[ 云计算 | AWS ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南

文章目录
- 一、前言
- 二、所需 Maven 依赖
- 三、先决必要的几个条件信息
- 四、创建客户端连接
- 五、Amazon S3 存储桶操作
- 5.1. 创建桶
- 5.2. 列出桶
- 六、Amazon S3 对象操作
- 6.1. 上传对象
- 6.2. 列出对象
- 6.3. 下载对象
- 6.4. 复制、重命名和移动对象
- 6.5. 删除对象
- 6.6. 删除多个对象
- 七、文末总结
一、前言
在本文中,我们将探索如何利用 Java 编程与 Amazon S3(即简单存储服务)存储系统进行互动。
需要牢记,S3 的结构异常简单:每个存储桶能够容纳大量的对象,这些对象可以通过 SOAP 接口或 REST 风格的 API 进行访问。
接下来,我们将使用适用于Java的AWS开发工具包来实现S3存储桶的创建、列举以及删除。同时,我们还将学会如何上传、列举、下载、复制、移动、重命名以及删除这些存储桶内的各个对象。
二、所需 Maven 依赖
在开始之前,我们需要在项目中声明 AWS SDK 依赖项:
<dependency><groupId>software.amazon.awssdk</groupId><artifactId>s3</artifactId><version>2.20.52</version>
</dependency>
要查看最新版本,我们可以检查 Maven Central,或者其他的国内 Maven 仓库。
三、先决必要的几个条件信息
要使用AWS SDK,我们需要一些东西:
- AWS 帐户:我们需要一个 Amazon Web Services 帐户。如果我们没有,我们可以直接在 AWS 控制台创建一个帐户。
- AWS 安全凭证:这些是我们的访问密钥,允许我们以编程方式调用 AWS API 操作。我们可以通过两种方式获取这些凭证:使用“安全凭证”页面的访问密钥部分中的 AWS 根账户凭证,或者使用
IAM控制台中的 IAM 用户凭证。 - 选择 AWS 区域(Region):我们还必须选择要存储 Amazon S3 数据的 AWS 区域。请记住,S3 存储价格因地区而异。有关更多详细信息,请参阅官方文档。
四、创建客户端连接
首先,我们需要创建一个客户端连接来访问 Amazon S3 Web 服务。为此,我们将使用 Amazon S3 接口:
AWSCredentials credentials = new BasicAWSCredentials("<AWS accesskey>", "<AWS secretkey>"
);
然后我们将配置客户端:
AmazonS3 s3client = AmazonS3ClientBuilder.standard().withCredentials(new AWSStaticCredentialsProvider(credentials)).withRegion(Regions.US_EAST_2).build();
五、Amazon S3 存储桶操作
5.1. 创建桶
需要注意的是,存储桶命名空间是由系统的所有用户共享的。因此,我们的存储桶名称在 Amazon S3 中的所有现有存储桶名称中必须是唯一的(稍后我们将了解如何检查这一点)。
另外,根据官方文档规定,Bucket 名称必须符合以下要求:
- 名称不应包含下划线
- 名称长度应介于 3 到 63 个字符之间
- 名称不应以破折号结尾
- 名称不能包含相邻的句点
- 名称后面不能包含破折号(例如,“my-.bucket.com”和“my.-bucket”无效)
- 名称不能包含大写字符
现在让我们创建一个存储桶:
String bucketName = "baeldung-bucket";if(s3client.doesBucketExist(bucketName)) {LOG.info("Bucket name is not available."+ " Try again with a different Bucket name.");return;
}
CreateBucketRequest bucketRequest = CreateBucketRequest.builder().bucket(bucketName).build();s3Client.createBucket(bucketRequest);
在创建存储桶之前,我们必须使用doesBucketExist()方法检查存储桶名称是否可用。如果名称可用,那么我们将构建一个CreateBucketRequest 并提供存储桶名称。最后一步是将bucketRequest传递给 S3Client 的CreateBucketRequest createBucketRequest的createBucket。
5.2. 列出桶
现在我们已经创建了一些存储桶,让我们使用listBuckets ()方法打印 S3 环境中可用的所有存储桶的列表。此方法将返回一个ListBucketsResponse, 其中包含有关存储桶的信息。
ListBucketsResponse listBucketsResponse = s3Client.listBuckets();// Display the bucket names
List<Bucket> buckets = listBucketsResponse.buckets();
System.out.println("Buckets:");
for (Bucket bucket : buckets) {System.out.println(bucket.name());
}
这将列出 S3 环境中存在的所有存储桶:
baeldung-bucket
baeldung-bucket-test2
elasticbeanstalk-us-east-2
5.3. 删除桶
**在删除存储桶之前,确保存储桶是空的非常重要。**否则,将会抛出异常。
首先,我们需要构建一个DeleBucketRequest实例并向其传递存储桶名称。然后,我们调用 s3Client 对象上的deleteBucket方法,并将请求作为参数传递。
另请注意,只有存储桶的所有者才能删除它,无论其权限如何(访问控制策略):
try {DeleteBucketRequest deleteBucketRequest = DeleteBucketRequest.builder().bucket(bucketName).build();s3Client.deleteBucket(deleteBucketRequest);System.out.println("Successfully deleted bucket : " + bucketName);
} catch (S3Exception e) {System.err.println(e.getMessage());System.exit(1);
}
六、Amazon S3 对象操作
Amazon S3 存储桶内的文件或数据集合称为对象。我们可以对对象执行多种操作,例如上传、列出、下载、复制、移动、重命名和删除。
6.1. 上传对象
上传对象是一个非常简单的过程。首先,我们将构建一个PutObjectRequest实例,指定存储桶名称和密钥。然后,我们将该请求和包含数据的文件的路径传递给 s3Client 的putObject方法:
PutObjectRequest request = PutObjectRequest.builder().bucket(bucketName).key(key).build();return s3Client.putObject(request, Path.of(file.toURI()) );
6.2. 列出对象
我们将使用listObjects()方法列出 S3 存储桶中的所有可用对象:
ListObjectsV2Request listObjectsV2Request = ListObjectsV2Request.builder().bucket(bucketName).build();
ListObjectsV2Response listObjectsV2Response = s3Client.listObjectsV2(listObjectsV2Request);List<S3Object> contents = listObjectsV2Response.contents();System.out.println("Number of objects in the bucket: " + contents.stream().count());
contents.stream().forEach(System.out::println);
要列出 AWS S3 存储桶中的对象,我们需要创建一个ListObjectsV2Request实例并指定存储桶名称。然后,我们在 s3Client 对象上调用 listObjectsV2方法,并将请求作为参数传递。此方法返回一个ListObjectsV2Response,其中包含有关存储桶中对象的信息。
6.3. 下载对象
要下载对象,我们首先创建一个GetObjectRequest实例并将存储桶名称和密钥作为输入参数传递给它。然后,我们将其提供给 getObjectAsBytes()方法并获取响应。一旦我们得到响应,我们就可以提取字节数组。最后一步是处理字节数组:
GetObjectRequest objectRequest = GetObjectRequest.builder().bucket(bucketName).key(objectKey).build();ResponseBytes<GetObjectResponse> responseResponseBytes = s3Client.getObjectAsBytes(objectRequest);byte[] data = responseResponseBytes.asByteArray();// Write the data to a local file.
java.io.File myFile = new java.io.File("/Users/user/Desktop/hello.txt" );
OutputStream os = new FileOutputStream(myFile);
os.write(data);
System.out.println("Successfully obtained bytes from an S3 object");
os.close();
6.4. 复制、重命名和移动对象
我们可以通过调用 s3client 上的copyObject()方法来复制对象,该方法接受CopyObjectRequest实例。因此,CopyObjectRequest接受四个参数:
- 源存储桶名称
- 源存储桶中的对象键
- 目标存储桶名称(可以与源存储桶名称相同)
- 目标存储桶中的对象键
CopyObjectRequest copyObjectRequest = CopyObjectRequest.builder().sourceBucket(sourceBucketName).sourceKey(sourceKey).destinationBucket(destinationBucketName).destinationKey(destinationKey).build();return s3Client.copyObject(copyObjectRequest);
注意:我们可以结合使用copyObject()方法和deleteObject()来执行移动和重命名任务。这将涉及首先复制对象,然后将其从旧位置删除。
6.5. 删除对象
要删除对象,我们将在s3client上调用deleteObject()方法并传递DeleteObjectRequest实例。为了创建DeleteObjectRequest实例,我们需要传递要删除的对象的键和存储桶名称:
DeleteObjectRequest deleteObjectRequest = DeleteObjectRequest.builder().bucket(bucketName).key(objectKey).build();s3Client.deleteObject(deleteObjectRequest);
6.6. 删除多个对象
要一次删除多个对象,我们首先创建DeleteObjectsRequest对象并传递存储桶。然后我们将传递一个包含所有要删除的对象键的 ArrayList。
一旦我们有了这个DeleteObjectsRequest对象,我们就可以将它作为参数传递给我们的 s3client 的deleteObjects()方法。如果成功,它将删除我们提供的所有对象:
ArrayList<ObjectIdentifier> toDelete = new ArrayList<>();
for(String objKey : keys) {toDelete.add(ObjectIdentifier.builder().key(objKey).build());
}DeleteObjectsRequest deleteObjectRequest = DeleteObjectsRequest.builder().bucket(bucketName).delete(Delete.builder().objects(toDelete).build()).build();s3Client.deleteObjects(deleteObjectRequest);
七、文末总结
在本文中,我们重点介绍了在存储桶级别和对象级别与 Amazon S3 Web 服务交互的基础知识。重点在 Java 应用中使用 Amazon S3(Simple Storage Service)进行存储桶和对象操作的方法、详细说明了如何进行存储桶操作,包括创建桶和列出桶。在对象操作部分,我们涵盖了上传、列出和下载对象的过程,还介绍了复制、重命名、移动对象以及删除对象的方法。此外,我们还提供了删除多个对象的操作步骤。通过本文,小伙伴们可以了解如何通过 Java 代码有效地与 Amazon S3 进行交互,实现对存储桶和对象的各种操作。
相关文章:
[ 云计算 | AWS ] Java 应用中使用 Amazon S3 进行存储桶和对象操作完全指南
文章目录 一、前言二、所需 Maven 依赖三、先决必要的几个条件信息四、创建客户端连接五、Amazon S3 存储桶操作5.1. 创建桶5.2. 列出桶 六、Amazon S3 对象操作6.1. 上传对象6.2. 列出对象6.3. 下载对象6.4. 复制、重命名和移动对象6.5. 删除对象6.6. 删除多个对象 七、文末总…...

【Spring Boot】Spring Boot 配置 Hikari 数据库连接池
文章目录 前言配置 前言 数据库连接池是一个提高程序与数据库的连接的优化,连接池它主要作用是提高性能、节省资源、控制连接数、连接管理等操作; 程序中的线程池与之同理,都是为了优化、提高性能。 配置 spring:datasource:hikari:# 设置是…...

MR混合现实石油化工课堂情景实训教学演示
MR(混合现实)技术是一种结合了虚拟现实(VR)和增强现实(AR)优势的新型技术,在教育领域具有广阔的应用前景。在石油化工课堂中,MR混合现实情景实训教学的应用可以大大提高学生的学习效…...

php thinkphp 抖音支付,订单同步接口分享
1. 抖音支付 需要获取抖音小程序的AppID,AppSecret,需要配置回调地址,Token获取SALT 官方地址:支付,订单同步 以下干货仅针对于有一定开发基础的精英,0基础的止步。 public function DouyinPay($openId,$id,$body 抖音担保支付…...

excel功能区(ribbonx)编程笔记--2 button控件与checkbox控件
我们上一章简单先了解了ribbonx的基本内容,以及使用举例实现自己修改ribbox的内容,本章紧接上一章,先讲解一下ribbonx的button控件。 在功能区的按钮中,可以使用内置图像或提供自已的图像,可以指定大按钮或者更小的形式,添加少量的代码甚至可以同时提供标签。此外,可以利…...

JavaScript 知识点
立即执行函数 代码(function () {// ... })();创建函数的同时立即执行,没有绑定任何事件,也无需等待任何异步操作function () {} 是一个匿名函数,包围它的一对括号将其转换为一个表达式,紧跟其后的一对括号调用了这个函数。立即执…...

深入理解 JVM 之——动手编译 JDK
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验 本篇为深入理解 Java 虚拟机第一章的实战内容,推荐在学习前先掌握基础的 Linux 操作、编译原理基础以及扎实的 C/C 功底。 该系列的 GitHub 仓库:https://github.com/Doge2077/lear…...
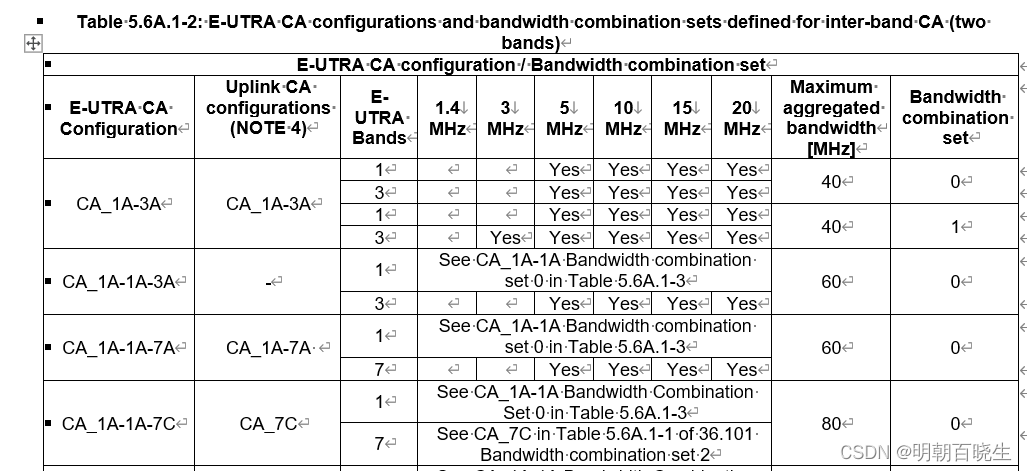
[移动通讯]【Carrier Aggregation in LTE】【 Theory + Log analysis-1】
CA: Carrrier Aggregation PCC: Primary Component Carrier SCC: SCC Secondary Component Carrier 目录: 背景介绍 PCC & SCC 聚合方式 Precondition for CA 一 背景介绍 在没有CA 技术前,手机和基站以单子载波的方式,收发…...

Sui诚邀您参加KBW「首尔Web3之夜」
韩国区块链周(KBW)是由FACTBLOCK创办,Hashed联合主办的年度盛会。今年的KBW将于9月4–10日在韩国首尔举办。作为亚洲最具影响力的Web3行业盛会之一,KBW将汇聚业界优秀的参与者和先驱者,共同探讨区块链行业的未来。 Su…...

19.CSS雨云动画特效
效果 源码 <!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><title>Cloud & Rain Animation</title><link rel="stylesheet" href="style.css"> </head> <bo…...
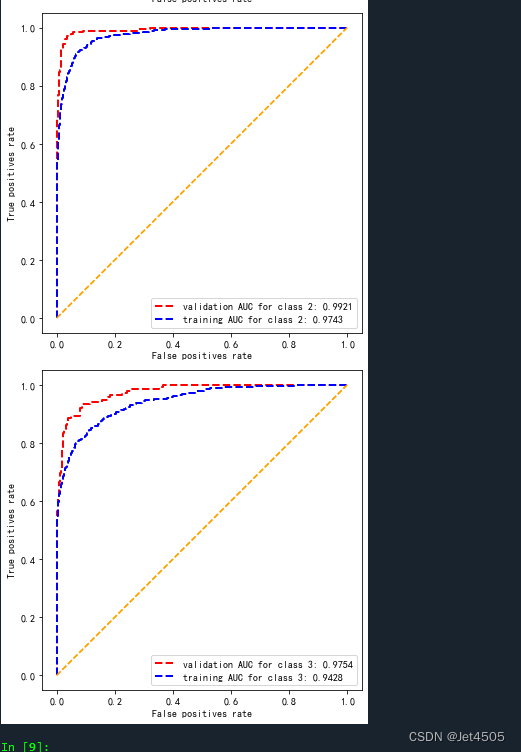
第61步 深度学习图像识别:多分类建模(TensorFlow)
基于WIN10的64位系统演示 一、写在前面 截至上期,我们一直都在做二分类的任务,无论是之前的机器学习任务,还是最近更新的图像分类任务。然而,在实际工作中,我们大概率需要进行多分类任务。例如肺部胸片可不仅仅能诊断…...

Spark 7:Spark SQL 函数定义
SparkSQL 定义UDF函数 方式1语法: udf对象 sparksession.udf.register(参数1,参数2,参数3) 参数1:UDF名称,可用于SQL风格 参数2:被注册成UDF的方法名 参数3:声明UDF的返回值类型 ud…...
ThinkPHP 文件上传 fileSystem 扩展的使用
ThinkPHP 文件上传 ThinkPHP 文件上传 扩展 filesystem一、安装 FileSystem 扩展二、认识 filesystem 配置文件 config/filesystem.php三、上传验证(涉及到验证器的知识点)四、文件上传demo ThinkPHP 文件上传 扩展 filesystem ThinkPHP 为我们 提供了 …...
液体神经网络LLN:通过动态信息流彻底改变人工智能
巴乌米克泰吉 一、说明 在在人工智能领域,神经网络已被证明是解决复杂问题的非常强大的工具。多年来,研究人员不断寻求创新方法来提高其性能并扩展其能力。其中一种方法是液体神经网络(LNN)的概念,这是一个利用动态计算…...

2023年的今天,PMP项目管理认证还值得考吗?
首先我肯定它值得考,PMP认证的教材和考纲都会随着项目管理工具和市场趋势而更新,不用担心会过时。 PMP项目管理认证是什么? 英文全称是Project Management Professional,中文全称叫做项目管理专业人士资格认证。它是由美国项目管…...

【JavaSE专栏91】Java如何主动发起Http、Https请求?
作者主页:Designer 小郑 作者简介:3年JAVA全栈开发经验,专注JAVA技术、系统定制、远程指导,致力于企业数字化转型,CSDN学院、蓝桥云课认证讲师。 主打方向:Vue、SpringBoot、微信小程序 本文讲解了如何使用…...

给oracle逻辑导出clob大字段、大数据量表提提速
文章目录 前言一、大表数据附:查询大表 二、解题思路1.导出排除大表的数据2.rowid切片导出大表数据Linux代码如下(示例):Windows代码如下(示例):手工执行代码如下(示例)&…...

研发规范第九讲:通用类命名规范(重点)
研发规范第九讲:通用类命名规范(重点) 无规范不成方圆。我自己非常注重搭建项目结构的起步过程,应用命名规范、模块的划分、目录(包)的命名,我觉得非常重要,如果做的足够好ÿ…...
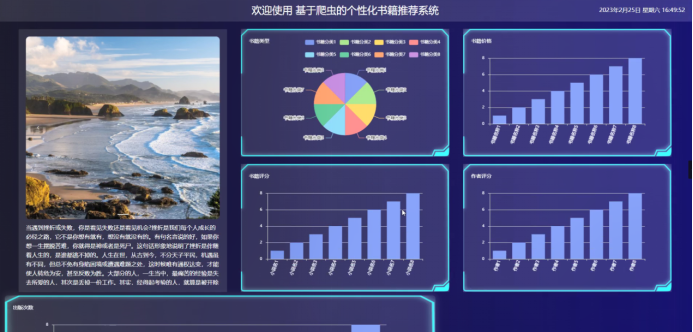
python+django+协同过滤算法-基于爬虫的个性化书籍推荐系统(包含报告+源码+开题)
为了提高个性化书籍推荐信息管理的效率;充分利用现有资源;减少不必要的人力、物力和财政支出来实现管理人员更充分掌握个性化书籍推荐信息的管理;开发设计专用系统--基于爬虫的个性化书籍推荐系统来进行管理个性化书籍推荐信息,以…...

系统架构:软件工程
文章目录 资源知识点自顶向下与自底向上形式化方法结构化方法敏捷方法净室软件工程面向服务的方法面向对象的方法快速应用开发螺旋模型软件过程和活动开放式源码开发方法功用驱动开发方法统一过程模型RUP基于构件的软件开发UML 资源 信息系统开发方法 知识点 自顶向下与自底…...
)
从74LS00与非门到74LS86异或门:手把手教你用面包板搭建数字电路基础实验(附波形分析)
从74LS00与非门到74LS86异或门:面包板上的数字电路实战指南 在电子技术的浩瀚海洋中,数字电路犹如一座连接现实与虚拟的桥梁。对于初学者而言,从理论到实践的跨越往往充满挑战——实验室里昂贵的设备、复杂的接线、固定的实验流程,…...

电力系统时序一致性保障:elec-ops-prediction的长时序稳定性约束实现
电力系统时序一致性保障:elec-ops-prediction的长时序稳定性约束实现 【免费下载链接】elec-ops-prediction elec-ops-prediction 是 CANN 社区 Electrical Engineering SIG(电力行业兴趣小组)旗下的电力负荷预测算子库, 聚焦于电…...

解密ASCII图表魔法:ditaa将文本艺术转化为专业图表的技术揭秘
解密ASCII图表魔法:ditaa将文本艺术转化为专业图表的技术揭秘 【免费下载链接】ditaa ditaa is a small command-line utility that can convert diagrams drawn using ascii art (drawings that contain characters that resemble lines like | / - ), into proper…...
)
用C语言链表实现一个简易图书管理系统(附完整源码)
从零构建C语言链表图书管理系统:工程化实践指南 当你第一次在数据结构课本上看到链表时,是否觉得这些抽象的概念离实际开发很遥远?作为C语言初学者,我完全理解这种困惑——直到亲手用链表实现了一个真正的图书管理系统。本文将带你…...

Zynq开发中XSA文件更新全流程:从硬件修改到软件调试
1. 项目概述:为什么需要更新XSA文件?在基于Xilinx Zynq系列SoC的开发流程里,XSA文件(Xilinx Support Archive)是一个承上启下的核心枢纽。它本质上是一个压缩包,里面封装了硬件平台(Hardware Pl…...

社会风气何以如此?渡劫未彻底,继续渡劫。从为人民服务到为节点服务
社会风气何以如此?渡劫未彻底,继续渡劫。从为人民服务到为节点服务。 Jianbing Zhu 1 1 ECT-OS-JiuHuaShan 文明实践室 ORCID: 0009-0006-8591-1891 DOI: 10.5281/zenodo.20302480 Email: ect-os-jiuhuashanzohomail.cn 预印本提交:202…...
)
WordPress密码忘了别慌!5种找回方法保姆级教程(含MySQL命令行和functions.php修改)
WordPress密码重置全攻略:从基础操作到高级解决方案 1. 紧急情况下的密码恢复策略 遇到WordPress后台密码丢失的情况,首先需要保持冷静。作为全球使用最广泛的内容管理系统之一,WordPress提供了多种密码恢复机制,适用于不同技术水…...

AI 智能体 8 层架构:生产级系统构建指南
AI 智能体(Agentic AI)革命的关键不在更好的提示词,而在于系统化的架构设计。随着企业竞相部署能够自主感知、推理、规划和行动的 AI 智能体(AI Agent),真正的挑战已经从"我们能构建吗?“转变为"…...

Folcolor:14种色彩让Windows文件夹管理效率提升300%
Folcolor:14种色彩让Windows文件夹管理效率提升300% 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 你是否厌倦了在无数个黄色文件夹中寻找目标文件?Folcolor为你带…...

Prompt核心原则与技巧
1. Prompt的本质Prompt是用户和模型之间的"接口"。设计好的Prompt就像把话说清楚——越清楚,模型越能给你想要的答案。类比:就像你请人帮忙做事:说"帮我处理一下" → 对方可能做错说"帮我把这封信装进信封ÿ…...