flink on yarn with kerberos 边缘提交
flink on yarn 带kerberos 远程提交 实现
- flink kerberos 配置
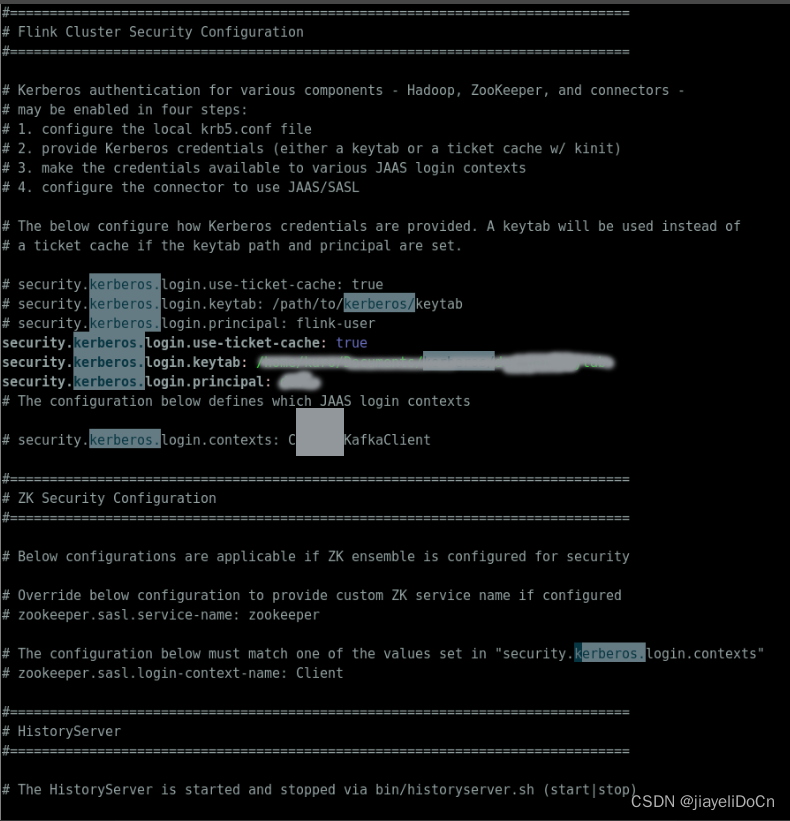
- 先使用ugi进行一次认证
- 正常提交
import com.google.common.io.Files;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.apache.flink.client.cli.CliFrontend;
import org.apache.flink.client.cli.CustomCommandLine;
import org.apache.flink.client.cli.DefaultCLI;
import org.apache.flink.client.cli.GenericCLI;
import org.apache.flink.client.deployment.ClusterDeploymentException;
import org.apache.flink.client.deployment.ClusterSpecification;
import org.apache.flink.client.deployment.application.ApplicationConfiguration;
import org.apache.flink.client.program.ClusterClientProvider;
import org.apache.flink.configuration.*;
import org.apache.flink.runtime.security.SecurityConfiguration;
import org.apache.flink.runtime.security.SecurityUtils;
import org.apache.flink.util.ExceptionUtils;
import org.apache.flink.yarn.YarnClientYarnClusterInformationRetriever;
import org.apache.flink.yarn.YarnClusterDescriptor;
import org.apache.flink.yarn.YarnClusterInformationRetriever;
import org.apache.flink.yarn.configuration.YarnConfigOptions;
import org.apache.flink.yarn.configuration.YarnDeploymentTarget;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hadoop.yarn.api.records.ApplicationId;
import org.apache.hadoop.yarn.client.api.YarnClient;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
import org.junit.Test;import java.io.File;
import java.io.IOException;
import java.lang.reflect.Constructor;
import java.lang.reflect.UndeclaredThrowableException;
import java.net.MalformedURLException;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;import static org.apache.flink.util.Preconditions.checkNotNull;/**
* @author: jiayeli.cn
* @description
* @date: 2023/8/29 下午9:09
*/@Slf4j
public class YarnClientTestCase {@Testpublic void submitJobWithYarnDesc() throws ClusterDeploymentException, IOException {// hadoopString hadoopConfDir = "/x/x/software/spark-3.3.2-bin-hadoop3/etc/hadoop";//flink的本地配置目录,为了得到flink的配置String flinkConfDir = "/opt/flink-1.14.3/conf";//存放flink集群相关的jar包目录String flinkLibs = "hdfs://node01:8020/lib/flink";//用户jarString userJarPath = "hdfs://node01:8020/jobs/streaming/testCase/TopSpeedWindowing.jar";String flinkDistJar = "hdfs://node01:8020/lib/flink/flink-dist_2.12-1.14.3.jar";String[] args = "".split("\\s+");String appMainClass = "org.apache.flink.streaming.examples.windowing.TopSpeedWindowing";String principal = "dev@JIAYELI.COM";String keyTab = "/x/x/workspace/bigdata/sparkLauncherTestcase/src/test/resource/dev_uer.keytab";enableKrb5(principal, keyTab);YarnClient yarnClient = YarnClient.createYarnClient();YarnConfiguration yarnConfiguration = new YarnConfiguration();Optional.ofNullable(hadoopConfDir).map(e -> new File(e)).filter(dir -> dir.exists()).map(File::listFiles).ifPresent(files -> {Arrays.asList(files).stream().filter(file -> Files.getFileExtension(file.getName()).equals(".xml")).forEach(conf -> yarnConfiguration.addResource(conf.getPath()));});yarnClient.init(yarnConfiguration);yarnClient.start();Configuration flinkConf = GlobalConfiguration.loadConfiguration(flinkConfDir);//set run modelflinkConf.setString(DeploymentOptions.TARGET, YarnDeploymentTarget.APPLICATION.getName());//set application nameflinkConf.setString(YarnConfigOptions.APPLICATION_NAME, "onYarnApiSubmitCase");//flink on yarn dependencyflinkConf.set(YarnConfigOptions.PROVIDED_LIB_DIRS, Collections.singletonList(new Path(flinkLibs).toString()));flinkConf.set(YarnConfigOptions.FLINK_DIST_JAR, flinkDistJar);flinkConf.set(PipelineOptions.JARS, Collections.singletonList(new Path(userJarPath).toString()));//设置:资源/并发度flinkConf.setInteger(CoreOptions.DEFAULT_PARALLELISM, 1);flinkConf.set(JobManagerOptions.TOTAL_PROCESS_MEMORY, MemorySize.parse("1G"));flinkConf.set(TaskManagerOptions.TOTAL_PROCESS_MEMORY, MemorySize.parse("1G"));flinkConf.setInteger(TaskManagerOptions.NUM_TASK_SLOTS, 1);ClusterSpecification clusterSpecification = new ClusterSpecification.ClusterSpecificationBuilder().setMasterMemoryMB(1024).setTaskManagerMemoryMB(1024).setSlotsPerTaskManager(2).createClusterSpecification();YarnClusterInformationRetriever ycir = YarnClientYarnClusterInformationRetriever.create(yarnClient);YarnConfiguration yarnConf = (YarnConfiguration) yarnClient.getConfig();ApplicationConfiguration appConfig = new ApplicationConfiguration(args, appMainClass);YarnClusterDescriptor yarnClusterDescriptor = new YarnClusterDescriptor(flinkConf,yarnConf,yarnClient,ycir,false);ClusterClientProvider<ApplicationId> applicationCluster =yarnClusterDescriptor.deployApplicationCluster( clusterSpecification, appConfig );yarnClient.stop();}private void enableKrb5(String principal, String keyTab) throws IOException {System.setProperty("java.security.krb5.conf", "/x/x/Documents/kerberos/krb5.conf");org.apache.hadoop.conf.Configuration krb5conf = new org.apache.hadoop.conf.Configuration();String krb5ConfPath = "/x/x/Documents/kerberos/krb5.conf";krb5conf.set("hadoop.security.authentication", "kerberos");// UserGroupInformation.setConfiguration(conf)UserGroupInformation.setConfiguration(krb5conf);// 登录Kerberos并获取UserGroupInformation实例UserGroupInformation.loginUserFromKeytab(principal, keyTab);UserGroupInformation ugi = UserGroupInformation.getCurrentUser();log.debug(ugi.toString());}
相关文章:
flink on yarn with kerberos 边缘提交
flink on yarn 带kerberos 远程提交 实现 flink kerberos 配置 先使用ugi进行一次认证正常提交 import com.google.common.io.Files; import lombok.extern.slf4j.Slf4j; import org.apache.commons.io.FileUtils; import org.apache.flink.client.cli.CliFrontend; import o…...
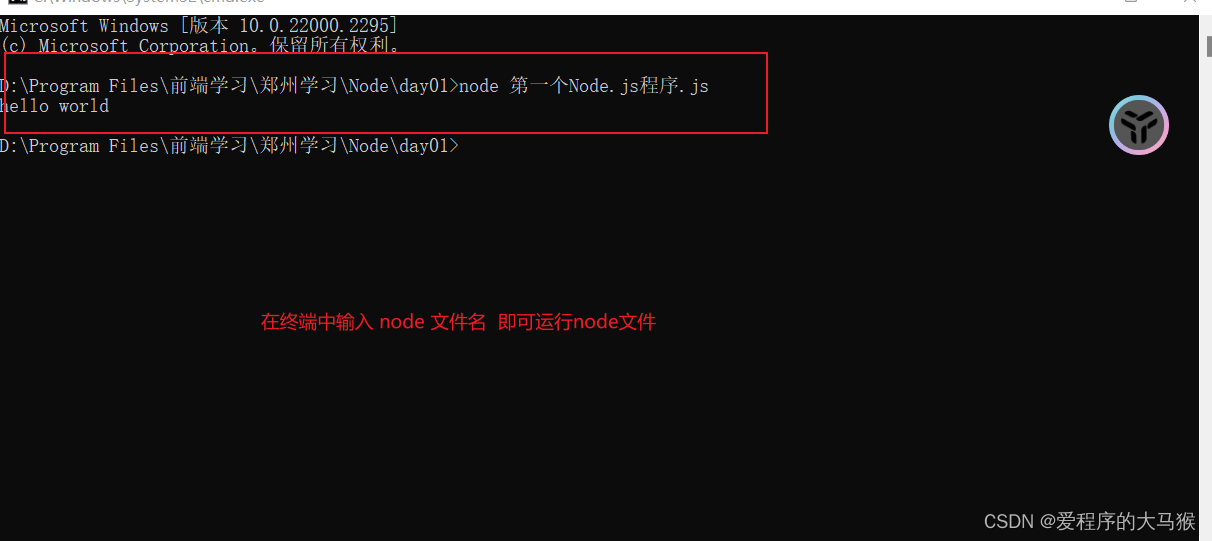
NodeJS的简介以及下载和安装
本章节会带大家下载并安装NodeJs 以及简单的入门,配有超详细的图片,一步步带大家进行下载与安装 NodeJs简介关于前端与后端Node是什么?为什么要学习NodeNodeJS的优点: NodeJS的下载与安装NodeJS的下载: NodeJS的快速入…...

量化面试-概率题
文章目录 一、题目1.糖果罐(绿皮书79页)2 折木棍(绿皮书89页)3 第一张ACE(绿皮书95页)4 n个均匀分布之和(绿皮书95页) 二、答案1. 糖果罐2 折木棍3 第一张ACE4 n个均匀分布之和 一、…...

【spark】java类在spark中的传递,scala object在spark中的传递
记录一个比较典型的问题,先讲一下背景,有这么一个用java写的类 public class JavaClass0 implements Serializable {private static String name;public static JavaClass0 getName(String str) {if (name null) {namestr;}return name;}... }然后在sp…...

php 文字生成图片保存到本地
你可以使用PHP的GD库来生成图片并保存到本地。首先,你需要确保你的PHP环境已经安装了GD库。然后,你可以使用GD库的函数来创建一个画布,并在上面绘制文字。最后,使用imagepng或imagejpeg函数将画布保存为PNG或JPEG格式的图片文件。…...

面试手撕—二叉搜索树及其后序遍历
一、引言 在面试地平线的时候,聊到了二叉搜索树,让手撕二叉搜索树,以下是要求 1、用类模板实现二叉搜索树 2、写一个函数,实现给一个vector数组,转换成二叉搜索树 3、写出二叉搜索树的后序遍历 二、代码实现 #inc…...

Java数据结构面试题以及答案
本专栏记录Java后端开发相关的面试题,欢迎大家阅读专栏的其他文章。 目录 1.B树和B树的区别?B树和B树的优点分别是? 2.排序算法的种类和复杂度 3.HashMap和Hashtable的原理、区别、应用场景 4.ConcurrentHashMap的原理、应用场景 5.Arra…...
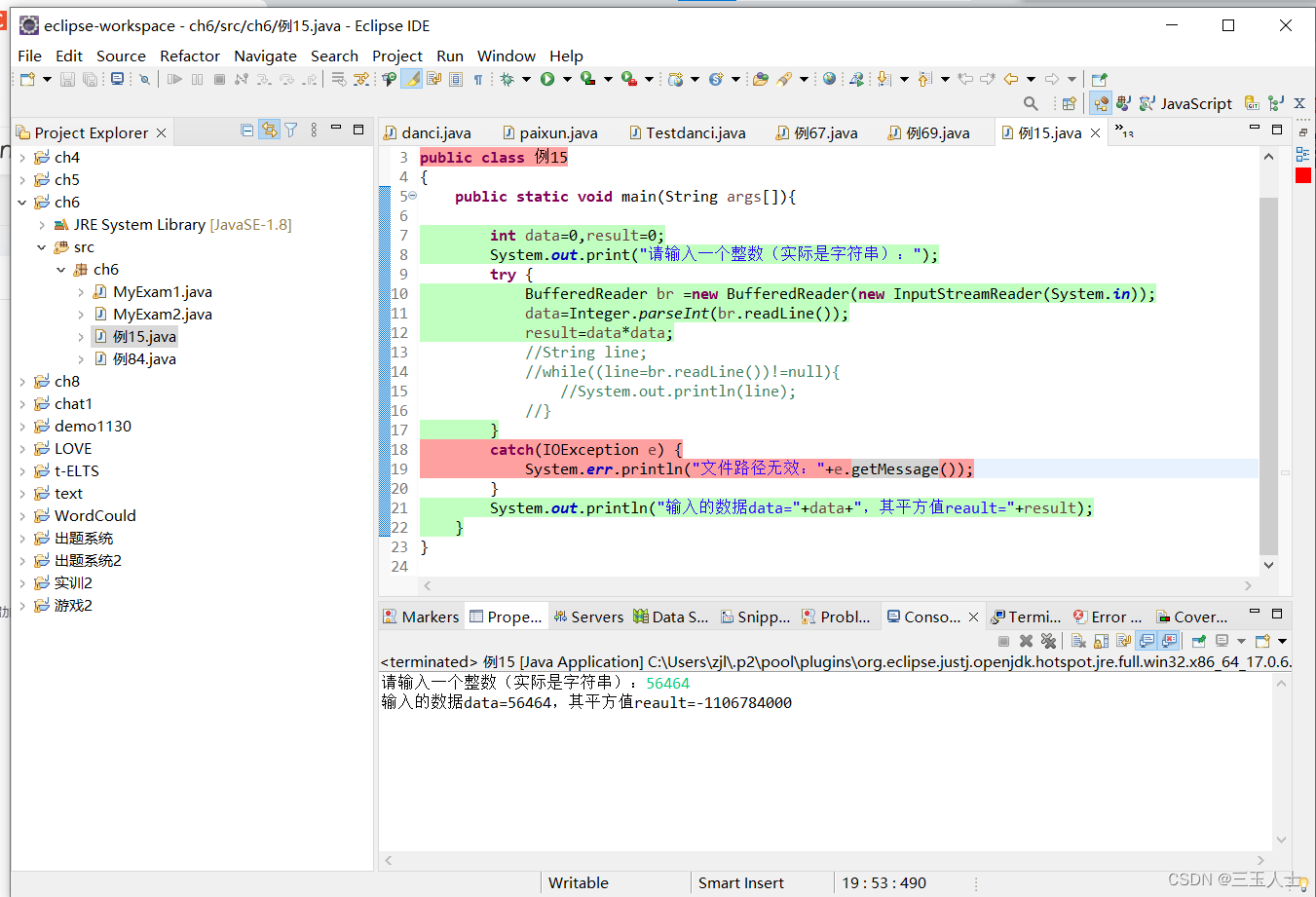
Java——它要求用户输入一个整数(实际上是一个字符串),然后计算该整数的平方值,并将结果输出。
这是一个Java程序,它要求用户输入一个整数(实际上是一个字符串),然后计算该整数的平方值,并将结果输出。程序的基本流程如下: 首先,声明并初始化变量data和result,它们的初始值都为…...

【科研论文配图绘制】task6直方图绘制
【科研论文配图绘制】task6直方图绘制 task6 主要掌握直方图的绘制技巧,了解直方图含义,清楚统计指标的添加方式 1.直方图 直方图是一种用于表示数据分布和离散情况的统计图形,它的外观和柱形图相近,但它所 表达的含义和柱形图…...

Leetcode刷题:395. 至少有 K 个重复字符的最长子串、823. 带因子的二叉树
Leetcode刷题:395. 至少有 K 个重复字符的最长子串、823. 带因子的二叉树 1. 395. 至少有 K 个重复字符的最长子串算法思路参考代码和运行结果 2. 823. 带因子的二叉树算法思路参考代码和运行结果 1. 395. 至少有 K 个重复字符的最长子串 题目难度:中等 标签&#…...
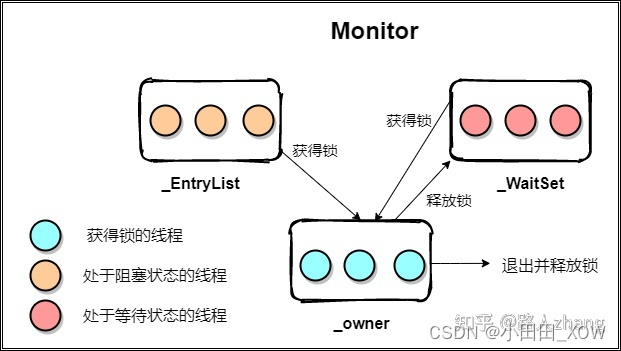
java八股文面试[多线程]——Synchronized的底层实现原理
笔试:画出Synchronized 线程状态流转实现原理图 synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized 翻译为中文的意思是同步,也称之为”同步锁“。 synchronized的作用是保证在同一时刻, 被修饰的代码块或方…...
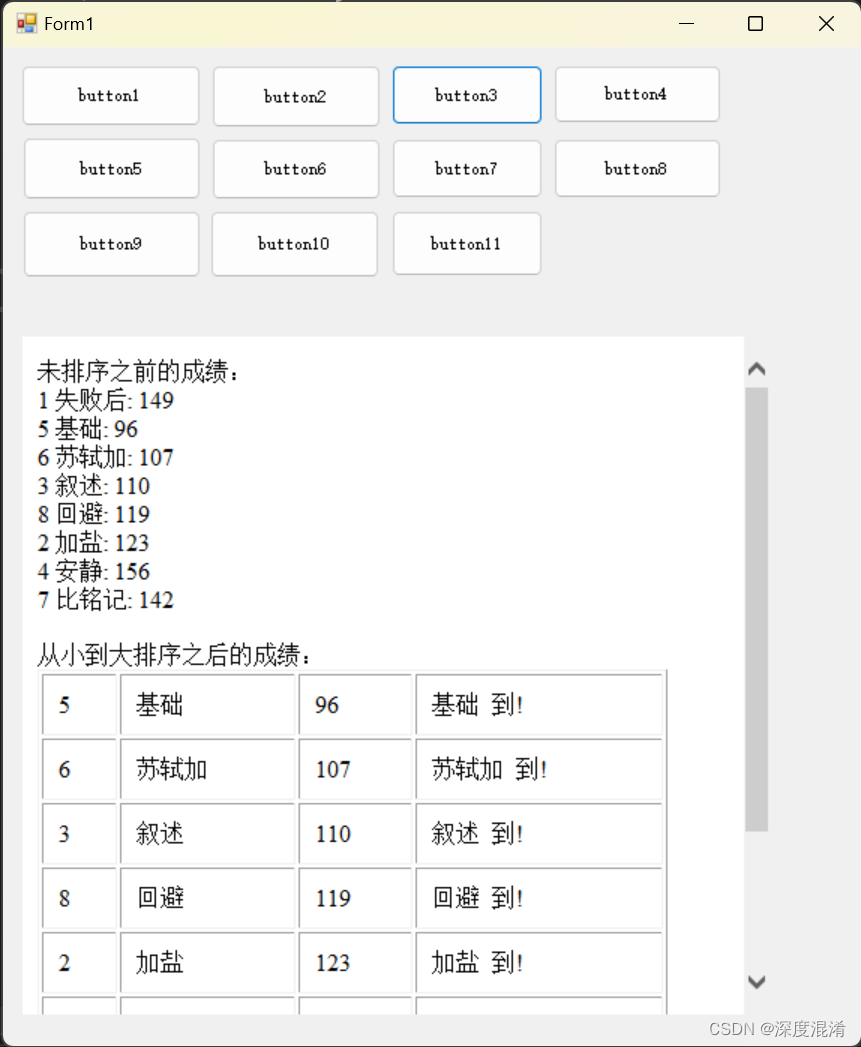
C#,《小白学程序》第三课:类、类数组与排序
类class把数值与功能巧妙的进行了结合,是编程技术的主要进步。 下面的程序你可以确立 分数 与 姓名 之间关系,并排序。 1 文本格式 /// <summary> /// 同学信息类 /// </summary> public class Classmate { /// <summary> /…...
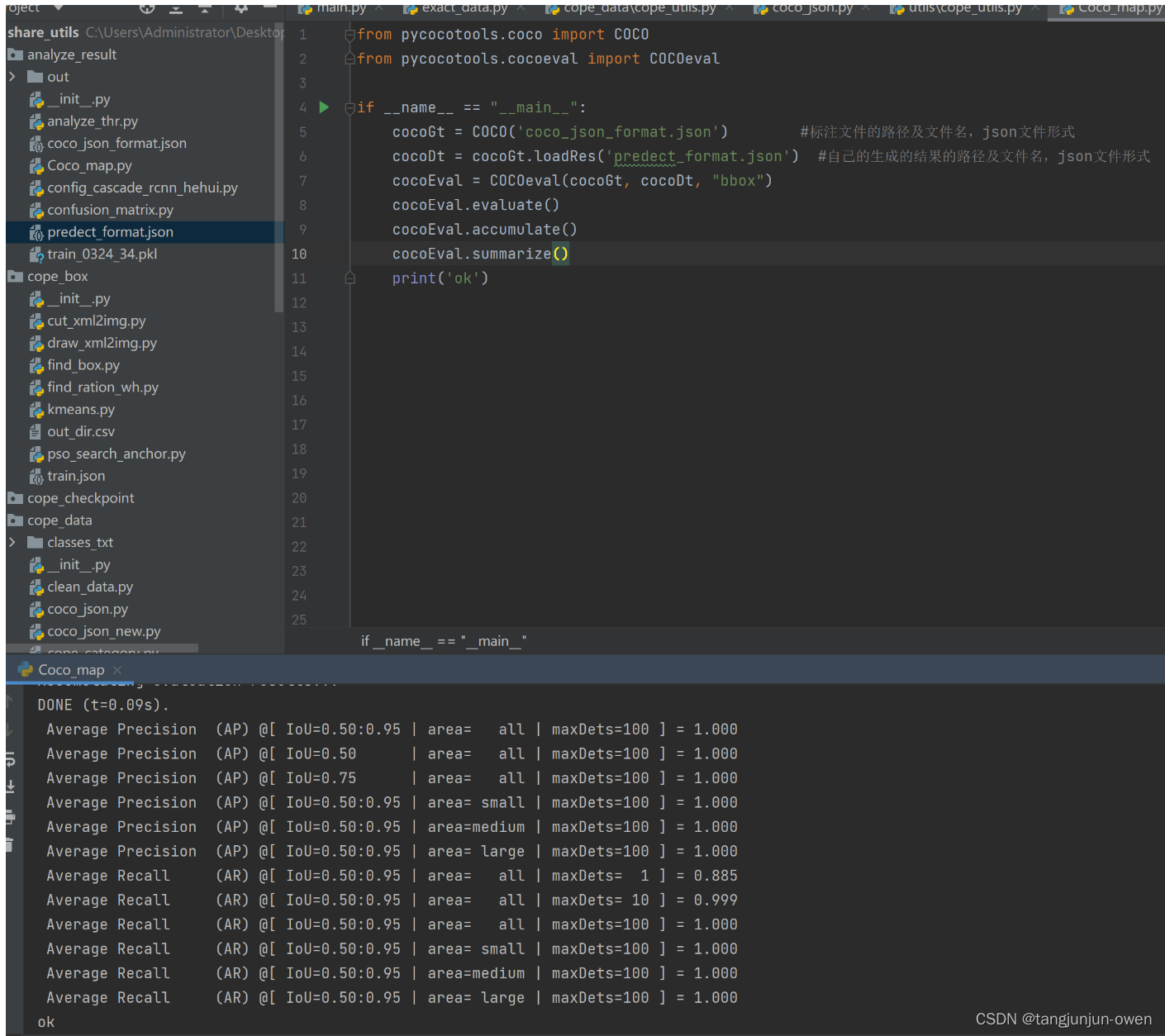
史上最全AP、mAP详解与代码实现
文章目录 前言一、mAP原理1、mAP概念2、准确率3、精确率4、召回率5、AP: Average Precision 二、mAP0.5与mAP0.5:0.951、mAP0.52、mAP0.5:0.95 三、mAP代码实现1、真实标签json文件格式2、模型预测标签json文件格式3、mAP代码实现4、mAP结果显示 四、模型集成mAP代码1、模型mai…...

百数应用中心——生产制造管理解决方案解决行业难题
传统生产制造业面临着许多挑战,其中一些主要问题包括效率低下、交期压力大、需求预测不准确、生产模式复杂、异常响应慢、库存高和计划脱节等。这些问题不仅影响了生产效率和质量,也导致了不必要的成本和客户满意度下降。 生产制造管理应用对于企业的生产…...
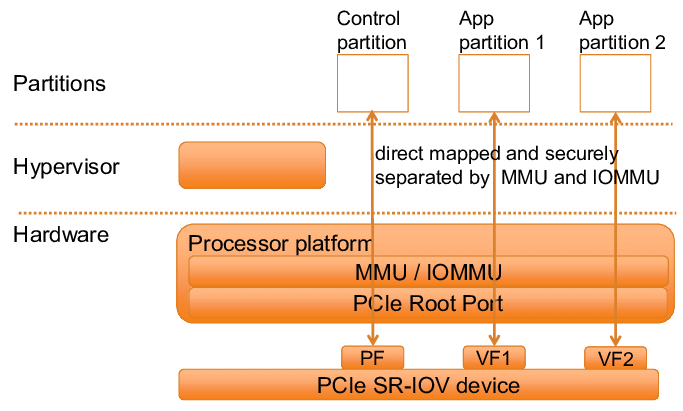
《存储IO路径》专题:IO虚拟化初探
大家好,欢迎来到今天的科技小课堂。今天我们要聊聊的是一项非常有趣且实用的技术——I/O虚拟化(Input/Output Virtualization,简称IOV)。想象一下,如果把物理硬件资源比作一道丰盛的大餐,那么IOV就是那位神…...
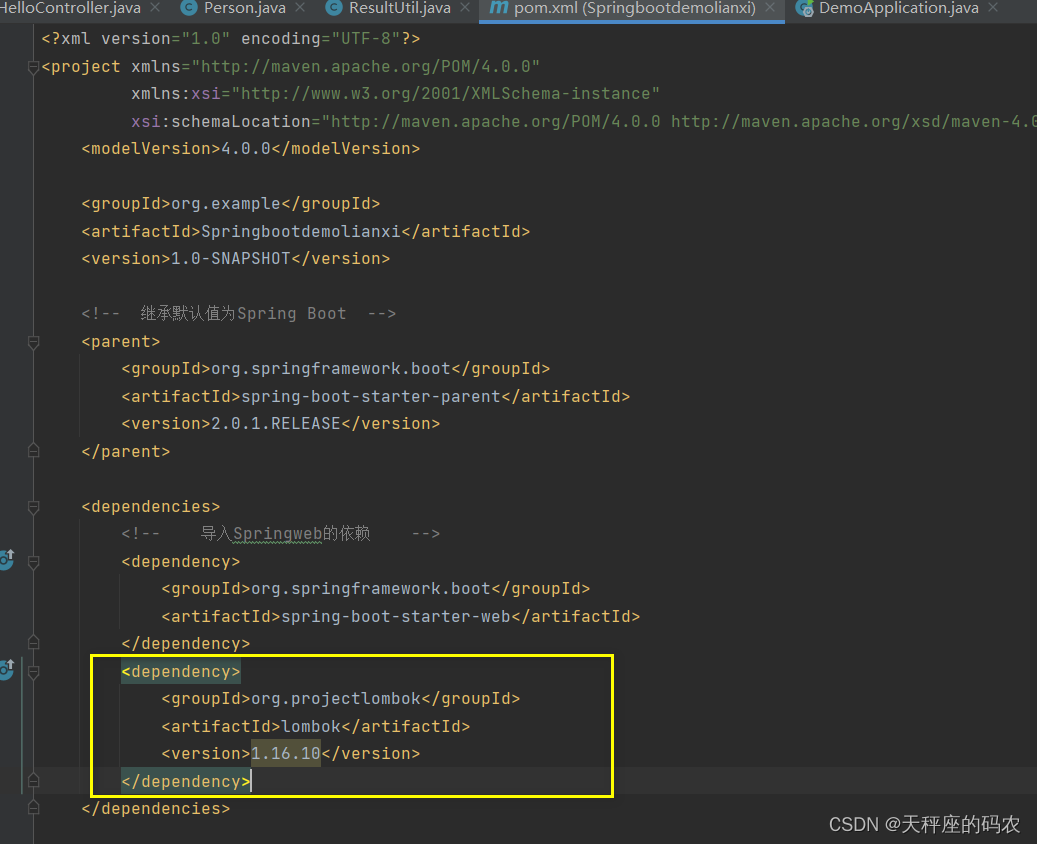
Springboot2.0快速入门(第一章)
目录 一,SpringBoot简介1.1,回顾什么是Spring1.2,Spring是如何简化Java开发的1.3,什么是SpringBoot 二,Hello,World2.1,准备工作2.2,创建基础项目说明2.3,创建第一个Hell…...
:PyFlink DataStream API之StreamExecutionEnvironment)
Flink流批一体计算(17):PyFlink DataStream API之StreamExecutionEnvironment
目录 StreamExecutionEnvironment Watermark watermark策略简介 使用 Watermark 策略 内置水印生成器 处理空闲数据源 算子处理 Watermark 的方式 创建DataStream的方式 通过list对象创建 使用DataStream connectors创建 使用Table & SQL connectors…...

javeee spring cglib动态代理
cglib动态代理 依赖 <dependency><groupId>cglib</groupId><artifactId>cglib-nodep</artifactId><version>3.2.4</version></dependency>代理类 package com.test.cglibProxy;import net.sf.cglib.proxy.Enhancer; import …...

【Docker】Dockerfile介绍
Dockerfile是一个文本文件,其中包含了一系列的指令,用于构建Docker镜像。这些指令可以用来自动化镜像的构建过程,并创建自定义镜像。 以下是一些常用的Dockerfile指令及其功能: FROM:指定基础镜像。这是Dockerfile中…...

两个hdfs之间迁移传输数据
本文参考其他大数据大牛的博文做了整理和实际验证,主要解决hdfs跨集群复制/迁移问题。 在hdfs数据迁移时总会涉及到两个hdfs版本版本问题,致力解决hdfs版本相同和不同两种情况的处理方式,长话短说,进正文。 distcp: hadoop自带的…...

K8s 日志治理:EFK 集群进阶配置 + 日志分片、归档、清理自动化方案
K8s 日志治理:EFK 集群进阶配置 + 日志分片、归档、清理自动化方案 前言:在Kubernetes(以下简称K8s)集群运维中,日志是问题排查、性能监控、合规审计的核心依据。EFK(Elasticsearch + Fluentd/Fluent Bit + Kibana)作为K8s日志收集与分析的主流架构,基础部署仅能满足“…...

GPT模型评估实战:开源工具gpt-stats构建多维度能力评测体系
1. 项目概述:一个为GPT模型“体检”的开源利器如果你和我一样,日常工作中经常和各类GPT模型打交道,无论是调用OpenAI的官方API,还是部署、微调开源的Llama、Qwen等模型,心里总会萦绕着一个问题:这个模型到底…...

科技早报晚报|2026年5月14日:调试工作台、Agent 证据格式与多智能体编排,今晚更值得做成产品的 3 个技术机会
科技早报晚报|2026年5月14日:调试工作台、Agent 证据格式与多智能体编排,今晚更值得做成产品的 3 个技术机会 一句话导读:今晚真正值得看的,不是又一个“更会写代码”的 Agent,而是 AI 工具链开始补上的三块…...
:mbuf、mempool、ethdev 的数据路径)
DPDK 教程(二):mbuf、mempool、ethdev 的数据路径
1 DPDK 教程(二):mbuf、mempool、ethdev 的数据路径 本文对应学习路径第二步:把“包从网卡进来到被应用消费”的主链路读成一张图。读完你应能口述:描述符环 → PMD RX → mbuf 与 mempool → 用户处理 → TX burst →…...

构建本地AI智能体:从LLM工具调用到自动化工作流实战
1. 项目概述:一个能“听懂”你需求的本地AI助手最近在折腾本地大语言模型(LLM)的朋友,可能都绕不开一个痛点:模型本身能力很强,但怎么让它真正“听话”,按照你的具体需求去执行任务?…...

代码随想录算法训练营Day-50 图论02 | 99.岛屿数量-深搜、99.岛屿数量-广搜 、100.岛屿的最大面积
99.岛屿数量-深搜主函数比较朴素:定义基础变量,接收数据,遍历图节点,对每个节点进行处理:遇到没访问过的陆地就result,然后深搜这篇陆地的上下左右,把和这片土地挨着的所有土地标记为访问过&…...

集成学习实战指南:从Bagging到Stacking的模型融合艺术
1. 为什么你需要掌握集成学习? 记得我第一次参加Kaggle比赛时,看到排行榜上那些大神们的模型分数高得离谱,而我的单模型怎么调参都追不上。后来才发现,他们都在用集成学习的魔法。简单来说,集成学习就像组建一个专家团…...

BLDC电机场景化创新:从性能参数到系统解决方案的转型路径
1. 项目概述:在红海中寻找蓝海最近几年,BLDC(无刷直流电机)赛道可以说是热闹非凡。从家里的扫地机器人、空气循环扇,到办公室的静音风扇、电动升降桌,再到路上的两轮电动车、新能源汽车,几乎无处…...

从‘反射’到‘压缩’:图解Nelder-Mead算法在SciPy中的实战调参
从几何视角解密Nelder-Mead算法:SciPy实战与参数调优艺术 当我们需要在复杂的参数空间中寻找最优解时,Nelder-Mead算法就像一位经验丰富的登山向导,不需要知道山势的陡峭程度(导数),仅凭对周围地形的感知就…...

使用curl命令快速调试taotoken的openai兼容聊天接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令快速调试taotoken的openai兼容聊天接口 在开发或集成大模型应用时,有时我们希望在无需依赖特定编程语言SD…...