给oracle逻辑导出clob大字段、大数据量表提提速
文章目录
- 前言
- 一、大表数据
- 附:查询大表
- 二、解题思路
- 1.导出排除大表的数据
- 2.rowid切片导出大表数据
- Linux代码如下(示例):
- Windows代码如下(示例):
- 手工执行代码如下(示例):
- 3.rowid切片导入大表数据
- 导入前准备
- linux代码如下(示例):
- windows代码如下(示例):
- 三、导出时业务卡顿如何停止
前言
Oracle在做数据迁移、还原测试库以及其他需要导出、导入数据的需求下,我们常用到数据泵来进行数据的转移操作,但往往很多事后我们要操作的库数据量都非常大,且数据库中clob字段非常多,就给我们导出带来了一些问题,导出慢或者卡在那里很久不动等问题;
有小伙伴可能会说你开并行不就行了吗?事实上当你数据库中大对象数据量占用较大时候,你会发现开并行没有任何用,那么怎么解决这个问题呢?那么思路是先排除大对象的表;然后大表再通过rowid切片多个进程导出导入。
提示:以下是本篇文章正文内容,下面案例可供参考
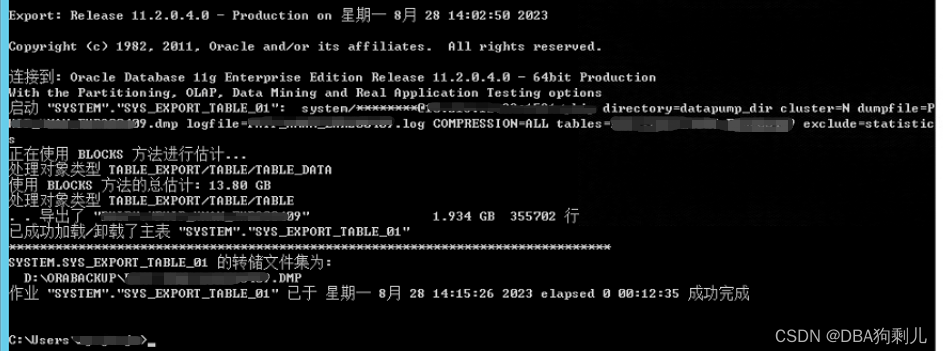
一、大表数据
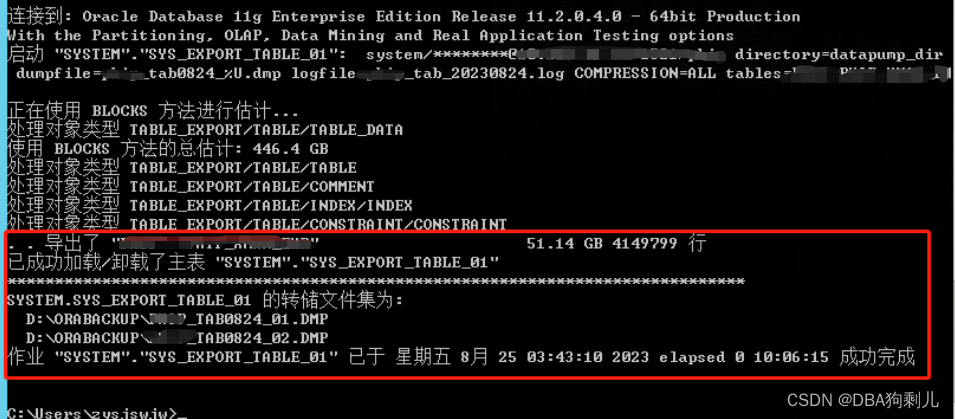
截图中可以看到,此表占用446G数据量,压缩完后大小为51G,开了2个进程并行,但没有效果,最终执行了10小时,时间是非常久的。
附:查询大表
--查看大对象,先排除导出,然后再单独导出
SELECT owner,tablespace_name,case SEGMENT_typewhen 'LOBSEGMENT' then(select table_name || '.' || column_namefrom dba_lobs twhere t.segment_name = s.segment_name)elseSEGMENT_NAMEend as SEGMENT_NAME,BYTES / 1024 / 1024 MB,BYTES / 1024 / 1024 / 1024 GBFROM DBA_SEGMENTS sOrder By 4 Desc,3 asc;
二、解题思路
1.导出排除大表的数据
命令参考:
expdp system/oracle@ip:1521/sidname directory=datapump_dir parallel=8 cluster=N dumpfile=exp_full0824_%U.dmp logfile=exp_full_20230824.log schemas=usrname COMPRESSION=ALL exclude=statistics exclude=TABLE:\"in\(\'table_name\'\)\"
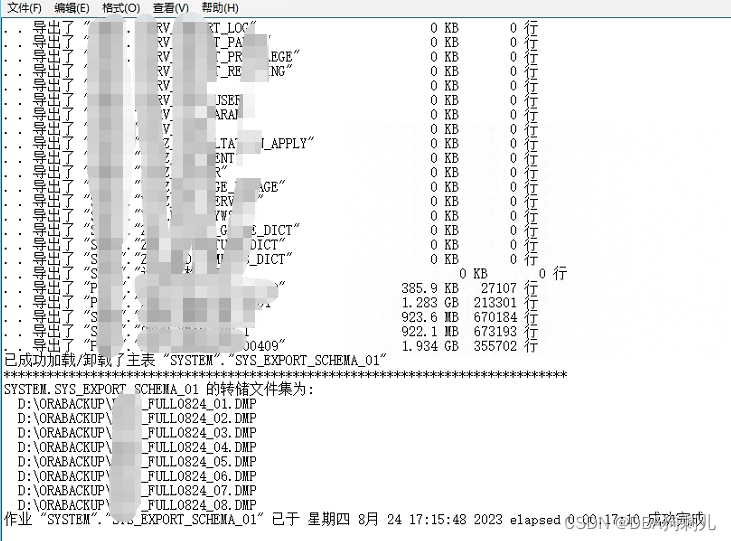
这里可以看到排除大表后整体导出时间下降到了17分钟!!!
2.rowid切片导出大表数据
rowid切片导出数据是从0开始,我们需要知道rowid的分配来控制最终想执行的并行数。
Linux代码如下(示例):
#!/bin/bash
chunk=9
for ((i=0;i<=8;i++));
do
expdp system/oracle TABLES=tablename QUERY=tablename:\"where mod\(dbms_rowid.rowid_block_number\(rowid\)\, ${chunk}\) = ${i}\" directory=DMP dumpfile=TX_${i}.DMP logfile=TX_${i}.log &
echo $i
sleep 10
done
Windows代码如下(示例):
@echo off
#这里可以带上IP地址、端口、sid
set connStr=system/oracle@ip:1521/sid_name
#这里指的并行数
set chunk=10
#sid_name
set oracle_sid=orcl
#oracle_home路径注意bin后边的‘\’
set oracle_home_path=d:\oracle\product\10.2.0\db_1\bin\rem 格式:FOR /L %variable IN (start,step,end) DO command [command-parameters]
#10个并行,0~9(开始标号、每次增加量、结束标号)
for /l %%a in (0,1,9) do (
start /b %oracle_home_path%expdp %connStr% TABLES=table_name QUERY=table_name:\"where mod\(dbms_rowid.rowid_block_number\(rowid\)\,%chunk%\) = %%a\" directory=expdpdump dumpfile=TX_%%a.DMP logfile=TX_%%a.log
timeout 10 >nul 2>nul
)
手工执行代码如下(示例):
#如下,打开三个窗口分别粘贴执行,如果要开更多的进程,需要更改3后后面的0~2
SQL> create or replace directory dmp as 'D:\dump\';
SQL> grant read,write on directory dmp to public;expdp system/oracle tables=table_name QUERY=table_name:\"where mod\(dbms_rowid.rowid_block_number\(rowid\)\,3\) = 0\" directory=DMP dumpfile=xxxx_0.dmp logfile=xxxx_0.log
expdp system/oracle tables=table_name QUERY=table_name:\"where mod\(dbms_rowid.rowid_block_number\(rowid\)\,3\) = 1\" directory=DMP dumpfile=xxxx_1.dmp logfile=xxxx_1.log
expdp system/oracle tables=table_name QUERY=table_name:\"where mod\(dbms_rowid.rowid_block_number\(rowid\)\,3\) = 2\" directory=DMP dumpfile=xxxx_2.dmp logfile=xxxx_2.log
)
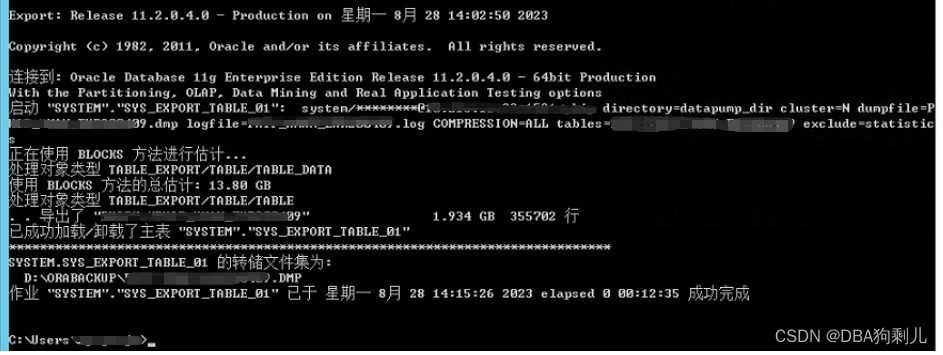
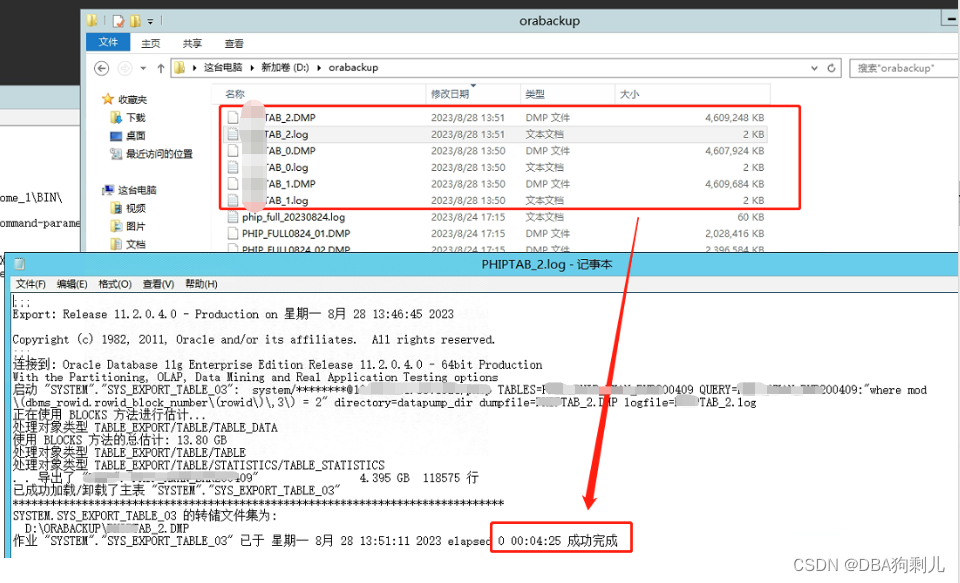
以上我拿一张14G数据表进行测试,3个并行度执行实际4分半,实际测试中切片导出数据也可以加压缩参数。
对比此张图可以看到我的切片测试已将导出实际提升了2倍左右,如果并行度更高的话,那么我们的整体时间会成倍降低。
3.rowid切片导入大表数据
导入前准备
在导入大表数据之前需要做的是:
#确保大表所在的表空间存在
select table_name,tablespace from user_tables where table_name='TABLE_NAME';
#创建用户以及表结构,建议使用plsql查询
SELECT DBMS_METADATA.GET_DDL('TABLE','TABLE_NAME') from DUAL;
linux代码如下(示例):
#!/bin/bash
for ((i=0;i<=8;i++));
do
#echo dumpfile=TX_${i}.DMP
impdp \"/ as sysdba\" directory=impdpdump dumpfile=TX_${i}.DMP logfile=impdp_TX_${i}.log DATA_OPTIONS=DISABLE_APPEND_HINT TRANSFORM=DISABLE_ARCHIVE_LOGGING:Y CONTENT=DATA_ONLY &
sleep 10
done
windows代码如下(示例):
@echo offset connStr=system/oracle
set oracle_sid=orcl
set oracle_home_path=d:\oracle\product\10.2.0\db_1\bin\rem 格式:FOR /L %variable IN (start,step,end) DO command [command-parameters]for /l %%a in (0,1,9) do (
rem 11g upper >start /b %oracle_home_path%impdp %connStr% directory=impdpdump dumpfile=TX_%%a.DMP logfile=imp_TX_%%a.log DATA_OPTIONS=DISABLE_APPEND_HINT TRANSFORM=DISABLE_ARCHIVE_LOGGING:Y CONTENT=DATA_ONLYstart /b %oracle_home_path%impdp %connStr% directory=impdpdump dumpfile=TX_%%a.DMP logfile=imp_TX_%%a.log CONTENT=DATA_ONLY
timeout 10 >nul 2>nul
)

测试表导入成功,和切片导出的时间基本相同。
三、导出时业务卡顿如何停止
select s.inst_id,to_char(sysdate,'YYYY-MM-DD HH24:MI:SS') "DATE", s.program, s.sid, 'orakill orcl2 '||spid,'kill -9 '||spid, s.status, s.username, d.job_name, p.spid, s.serial#, p.pid ,'ALTER SYSTEM KILL SESSION '||''''||s.SID||','||s.SERIAL#||',@'||s.inst_id||''''||' IMMEDIATE;' killsefrom gv$session s, gv$process p, dba_datapump_sessions d where p.addr=s.paddr and s.saddr=d.saddr and s.inst_id=p.inst_id and s.inst_id=d.inst_id; select 'orakill orcl '||spid ,'ALTER SYSTEM KILL SESSION '||''''||t1.SID||','||t1.SERIAL#||''''||' IMMEDIATE;' killse
--,'kill -9 '||spidfrom sys.gV_$PROCESS t,gv$session t1,dba_datapump_sessions d where t.addr=t1.paddr and t1.saddr=d.saddrand t1.Type='USER' and t1.username is not null;select 'drop table ' || owner_name || '.' || job_name || ' purge;' from dba_datapump_jobs where state = 'NOT RUNNING' ;
参考文献:https://mp.weixin.qq.com/s/pKNe2EzpB_PM0itpa4jrdA
相关文章:
给oracle逻辑导出clob大字段、大数据量表提提速
文章目录 前言一、大表数据附:查询大表 二、解题思路1.导出排除大表的数据2.rowid切片导出大表数据Linux代码如下(示例):Windows代码如下(示例):手工执行代码如下(示例)&…...

研发规范第九讲:通用类命名规范(重点)
研发规范第九讲:通用类命名规范(重点) 无规范不成方圆。我自己非常注重搭建项目结构的起步过程,应用命名规范、模块的划分、目录(包)的命名,我觉得非常重要,如果做的足够好ÿ…...
python+django+协同过滤算法-基于爬虫的个性化书籍推荐系统(包含报告+源码+开题)
为了提高个性化书籍推荐信息管理的效率;充分利用现有资源;减少不必要的人力、物力和财政支出来实现管理人员更充分掌握个性化书籍推荐信息的管理;开发设计专用系统--基于爬虫的个性化书籍推荐系统来进行管理个性化书籍推荐信息,以…...

系统架构:软件工程
文章目录 资源知识点自顶向下与自底向上形式化方法结构化方法敏捷方法净室软件工程面向服务的方法面向对象的方法快速应用开发螺旋模型软件过程和活动开放式源码开发方法功用驱动开发方法统一过程模型RUP基于构件的软件开发UML 资源 信息系统开发方法 知识点 自顶向下与自底…...
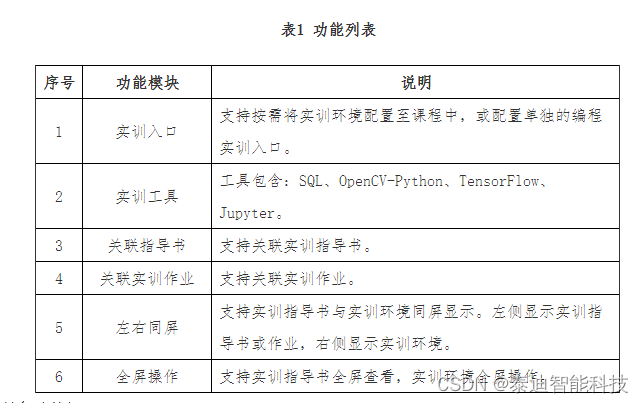
泰迪大数据实训平台产品介绍
大数据产品包括:大数据实训管理平台、大数据开发实训平台、大数据编程实训平台等 大数据实训管理平台 泰迪大数据实训平台从课程管理、资源管理、实训管理等方面出发,主要解决现有实验室无法满足教学需求、传统教学流程和工具低效耗时和内部教学…...

Linux- 文件夹相关的常用指令
1. 统计文件夹下的文件数量 在 Linux 下,有几种方法可以统计文件夹下的文件数量: 使用 ls 和 wc 命令: 这种方式可以统计目录下的直接子文件(不包括子目录里的文件)。 ls -l <目录路径> | wc -l注意:…...
在 macOS 中安装 TensorFlow 1g
tensorflow 需要多大空间 pip install tensorflow pip install tensorflow Looking in indexes: https://pypi.douban.com/simple/ Collecting tensorflowDownloading https://pypi.doubanio.com/packages/1a/c1/9c14df0625836af8ba6628585c6d3c3bf8f1e1101cafa2435eb28a7764…...

数学建模:CRITIC赋权法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 CRITIC赋权法 算法流程 构建原始数据矩阵 X X X,他是一个 m ∗ n m * n m∗n 的矩阵, m m m 表示评价对象个数, n n n 表示指标个数对原始数据矩阵进行正向化处理计算…...

Facebook message tag 使用攻略
Messenger 讯息传不出去?无法发送FB 讯息给非好友? 2020年3月,Facebook 为了防止用户被过多的推广或垃圾讯息困扰而更新使用条款,现在商家要用FB传讯息给所有人(包括非好友),应该使用 Facebook …...

气传导耳机哪个品牌比较好?综合表现很不错的气传导耳机推荐
气传导耳机不仅能够提升幸福感还能听到周围环境声,大大提高安全性。如果你在寻找一款高品质的气传导耳机,又不知从何入手时,不要担心,我已经为你精心挑选了四款市面上综合表现很不错的气传导耳机,让你享受更好的音质…...

Rabbitmq的消息转换器
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象 ,只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题: 数据体积过大 有安全漏洞 可读…...

nvidia-docker的使用
拉取镜像 docker pull nvidia/cuda可能出现的问题 问题描述 Error response from daemon: manifest for nvidia/cuda:latest not found: manifest unknown: manifest解决方法: 为找到正确且合适的docker镜像版本 在supported-tags中找到与自己系统对应的cuda版本…...
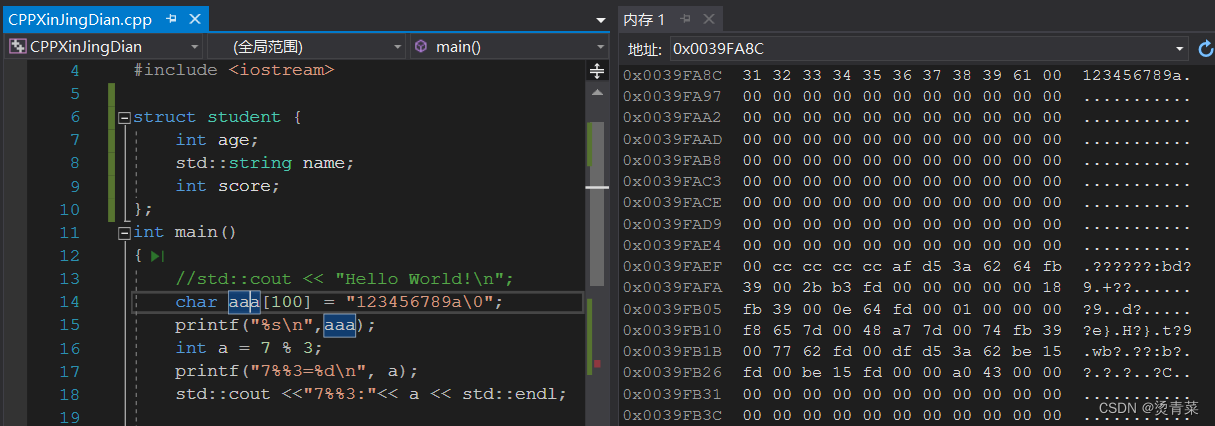
C++新经典 | C语言
目录 一、基础之查漏补缺 1.float精度问题 2.字符型数据 3.变量初值问题 4.赋值&初始化 5.头文件之<> VS " " 6.逻辑运算 7.数组 7.1 二维数组初始化 7.2 字符数组 8.字符串处理函数 8.1 strcat 8.2 strcpy 8.3 strcmp 8.4 strlen 9.函数 …...
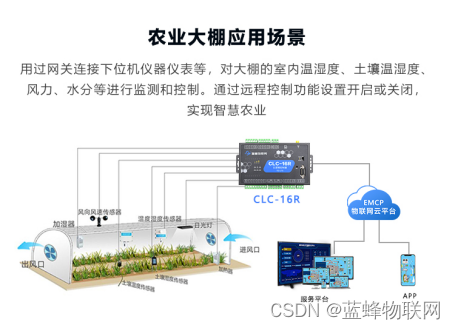
物联网智慧种植农业大棚系统
一、项目背景 智慧农业是是将物联网技术和农业生产箱管理的新型农业,依托部署在农业生产现场的各种传感节点,以物联网网关为通道形成数据传输网络,可以实现控制柜、环境监测传感器、气象监测机器等设备的远程监控,达到及时高校的…...

TabBar组件如何跳转页面?
1、先引入 2、假数据 const tabs [{key: home,title: 首页,icon: <AppOutline />,badge: Badge.dot,},{key: todo,title: 待办,icon: <UnorderedListOutline />,badge: 5,},{key: message,title: 消息,icon: (active: boolean) >active ? <MessageFill /&…...

Vue.js中,router和route
<div class"search">{{$route.params.things}}<van-nav-bar fixed title"商品列表" left-arrow click-left"$router.go(-1)" /><van-searchreadonlyshape"round"background"#ffffff"value"手机"sh…...

【微服务】07-缓存
文章目录 为不同的场景设计合适的缓存策略1. 缓存是什么2. 缓存的场景3. 缓存的策略4. 缓存位置5. 缓存实现的要点6. 注意问题7. 使用的组件8. 内存缓存和分布式缓存区别 总结 为不同的场景设计合适的缓存策略 1. 缓存是什么 缓存是计算结果的“临时”存储和重复使用缓存本质…...

权限校验中的“双token”方案
1. 双Token中的两个token分别是什么? 1.1 access_token 1.2 fresh_token 2. 为什么需要双token?一个token不行吗? 答: 两个token的职责不同。其中,access_token是在每次请求的时候携带给后端进行权限校验ÿ…...

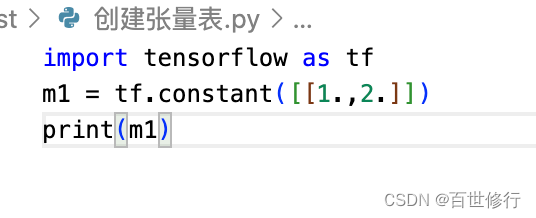
TensorFlow的基本概念
TensorFlow 是由 Google 开发的开源机器学习框架,其基本概念如下: 1. 张量(Tensor):TensorFlow 中最基本的数据结构,是多维数组,可以理解为向量或矩阵的推广。常见的张量有常量张量、变量张量和…...
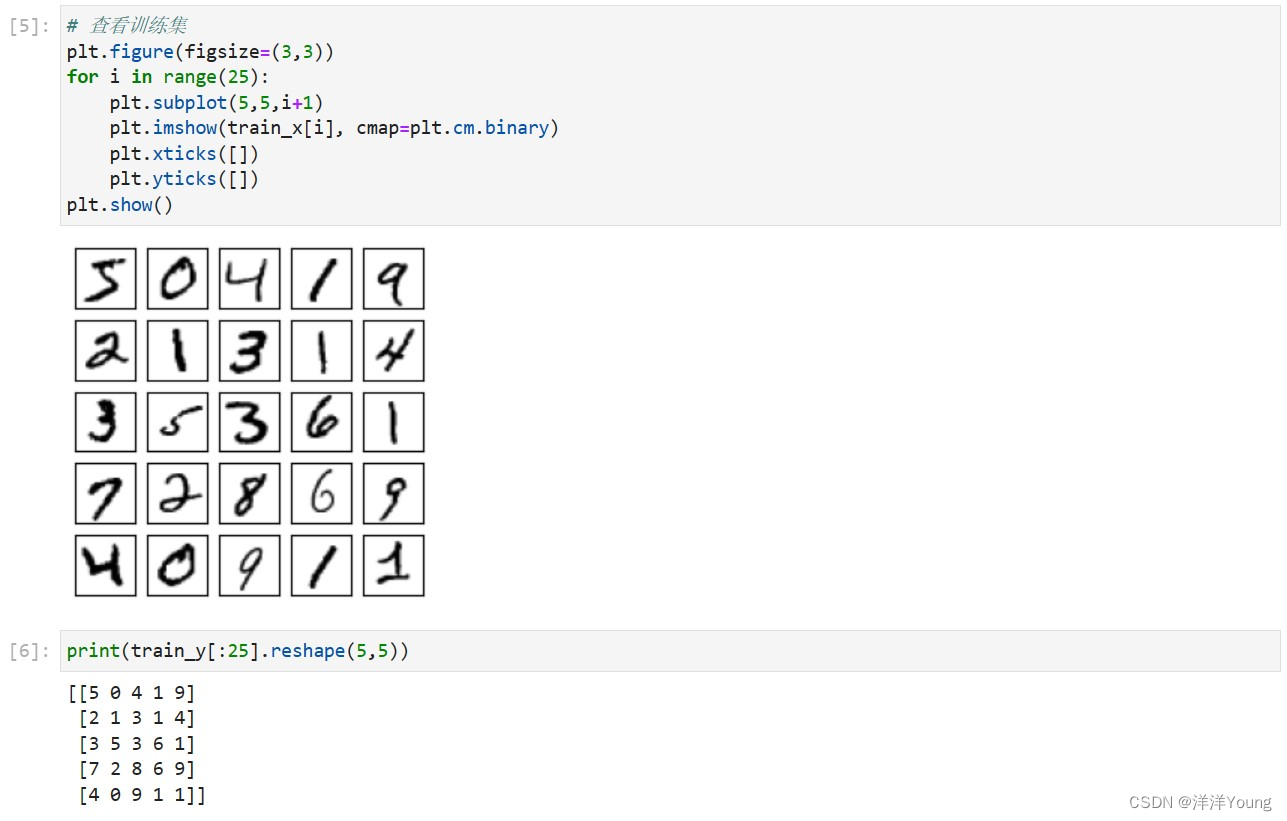
【卷积神经网络】MNIST 手写体识别
LeNet-5 是经典卷积神经网络之一,1998 年由 Yann LeCun 等人在论文 《Gradient-Based Learning Applied to Document Recognition》中提出。LeNet-5 网络使用了卷积层、池化层和全连接层,实现可以应用于手写体识别的卷积神经网络。TensorFlow 内置了 MNI…...

编写同城公益捐书物资登记流转程序,统计闲置书籍物资,对接公益捐赠渠道。
一个完全去营销化、偏工程与社会创新视角的 Python 示例项目,定位为创新与创业实验课程原型,不绑定任何公益平台、不引导捐赠渠道、不涉及任何机构背书,仅作为物资登记与流转建模工具。 同城公益捐书物资登记流转程序 ——基于物资生命周期管…...

双向脑机接口:从神经信号解码到感觉编码的核心原理与挑战
1. 从科幻到现实:双向脑机接口的演进与核心挑战十几年前,当我第一次在学术会议上看到猴子用意念控制机械臂抓取食物的视频时,那种震撼至今记忆犹新。那时,脑机接口(BCI)还只是顶级实验室里昂贵的“魔术”。…...

HLS行为差异测试:挑战与LLM驱动的解决方案
1. 高层次综合(HLS)行为差异测试的挑战与机遇在AI计算和边缘计算快速发展的今天,FPGA因其可重构性和并行计算能力,成为硬件加速的重要选择。高层次综合(High-Level Synthesis, HLS)技术允许开发者使用C/C等高级语言编写算法,然后自动转换为硬…...

Intel 14代酷睿接口更迭:技术推演与用户决策指南
1. 项目概述:一次关于“接口更迭”的深度技术推演最近,关于下一代酷睿处理器的传闻又开始在圈内流传,一个核心的焦点再次被推上风口浪尖:Intel 14代酷睿(Raptor Lake Refresh)可能又要更换CPU插槽接口了。这…...

别再只当Atlas是元数据仓库了!手把手教你用它的UI搞定数据分类与血缘追溯
别再只当Atlas是元数据仓库了!手把手教你用它的UI搞定数据分类与血缘追溯 数据治理工具常被视为"高大上"的架构师专属玩具,但Apache Atlas的UI界面却藏着连一线工程师都能立刻上手的实用功能。上周排查一个报表异常时,我发现团队里…...

GPT-4高考全真模拟测试:能力边界、技术原理与教育启示
1. 项目缘起与核心目标最近,我身边不少朋友,尤其是家里有考生的,都在讨论一个话题:现在这些大语言模型,比如GPT-4,到底有多“聪明”?它能不能像人一样思考,甚至去参加我们的高考&…...
)
告别丑表格!用xlsx-style给Vue+Element UI导出的Excel加个美颜(附完整代码)
专业级Excel导出美化实战:VueElement UI与xlsx-style深度整合指南 在企业级后台管理系统开发中,数据报表的导出功能几乎是标配需求。但开发者常遇到这样的尴尬:精心设计的页面表格导出为Excel后,所有样式荡然无存,变成…...

ubuntu服务器部署ai应用如何通过taotoken实现多模型稳定调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Ubuntu 服务器部署 AI 应用如何通过 Taotoken 实现多模型稳定调用 在 Ubuntu 服务器上部署 AI 应用时,开发者常常面临一…...

实习生,企业的青春代言人
为什么优质的口碑是招募最好的助推器? 在校园招聘中,应届生们不仅看官网的宣传,更看重学长学姐的“真实评价”。一份优质的校招实习经历,不仅能为企业培养出未来的中坚力量,更能通过学生的自发传播,让实习…...

Taotoken用量看板与账单追溯为团队开发带来的成本管控体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与账单追溯为团队开发带来的成本管控体验 对于依赖大模型API进行开发的团队而言,成本的可观测与可控性…...