网络爬虫到底是个啥?
网络爬虫到底是个啥?
当涉及到网络爬虫技术时,需要考虑多个方面,从网页获取到最终的数据处理和分析,每个阶段都有不同的算法和策略。以下是这些方面的详细解释:
-
网页获取(Web Crawling): 网页获取是爬虫的起始阶段。爬虫需要从网络上下载网页内容,这可能涉及到发送HTTP请求、处理响应、处理HTTP状态码等等。在这个阶段,可能需要考虑并发请求、代理设置、请求头的模拟、请求频率的控制等。
-
网页跟踪(Web Crawling): 一旦获得网页内容,爬虫需要跟踪链接,从一个页面跳转到另一个页面,以便深度搜索整个网站。在跟踪的过程中,需要处理相对链接、绝对链接、动态加载内容(如JavaScript渲染的内容)、循环链接等情况。
-
网页分析(Web Parsing): 网页分析是从网页中提取有用信息的过程。这包括解析HTML或XML内容,提取文本、链接、图片等元素。常见的工具是HTML解析器,如Beautiful Soup和Jsoup。
-
网页搜索(Web Indexing): 在爬取大量网页后,需要构建索引以进行快速检索。这包括建立反向索引,将关键词与网页相关联,以便后续的搜索和排序。
-
网页评级(Web Ranking): 当搜索结果很多时,需要对结果进行排序,以提供最相关和有用的页面。这涉及到评估网页的重要性、权重等,以确定其在搜索结果中的排名。
-
结构/非结构化数据抽取(Data Extraction): 一旦获得网页内容,爬虫可能需要从中提取结构化或非结构化数据。例如,从新闻网站中提取标题、日期、作者和内容,或从电子商务网站中提取商品信息。
-
数据挖掘(Data Mining): 数据挖掘是进一步分析和处理从网页中提取的数据的过程。这可能包括文本分析、情感分析、主题建模、聚类分析等,以便从大量数据中发现有用的信息。
网络爬虫技术涉及到了上述多个方面,每个方面都有其特定的算法、策略和工具。对于新手来说,了解和学习这些基础技术是一个逐步的过程,需要不断地实践和深入学习。网络爬虫的应用范围广泛,包括搜索引擎、数据采集、舆情监测等领域,因此掌握这些基础技术对于构建高效和精确的爬虫系统至关重要。
详细讲解一下:结构/非结构化数据抽取(Data Extraction)
结构/非结构化数据抽取是网络爬虫过程中的一个关键步骤,它涉及从网页中提取出有用信息,并将其转化为可以进一步处理和分析的形式。这个步骤可以分为两种情况:抽取结构化数据和抽取非结构化数据。
-
抽取结构化数据: 结构化数据是按照一定规则和模式组织的数据,通常以表格、数据库表或类似的形式存在。抽取结构化数据的目标是从网页中提取出特定的字段和值,使得这些数据可以被轻松地导入到数据库中,或者用于进一步的数据分析。
例如,假设你要从电子商务网站爬取商品信息,如商品名称、价格、描述和评价。在这种情况下,抽取结构化数据可能涉及以下步骤:
- 通过解析HTML或XPath等方法,定位到包含商品信息的HTML元素。
- 使用正则表达式、字符串处理或HTML解析器,提取出每个商品的名称、价格、描述等字段。
- 将这些字段值存储到结构化数据格式(如JSON、CSV、数据库)中,以便进一步处理和分析。
-
抽取非结构化数据: 非结构化数据指的是没有明确格式或模式的数据,例如文本内容、图像、音频等。抽取非结构化数据的目标是从网页中提取出有用的信息,使其能够用于自然语言处理、文本分析、情感分析等任务。
例如,假设你从新闻网站爬取新闻文章,你可能要抽取文章的标题、正文和日期。这里的抽取非结构化数据可能包括以下步骤:
- 通过解析HTML或XPath等方法,定位到包含新闻文章内容的HTML元素。
- 使用文本处理技术,如分词、句法分析等,从文章内容中抽取出标题、正文等部分。
- 使用日期解析工具,从网页中提取出发布日期。
- 将抽取到的文本数据进行清洗和预处理,使其适合进行进一步的文本分析。
无论是抽取结构化数据还是非结构化数据,都需要根据具体的网页结构和数据特点采用合适的方法和技术。这个步骤的效率和准确性直接影响后续的数据分析和应用,因此需要仔细考虑数据抽取的策略和实现。
再详细讲解一下:数据挖掘(Data Mining)
数据挖掘(Data Mining)是从大量数据中发现隐藏模式、关联、趋势和规律的过程。它是将统计学、机器学习、数据库技术等多个领域相结合,以自动地从数据中提取有用的信息和知识。数据挖掘的目标是识别出数据中的模式,从而用于预测、分类、聚类、关联规则挖掘等各种应用。
以下是数据挖掘的几个关键概念和步骤:
-
特征选择与预处理: 在进行数据挖掘之前,首先需要对原始数据进行预处理。这包括数据清洗、缺失值处理、异常值检测等。同时,选择合适的特征(属性、变量)也是至关重要的,因为不同的特征对于挖掘目标的影响可能不同。特征选择可以提高挖掘模型的效率和准确性。
-
数据探索与可视化: 在数据挖掘之前,进行数据探索性分析可以帮助了解数据的分布、关系和趋势。可视化技术如散点图、直方图、热图等能够直观地展示数据的特点,有助于选择合适的挖掘方法。
-
模型选择与建立: 在数据挖掘过程中,选择适当的模型是关键。不同的问题可能需要不同类型的模型,如分类、回归、聚类等。根据问题的性质,可以选择支持向量机、决策树、神经网络、聚类算法等等。模型的选择应该基于问题的复杂性、数据分布等因素。
-
模型训练与评估: 在选择模型后,需要用已有的数据进行模型的训练。训练模型的过程涉及参数调整、优化算法等。之后,需要使用测试数据对模型进行评估,以了解其泛化能力和性能。常见的评估指标包括准确率、召回率、F1值等。
-
模型应用与预测: 训练好的模型可以用于进行预测、分类、聚类等任务。在实际应用中,模型可以用来做新数据的预测,从而产生有价值的结果。例如,基于历史销售数据的模型可以用来预测未来销售趋势。
-
模式解释与知识提取: 数据挖掘不仅仅是找到模式,还包括解释这些模式。从模型中提取知识,可以帮助人们更好地理解数据的内在规律。解释可以帮助决策者做出更明智的决策。
数据挖掘在多个领域中得到广泛应用,包括金融、健康、市场营销、社交网络等。通过数据挖掘,人们可以发现商机、改进流程、优化资源分配等,从而为决策和战略制定提供支持。
再详细讲解一下:特征选择与预处理
特征选择与预处理是数据挖掘过程中的重要步骤,它们的目标是在原始数据中找到对挖掘任务有用的特征,并对数据进行清洗和转换,以便于后续的建模和分析。下面详细讲解一下特征选择与预处理的过程:
特征选择(Feature Selection):
特征选择是从原始数据中选择对于挖掘任务有用的特征,排除无关或冗余的特征。特征选择的主要目的是减少数据的维度,提高模型的性能、泛化能力和解释性。以下是特征选择的一些常用方法:
-
过滤式方法(Filter Methods): 这些方法在特征选择之前独立地对特征进行评估,然后选择那些与目标变量最相关的特征。常用的评估方法包括卡方检验、信息增益、互信息等。
-
包裹式方法(Wrapper Methods): 这些方法通过尝试不同的特征子集来训练模型,并使用模型的性能作为特征的评估指标。典型的包裹式方法是递归特征消除(Recursive Feature Elimination)。
-
嵌入式方法(Embedded Methods): 嵌入式方法将特征选择与模型训练过程结合起来,在模型训练的过程中动态地选择特征。例如,决策树和随机森林可以通过特征的重要性来选择特征。
数据预处理:
数据预处理是对原始数据进行清洗和转换,以使数据更适合于挖掘任务的处理。以下是数据预处理的一些常见步骤:
-
数据清洗(Data Cleaning): 数据清洗是处理数据中的错误、缺失值和异常值的过程。错误和异常值可能会影响模型的训练和性能,缺失值则可能导致信息不完整。常见的数据清洗方法包括替换缺失值、平滑异常值、删除异常记录等。
-
数据变换(Data Transformation): 数据变换是对数据进行转换,使其更适合于模型的训练和分析。常见的数据变换方法包括标准化(使数据均值为0,方差为1)、归一化(将数据缩放到特定范围内)、对数变换等。
-
数据规约(Data Reduction): 数据规约是减少数据量和维度的过程,以提高计算效率和模型性能。常用的数据规约方法包括主成分分析(PCA)、线性判别分析(LDA)等。
-
特征工程(Feature Engineering): 特征工程是创造新特征或组合现有特征,以提供更有用的信息。例如,从时间戳中提取年、月、日等特征,从文本中提取关键词等。
数据预处理和特征选择是数据挖掘成功的关键步骤,它们的质量直接影响后续模型的准确性和效率。通过合理的特征选择和预处理,可以从原始数据中提取出最有价值的信息,为数据挖掘任务提供更好的基础。
再详细讲解一下:数据探索与可视化
数据探索与可视化是数据挖掘过程中的重要环节,它们的目标是通过探索性分析和可视化工具来深入理解数据的特征、分布、关系以及潜在模式。这有助于揭示数据的隐藏信息,为后续的建模和分析提供指导。下面详细讲解一下数据探索与可视化的过程:
数据探索(Data Exploration):
数据探索是对数据进行初步分析,以了解数据的特点、趋势和异常。这有助于我们构建初始的假设,为后续的数据处理和建模提供方向。以下是数据探索的一些常见步骤:
-
数据摘要(Data Summarization): 在这一步,我们可以计算数据的统计指标,如均值、中位数、标准差等,以了解数据的分布和集中趋势。
-
数据分布分析(Distribution Analysis): 通过绘制直方图、密度图等图表,我们可以观察数据的分布情况,判断是否符合正态分布或其他特定分布。
-
数据关系分析(Relationship Analysis): 我们可以绘制散点图、热力图等图表,来分析不同特征之间的关系,从而了解它们之间的相关性和趋势。
-
数据异常检测(Outlier Detection): 通过箱线图、Z分数等方法,可以检测数据中的异常值,即与其他值明显不同的极端值。
数据可视化(Data Visualization):
数据可视化是使用图表、图形和可视化工具来呈现数据的过程,使数据更易于理解和分析。以下是数据可视化的一些常见方法:
-
散点图(Scatter Plot): 散点图可以用来展示两个数值变量之间的关系,帮助观察变量之间的分布和趋势。
-
直方图(Histogram): 直方图可以展示数值变量的分布情况,帮助我们了解数据的集中趋势和范围。
-
箱线图(Box Plot): 箱线图可以显示数据的分布、异常值以及中位数等关键统计信息。
-
热力图(Heatmap): 热力图可以展示不同变量之间的相关性,通过颜色的深浅来表示变量之间的关系强度。
-
折线图(Line Chart): 折线图可以展示时间序列数据的趋势,帮助观察随时间变化的模式。
数据探索与可视化有助于发现数据中的模式、异常和趋势,帮助我们构建合适的数据处理和分析策略。通过有效的数据可视化,我们可以更清晰地理解数据,从而做出更准确的决策和建模选择。
相关文章:

网络爬虫到底是个啥?
网络爬虫到底是个啥? 当涉及到网络爬虫技术时,需要考虑多个方面,从网页获取到最终的数据处理和分析,每个阶段都有不同的算法和策略。以下是这些方面的详细解释: 网页获取(Web Crawling)&#x…...
前端行级元素和块级元素的基本区别
块级元素和行内元素的基本区别是, 行内元素可以与其他行内元素并排;块级元素独占一行,不能与其他任何元素并列; 下面看一下; <!DOCTYPE html> <html> <head> <meta charset"utf-8"&…...

CentOS 7用二进制安装MySQL5.7
[rootlocalhost ~]# [rootlocalhost ~]# ll 总用量 662116 -rw-------. 1 root root 1401 8月 29 19:29 anaconda-ks.cfg -rw-r--r--. 1 root root 678001736 8月 29 19:44 mysql-5.7.40-linux-glibc2.12-x86_64.tar.gz [rootlocalhost ~]# tar xf mysql-5.7.40-linux-…...

华为加速回归Mate 60发布, 7nm全自研工艺芯片
华为于今天12:08推出“HUAWEI Mate 60 Pro先锋计划”,让部分消费者提前体验。在华为商城看到,华为Mate 60 pro手机已上架,售价6999元,提供雅川青、白沙银、南糯紫、雅丹黑四种配色供选择。 据介绍,华为在卫星通信领域…...

Linux系列讲解 —— 【systemd】下载及编译记录
Ubuntu18.04的init程序合并到了systemd中,本篇文章记录一下systemd的下载和编译。 1. 下载systemd源码 (1) 查看systemd版本号,用来确定需要下载的分支 sunsun-pc:~$ systemd --version systemd 237 PAM AUDIT SELINUX IMA APPARMOR SMACK SYSVINIT UT…...
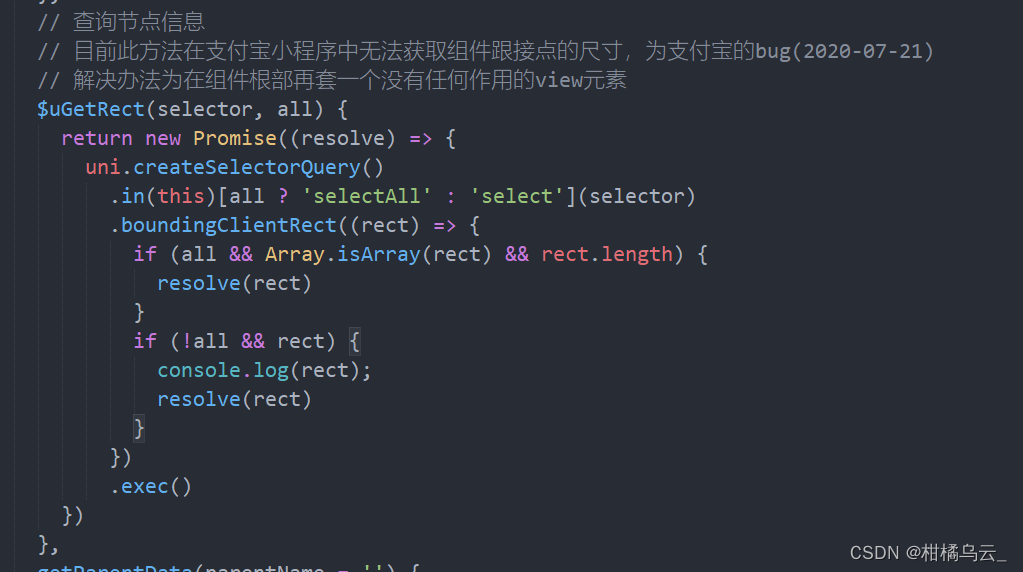
u-view 的u-calendar 组件设置默认日期后,多次点击后,就不滚动到默认日期的位置
场景:uniapp开发微信小程序 vue2 uview版本:2.0.36 ; u-calendar 组件设置默认日期后 我打开弹窗,再关闭弹窗, 重复两次 就不显示默认日期了 在源码中找到这个位置进行打印值,根据出bug前后的值进行…...

vue naive ui 按钮绑定按键
使用vue (naive ui) 绑定Enter 按键 知识点: 按键绑定Button全局挂载使得message,notification, dialog, loadingBar 等NaiveUI 生效UMD方式使用vue 与 naive ui将vue默认的 分隔符大括号 替换 为 [[ ]] <!DOCTYPE html> <html lang"en"> <head>…...
Viobot基本功能使用及介绍
设备拿到手当然是要先试一下效果的,这部分可以参考本专栏的第一篇 Viobot开机指南。 接下来我们就从UI开始熟悉这个产品吧! 1.状态 设备上电会自动运行它的程序,开启了一个服务器,上位机通过连接这个服务器连接到设备,…...

《PMBOK指南》第七版12大原则和8大绩效域
《PMBOK指南》第七版12大原则 原则1:成为勤勉、尊重和关心他人的管家 原则2:营造协作的项目团队环境 原则3:有效地干系人参与 原则4:聚焦于价值 原则5:识别、评估和响应系统交互 原则6:展现领导力行为…...

docker 启动命令
cd /ycw/docker docker build -f DockerFile -t jshepr:1.0 . #前面测试docker已经介绍过该命令下面就不再介绍了 docker images docker run -it -p 7003:9999 --name yyy -d jshepr:1.0 #上面运行报错 用这个 不报错就不用 docker rm yyy docker ps #查看项目日志 docker …...
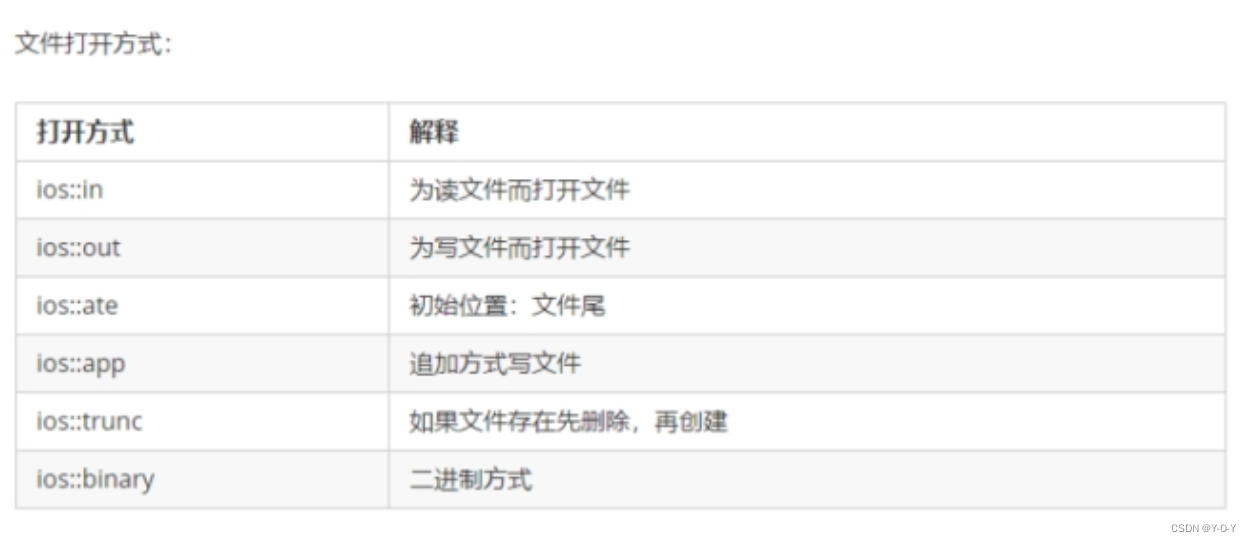
C++ DAY7
一、类模板 建立一个通用的类,其类中的类型不确定,用一个虚拟类型替代 template<typename T> 类template ----->表示开始创建模板 typename -->表明后面的符号是数据类型,typename 也可以用class代替 T ----->表示数据类型…...

Vue2 使用插件 Volar 报错:<template v-for> key should be placed on the <template> tag.
目录 问题描述 版本描述 问题定位 问题解决 VS Code 插件地址 问题描述 在 VS Code 上使用插件 Volar 开发 Vue3 项目,然后去改 Vue2 项目时,对没有放在<template v-for> 元素上的 :key,会提示 <template v-for> key should…...
和 run ()有什么区别)
启动线程方法 start ()和 run ()有什么区别
在Java中,线程可以通过调用start()方法或者直接调用run()方法来执行。这两种方式有着重要的区别: start() 方法:当你调用线程的start()方法时,它会使线程进入就绪状态,等待系统调度。系统会为该线程分配资源,并在合适的时机执行线程的run()方法。实际上,start()方法会启…...

Java的全排列模板
c有全排列函数,我们Java没有,所以我们只能自己手写了。 模板一:(不去重) import java.util.ArrayList; import java.util.Random; import java.util.Scanner; public class liyunpeng {public static void main(Stri…...
读书笔记——《万物有灵》
前言 上一本书是《走出荒野》,太平洋步道女王提到了这本书《万物有灵》,她同样是看一点撕一点的阅读。我想,在她穿越山河森林,听见鸟鸣溪流的旅行过程中,是不是看这本描写动物有如何聪明的书——《万物有灵》…...

面试现场表现:展示你的编程能力和沟通技巧
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

34亿的mysql表如何优雅的扩字段长度兵并归档重建
业务背景: 该系统有一张表数据量已达到34亿,并且有个字段长度不够,导致很多数据无法插入。因为业务只要保留近2个月数据即可,所以需要接下来需要做2点:1,扩字段长度 2,只保留近2个月的数据。 …...
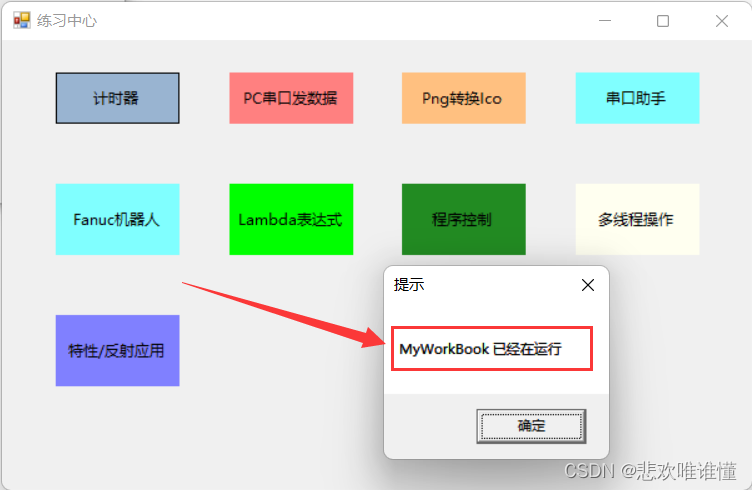
C#_进程单例模式.秒懂Mutex
什么是Mutex? 可以定义调用线程是否具有互斥性,程序创建者拥有控制权,相反只能引用程序。 参数1:如果是程序创建者,就获得控制权。 参数2:名称,可使用GUID生成。 参数3:out 返回值…...
)
AcWing 5050. 排序 (每日一题)
题目描述 给定一个长度为 n 的由小写字母构成的字符串。 请你按照 a∼z 的顺序,对字符串内的字符进行重新排序,并输出重新排序后的字符串。 输入格式 第一行包含整数 T ,表示共有 T 组测试数据。 每组数据第一行包含整数 n 。 第二行包…...

【TypeScript】proxy 和 Reflect
proxy (代理) 和 Reflect (反射) 参数一样。 基本用法 let person { name: xx, age: 20} // proxy 支持对象,数组,函数,set,map // 代理对象的常用模式:前面一个对象&…...

别再用 STVP 了!用 IAR 3.11.1 调试 STM8S003 点灯程序,效率翻倍
告别STVP:用IAR 3.11.1高效调试STM8S003点灯程序全指南 在嵌入式开发领域,工具链的选择往往决定了开发效率的上限。对于STM8系列开发,许多工程师仍在使用STVP这种基础的烧录工具,却不知已经错过了IAR Embedded Workbench带来的效…...

Chrome密码恢复终极指南:如何安全找回所有浏览器保存的密码
Chrome密码恢复终极指南:如何安全找回所有浏览器保存的密码 【免费下载链接】chromepass Get all passwords stored by Chrome on WINDOWS. 项目地址: https://gitcode.com/gh_mirrors/chr/chromepass 你是否曾经因为忘记某个重要网站的密码而焦虑࿱…...

Pulover‘s Macro Creator:你的数字助手,让电脑学会“自己工作“
Pulovers Macro Creator:你的数字助手,让电脑学会"自己工作" 【免费下载链接】PuloversMacroCreator Automation Utility - Recorder & Script Generator 项目地址: https://gitcode.com/gh_mirrors/pu/PuloversMacroCreator 你是否…...

FineBI组件制作-表格
FineBI 为用户提供了三种表格类型:明细表、分组表、交叉表。 明细表 明细表将表格中的所有数据一条一条都罗列出来,用于展示明细数据,通常包含了大量的数据记录,可以用于进行分析、查询等操作。特点: 可以展示数据的详…...

宣传片微电影制作拍摄
荣誉见证实力・匠心铸就品牌|国隆映像传媒,6 年深耕乌鲁木齐,斩获全国影像盛典、脱贫攻坚、文旅代言等多项大奖,为企事业单位提供一站式影视制作服务。...
:12个被官方文档刻意隐藏的--stylize与--chaos协同公式)
Midjourney阿盖洛印相实战手册(从暗房哲学到AI指令映射):12个被官方文档刻意隐藏的--stylize与--chaos协同公式
更多请点击: https://codechina.net 第一章:Midjourney阿盖洛印相的暗房哲学溯源 阿盖洛印相(Argyrotype)作为19世纪末由William Willis发明的铁银工艺变体,以硝酸银与有机银络合物在明胶或纤维素基质中光解还原为核心…...

Adobe GenP 3.0:终极Adobe全家桶破解工具使用指南
Adobe GenP 3.0:终极Adobe全家桶破解工具使用指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe Creative Cloud作为专业设计师和创意工作者的核…...

Google I/O 2026最魔幻的一幕:发新模型的同时,Google砍了自己的CLI
5月19号凌晨,我刚躺下准备刷会儿手机睡觉,结果被朋友圈刷屏了。 Google I/O 2026,总共两个小时的 keynote,愣是让我看到凌晨两点。不是因为我有多敬业,而是信息量实在太大——大到我觉得不记下来,明天就忘了…...

十大榜单全覆盖,价值兑现引领:联想定义中国AI企业新高度
当前,全球 AI 产业已正式迈入规模化商业落地的关键周期,“技术炫技”让位于“价值兑现”,“算力筑基—技术创新—场景落地”的协同闭环成为高质量发展的核心逻辑。据《全球首席信息官(CIO)报告:企业级 AI 竞…...
)
别再傻等!解决conda install nb_conda卡在solving environment的3个高效方法(附清华源配置)
彻底解决conda install卡在solving environment的终极指南 当你满怀期待地在终端输入conda install nb_conda准备为Jupyter Notebook添加环境管理功能时,却发现进度条永远卡在"solving environment"这一步,这种体验就像在高速公路上遇到无休止…...