强化学习(2)
强化学习(1)
1.多智能体深度强化学习重要性采样
多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning,MADRL)是指在多智能体环境下使用深度强化学习算法进行协同学习。重要性采样(Importance Sampling)是一种统计学方法,用于计算期望值,可以用于加速强化学习中的收敛。在MADRL中,重要性采样可以用于优化每个智能体的策略,从而提高整个系统的效率和性能。具体而言,每个智能体的策略在训练过程中需要采样环境中的状态,并基于采样到的状态进行更新。重要性采样可以在样本中分配不同的权重,以便更好地表示期望值,从而提高训练的效率和稳定性。
2.深度强化学习中的Fingerprints
在深度强化学习中,Fingerprints通常指的是在观测序列和动作序列上生成的一个固定长度的向量,用于表示一个智能体的行为轨迹或策略。这个向量可以被看作是对智能体策略或行为轨迹的压缩或摘要。这种向量通常会被用于比较不同智能体之间的策略或行为轨迹的相似性,或者用于计算智能体的性能指标。
生成Fingerprints的方法有很多种,其中比较常用的一种是使用深度神经网络对智能体的行为轨迹进行编码,得到一个固定长度的向量。这个向量通常会被训练成能够在不同智能体之间区分不同策略或行为轨迹的特征。
3.VPG is an on-policy algorithm
VPG 是指 “Vanilla Policy Gradient”,也称为基本策略梯度算法。它是一种基于策略梯度的在线学习算法,用于强化学习中的无模型环境。在 VPG 中,代理通过与环境进行交互来收集经验数据,然后使用这些数据来更新策略参数。
VPG 算法的基本思想是通过最大化累积回报来优化策略,而不是通过值函数的估计值。它直接对策略参数执行梯度上升操作,使得代理可以学习到使得回报最大化的动作策略。VPG 算法是一种在线学习算法,意味着代理在每次与环境交互时都会进行参数更新。
VPG 的一种常见变体是使用策略梯度定理中的重要性采样技术,以减小采样偏差。此外,VPG 还可以与基线函数结合,用于减小梯度估计的方差。这些技术可以提高算法的稳定性和收敛性。
总而言之,VPG 是一种基于策略梯度的在线学习算法,用于强化学习任务中的无模型环境。它通过最大化累积回报来优化策略参数,以学习到使得回报最大化的动作策略。
4.The Spinning Up implementation of VPG supports parallelization with MPI.
VPG:
Spinning Up 是一个开源的强化学习库,其中包含了对 VPG(Vanilla Policy Gradient)算法的实现。这个实现支持使用 MPI(Message Passing Interface)进行并行化。
MPI 是一种用于在分布式计算环境中进行通信和并行计算的标准接口。通过使用 MPI,Spinning Up 的 VPG 实现可以将计算任务分发给多个计算节点,并在节点之间进行通信,以加速算法的执行过程。这种并行化可以提高算法的效率,特别是在需要进行大量采样和计算的情况下。
使用 MPI 进行并行化的 VPG 实现允许在多个计算节点上同时进行环境交互和参数更新。每个节点都可以独立地与环境交互,并使用本地采样数据进行策略参数的更新。然后,节点之间通过 MPI 进行通信,共享更新后的参数和经验数据,以保持一致的策略更新。
通过将计算任务分布到多个计算节点上,并通过 MPI 进行通信,Spinning Up 的 VPG 实现可以充分利用分布式计算环境的资源,加速算法的执行速度,提高训练效率,并且在大规模问题上具有可扩展性。
5.幂长度表示所有训练智能体在环境中的每个幂的平均长度
幂长度是指在强化学习中,所有训练智能体在环境中每个幂的平均步数或时长。
在强化学习中,一个幂(episode)是指从智能体开始与环境交互,到达终止状态或满足其他终止条件之间的一系列动作和状态转换。幂长度是用来衡量训练智能体在环境中运行的效率和持续时间的指标。
计算幂长度的方法是对所有训练智能体完成的幂进行统计,并计算它们的平均长度。具体而言,对于每个幂,记录下智能体与环境进行的步数或时长,然后将所有幂的长度相加,并除以幂的总数,得到平均幂长度。
幂长度的平均值可以帮助评估智能体的学习效率和性能。较长的平均幂长度可能意味着智能体需要更多的步骤才能达到预期的目标,而较短的平均幂长度则表明智能体能够更快地学习并有效地在环境中行动。
通过监测和分析幂长度,可以对训练过程中的学习进展和智能体性能进行评估和比较,以便进行调整和改进。
6.策略损失表示损失函数的平均幅度,与策略(决定操作的过程)变化的程度相关
策略损失是指在强化学习中,用于优化策略的损失函数的平均幅度。它与策略的变化程度密切相关。
在强化学习中,智能体的目标是通过优化策略来最大化累积回报。策略是指决定智能体在不同状态下选择哪个操作的过程。为了优化策略,需要定义一个损失函数,用于衡量当前策略的好坏,并根据损失函数的梯度信息进行策略更新。
策略损失反映了当前策略的平均变化幅度。当策略损失较大时,意味着策略的变化幅度也较大。这可能表示策略在尝试不同的动作选择或策略参数调整,以寻找更优的策略。相反,当策略损失较小时,策略的变化幅度较小,表示策略已经相对稳定或接近最优解。
策略损失的平均幅度可以用来监测策略的变化情况。较大的策略损失意味着策略正在经历较大的变化和调整,而较小的策略损失表示策略相对稳定。在训练过程中,可以根据策略损失的变化情况来评估策略更新的效果,并进行调整和优化。
通过控制策略损失的平均幅度,可以平衡策略的探索和利用,以确保智能体在学习过程中既能够尝试新的策略,又能够保持策略的稳定性和收敛性。
7.值损失:价值函数更新的平均损失
值损失是指在强化学习中,用于更新价值函数的损失函数的平均损失。
在强化学习中,价值函数用于估计每个状态的价值或期望回报。价值函数可以是状态值函数(V函数)或动作值函数(Q函数),用于评估在当前策略下,智能体在不同状态或状态动作对上的预期回报。
为了优化价值函数,需要定义一个损失函数,用于衡量当前价值函数的估计值与目标值之间的差异,并根据损失函数的梯度信息进行价值函数的更新。值损失即表示在这个过程中,损失函数的平均损失。
值损失的平均损失可以用来监测价值函数的更新情况。较大的值损失意味着当前的价值函数估计与目标值之间存在较大的差异,需要更多的更新来逼近真实的价值。相反,较小的值损失表示价值函数的更新较为精确,估计值已经接近目标值。
通过控制值损失的平均损失,可以平衡价值函数的收敛速度和稳定性。较大的值损失可能需要更多的训练步骤和参数更新来减小损失,但也可能导致训练不稳定。较小的值损失则表示价值函数的更新相对稳定,但也可能导致收敛速度较慢。
因此,值损失的平均损失在强化学习中是一个重要的指标,用于评估和监测价值函数的更新效果,并在训练过程中进行调整和优化。
8.策略熵:表示模型的决策随机性
策略熵是在强化学习中用来衡量模型决策随机性的指标。
在强化学习中,智能体通过学习一个策略来做出决策。策略是一种从状态到动作的映射关系,用于确定在给定状态下应该选择哪个动作。策略的熵是指在给定状态下,策略对不同动作的选择的随机性或不确定性。
策略熵的计算基于策略函数中每个动作的概率分布。较高的策略熵表示模型在给定状态下对不同动作的选择具有更高的随机性,即模型更加不确定或随机。相反,较低的策略熵表示模型的决策更加确定和确定性,即模型偏向于选择某个特定的动作。
策略熵在强化学习中起到重要的作用。较高的策略熵可以促进探索,使智能体更有可能尝试不同的动作,以发现潜在的高回报策略。然而,过高的策略熵也可能导致决策的随机性过大,降低了智能体的性能和效率。相反,较低的策略熵可以提高智能体的决策确定性,但可能导致局部最优解陷阱和缺乏探索。
通过调整策略熵的大小,可以在探索和利用之间进行平衡,以实现更有效的学习和决策过程。例如,可以使用熵正则化或熵奖励的方法来控制策略熵的大小,并在训练过程中动态调整策略的随机性。
总之,策略熵是衡量模型决策随机性的指标,在强化学习中用于平衡探索和利用,并影响智能体的学习和决策行为。
9.学习率:训练算法在搜索最优策略时的步长,应该随时间减少。
学习率(Learning rate)是在搜索最优策略时控制训练算法步长的参数。通常情况下,学习率应随着时间的推移逐渐减小。
初始阶段使用相对较大的学习率有助于快速收敛和快速学习。较大的学习率可以使参数在训练初期有较大的变化,从而加快学习速度。然而,随着训练的进行,较大的学习率可能导致参数在最优点附近震荡或发散。
因此,逐渐减小学习率是一个常见的做法,它有助于在接近最优解时更精确地调整模型参数,使其收敛到全局最优解或局部最优解。通过减小学习率,参数更新的步长也会减小,使得模型更加稳定,能够更好地调整参数,避免过度拟合和震荡。
常用的学习率衰减策略包括:
固定衰减:事先设定一个衰减率和衰减周期,在每个周期结束时将学习率按照设定的衰减率进行更新。
指数衰减:学习率按指数函数进行衰减,例如每个周期后学习率乘以一个小于1的衰减因子。
学习率调度:根据训练过程中的性能指标或损失函数变化情况动态调整学习率,例如在损失函数下降缓慢时减小学习率。
自适应方法:使用自适应优化算法,如Adam、Adagrad、RMSprop等,这些算法可以根据梯度信息自动调整学习率的大小。
选择适当的学习率衰减策略和衰减速度是一个经验性的过程,取决于具体的问题和数据集。需要进行实验和调整,以找到最佳的学习率衰减策略,以获得更好的训练效果和收敛性。
10.分散式训练
分散式训练(Distributed Training)是一种在多个计算设备或计算节点上同时进行模型训练的方法,旨在提高训练速度和效率。通过将计算和数据分布到多个设备或节点上并进行并行计算,可以加快模型训练的速度,并处理更大规模的数据和更复杂的模型。
以下是分散式训练的一般步骤和关键概念:
数据并行性(Data Parallelism):将训练数据分成多个批次,并将每个批次分发到不同的设备或节点上进行并行处理。每个设备或节点都计算相同的模型更新,并将结果同步回主模型。这种方法适用于具有大量训练数据的情况。
模型并行性(Model Parallelism):将模型分解为多个部分,并将每个部分分配到不同的设备或节点上进行并行计算。每个设备或节点计算模型的不同部分,并将中间结果传递给其他设备或节点以完成模型的计算。这种方法适用于具有大量参数或大型模型的情况。
参数服务器(Parameter Server):在分散式训练中,参数服务器是一个集中管理和存储模型参数的组件。各个设备或节点可以通过参数服务器来获取最新的参数,并将计算结果上传到参数服务器进行参数更新。
通信机制:在分散式训练中,设备或节点之间需要进行通信来传递数据和参数。常见的通信机制包括消息传递接口(Message Passing Interface,MPI)、分布式队列和参数服务器等。
同步更新和异步更新:在分散式训练中,参数更新的方式可以是同步的或异步的。同步更新要求等待所有设备或节点完成计算并将结果同步回主模型后,才进行参数更新。异步更新允许设备或节点独立地进行计算和参数更新,不需要等待其他设备或节点。
分散式训练可以通过有效地利用多台计算设备或计算节点的计算资源,加快模型训练的速度,并提供更好的可扩展性和容错性。然而,分散式训练也带来了一些挑战,如数据同步、通信开销和一致性问题等,需要仔细设计和管理。
11.MLP policies
MLP策略是指在强化学习中基于多层感知器(Multi-Layer Perceptron,MLP)神经网络的策略。MLP是一种前馈神经网络,由多个层次的相互连接的节点(神经元)组成,每个神经元与前一层和后一层的所有神经元相连接。MLP广泛应用于各种机器学习任务,包括强化学习。
在强化学习中,MLP策略用于将状态或观测映射到动作。MLP将状态或观测作为输入,并产生一个关于可能动作的概率分布。MLP的输出层通常使用softmax激活函数,确保动作的概率之和为1。
MLP策略在表示状态和动作之间的映射时具有灵活性和表达能力。通过调整层数、每层的神经元数量和激活函数,MLP策略可以学习复杂的决策过程,并捕捉状态和动作之间的非线性关系。
在强化学习中训练MLP策略通常使用梯度下降和反向传播等技术,根据从环境中获得的奖励更新网络参数。可以使用诸如深度Q网络(Deep Q-Networks,DQN)、近端策略优化(Proximal Policy Optimization,PPO)和信赖域策略优化(Trust Region Policy Optimization,TRPO)等强化学习算法与MLP策略配合使用。
12. SGD
SGD(随机梯度下降法)是一种常用的优化算法,用于在机器学习和深度学习中更新模型参数以最小化损失函数。
SGD的核心思想是通过不断迭代来更新参数,每次迭代使用一小批次(称为mini-batch)的训练样本来计算梯度,并根据梯度的方向更新参数。这种随机性使得SGD具有较快的训练速度和较小的内存需求,尤其适用于大规模数据集和高维参数空间。
SGD的更新规则可以概括为以下步骤:
初始化模型参数。
将训练数据划分为小批次。
对于每个小批次:
计算损失函数关于参数的梯度。
使用学习率乘以梯度来更新参数。
重复上述步骤,直到达到指定的停止条件(例如达到最大迭代次数或损失函数收敛)。
SGD算法的一个关键点是学习率(learning rate),它控制了参数更新的步幅。较大的学习率可能导致参数在优化过程中波动较大,难以收敛;而较小的学习率可能导致收敛速度较慢。因此,选择合适的学习率是使用SGD的重要考虑因素之一。
SGD的变种包括批量梯度下降(Batch Gradient Descent,BGD)和小批量梯度下降(Mini-batch Gradient Descent),它们在每次迭代时使用的样本数量不同。BGD使用全部训练样本计算梯度,而Mini-batch GD使用小批次样本计算梯度。SGD可以看作是Mini-batch GD的特例,即每个小批次只包含一个样本。
除了SGD,还有其他优化算法,如动量法(Momentum)、AdaGrad、Adam等,它们通过引入额外的技巧或自适应调整学习率的方式来改善优化过程。这些算法可以根据任务的特点和性能需求选择适当的优化算法。
13.LSTM 策略
LSTM(长短期记忆)是一种常用的循环神经网络(RNN)结构,用于处理和建模序列数据。在机器学习中,LSTM可以应用于策略学习,特别是在强化学习中,用于构建智能体的策略。
LSTM策略利用LSTM网络来学习和表示智能体的策略。LSTM网络通过自己的内部门控机制,能够对输入序列进行记忆和选择性地忘记信息,使其能够处理长期依赖关系。这使得LSTM网络在处理包含时间序列或其他序列结构的数据时非常有效。
在强化学习中,LSTM策略通常用于学习智能体在不同时间步骤下的动作选择。LSTM接受当前状态作为输入,并输出一个动作或动作分布,以指导智能体的行为。由于LSTM的记忆性质,它可以从历史观察中获取信息,并在当前状态下做出更有信息量的决策。
LSTM策略的训练通常使用强化学习算法,如深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)或Proximal Policy Optimization(PPO)。这些算法通过与环境进行交互收集经验,然后使用LSTM策略来更新参数,以最大化长期累积奖励或其他指定的目标函数。
LSTM策略在许多任务和领域中都有广泛的应用,例如自然语言处理、语音识别、机器翻译、时间序列预测等。通过使用LSTM策略,智能体可以更好地理解和建模序列数据的结构和上下文信息,从而提高其在复杂任务中的表现能力。
14.entropy bonus
熵奖励(Entropy Bonus)是在强化学习中使用的一种技术,用于促进智能体在学习过程中探索更多的行为空间。它是基于策略的熵(Entropy)的概念。
在强化学习中,智能体的策略通常表示为一个概率分布,描述了在给定状态下选择每个动作的概率。策略的熵是对这个概率分布的不确定性的度量。当策略的熵较高时,表示智能体在选择动作时更加随机和不确定。
熵奖励的目的是增加策略的熵,以鼓励智能体在学习过程中保持较高的探索性。通过给予较高熵的策略一定的奖励,智能体被鼓励更多地尝试不同的动作,并更好地探索环境,而不是仅仅依赖已知的最佳动作。
熵奖励通常通过在强化学习的目标函数中引入一个熵项来实现。这个熵项是策略熵的负数乘以一个权重系数,加到累积奖励中。通过最大化目标函数,智能体在平衡奖励和探索性之间进行学习。
熵奖励在许多强化学习算法中都有应用,例如深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)和Proximal Policy Optimization(PPO)。它被广泛用于解决探索与利用之间的平衡问题,并提高智能体的学习效率和性能。
需要注意的是,熵奖励并不适用于所有任务和环境。在某些情况下,过高的熵奖励可能导致智能体过于随机和探索,而无法有效地学习和执行任务。因此,在应用熵奖励时,需要根据具体情况进行权衡和调整。
15.generalized advantage estimate parameter
广义优势估计(Generalized Advantage Estimation,GAE)是一种强化学习算法,用于估计动作价值函数的优势值。在GAE算法中,有几个参数需要进行设置和调整。
Advantage Discount Factor(优势折扣因子):在计算优势估计时,需要考虑未来奖励的累积。优势折扣因子决定了未来奖励的衰减速度。通常使用一个介于0到1之间的数值,表示未来奖励的衰减程度。较大的折扣因子会更加重视未来奖励,而较小的折扣因子则更加注重即时奖励。
Lambda Parameter(Lambda参数):Lambda参数用于平衡立即奖励和未来奖励在优势估计中的权重。
Lambda参数是一个介于0到1之间的数值。当Lambda接近0时,只考虑立即奖励,而当Lambda接近1时,更加平衡当前奖励和未来奖励。选择合适的Lambda参数可以平衡短期回报和长期回报之间的权衡。
这两个参数可以根据具体的问题和任务进行调整和优化。一般来说,需要通过实验和调试来找到最佳的参数值,以获得良好的优势估计结果。这可以通过训练模型并进行性能评估来完成,同时结合领域知识和经验进行参数调整。
需要注意的是,GAE算法还涉及其他参数,如价值函数的近似器、学习率等。这些参数也需要进行适当的设置和调整,以使算法在具体问题中获得最佳性能。
相关文章:
)
强化学习(2)
强化学习(1) 1.多智能体深度强化学习重要性采样 多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning,MADRL)是指在多智能体环境下使用深度强化学习算法进行协同学习。重要性采样(Importance Sampling)是…...

Visual Studio 2022的MFC框架——theApp全局对象
我是荔园微风,作为一名在IT界整整25年的老兵,今天我们来重新审视一下Visual Studio 2022下开发工具的MFC框架知识。 MFC中的WinMain函数是如何与MFC程序中的各个类组织在一起的呢?MFC程序中的类是如何与WinMain函数关联起来的呢?…...

SpringBoot Cache
一、基本概念 Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,例如: • EHCache • Caffeine …...

vue 简单实验 自定义组件 component
1.代码 <script src"https://unpkg.com/vuenext" rel"external nofollow" ></script> <div id"components-demo"><button-counter></button-counter> </div> <script> // 创建一个Vue 应用 const ap…...
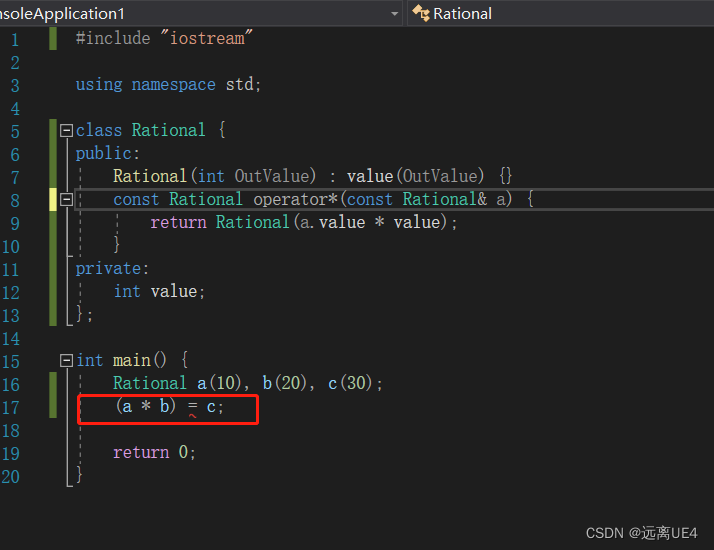
C++ 改善程序的具体做法 学习笔记
1、尽量用const enum inline替换#define 因为#define是做预处理操作,编译器从未看见该常量,编译器刚开始编译,它就被预处理器移走了,而#define的本质就是做替换,它可能从来未进入记号表 解决方法是用常量替换宏 语言…...

Unity 之 GameObject.Find()在场景中查找指定名称的游戏对象
文章目录 GameObject.Find 是 Unity 中的一个函数,用于在场景中查找指定名称的游戏对象。这个函数的主要作用是根据游戏对象的名称来查找并返回一个引用,使您能够在代码中操作该对象。以下是有关 GameObject.Find 的详细介绍: 函数签名&…...
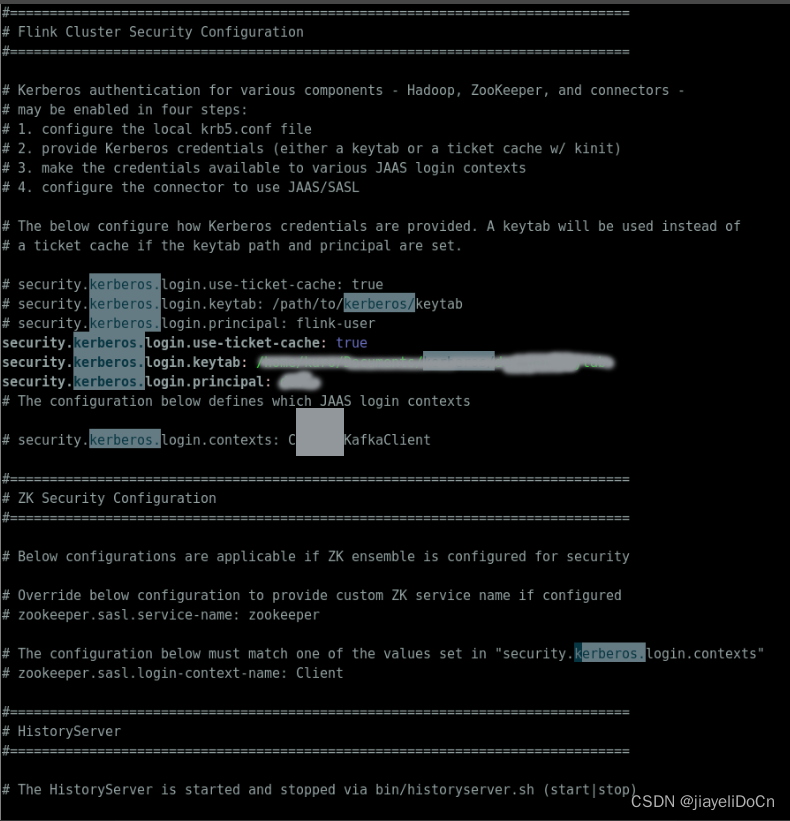
flink on yarn with kerberos 边缘提交
flink on yarn 带kerberos 远程提交 实现 flink kerberos 配置 先使用ugi进行一次认证正常提交 import com.google.common.io.Files; import lombok.extern.slf4j.Slf4j; import org.apache.commons.io.FileUtils; import org.apache.flink.client.cli.CliFrontend; import o…...
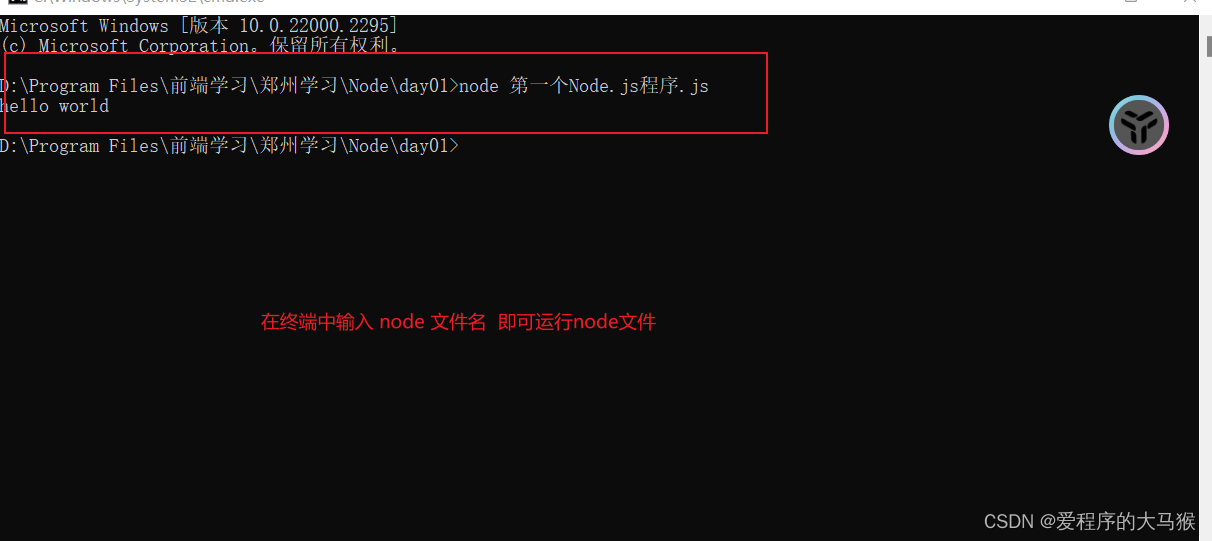
NodeJS的简介以及下载和安装
本章节会带大家下载并安装NodeJs 以及简单的入门,配有超详细的图片,一步步带大家进行下载与安装 NodeJs简介关于前端与后端Node是什么?为什么要学习NodeNodeJS的优点: NodeJS的下载与安装NodeJS的下载: NodeJS的快速入…...

量化面试-概率题
文章目录 一、题目1.糖果罐(绿皮书79页)2 折木棍(绿皮书89页)3 第一张ACE(绿皮书95页)4 n个均匀分布之和(绿皮书95页) 二、答案1. 糖果罐2 折木棍3 第一张ACE4 n个均匀分布之和 一、…...

【spark】java类在spark中的传递,scala object在spark中的传递
记录一个比较典型的问题,先讲一下背景,有这么一个用java写的类 public class JavaClass0 implements Serializable {private static String name;public static JavaClass0 getName(String str) {if (name null) {namestr;}return name;}... }然后在sp…...

php 文字生成图片保存到本地
你可以使用PHP的GD库来生成图片并保存到本地。首先,你需要确保你的PHP环境已经安装了GD库。然后,你可以使用GD库的函数来创建一个画布,并在上面绘制文字。最后,使用imagepng或imagejpeg函数将画布保存为PNG或JPEG格式的图片文件。…...

面试手撕—二叉搜索树及其后序遍历
一、引言 在面试地平线的时候,聊到了二叉搜索树,让手撕二叉搜索树,以下是要求 1、用类模板实现二叉搜索树 2、写一个函数,实现给一个vector数组,转换成二叉搜索树 3、写出二叉搜索树的后序遍历 二、代码实现 #inc…...

Java数据结构面试题以及答案
本专栏记录Java后端开发相关的面试题,欢迎大家阅读专栏的其他文章。 目录 1.B树和B树的区别?B树和B树的优点分别是? 2.排序算法的种类和复杂度 3.HashMap和Hashtable的原理、区别、应用场景 4.ConcurrentHashMap的原理、应用场景 5.Arra…...
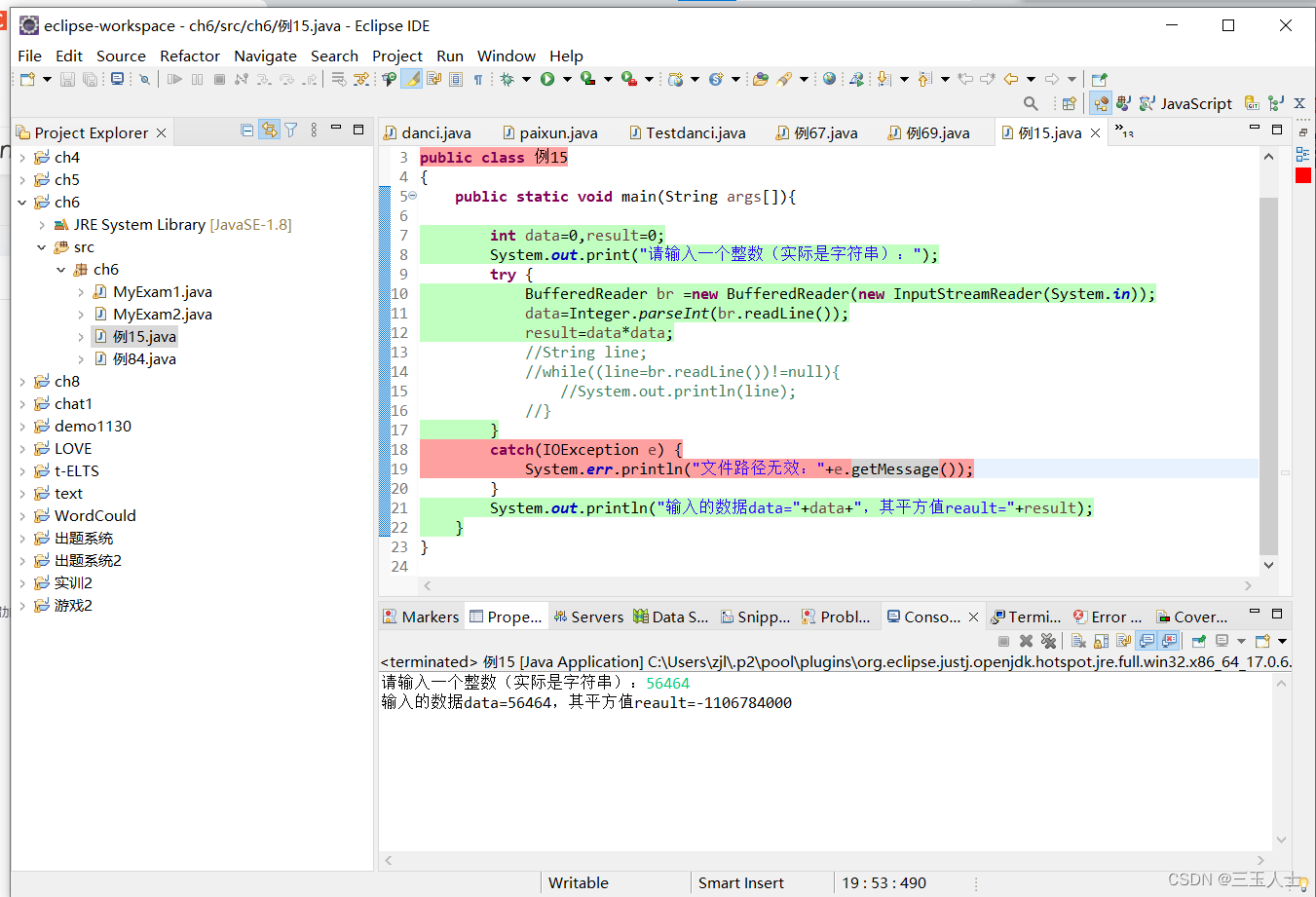
Java——它要求用户输入一个整数(实际上是一个字符串),然后计算该整数的平方值,并将结果输出。
这是一个Java程序,它要求用户输入一个整数(实际上是一个字符串),然后计算该整数的平方值,并将结果输出。程序的基本流程如下: 首先,声明并初始化变量data和result,它们的初始值都为…...

【科研论文配图绘制】task6直方图绘制
【科研论文配图绘制】task6直方图绘制 task6 主要掌握直方图的绘制技巧,了解直方图含义,清楚统计指标的添加方式 1.直方图 直方图是一种用于表示数据分布和离散情况的统计图形,它的外观和柱形图相近,但它所 表达的含义和柱形图…...

Leetcode刷题:395. 至少有 K 个重复字符的最长子串、823. 带因子的二叉树
Leetcode刷题:395. 至少有 K 个重复字符的最长子串、823. 带因子的二叉树 1. 395. 至少有 K 个重复字符的最长子串算法思路参考代码和运行结果 2. 823. 带因子的二叉树算法思路参考代码和运行结果 1. 395. 至少有 K 个重复字符的最长子串 题目难度:中等 标签&#…...
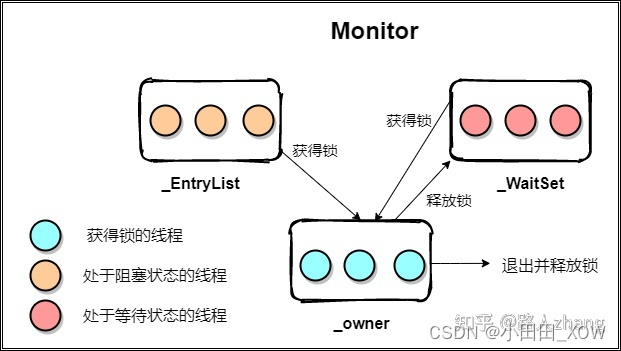
java八股文面试[多线程]——Synchronized的底层实现原理
笔试:画出Synchronized 线程状态流转实现原理图 synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized 翻译为中文的意思是同步,也称之为”同步锁“。 synchronized的作用是保证在同一时刻, 被修饰的代码块或方…...
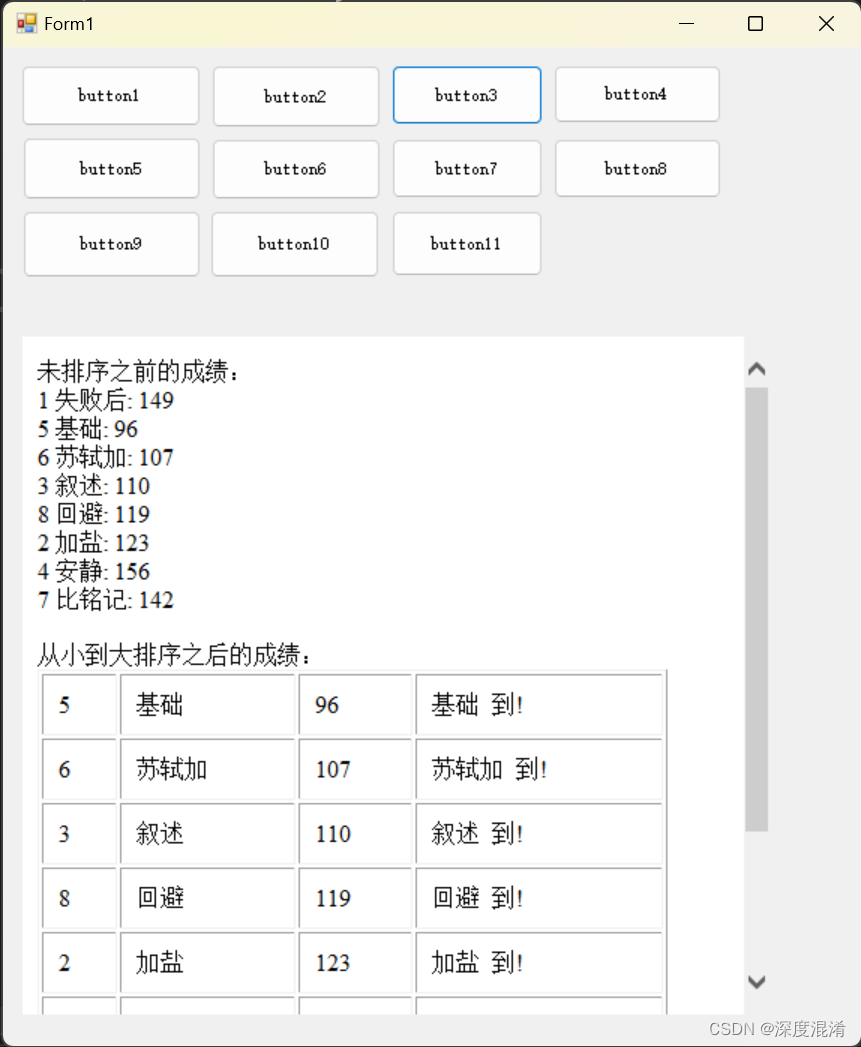
C#,《小白学程序》第三课:类、类数组与排序
类class把数值与功能巧妙的进行了结合,是编程技术的主要进步。 下面的程序你可以确立 分数 与 姓名 之间关系,并排序。 1 文本格式 /// <summary> /// 同学信息类 /// </summary> public class Classmate { /// <summary> /…...
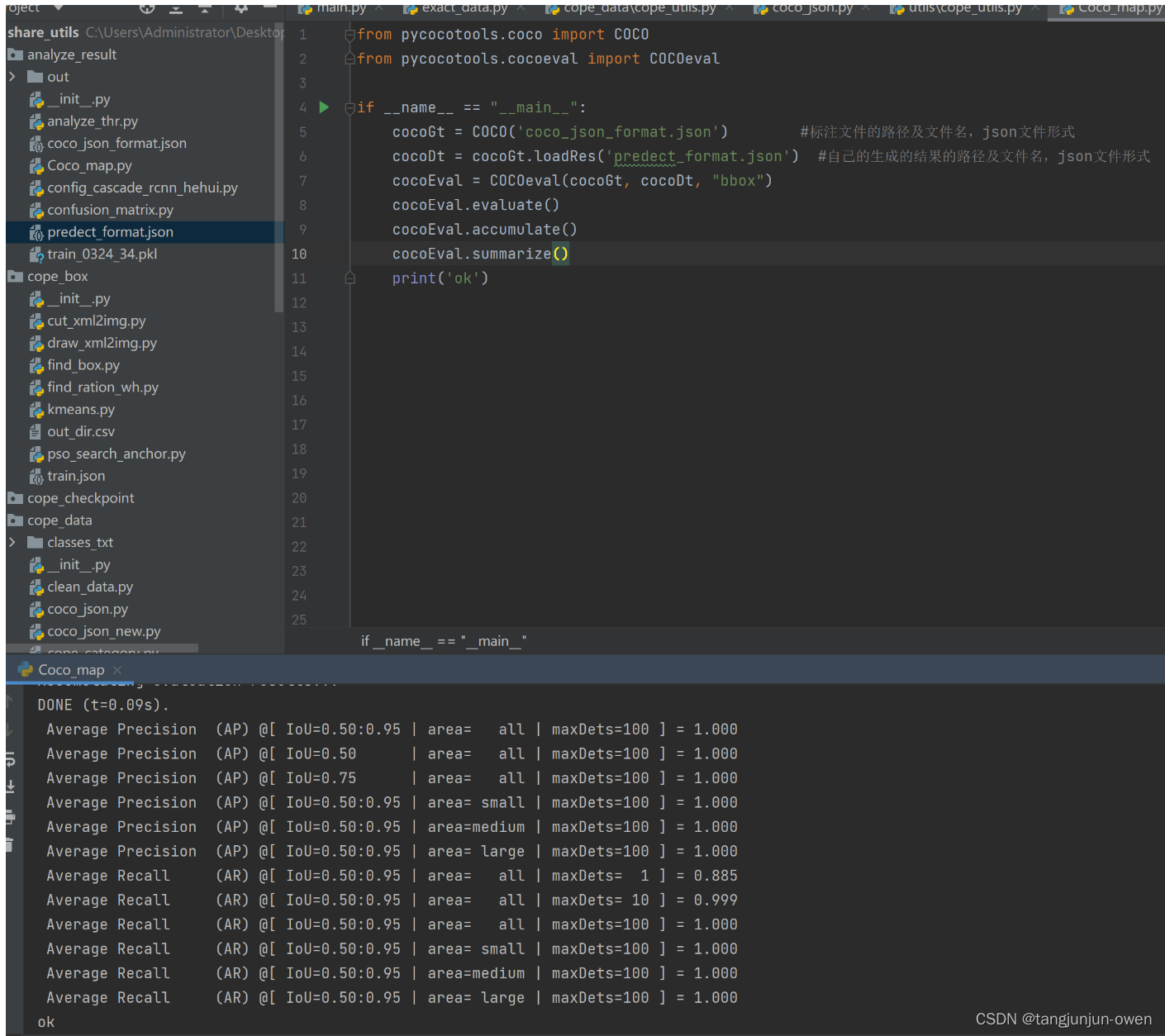
史上最全AP、mAP详解与代码实现
文章目录 前言一、mAP原理1、mAP概念2、准确率3、精确率4、召回率5、AP: Average Precision 二、mAP0.5与mAP0.5:0.951、mAP0.52、mAP0.5:0.95 三、mAP代码实现1、真实标签json文件格式2、模型预测标签json文件格式3、mAP代码实现4、mAP结果显示 四、模型集成mAP代码1、模型mai…...

百数应用中心——生产制造管理解决方案解决行业难题
传统生产制造业面临着许多挑战,其中一些主要问题包括效率低下、交期压力大、需求预测不准确、生产模式复杂、异常响应慢、库存高和计划脱节等。这些问题不仅影响了生产效率和质量,也导致了不必要的成本和客户满意度下降。 生产制造管理应用对于企业的生产…...

VSCode扩展一键克隆Git仓库:告别终端切换,提升开发效率
1. 项目概述:在VSCode里直接克隆仓库,告别终端切换如果你和我一样,每天的工作流都离不开Git和VSCode,那你一定经历过这个场景:在浏览器上看到一个不错的开源项目,复制它的GitHub链接,然后切到终…...

基于cursor-maker构建可复用AI指令模板,提升开发效率与代码一致性
1. 项目概述:一个为开发者赋能的AI代码生成工具如果你是一名开发者,尤其是经常在VSCode里写代码的朋友,那么对Cursor这款集成了AI能力的编辑器一定不陌生。它最大的魅力在于,你可以用自然语言描述你的需求,AI就能帮你生…...

5分钟搞定B站视频备份:m4s-converter完整使用教程
5分钟搞定B站视频备份:m4s-converter完整使用教程 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的情况࿱…...

Solidworks光学实验室:从零搭建一个‘偏振识别’光路模型的全流程记录
SolidWorks光学实验室:偏振识别光路建模全流程实战 在光学研究领域,论文中的二维示意图往往难以完整呈现复杂光路系统的三维空间关系。当我们需要复现一篇顶刊论文中的偏振识别实验时,如何将平面图表转化为可交互的三维模型?本文…...

AI智能体如何通过MCP协议标准化调用外部工具
1. 项目概述:当AI智能体学会“使用工具” 最近在探索AI智能体开发时,我遇到了一个非常有意思的项目: agentsimdev/agentsim-mcp 。乍一看这个名字,可能有些朋友会感到困惑,这“MCP”是什么?是“模型上下文…...
)
PyTorch实战:基于ResNet-50的室内场景图像分类(附完整代码与MIT67数据集处理)
1. 室内场景分类与ResNet-50实战概述 室内场景分类是计算机视觉中的经典任务,比如区分客厅、厨房、卧室等不同功能区域。这个任务看似简单,但实际应用中会遇到光照变化、视角差异、物体遮挡等挑战。我去年参与过一个智能家居项目,就遇到过摄像…...

标注数据集保姆级教程:从入门到排名第一,看这一篇就够了
一、常见坑与避雷第一,过度依赖众包导致标签质量参差不齐。企业往往以价格为先,忽视了众包工人对领域术语的理解深度,从而造成模型召回率下降7%。第二,缺乏统一标注工具链。使用Excel、Word等异构工具会让数据格式碎片化ÿ…...
)
【Oracle数据库指南】第36篇:Oracle用户与权限管理详解(完整版)
上一篇【第35篇】Oracle特殊对象——簇与索引组织表(IOT) 下一篇【第37篇】Oracle角色与PROFILE管理详解 摘要 Oracle数据库的用户与权限管理是安全管理的核心,建立科学的用户体系是保障数据安全的第一步。本文系统讲解Oracle用户账户的完整…...

Claude最新金融智能体模板到底能做什么?一文看懂真实业务场景
Claude最新发布的10大金融智能体模板,在金融科技圈引发了不小关注。原因并不只是它能够生成报告、总结财报,而是它第一次以“业务角色”的形式进入金融流程。无论是Pitch Builder、Earnings Reviewer,还是KYC Screener,本质上都已…...

从MobileNetV3看SE模块的‘轻量化’陷阱:参数量暴增2M,真的划算吗?
MobileNetV3中SE模块的工程化权衡:当2M参数量遇上边缘部署 在移动端AI模型部署的战场上,每一KB内存和每一毫秒延迟都值得斤斤计较。2019年问世的MobileNetV3作为轻量化网络的标杆之作,却在SE(Squeeze-and-Excitation)模…...