CUDA小白 - NPP(2) -图像处理-算数和逻辑操作(2)
cuda小白
原始API链接 NPP
GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》
常见的NppStatus,可以看这里。
如有问题,请指出,谢谢
Logical Operations
逻辑操作主要就是与、或、异或、右移、左移,非等逻辑操作,同样还是分为两个大类,一个是基于单张图像和常数的,另外一个是基于多张图像的。
AndC
第一大类以AndC为例子,主要是就是比较图像与提供的constant(每个通道一个值)进行与操作之后的结果。
// 有无I的区别在于是否直接对图像进行操作
NppStatus nppiAndC_8u_C3R(const Npp8u *pSrc1,int nSrc1Step,const Npp8u aConstants[3],Npp8u *pDst,int nDstStep,NppiSize oSizeROI);
NppStatus nppiAndC_8u_C3IR(const Npp8u aConstants[3],Npp8u *pSrcDst,int nSrcDstStep,NppiSize oSizeROI);
code
#include <iostream>
#include <cuda_runtime.h>
#include <npp.h>
#include <opencv2/opencv.hpp>#define PRINT_VALUE(value) { \std::cout << "[GPU] " << #value << " = " << value << std::endl; }#define CUDA_FREE(ptr) { if (ptr != nullptr) { cudaFree(ptr); ptr = nullptr; } }int main() {std::string directory = "../";// =============== load image ===============cv::Mat image = cv::Mat(500, 500, CV_8UC3, cv::Scalar(255, 255, 255));cv::Rect rc1 = cv::Rect(150, 150, 200, 200);cv::Rect rc2 = cv::Rect(200, 200, 200, 200);cv::Rect rc3 = cv::Rect(300, 0, 100, 200);cv::Rect rc4 = cv::Rect(0, 0, 200, 100);cv::Mat(200, 200, CV_8UC3, cv::Scalar(75, 75, 75)).copyTo(image(rc1));cv::Mat(200, 200, CV_8UC3, cv::Scalar(100, 100, 100)).copyTo(image(rc2));cv::Mat(200, 100, CV_8UC3, cv::Scalar(125, 125, 125)).copyTo(image(rc3));cv::Mat(100, 200, CV_8UC3, cv::Scalar(150, 150, 150)).copyTo(image(rc4));cv::imwrite(directory + "orin.jpg", image);int image_width = image.cols;int image_height = image.rows;int image_size = image_width * image_height * 3;std::cout << "Image info : image_width = " << image_width<< ", image_height = " << image_height << std::endl;// =============== malloc && cpy ===============uint8_t *in_ptr;cudaMalloc((void**)&in_ptr, image_size * sizeof(uint8_t));cudaMemcpy(in_ptr, image.data, image_size, cudaMemcpyHostToDevice);uint8_t *out_ptr, *out_ptr1;cudaMalloc((void**)&out_ptr, image_size * sizeof(uint8_t));cudaMalloc((void**)&out_ptr1, image_size * sizeof(uint8_t));NppiSize roi1, roi2;roi1.width = image_width;roi1.height = image_height;roi2.width = image_width / 2;roi2.height = image_height / 2;uint8_t constant[3] = { (uint8_t)100, (uint8_t)100, (uint8_t)100 };// nppiAdd_8u_C3RSfscv::Mat out_image = cv::Mat::zeros(image_height, image_width, CV_8UC3);cv::Mat out_image1 = cv::Mat::zeros(image_height, image_width, CV_8UC3);NppStatus status;status = nppiAndC_8u_C3R(in_ptr, image_width * 3, constant, out_ptr, image_width * 3, roi1);if (status != NPP_SUCCESS) {std::cout << "[GPU] ERROR nppiAndC_8u_C3R failed, status = " << status << std::endl;return false;}cudaMemcpy(out_image.data, out_ptr, image_size, cudaMemcpyDeviceToHost);cv::imwrite(directory + "and.jpg", out_image);status = nppiAndC_8u_C3R(in_ptr, image_width * 3, constant, out_ptr1, image_width * 3, roi2);if (status != NPP_SUCCESS) {std::cout << "[GPU] ERROR nppiAndC_8u_C3R failed, status = " << status << std::endl;return false;}cudaMemcpy(out_image1.data, out_ptr1, image_size, cudaMemcpyDeviceToHost);cv::imwrite(directory + "and_roi.jpg", out_image1);// freeCUDA_FREE(in_ptr)CUDA_FREE(out_ptr)CUDA_FREE(out_ptr1)
}
make
cmake_minimum_required(VERSION 3.20)
project(test)find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
file(GLOB CUDA_LIBS "/usr/local/cuda/lib64/*.so")add_executable(test test.cpp)
target_link_libraries(test${OpenCV_LIBS}${CUDA_LIBS}
)
result
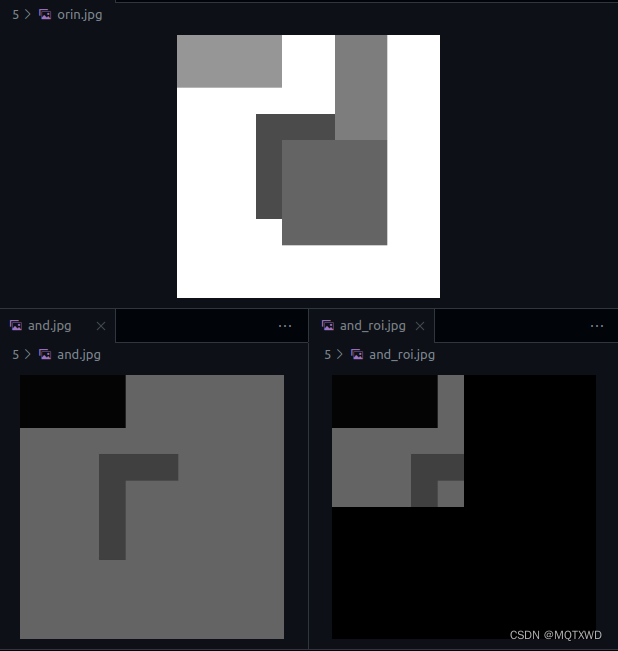
注意点:
- 该函数是将图像的三个通道分别于Constant的值进行按位与的操作,测试的例子中分别使用了255,75, 100, 125, 150三种像素,与100与之后分别为100,4,4,100,100,4。
- 由于roi的存在,可以仅保存roi区域内的结果,也就是说输出的地址其可以仅申请roi的区域的大小。
And
针对两张图的操作,包含与、或、非、异或。
NppStatus nppiAnd_8u_C3R(const Npp8u *pSrc1,int nSrc1Step,const Npp8u *pSrc2,int nSrc2Step,Npp8u *pDst,int nDstStep,NppiSize oSizeROI);NppStatus nppiAnd_8u_C3IR(const Npp8u *pSrc,int nSrcStep,Npp8u *pSrcDst,int nSrcDstStep,NppiSize oSizeROI);
code
#include <iostream>
#include <cuda_runtime.h>
#include <npp.h>
#include <opencv2/opencv.hpp>#define PRINT_VALUE(value) { \std::cout << "[GPU] " << #value << " = " << value << std::endl; }#define CUDA_FREE(ptr) { if (ptr != nullptr) { cudaFree(ptr); ptr = nullptr; } }int main() {std::string directory = "../";// =============== load image ===============cv::Mat image_dog = cv::imread(directory + "dog.png");int image_width = image_dog.cols;int image_height = image_dog.rows;int image_size = image_width * image_height * 3;cv::Mat image = cv::Mat(image_height, image_width, CV_8UC3, cv::Scalar(100, 125, 150));std::cout << "Image info : image_width = " << image_width<< ", image_height = " << image_height << std::endl;// =============== malloc && cpy ===============uint8_t *in_ptr, *mask;cudaMalloc((void**)&in_ptr, image_size * sizeof(uint8_t));cudaMalloc((void**)&mask, image_size * sizeof(uint8_t));cudaMemcpy(in_ptr, image_dog.data, image_size, cudaMemcpyHostToDevice);cudaMemcpy(mask, image.data, image_size, cudaMemcpyHostToDevice);uint8_t *out_ptr, *out_ptr1;cudaMalloc((void**)&out_ptr, image_size * sizeof(uint8_t));cudaMalloc((void**)&out_ptr1, image_size * sizeof(uint8_t));NppiSize roi1, roi2;roi1.width = image_width;roi1.height = image_height;roi2.width = image_width / 2;roi2.height = image_height / 2;// nppiAdd_8u_C3RSfscv::Mat out_image = cv::Mat::zeros(image_height, image_width, CV_8UC3);cv::Mat out_image1 = cv::Mat::zeros(image_height, image_width, CV_8UC3);NppStatus status;status = nppiAnd_8u_C3R(in_ptr, image_width * 3, mask, image_width * 3, out_ptr, image_width * 3, roi1);if (status != NPP_SUCCESS) {std::cout << "[GPU] ERROR nppiAnd_8u_C3R failed, status = " << status << std::endl;return false;}cudaMemcpy(out_image.data, out_ptr, image_size, cudaMemcpyDeviceToHost);cv::imwrite(directory + "and.jpg", out_image);status = nppiAnd_8u_C3R(in_ptr, image_width * 3, mask, image_width * 3, out_ptr1, image_width * 3, roi2);if (status != NPP_SUCCESS) {std::cout << "[GPU] ERROR nppiAnd_8u_C3R failed, status = " << status << std::endl;return false;}cudaMemcpy(out_image1.data, out_ptr1, image_size, cudaMemcpyDeviceToHost);cv::imwrite(directory + "and_roi.jpg", out_image1);// freeCUDA_FREE(in_ptr)CUDA_FREE(out_ptr)CUDA_FREE(out_ptr1)
}
make
cmake_minimum_required(VERSION 3.20)
project(test)find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})find_package(CUDA REQUIRED)
include_directories(${CUDA_INCLUDE_DIRS})
file(GLOB CUDA_LIBS "/usr/local/cuda/lib64/*.so")add_executable(test test.cpp)
target_link_libraries(test${OpenCV_LIBS}${CUDA_LIBS}
)
result
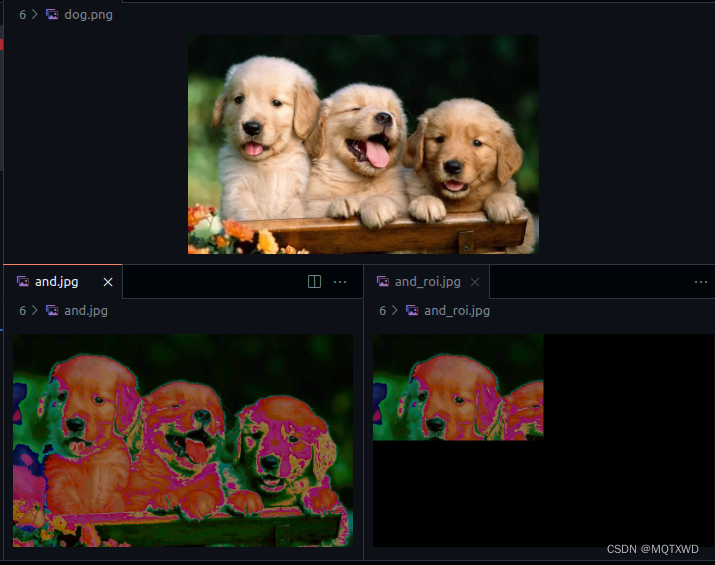
Alpha Composition
主要功能是图像的合成(AlphaComp)以及图像的不透明度调整(AlphaPremulC)。
AlphaCompC
该接口主要完成的两张图像(单通道,三通道,四通道)的合成,主要是操作是根据NppiAlphaOp来完成一定的操作。
NppStatus nppiAlphaCompC_8u_C3R(const Npp8u *pSrc1,int nSrc1Step,Npp8u nAlpha1,const Npp8u *pSrc2,int nSrc2Step,Npp8u nAlpha2,Npp8u *pDst,int nDstStep,NppiSize oSizeROI,NppiAlphaOp eAlphaOp);
AlphaComp
该接口主要完成的两张单通道或者四通道的图像的合成。主要是操作是根据NppiAlphaOp来完成一定的操作。
NppStatus nppiAlphaComp_8u_AC1R(const Npp8u *pSrc1,int nSrc1Step,const Npp8u *pSrc2,int nSrc2Step,Npp8u *pDst,int nDstStep,NppiSize oSizeROI,NppiAlphaOp eAlphaOp);
与AlphaCompC的区别在于,AlphaCompC可以指定每个输入图像的比例来完成对应的Operation,而AlphaComp则是没有。
相关文章:
CUDA小白 - NPP(2) -图像处理-算数和逻辑操作(2)
cuda小白 原始API链接 NPP GPU架构近些年也有不少的变化,具体的可以参考别的博主的介绍,都比较详细。还有一些cuda中的专有名词的含义,可以参考《详解CUDA的Context、Stream、Warp、SM、SP、Kernel、Block、Grid》 常见的NppStatus…...
)
python+redis实现布隆过滤器(含redis5.0版本以上和5.0以下版本的两份代码)
布隆过滤器是一种空间效率极高的概率数据结构,用于测试一个元素是否是集合的成员。如果布隆过滤器返回 False,则元素绝对不在集合中。如果返回 True,则元素可能在集合中,但也可能是一个误报。布隆过滤器利用了多个不同的哈希函数对…...
)
SpringBoot Thymeleaf iText7 生成 PDF(2023/08/29)
SpringBoot Thymeleaf iText7 生成 PDF(2023/08/29) 文章目录 SpringBoot Thymeleaf iText7 生成 PDF(2023/08/29)1. 前言2. 技术思路3. 实现过程4. 测试 1. 前言 近期在项目种遇到了实时生成复杂 PDF 的需求,经过一番…...
【核磁共振成像】并行采集MRI
目录 一、并行成像二、SENSE重建三、SMASH重建四、灵敏度校准五、AUTO-SMASH和VD-AUTO-SMASH六、GRAPPA重建七、SPACE RIP重建算法八、PILS重建算法九、PRUNO重建算法十、UNFOLD算法 一、并行成像 并行MR成像(pMRI):相位阵列接受线圈不但各有自己专用的接受通道,而且…...
深度图相关评测网站
文章目录 1 单目/Stereo相关测评网站介绍12 单目/Stereo相关测评网站介绍23 单目/Stereo相关测评网站介绍3 1 单目/Stereo相关测评网站介绍1 https://vision.middlebury.edu/stereo/eval3/ 2 单目/Stereo相关测评网站介绍2 http://www.cvlibs.net/datasets/kitti/eval_stereo…...
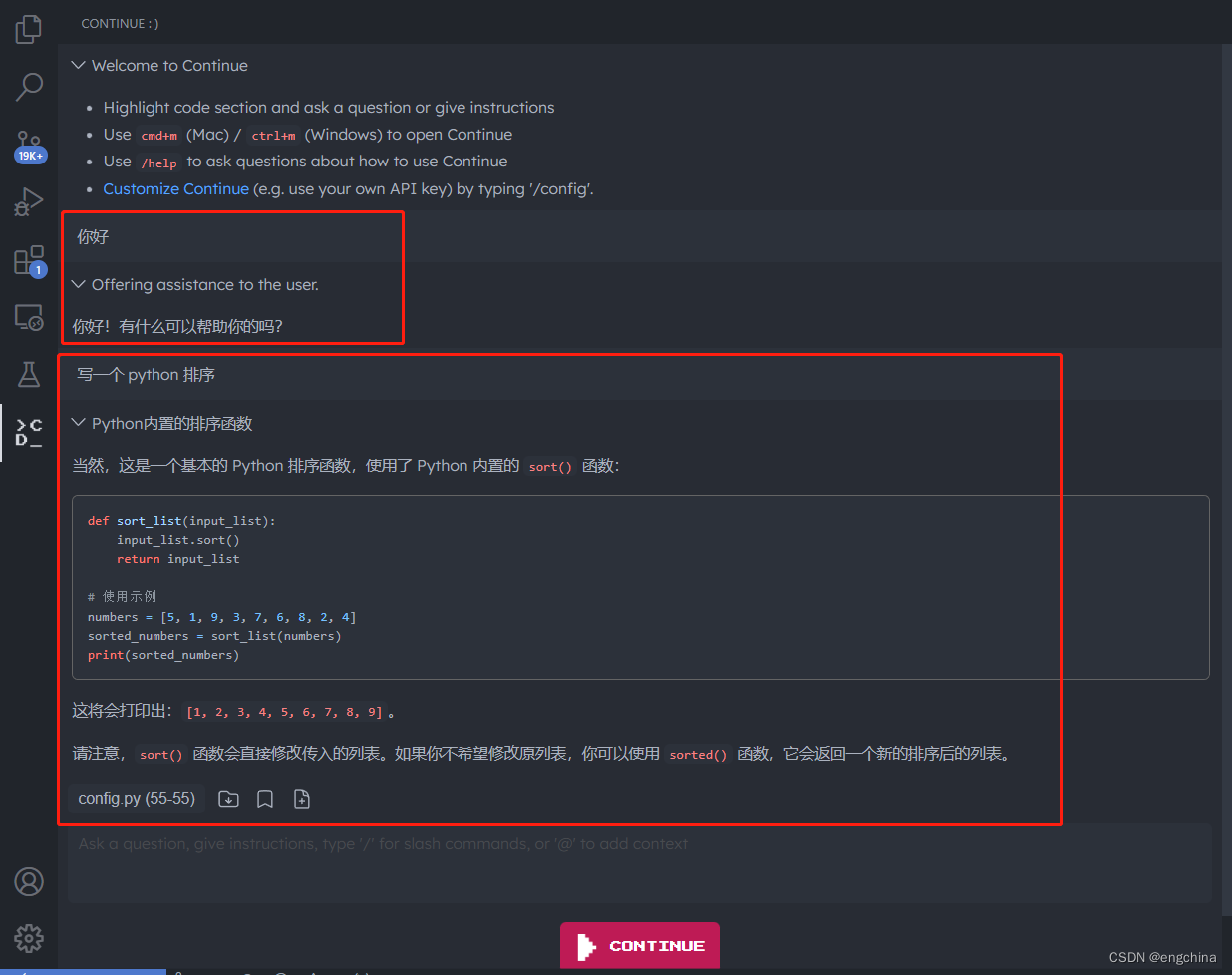
本地部署 CodeLlama 并在 VSCode 中使用 CodeLlama
本地部署 CodeLlama 并在 VSCode 中使用 CodeLlama 1. CodeLlama 是什么2. CodeLlama Github 地址3. 下载 CodeLlama 模型4. 部署 CodeLlama5. 在 VSCode 中使用 CodeLlama6. 使用WSGI启动服务7. 创建 start.sh 启动脚本 1. CodeLlama 是什么 Code Llama 是一个基于 Llama 2 的…...

Agilent33220A任意波形发生器
20MHz正弦波和方波脉冲、斜披、三角波,噪声和直流波形14-bit,50MSa/s,64K点任意波形AM、FM、PM、FSK和PWM凋制线性和对数扫描及脉冲串模式10mVpp至10Vpp幅苗范围图形化界面可以对信号设置进行可视化验证通过USB、GPIB和LAN连接 性能优异的各种函数的波形…...
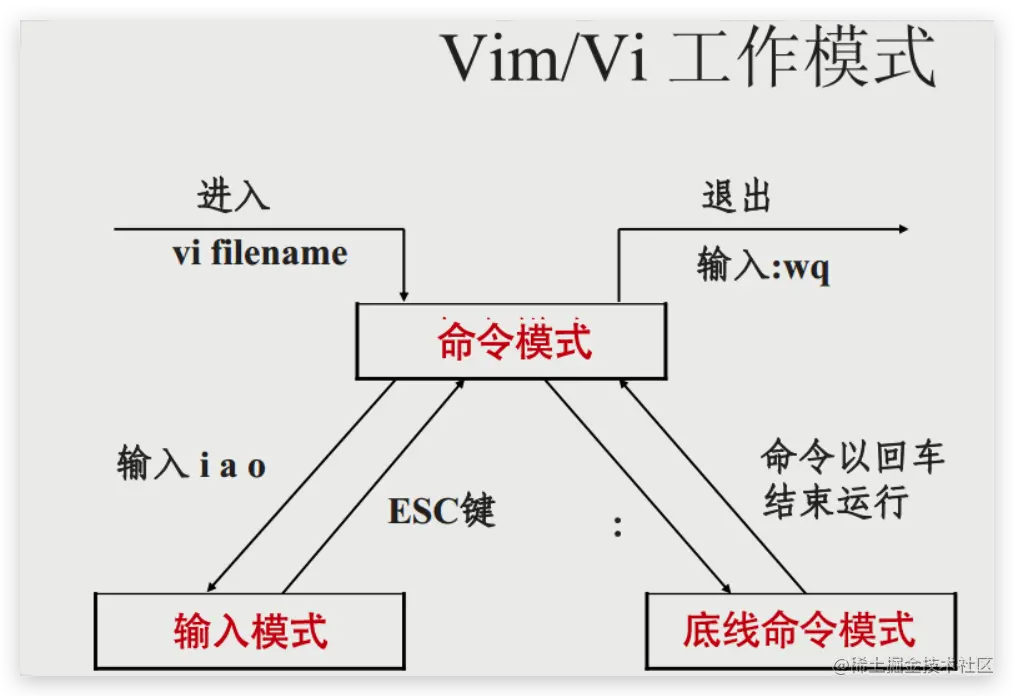
springboot第37集:kafka,mqtt,Netty,nginx,CentOS,Webpack
image.png binzookeeper-server-start.shconfigzookeeper.properties.png image.png image.png 消费 image.png image.png image.png image.png image.png image.png image.png image.png image.png Netty的优点有很多: API使用简单,学习成本低。功能强大…...
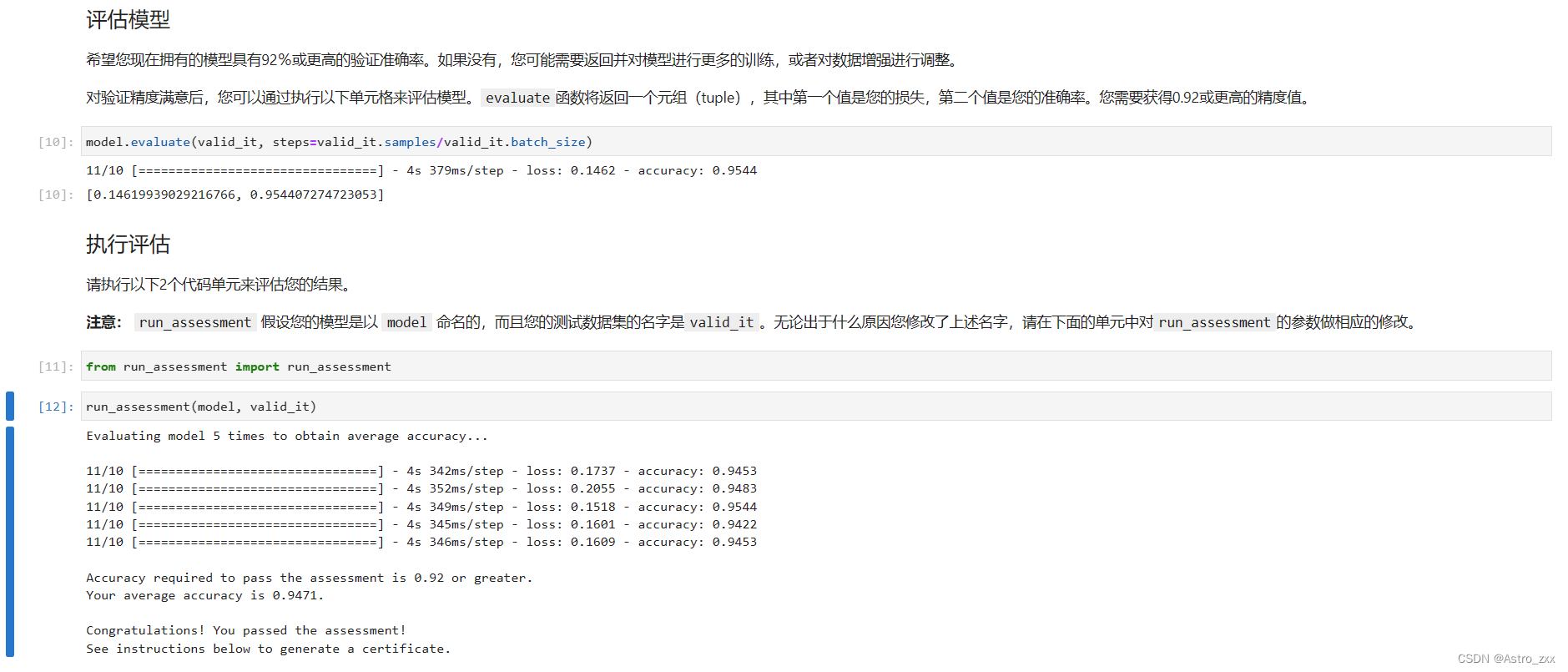
NVIDIA DLI 深度学习基础 答案 领取证书
最后一节作业是水果分类的任务,一共6类,使用之前学习的知识在代码段上进行填空。 加载ImageNet预训练的基础模型 from tensorflow import kerasbase_model keras.applications.VGG16(weights"imagenet",input_shape(224, 224, 3),include_t…...

axios模拟表单提交
axios默认是application/json方式提交,controller接收的时候必须以RequestBody的方式接收,有时候不太方便。如果axios以application/x-www-form-urlencoded方式提交数据,controller接收的时候只要保证名字应对类型正确即可。 前端代码&#…...

智安网络|探索物联网架构:构建连接物体与数字世界的桥梁
物联网是指通过互联网将各种物理设备与传感器连接在一起,实现相互通信和数据交换的网络系统。物联网架构是实现这一连接的基础和框架,它允许物体与数字世界之间的互动和协作。 一、物联网架构的概述 物联网架构是一种分层结构,它将物联网系…...
胡歌深夜发文:我对不起好多人
胡歌的微博又上了热搜。 8月29日01:18分,胡歌微博发文称:“我尽量保持冷静,我对不起好多人,我希望对得起这短暂的一生”,并配了一张自己胡子拉碴的图,右眼的伤疤清晰可见。 不少网友留言称“哥你又喝多了吗…...

C++二级题
数字放大 #include<iostream> #include<string.h> #include<stdio.h> #include<iomanip> #include<cmath> #include<bits/stdc.h> int a[2000][2000]; int b[2000]; char c[2000]; long long n; using namespace std; int main() {cin>…...

NetApp AFF A900:适用于数据中心的超级产品
NetApp AFF A900:适用于数据中心的超级产品 AFF A 系列中的 AFF A900 高端 NVMe 闪存存储功能强大、安全可靠、具有故障恢复能力,提供您为任务关键型企业级应用程序提供动力并保持数据始终可用且安全所需的一切。 产品功能与特性 AFF A900:…...

入海排污口水质自动监测系统,助力把好入河入海“闸门”
随着经济社会的不断发展,污水的排放强度不断加大,大量的污水排入河流、湖泊和海洋中,造成了水体污染,严重影响着我国的用水安全、公众健康、经济发展与社会稳定。入河入海排污口是污染物进入河流和海洋的最后关口,也是…...
:基础知识梳理(概念部分))
AUTOSAR知识点 之 ECUM (一):基础知识梳理(概念部分)
目录 1、概述 2、ECUM的工作状态 2.1、Startup状态 2.2、UP状态 2.3、RUN状态 2.4、SLEEP状态...
(二、数组交集问题))
leetcode分类刷题:哈希表(Hash Table)(二、数组交集问题)
1、当需要快速判断某元素是否出现在序列中时,就要用到哈希表了。 2、本文针对的总结题型为给定两个及多个数组,求解它们的交集。接下来,按照由浅入深层层递进的顺序总结以下几道题目。 3、以下题目需要共同注意的是:对于两个数组&…...
[Mac软件]Adobe After Effects 2023 v23.5 中文苹果电脑版(支持M1)
After Effects是动画图形和视觉效果的行业标准。由运动设计师、平面设计师和视频编辑用于创建复杂的动画图形和视觉上吸引人的视频。 创建动画图形 使用预设样式为文本和图形添加动画效果,或逐帧调整它们。编辑、添加深度、制作动画或转换为可编辑的路径ÿ…...
)
范德波尔方程详细介绍与Python实现(附说明)
引言: 在研究真空管放大器的过程中,写下了一个振动微分方程。当时人们并没有混沌或是对初始条件敏感的概念。不过,当混沌理论有一定发展后,人们重新回顾这个方程时发现它其实是个混沌方程。当时,范德波尔在 Nature 杂志报告了基于这个微分方程的霓虹灯实验,发现当驱动信号…...
常用的GPT插件
0.简介 随着chatgpt爆火,这玩意并不对国内用户开放,如果想要使用的话还要需要进行翻墙以及国外手机号才能进行注册。 对于国内来说有很多国内免费的方法,这里就整理一下,方便大家开发 1. 网站类型 下面的网站无需注册即可免费…...

Modbus三种类型详解:RTU、ASCII、TCP
Modbus协议主要分为三种类型:Modbus RTU、Modbus ASCII和Modbus TCP。这三种类型基于不同的物理层和编码方式,以适应不同的通信环境和需求。 下表清晰地对比了这三种主要类型的核心差异: 特性维度Modbus RTU (Remote Terminal Unit)Modbus …...

Performance Fish深度解析:如何通过四级缓存架构实现《环世界》400%性能优化
Performance Fish深度解析:如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance Fish是一款专为《环世界》&#x…...

现货TJA1101AHN/0Z是NXP推出的一款高性能、低功耗的汽车以太网PHY芯片,作为TJA1101A的改进版本,专为车载电子系统设计,支持100BASE-T1标准,具备出色的可靠性与集成度
TJA1101AHN/0Z 是NXP(恩智浦)推出的一款高性能、低功耗的汽车以太网PHY芯片,作为TJA1101A的改进版本,专为车载电子系统设计,支持100BASE-T1标准,具备出色的可靠性与集成度。核心性能与优势:…...

Sunshine游戏串流:打造你自己的云端游戏主机
Sunshine游戏串流:打造你自己的云端游戏主机 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在客厅大屏、卧室平板甚至手机上玩书房电脑里的3A大作吗?S…...

RT-Thread启动流程与BSP移植实战:从复位向量到多任务调度
1. 项目概述:从“上电”到“跑起来”的旅程当你拿到一块新的开发板,烧录好RT-Thread的固件,按下复位键,屏幕上开始打印出熟悉的“ | / -”启动动画和版本信息时,你有没有想过,从芯片上电复位到你的main_thr…...
)
保姆级教程:用Python+OpenCV高效切割Potsdam语义分割数据集(附完整代码)
PythonOpenCV实战:Potsdam语义分割数据集高效切割全流程解析 第一次接触Potsdam数据集时,面对那些6000x6000像素的巨幅航拍图像,我的GPU在训练时直接报显存不足的错误。这让我意识到,高分辨率图像的切割预处理不是可选项…...

iOS 18.1 5G功能深度解析:从智能省电到SA网络优化
1. 项目概述:一次聚焦于连接体验的深度更新作为一名长期跟踪移动操作系统生态的从业者,每次苹果发布新的iOS版本,我都会习惯性地去拆解其更新日志,看看哪些是“面子工程”,哪些是真正触及用户体验核心的“里子升级”。…...

CANN/asnumpy-docs 架构设计
Architecture 【免费下载链接】asnumpy-docs 项目地址: https://gitcode.com/cann/asnumpy-docs This document describes the internal architecture of AsNumpy, including the three-layer design, the core NPUArray data structure, the API module layout, and t…...

告警爆炸,根因定位困难?用DevOps Agent帮你自动查!
随着企业在亚马逊云科技上的工作负载日益复杂——Amazon EC2集群、Amazon RDS数据库、Amazon ECS/EKS容器、Amazon Lambda函数、网络与负载均衡等多种服务交织运行——运维团队面临严峻挑战:告警爆炸:Amazon CloudWatch、第三方监控(Datadog、…...

终极指南:如何在Windows 11上轻松安装Android应用?APK Installer完整教程
终极指南:如何在Windows 11上轻松安装Android应用?APK Installer完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Window…...