第61步 深度学习图像识别:多分类建模(TensorFlow)
基于WIN10的64位系统演示
一、写在前面
截至上期,我们一直都在做二分类的任务,无论是之前的机器学习任务,还是最近更新的图像分类任务。然而,在实际工作中,我们大概率需要进行多分类任务。例如肺部胸片可不仅仅能诊断肺结核,还有COVID-19、细菌性(病毒性)肺炎等等,这就涉及到图像识别的多分类任务。
本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,构建Mobilenet多分类模型,原因还是因为它建模速度快。
同样,基于GPT-4辅助编程,改写过程见后面。
二、误判病例分析实战
使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,健康人900张,肺结核病人700张,COVID-19病人549张、细菌性(病毒性)肺炎组900张,分别存入单独的文件夹中。
(a)直接分享代码
######################################导入包###################################
from tensorflow import keras
import tensorflow as tf
from tensorflow.python.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout, Activation, Reshape, Softmax, GlobalAveragePooling2D, BatchNormalization
from tensorflow.python.keras.layers.convolutional import Convolution2D, MaxPooling2D
from tensorflow.python.keras import Sequential
from tensorflow.python.keras import Model
from tensorflow.python.keras.optimizers import adam_v2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator, image_dataset_from_directory
from tensorflow.python.keras.layers.preprocessing.image_preprocessing import RandomFlip, RandomRotation, RandomContrast, RandomZoom, RandomTranslation
import os,PIL,pathlib
import warnings
#设置GPU
gpus = tf.config.list_physical_devices("GPU")if gpus:gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0],"GPU")warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号################################导入数据集#####################################
#1.导入数据
#1.导入数据
data_dir = "./MTB-1" # 修改了路径
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)batch_size = 32
img_height = 100
img_width = 100train_ds = image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)val_ds = image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)class_names = train_ds.class_names
print(class_names)
print(train_ds)#2.检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break#3.配置数据
AUTOTUNE = tf.data.AUTOTUNEdef train_preprocessing(image,label):return (image/255.0,label)train_ds = (train_ds.cache().shuffle(800).map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size.prefetch(buffer_size=AUTOTUNE)
)val_ds = (val_ds.cache().map(train_preprocessing) # 这里可以设置预处理函数
# .batch(batch_size) # 在image_dataset_from_directory处已经设置了batch_size.prefetch(buffer_size=AUTOTUNE)
)#4. 数据可视化
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")class_names = ["COVID-19", "Normal", "Pneumonia", "Tuberculosis"] # 修改类别标签for images, labels in train_ds.take(1):for i in range(15):plt.subplot(4, 5, i + 1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片plt.imshow(images[i])# 显示标签plt.xlabel(class_names[labels[i]-1])plt.show()######################################数据增强函数################################data_augmentation = Sequential([RandomFlip("horizontal_and_vertical"),RandomRotation(0.2),RandomContrast(1.0),RandomZoom(0.5,0.2),RandomTranslation(0.3,0.5),
])def prepare(ds):ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y), num_parallel_calls=AUTOTUNE)return ds
train_ds = prepare(train_ds)###############################导入mobilenet_v2################################
#获取预训练模型对输入的预处理方法
from tensorflow.python.keras.applications import mobilenet_v2
from tensorflow.python.keras import Input, regularizers
IMG_SIZE = (img_height, img_width, 3)base_model = mobilenet_v2.MobileNetV2(input_shape=IMG_SIZE, include_top=False, #是否包含顶层的全连接层weights='imagenet')inputs = Input(shape=IMG_SIZE)
#模型
x = base_model(inputs, training=False) #参数不变化
#全局池化
x = GlobalAveragePooling2D()(x)
#BatchNormalization
x = BatchNormalization()(x)
#Dropout
x = Dropout(0.8)(x)
#Dense
x = Dense(128, kernel_regularizer=regularizers.l2(0.1))(x) # 全连接层减少到128,添加 L2 正则化
#BatchNormalization
x = BatchNormalization()(x)
#激活函数
x = Activation('relu')(x)
#输出层
outputs = Dense(4, kernel_regularizer=regularizers.l2(0.1))(x) # 输出层神经元数量修改为4
#BatchNormalization
outputs = BatchNormalization()(outputs)
#激活函数
outputs = Activation('softmax')(outputs) # 激活函数修改为'softmax'
#整体封装
model = Model(inputs, outputs)
#打印模型结构
print(model.summary())
#############################编译模型#########################################
#定义优化器
from tensorflow.python.keras.optimizers import adam_v2, rmsprop_v2
#from tensorflow.python.keras.optimizer_v2.gradient_descent import SGD
optimizer = adam_v2.Adam()
#optimizer = SGD(learning_rate=0.001)
#optimizer = rmsprop_v2.RMSprop()#常用的优化器
#all_classes = {
# 'adadelta': adadelta_v2.Adadelta,
# 'adagrad': adagrad_v2.Adagrad,
# 'adam': adam_v2.Adam,
# 'adamax': adamax_v2.Adamax,
# 'experimentaladadelta': adadelta_experimental.Adadelta,
# 'experimentaladagrad': adagrad_experimental.Adagrad,
# 'experimentaladam': adam_experimental.Adam,
# 'experimentalsgd': sgd_experimental.SGD,
# 'nadam': nadam_v2.Nadam,
# 'rmsprop': rmsprop_v2.RMSprop,#编译模型
model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy', # 多分类问题metrics=['accuracy'])#训练模型
from tensorflow.python.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateSchedulerNO_EPOCHS = 50
PATIENCE = 10
VERBOSE = 1# 设置动态学习率
annealer = LearningRateScheduler(lambda x: 1e-5 * 0.99 ** (x+NO_EPOCHS))# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)#
checkpointer = ModelCheckpoint('mtb_4_jet_best_model_mobilenetv3samll.h5',monitor='val_accuracy',verbose=VERBOSE,save_best_only=True,save_weights_only=True)train_model = model.fit(train_ds,epochs=NO_EPOCHS,verbose=1,validation_data=val_ds,callbacks=[earlystopper, checkpointer, annealer])#保存模型
model.save('mtb_4_jet_best_model_mobilenet.h5')
print("The trained model has been saved.")from tensorflow.python.keras.models import load_model
train_model=load_model('mtb_4_jet_best_model_mobilenet.h5')
###########################Accuracy和Loss可视化#################################
import matplotlib.pyplot as pltloss = train_model.history['loss']
acc = train_model.history['accuracy']
val_loss = train_model.history['val_loss']
val_acc = train_model.history['val_accuracy']
epoch = range(1, len(loss)+1)fig, ax = plt.subplots(1, 2, figsize=(10,4))
ax[0].plot(epoch, loss, label='Train loss')
ax[0].plot(epoch, val_loss, label='Validation loss')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, acc, label='Train acc')
ax[1].plot(epoch, val_acc, label='Validation acc')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
#plt.show()
plt.savefig("loss-acc.pdf", dpi=300,format="pdf")####################################混淆矩阵可视化#############################
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.models import load_model
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import math
from sklearn.metrics import precision_recall_fscore_support, accuracy_score# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions, class_names):# 生成混淆矩阵conf_numpy = confusion_matrix(labels, predictions)# 将矩阵转化为 DataFrameconf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names) plt.figure(figsize=(8,7))sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")plt.title('Confusion matrix',fontsize=15)plt.ylabel('Actual value',fontsize=14)plt.xlabel('Predictive value',fontsize=14)val_pre = []
val_label = []
for images, labels in val_ds:for image, label in zip(images, labels):img_array = tf.expand_dims(image, 0)prediction = model.predict(img_array)val_pre.append(np.argmax(prediction, axis=-1))val_label.append(label.numpy()) # 需要将标签转换为 numpy 数组class_names = ['COVID-19', 'Normal', 'Pneumonia', 'Tuberculosis'] # 修改为你的类别名称
plot_cm(val_label, val_pre, class_names)
plt.savefig("val-cm.pdf", dpi=300,format="pdf")precision_val, recall_val, f1_val, _ = precision_recall_fscore_support(val_label, val_pre, average='micro')
acc_val = accuracy_score(val_label, val_pre)
error_rate_val = 1 - acc_valprint("验证集的灵敏度(召回率)为:",recall_val, "验证集的特异度为:",precision_val, # 在多分类问题中,特异度定义不明确,这里我们使用精确度来代替"验证集的准确率为:",acc_val, "验证集的错误率为:",error_rate_val,"验证集的F1为:",f1_val)train_pre = []
train_label = []
for images, labels in train_ds:for image, label in zip(images, labels):img_array = tf.expand_dims(image, 0)prediction = model.predict(img_array)train_pre.append(np.argmax(prediction, axis=-1))train_label.append(label.numpy())plot_cm(train_label, train_pre, class_names)
plt.savefig("train-cm.pdf", dpi=300,format="pdf")precision_train, recall_train, f1_train, _ = precision_recall_fscore_support(train_label, train_pre, average='micro')
acc_train = accuracy_score(train_label, train_pre)
error_rate_train = 1 - acc_trainprint("训练集的灵敏度(召回率)为:",recall_train, "训练集的特异度为:",precision_train, # 在多分类问题中,特异度定义不明确,这里我们使用精确度来代替"训练集的准确率为:",acc_train, "训练集的错误率为:",error_rate_train,"训练集的F1为:",f1_train)################################模型性能参数计算################################
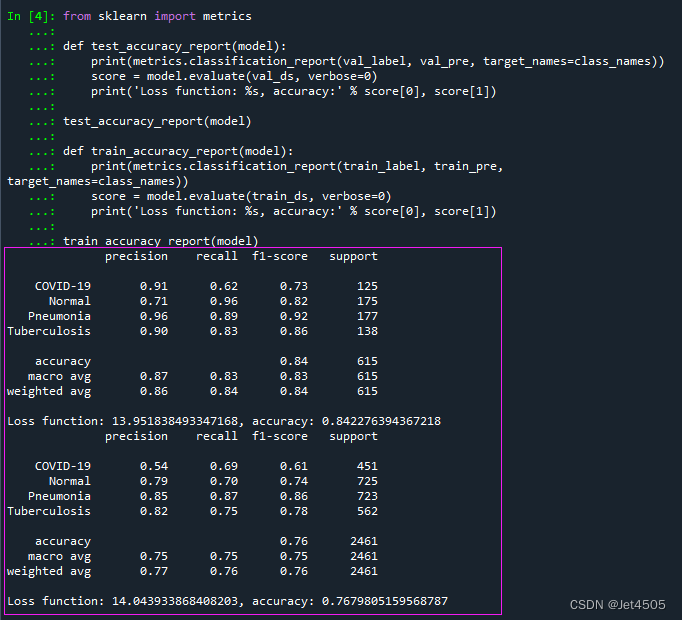
from sklearn import metricsdef test_accuracy_report(model):print(metrics.classification_report(val_label, val_pre, target_names=class_names)) score = model.evaluate(val_ds, verbose=0)print('Loss function: %s, accuracy:' % score[0], score[1])test_accuracy_report(model)def train_accuracy_report(model):print(metrics.classification_report(train_label, train_pre, target_names=class_names)) score = model.evaluate(train_ds, verbose=0)print('Loss function: %s, accuracy:' % score[0], score[1])train_accuracy_report(model)################################AUC曲线绘制####################################
from sklearn import metrics
from sklearn.preprocessing import LabelBinarizer
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.models import load_model
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import mathdef plot_roc(name, labels, predictions, **kwargs):fp, tp, _ = metrics.roc_curve(labels, predictions)plt.plot(fp, tp, label=name, linewidth=2, **kwargs)plt.xlabel('False positives rate')plt.ylabel('True positives rate')ax = plt.gca()ax.set_aspect('equal')# 需要将标签进行one-hot编码
lb = LabelBinarizer()
lb.fit([0, 1, 2, 3]) # 训练标签编码器,这里设定有四个类别
n_classes = 4 # 类别数量val_pre_auc = []
val_label_auc = []for images, labels in val_ds:for image, label in zip(images, labels): img_array = tf.expand_dims(image, 0) prediction_auc = model.predict(img_array)val_pre_auc.append(prediction_auc[0])val_label_auc.append(lb.transform([label])[0]) # 这里需要使用标签编码器进行编码val_pre_auc = np.array(val_pre_auc)
val_label_auc = np.array(val_label_auc)auc_score_val = [metrics.roc_auc_score(val_label_auc[:, i], val_pre_auc[:, i]) for i in range(n_classes)]train_pre_auc = []
train_label_auc = []for images, labels in train_ds:for image, label in zip(images, labels):img_array_train = tf.expand_dims(image, 0) prediction_auc = model.predict(img_array_train)train_pre_auc.append(prediction_auc[0])train_label_auc.append(lb.transform([label])[0])train_pre_auc = np.array(train_pre_auc)
train_label_auc = np.array(train_label_auc)auc_score_train = [metrics.roc_auc_score(train_label_auc[:, i], train_pre_auc[:, i]) for i in range(n_classes)]for i in range(n_classes):plot_roc('validation AUC for class {0}: {1:.4f}'.format(i, auc_score_val[i]), val_label_auc[:, i] , val_pre_auc[:, i], color="red", linestyle='--')plot_roc('training AUC for class {0}: {1:.4f}'.format(i, auc_score_train[i]), train_label_auc[:, i], train_pre_auc[:, i], color="blue", linestyle='--')plt.legend(loc='lower right')
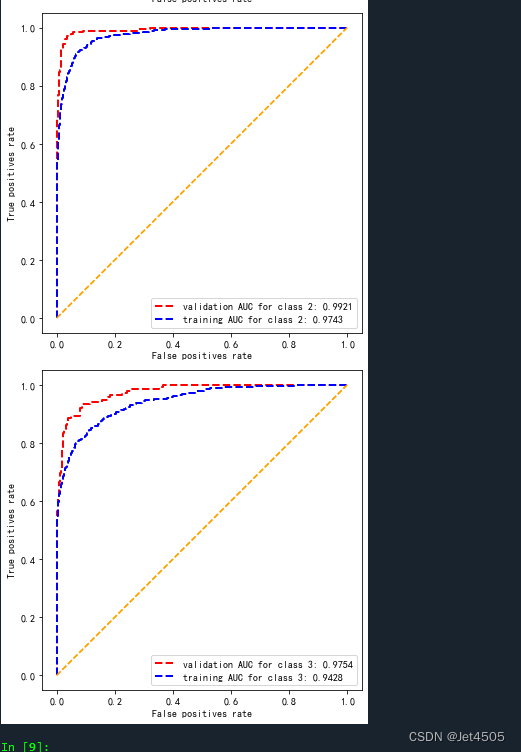
plt.savefig("roc.pdf", dpi=300,format="pdf")for i in range(n_classes):print("Class {0} 训练集的AUC值为:".format(i), auc_score_train[i], "验证集的AUC值为:", auc_score_val[i])################################AUC曲线绘制-分开展示####################################
from sklearn import metrics
from sklearn.preprocessing import LabelBinarizer
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.models import load_model
from matplotlib.pyplot import imshow
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import pandas as pd
import mathdef plot_roc(ax, name, labels, predictions, **kwargs):fp, tp, _ = metrics.roc_curve(labels, predictions)ax.plot(fp, tp, label=name, linewidth=2, **kwargs)ax.plot([0, 1], [0, 1], color='orange', linestyle='--')ax.set_xlabel('False positives rate')ax.set_ylabel('True positives rate')ax.set_aspect('equal')# 需要将标签进行one-hot编码
lb = LabelBinarizer()
lb.fit([0, 1, 2, 3]) # 训练标签编码器,这里设定有四个类别
n_classes = 4 # 类别数量val_pre_auc = []
val_label_auc = []for images, labels in val_ds:for image, label in zip(images, labels): img_array = tf.expand_dims(image, 0) prediction_auc = model.predict(img_array)val_pre_auc.append(prediction_auc[0])val_label_auc.append(lb.transform([label])[0]) # 这里需要使用标签编码器进行编码val_pre_auc = np.array(val_pre_auc)
val_label_auc = np.array(val_label_auc)auc_score_val = [metrics.roc_auc_score(val_label_auc[:, i], val_pre_auc[:, i]) for i in range(n_classes)]train_pre_auc = []
train_label_auc = []for images, labels in train_ds:for image, label in zip(images, labels):img_array_train = tf.expand_dims(image, 0) prediction_auc = model.predict(img_array_train)train_pre_auc.append(prediction_auc[0])train_label_auc.append(lb.transform([label])[0])train_pre_auc = np.array(train_pre_auc)
train_label_auc = np.array(train_label_auc)auc_score_train = [metrics.roc_auc_score(train_label_auc[:, i], train_pre_auc[:, i]) for i in range(n_classes)]fig, axs = plt.subplots(n_classes, figsize=(5, 20))for i in range(n_classes):plot_roc(axs[i], 'validation AUC for class {0}: {1:.4f}'.format(i, auc_score_val[i]), val_label_auc[:, i] , val_pre_auc[:, i], color="red", linestyle='--')plot_roc(axs[i], 'training AUC for class {0}: {1:.4f}'.format(i, auc_score_train[i]), train_label_auc[:, i], train_pre_auc[:, i], color="blue", linestyle='--')axs[i].legend(loc='lower right')plt.tight_layout()
plt.savefig("roc.pdf", dpi=300,format="pdf")for i in range(n_classes):print("Class {0} 训练集的AUC值为:".format(i), auc_score_train[i], "验证集的AUC值为:", auc_score_val[i])(b)调教GPT-4的过程
(b1)咒语:请根据{代码1},改写和续写《代码2》。代码1:{也就是之前用tensorflow写的误判病例分析部分};代码2:《也就是修改之前的Mobilenet模型建模代码》
然后根据具体情况调整即可,当然是在GPT的帮助下。
三、输出结果
(1)学习曲线

(2)混淆矩阵

(3)性能参数
(4)ROC曲线
(4.1)和在一起的:

(4.2)分开的:

四、数据
链接:https://pan.baidu.com/s/1rqu15KAUxjNBaWYfEmPwgQ?pwd=xfyn
提取码:xfyn
相关文章:
第61步 深度学习图像识别:多分类建模(TensorFlow)
基于WIN10的64位系统演示 一、写在前面 截至上期,我们一直都在做二分类的任务,无论是之前的机器学习任务,还是最近更新的图像分类任务。然而,在实际工作中,我们大概率需要进行多分类任务。例如肺部胸片可不仅仅能诊断…...

Spark 7:Spark SQL 函数定义
SparkSQL 定义UDF函数 方式1语法: udf对象 sparksession.udf.register(参数1,参数2,参数3) 参数1:UDF名称,可用于SQL风格 参数2:被注册成UDF的方法名 参数3:声明UDF的返回值类型 ud…...
ThinkPHP 文件上传 fileSystem 扩展的使用
ThinkPHP 文件上传 ThinkPHP 文件上传 扩展 filesystem一、安装 FileSystem 扩展二、认识 filesystem 配置文件 config/filesystem.php三、上传验证(涉及到验证器的知识点)四、文件上传demo ThinkPHP 文件上传 扩展 filesystem ThinkPHP 为我们 提供了 …...
液体神经网络LLN:通过动态信息流彻底改变人工智能
巴乌米克泰吉 一、说明 在在人工智能领域,神经网络已被证明是解决复杂问题的非常强大的工具。多年来,研究人员不断寻求创新方法来提高其性能并扩展其能力。其中一种方法是液体神经网络(LNN)的概念,这是一个利用动态计算…...

2023年的今天,PMP项目管理认证还值得考吗?
首先我肯定它值得考,PMP认证的教材和考纲都会随着项目管理工具和市场趋势而更新,不用担心会过时。 PMP项目管理认证是什么? 英文全称是Project Management Professional,中文全称叫做项目管理专业人士资格认证。它是由美国项目管…...

【JavaSE专栏91】Java如何主动发起Http、Https请求?
作者主页:Designer 小郑 作者简介:3年JAVA全栈开发经验,专注JAVA技术、系统定制、远程指导,致力于企业数字化转型,CSDN学院、蓝桥云课认证讲师。 主打方向:Vue、SpringBoot、微信小程序 本文讲解了如何使用…...

给oracle逻辑导出clob大字段、大数据量表提提速
文章目录 前言一、大表数据附:查询大表 二、解题思路1.导出排除大表的数据2.rowid切片导出大表数据Linux代码如下(示例):Windows代码如下(示例):手工执行代码如下(示例)&…...

研发规范第九讲:通用类命名规范(重点)
研发规范第九讲:通用类命名规范(重点) 无规范不成方圆。我自己非常注重搭建项目结构的起步过程,应用命名规范、模块的划分、目录(包)的命名,我觉得非常重要,如果做的足够好ÿ…...
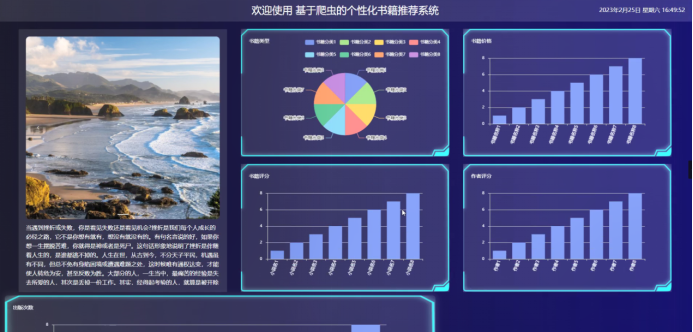
python+django+协同过滤算法-基于爬虫的个性化书籍推荐系统(包含报告+源码+开题)
为了提高个性化书籍推荐信息管理的效率;充分利用现有资源;减少不必要的人力、物力和财政支出来实现管理人员更充分掌握个性化书籍推荐信息的管理;开发设计专用系统--基于爬虫的个性化书籍推荐系统来进行管理个性化书籍推荐信息,以…...

系统架构:软件工程
文章目录 资源知识点自顶向下与自底向上形式化方法结构化方法敏捷方法净室软件工程面向服务的方法面向对象的方法快速应用开发螺旋模型软件过程和活动开放式源码开发方法功用驱动开发方法统一过程模型RUP基于构件的软件开发UML 资源 信息系统开发方法 知识点 自顶向下与自底…...
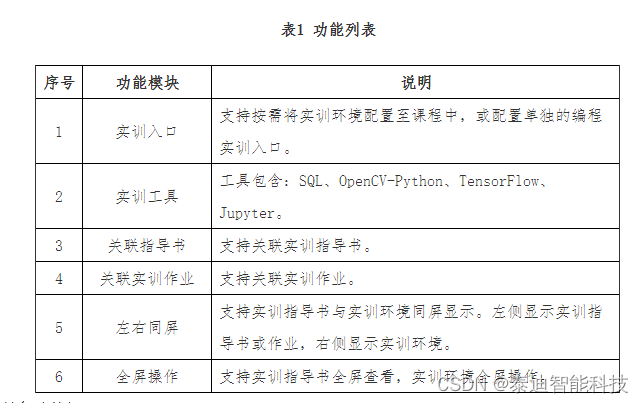
泰迪大数据实训平台产品介绍
大数据产品包括:大数据实训管理平台、大数据开发实训平台、大数据编程实训平台等 大数据实训管理平台 泰迪大数据实训平台从课程管理、资源管理、实训管理等方面出发,主要解决现有实验室无法满足教学需求、传统教学流程和工具低效耗时和内部教学…...

Linux- 文件夹相关的常用指令
1. 统计文件夹下的文件数量 在 Linux 下,有几种方法可以统计文件夹下的文件数量: 使用 ls 和 wc 命令: 这种方式可以统计目录下的直接子文件(不包括子目录里的文件)。 ls -l <目录路径> | wc -l注意:…...
在 macOS 中安装 TensorFlow 1g
tensorflow 需要多大空间 pip install tensorflow pip install tensorflow Looking in indexes: https://pypi.douban.com/simple/ Collecting tensorflowDownloading https://pypi.doubanio.com/packages/1a/c1/9c14df0625836af8ba6628585c6d3c3bf8f1e1101cafa2435eb28a7764…...

数学建模:CRITIC赋权法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 CRITIC赋权法 算法流程 构建原始数据矩阵 X X X,他是一个 m ∗ n m * n m∗n 的矩阵, m m m 表示评价对象个数, n n n 表示指标个数对原始数据矩阵进行正向化处理计算…...

Facebook message tag 使用攻略
Messenger 讯息传不出去?无法发送FB 讯息给非好友? 2020年3月,Facebook 为了防止用户被过多的推广或垃圾讯息困扰而更新使用条款,现在商家要用FB传讯息给所有人(包括非好友),应该使用 Facebook …...

气传导耳机哪个品牌比较好?综合表现很不错的气传导耳机推荐
气传导耳机不仅能够提升幸福感还能听到周围环境声,大大提高安全性。如果你在寻找一款高品质的气传导耳机,又不知从何入手时,不要担心,我已经为你精心挑选了四款市面上综合表现很不错的气传导耳机,让你享受更好的音质…...

Rabbitmq的消息转换器
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象 ,只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题: 数据体积过大 有安全漏洞 可读…...

nvidia-docker的使用
拉取镜像 docker pull nvidia/cuda可能出现的问题 问题描述 Error response from daemon: manifest for nvidia/cuda:latest not found: manifest unknown: manifest解决方法: 为找到正确且合适的docker镜像版本 在supported-tags中找到与自己系统对应的cuda版本…...
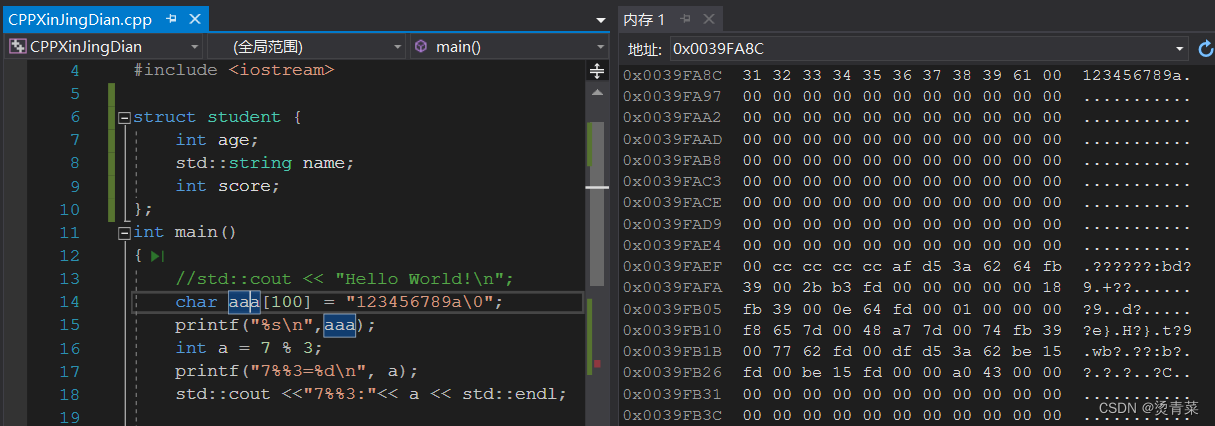
C++新经典 | C语言
目录 一、基础之查漏补缺 1.float精度问题 2.字符型数据 3.变量初值问题 4.赋值&初始化 5.头文件之<> VS " " 6.逻辑运算 7.数组 7.1 二维数组初始化 7.2 字符数组 8.字符串处理函数 8.1 strcat 8.2 strcpy 8.3 strcmp 8.4 strlen 9.函数 …...
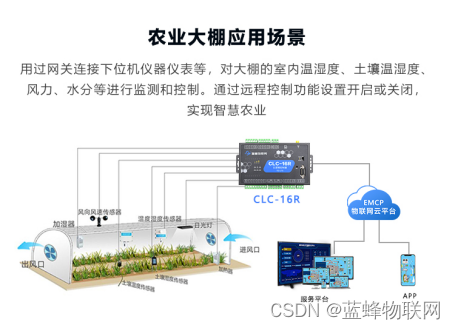
物联网智慧种植农业大棚系统
一、项目背景 智慧农业是是将物联网技术和农业生产箱管理的新型农业,依托部署在农业生产现场的各种传感节点,以物联网网关为通道形成数据传输网络,可以实现控制柜、环境监测传感器、气象监测机器等设备的远程监控,达到及时高校的…...

BooruDatasetTagManager自定义界面与快捷键:打造个性化工作流程的终极指南 [特殊字符]
BooruDatasetTagManager自定义界面与快捷键:打造个性化工作流程的终极指南 🎨 【免费下载链接】BooruDatasetTagManager 项目地址: https://gitcode.com/gh_mirrors/bo/BooruDatasetTagManager BooruDatasetTagManager是一款强大的AI训练数据标签…...

3步快速部署海风小店微信小程序商城 - 开源免费商用实战指南
3步快速部署海风小店微信小程序商城 - 开源免费商用实战指南 【免费下载链接】hioshop-miniprogram 微信小程序商城,开源免费商用,海风小店 项目地址: https://gitcode.com/gh_mirrors/hi/hioshop-miniprogram 海风小店是一款基于Node.jsThinkJSM…...
;RGRRQPIPKA)
HCV Core Protein (59-68);RGRRQPIPKA
一、基础信息多肽名称:丙型肝炎病毒 核心蛋白片段 (59-68) 英文名称:HCV Core Protein (59-68) 三字母序列:Arg-Gly-Arg-Arg-Gln-Pro-Ile-Pro-Lys-Ala 单字母序列:RGRRQPIPKA 氨基酸数量:10 aa 结构特征:线…...

BiliTools终极指南:三步搞定B站资源下载神器
BiliTools终极指南:三步搞定B站资源下载神器 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools BiliTools是…...

Sora 2发布即封神?Veo 2悄悄升级3项底层架构,92%开发者尚未察觉的性能跃迁,
更多请点击: https://kaifayun.com 第一章:Sora 2与Veo 2对比评测 核心定位与架构差异 Sora 2 是 OpenAI 推出的原生视频生成模型,基于扩散 Transformer 架构,支持长达 60 秒、1080p 分辨率的连贯视频生成,其训练数据…...

为什么你的Midjourney出图总像快照?——深度拆解--camera、--lens、--lighting三大未公开参数的物理建模逻辑
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney出图总像快照?——核心问题诊断与视觉语义断层解析 Midjourney 生成图像常被诟病“缺乏绘画性”“构图平庸”“质感单薄”,其本质并非模型能力不足,而是…...

【Perplexity商业搜索避坑白皮书】:5类典型误搜场景、4种权威信源验证法,附Gartner认证验证清单
更多请点击: https://kaifayun.com 第一章:【Perplexity商业搜索避坑白皮书】:5类典型误搜场景、4种权威信源验证法,附Gartner认证验证清单 高频误搜场景识别 在企业级商业情报检索中,以下五类误搜行为显著降低决策可…...

RISC-V PMP物理内存保护:硬件级隔离机制与嵌入式系统实战配置
1. 项目概述:为什么我们需要物理内存保护?在嵌入式系统、实时操作系统乃至一些对可靠性要求极高的服务器场景里,系统崩溃往往不是由复杂的逻辑错误直接导致的,而是源于一些看似“低级”的内存访问越界。想象一下,你正在…...

51单片机电子秤的语音播报怎么选?JQ8400模块 vs OTP芯片,实测成本与易用性对比
51单片机电子秤语音方案实战选型:JQ8400模块与OTP芯片的深度拆解 在智能硬件开发中,语音交互功能正从锦上添花的附加项逐渐变为核心用户体验的关键组成部分。以51单片机电子秤为例,语音播报功能不仅能提升产品的无障碍使用体验,还…...

cann/hcomm:HcommWriteOnThread线程写入函数
HcommWriteOnThread 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 产品支持情况 Ascend 950PR/Ascend 950DT:支…...