实训笔记8.25
实训笔记8.25
- 8.25笔记
- 一、Flume数据采集技术
- 1.1 Flume实现数据采集主要借助Flume的组成架构
- 1.2 Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf
- 1.2.1 脚本文件主要由五部分组成
- 二、Flume案例实操
- 2.1 采集一个网络端口的数据到控制台
- 2.1.1 分析案例的组件类型
- 2.2.2 编写脚本文件portToConsole.conf
- 2.2.3 根据脚本文件启动Flume采集程序
- 2.2.4 测试
- 2.2 采集一个文件的数据到控制台
- 2.2.1 案例需求
- 2.2.2 案例分析
- 2.2.3 编写脚本文件
- 2.2.4 启动
- 2.2.5 测试
- 2.3 采集一个文件夹下的新文件数据到控制台
- 2.3.1 案例需求
- 2.3.2 案例分析
- 2.3.3 编写配置文件
- 2.3.4 运行
- 2.3.5 测试
- 2.4 采集一个网络端口的数据到HDFS中
- 2.4.1 案例需求
- 2.4.2 案例分析
- 2.4.3 编写脚本文件
- 2.5 多数据源和多目的地案例
- 2.5.1 案例需求
- 2.5.2 案例分析
- 2.5.3 编写脚本文件
- 2.6 多Flume进程组合的案例
- 2.6.1 案例需求
- 2.6.2 案例分析
- 2.6.3 编写脚本文件
- 2.6.4 启动脚本程序
- 三、Hadoop、Hive、SQOOP、Flume、Zookeeper(HA高可用)、Azkaban
8.25笔记
一、Flume数据采集技术
将海量的数据通过某种技术采集到大数据环境中进行存储和管理,为后期的大数据处理分析做准备 常见的数据:网站/软件的运行日志、记录的日志,软件的结构化数据、爬虫数据、传感器采集数据…
Flume是apache开源的顶尖项目,专门是采集和聚合海量的日志数据。但是随着Flume技术的发展,支持很多种其他类型数据源的数据采集。
1.1 Flume实现数据采集主要借助Flume的组成架构
Agent、Source、Channel、Sink、Event、Flume采集脚本xxx.conf
一个agent进程中,可以有多个Source、channel、sink, 其中一个source只能连接一个数据源,一个sink只能连接一个目的地。 而且在一个Flume的agent进程中,一个source采集的数据可以发送给多个channel,但是一个sink只能拉取一个channel的数据。
1.2 Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf
Flume支持多种数据源、管道、目的地,我们采集数据的时候,并不是所有的数据源和目的地都要使用,而是使用我们需要的源头和目的地。但是Flume不知道你需要什么数据源、需要什么目的地。 通过脚本文件指定我们采集的数据源、目的地、管道
1.2.1 脚本文件主要由五部分组成
-
起别名
我们可以根据采集脚本启动一个Flume进程Agent,一个Flume支持启动多个Agent,Flume要求每一个Agent必须有自己的一个别名,Flume启动的多个Agent的别名不能重复。
同时Flume一个Agent进程中,可以有多个source、多个channel、多个sink,如何区分多个组件? 我们还需要多Agent进程中的source、channel、sink起别名的
Agent、source、channel、sink起别名
-
配置Source组件
我们一个Flume进程中,可能存在1个或者多个数据源,每一个source组件需要连接一个数据源,但是数据源到底是谁,如何连接,我们需要配置。
-
配置channel组件
一个Agent中,可能存在一个或者多个channel,channel也有很多种类型的,因此我们需要配置我们channel的类型以及channel的容量
-
配置Sink组件一个Agent,可以同时将数据下沉到多个目的地,一个sink只能连接一个目的地,目的地到底是谁,如何连接,需要配置sink
-
组装source、channel、sink(核心)
一个source的数据可以发送给多个channel,一个sink只能读取一个channel的数据。因此我们需要根据业务逻辑配置source、channel、sink的连接关系。
二、Flume案例实操
2.1 采集一个网络端口的数据到控制台
2.1.1 分析案例的组件类型
- source:网络端口 netcat
- channel:基于内存的管道即可memory
- sink:控制台–Flume的日志输出logger
2.2.2 编写脚本文件portToConsole.conf
# 1、配置agent、source、channel、sink的别名
demo.sources=s1
demo.channels=c1
demo.sinks=k1# 2、配置source组件连接的数据源--不同数据源的配置项都不一样 监听netcat type bind port
demo.sources.s1.type=netcat
demo.sources.s1.bind=localhost
demo.sources.s1.port=44444# 3、配置channel组件的类型--不同类型的管道配置项也不一样 基于内存memory的管道
demo.channels.c1.type=memory
demo.channels.c1.capacity=1000
demo.channels.c1.transactionCapacity=200# 4、配置sink组件连接的目的地--不同类型的sink配置项不一样 基于logger的下沉地
demo.sinks.k1.type=logger# 5、配置source channel sink之间的连接 source连接channel sink也要连接channel
# 一个source的数据可以发送给多个channel 一个sink只能拉取一个channel的数据
demo.sources.s1.channels=c1
demo.sinks1.k1.channel=c1 2.2.3 根据脚本文件启动Flume采集程序
flume-ng agent -n agent的别名(必须和文件中别名保持一致) -f xxx.conf的路径 -Dflume.root.logger=INFO,console
2.2.4 测试
我们只需要给本地的44444端口发送数据,看看Flume的控制台能否把数据输出即可
需要新建一个和Linux的连接窗口,然后使用 telnet localhost 44444 命令连接本地的44444端口发送数据
telnet软件linux默认没有安装,需要使用yum安装一下 yum install -y telnet
必须先启动flume采集程序,再telnet连接网络端口发送数据
2.2 采集一个文件的数据到控制台
2.2.1 案例需求
现在有一个文件,文件源源不断的记录用户的访问日志信息,我们现在想通过Flume去监听这个文件,一旦当这个文件有新的用户数据产生,把数据采集到flume的控制台上
2.2.2 案例分析
source:exec(将一个linux命令的输出导出数据源、自己写监听命令) 、taildir
channel:memory
sink:logger
2.2.3 编写脚本文件
#1、起别名
demo01.sources=s1
demo01.channels=c1
demo01.sinks=k1#2、定义数据源 Spooling Directory Source
demo01.sources.s1.type=spooldir
demo01.sources.s1.spoolDir=/root/demo#3、定义管道
demo01.channels.c1.type=memory
demo01.channels.c1.capacity=1000
demo01.channels.c1.transactionCapacity=200#4、配置sink目的地 logger
demo01.sinks.k1.type=logger#5、关联组件
demo01.sources.s1.channels=c1
demo01.sinks.k1.channel=c1
2.2.4 启动
2.2.5 测试
2.3 采集一个文件夹下的新文件数据到控制台
2.3.1 案例需求
有一个文件夹,文件夹下记录着网站产生的很多日志数据,而且日志文件不止一个,就像把文件夹下所有的文件数据采集到控制台,同时如果这个文件夹下有新的数据文件产生,也会把新文件的数据全部采集到控制台上
2.3.2 案例分析
source:Spooling Directory Source
channel:memory
sink:logger
2.3.3 编写配置文件
#1、起别名
demo01.sources=s1
demo01.channels=c1
demo01.sinks=k1#2、定义数据源 exec linux命令 监听一个文件 tail -f|-F 文件路径
demo01.sources.s1.type=exec
demo01.sources.s1.command=tail -F /root/a.log#3、定义管道
demo01.channels.c1.type=memory
demo01.channels.c1.capacity=1000
demo01.channels.c1.transactionCapacity=200#4、配置sink目的地 logger
demo01.sinks.k1.type=logger#5、关联组件
demo01.sources.s1.channels=c1
demo01.sinks.k1.channel=c1
2.3.4 运行
2.3.5 测试
2.1~2.3:
单source、sink、channel
souece数据源不一样
sink目的地都是一样的
2.4 采集一个网络端口的数据到HDFS中
2.4.1 案例需求
监控一个网络端口产生的数据,一旦当端口产生新的数据,就把数据采集到HDFS上以文件的形式进行存放
2.4.2 案例分析
source:网络端口netcat
channel:基于内存的管道 memory
sink:HDFS
2.4.3 编写脚本文件
启动采集进程(必须先启动HDFS)
# 1、配置agent、source、channel、sink的别名
demo.sources=s1
demo.channels=c1
demo.sinks=k1# 2、配置source组件连接的数据源--不同数据源的配置项都不一样 监听netcat type bind port
demo.sources.s1.type=netcat
demo.sources.s1.bind=localhost
demo.sources.s1.port=44444# 3、配置channel组件的类型--不同类型的管道配置项也不一样 基于内存memory的管道
demo.channels.c1.type=memory
demo.channels.c1.capacity=1000
demo.channels.c1.transactionCapacity=200# 4、配置sink组件连接的目的地--基于HDFS的
demo.sinks.k1.type=hdfs
# 配置采集到HDFS上的目录 数据在目录下以文件的形式进行存放
demo.sinks.k1.hdfs.path=hdfs://single:9000/flume
# 目录下生成的文件的前缀 如果没有配置 默认就是FlumeData
demo.sinks.k1.hdfs.filePrefix=collect
# 指定生成的文件的后缀 默认是没有后缀 生成的文件的格式collect.时间戳.txt
demo.sinks.k1.hdfs.fileSuffix=.txt
# 目录采集的数据并不是记录到一个文件中,文件是会滚动生成新的文件的
# 滚动的规则有三种:1、基于时间滚动 2、基于文件的容量滚动 3、基于文件的记录的event数量进行滚动
# 时间 30s 容量1024b event 10
# 时间滚动规则 单位是s 如果指设置为0 那么就代表不基于时间生成新的文件
demo.sinks.k1.hdfs.rollInterval=60
# 文件容量的滚动规则 单位b 如果设置为0 代表不基于容量滚动生成新的文件
demo.sinks.k1.hdfs.rollSize=100
# event数量滚动规则 一般都设置为0 代表不基于event数量滚动生成新的文件
demo.sinks.k1.hdfs.rollCount=0
# 文件在HDFS上的默认存储格式是SequenceFile文件格式
demo.sinks.k1.hdfs.fileType=DataStream
# 设置event的头部使用本地时间戳作为header
demo.sinks.k1.hdfs.useLocalTimeStamp=true# 5、配置source channel sink之间的连接 source连接channel sink也要连接channel
# 一个source的数据可以发送给多个channel 一个sink只能拉取一个channel的数据
demo.sources.s1.channels=c1
demo.sinks.k1.channel=c1 【注意】flume的依赖的guava和hadoop的guava有冲突,需要将flume的lib目录下的guava依赖删除,同时将hadoop的share/common/lib/guava依赖复制到flume的lib目录下
2.5 多数据源和多目的地案例
2.5.1 案例需求
现在有三个数据源:
- 网络端口
- 文件
- 文件夹
想把这三个数据源的数据全部采集到HDFS的指定目录下,同时还要求把文件数据源的数据在控制台上同步进行展示
2.5.2 案例分析
source:netcat exec spooldir
channel:两个基于内存的
sink:1、hdfs 2、logger
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z29G2KBz-1692957630143)(./8.24/f425ae220d03cd4e9364dc83cd39d4e6c687f929e275b56685ea599b18e98954.png)]](https://img-blog.csdnimg.cn/188423c112b84052b90c45b6ec2ceeaa.png)
2.5.3 编写脚本文件
# 1、起别名 三个数据源 两个管道 两个sink
more.sources=s1 s2 s3
more.channels=c1 c2
more.sinks=k1 k2# 2、定义数据源 三个
# 定义s1数据源 s1连接的网络端口
more.sources.s1.type=netcat
more.sources.s1.bind=localhost
more.sources.s1.port=44444# 定义s2的数据源 s2连接的是一个文件 /root/more.log文件
more.sources.s2.type=exec
more.sources.s2.command=tail -F /root/more.log# 定义s3的数据源 s3监控的是一个文件夹 /root/more
more.sources.s3.type=spooldir
more.sources.s3.spoolDir=/root/more# 3、定义channel 两个 基于内存的
# 定义c1管道 c2管道需要接受三个数据源的数据
more.channels.c1.type=memory
more.channels.c1.capacity=20000
more.channels.c1.transactionCapacity=5000# 定义c2管道 c2管道只需要接受一个数据源 s2的数据
more.channels.c2.type=memory
more.channels.c2.capacity=5000
more.channels.c2.transactionCapacity=500# 4、定义sink 两个 HDFS logger
# 定义k1这个sink 基于hdfs
more.sinks.k1.type=hdfs
# HDFS支持生成动态目录--基于时间的 /more/2023-08-25
more.sinks.k1.hdfs.path=hdfs://single:9000/more/%Y-%m-%d
# 如果设置了动态目录,那么必须指定动态目录的滚动规则-多长时间生成一个新的目录
more.sinks.k1.hdfs.round=true
more.sinks.k1.hdfs.roundValue=24
more.sinks.k1.hdfs.roundUnit=hourmore.sinks.k1.hdfs.filePrefix=collect
more.sinks.k1.hdfs.fileSuffix=.txt
more.sinks.k1.hdfs.rollInterval=0
more.sinks.k1.hdfs.rollSize=134217728
more.sinks.k1.hdfs.rollCount=0
more.sinks.k1.hdfs.fileType=DataStream
more.sinks.k1.hdfs.useLocalTimeStamp=true# 定义k2 logger
more.sinks.k2.type=logger# 5、组合agent的组件
more.sources.s1.channels=c1
more.sources.s2.channels=c1 c2
more.sources.s3.channels=c1
more.sinks.k1.channel=c1
more.sinks.k2.channel=c2
2.6 多Flume进程组合的案例
2.6.1 案例需求
三个Flume进程,其中第一个Flume采集端口的数据,第二个Flume采集文件的数据,要求第一个Flume进程和第二个Flume进程将采集到的数据发送给第三个Flume进程,第三个Flume进程将接受到的数据采集到控制台上。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1CDBUphH-1692957630145)(./8.24/fcb49d25d9bc2d5e9f772e55d7f6a98abea36794b94d2052d80e81af892cf4e0.png)]](https://img-blog.csdnimg.cn/9b1713cdb2ac41e68b6454cb16371b8f.png)
2.6.2 案例分析
- first agent
- source :netcat
- channel:memory
- sink:avro
- second agent
- source:exec
- channel:memory
- sink:avro
- third agent
- source:avro
- channel:memory
- sink:logger
2.6.3 编写脚本文件
第一个脚本监听端口到avro的
first.sources=s1
first.channels=c1
first.sinks=k1first.sources.s1.type=netcat
first.sources.s1.bind=localhost
first.sources.s1.port=44444first.channels.c1.type=memory
first.channels.c1.capacity=1000
first.channels.c1.transactionCapacity=500first.sinks.k1.type=avro
first.sinks.k1.hostname=localhost
first.sinks.k1.port=60000first.sources.s1.channels=c1
first.sinks.k1.channel=c1
第二脚本文件监听文件数据到avro的
second.sources=s1
second.channels=c1
second.sinks=k1second.sources.s1.type=exec
second.sources.s1.command=tail -F /root/second.txtsecond.channels.c1.type=memory
second.channels.c1.capacity=1000
second.channels.c1.transactionCapacity=500second.sinks.k1.type=avro
second.sinks.k1.hostname=localhost
second.sinks.k1.port=60000second.sources.s1.channels=c1
second.sinks.k1.channel=c1
第三个脚本文件监听avro汇总的数据到logger的
third.sources=s1
third.channels=c1
third.sinks=k1# avro类型当作source 需要 bind和port参数 如果当作sink使用 需要hostname port
third.sources.s1.type=avro
third.sources.s1.bind=localhost
third.sources.s1.port=60000third.channels.c1.type=memory
third.channels.c1.capacity=1000
third.channels.c1.transactionCapacity=500third.sinks.k1.type=loggerthird.sources.s1.channels=c1
third.sinks.k1.channel=c1
2.6.4 启动脚本程序
先启动第三个脚本,再启动第一个和第二脚本
三、Hadoop、Hive、SQOOP、Flume、Zookeeper(HA高可用)、Azkaban
相关文章:
实训笔记8.25
实训笔记8.25 8.25笔记一、Flume数据采集技术1.1 Flume实现数据采集主要借助Flume的组成架构1.2 Flume采集数据的时候,核心是编写Flume的采集脚本xxx.conf1.2.1 脚本文件主要由五部分组成 二、Flume案例实操2.1 采集一个网络端口的数据到控制台2.1.1 分析案例的组件…...

vue自定义监听元素宽高指令
在 main.js 中添加 // 自定义监听元素高度变化指令 const resizerMap new WeakMap() const resizeObserver new ResizeObserver((entries) > {for (const entry of entries) {const handle resizerMap.get(entry.target)if (handle) {handle({width: entry.borderBoxSiz…...

网络爬虫到底是个啥?
网络爬虫到底是个啥? 当涉及到网络爬虫技术时,需要考虑多个方面,从网页获取到最终的数据处理和分析,每个阶段都有不同的算法和策略。以下是这些方面的详细解释: 网页获取(Web Crawling)&#x…...
前端行级元素和块级元素的基本区别
块级元素和行内元素的基本区别是, 行内元素可以与其他行内元素并排;块级元素独占一行,不能与其他任何元素并列; 下面看一下; <!DOCTYPE html> <html> <head> <meta charset"utf-8"&…...

CentOS 7用二进制安装MySQL5.7
[rootlocalhost ~]# [rootlocalhost ~]# ll 总用量 662116 -rw-------. 1 root root 1401 8月 29 19:29 anaconda-ks.cfg -rw-r--r--. 1 root root 678001736 8月 29 19:44 mysql-5.7.40-linux-glibc2.12-x86_64.tar.gz [rootlocalhost ~]# tar xf mysql-5.7.40-linux-…...

华为加速回归Mate 60发布, 7nm全自研工艺芯片
华为于今天12:08推出“HUAWEI Mate 60 Pro先锋计划”,让部分消费者提前体验。在华为商城看到,华为Mate 60 pro手机已上架,售价6999元,提供雅川青、白沙银、南糯紫、雅丹黑四种配色供选择。 据介绍,华为在卫星通信领域…...

Linux系列讲解 —— 【systemd】下载及编译记录
Ubuntu18.04的init程序合并到了systemd中,本篇文章记录一下systemd的下载和编译。 1. 下载systemd源码 (1) 查看systemd版本号,用来确定需要下载的分支 sunsun-pc:~$ systemd --version systemd 237 PAM AUDIT SELINUX IMA APPARMOR SMACK SYSVINIT UT…...
u-view 的u-calendar 组件设置默认日期后,多次点击后,就不滚动到默认日期的位置
场景:uniapp开发微信小程序 vue2 uview版本:2.0.36 ; u-calendar 组件设置默认日期后 我打开弹窗,再关闭弹窗, 重复两次 就不显示默认日期了 在源码中找到这个位置进行打印值,根据出bug前后的值进行…...

vue naive ui 按钮绑定按键
使用vue (naive ui) 绑定Enter 按键 知识点: 按键绑定Button全局挂载使得message,notification, dialog, loadingBar 等NaiveUI 生效UMD方式使用vue 与 naive ui将vue默认的 分隔符大括号 替换 为 [[ ]] <!DOCTYPE html> <html lang"en"> <head>…...
Viobot基本功能使用及介绍
设备拿到手当然是要先试一下效果的,这部分可以参考本专栏的第一篇 Viobot开机指南。 接下来我们就从UI开始熟悉这个产品吧! 1.状态 设备上电会自动运行它的程序,开启了一个服务器,上位机通过连接这个服务器连接到设备,…...

《PMBOK指南》第七版12大原则和8大绩效域
《PMBOK指南》第七版12大原则 原则1:成为勤勉、尊重和关心他人的管家 原则2:营造协作的项目团队环境 原则3:有效地干系人参与 原则4:聚焦于价值 原则5:识别、评估和响应系统交互 原则6:展现领导力行为…...

docker 启动命令
cd /ycw/docker docker build -f DockerFile -t jshepr:1.0 . #前面测试docker已经介绍过该命令下面就不再介绍了 docker images docker run -it -p 7003:9999 --name yyy -d jshepr:1.0 #上面运行报错 用这个 不报错就不用 docker rm yyy docker ps #查看项目日志 docker …...
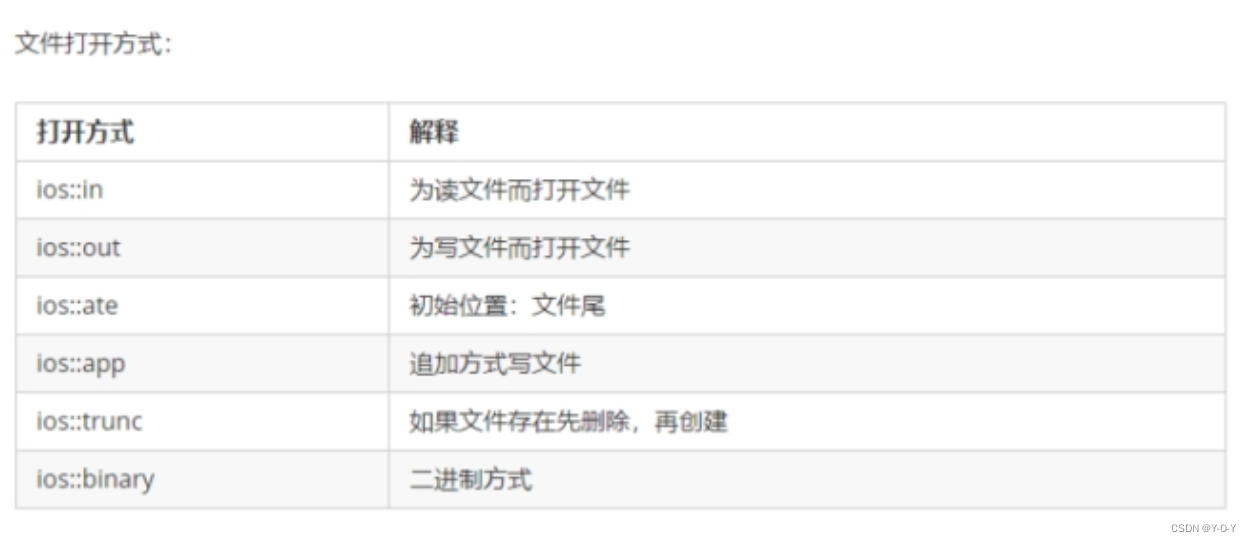
C++ DAY7
一、类模板 建立一个通用的类,其类中的类型不确定,用一个虚拟类型替代 template<typename T> 类template ----->表示开始创建模板 typename -->表明后面的符号是数据类型,typename 也可以用class代替 T ----->表示数据类型…...

Vue2 使用插件 Volar 报错:<template v-for> key should be placed on the <template> tag.
目录 问题描述 版本描述 问题定位 问题解决 VS Code 插件地址 问题描述 在 VS Code 上使用插件 Volar 开发 Vue3 项目,然后去改 Vue2 项目时,对没有放在<template v-for> 元素上的 :key,会提示 <template v-for> key should…...
和 run ()有什么区别)
启动线程方法 start ()和 run ()有什么区别
在Java中,线程可以通过调用start()方法或者直接调用run()方法来执行。这两种方式有着重要的区别: start() 方法:当你调用线程的start()方法时,它会使线程进入就绪状态,等待系统调度。系统会为该线程分配资源,并在合适的时机执行线程的run()方法。实际上,start()方法会启…...

Java的全排列模板
c有全排列函数,我们Java没有,所以我们只能自己手写了。 模板一:(不去重) import java.util.ArrayList; import java.util.Random; import java.util.Scanner; public class liyunpeng {public static void main(Stri…...
读书笔记——《万物有灵》
前言 上一本书是《走出荒野》,太平洋步道女王提到了这本书《万物有灵》,她同样是看一点撕一点的阅读。我想,在她穿越山河森林,听见鸟鸣溪流的旅行过程中,是不是看这本描写动物有如何聪明的书——《万物有灵》…...

面试现场表现:展示你的编程能力和沟通技巧
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

34亿的mysql表如何优雅的扩字段长度兵并归档重建
业务背景: 该系统有一张表数据量已达到34亿,并且有个字段长度不够,导致很多数据无法插入。因为业务只要保留近2个月数据即可,所以需要接下来需要做2点:1,扩字段长度 2,只保留近2个月的数据。 …...
C#_进程单例模式.秒懂Mutex
什么是Mutex? 可以定义调用线程是否具有互斥性,程序创建者拥有控制权,相反只能引用程序。 参数1:如果是程序创建者,就获得控制权。 参数2:名称,可使用GUID生成。 参数3:out 返回值…...

第11章:故障诊断与处理
第11章:故障诊断与处理 11.1 常见故障类型与原因 集群级故障 故障类型 症状 常见原因 集群Red 存在未分配的主分片 节点故障、磁盘满、分片损坏 集群Yellow 存在未分配的副本分片 节点不足、磁盘满、副本数过多 集群脑裂 多个Master节点 网络分区、Master配置错误 集群无响应…...
亲测靠谱的AI论文网站,毕业生收藏备用)
(良心整理)亲测靠谱的AI论文网站,毕业生收藏备用
毕业季论文写作真的这么难吗?选题卡壳、文献翻不完、写不下去、查重过不了、格式总不对…… 这份亲测靠谱的AI论文工具合集,涵盖中英文写作、全流程辅助和专项功能,免费和高性价比都有,从开题到定稿全程帮你搞定,毕业生…...

开源数据库 TimescaleDB 2.27.1 发布:性能改进与多项错误修复,官方建议尽快升级
开源数据库 TimescaleDB 2.27.1 版本正式发布,较 2.27.0 版本有性能改进和错误修复,官方建议用户尽快升级。 TimescaleDB 简介 TimescaleDB 是基于 PostgreSQL 构建的开源数据库,打包为 PostgreSQL 扩展程序,可让 SQL 扩展到时间序…...

利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题 对于依赖Claude Code进行日常开发的工程师而言,服…...

Cocos学习笔记:帧动画制作与动画编辑器使用
一、帧动画基础原理核心逻辑:帧动画本质是逐帧替换精灵(Sprite)的显示图片,通过控制图片切换频率,让静态序列图呈现连续动态效果。视觉原理:人眼存在视觉残留特性,短时间内连续播放 24 帧以上图…...

别再让治具压坏你的板子!手把手教你用TSK-64应力测试仪搞定ICT/FCT应力管控
从应力失控到精准管控:TSK-64测试仪在ICT/FCT产线的实战指南 当产线突然出现批量PCBA功能异常时,多数工程师的第一反应是检查焊接质量或元器件性能,却往往忽略了治具施加的机械应力这个"隐形杀手"。某汽车电子制造商曾因FCT治具压力…...
)
ElevenLabs客家话语音合规红线预警:GDPR+《生成式AI服务管理暂行办法》双框架下,3类方言数据采集授权漏洞与2种语音指纹脱敏方案(含可审计代码模板)
更多请点击: https://codechina.net 第一章:ElevenLabs客家话语音合规红线预警总览 ElevenLabs 作为前沿的AI语音合成平台,其多语言支持能力持续扩展,但对客家话等非标准化方言的生成存在明确的合规边界。平台未将客家话列入官方…...

长期使用 Taotoken Token Plan 套餐在成本控制方面的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken Token Plan 套餐在成本控制方面的实际感受 1. 从按需付费到计划订阅的转变 最初接触 Taotoken 时,…...

KaTrain终极指南:用AI围棋教练快速提升你的棋艺水平
KaTrain终极指南:用AI围棋教练快速提升你的棋艺水平 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 你是否曾经在对局后感到困惑,不知道自己的失误究竟在哪…...

【独家首发】ElevenLabs未公开的粤语语音增强技巧:3个隐藏prompt指令+2个音频后处理脚本
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广东话语音合成的技术边界与本地化挑战 ElevenLabs 作为全球领先的语音合成平台,其多语言支持能力广受关注,但粤语(广东话)尚未被官方列为正式…...