whisper语音识别部署及WER评价
1.whisper部署
详细过程可以参照:🏠
创建项目文件夹
mkdir whisper cd whisperconda创建虚拟环境
conda create -n py310 python=3.10 -c conda-forge -y安装pytorch
pip install --pre torch torchvision torchaudio --extra-index-url下载whisper
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git安装相关包
pip install tqdm pip install numba pip install tiktoken==0.3.3 brew install ffmpeg测试一下whispet是否安装成功(默认识别为中文)
whisper test.wav --model small #test.wav为自己的测试wav文件,map3也支持 small是指用小模型whisper识别中文的时候经常会输出繁体,加入一下参数可以避免:
whisper test.wav --model small --language zh --initial_prompt "以下是普通话的句子。" #注意"以下是普通话的句子。"不能随便修改,只能是这句话才有效果。
2.脚本批量测试
创建test.sh脚本,输入一下内容,可以实现对某一文件夹下的wav文件逐个中文语音识别。
#!/bin/bash
for ((i=0;i<300;i++));dofile="wav/A13_${i}.wav"if [ ! -f "$file" ];thenbreakfiwhisper "$file" --model medium --output_dir denied --language zh --initial_prompt "以下是普通话的句子。"
done实现英文语音识别需要修改为:
#!/bin/bash
for ((i=0;i<300;i++));dofile="en/${i}.wav"if [ ! -f "$file" ];thenbreakfiwhisper "$file" --model small --output_dir denied --language en
done3.对运行出来的结果进行评测
一般地,语音识别通常采用WER,即词错误率,评估语音识别和文本转换质量。
这里我们主要采用 github上的开源项目:🌟 编写的python-wer代码对结果进行评价。
其中,我们的正确样本形式为:
whisper输出的预测结果形式为:
因此要对文本进行处理(去空格、去标点符号)后进行wer评价,相关代码如下:
(可根据具体情况修改calculate_WER)


import sys
import numpydef editDistance(r, h):'''This function is to calculate the edit distance of reference sentence and the hypothesis sentence.Main algorithm used is dynamic programming.Attributes: r -> the list of words produced by splitting reference sentence.h -> the list of words produced by splitting hypothesis sentence.'''d = numpy.zeros((len(r)+1)*(len(h)+1), dtype=numpy.uint8).reshape((len(r)+1, len(h)+1))for i in range(len(r)+1):d[i][0] = ifor j in range(len(h)+1):d[0][j] = jfor i in range(1, len(r)+1):for j in range(1, len(h)+1):if r[i-1] == h[j-1]:d[i][j] = d[i-1][j-1]else:substitute = d[i-1][j-1] + 1insert = d[i][j-1] + 1delete = d[i-1][j] + 1d[i][j] = min(substitute, insert, delete)return ddef getStepList(r, h, d):'''This function is to get the list of steps in the process of dynamic programming.Attributes: r -> the list of words produced by splitting reference sentence.h -> the list of words produced by splitting hypothesis sentence.d -> the matrix built when calulating the editting distance of h and r.'''x = len(r)y = len(h)list = []while True:if x == 0 and y == 0: breakelif x >= 1 and y >= 1 and d[x][y] == d[x-1][y-1] and r[x-1] == h[y-1]: list.append("e")x = x - 1y = y - 1elif y >= 1 and d[x][y] == d[x][y-1]+1:list.append("i")x = xy = y - 1elif x >= 1 and y >= 1 and d[x][y] == d[x-1][y-1]+1:list.append("s")x = x - 1y = y - 1else:list.append("d")x = x - 1y = yreturn list[::-1]def alignedPrint(list, r, h, result):'''This funcition is to print the result of comparing reference and hypothesis sentences in an aligned way.Attributes:list -> the list of steps.r -> the list of words produced by splitting reference sentence.h -> the list of words produced by splitting hypothesis sentence.result -> the rate calculated based on edit distance.'''print("REF:", end=" ")for i in range(len(list)):if list[i] == "i":count = 0for j in range(i):if list[j] == "d":count += 1index = i - countprint(" "*(len(h[index])), end=" ")elif list[i] == "s":count1 = 0for j in range(i):if list[j] == "i":count1 += 1index1 = i - count1count2 = 0for j in range(i):if list[j] == "d":count2 += 1index2 = i - count2if len(r[index1]) < len(h[index2]):print(r[index1] + " " * (len(h[index2])-len(r[index1])), end=" ")else:print(r[index1], end=" "),else:count = 0for j in range(i):if list[j] == "i":count += 1index = i - countprint(r[index], end=" "),print("\nHYP:", end=" ")for i in range(len(list)):if list[i] == "d":count = 0for j in range(i):if list[j] == "i":count += 1index = i - countprint(" " * (len(r[index])), end=" ")elif list[i] == "s":count1 = 0for j in range(i):if list[j] == "i":count1 += 1index1 = i - count1count2 = 0for j in range(i):if list[j] == "d":count2 += 1index2 = i - count2if len(r[index1]) > len(h[index2]):print(h[index2] + " " * (len(r[index1])-len(h[index2])), end=" ")else:print(h[index2], end=" ")else:count = 0for j in range(i):if list[j] == "d":count += 1index = i - countprint(h[index], end=" ")print("\nEVA:", end=" ")for i in range(len(list)):if list[i] == "d":count = 0for j in range(i):if list[j] == "i":count += 1index = i - countprint("D" + " " * (len(r[index])-1), end=" ")elif list[i] == "i":count = 0for j in range(i):if list[j] == "d":count += 1index = i - countprint("I" + " " * (len(h[index])-1), end=" ")elif list[i] == "s":count1 = 0for j in range(i):if list[j] == "i":count1 += 1index1 = i - count1count2 = 0for j in range(i):if list[j] == "d":count2 += 1index2 = i - count2if len(r[index1]) > len(h[index2]):print("S" + " " * (len(r[index1])-1), end=" ")else:print("S" + " " * (len(h[index2])-1), end=" ")else:count = 0for j in range(i):if list[j] == "i":count += 1index = i - countprint(" " * (len(r[index])), end=" ")print("\nWER: " + result)return resultdef wer(r, h):"""This is a function that calculate the word error rate in ASR.You can use it like this: wer("what is it".split(), "what is".split()) """# build the matrixd = editDistance(r, h)# find out the manipulation stepslist = getStepList(r, h, d)# print the result in aligned wayresult = float(d[len(r)][len(h)]) / len(r) * 100result = str("%.2f" % result) + "%"result=alignedPrint(list, r, h, result)return result# 计算总WER
def calculate_WER():with open("whisper_out.txt", "r") as f:text1_list = [i[11:].strip("\n") for i in f.readlines()]with open("A13.txt", "r") as f:text2_orgin_list = [i[11:].strip("\n") for i in f.readlines()]total_distance = 0total_length = 0WER=0symbols = ",@#¥%……&*()——+~!{}【】;‘:“”‘。?》《、"# calculate distance between each pair of textsfor i in range(len(text1_list)):match1 = re.search('[\u4e00-\u9fa5]', text1_list[i])if match1:index1 = match1.start()else:index1 = len(text1_list[i])match2 = re.search('[\u4e00-\u9fa5]', text2_orgin_list[i])if match2:index2 = match2.start()else:index2 = len( text2_orgin_list[i])result1= text1_list[i][index1:]result1= result1.translate(str.maketrans('', '', symbols))result2= text2_orgin_list[i][index2:]result2=result2.replace(" ", "")print(result1)print(result2)result=wer(result1,result2)WER+=float(result.strip('%')) / 100WER=WER/len(text1_list)print("总WER:", WER)print("总WER:", WER.__format__('0.2%'))
calculate_WER()评价结果形如:

4.与paddlespeech的测试对比:
| 数据集 | 数据量 | paddle (中英文分开) | paddle (同一模型) | whisper(small) (同一模型) | whisper(medium) (同一模型) | ||
| zhthchs30 (中文错字率) | 250 | 11.61% | 45.53% | 24.11% | 13.95% | ||
| LibriSpeech (英文错字率) | 125 | 7.76% | 50.88% | 9.31% | 9.31% |
5.测试所用数据集
自己处理过的开源wav数据
相关文章:
whisper语音识别部署及WER评价
1.whisper部署 详细过程可以参照:🏠 创建项目文件夹 mkdir whisper cd whisper conda创建虚拟环境 conda create -n py310 python3.10 -c conda-forge -y 安装pytorch pip install --pre torch torchvision torchaudio --extra-index-url 下载whisper p…...

java太卷了,怎么办?
忧虑: 马上就到30岁了,最近对于自己职业生涯的规划甚是焦虑。在网站论坛上,可谓是哀鸿遍野,大家纷纷叙述着自己被裁后求职的艰辛路程,这更加加深了我的忧虑,于是在各大论坛开始“求医问药”,想…...

android多屏触摸相关的详解方案-安卓framework开发手机车载车机系统开发课程
背景 直播免费视频课程地址:https://www.bilibili.com/video/BV1hN4y1R7t2/ 在做双屏相关需求开发过程中,经常会有对两个屏幕都要求可以正确触摸的场景。但是目前我们模拟器默认创建的双屏其实是没有办法进行触摸的 修改方案1 静态修改方案 使用命令…...
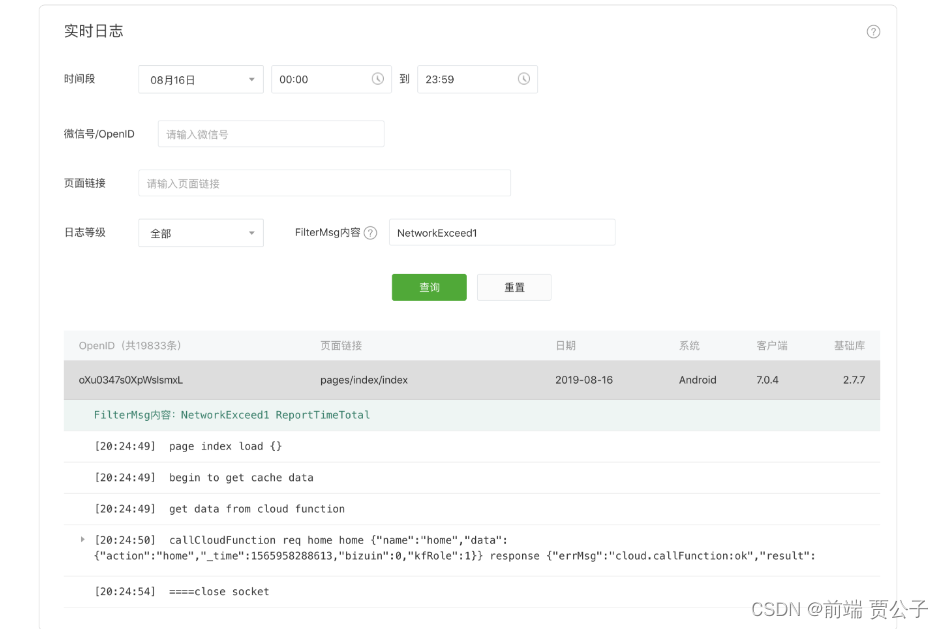
微信小程序 实时日志
目录 实时日志 背景 如何使用 如何查看日志 注意事项 实时日志 背景 为帮助小程序开发者快捷地排查小程序漏洞、定位问题,我们推出了实时日志功能。从基础库2.7.1开始,开发者可通过提供的接口打印日志,日志汇聚并实时上报到小程序后台…...
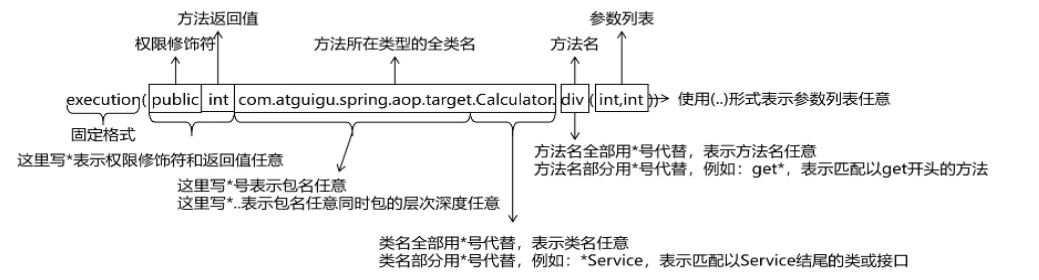
Spring AOP基于注解方式实现和细节
目录 一、Spring AOP底层技术 二、初步实现AOP编程 三、获取切点详细信息 四、 切点表达式语法 五、重用(提取)切点表达式 一、Spring AOP底层技术 SpringAop的核心在于动态代理,那么在SpringAop的底层的技术是依靠了什么技术呢&#x…...

CVPR2023论文及代码合集来啦~
以下内容由马拉AI整理汇总。 下载:点我跳转。 狂肝200小时的良心制作,529篇最新CVPR2023论文及其Code,汇总成册,制作成《CVPR 2023论文代码检索目录》,包括以下方向: 1、2D目标检测 2、视频目标检测 3、…...
基于ETLCloud的自定义规则调用第三方jar包实现繁体中文转为简体中文
背景 前面曾体验过通过零代码、可视化、拖拉拽的方式快速完成了从 MySQL 到 ClickHouse 的数据迁移,但是在实际生产环境,我们在迁移到目标库之前还需要做一些过滤和转换工作;比如,在诗词数据迁移后,发现原来 MySQL 中…...
TDesign在按钮上加入图标组件
在实际开发中 我们经常会遇到例如 添加或者查询 我们需要在按钮上加入图标的操作 TDesign自然也有预备这样的操作 首先我们打开文档看到图标 例如 我们先用某些图标 就可以点开下面的代码 可以看到 我们的图标大部分都是直接用tdesign-icons-vue 导入他的组件就可以了 而我…...

Linux 终端命令行 产品介绍
Linux命令手册内置570多个Linux 命令,内容包含 Linux 命令手册。 【软件功能】: 文件传输 bye、ftp、ftpcount、ftpshut、ftpwho、ncftp、tftp、uucico、uucp、uupick、uuto、scp备份压缩 ar、bunzip2、bzip2、bzip2recover、compress、cpio、dump、gun…...
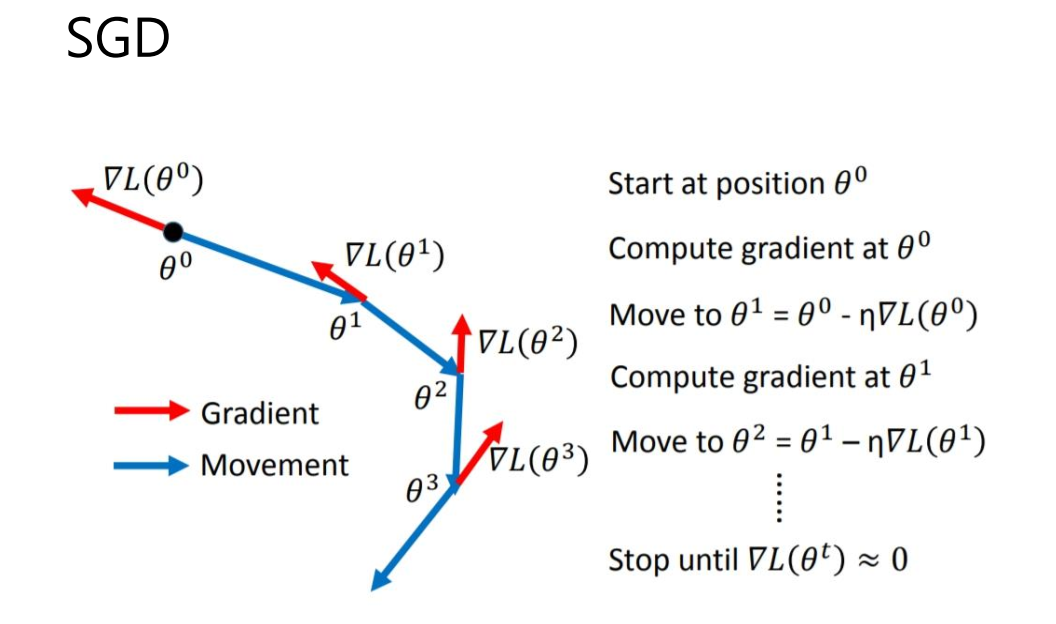
计算机毕设 基于深度学习的植物识别算法 - cnn opencv python
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 MobileNetV2网络4 损失函数softmax 交叉熵4.1 softmax函数4.2 交叉熵损失函数 5 优化器SGD6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点&a…...
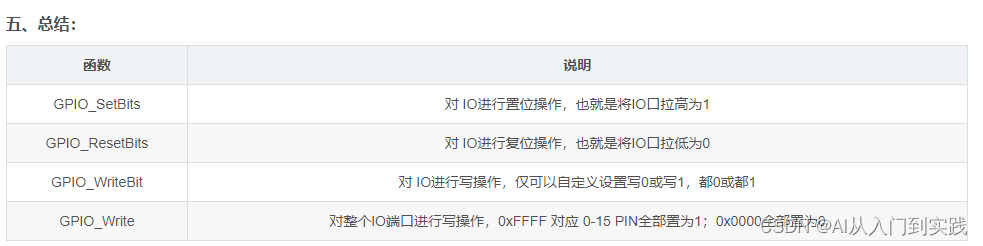
【STM32】学习笔记-江科大
【STM32】学习笔记-江科大 1、STM32F103C8T6的GPIO口输出 2、GPIO口输出 GPIO(General Purpose Input Output)通用输入输出口可配置为8种输入输出模式引脚电平:0V~3.3V,部分引脚可容忍5V输出模式下可控制端口输出高低电平&#…...
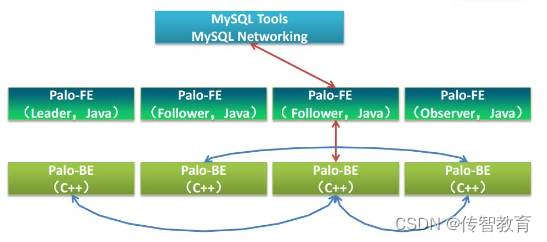
Doris架构中包含哪些技术?
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。 为什么要将这三种技术整合? Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎。 Impala是一个…...
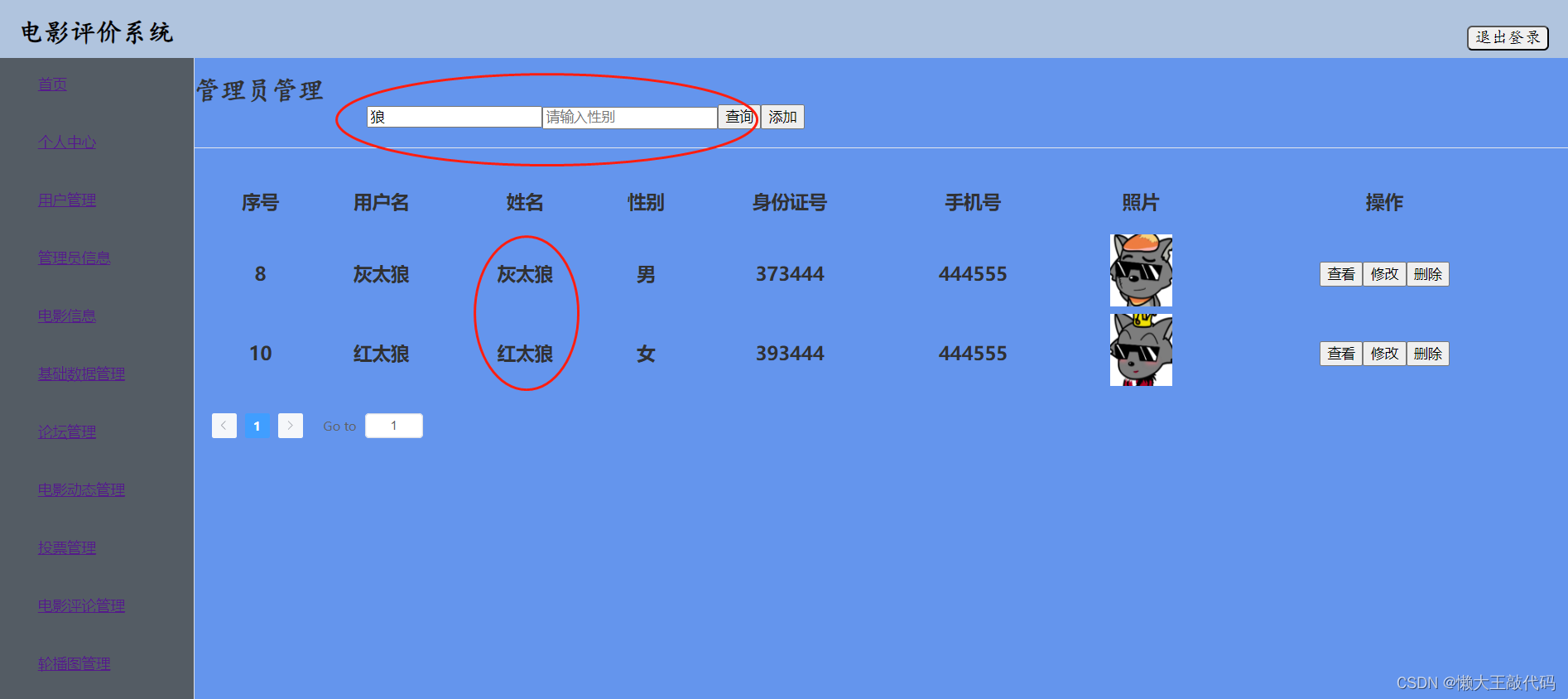
《vue3实战》通过indexOf方法实现电影评价系统的模糊查询功能
目录 前言 一、indexOf是什么?indexOf有什么作用? 含义: 作用: 二、功能实现 这段是查询过程中过滤筛选功能的代码部分: 分析: 这段是查询用户和性别功能的代码部分: 分析: 三、最终效…...

java对时间序列每x秒进行分组
问题:将一个时间序列每5秒分一组,返回嵌套的list; 原理:int除int会得到一个int(也就是损失精度) 输入:排序后的list,每几秒分组值 private static List<List<Long>> get…...

八月更新 | CI 构建计划触发机制升级、制品扫描 SBOM 分析功能上线!
点击链接了解详情 这个八月,腾讯云 CODING DevOps 对持续集成、制品管理、项目协同、平台权限等多个产品模块进行了升级改进,为用户提供更灵活便捷的使用体验。以下是 CODING 新功能速递,快来看看是否有您期待已久的功能特性: 01…...

Spring核心配置步骤-完全基于XML的配置
Spring框架的核心配置涉及多个方面,包括依赖注入(DI)、面向切面编程(AOP)等。以下是一般情况下配置Spring应用程序的核心步骤: 1. **引入Spring依赖:** 在项目的构建工具(如Maven、…...

宏基官网下载的驱动怎么安装(宏基笔记本如何安装系统)
本文为大家介绍宏基官网下载的驱动怎么安装宏基笔记本驱动(宏基笔记本如何安装系统),下面和小编一起看看详细内容吧。 宏碁笔记本怎么一键更新驱动 1. 单击“开始”,然后选择“所有程序”。 2. 单击Acer,然后单击Acer eRecovery Management。…...

基于AVR128单片机抢答器proteus仿真设计
一、系统方案 二、硬件设计 原理图如下: 三、单片机软件设计 1、首先是系统初始化 void timer0_init() //定时器初始化 { TCCR00x07; //普通模式,OC0不输出,1024分频 TCNT0f_count; //初值,定时为10ms TIFR0x01; //清中断标志…...

openGauss学习笔记-54 openGauss 高级特性-MOT
文章目录 openGauss学习笔记-54 openGauss 高级特性-MOT54.1 MOT特性及价值54.2 MOT关键技术54.3 MOT应用场景54.4 不支持的数据类型54.5 使用MOT54.6 将磁盘表转换为MOT openGauss学习笔记-54 openGauss 高级特性-MOT openGauss引入了MOT(Memory-Optimized Table&…...

InsCode AI 创作助手
RESTful API是一种架构风格和设计原则,用于构建Web服务和应用程序。它基于HTTP协议,以资源为中心,对资源进行各种操作。RESTful API的主要特点包括: 使用HTTP协议进行传输和通信;操作和状态均以资源为中心;…...

深度解析Clarity AI超分辨率架构:从算法原理到实战优化指南
深度解析Clarity AI超分辨率架构:从算法原理到实战优化指南 【免费下载链接】clarity-upscaler Clarity AI | AI Image Upscaler & Enhancer - free and open-source Magnific Alternative 项目地址: https://gitcode.com/GitHub_Trending/cl/clarity-upscale…...

cimgui生成器完全解析:从Lua脚本到C接口的魔法转换 [特殊字符]
cimgui生成器完全解析:从Lua脚本到C接口的魔法转换 🎯 【免费下载链接】cimgui c-api for imgui (https://github.com/ocornut/imgui) Look at: https://github.com/cimgui for other widgets 项目地址: https://gitcode.com/gh_mirrors/ci/cimgui …...

未来5年,程序员换工作,请做好降薪准备!
最近看到不少大厂的去年和一季度财报都公布了,不少人年终奖也发的差不多了,再加上金三银四也过了有一段时间了。按理来说,该晋升的晋升,该跳槽的跳槽,该加薪的加薪,基本尘埃落定,我公号后台应该…...

别再死记硬背公式了!用‘推磨小矮人’和‘磁极跳舞’理解PMSM的电角度与机械角度
用“推磨小矮人”和“磁极跳舞”轻松掌握PMSM角度转换 电机控制领域的初学者常被永磁同步电机(PMSM)中电角度与机械角度的关系困扰。传统教材中“电角度极对数机械角度”的公式虽然简洁,却缺乏直观的物理图像支撑。本文将用两个生活化的比喻…...

别再为EDFA仿真报错发愁了!手把手教你用OptiSystem搞定‘Initial Delay’和‘Iterations’设置
光通信仿真实战:EDFA参数调优与收敛问题深度解析 第一次打开OptiSystem完成EDFA仿真时,看到红色报错提示框弹出那种手足无措的感觉,相信很多工程师都记忆犹新。不同于简单的单向光路设计,掺铒光纤放大器(EDFAÿ…...

3分钟学会B站缓存视频转换:m4s转MP4完整指南
3分钟学会B站缓存视频转换:m4s转MP4完整指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过这样的困扰?在B…...

论文排版不求人:手把手教你用Word样式搞定独立目录、分栏与页眉页脚
论文排版不求人:Word样式驱动的全流程排版解决方案 在学术写作中,内容质量与格式规范同等重要。一篇结构清晰、排版专业的论文不仅能提升阅读体验,更能体现研究者的严谨态度。然而,许多学者和学生在面对Word复杂的排版功能时常常陷…...

18V/4A同步降压转换器:MPQ8632GLE-4的COT控制与快速瞬态响应解析
MPQ8632GLE-4:4A/18V 同步降压转换器的紧凑型电源解决方案在通信设备、分布式电源系统以及服务器主板等应用中,电源管理单元需要在小面积内实现高效率的电压转换,同时保持良好的瞬态响应。传统的 PWM 控制器往往需要复杂的环路补偿设计&#…...

STM32F103驱动TM1650数码管:从硬件连接到完整代码的保姆级避坑指南
STM32F103驱动TM1650数码管:从硬件连接到完整代码的保姆级避坑指南 第一次接触STM32F103和TM1650数码管模块时,我像大多数嵌入式新手一样,以为按照教程连接几根线、复制几段代码就能轻松点亮数码管。直到实际动手才发现,从硬件连接…...

OBS背景移除插件:从零到一的AI虚拟背景终极指南 [特殊字符]
OBS背景移除插件:从零到一的AI虚拟背景终极指南 🎬 【免费下载链接】obs-backgroundremoval An OBS plugin for removing background in portrait images (video), making it easy to replace the background when recording or streaming. 项目地址: …...