深度学习10:Attention 机制
目录
Attention 的本质是什么
Attention 的3大优点
Attention 的原理
Attention 的 N 种类型
Attention 的本质是什么
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。

Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。大家看一下下面这张图:我们一定会看清「锦江饭店」4个字,如下图:

但是我相信没人会意识到「锦江饭店」上面还有一串「电话号码」,也不会意识到「喜运来大酒家」,如下图:

所以,当我们看一张图片的时候,其实是这样的:

上面所说的,我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
AI 领域的 Attention 机制
Attention 机制最早是在计算机视觉里应用的,随后在 NLP 领域也开始应用了
如果用图来表达 Attention 的位置大致是下面的样子:

这里先让大家对 Attention 有一个宏观的概念,下文会对 Attention 机制做更详细的讲解。在这之前,我们先说说为什么要用 Attention。
Attention 的3大优点
之所以要引入 Attention 机制,主要是3个原因:
- 参数少
- 速度快
- 效果好
参数少
模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
速度快
Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
效果好
在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的预期就是被挑出来的重点。
Attention 的原理
下面的动图演示了attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。
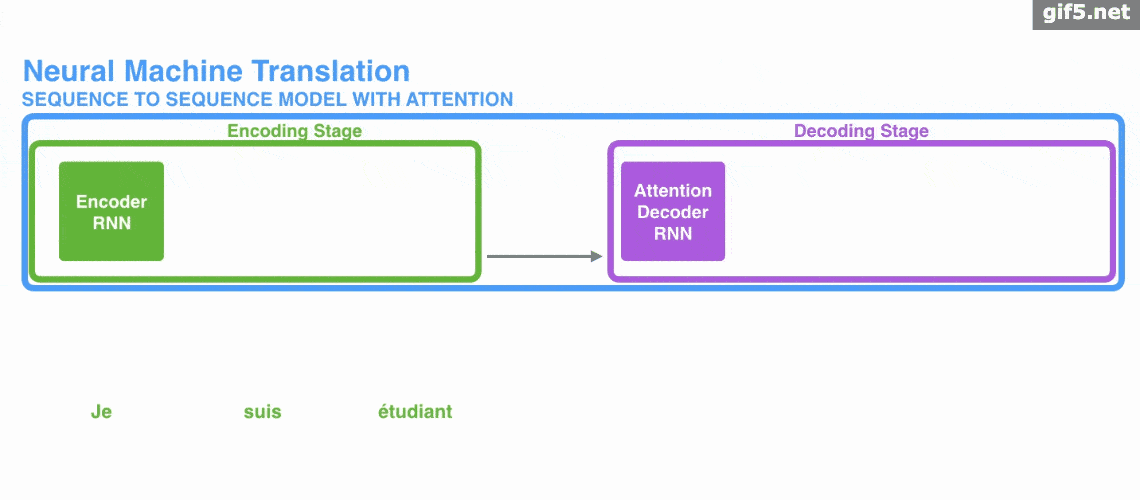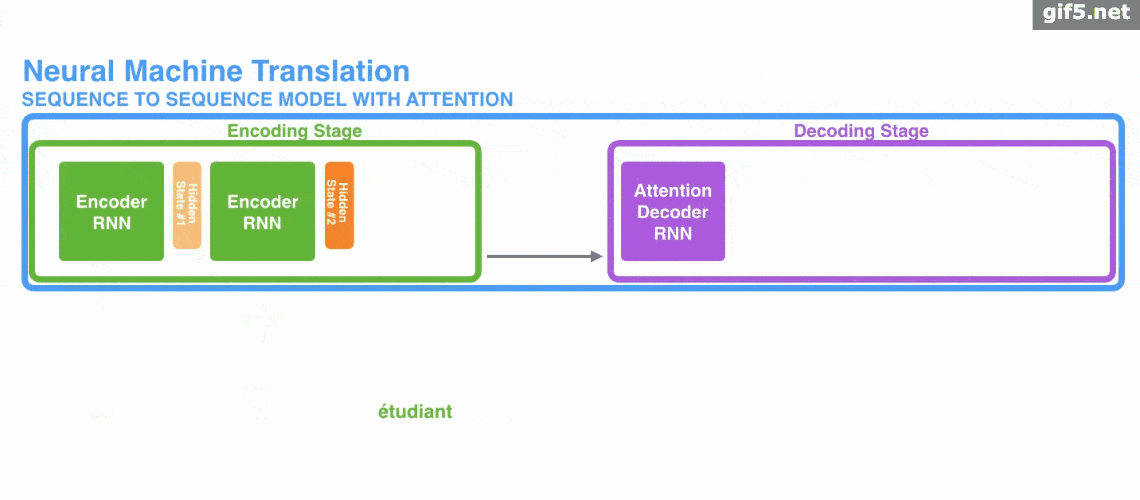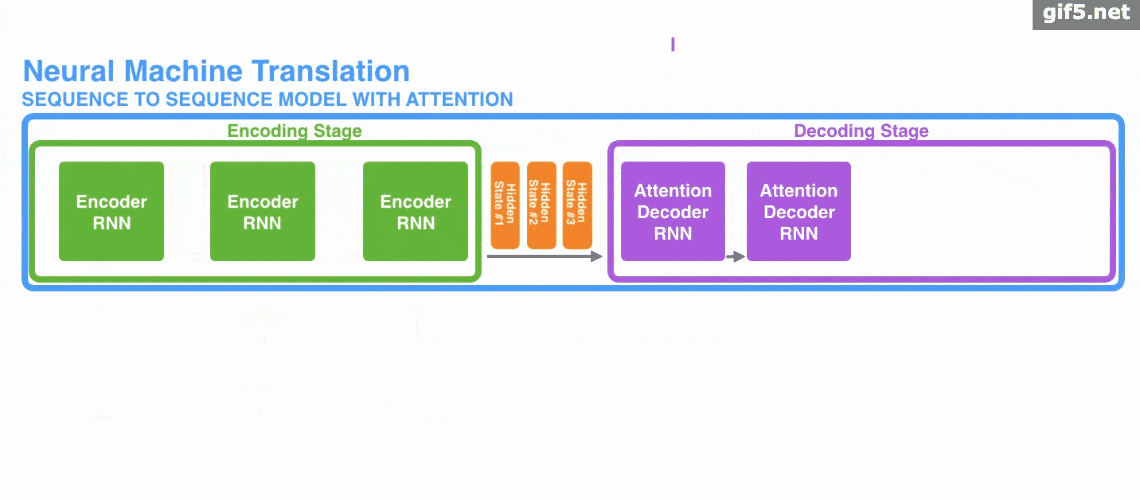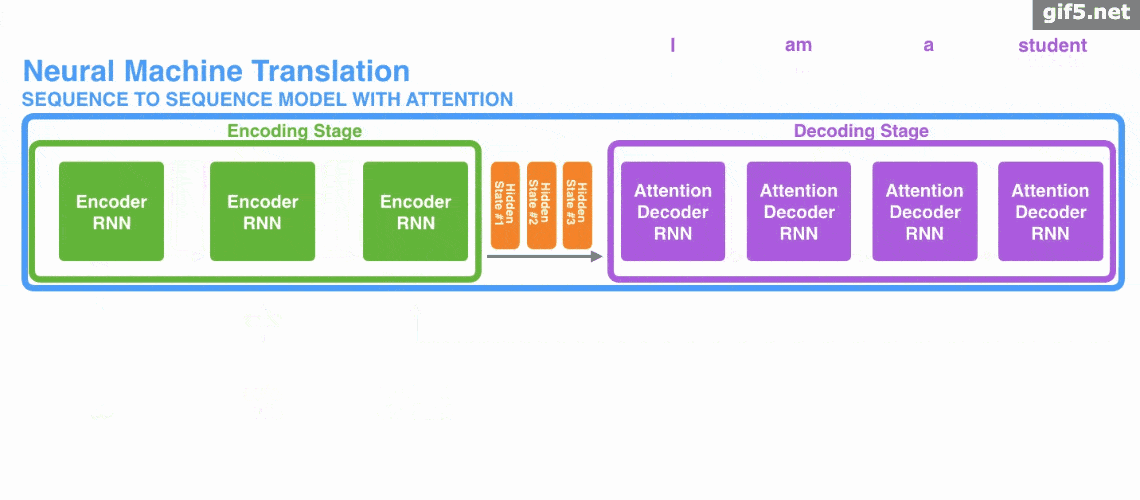
但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。
下面的图片则是脱离 Encoder-Decoder 框架后的原理图解。
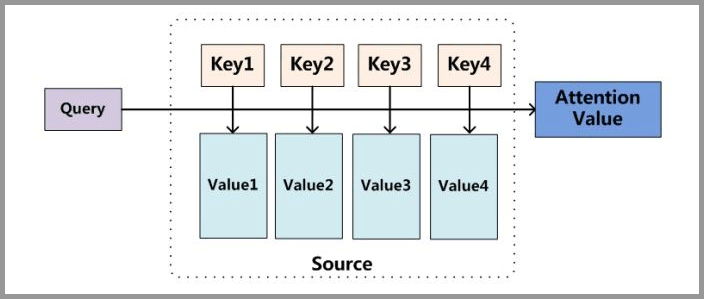
小故事讲解
上面的图看起来比较抽象,下面用一个例子来解释 attention 的原理:
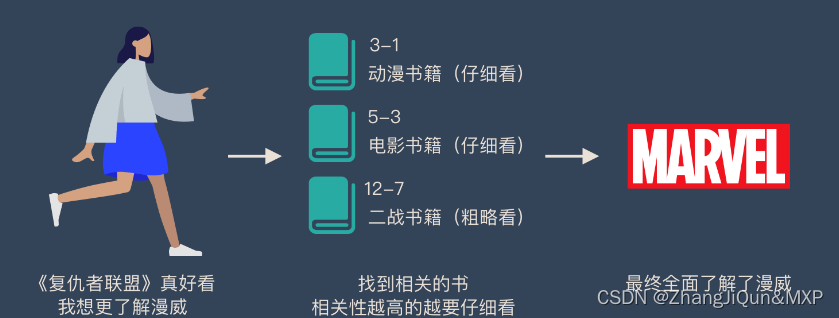
图书管(source)里有很多书(value),为了方便查找,我们给书做了编号(key)。当我们想要了解漫威(query)的时候,我们就可以看看那些动漫、电影、甚至二战(美国队长)相关的书籍。
为了提高效率,并不是所有的书都会仔细看,针对漫威来说,动漫,电影相关的会看的仔细一些(权重高),但是二战的就只需要简单扫一下即可(权重低)。
当我们全部看完后就对漫威有一个全面的了解了。
Attention 原理的3步分解:
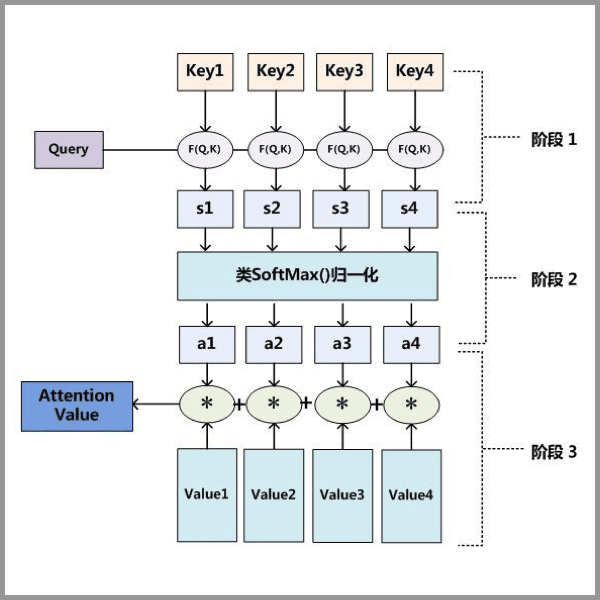
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
从上面的建模,我们可以大致感受到 Attention 的思路简单,四个字“带权求和”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感)->提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)->融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)->登峰造极(沉浸地大量练习)。
这也如同attention的发展脉络,RNN 时代是死记硬背的时期,attention 的模型学会了提纲挈领,进化到 transformer,融汇贯通,具备优秀的表达学习能力,再到 GPT、BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。
要回答为什么 attention 这么优秀?是因为它让模型开窍了,懂得了提纲挈领,学会了融会贯通。
想要了解更多技术细节,可以看看下面的文章或者视频:
「文章」深度学习中的注意力机制
「文章」遍地开花的 Attention,你真的懂吗?
「文章」探索 NLP 中的 Attention 注意力机制及 Transformer 详解
「视频」李宏毅 – transformer
「视频」李宏毅 – ELMO、BERT、GPT 讲解
Attention 的 N 种类型
Attention 有很多种不同的类型:Soft Attention、Hard Attention、静态Attention、动态Attention、Self Attention 等等。下面就跟大家解释一下这些不同的 Attention 都有哪些差别。
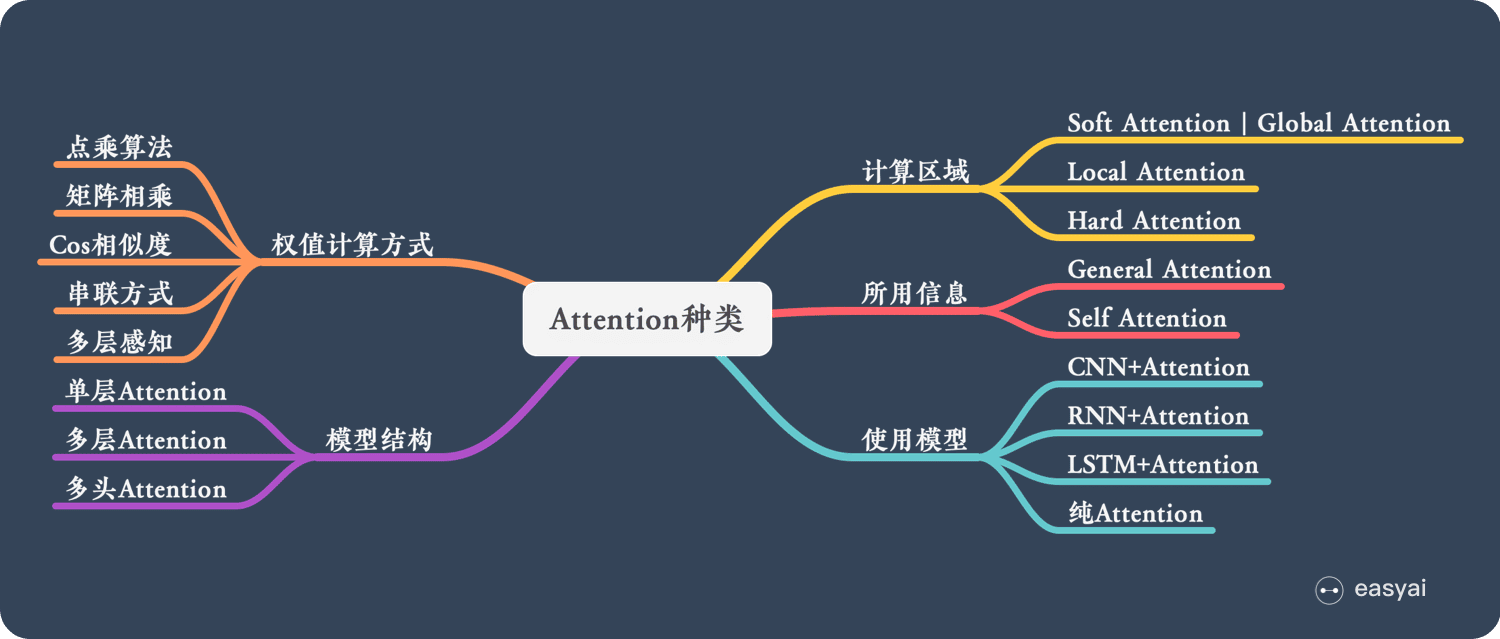
由于这篇文章《Attention用于NLP的一些小结》已经总结的很好的,下面就直接引用了:
本节从计算区域、所用信息、结构层次和模型等方面对Attention的形式进行归类。
1. 计算区域
根据Attention的计算区域,可以分成以下几种:
1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
2. 所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算attention,这里问题属于原文,文章词向量就属于外部信息。
2)Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
3. 结构层次
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:
![]()
最后再把这些结果拼接起来:
![]()
4. 模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
1)CNN+Attention
CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。
另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
a. 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
2)LSTM+Attention
LSTM内部有Gate机制(GATE:高效处理表格数据的深度学习架构),
其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息
我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有:
a. 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
3)纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
5. 相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
1)点乘:最简单的方法,
![]()
2)矩阵相乘:
![]()
3)cos相似度:

4)串联方式:把q和k拼接起来,
![]()
5)用多层感知机也可以:
![]()
相关文章:
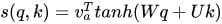
深度学习10:Attention 机制
目录 Attention 的本质是什么 Attention 的3大优点 Attention 的原理 Attention 的 N 种类型 Attention 的本质是什么 Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。 Attention…...
)
简单着色器编写(中下)
这篇我们来介绍另一部分函数。 static unsigned int CreateShader(const std::string& vertexShader, const std::string& fragmentShader) {unsigned int program glCreateProgram();unsigned int vs CompileShader(GL_VERTEX_SHADER,vertexShader);unsigned int f…...
matlab使用教程(24)—常微分方程(ODE)求解器
1.常微分方程 常微分方程 (ODE) 包含与一个自变量 t(通常称为时间)相关的因变量 y 的一个或多个导数。此处用于表示 y 关于 t 的导数的表示法对于一阶导数为 y ′ ,对于二阶导数为 y ′′,依此类推。ODE 的阶数等于 y 在方程中…...

企业级数据共享规模化模式
数据共享正在成为企业数据战略的重要元素。对于公司而言,Amazon Data Exchange 这样的亚马逊云科技服务提供了与其他公司共享增值数据或从这些数据获利的途径。一些企业希望有一个数据共享平台,他们可以在该平台上建立协作和战略方法,在封闭、…...
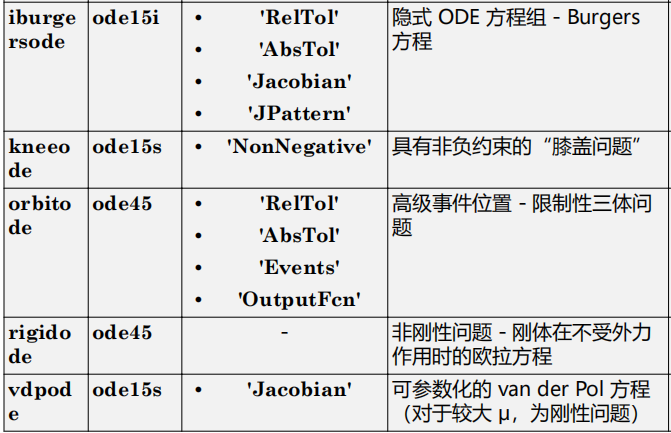
Web服务器-Tomcat详细原理与实现
Tomcat 安装与使用 :MAC 安装配置使用Tomcat - 掘金 安装后本计算机就相当于一台服务器了!!! 方式一:使用本地安装的Tomcat 1、将项目文件移动到Tomcat的webapps目录下。 2、启动Tomcat 3、在浏览器输入想要加载的…...
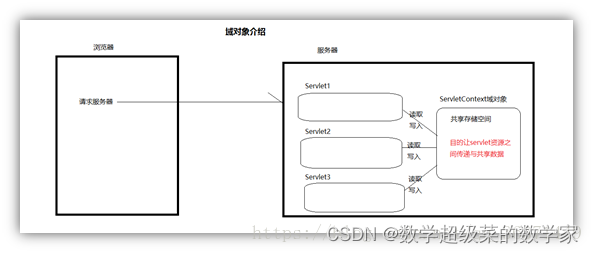
ARM处理器核心概述
一、基于ARM处理器的嵌入式系统 ARM核深度嵌入SOC中,通过JTAG口进行外部调试。计通常既有外部内存又有内部内存,从而支持不通的内存宽度、速度和大小。一般会包含一个中断控制器。可能包含一些Primece外设,需要从ARM公司取得授权。总线使用A…...
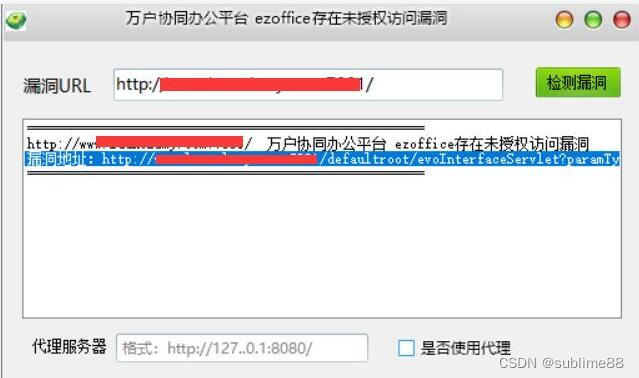
万户协同办公平台 ezoffice存在未授权访问漏洞 附POC
文章目录 万户协同办公平台 ezoffice存在未授权访问漏洞 附POC1. 万户协同办公平台 ezoffice简介2.漏洞描述3.影响版本4.fofa查询语句5.漏洞复现6.POC&EXP7.整改意见8.往期回顾 万户协同办公平台 ezoffice存在未授权访问漏洞 附POC 免责声明:请勿利用文章内的相…...
使用ctcloss训练矩阵生成目标字符串
首先我们需要明确 c t c l o s s ctcloss ctcloss是用来做什么的。比如说要生成的目标字符串长度为 l l l,而这个字符串包含 s s s个字符,字符串允许的最大长度为 L L L,这里认为一个位置是一个时间步,就是一拍,记为 T…...
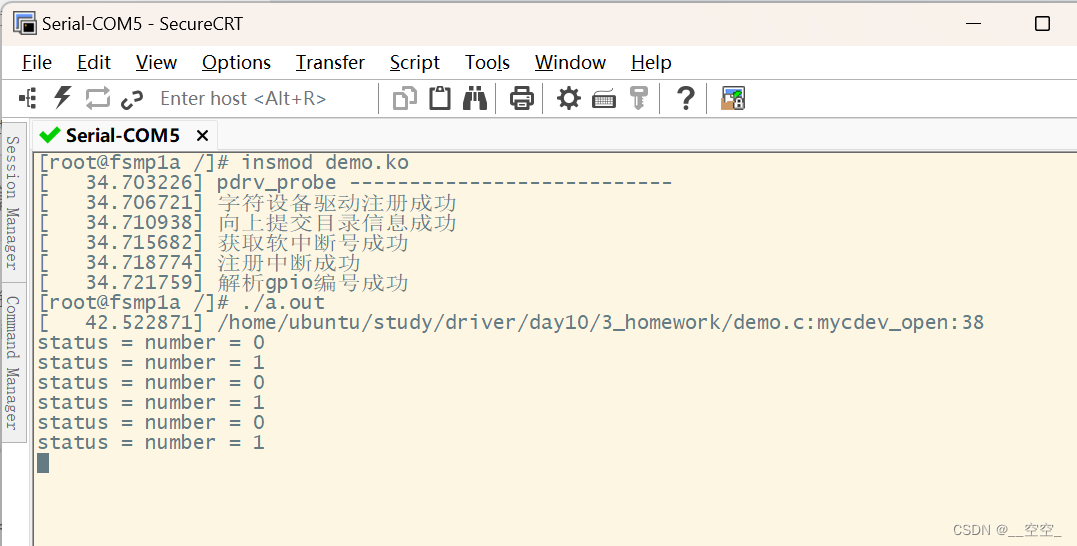
驱动 - 20230829
练习 基于platform实现 在根节点下,增加设备树 myplatform {compatible"hqyj,myplatform";interrupts-extended<&gpiof 9 0>, <&gpiof 7 0>, <&gpiof 8 0>;led1-gpio<&gpioe 10 0>;reg<0x12345678 59>;}…...

数组(个人学习笔记黑马学习)
一维数组 1、定义方式 #include <iostream> using namespace std;int main() {//三种定义方式//1.int arr[5];arr[0] 10;arr[1] 20;arr[2] 30;arr[3] 40;arr[4] 50;//访问数据元素/*cout << arr[0] << endl;cout << arr[1] << endl;cout &l…...

layui表格事件分析实例
在 layui 的表格组件中,区分表头事件和行内事件是通过事件类型(toolbar 和 tool)以及 lay-filter 值来实现的。 我们有一个表格,其中有一个工具栏按钮和操作按钮。我们将使用 layui 的 table 组件来处理这些事件。 HTML 结构&…...

Android NDK JNI与Java的相互调用
一、Jni调用Java代码 jni可以调用java中的方法和java中的成员变量,因此JNIEnv定义了一系列的方法来帮助我们调用java的方法和成员变量。 以上就是jni调用java类的大部分方法,如果是静态的成员变量和静态方法,可以使用***GetStaticMethodID、CallStaticObjectMethod等***。就…...

装备制造企业如何执行精益管理?
导 读 ( 文/ 2358 ) 精益管理是一种以提高效率、降低成本和优化流程为目标的管理方法。装备制造行业具备人工参与度高,产成品价值高,质量要求高的特点。 在装备制造企业中实施精益管理可以帮助企业提高竞争力、提升生产效率并提供高质量的产品。本文将…...

PHP8中自定义函数-PHP8知识详解
1、什么是函数? 函数,在英文中的单词是function,这个词语有功能的意思,也就是说,使用函数就是在编程的过程中,实现一定的功能。即函数就是实现一定功能的一段特定代码。 在前面的教学中,我们已…...

虚拟化技术:云计算发展的核心驱动力
文章目录 虚拟化技术的概念和作用虚拟化技术的优势虚拟化技术对未来发展的影响结论 🎉欢迎来到AIGC人工智能专栏~虚拟化技术:云计算发展的核心驱动力 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客🎈该系…...

光伏+旅游景区
传统化石燃料可开发量逐渐减少,并且对环境造成的危害日益突出。全世界都把目光投向了可再生能源,希望可再生能源能够改变人类的能源结构。丰富的太阳能取之不尽、用之不竭,同时对环境没有影响,光伏发电是近些年来发展最快…...
)
手搓文本向量数据库(自然语言搜索生成模型)
import paddle import jieba import pandas as pd import numpy as np import os from glob import glob from multiprocessing import Process, Manager, freeze_supportfrom tqdm import tqdm# 首先 确定的是输出的时候一定要使用pd.to_pickle() pd.read_pickle() # 计算的时…...

EVO大赛是什么
价格是你所付出的东西,而价值是你得到的东西 EVO大赛是什么? “EVO”大赛全称“Evolution Championship Series”,是北美最高规格格斗游戏比赛,大赛正式更名后已经连续举办12年,是全世界最大规模的格斗游戏赛事。常见…...

linux中使用clash代理
本机环境:ubuntu16 安装代理工具(这里使用clash) 可以手动下载解压,下载地址:https://github.com/Dreamacro/clash 也可以直接使用命令行,演示如下: userlocalhost:~$ curl https://glados.r…...
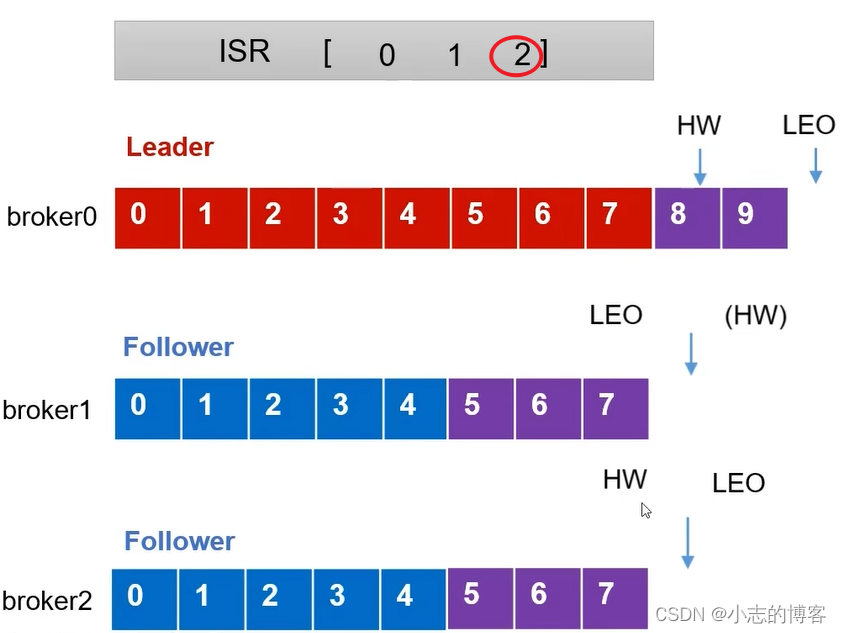
Kafka3.0.0版本——Follower故障处理细节原理
目录 一、服务器信息二、服务器基本信息及相关概念2.1、服务器基本信息2.2、LEO的概念2.3、HW的概念 三、Follower故障处理细节 一、服务器信息 三台服务器 原始服务器名称原始服务器ip节点centos7虚拟机1192.168.136.27broker0centos7虚拟机2192.168.136.28broker1centos7虚拟…...

随身移动文件工作站 金士顿高速移动固态系列
当下移动办公已成为职场人的常态,无论是商务会谈时给客户演示视频、设计文件,还是户外创作时调取海量素材,亦或是日常通勤中处理微信接收的各类文件,都离不开高效的文件存储与传输支持。但现实中的痛点却屡屡困扰着大家࿱…...

论完善代码版本信息构建AI在精工产业与智能设备短板—东方仙盟
出众的现代 AI时至今日,人工智能发展日新月异。在 UI 设计、网页开发、纯软件系统搭建等不依托实体硬件的领域,AI 表现已然成熟。常规信息化工作,AI 皆可独立完成,效率出众,为日常开发与设计减负良多。精工硬件领域 AI…...

极域电子教室破解指南:快速恢复电脑控制权的完整方案
极域电子教室破解指南:快速恢复电脑控制权的完整方案 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾经在学校的计算机教室中,面对被极域电子教室…...

GBase 8c存储过程调试接口使用指南
本文针对南大通用 GBase 8c 数据库,围绕存储过程的使用与问题定位,基于 DBE_PLDEBUGGER 调试接口,详细说明存储过程调试的核心接口、标准流程、常用命令与完整实战操作步骤,帮助用户快速掌握调试方法,高效定位与解决存…...

告别claude code封号烦恼使用taotoken稳定密钥与聚合接口的配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 告别Claude Code封号烦恼使用Taotoken稳定密钥与聚合接口的配置指南 对于依赖Claude Code进行编程辅助的开发者而言,直…...
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是…...

终极指南:如何在Windows上简单快速实现SSH远程文件系统挂载
终极指南:如何在Windows上简单快速实现SSH远程文件系统挂载 【免费下载链接】sshfs-win SSHFS For Windows 项目地址: https://gitcode.com/gh_mirrors/ss/sshfs-win SSHFS-Win是一个革命性的开源工具,它让你能够在Windows操作系统中通过SSH协议直…...

【Lovable开发者私藏资源包】:含官方未公开API文档、调试插件源码与CI/CD配置清单
更多请点击: https://kaifayun.com 第一章:Lovable应用开发完整教程 Lovable 是一个面向现代 Web 应用的轻量级响应式框架,专为构建高交互性、可访问性强且易于维护的单页应用(SPA)而设计。它不依赖虚拟 DOMÿ…...

3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包
3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对一个…...

告别数据锁定:用youdaonote-pull实现有道云笔记的本地化自由
告别数据锁定:用youdaonote-pull实现有道云笔记的本地化自由 【免费下载链接】youdaonote-pull 📝 一个一键导出 / 备份「有道云笔记」所有笔记的 Python 脚本。 A Python script to export/backup all the notes of the "Youdao Note". 项目…...