基于大语言模型知识问答应用落地实践 – 知识库构建(下)

上篇介绍了构建知识库的大体流程和一些优化经验细节,但并没有结合一个具体的场景给出更细节的实战经验以及相关的一些 benchmark 等,所以本文将会切入到一个具体场景进行讨论。
目标场景:对于 PubMed 医疗学术数据中的 1w 篇文章进行知识库构建,实现快速的注入和查询速度。
主要讨论的内容会覆盖 OpenSearch 集群规模设计、知识库 Index 设计以及实验步骤细节。
01
资源推算
一般来说,我们需要按照以下 OpenSearch 集群的设计指导原则,选择 OpenSearch 的资源配置:
如果偏向搜索的工作负载那么应该使用 10-30GB 的 shard 大小,如果偏向日志的工作负载,应该采用 30-50GB 的节点大小;
请尝试将分片数量设为数据节点数量的偶数倍,有助于分片在数据节点上均匀分布;
每个节点的分片数,与 JVM 堆内存成正比,每 GB 内存的分片不超过 25 个;
每个 5 个 vCPU 能对应一个分片,比如 8 个 vCPU 则最多支持 6 个 shard;
如果有启用 k-NN 字段,参考如下表格进行内存的推算。

依据目前的信息,仅仅知道所要索引的原始文档数。由于文档切分等中间处理过程,无法估算具体的内存用量和存储量,所以需要用小批量的实验数据进行测试推演。
在小批量实验中尝试索引了 300 篇文档,通过切分共产生出了约 203k 条记录,4.5GB 存储量。那么按比例换算如果需要索引 1 万篇文档,那么会产生约 700w 记录,150GB 存储。如下图所示:

从知识问答 Chatbot 场景出发,属于搜索的工作负载,Shard 的大小应在 10-30GB 范围内以增加搜索性能。shard 数量一般遵循节点数的倍数的原则,假设是 2 节点集群那么可以是 [2, 4, 8, 16 …]。以 150GB 存储总量进行计算,shard 可以为 8, 10, 12, 14, 16,当 shard 数为 8 时,每个 shard 存储量为 18.75GB,符合要求。
向量检索方面为了同时保证 recall 和 latency,采用了 HNSW 算法。另外参考 中的 benchmark 结论,HNSW 算法中 m 值可以设定为 16。那么内存规划方面,依照上表公式进行内存占用的推算:

一般每个节点的堆外内存占比 50%,根据knn.memory.circuit_breaker.limit=70% 的最佳实践设定,那么 35% 的节点内存被 KNN 占用,那么推算出整个节点的内存应为 22.9GB / 35% = 65GB。
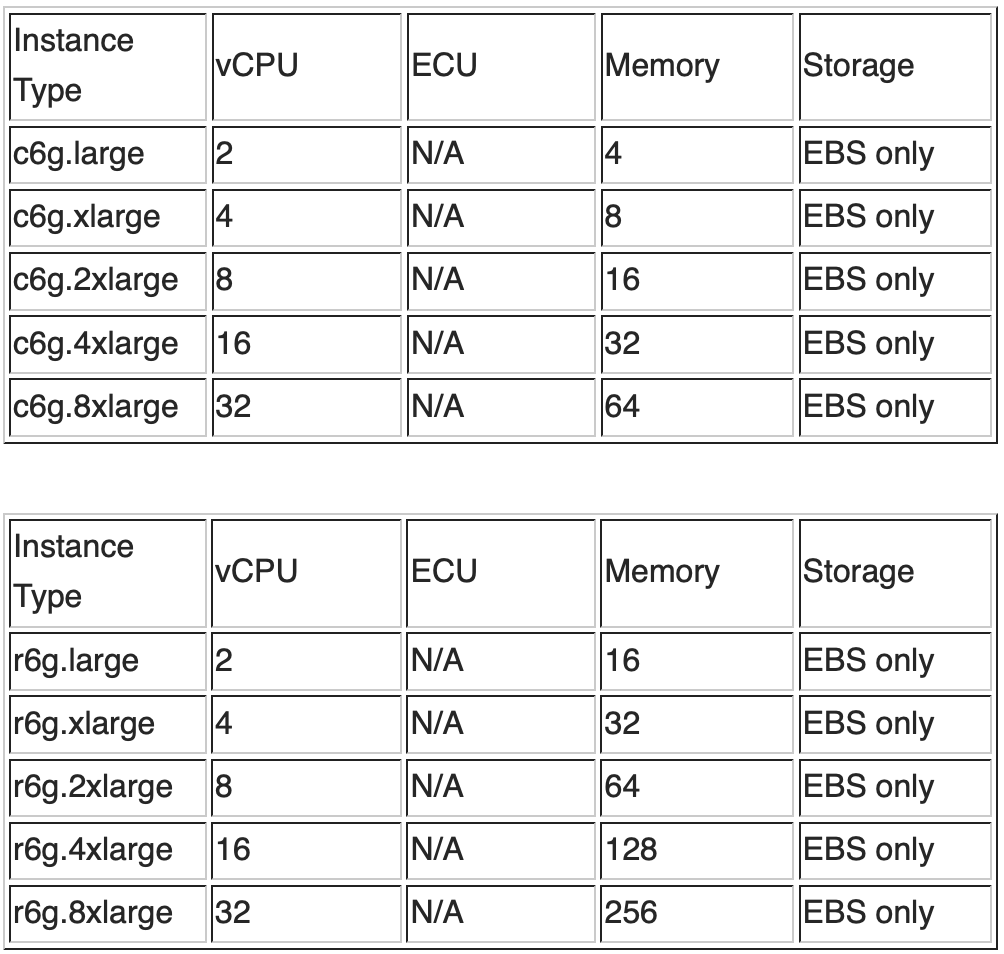
vCPU 的规划方面,假设 shard 数为 8,乘以 1.5vCPU/Shard 的系数,vCPU 个数至少需要为 12 以上。结合如下 C 系和 R 系的实例配置信息和价格信息,综合考虑内存和 vCPU 的要求,选择 C 系的 2 节点 c6g.4xlarge 或者 R 系的 2 节点 r6g.2xlarge。
02
索引构建实验
索引构建中需要关注的主要有三点:
数据完整性,保证所有的知识都能被查询到,不会因为摄入异常导致数据缺失。
构建速度,知识召回部分可能存在反复的效果调整,需要反复多次摄入,速度对全链路开发调优的效率很重要。
查询性能,保证场景中的实时会话体验。
整个摄入过程,从过程上基本可以划分为三个阶段:文本切分、文本向量化以及摄入 Amazon OpenSearch。其中文本切分和文本向量化的处理是临时性的工作负载,原则上可以提升 glue job 的并发数和 Amazon SageMaker Endpoint 背后的节点数来线性提高对这块工作负载的处理速度,但 OpenSearch 属于一个预分配的资源(注:今年即将发布的 OpenSearch Severless k-NN 向量数据库会改变这一点)。后两个部分,即向量化和 OpenSearch 摄入可能会是整个流程的瓶颈,完整流程测试不容易进行拆解分析性能瓶颈,所以本试验会分别对这两部分进行测试。
实验 1 – Embedding Model 吞吐测试
使用 paraphrase-multilingual-deploy.ipynb 进行部署,部署 10 台 g4dn.xlarge 机型;
https://github.com/aws-samples/private-llm-qa-bot/blob/main/notebooks/embedding/paraphrase-multilingual-deploy.ipynb
注释掉下游写入 OpenSearch 造成的影响,暂时注释掉相关代码;
https://github.com/aws-samples/private-llm-qa-bot/blob/main/code/aos_write_job.py
利用 batch_upload_docs.py 启动多 glue job 进行并发运行。
https://github.com/aws-samples/private-llm-qa-bot/blob/main/code/batch_upload_docs.py
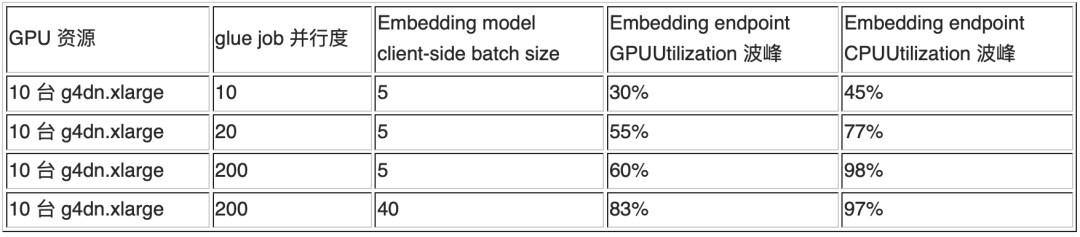
这部分处理流程中,通过调整 glue job 的并行度与 client-side batch size 可以调整向量化这一步骤的吞吐能力。当 GPU 利用率不足时,提高 client-side batch size 能够提高 GPU 的利用率。经过简单测试发现,确实能证明这个假设,具体数据可以参考如下实验结果:
实验 2 – Amazon OpenSearch 摄入测试
1. 随机生成向量,替换掉 Embedding 模型调用,参考如下代码:
import numpy as np
AOS_BENCHMARK_ENABLED=Truedef get_embedding(smr_client, text_arrs, endpoint_name=EMB_MODEL_ENDPOINT):if AOS_BENCHMARK_ENABLED:text_len = len(text_arrs)return [ np.random.rand(768).tolist() for i in range(text_len) ]# call sagemaker endpoint to calculate embeddings...return embeddings左滑查看更多
2. 构建 OpenSearch 集群以及索引,并优化设置;
a. 构建对应的索引
向量字段涉及到的两个参数 ef_construction 和 m。ef_construction 指定构建 k-NN 图的时候的动态列表大小,值越大其向量数据的图更精确,但索引的速度也响应更慢。m 指定 k-NN 中每个向量双向链表的数量,越大检索越准确,但相应内存占用会显著增大。参考博客<Choose the k-NN algorithm for your billion-scale use case with OpenSearch>中的 benchmark 结论 (https://aws.amazon.com/cn/blogs/big-data/choose-the-k-nn-algorithm-for-your-billion-scale-use-case-with-opensearch/),对于当前的数据规模,参数 ef_construction:128 和 m:16 已经足以保证召回率,另外在构建索引时可以关注以下几点:
添加一个 publish_date 字段方便后续根据时间来删除/更新知识;
添加 idx 整型字段用于记录对应片段在全文中的顺序,在召回时可以基于 range_search 召回相邻上下文片段;
只做过滤不做关键字召回的字段设置成 keyword 类型,有利于索引速度。具体可以参考如下代码:
PUT chatbot-index
{"settings" : {"index":{"number_of_shards" : 8,"number_of_replicas" : 0,"knn": "true","knn.algo_param.ef_search": 32,"refresh_interval": "60s"}},"mappings": {"properties": {"publish_date" : {"type": "date","format": "yyyy-MM-dd HH:mm:ss"},"idx" : {"type": "integer"},"doc_type" : {"type" : "keyword"},"doc": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"doc_title": {"type": "keyword"},"doc_category": {"type": "keyword"},"embedding": {"type": "knn_vector","dimension": 768,"method": {"name": "hnsw","space_type": "cosinesimil","engine": "nmslib","parameters": {"ef_construction": 128,"m": 16}} }}}
}左滑查看更多
b.设置 knn 相关参数,参考《基于大语言模型知识问答应用落地实践 – 知识库构建(上)》
PUT /_cluster/settings
{"transient": {"knn.algo_param.index_thread_qty": 8,"knn.memory.circuit_breaker.limit": "70%"}
}左滑查看更多
c.开启多 glue job 进行并发摄入,可以参考如下代码:
# 注意${Concurrent_num} 不能超过
# glue job->job detail->Advanced properties->Maximum concurrency 设置中最大限制
python batch_upload_docs.py \
--bucket "${bucket_name}" \--aos_endpoint "${OpenSearch_Endpoint}" \--emb_model_endpoint "${EmbeddingModel_Endpoint}" \--concurrent_runs_quota ${Concurrent_num} \--job_name "${Glue_jobname}"左滑查看更多
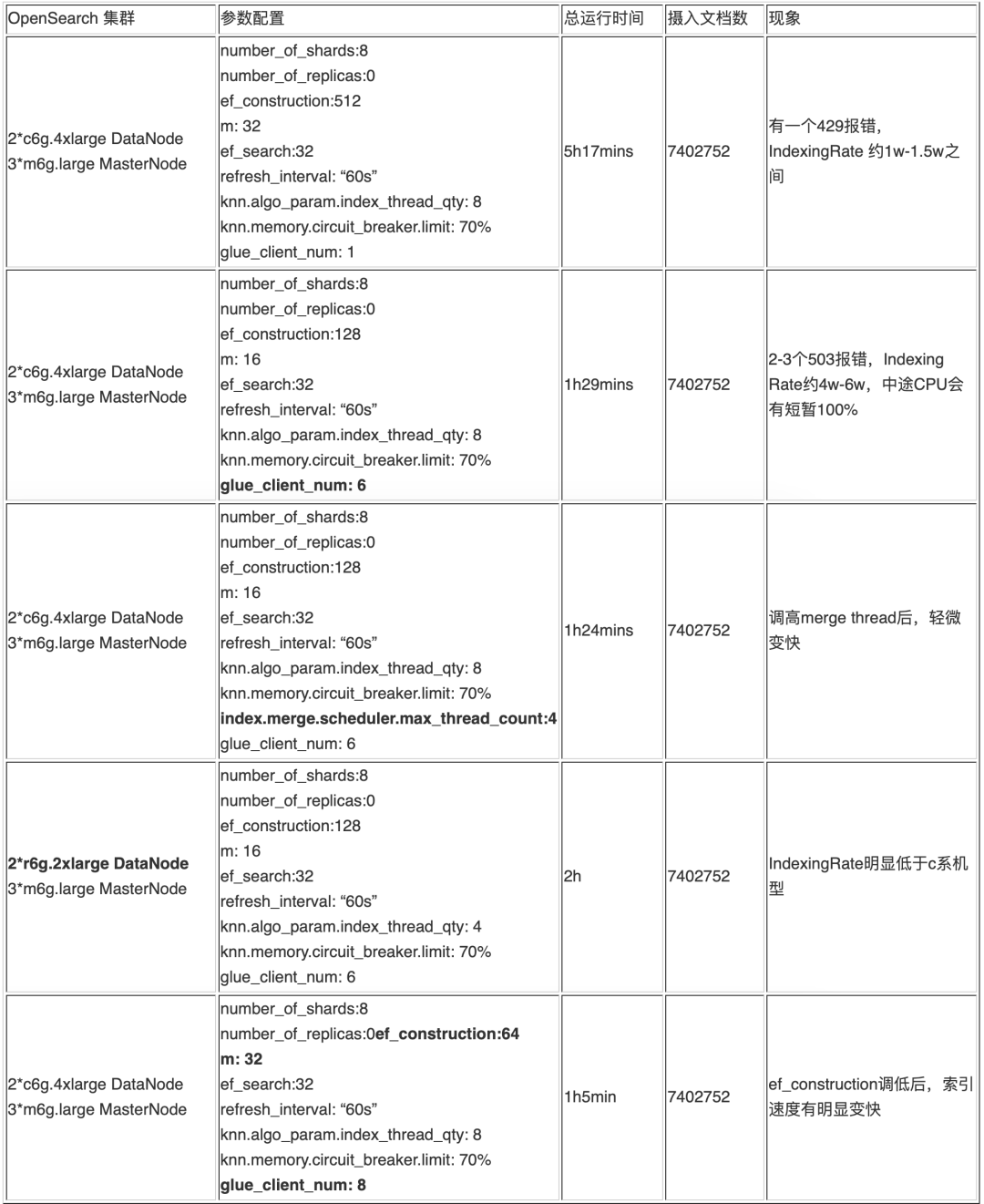
3. 部分实验结果明细
每轮实验中,调整的参数已经用加粗字体标注出来,供参考用于指导后续的数据注入中的参数调整。
实验 3 – 全流程摄入测试
a. 部分实验记录明细
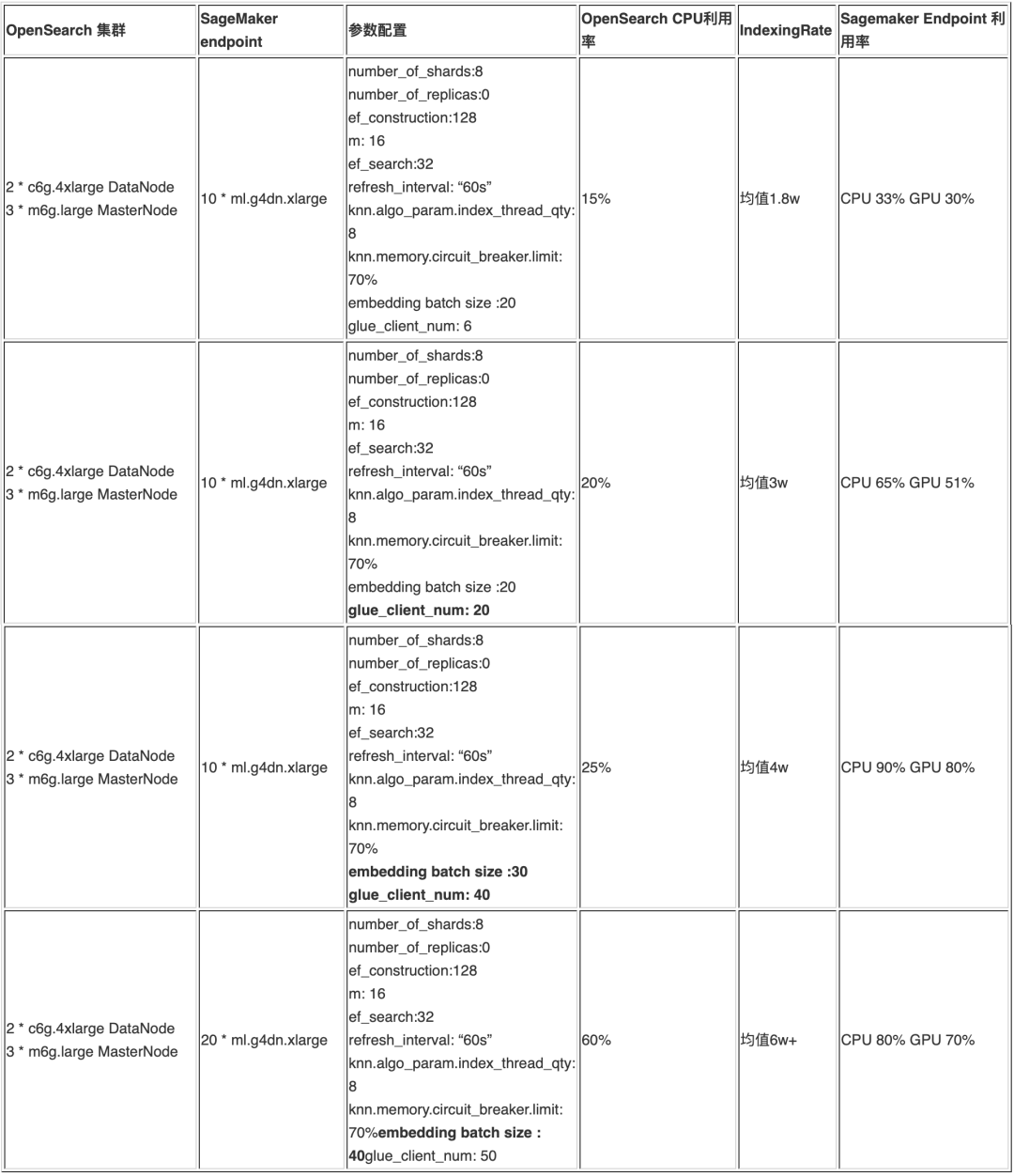
b. 初步实验结论
参考以上的实验记录可知,1 万篇文档拆分成 700 万条向量后,通过调整客户端并发,推理端点的节点数和推理 Batch Size 可以在 1 小时左右完成摄入,且完整性没有问题。能够满足大规模知识构建的要求,如果文档量继续增长,可以继续扩展 OpenSearch 节点和 SageMaker Endpoint 节点。
03
索引构建经验总结
以往 OpenSearch 摄入时的一些最佳实践中并不包含 knn 的情况,所以在 knn 索引存在的情况,不能完全参照之前的结论,通过以上三种不同的实验方式,在多次实验的过程中,本文得到了以下的一些实践经验和结论,供参考:
a. CPU 利用率和参数 ef_construction 与 m 明显正相关,在实验中使用较大的 ef_construction 和 m 时,CPU 很容易达到 100%。实验中,在其他参数相同的情况下,ef_construction 为 512 时,CPU 利用率会长期保持在 100%,改为 2 时,利用率基本在 20% 以下,峰值不超过 30%。
b. 客户端并行数量与 OpenSearch 的摄入速度和负载成正相关,但并不是线性相关。多客户端能提高摄入速度,但是客户端数量过多,可能会导致大量的(429, ‘429 Too Many Requests /_bulk’)和(503, “No server available to handle the request..”)等错误。
c. 指数退避重试机制能保证摄入的完整性以及因集群瞬时不可用导致的大面积写入失败,opensearch-py包中有如下摄入函数, 如果并发客户端过多,可能会导致CPU利用率一直位于100%,在max_retries的重试次数内,每次会等待 initial_backoff * (attampt_idx ** 2)的时间,通过设定一个较大的initial_backoff等待时间,能避免在客户端并发数偏大的情况下出现大面积429错误。另外客户端数也不能过大,否则也会更容易出现大量的503相关错误。对于偶发的503报错,可以利用 glue 的 retry 机制处理,保证写入的完整性。
# chunk_size 为文档数 默认值为 500
# max_chunk_bytes 为写入的最大字节数,默认 100M 过大,可以改成 10-15M
# max_retries 重试次数
# initial_backoff 为第一次重试时 sleep 的秒数,再次重试会翻倍
# max_backoff 最大等待时间
response = helpers.bulk(client,doc_generator,max_retries=3,initial_backoff=200, #默认值为 2,建议大幅提高max_backoff=800,max_chunk_bytes=10 * 1024 * 1024) #10M 社区建议值左滑查看更多
注意:在大规模数据摄入的生产场景中,不建议使用LangChain提供的向量数据库接口,查看其源码可知,LangChain的默认实现是单客户端,且其内部实现没有使用指数退避Retry机制,无法保证摄入速度和完整性。
d. 写入完成后,建议查询文档的去重数量,确保写入的完整性。可以在 OpenSearch Dashboard 的 Dev tools 中使用如下的 DSL 语句查询文档总数。注意 cardinality 方式的统计不是精准统计值,可以提高 precision_threshold 参数值来提高其准确性。
POST /{index_name}/_search
{"size": 0,"aggs": {"distinct_count": {"cardinality": {"field": "{field_name}","precision_threshold": 20000}}}
}=> 10000左滑查看更多
同时可以按照文档名统计对应的 chunk 数量,可以帮助发现潜在文档处理质量问题,参考下面代码:
GET /{index_name}/_search
{"size": 0,"aggs": {"distinct_values": {"terms": {"field": "doc_title"}}}
}=>
...
"aggregations": {"distinct_values": {"buckets": [{"key": "ai-content/batch/PMC10000335.txt","doc_count": 42712},{"key": "ai-content/batch/PMC10005506.txt","doc_count": 5279},...{"key": "ai-content/batch/PMC10008235.txt","doc_count": 9},{"key": "ai-content/batch/PMC10001778.txt","doc_count": 1}]}左滑查看更多
e. refresh_interval 设置为 -1,在其他相关参数的相同的情况下,503 报错明显增加。更改为 60s 后,情况有明显好转, 如果发生类似问题,可以做类似的调整。
04
检索性能调优
数据注入完毕以后,直接查询性能是十分差的,查询时延可能在几秒甚至十几秒。需要进行一些必要的优化。核心的主要有两点:
a. Segment 合并
Segment 是 OpenSearch 中的最小搜索单元。如果每个 shard 只有 1 个 segment,搜索效率将达到最高。为了实现这个目标,我们可以通过控制 refresh interval 来降低小 segment 的生成速度,或者手动进行 segment merge。这将有助于减少搜索过程中的开销,提高搜索速度。
可以在 OpenSearch Dashboard 的 Dev tools 中通过如下的 DSL 执行合并,整个合并过程比较长,执行之前可以调高用于合并的线程最大值,能够提高合并的速度。
# merge segments
POST /{index_name}/_forcemerge?max_num_segments=1?pretty# increase max_thread_count for merge task
PUT {index_name}/_settings
{"index.merge.scheduler.max_thread_count": 8
}左滑查看更多
合并前后可以执行如下 DSL 来检查当前的 segments 情况:
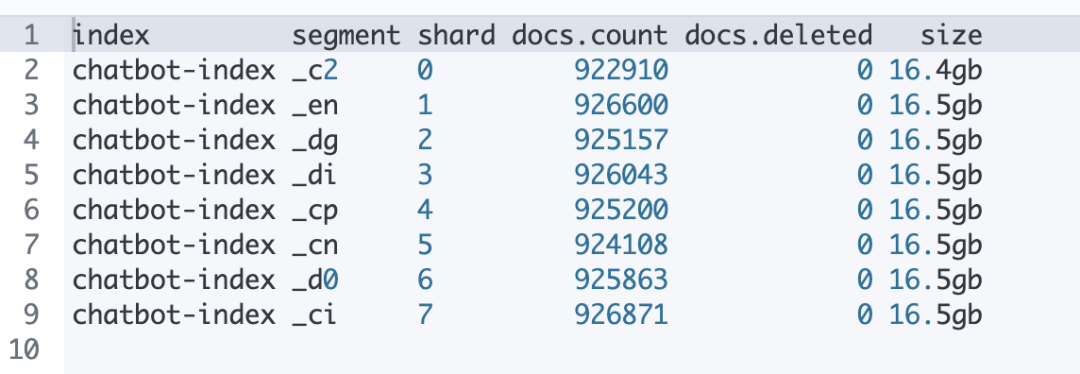
GET _cat/segments/{index_name}?v&h=index,segment,shard,docs.count,docs.deleted,size左滑查看更多
以下表格是合并 segments 后的情况,合并完成后每个 shard 下仅有一个 segment,数据也均匀分布,标记删除的数据也被清理掉了。
b. k-NN 索引 warmup
由于 k-NN 索引的性能与索引数据结构是否缓存到内存中密切相关,能够提供的缓存内容容量对性能影响很大。可以执行以下 DSL 命令,对 k-NN 索引进行预热
GET /_plugins/_knn/warmup/{index_name}?pretty左滑查看更多
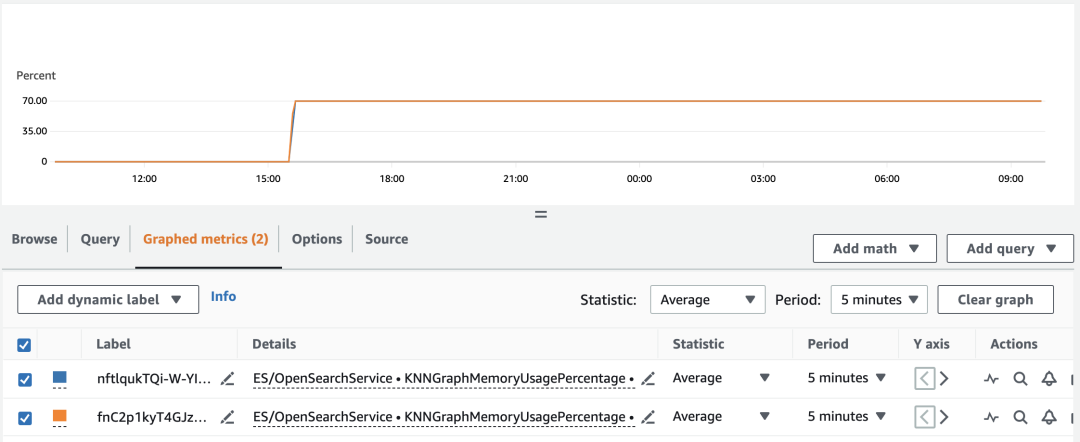
预热执行很快,预热完毕以后,性能会有明显改善。可以到 CloudWatch 中去查看 OpenSearch Domain 中的 KNNGraphMemoryUsagePercentage 指标进行确认是否执行完毕,如图所示:
05
结语
本文在本系列上篇博客的基础上,通过一个真实数据场景的实践进行更详细的阐述,讨论的重点更多放在针对大规模的文档、更快更完整地构建基于向量数据的知识库上面,这对于一些行业如金融、法律、医疗等行业知识库的构建具备指导借鉴意义。
本文的第一部分对于 Amazon OpenSearch 的集群配置选择给出了一些方法参考,第二三四部分对于数据摄入和检索性能等方面给出了一些初步的经验总结。
本系列后续还有几篇相关博客进一步深入阐述,其中包括:
《Amazon OpenSearch 向量数据库的性能评估与选型分析》,会针对 Amazon OpenSearch 作为向量数据库,讨论其优势及定位,在索引和查询等方面给出更加详细的 benchmark,给用户更加丰富的参考信息。
《基于大语言模型知识问答应用落地实践 – 知识召回调优》,会在知识库构建的前提和背景下,讨论如何更好的召回对应的知识,包括各种适用的召回手段和实践技巧。另外,本文提到的代码细节可以参考配套资料:
代码库 aws-samples/private-llm-qa-bot
https://github.com/aws-samples/private-llm-qa-bot
workshop <基于 Amazon OpenSearch+大语言模型的智能问答系统>(中英文版本)
https://github.com/aws-samples/private-llm-qa-bot
参考文献:
1. Choose the k-NN algorithm for your billion-scale use case with OpenSearch
https://aws.amazon.com/cn/blogs/big-data/choose-the-k-nn-algorithm-for-your-billion-scale-use-case-with-opensearch/
本篇作者

李元博
亚马逊云科技 Analytic 与 AI/ML 方面的解决方案架构师,专注于 AI/ML 场景的落地的端到端架构设计和业务优化,同时负责数据分析方面的 Amazon Clean Rooms 产品服务。在互联网行业工作多年,对用户画像,精细化运营,推荐系统,大数据处理方面有丰富的实战经验。

孙健
亚马逊云科技大数据解决方案架构师,负责基于亚马逊云科技的大数据解决方案的咨询与架构设计,同时致力于大数据方面的研究和推广。在大数据运维调优、容器解决方案,湖仓一体以及大数据企业应用等方面有着丰富的经验。

汤市建
亚马逊云科技数据分析解决方案架构师,负责客户大数据解决方案的咨询与架构设计。

郭韧
亚马逊云科技 AI 和机器学习方向解决方案架构师,负责基于亚马逊云科技的机器学习方案架构咨询和设计,致力于游戏、电商、互联网媒体等多个行业的机器学习方案实施和推广。在加入亚马逊云科技之前,从事数据智能化相关技术的开源及标准化工作,具有丰富的设计与实践经验。


听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
基于大语言模型知识问答应用落地实践 – 知识库构建(下)
上篇介绍了构建知识库的大体流程和一些优化经验细节,但并没有结合一个具体的场景给出更细节的实战经验以及相关的一些 benchmark 等,所以本文将会切入到一个具体场景进行讨论。 目标场景:对于 PubMed 医疗学术数据中的 1w 篇文章进行知识库构…...

Hive UDF自定义函数上线速记
0. 编写hive udf函数jar包 略 1. 永久函数上线 1.1 提交jar包至hdfs 使用命令or浏览器上传jar到hdfs,命令的话格式如下 hdfs dfs -put [Linux目录] [hdfs目录] 示例: hdfs dfs -put /home/mo/abc.jar /tmp1.2 将 JAR 文件添加到 Hive 中 注意hdfs路径前面要加上hdfs://na…...

【nacos】【sentinel】【gateway】docker-compose安装及web项目部署
docker安装 【centos】【docker】安装启动 docker-compose安装 【docker-compose】安装使用 配置文件 version: 2 networks: #自定义网络myapp,为了只有这些服务可以在该网络内相互访问myapp:driver: bridge services: #将容器抽象成服务nacos: #注册中心image…...
用idea查看sqlite数据库idea sqlite
1、安装Database Navigator插件 2、导入数据库并查看 3、删除数据库连接 在此做个笔记...

流媒体服务器与视频服务器有什么区别?
流媒体服务器与视频服务器有什么区别? 流媒体服务器用在远程教育,视频点播、网络电台、网络视频等方面。 直播过程中就需要使用流媒体服务器,一个完整的直播过程,包括采集、处理、编码、封包、推流、传输、转码、分发、解码、播放…...

03-基础例程3
基础例程3 01、外部中断 ESP32的外部中断有上升沿、下降沿、低电平、高电平触发模式。 实验目的 使用外部中断功能实现按键控制LED的亮灭 按键按下为0。【即下降沿】 * 接线说明:按键模块-->ESP32 IO* (K1-K4)-->(14,27,26,25)* * …...

Vue结合ElementUi修改<el-table>表格的背景颜色和表头样式
本项目在开发过程中vueelementui , 页面中使用了table表格的样式, 需要对原先的样式进行修改,以下是简单的修改样式内容:项目中某个 html中引用的table表格内容,定义了div的class : device_err :<div class"device_err&q…...

git clone与git pull区别
从字面意思也可以理解,都是往下拉代码,git clone是克隆,git pull 是拉。 但是,也有区别: 从远程服务器克隆一个一模一样的版本库到本地, 复制的是整个版本库,叫做clone.(clone是将一个库复制到你…...

MyBatis学习简要
目录 什么是MyBatis? MyBatis实现的设想 MyBatis基于配置文件的开发步骤 mybatis的配置文件 Mapper代理开发 配置文件完成增删改查的三步 注解开发 一、条件查询 参数接收时,参数的设置: 动态条件查询: 二、添加功能 步骤…...
forlium 笔记 Map
用于创建交互式地图 1 主要参数 1.1. location 地图位置 地图的经纬度 import foliumm folium.Map(location[31.186358, 121.510256],zoom_start15)m 1.2 tiles 内置样式 默认是OpenStreetMap 1.2.1 Stamen Terrain 它强调了地形特征,如山脉、河流和道路 m …...
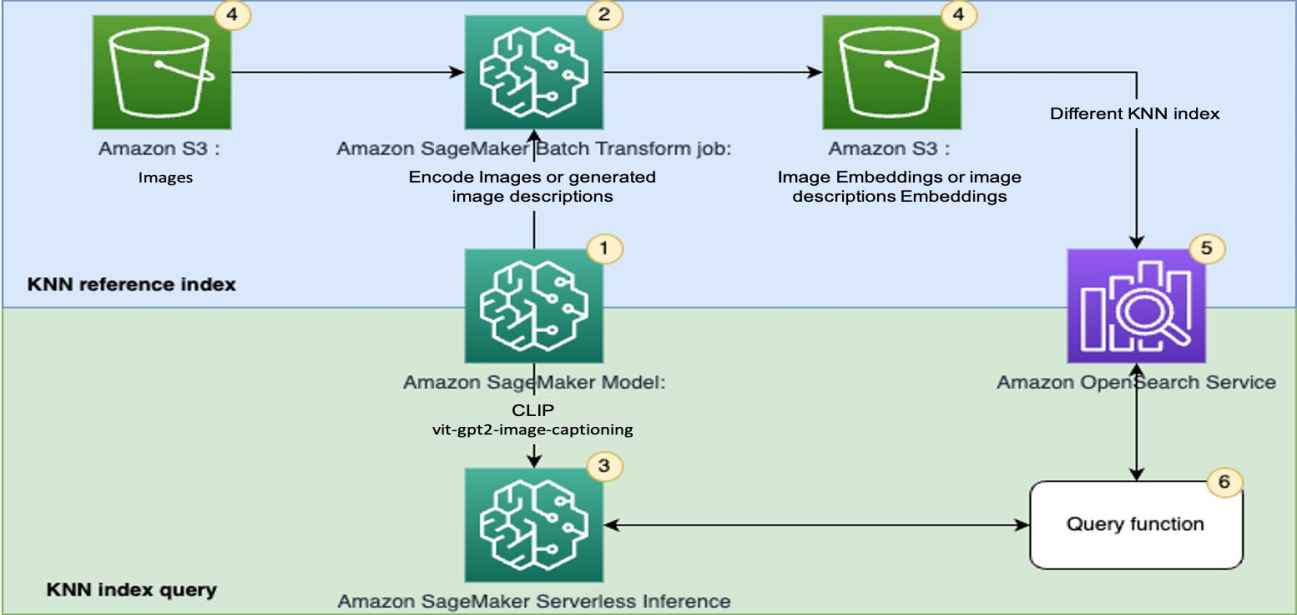
解读亚马逊云科技语义搜图检索方案
图像检索(包括文搜图和图搜图)是各个行业中常见的一个应用场景。比如在电商场景中,基于以图搜图做相似商品查找;在云相册场景中,基于文搜图来找寻所需的图像素材。 传统基于标签的图像检索方式,即先使用目标…...

git基本使用
1、创建仓库,提交代码 Git 全局设置: git config --global user.name "许歌" //全局绑定用户名 git config --global user.email "12075507xu-ge111user.noreply.gitee.com" //全局绑定邮箱创建 git 仓库: mkdir t…...
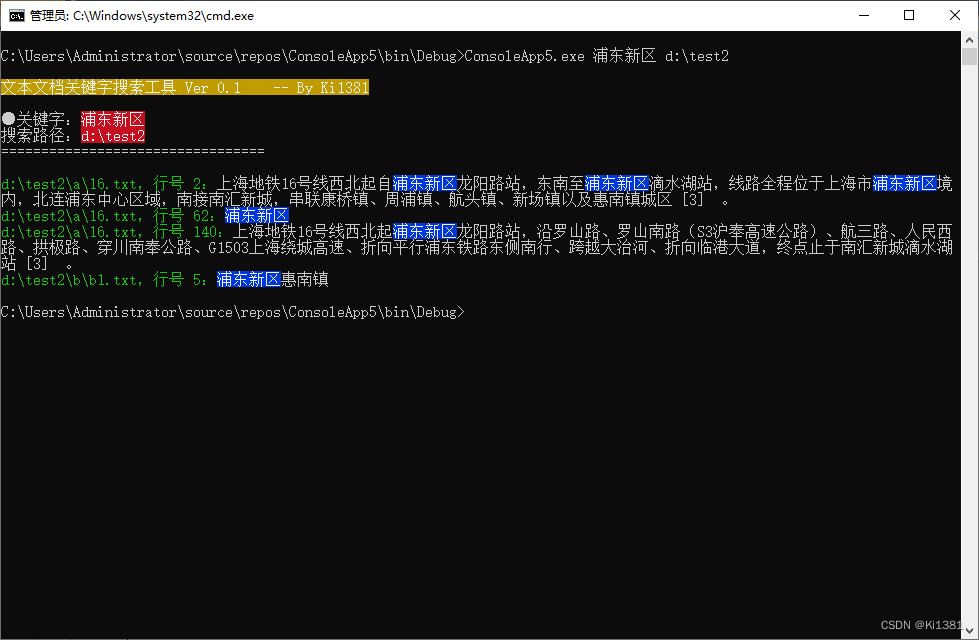
为C# Console应用化个妆
说到Windows的cmd,刻板印象就是黑底白字的命令行界面。跟Linux花花绿绿的界面比,似乎单调了许多。但其实C#开发的Console应用也可以摆脱单调非黑即白的UI。 最近遇到个需求,要在一堆纯文本文件里找指定的关键字(后续还要人肉判断…...

VUE环境下 CSS3+JS 实现发牌 翻牌
创建牌容器(关键点:overflow:hidden): <div class"popup-box"></div> .popup-box {position: absolute;width: 100vw;height: 100vh;top: 0px;left: 0;overflow: hidden; } 创建每一张牌《固…...
WSL Opencv with_ffmpeg conan1.60.0
我是ubuntu18. self.options[“opencv”].with_ffmpeg True 关键是gcc版本需要conan支持,比如我的是: compilergcc compiler.version7.5 此外还需要安装系统所需库: https://qq742971636.blog.csdn.net/article/details/132559789 甚至来…...

Android中正确使用Handler的姿势
在Android中,Handler是一种用于在不同线程之间传递消息和任务的机制。以下是在Android中正确使用Handler的一些姿势: 1. 在主线程中创建Handler对象 在Android中,只有主线程(也称为UI线程)可以更新UI。因此ÿ…...

webSocket前后端交互pc端版
前端代码 <!--* Author: 第一好帅宝* Date: 2023-08-29 16:12:26* LastEditTime: 2023-08-29 16:54:50* FilePath: \websocket\ceshi.html --> <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name&…...
)
Java-day13(枚举与注解)
枚举与注解 枚举 1.自定义枚举 如果枚举只有单个成员,则可以作为单例模式的实现方式 public class test{ public static void main(String[] args) { Season spring Season.spring;System.out.println(spring);spring.show();System.out.println(…...

vue PDF或Word转换为HTML并保留原有样式
方法一 要将PDF或Word转换为HTML并保留原有样式,可以使用pdfjs-dist和mammoth.js这两个库。首先需要安装这两个库: npm install pdfjs-dist mammoth.js然后在Vue项目中使用这两个库进行转换: import * as pdfjsLib from pdfjs-dist; impor…...

华硕笔记本摄像头倒置怎么办?华硕笔记本摄像头上下颠倒怎么调整
笔记本电脑相较于台式电脑,更易携带,解决了很大一部分人的使用需求。但是笔记本电脑也存在很多不足,比如华硕笔记本电脑就经常会出现摄像头倒置的错误,出现这种问题要如何修复呢?下面就来看看详细的调整方法。 华硕笔记…...

fltk-rs主题定制技巧:打造个性化GUI界面的10个实用方法
fltk-rs主题定制技巧:打造个性化GUI界面的10个实用方法 【免费下载链接】fltk-rs Rust bindings for the FLTK GUI library. 项目地址: https://gitcode.com/gh_mirrors/fl/fltk-rs 想要让你的Rust GUI应用与众不同吗?fltk-rs作为FLTK GUI库的Rus…...

告别繁琐点击:3大功能助你实现智能文档获取与自动化下载
告别繁琐点击:3大功能助你实现智能文档获取与自动化下载 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了…...

社保照片怎么手机搞定?社保照片要求有哪些?2026手机拍摄社保照片完整指南
社保办理、医保激活、养老金申请……这些民生相关的事务都离不开一张正式的证件照。很多人以为必须去照相馆花钱拍摄,但其实用手机就能完全搞定。无论是首次办理社保还是证件过期更新,这篇教程都能帮你省时省钱,拍出符合社保部门要求的标准照…...

企业微信SCRM与客户管理系统推荐:2026年这12家值得关注
2026年,一个企业要选客户管理系统,第一个要回答的问题是:你的客户在哪里?如果答案是"微信",那企业微信SCRM就是最直接的路径——而在这个领域,微盛企微管家作为企业微信最大ISV,服务了…...

UV-UI框架终极指南:如何快速构建跨平台应用
UV-UI框架终极指南:如何快速构建跨平台应用 【免费下载链接】uv-ui uv-ui 破釜沉舟之兼容vue32、app、h5、小程序等多端基于uni-app和uView2.x的生态框架,支持单独导入,开箱即用,利剑出击。 项目地址: https://gitcode.com/gh_m…...
)
保姆级教程:在Ubuntu 18.04 + ROS Melodic上搞定Intel RealSense D415深度相机驱动(附固件升级避坑指南)
从零搭建ROS Melodic环境:Intel RealSense D415深度相机全流程配置指南 第一次将Intel RealSense D415深度相机连接到Ubuntu 18.04系统时,我遇到了驱动不兼容、固件版本冲突、USB连接不稳定等一系列问题。经过多次尝试和调试,终于总结出一套…...

暗黑破坏神2存档编辑器终极指南:5分钟掌握Diablo Edit2核心功能
暗黑破坏神2存档编辑器终极指南:5分钟掌握Diablo Edit2核心功能 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经因为暗黑破坏神2中角色技能点分配失误而苦恼?是否…...

SpinalHDL Pipeline库核心要素解析:从Stageable到流水线构建实战
1. Pipeline核心要素深度解析:从概念到实战在数字电路设计,尤其是处理器流水线这类复杂逻辑的构建中,我们常常需要一种更抽象、更灵活的方式来组织数据流和控制流。传统的RTL描述方式在面对多级流水、动态数据传递和复杂交互时,代…...

ROS2 Humble下colcon编译实战:从创建workspace到运行自定义节点
ROS2 Humble下colcon编译实战:从创建workspace到运行自定义节点 在机器人开发领域,ROS2已经成为事实上的标准框架,而colcon作为其官方推荐的构建工具,掌握它的使用技巧能显著提升开发效率。本文将带您完成一个完整的ROS2项目构建流…...
)
千问 LeetCode 2478.完美分割的方案数 public int beautifulPartitions(String s, int k, int minLength)
好的,这是 LeetCode 2478 "完美分割的方案数" 的 Java 实现。 解题思路 核心是动态规划 + 前缀和优化: 1. 定义状态:dp[i][j] 表示前 i 个字符分成 j 段的方案数 2. 状态转移:对于每个可能的分割点,需要满足: - 当前段长度 ≥ minLength - 当前段首字…...