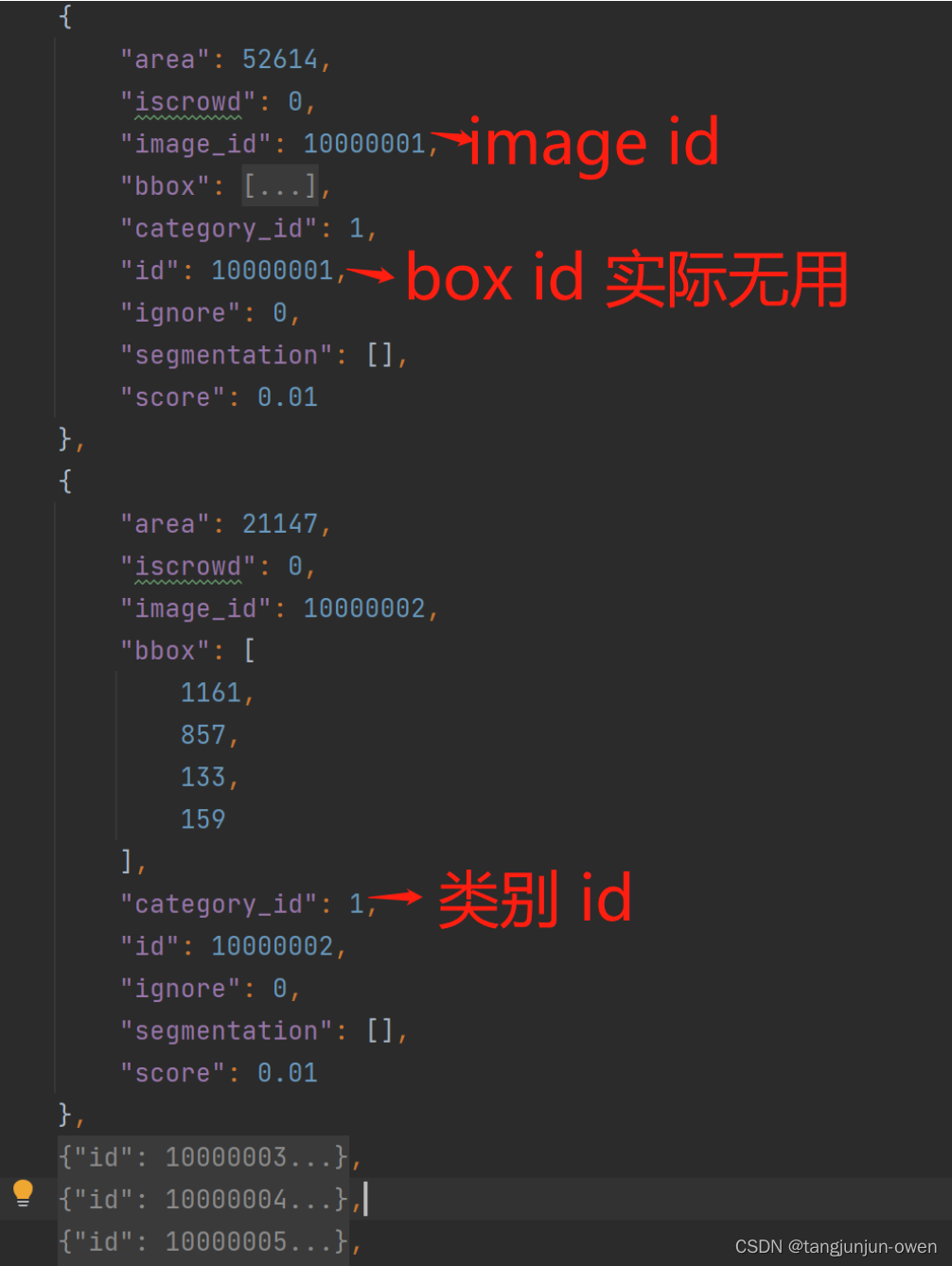
特别注意:image id 对应真实coco json图像的image-id,类别id也是对应真实coco json中的类别id。
3、mAP代码实现
我们调用pycocotool库中集成map方法,按照以上给出gt与pred的json格式,可实现map计算,其详细代码如下:
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOevalif __name__ == "__main__":cocoGt = COCO('coco_json_format.json') #标注文件的路径及文件名,json文件形式cocoDt = cocoGt.loadRes('predect_format.json') #自己的生成的结果的路径及文件名,json文件形式cocoEval = COCOeval(cocoGt, cocoDt, "bbox")cocoEval.evaluate()cocoEval.accumulate()cocoEval.summarize()
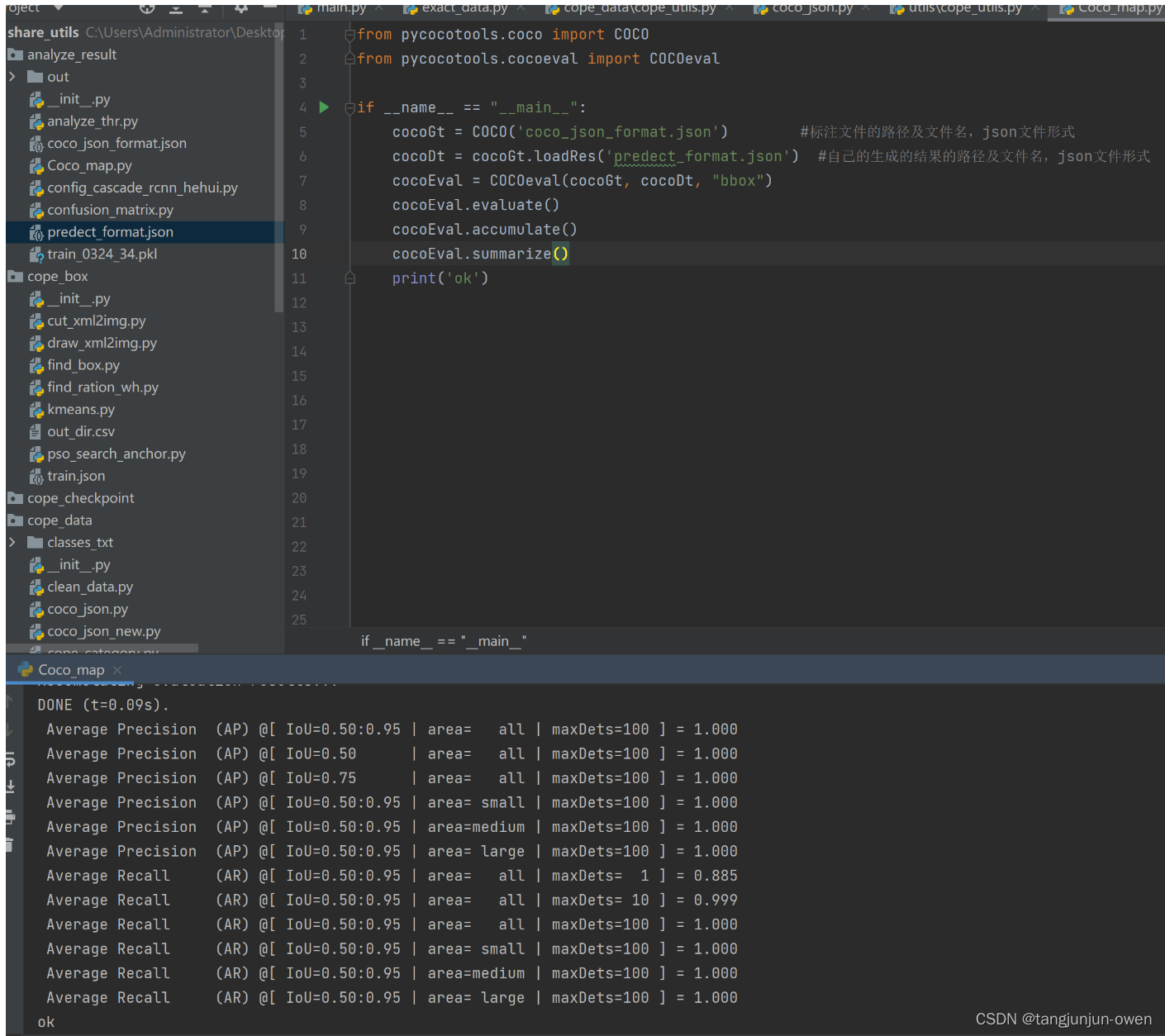
4、mAP结果显示
我使用gt与pred为相同信息,为此结果为1。
四、模型集成mAP代码
最后,我是将mAP代码集成多个检测模型,我也在这里大致介绍如何集成模型预测mAP。
1、模型main函数
以下代码展示,检测模型输出后如何集成Computer_map()函数计算mAP方法,我已在代码中有解释,其详情如下:
def computer_main(data_root, model):'''data_root:任何文件夹,但必须保证每个图片与对应xml必须放在同一个文件夹中model:模型,用于预测'''C = Computer_map()img_root_lst = C.get_img_root_lst(data_root) # 获得图片绝对路径与图片产生image_id映射关系# 在self.coco_json中保存categories,便于产生coco_json和predetect_jsoncategories = model.CLASSES # 可以给txt路径读取,或直接给列表 #*********************得到classes,需要更改的地方***********##C.get_categories(categories)# 产生coco_json格式xml_root_lst = [name[:-3] + 'xml' for name in img_root_lst]for xml_root in xml_root_lst: C.xml2cocojson(xml_root) # 产生coco json 并保存到self.coco_json中# 产生预测的jsonfor img_path in img_root_lst:parse_result = predict(model, img_path) ####**********************需要更改的地方***********************####result, classes = parse_result['result'], parse_result['classes']# restult 格式为列表[x1,y1,x2,y2,score,label],若无结果为空img_name = C.get_strfile(img_path)C.detect2json(result, img_name)C.computer_map() # 计算map
2、模型mAP计算代码
以下代码为Computer_map()函数计算mAP方法,我已在代码中有解释,其详情如下:
class Computer_map():'''主代码样列def computer_main(data_root, model):#data_root:任何文件夹,但必须保证每个图片与对应xml必须放在同一个文件夹中,model:模型,用于预测C = Computer_map()img_root_lst = C.get_img_root_lst(data_root) # 获得图片绝对路径与图片产生image_id映射关系# 在self.coco_json中保存categories,便于产生coco_json和predetect_jsoncategories = model.CLASSES # 可以给txt路径读取,或直接给列表 #*********************得到classes,需要更改的地方***********##C.get_categories(categories)# 产生coco_json格式xml_root_lst = [name[:-3] + 'xml' for name in img_root_lst]for xml_root in xml_root_lst: C.xml2cocojson(xml_root) # 产生coco json 并保存到self.coco_json中# 产生预测的jsonfor img_path in img_root_lst:parse_result = predict(model, img_path) ####**********************需要更改的地方***********************####result, classes = parse_result['result'], parse_result['classes']# restult 格式为列表[x1,y1,x2,y2,score,label],若无结果为空img_name = C.get_strfile(img_path)C.detect2json(result, img_name)C.computer_map() # 计算map'''def __init__(self):self.img_format = ['png', 'jpg', 'JPG', 'PNG', 'bmp', 'jpeg']self.coco_json = {'images': [], 'type': 'instances', 'annotations': [], 'categories': []}self.predetect_json = [] # 保存字典self.image_id = 10000000 # 图像的id,每增加一张图片便+1self.anation_id = 10000000self.imgname_map_id = {} # 图片名字映射iddef read_txt(self, file_path):with open(file_path, 'r') as f:content = f.read().splitlines()return contentdef get_categories(self, categories):'''categories:为字符串,指绝对路径;为列表,指类本身return:将categories存入coco json中'''if isinstance(categories, str):categories = self.read_txt(categories)elif isinstance(categories, list or tuple):categories = list(categories)category_json = [{"supercategory": cat, "id": i + 1, "name": cat} for i, cat in enumerate(categories)]self.coco_json['categories'] = category_jsondef computer_map(self, coco_json_path=None, predetect_json_path=None):from pycocotools.coco import COCOfrom pycocotools.cocoeval import COCOevalfrom collections import defaultdictimport timeimport jsonfrom pycocotools import mask as maskUtilsimport numpy as np# 继承修改coco json文件class COCO_modify(COCO):def __init__(self, coco_json_data=None):"""Constructor of Microsoft COCO helper class for reading and visualizing annotations.:param annotation_file (str): location of annotation file:param image_folder (str): location to the folder that hosts images.:return:"""# load datasetself.dataset, self.anns, self.cats, self.imgs = dict(), dict(), dict(), dict()self.imgToAnns, self.catToImgs = defaultdict(list), defaultdict(list)if coco_json_data is not None:print('loading annotations into memory...')tic = time.time()if isinstance(coco_json_data, str):with open(coco_json_data, 'r') as f:dataset = json.load(f)assert type(dataset) == dict, 'annotation file format {} not supported'.format(type(dataset))print('Done (t={:0.2f}s)'.format(time.time() - tic))else:dataset = coco_json_dataself.dataset = datasetself.createIndex()def loadRes(self, predetect_json_data):import copy"""Load result file and return a result api object.:param resFile (str) : file name of result file:return: res (obj) : result api object"""res = COCO_modify()res.dataset['images'] = [img for img in self.dataset['images']]print('Loading and preparing results...')tic = time.time()if isinstance(predetect_json_data, str):with open(predetect_json_data, 'r') as f:anns = json.load(f)print('Done (t={:0.2f}s)'.format(time.time() - tic))else:anns = predetect_json_dataassert type(anns) == list, 'results in not an array of objects'annsImgIds = [ann['image_id'] for ann in anns]assert set(annsImgIds) == (set(annsImgIds) & set(self.getImgIds())), \'Results do not correspond to current coco set'if 'caption' in anns[0]:imgIds = set([img['id'] for img in res.dataset['images']]) & set([ann['image_id'] for ann in anns])res.dataset['images'] = [img for img in res.dataset['images'] if img['id'] in imgIds]for id, ann in enumerate(anns):ann['id'] = id + 1elif 'bbox' in anns[0] and not anns[0]['bbox'] == []:res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])for id, ann in enumerate(anns):bb = ann['bbox']x1, x2, y1, y2 = [bb[0], bb[0] + bb[2], bb[1], bb[1] + bb[3]]if not 'segmentation' in ann:ann['segmentation'] = [[x1, y1, x1, y2, x2, y2, x2, y1]]ann['area'] = bb[2] * bb[3]ann['id'] = id + 1ann['iscrowd'] = 0elif 'segmentation' in anns[0]:res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])for id, ann in enumerate(anns):# now only support compressed RLE format as segmentation resultsann['area'] = maskUtils.area(ann['segmentation'])if not 'bbox' in ann:ann['bbox'] = maskUtils.toBbox(ann['segmentation'])ann['id'] = id + 1ann['iscrowd'] = 0elif 'keypoints' in anns[0]:res.dataset['categories'] = copy.deepcopy(self.dataset['categories'])for id, ann in enumerate(anns):s = ann['keypoints']x = s[0::3]y = s[1::3]x0, x1, y0, y1 = np.min(x), np.max(x), np.min(y), np.max(y)ann['area'] = (x1 - x0) * (y1 - y0)ann['id'] = id + 1ann['bbox'] = [x0, y0, x1 - x0, y1 - y0]print('DONE (t={:0.2f}s)'.format(time.time() - tic))res.dataset['annotations'] = annsres.createIndex()return rescoco_json_data = coco_json_path if coco_json_path is not None else self.coco_jsoncocoGt = COCO_modify(coco_json_data) # 标注文件的路径及文件名,json文件形式predetect_json_data = predetect_json_path if predetect_json_path is not None else self.predetect_jsoncocoDt = cocoGt.loadRes(predetect_json_data) # 自己的生成的结果的路径及文件名,json文件形式cocoEval = COCOeval(cocoGt, cocoDt, "bbox")cocoEval.evaluate()cocoEval.accumulate()cocoEval.summarize()def get_img_root_lst(self, root_data):import osimg_root_lst = []for dir, file, names in os.walk(root_data):img_lst = [os.path.join(dir, name) for name in names if name[-3:] in self.img_format]img_root_lst = img_root_lst + img_lstfor na in img_lst: # 图片名字映射image_idself.image_id += 1self.imgname_map_id[self.get_strfile(na)] = self.image_idreturn img_root_lst # 得到图片绝对路径def get_strfile(self, file_str, pos=-1):'''得到file_str / or \\ 的最后一个名称'''endstr_f_filestr = file_str.split('\\')[pos] if '\\' in file_str else file_str.split('/')[pos]return endstr_f_filestrdef read_xml(self, xml_root):''':param xml_root: .xml文件:return: dict('cat':['cat1',...],'bboxes':[[x1,y1,x2,y2],...],'whd':[w ,h,d])'''import xml.etree.ElementTree as ETimport osdict_info = {'cat': [], 'bboxes': [], 'box_wh': [], 'whd': []}if os.path.splitext(xml_root)[-1] == '.xml':tree = ET.parse(xml_root) # ET是一个xml文件解析库,ET.parse()打开xml文件。parse--"解析"root = tree.getroot() # 获取根节点whd = root.find('size')whd = [int(whd.find('width').text), int(whd.find('height').text), int(whd.find('depth').text)]xml_filename = root.find('filename').textdict_info['whd'] = whddict_info['xml_filename'] = xml_filenamefor obj in root.findall('object'): # 找到根节点下所有“object”节点cat = str(obj.find('name').text) # 找到object节点下name子节点的值(字符串)bbox = obj.find('bndbox')x1, y1, x2, y2 = [int(bbox.find('xmin').text),int(bbox.find('ymin').text),int(bbox.find('xmax').text),int(bbox.find('ymax').text)]b_w = x2 - x1 + 1b_h = y2 - y1 + 1dict_info['cat'].append(cat)dict_info['bboxes'].append([x1, y1, x2, y2])dict_info['box_wh'].append([b_w, b_h])else:print('[inexistence]:{} suffix is not xml '.format(xml_root))return dict_infodef xml2cocojson(self, xml_root):'''处理1个xml,将其真实json保存到self.coco_json中'''assert len(self.coco_json['categories']) > 0, 'self.coco_json[categories] must exist v'categories = [cat_info['name'] for cat_info in self.coco_json['categories']]xml_info = self.read_xml(xml_root)if len(xml_info['cat']) > 0:xml_filename = xml_info['xml_filename']xml_name = self.get_strfile(xml_root)img_name = xml_name[:-3] + xml_filename[-3:]# 转为coco json时候,若add_file为True则在coco json文件的file_name增加文件夹名称+图片名字image_id = self.imgname_map_id[img_name]w, h, d = xml_info['whd']# 构建json文件字典image_json = {'file_name': img_name, 'height': h, 'width': w, 'id': image_id}ann_json = []for i, category in enumerate(xml_info['cat']):# 表示有box存在,可以添加images信息category_id = categories.index(category) + 1 # 给出box对应标签索引为类self.anation_id = self.anation_id + 1xmin, ymin, xmax, ymax = xml_info['bboxes'][i]o_width, o_height = xml_info['box_wh'][i]if (xmax <= xmin) or (ymax <= ymin):print('code:[{}] will be abandon due to {} min of box w or h more than max '.format(category,xml_root)) # 打印错误的boxelse:ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id': image_id,'bbox': [xmin, ymin, o_width, o_height],'category_id': category_id, 'id': self.anation_id, 'ignore': 0,'segmentation': []}ann_json.append(ann)if len(ann_json) > 0: # 证明存在 annotationfor ann in ann_json: self.coco_json['annotations'].append(ann)self.coco_json['images'].append(image_json)def detect2json(self, predetect_result, img_name,score_thr=-1):'''predetect_result:为列表,每个列表中包含[x1, y1, x2, y2, score, label]img_name: 图片的名字'''if len(predetect_result) > 0:categories = [cat_info['name'] for cat_info in self.coco_json['categories']]for result in predetect_result:x1, y1, x2, y2, score, label = resultif score>score_thr:w, h = int(x2 - x1), int(y2 - y1)x1, y1 = int(x1), int(y1)img_name_new = self.get_strfile(img_name)image_id = self.imgname_map_id[img_name_new]category_id = list(categories).index(label) + 1detect_json = {"area": w * h,"iscrowd": 0,"image_id": image_id,"bbox": [x1,y1,w,h],"category_id": category_id,"id": image_id,"ignore": 0,"segmentation": [],"score": score}self.predetect_json.append(detect_json)def write_json(self,out_dir):import osimport jsoncoco_json_path=os.path.join(out_dir,'coco_json_data.json')with open(coco_json_path, 'w') as f:json.dump(self.coco_json, f, indent=4) # indent表示间隔长度predetect_json_path=os.path.join(out_dir,'predetect_json_data.json')with open(predetect_json_path, 'w') as f:json.dump(self.predetect_json, f, indent=4) # indent表示间隔长度
原理参考博客点击这里
相关文章:
史上最全AP、mAP详解与代码实现
文章目录 前言一、mAP原理1、mAP概念2、准确率3、精确率4、召回率5、AP: Average Precision 二、mAP0.5与mAP0.5:0.951、mAP0.52、mAP0.5:0.95 三、mAP代码实现1、真实标签json文件格式2、模型预测标签json文件格式3、mAP代码实现4、mAP结果显示 四、模型集成mAP代码1、模型mai…...

百数应用中心——生产制造管理解决方案解决行业难题
传统生产制造业面临着许多挑战,其中一些主要问题包括效率低下、交期压力大、需求预测不准确、生产模式复杂、异常响应慢、库存高和计划脱节等。这些问题不仅影响了生产效率和质量,也导致了不必要的成本和客户满意度下降。 生产制造管理应用对于企业的生产…...
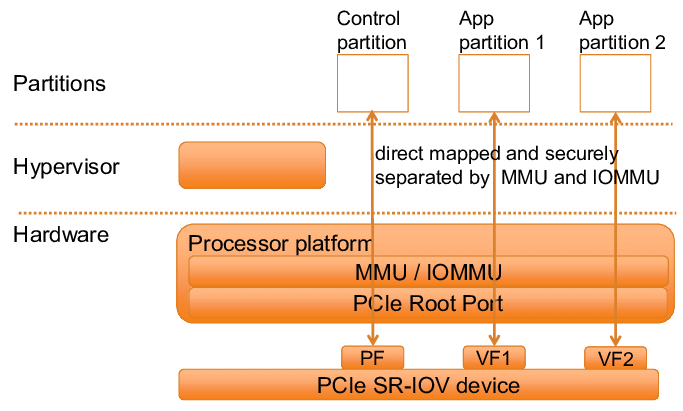
《存储IO路径》专题:IO虚拟化初探
大家好,欢迎来到今天的科技小课堂。今天我们要聊聊的是一项非常有趣且实用的技术——I/O虚拟化(Input/Output Virtualization,简称IOV)。想象一下,如果把物理硬件资源比作一道丰盛的大餐,那么IOV就是那位神…...
Springboot2.0快速入门(第一章)
目录 一,SpringBoot简介1.1,回顾什么是Spring1.2,Spring是如何简化Java开发的1.3,什么是SpringBoot 二,Hello,World2.1,准备工作2.2,创建基础项目说明2.3,创建第一个Hell…...
:PyFlink DataStream API之StreamExecutionEnvironment)
Flink流批一体计算(17):PyFlink DataStream API之StreamExecutionEnvironment
目录 StreamExecutionEnvironment Watermark watermark策略简介 使用 Watermark 策略 内置水印生成器 处理空闲数据源 算子处理 Watermark 的方式 创建DataStream的方式 通过list对象创建 使用DataStream connectors创建 使用Table & SQL connectors…...

javeee spring cglib动态代理
cglib动态代理 依赖 <dependency><groupId>cglib</groupId><artifactId>cglib-nodep</artifactId><version>3.2.4</version></dependency>代理类 package com.test.cglibProxy;import net.sf.cglib.proxy.Enhancer; import …...

【Docker】Dockerfile介绍
Dockerfile是一个文本文件,其中包含了一系列的指令,用于构建Docker镜像。这些指令可以用来自动化镜像的构建过程,并创建自定义镜像。 以下是一些常用的Dockerfile指令及其功能: FROM:指定基础镜像。这是Dockerfile中…...

两个hdfs之间迁移传输数据
本文参考其他大数据大牛的博文做了整理和实际验证,主要解决hdfs跨集群复制/迁移问题。 在hdfs数据迁移时总会涉及到两个hdfs版本版本问题,致力解决hdfs版本相同和不同两种情况的处理方式,长话短说,进正文。 distcp: hadoop自带的…...

C++ 缺失的数字
有n个数字,值就是1~n,现发现丢失了2个数字,请你根据剩余的n-2个数字,编程计算一下,缺失的是哪两个数字呢? (使用桶排,标记输入过的数字) #include<bits/stdc.h> us…...
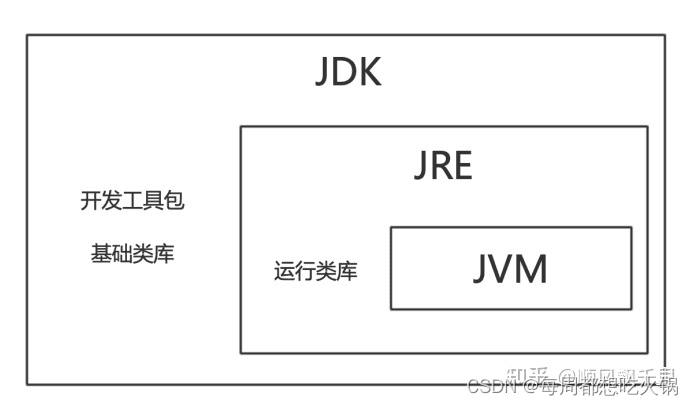
JVM,JRE和JDK的区别
JVM,JRE和JDK的区别 JVM(Java Virtual Machine,Java虚拟机)JREJRE目录结构 JDK JVM(Java Virtual Machine,Java虚拟机) Java程序的跨平台特性主要是指字节码文件可以在任何具有Java虚拟机的计算机或者电子设备上运行,Java虚拟机中…...
合宙Air724UG LuatOS-Air LVGL API控件--日历 (Calendar)
日历 (Calendar) LVGL 提供了一个用来选择和显示当前日期的日历控件。 示例代码 – 高亮显示的日期 highlightDate lvgl.calendar_date_t() – 日历点击的回调函数 – 将点击日期设置高亮 function event_handler(obj, event) if event lvgl.EVENT_VALUE_CHANGED then da…...

[python]问题:pandas处理excel里的多个sheet
Pandas 可以很容易地处理 Excel 文件中的多个工作表。首先,你需要安装 pandas 和 openpyxl(用于读取 .xlsx 文件)库。你可以使用以下命令安装这两个库: pip install pandas openpyxl接下来,你可以使用以下代码来处理 Excel 文件中的多个工作表: import pandas as pd# 读…...

[MySQL] MySQL基础操作汇总
文章目录 前言1.数据库概述1.1 数据库相关概念1.2登录MySQL:1.3 MySQL常用命令1.4表:1.5SQL语句分类: 2.CRUD操作2.1 DQL1.基础查询基础查询(简单查询)条件查询:排序查询:分组查询:分…...

C语言每日一题 ---- 打印从1到最大的n位数(Day 1)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C语言天天练 &#x…...

2023-08-23 LeetCode每日一题(统计点对的数目)
2023-08-23每日一题 一、题目编号 1782. 统计点对的数目二、题目链接 点击跳转到题目位置 三、题目描述 给你一个无向图,无向图由整数 n ,表示图中节点的数目,和 edges 组成,其中 edges[i] [ui, vi] 表示 ui 和 vi 之间有一…...
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略 目录 SQLCoder的简介 1、结果 2、按问题类别的结果 SQLCoder的安装 1、硬件要求 2、下载模型权重 3、使用SQLCoder 4、Colab中运行SQLCoder 第一步,配置环境 第二步,测试 第…...

数学建模(四)整数规划—匈牙利算法
目录 一、0-1型整数规划问题 1.1 案例 1.2 指派问题的标准形式 2.2 非标准形式的指派问题 二、指派问题的匈牙利解法 2.1 匈牙利解法的一般步骤 2.2 匈牙利解法的实例 2.3 代码实现 一、0-1型整数规划问题 1.1 案例 投资问题: 有600万元投资5个项目&…...

openGauss学习笔记-47 openGauss 高级数据管理-权限
文章目录 openGauss学习笔记-47 openGauss 高级数据管理-权限47.1 语法格式47.2 参数说明47.3 示例 openGauss学习笔记-47 openGauss 高级数据管理-权限 数据库对象创建后,进行对象创建的用户就是该对象的所有者。数据库安装后的默认情况下,未开启三权分…...
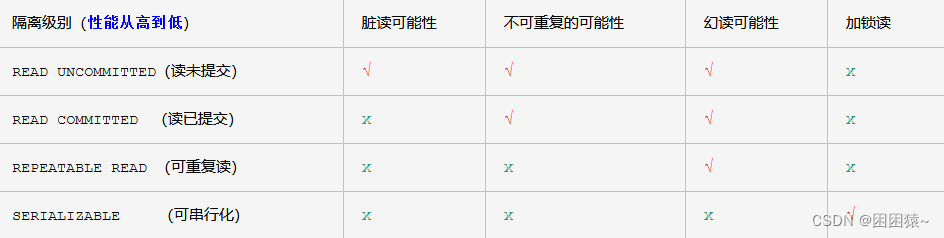
开始MySQL之路——MySQL 事务(详解分析)
MySQL 事务概述 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等…...

注解和class对象和mysql
注解 override 通常是用在方法上的注解表示该方法是有重写的 interface 表示一个注解类 比如 public interface override{} 这就表示是override是一个注解类 target 修饰注解的注解表示元注解 deprecated 修饰某个元素表示该元素已经过时了 1.不代表该元素不能用了&…...

Agent史上最全八股,来啦!
涉及到 RAG、MCP、Skills 等 12 个方向,共计 200 多个问题。 因为最近一段时间,我越来越明显地感觉到,前端 AI 方面的面试已经越来越倾向语 AI 化了。 以前很多同学去面试,面试官问的还是比较浅的东西。 你用过哪些大模型…...

基于MCP协议为AI智能体赋予本地桌面自动化能力
1. 项目概述:为AI智能体赋予“手和眼”的桌面操作技能如果你正在使用像Cursor、Claude Code或Codex这类AI编程助手,可能会发现一个痛点:它们能帮你写代码、分析问题,但无法直接操作你的电脑。你想让它帮你打开一个软件、填写一个表…...

大语言模型与强化学习融合:从理论到DPO实践指南
1. 项目概述:当强化学习遇上大语言模型 最近在整理自己过去一年读过的论文,发现一个非常有意思的趋势:大语言模型和强化学习的交叉研究,正在以一种前所未有的速度爆发。这不仅仅是学术界的热点,更是工业界试图将LLM从“…...

亲测分享!优豆云免费资源助力我的小站起飞,还有惊喜优惠
大家好呀! 最近一直在捣鼓自己的个人小项目和博客,对于像我这样的新手来说,成本控制是首要考虑的问题。偶然间发现了 优豆云 这个宝藏平台 (https://www.udouyun.com),简直是为我们这些预算有限但又想练手、展示创意的朋友量身定做…...

深圳汽车救援公司有哪些
行业痛点分析在深圳这座现代化大都市中,汽车已成为市民出行的重要工具。然而,随之而来的汽车救援问题也日益凸显。当前,汽车救援领域面临的技术挑战主要包括响应速度慢、救援效率低、服务范围有限等问题。据数据表明,深圳市内每天…...

如何快速掌握星穹铁道抽卡数据分析工具:专业玩家的终极指南
如何快速掌握星穹铁道抽卡数据分析工具:专业玩家的终极指南 【免费下载链接】star-rail-warp-export Honkai: Star Rail Warp History Exporter 项目地址: https://gitcode.com/gh_mirrors/st/star-rail-warp-export 星穹铁道跃迁记录导出工具是一款专为《崩…...

DSub:Android平台上最完整的Subsonic音乐客户端指南
DSub:Android平台上最完整的Subsonic音乐客户端指南 【免费下载链接】Subsonic Home of the DSub Android client fork 项目地址: https://gitcode.com/gh_mirrors/su/Subsonic DSub是一款专为Android设备设计的开源Subsonic客户端,让您能够随时随…...

USB IP设计演进与FinFET工艺挑战解析
1. USB IP设计的技术演进背景USB(通用串行总线)从1996年首次发布至今,已成为现代电子设备不可或缺的核心接口标准。作为一位从事芯片设计15年的工程师,我亲眼见证了USB IP从最初的简单外设连接到如今支持10Gbps高速传输的完整技术…...

FDS火灾模拟完整指南:从零开始掌握建筑消防安全分析
FDS火灾模拟完整指南:从零开始掌握建筑消防安全分析 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 你是否曾想知道火灾发生时,烟雾如何在建筑中扩散?或者如何科学评估人员疏散的安全…...

算法融合自动紧急制动控制策略【附程序】
✨ 长期致力于自动紧急制动、路面识别、模糊算法、模型预测控制、联合仿真研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于模糊逻辑的路面附着系数…...