Flink流批一体计算(17):PyFlink DataStream API之StreamExecutionEnvironment
目录
StreamExecutionEnvironment
Watermark
watermark策略简介
使用 Watermark 策略
内置水印生成器
处理空闲数据源
算子处理 Watermark 的方式
创建DataStream的方式
通过list对象创建
使用DataStream connectors创建
使用Table & SQL connectors创建
StreamExecutionEnvironment
编写一个 Flink Python DataStream API 程序,首先需要声明一个执行环境StreamExecutionEnvironment,这是流式程序执行的上下文。
你将通过它来设置作业的属性(例如默认并发度、重启策略等)、创建源、并最终触发作业的执行。
env = StreamExecutionEnvironment.get_execution_environment()
env.set_runtime_mode(RuntimeExecutionMode.BATCH)
env.set_parallelism(1)创建了 StreamExecutionEnvironment 之后,你可以使用它来声明数据源。数据源从外部系统(如 Apache Kafka、Rabbit MQ 或 Apache Pulsar)拉取数据到 Flink 作业里。
为了简单起见,本教程读取文件作为数据源。
ds = env.from_source(source=FileSource.for_record_stream_format(StreamFormat.text_line_format(),input_path).process_static_file_set().build(),watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),source_name="file_source"
)Watermark
大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
为了解决乱序数据,flink引入watermark。引入watermark机制则会等待晚到的数据一段时间,等待时间到则触发计算,如果数据延迟很大,通常也会被丢弃或者另外处理。
为了使用事件时间语义,Flink 应用程序需要知道事件时间戳对应的字段,意味着数据流中的每个元素都需要拥有可分配的事件时间戳。其通常通过使用 TimestampAssigner API 从元素中的某个字段去访问/提取时间戳。
watermark策略简介
时间戳的分配与 watermark 的生成是齐头并进的,其可以告诉 Flink 应用程序事件时间的进度。其可以通过指定 WatermarkGenerator 来配置 watermark 的生成方式。
使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy。WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,并且用户也可以在某些必要场景下构建自己的 watermark 策略。
使用 Watermark 策略
WatermarkStrategy 可以在 Flink 应用程序中的两处使用,第一种是直接在数据源上使用,第二种是直接在非数据源的操作之后使用。
第一种方式相比会更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确。直接在源上指定 WatermarkStrategy 意味着你必须使用特定数据源接口。
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy)
内置水印生成器
水印策略定义了如何在流源中生成水印。WatermarkStrategy是生成水印的WatermarkGenerator和分配记录内部时间戳的TimestampAssigner的生成器/工厂。
BoundedOutOfOrderness(Duration),为创建WatermarkStrategy常见的内置策略。
for_bound_out_of_ordernness(max_out_of_orderness:pyflink.common.time.Duration)为记录无序的情况创建水印策略,但可以设置事件无序程度的上限。
无序绑定B意味着一旦遇到时间戳为T的事件,就不会再出现早于(T-B)的事件。
for_bound_out_of_ordernness(5)
for_mononous_timestamps()为时间戳单调递增的情况创建水印策略。
水印是定期生成的,并严格遵循数据中的最新时间戳。该策略引入的延迟主要是生成水印的周期间隔。
WatermarkStrategy.for_monotonous_timestamps()
with_timestamp_assigner(timestamp_assigner:pyflink.common.watermark_strategy.TimestampAssigner)
创建一个新的WatermarkStrategy,该策略通过实现TimestampAssigner接口使用给定的TimestampAssigner。
参数: timestamp_assigner 给定的TimestampAssigner。
Return: 包装TimestampAssigner的WaterMarkStrategy。
watermark_strategy = WatermarkStrategy.for_monotonous_timestamps()
with_timestamp_assigner(MyTimestampAssigner())
处理空闲数据源
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark。我们称这类数据源为空闲输入或空闲源。在这种情况下,当某些其他分区仍然发送事件数据的时候就会出现问题。由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化。
为了解决这个问题,你可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态。WatermarkStrategy 为此提供了一个工具接口withIdleness(Duration.ofMinutes(1))
with_idleness(idle_timeout:pyfrink.common.time.Duration)
创建一个新的丰富的WatermarkStrategy,它也在创建的WatermarkGenerator中执行空闲检测。
参数:idle_timeout–空闲超时。
Return:配置了空闲检测的新水印策略。
算子处理 Watermark 的方式
一般情况下,在将 watermark 转发到下游之前,需要算子对其进行触发的事件完全进行处理。例如,WindowOperator 将首先计算该 watermark 触发的所有窗口数据,当且仅当由此 watermark 触发计算进而生成的所有数据被转发到下游之后,其才会被发送到下游。换句话说,由于此 watermark 的出现而产生的所有数据元素都将在此 watermark 之前发出。
相同的规则也适用于 TwoInputstreamOperator。但是,在这种情况下,算子当前的 watermark 会取其两个输入的最小值。
创建DataStream的方式
通过list对象创建
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
ds = env.from_collection(collection=[(1, 'aaa|bb'), (2, 'bb|a'), (3, 'aaa|a')],type_info=Types.ROW([Types.INT(), Types.STRING()]))使用DataStream connectors创建
使用add_source函数,此函数仅支持FlinkKafkaConsumer,仅在streaming执行模式下使用
from pyflink.common.serialization import JsonRowDeserializationSchema
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import FlinkKafkaConsumerenv = StreamExecutionEnvironment.get_execution_environment()
# the sql connector for kafka is used here as it's a fat jar and could avoid dependency issues
env.add_jars("file:///path/to/flink-sql-connector-kafka.jar")
deserialization_schema = JsonRowDeserializationSchema.builder() \.type_info(type_info=Types.ROW([Types.INT(), Types.STRING()])).build()kafka_consumer = FlinkKafkaConsumer(topics='test_source_topic',deserialization_schema=deserialization_schema,properties={'bootstrap.servers': 'localhost:9092', 'group.id': 'test_group'})ds = env.add_source(kafka_consumer)使用from_source函数,此函数仅支持NumberSequenceSource和FileSource自定义数据源,仅在streaming执行模式下使用
from pyflink.common.typeinfo import Types
from pyflink.common.watermark_strategy import WatermarkStrategy
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import NumberSequenceSourceenv = StreamExecutionEnvironment.get_execution_environment()
seq_num_source = NumberSequenceSource(1, 1000)
ds = env.from_source(source=seq_num_source,watermark_strategy=WatermarkStrategy.for_monotonous_timestamps(),source_name='seq_num_source',type_info=Types.LONG())使用Table & SQL connectors创建
首先用Table & SQL connectors创建表,再转换为DataStream.
from pyflink.common.typeinfo import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironmentenv = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(stream_execution_environment=env)t_env.execute_sql("""CREATE TABLE my_source (a INT,b VARCHAR) WITH ('connector' = 'datagen','number-of-rows' = '10')""")ds = t_env.to_append_stream(t_env.from_path('my_source'),Types.ROW([Types.INT(), Types.STRING()]))相关文章:
:PyFlink DataStream API之StreamExecutionEnvironment)
Flink流批一体计算(17):PyFlink DataStream API之StreamExecutionEnvironment
目录 StreamExecutionEnvironment Watermark watermark策略简介 使用 Watermark 策略 内置水印生成器 处理空闲数据源 算子处理 Watermark 的方式 创建DataStream的方式 通过list对象创建 使用DataStream connectors创建 使用Table & SQL connectors…...

javeee spring cglib动态代理
cglib动态代理 依赖 <dependency><groupId>cglib</groupId><artifactId>cglib-nodep</artifactId><version>3.2.4</version></dependency>代理类 package com.test.cglibProxy;import net.sf.cglib.proxy.Enhancer; import …...

【Docker】Dockerfile介绍
Dockerfile是一个文本文件,其中包含了一系列的指令,用于构建Docker镜像。这些指令可以用来自动化镜像的构建过程,并创建自定义镜像。 以下是一些常用的Dockerfile指令及其功能: FROM:指定基础镜像。这是Dockerfile中…...

两个hdfs之间迁移传输数据
本文参考其他大数据大牛的博文做了整理和实际验证,主要解决hdfs跨集群复制/迁移问题。 在hdfs数据迁移时总会涉及到两个hdfs版本版本问题,致力解决hdfs版本相同和不同两种情况的处理方式,长话短说,进正文。 distcp: hadoop自带的…...

C++ 缺失的数字
有n个数字,值就是1~n,现发现丢失了2个数字,请你根据剩余的n-2个数字,编程计算一下,缺失的是哪两个数字呢? (使用桶排,标记输入过的数字) #include<bits/stdc.h> us…...
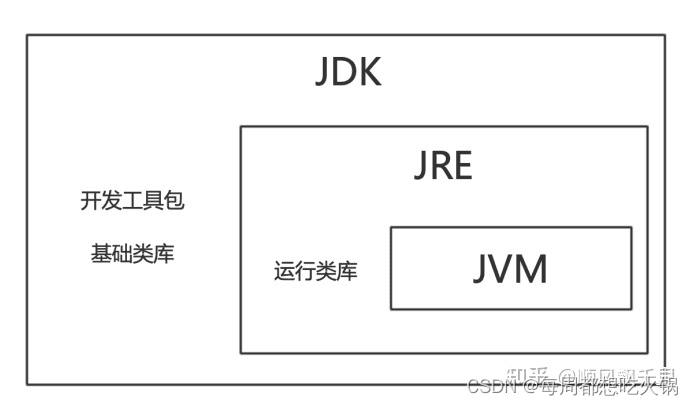
JVM,JRE和JDK的区别
JVM,JRE和JDK的区别 JVM(Java Virtual Machine,Java虚拟机)JREJRE目录结构 JDK JVM(Java Virtual Machine,Java虚拟机) Java程序的跨平台特性主要是指字节码文件可以在任何具有Java虚拟机的计算机或者电子设备上运行,Java虚拟机中…...
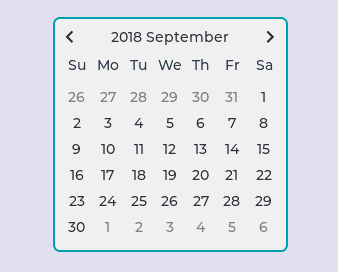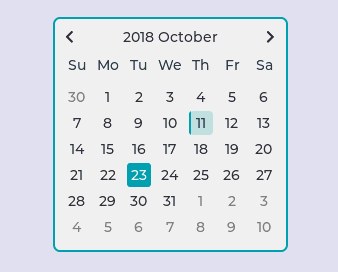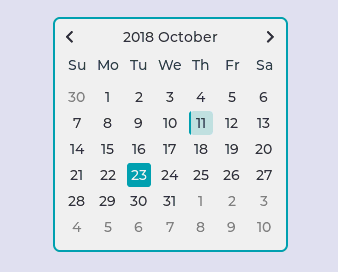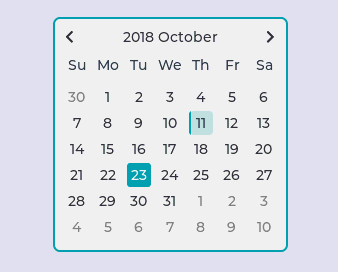
合宙Air724UG LuatOS-Air LVGL API控件--日历 (Calendar)
日历 (Calendar) LVGL 提供了一个用来选择和显示当前日期的日历控件。 示例代码 – 高亮显示的日期 highlightDate lvgl.calendar_date_t() – 日历点击的回调函数 – 将点击日期设置高亮 function event_handler(obj, event) if event lvgl.EVENT_VALUE_CHANGED then da…...

[python]问题:pandas处理excel里的多个sheet
Pandas 可以很容易地处理 Excel 文件中的多个工作表。首先,你需要安装 pandas 和 openpyxl(用于读取 .xlsx 文件)库。你可以使用以下命令安装这两个库: pip install pandas openpyxl接下来,你可以使用以下代码来处理 Excel 文件中的多个工作表: import pandas as pd# 读…...

[MySQL] MySQL基础操作汇总
文章目录 前言1.数据库概述1.1 数据库相关概念1.2登录MySQL:1.3 MySQL常用命令1.4表:1.5SQL语句分类: 2.CRUD操作2.1 DQL1.基础查询基础查询(简单查询)条件查询:排序查询:分组查询:分…...

C语言每日一题 ---- 打印从1到最大的n位数(Day 1)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C语言天天练 &#x…...

2023-08-23 LeetCode每日一题(统计点对的数目)
2023-08-23每日一题 一、题目编号 1782. 统计点对的数目二、题目链接 点击跳转到题目位置 三、题目描述 给你一个无向图,无向图由整数 n ,表示图中节点的数目,和 edges 组成,其中 edges[i] [ui, vi] 表示 ui 和 vi 之间有一…...
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略
LLMs之Code:SQLCoder的简介、安装、使用方法之详细攻略 目录 SQLCoder的简介 1、结果 2、按问题类别的结果 SQLCoder的安装 1、硬件要求 2、下载模型权重 3、使用SQLCoder 4、Colab中运行SQLCoder 第一步,配置环境 第二步,测试 第…...

数学建模(四)整数规划—匈牙利算法
目录 一、0-1型整数规划问题 1.1 案例 1.2 指派问题的标准形式 2.2 非标准形式的指派问题 二、指派问题的匈牙利解法 2.1 匈牙利解法的一般步骤 2.2 匈牙利解法的实例 2.3 代码实现 一、0-1型整数规划问题 1.1 案例 投资问题: 有600万元投资5个项目&…...

openGauss学习笔记-47 openGauss 高级数据管理-权限
文章目录 openGauss学习笔记-47 openGauss 高级数据管理-权限47.1 语法格式47.2 参数说明47.3 示例 openGauss学习笔记-47 openGauss 高级数据管理-权限 数据库对象创建后,进行对象创建的用户就是该对象的所有者。数据库安装后的默认情况下,未开启三权分…...
开始MySQL之路——MySQL 事务(详解分析)
MySQL 事务概述 MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等…...

注解和class对象和mysql
注解 override 通常是用在方法上的注解表示该方法是有重写的 interface 表示一个注解类 比如 public interface override{} 这就表示是override是一个注解类 target 修饰注解的注解表示元注解 deprecated 修饰某个元素表示该元素已经过时了 1.不代表该元素不能用了&…...
【桌面小屏幕项目】ESP32开发环境搭建
视频教程链接: 【【有手就行系列】嵌入式单片机教程-桌面小屏幕实战教学 从设计、硬件、焊接到代码编写、调试 ESP32 持续更新2022】 https://www.bilibili.com/video/BV1wV4y1G7Vk/?share_sourcecopy_web&vd_source4fa5fad39452b08a8f4aa46532e890a7 一、esp…...

CSS 滚动容器与固定 Tabbar 自适应的几种方式
问题 容器高度使用 px 定高时,随着页面高度发生变化,组件展示的数量不能最大化的铺满,导致出现底部留白。容器高度使用 vw 定高时,随着页面宽度发生变化,组件展示的数量不能最大化的铺满,导致出现底部留白…...

IP 地址追踪工具
IP 地址跟踪工具是一种网络实用程序,允许您扫描、跟踪和获取详细信息,例如 IP 地址的 MAC 和接口 ID。IP 跟踪解决方案通过使用不同的网络扫描协议来检查网络地址空间来收集这些详细信息。一些高级 IP 地址跟踪器软件(如 OpUtils)…...

最新企业网盘产品推荐榜发布
随着数字化发展,传统的文化存储方式已无法跟上企业发展的步伐。云存储的出现为企业提供了新的文件管理存储模式。企业网盘作为云存储的代表性工具,被越来越多的企业所青睐。那么在众多企业网盘产品中,企业该如何找到合适的企业网盘呢…...

AI智能体安全审计实战:构建可插拔的安全技能库
1. 项目概述:一个面向AI智能体的安全审计技能库最近在折腾AI智能体(Agent)的开发,发现一个挺有意思的现象:大家把大量精力都花在了让智能体“更聪明”上,比如提升其推理能力、扩展工具调用范围,…...

【maaath】 Flutter for OpenHarmony 饮水水质监测应用开发实战
Flutter for OpenHarmony 饮水水质监测应用开发实战欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 作者:maaath一、引言 随着人们对健康饮水的关注度日益提升,水质监测已成为日常生活中不可或缺的一部分。无论是家庭…...

一文讲透编程基础的3大核心模块,新手入门再也不迷茫
文章目录前言一、数据结构:程序的骨架,没有它代码就是一盘散沙1.1 为什么AI写的代码你改不动?因为你不懂数据结构1.2 新手必学的5个核心数据结构,多一个都不用先学(1)数组:最基础也最重要的数据…...

pico示波器采集软件SSL1000A在功率器件测试的应用
在新能源汽车电控体系里,IGBT、MOSFET 是电机控制器、OBC、DC-DC 等核心模块的 “功率开关”,它们的开关特性、瞬态响应、稳定可靠性直接影响整车效率与安全。功率器件测试看似简单,实则细节要求极高,因为器件在高频开关中产生的尖…...

ARM异常级别与系统寄存器访问控制机制解析
1. ARM异常级别与系统寄存器访问控制机制解析在ARMv8/v9架构中,异常级别(Exception Level)构成了处理器权限管理的核心框架。这个分层保护机制从EL0(用户应用程序)延伸到EL3(安全监控模式),每个级别都有明确…...

1985~2025年各省市区县不同土地覆盖类型的土地面积
各省市区县不同土地覆盖类型的土地面积原始数据为栅格数据:「The 30m annual land cover datasets and its dynamics in China from 1985 to 2025」土地覆被类型包括 9 种,具体为:Barren(裸地)、Cropland(耕…...

《2026 年生成电商主图最好的 5 个软件,实测后我只留了这几款》
做电商 5 年,从淘宝做到亚马逊,我用过的主图设计工具不下 20 款。2026 年 AI 工具爆发后,很多老软件其实已经被淘汰了。这篇把我目前还在用的 5 款整理出来,都是真金白银测过的,不是广告。先说结论:如果你只看一句话——想一键出主图详情页全套:选潮际好麦只做白底主图:选佐糖要…...

【ElevenLabs情绪模拟技术深度解密】:20年AI语音工程师亲测的5大情感建模陷阱与避坑指南
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术深度解密 ElevenLabs 的情绪模拟并非简单调节语调或语速,而是通过多维度声学特征建模——包括基频(F0)动态包络、能量分布、共振峰偏移、微停…...

收藏!小白程序员必看:如何成为AI大模型应用开发工程师,解锁高薪新机遇?
AI大模型应用开发工程师是连接技术与产业的关键角色,负责将复杂AI技术转化为实用工具。他们需分析业务需求、选择适配技术、开发对接应用,并进行测试优化与运维。这一职业因“技术业务”复合能力稀缺,薪资待遇优厚,是当前极具吸引…...

还在手动逐帧做抖音视频转文字?2026年这5款工具,1分钟搞定万字转写省3小时
开完2小时部门会,你留下来对着录音逐句整理纪要,3小时过去才敲了一半;做内容博主转抖音口播脚本,手动逐帧倒放听,耳机戴得耳朵疼,错字还一堆;访谈完嘉宾,几小时的录音要赶稿子&#…...