手搓文本向量数据库(自然语言搜索生成模型)
import paddle
import jieba
import pandas as pd
import numpy as np
import os
from glob import glob
from multiprocessing import Process, Manager, freeze_supportfrom tqdm import tqdm# 首先 确定的是输出的时候一定要使用pd.to_pickle() pd.read_pickle()
# 计算的时候可以使用 gpu 计算和cpu 计算两种
# str_to_voc_id 的时候使用 cpu pandas merge 等
# voc_id_to_encoder 可以使用任何的方法,当前使用 sin 和 位置码 代替em 后期使用em
# 相似计算方法 后期实现更多方法
# 且要加上多进程 ,后期会增加 ,内存自动检测分块策略
class SearchTensorDataSet:def __init__(self, data_set_name, data_voc_name):""":param data_set_name: 存储pandas_pickle 的 向量数据:param data_voc_name: 存储pandas_pickle 的 词表"""if os.path.exists(data_set_name):self.read_data_set(data_set_name)self.current_data_set_name = data_set_nameelse:assert data_set_nameif os.path.exists(data_voc_name):self.read_data_voc(data_voc_name)self.current_data_voc_name = data_voc_nameelse:assert data_voc_nameself.voc_to_tensor = VocToTensor()def read_data_set(self, read_data_set_name):""":param read_data_set_name: 存储pandas_pickle 的 向量数据:return:"""data_set_paths = glob(read_data_set_name + "/*")data_set_df_next_voc_id = []data_set_df_next_voc = []data_set_df_up_voc_id = []data_set_df_up_voc = []for one_paths in tqdm(data_set_paths):if "up" in one_paths:data_set = pd.read_pickle(one_paths)data_set_df_up_voc+=data_set["voc"]data_set_df_up_voc_id.append(np.vstack(data_set["voc_id"]))else:data_set = pd.read_pickle(one_paths)data_set_df_next_voc += data_set["voc"]data_set_df_next_voc_id.append(np.vstack(data_set["voc_id"]))self.data_set = [{"voc":data_set_df_up_voc,"voc_id":data_set_df_up_voc_id}, {"voc":data_set_df_next_voc,"voc_id":data_set_df_next_voc_id}]def read_data_voc(self, read_data_voc_name):""":param read_data_voc_name:voc 词表路径:return:“”"""self.voc_table = pd.read_pickle(read_data_voc_name)self.voc_table=pd.DataFrame({"voc":self.voc_table["voc_id"],"voc_id":list(range(len(self.voc_table["voc_id"])))})def search_data(self, text, top):"""计算 dot 排序 取值 而后 top 个 而后分别计算出 top 的前后相关top 倒数第一内的 上下相关文个数而后 使用这个值进行排序方可要可以加载和区分数据 上下的库:param text::param top::return:"""voc_id = self.voc_to_tensor.text_to_voc(text, self.voc_table)voc_tensor = self.voc_to_tensor.voc_to_tensor(voc_id["voc_id"],em_dim=8)self.dot_top(self.data_set,voc_tensor,top)def dot_top(self, dat_set, vot,stop):""":param dat_set::param vot::return:"""vector_database_up,vector_database_next =dat_setinput_vector = vot# 使用paddle 定会炸内存score=np.dot(np.vstack(vector_database_next["voc_id"]), input_vector[-1])arg_index=np.argsort(score)[:stop]one_score=[score[i] for i in arg_index]# np.dot(input_vector[-1, :8], np.vstack(vector_database_up["voc_id"]))# res = paddle.dot(paddle.zeros(np.vstack(vector_database_up["voc_id"]).shape) + paddle.to_tensor(input_vector).reshape([1, -1]),# paddle.to_tensor(vector_database_up).astype("float32"))one_text=[vector_database_next["voc"][i] for i in arg_index]top_nc=[]for two in one_text:voc_id = self.voc_to_tensor.text_to_voc(two, self.voc_table)voc_tensor = self.voc_to_tensor.voc_to_tensor(voc_id["voc_id"], em_dim=8)up_score = np.dot(np.vstack(vector_database_up["voc_id"]), voc_tensor[-1])next_score = np.dot(np.vstack(vector_database_next["voc_id"]), voc_tensor [-1])nc = sum(up_score<max(one_score))*sum(next_score<max(one_score))top_nc.append(nc)print(nc,two)print(top_nc)class VocToTensor:def __init__(self):passdef voc_to_tensor(self, voc_id, em='sample_for_sin', em_dim=512):""":param voc_id::param em: em_func:param em_dim: 隐藏层维度:return:"""if "sample_for_sin" in em:return self.local_for_sin_encoder_one(voc_id, em_dim)@staticmethoddef local_for_sin_encoder_one(voc_id, em_dim, device="gpu"):""":param voc_id::param em_dim::return:"""if device == "cpu":voc_id_sample = np.linspace(0, np.expand_dims(voc_id.values, 0), em_dim).transpose([2, 1, 0])add = 0for i in range(voc_id_sample.shape[1]):one = voc_id_sample[:, i:i + 1]add = np.sin(one + add)return add.squeeze(1).astype("float16")else:voc_id_sample = np.linspace(0, np.expand_dims(voc_id.values, 0), em_dim).transpose([2, 1, 0])voc_id_sample = paddle.to_tensor(voc_id_sample, dtype="float32")add = 0for i in range(voc_id_sample.shape[1]):one = voc_id_sample[:, i:i + 1]add = paddle.sin(one + add)return add.squeeze(1).numpy().astype("float16")@staticmethoddef text_to_voc(search_text, voc_table):""":param search_text: 被搜的文本:param voc_table: 被搜的文本:return: voc_id"""one_data = "".join(search_text.split())one_data = list(jieba.cut(one_data))one_i = pd.DataFrame({"voc": one_data})voc_idf_one = voc_table[voc_table["voc"].isin(one_i["voc"])]one_id = pd.merge(one_i, voc_idf_one, on="voc", how="left")return one_idclass GenVocTensorForDataSet:def __init__(self):self.voc_to_tensor = VocToTensor()@staticmethoddef gen_data_voc(data_v, data_voc_list):""":param data_v::param data_voc_list::return:"""set_list = set()for one_path in tqdm(data_v):with open(one_path, "r", encoding="utf-8") as f:dataa = f.read()dataa = "".join(dataa.split())set_list |= set(jieba.cut(dataa))data_voc_list.append(set_list)def gen_voc_run(self, voc_name, voc_root_dir, works_num=16):""":param voc_name: voc pandas pickle 表 的 名字 /ds/ss/voc_name 或者 voc_name:param voc_root_dir: txt 数据文件夹 路径:param works_num: 进程数量:return: "" 输出的是voc pandas pickle 表"""paths_list_g = glob(pathname=voc_root_dir + "*")res_data = Manager().list()np.random.shuffle(paths_list_g)works_num_steps = len(paths_list_g) // works_nump_list = []for i in range(0, len(paths_list_g), works_num_steps):j = i + works_num_stepsone_works = paths_list_g[i:j]p = Process(target=self.gen_data_voc, args=(one_works, res_data))p.start()p_list.append(p)for p in p_list:p.join()voc_set = set()while len(res_data) > 0:voc_set |= res_data.pop()voc_id = ["<<<<<<<<pad>>>>>>>>>>>"] + sorted(voc_set)pd.DataFrame({"voc_id": voc_id}).to_pickle("{}.pandas_pickle_voc_id".format(voc_name))@staticmethoddef save_func_run(one_id, func="one"):""":param one_id::param func::return:"""if func == "one":return pd.DataFrame({"voc_id": one_id[:-1]["voc_id"].values, "voc": one_id[1:]["voc"].values})elif func == "two":return pd.DataFrame({"voc_id": one_id[1:]["voc_id"].values, "voc": one_id[:-1]["voc"].values})def gen_data_tensor(self, data_v, data_path, voc_i_list, process_count, total_c, data_prefix, em='sample_for_sin',em_dim=512, data_set_class="one"):""":param data_v::param data_path::param voc_i_list::param process_count::param total_c::param em::param em_dim::data_set_class::return:"""voc_idf = voc_i_list[0]voc_id_list = []voc_list=[]for one_v in tqdm(data_v):# print(len(one_list))with open(one_v, "r", encoding="utf-8") as f:one_data = f.read()total_c["count"] += 1one_id = self.voc_to_tensor.text_to_voc(one_data, voc_idf)one_id = self.save_func_run(one_id, data_set_class)voc_id = self.voc_to_tensor.voc_to_tensor(one_id["voc_id"], em=em, em_dim=em_dim)voc_list+=one_id["voc"].values.tolist()voc_id_list.append(voc_id)if len(voc_id_list) % 5000 == 0:pd.to_pickle({"voc":voc_list,"voc_id":voc_id_list} ,data_path + "/{}{}{}.pandas_pickle_data_set".format(process_count, data_prefix, total_c["count"]))voc_id_list = []voc_list = []pd.to_pickle({"voc": voc_list, "voc_id": voc_id_list},data_path + "/{}{}{}.pandas_pickle_data_set".format(process_count, data_prefix, total_c["count"]))def gen_voc_data_to_tensor_set(self, paths_list_dir, out_dir, voc_id_name, data_prefix, works_num=8,data_set_class="one", em_hidden_dim=128):""":param paths_list_dir: txt 文件夹:param data_prefix::param out_dir: 输出 pandas_pickle 文件夹:param voc_id_name: voc_id_name 路径:param works_num: 进程数:data_set_class: 数据类型:return:"""paths_list_pr = glob(pathname=paths_list_dir + "*")voc_id = pd.read_pickle(voc_id_name)["voc_id"]voc_df = Manager().list()voc_idf = pd.DataFrame({"voc": voc_id})voc_idf["voc_id"] = voc_idf.index.values.copy()voc_df.append(voc_idf)total_count = Manager().dict()total_count["count"] = 0p_list = []# 发任务到异步进程for i in range(0, len(paths_list_pr), len(paths_list_pr) // works_num):j = len(paths_list_pr) // works_num + ip = Process(target=self.gen_data_tensor, args=(paths_list_pr[i:j], out_dir, voc_df, i, total_count, data_prefix, 'sample_for_sin', em_hidden_dim,data_set_class))p.start()p_list.append(p)for p in p_list:p.join()if __name__ == '__main__':freeze_support()txt_p = "E:/just_and_sum/data_sets/"gvt_fds = GenVocTensorForDataSet()# 生成词表# gvt_fds.gen_voc_run("voc_id_",txt_p,12)# 生成向量库# gvt_fds.gen_voc_data_to_tensor_set(txt_p, "E:\just_and_sum\data_set_p", "voc_id_cut", "next", works_num=8,# data_set_class="one", em_hidden_dim=8)# gvt_fds.gen_voc_data_to_tensor_set(txt_p, "E:\just_and_sum\data_set_p", "voc_id_cut", "up", works_num=8,# data_set_class="two", em_hidden_dim=8)# # 查询# 增加库 或者词表 直接进行词表append 和 增加 数据pickle 到数据库的文件夹中方可(只要保证输出)但是词表只要使用拼接思想方可,# 加入上下库方可stds = SearchTensorDataSet("E:\just_and_sum\data_set_p", "voc_id_cut")stds.search_data("或者说直接使用进制拆分策略", top=10)相关文章:
)
手搓文本向量数据库(自然语言搜索生成模型)
import paddle import jieba import pandas as pd import numpy as np import os from glob import glob from multiprocessing import Process, Manager, freeze_supportfrom tqdm import tqdm# 首先 确定的是输出的时候一定要使用pd.to_pickle() pd.read_pickle() # 计算的时…...

EVO大赛是什么
价格是你所付出的东西,而价值是你得到的东西 EVO大赛是什么? “EVO”大赛全称“Evolution Championship Series”,是北美最高规格格斗游戏比赛,大赛正式更名后已经连续举办12年,是全世界最大规模的格斗游戏赛事。常见…...

linux中使用clash代理
本机环境:ubuntu16 安装代理工具(这里使用clash) 可以手动下载解压,下载地址:https://github.com/Dreamacro/clash 也可以直接使用命令行,演示如下: userlocalhost:~$ curl https://glados.r…...
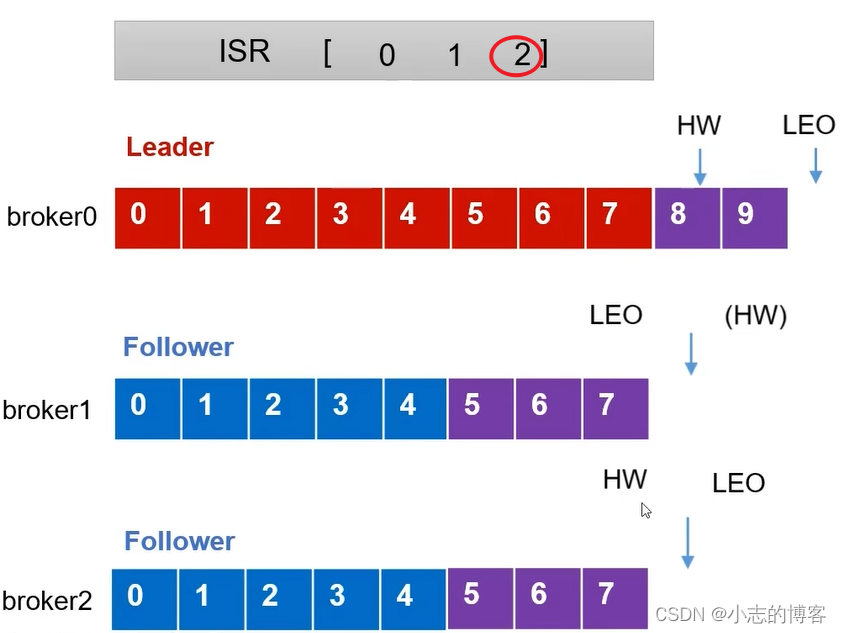
Kafka3.0.0版本——Follower故障处理细节原理
目录 一、服务器信息二、服务器基本信息及相关概念2.1、服务器基本信息2.2、LEO的概念2.3、HW的概念 三、Follower故障处理细节 一、服务器信息 三台服务器 原始服务器名称原始服务器ip节点centos7虚拟机1192.168.136.27broker0centos7虚拟机2192.168.136.28broker1centos7虚拟…...
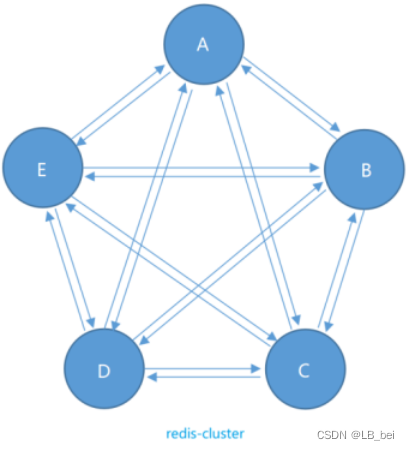
13.redis集群、主从复制、哨兵
1.redis主从复制 主从复制是指将一台redis服务器(主节点-master)的数据复制到其他的redis服务器(从节点-slave),默认每台redis服务器都是主节点,每个主节点可以有多个或没有从节点,但一个从节点…...
linux字符串处理
目录 1 C 截取字符串,截取两个子串中间的字符串2 获取该字符串后面的字符串用 strstr() 函数查找需要提取的特定字符串,然后通过指针运算获取该字符串后面的字符串用 strtok() 函数分割字符串,找到需要提取的特定字符串后,调用 strtok() 传入…...

Nginx入门——Nginx的docker版本和windows版本安装和使用 代理的概念 负载分配策略
目录 引出nginx是啥正向代理和反向代理正向代理反向代理 nginx的安装使用Docker版本的nginx安装下载创建挂载文件获取配置文件创建docker容器拷贝容器中的配置文件删除容器 创建运行容器开放端口进行代理和测试 Windows版本的使用反向代理多个端口运行日志查看启动关闭重启 负载…...

Zebec Protocol:模块化 L3 链 Nautilus Chain,深度拓展流支付体系
过去三十年间,全球金融科技领域已经成熟并迅速增长,主要归功于不同的数字支付媒介的出现。然而,由于交易延迟、高额转账费用等问题愈发突出,更高效、更安全、更易访问的支付系统成为新的刚需。 此前,咨询巨头麦肯锡的一…...
Oracle-rolling upgrade升级19c
前言: 本文主要描述Oracle11g升19c rolling upgrade升级测试,通过逻辑DGautoupgrade方式实现rolling upgrade,从而达到在较少停机时间内完成Oracle11g升级到19c的目标 升级介绍: 升级技术: rolling upgrade轮询升级,通过采用跨版…...

Spring IOC详解
Spring 笔记 官网:https://spring.io/ 核心功能:当你的项目启动的时候,自动的将当前项目的各种 Bean 都自动的注册到 Spring 容器中,然后在项目的其他地方,如果需要用到这些 Bean,直接去 Spring 容器中查…...
Unity——DOTween插件使用方法简介
缓动动画既是一种编程技术,也是一种动画的设计思路。从设计角度来看,可以有以下描述 事先设计很多基本的动画样式,如移动、缩放、旋转、变色和弹跳等。但这些动画都以抽象方式表示,一般封装为程序函数动画的参数可以在使用时指定&…...
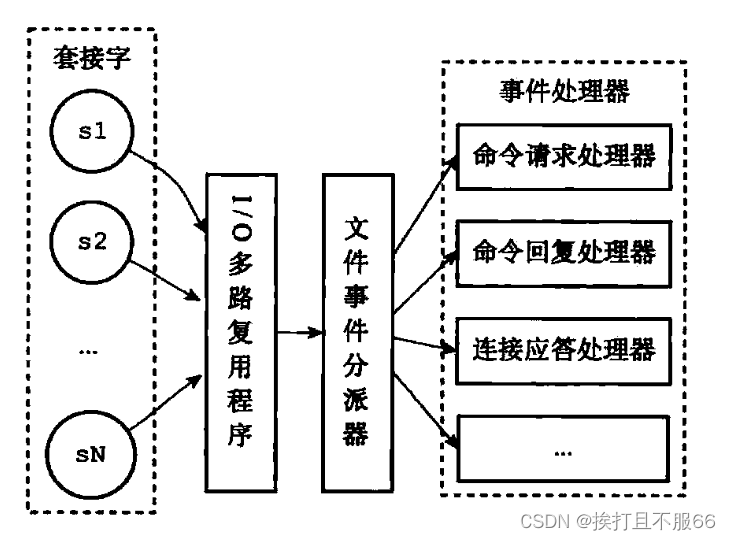
数据库——Redis 单线程模型详解
文章目录 Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型 (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file …...

leetcode 567. 字符串的排列(滑动窗口-java)
滑动窗口 字符串的排列滑动窗口代码演示进阶优化版 上期经典 字符串的排列 难度 -中等 leetcode567. 字符串的排列 给你两个字符串 s1 和 s2 ,写一个函数来判断 s2 是否包含 s1 的排列。如果是,返回 true ;否则,返回 false 。 换句…...

Git —— 分支重命名操作
在开发中,对某个分支进行重命名的操作: 1、本地分支重命名 本地分支是指:你当前这个分支还没有推送到远程的情况,这种情况修改分支名称就要方便很多 git branch -m 原始名称 新名称 //示例: 修改 test 为 newTest g…...

JavaIO流
JavaIO流 一、概念二、File类三、File类的使用1、File文件/文件夹类的创建2、File类的获取操作3、File类判断操作 - boolean4、File类对文件/文件夹的增删改5、File类的获取子文件夹以及子文件的方法 四、Java中IO流多种维度的维度1、按照流向 - Java程序2、按照流的大小分类3、…...

FlinkSql 如何实现数据去重?
摘要 很多时候flink消费上游kafka的数据是有重复的,因此有时候我们想数据在落盘之前进行去重,这在实际开发中具有广泛的应用场景,此处不说详细代码,只粘贴相应的flinksql 代码 --********************************************…...
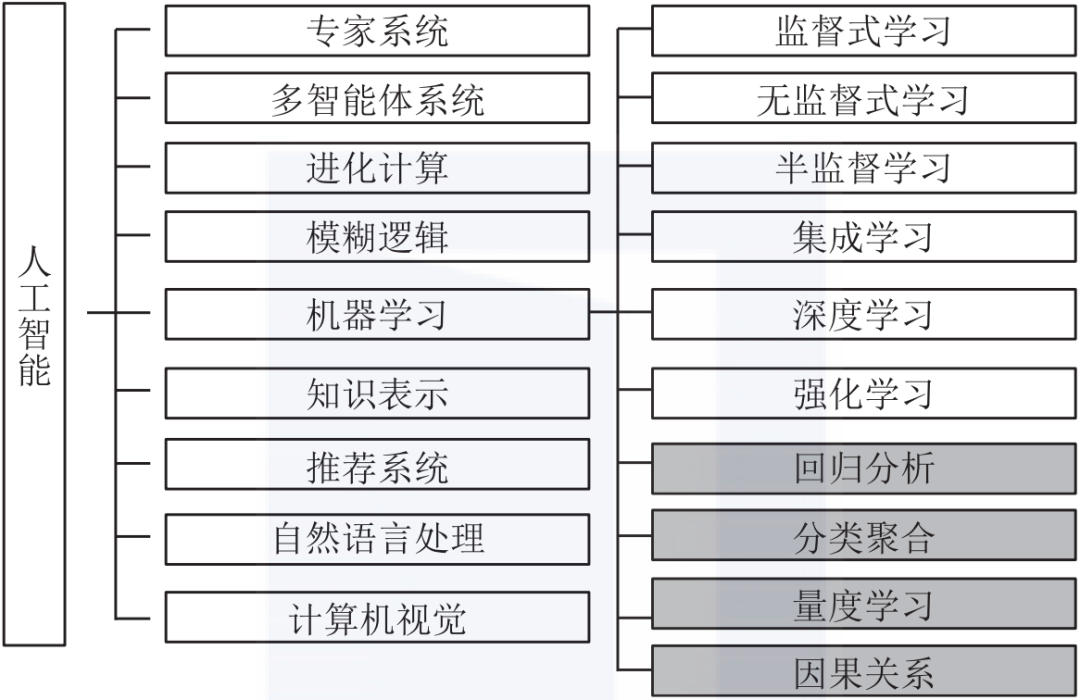
机器学习概念
目录 一、人工智能、机器学习、深度学习的关系 二、什么是深度学习? 2.1 深度学习常用算法 一、人工智能、机器学习、深度学习的关系 人工智能、机器学习和深度学习的关系如下所示。 二、什么是深度学习? 深度学习( DL, Deep Learning) 是机器学习 …...

【数据结构】排序(插入、选择、交换、归并) -- 详解
一、排序的概念及其运用 1、排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记…...
游戏中的图片打包流程,免费的png打包plist工具,一款把若干资源图片拼接为一张大图的免费工具
手机游戏开发中,为了提高图片渲染性能,经常需要将小图片合并成一张大图进行渲染。如果手工来做的话就非常耗时。TexturePacker就是一款非常不错方便的处理工具。TexturePacker虽然非常优秀,但不是免费的。 对于打包流程,做游戏的…...

Springboot实现ENC加密
Springboot实现ENC加密 1、导入依赖2、配置加密秘钥(盐)3、获取并配置密文4、重启项目测试5、自定义前缀、后缀6、自定义加密方式 1、导入依赖 关于版本,需要根据spring-boot版本,自行修改 <dependency><groupId>co…...

终极指南:119,376个英语单词发音MP3音频一键下载完整教程 [特殊字符]
终极指南:119,376个英语单词发音MP3音频一键下载完整教程 🎧 【免费下载链接】English-words-pronunciation-mp3-audio-download Download the pronunciation mp3 audio for 119,376 unique English words/terms 项目地址: https://gitcode.com/gh_mir…...

JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现
JMeter gRPC性能测试解决方案:微服务协议性能验证技术实现 【免费下载链接】jmeter-grpc-request JMeter gRPC Request load test plugin for gRPC 项目地址: https://gitcode.com/gh_mirrors/jm/jmeter-grpc-request 随着微服务架构的普及,gRPC已…...

OpenClaw Windows一键部署包简体中文版下载
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10分钟养出你的数字员工(2026最新版) 前言:2026年爆火的开源AI智能体OpenClaw(昵称小龙虾),GitHub星标超28万,凭“本地运…...

利用Taotoken CLI工具一键配置团队开发环境中的大模型调用参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken CLI工具一键配置团队开发环境中的大模型调用参数 在团队开发环境中,统一管理大模型调用参数是一个常见痛…...

一款多功能显示控制器芯片,FHD 120/144Hz,支持最高1920x1080@120Hz.
主要特性特性类别具体规格输入接口1VGA (模拟RGB)、1HDMI 1.4 (带HDCP1.4/2.2)、1DP1.2 组合接口 (兼容HDMI 1.4,带HDCP1.4/2.2)输出接口2 Port LVDS,支持8bit/10bit最大分辨率1920x1200100Hz 或 1920x1080120Hz (带ODC)色彩深度输入:6/8/10b…...

标书高效制作:Word 排版快捷键 + AI 工具组合工作流
在招投标文档制作中,Word 排版、格式调整、段落对齐、目录生成等重复操作,往往占用大量时间。熟练使用快捷键可以显著提升编辑速度,而结合 AI 辅助工具,则能从流程层面实现效率升级。本文分享一套安全、合规、无营销的纯办公实践方…...

AI音乐操作手册:从输入提示词到导出发布全流程
现在 AI 写歌工具已经不只是生成一段背景音乐,很多工具都可以从文字描述直接生成带人声的完整歌曲。真正影响体验的不是工具名字有多热,而是它适不适合当前场景:中文歌词、短视频配乐、个人纪念歌、细分曲风或者二次编辑,判断标准…...

【架构实战】日志体系ELK:集中化日志管理实践
【架构实战】日志体系ELK:集中化日志管理实践字数统计:约3500字一、从一个深夜告警说起 2024年双十一前的凌晨两点,我接到运维的电话:“支付服务挂了,用户投诉量飙升。” 我揉着眼睛打开电脑,第一件事就是登…...

伯朗特机器人集成智能料库,为多台激光切割机提供24小时不间断的板材上下料服务
在现代钣金加工、机箱电柜及金属构件制造领域,激光切割已成为核心工序。然而,随着多台激光切割机集群化作业成为常态,传统的板材上下料模式——依赖叉车转运、行车吊运及人工操作——日益暴露出效率瓶颈、劳动力密集、安全隐患及设备利用率不…...

RK3568与RK3399深度对比:从架构到实战,边缘计算如何选型?
1. 项目概述:为什么我们需要重新审视RK3568与RK3399?最近在给一个边缘计算项目做硬件选型,客户的需求很明确:需要一块性能足够、接口丰富、功耗可控且长期供货稳定的核心板。在国产处理器的候选名单里,瑞芯微的RK3399和…...