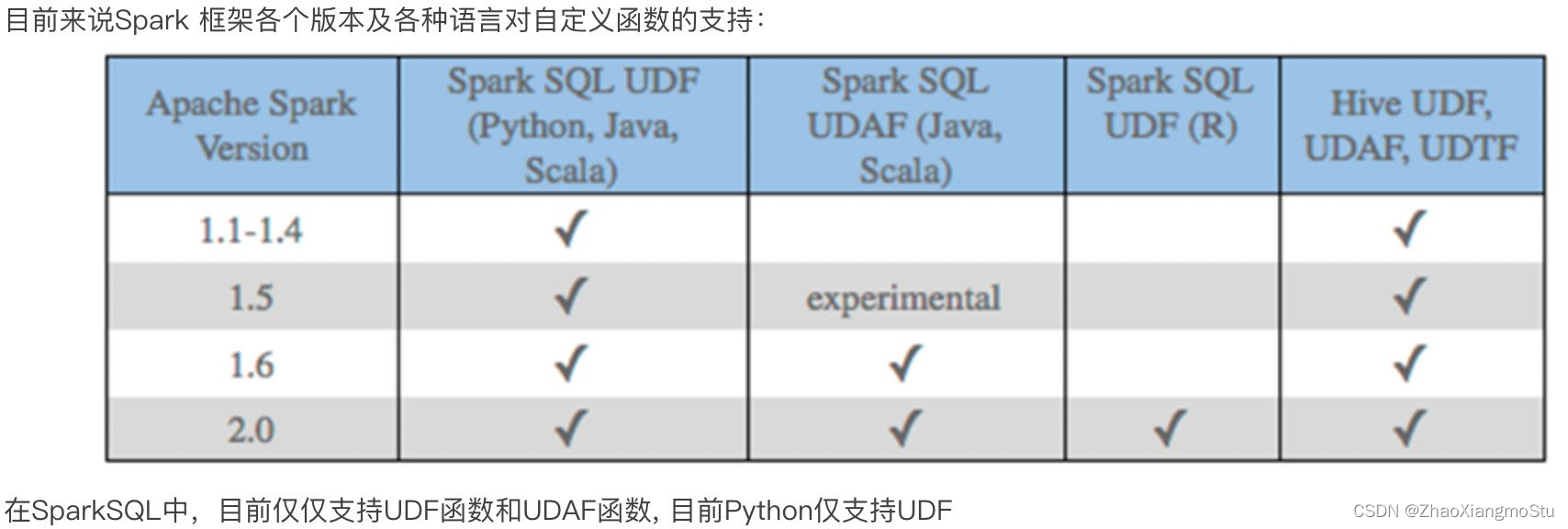
Spark 7:Spark SQL 函数定义
SparkSQL 定义UDF函数

方式1语法:
udf对象 = sparksession.udf.register(参数1,参数2,参数3)
参数1:UDF名称,可用于SQL风格
参数2:被注册成UDF的方法名
参数3:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
方式2语法:
udf对象 = F.udf(参数1, 参数2)
参数1:被注册成UDF的方法名
参数2:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
其中F是:
from pyspark.sql import functions as F
其中,被注册成UDF的方法名是指具体的计算方法,如:
def add(x, y): x + y
add就是将要被注册成UDF的方法名

# coding:utf8
import timefrom pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
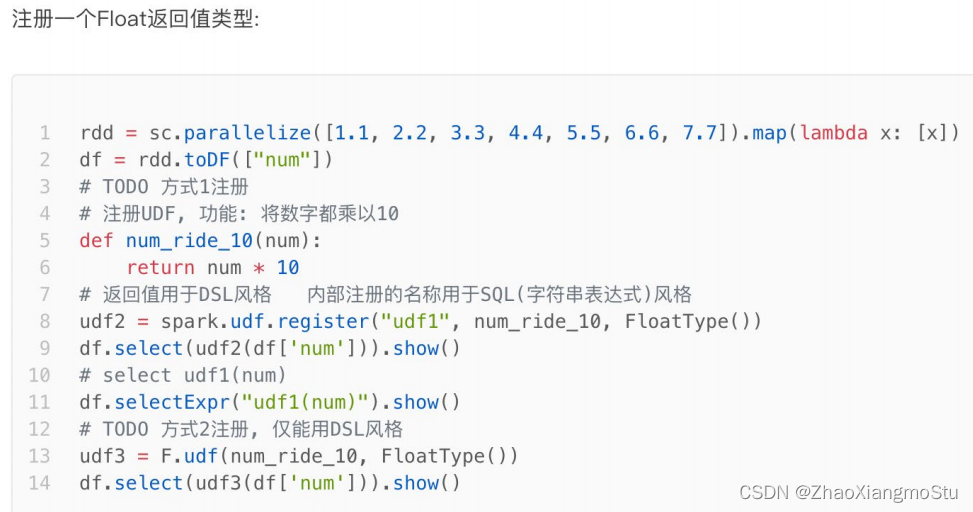
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\config("spark.sql.shuffle.partitions", 2).\getOrCreate()sc = spark.sparkContext# 构建一个RDDrdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x:[x])df = rdd.toDF(["num"])# TODO 1: 方式1 sparksession.udf.register(), DSL和SQL风格均可以使用# UDF的处理函数def num_ride_10(num):return num * 10# 参数1: 注册的UDF的名称, 这个udf名称, 仅可以用于 SQL风格# 参数2: UDF的处理逻辑, 是一个单独的方法# 参数3: 声明UDF的返回值类型, 注意: UDF注册时候, 必须声明返回值类型, 并且UDF的真实返回值一定要和声明的返回值一致# 返回值对象: 这是一个UDF对象, 仅可以用于 DSL 语法# 当前这种方式定义的UDF, 可以通过参数1的名称用于SQL风格, 通过返回值对象用户DSL风格udf2 = spark.udf.register("udf1", num_ride_10, IntegerType())# SQL风格中使用# selectExpr 以SELECT的表达式执行, 表达式 SQL风格的表达式(字符串)# select方法, 接受普通的字符串字段名, 或者返回值是Column对象的计算df.selectExpr("udf1(num)").show()# DSL 风格中使用# 返回值UDF对象 如果作为方法使用, 传入的参数 一定是Column对象df.select(udf2(df['num'])).show()# TODO 2: 方式2注册, 仅能用于DSL风格udf3 = F.udf(num_ride_10, IntegerType())df.select(udf3(df['num'])).show()df.selectExpr("udf3(num)").show()

# coding:utf8
import timefrom pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\config("spark.sql.shuffle.partitions", 2).\getOrCreate()sc = spark.sparkContext# 构建一个RDDrdd = sc.parallelize([["hadoop spark flink"], ["hadoop flink java"]])df = rdd.toDF(["line"])# 注册UDF, UDF的执行函数定义def split_line(data):return data.split(" ") # 返回值是一个Array对象# TODO1 方式1 构建UDFudf2 = spark.udf.register("udf1", split_line, ArrayType(StringType()))# DLS风格df.select(udf2(df['line'])).show()# SQL风格df.createTempView("lines")spark.sql("SELECT udf1(line) FROM lines").show(truncate=False)# TODO 2 方式2的形式构建UDFudf3 = F.udf(split_line, ArrayType(StringType()))df.select(udf3(df['line'])).show(truncate=False)

# coding:utf8
import string
import timefrom pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType, ArrayType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':# 0. 构建执行环境入口对象SparkSessionspark = SparkSession.builder.\appName("test").\master("local[*]").\config("spark.sql.shuffle.partitions", 2).\getOrCreate()sc = spark.sparkContext# 假设 有三个数字 1 2 3 我们传入数字 ,返回数字所在序号对应的 字母 然后和数字结合形成dict返回# 比如传入1 我们返回 {"num":1, "letters": "a"}rdd = sc.parallelize([[1], [2], [3]])df = rdd.toDF(["num"])# 注册UDFdef process(data):return {"num": data, "letters": string.ascii_letters[data]}"""UDF的返回值是字典的话, 需要用StructType来接收"""udf1 = spark.udf.register("udf1", process, StructType().add("num", IntegerType(), nullable=True).\add("letters", StringType(), nullable=True))df.selectExpr("udf1(num)").show(truncate=False)df.select(udf1(df['num'])).show(truncate=False)


SparkSQL 使用窗口函数


# coding:utf8
# 演示sparksql 窗口函数(开窗函数)
import string
from pyspark.sql import SparkSession
# 导入StructType对象
from pyspark.sql.types import ArrayType, StringType, StructType, IntegerType
import pandas as pd
from pyspark.sql import functions as Fif __name__ == '__main__':spark = SparkSession.builder. \appName("create df"). \master("local[*]"). \config("spark.sql.shuffle.partitions", "2"). \getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([('张三', 'class_1', 99),('王五', 'class_2', 35),('王三', 'class_3', 57),('王久', 'class_4', 12),('王丽', 'class_5', 99),('王娟', 'class_1', 90),('王军', 'class_2', 91),('王俊', 'class_3', 33),('王君', 'class_4', 55),('王珺', 'class_5', 66),('郑颖', 'class_1', 11),('郑辉', 'class_2', 33),('张丽', 'class_3', 36),('张张', 'class_4', 79),('黄凯', 'class_5', 90),('黄开', 'class_1', 90),('黄恺', 'class_2', 90),('王凯', 'class_3', 11),('王凯杰', 'class_1', 11),('王开杰', 'class_2', 3),('王景亮', 'class_3', 99)
])
schema = StructType().add("name", StringType()). \add("class", StringType()). \add("score", IntegerType())
df = rdd.toDF(schema)
# 窗口函数只用于SQL风格, 所以注册表先
df.createTempView("stu")
# TODO 聚合窗口
spark.sql("""
SELECT *, AVG(score) OVER() AS avg_score FROM stu
""").show()
# SELECT *, AVG(score) OVER() AS avg_score FROM stu 等同于
# SELECT * FROM stu
# SELECT AVG(score) FROM stu
# 两个SQL的结果集进行整合而来
spark.sql("""
SELECT *, AVG(score) OVER(PARTITION BY class) AS avg_score FROM stu
""").show()
# SELECT *, AVG(score) OVER(PARTITION BY class) AS avg_score FROM stu 等同于
# SELECT * FROM stu
# SELECT AVG(score) FROM stu GROUP BY class
# 两个SQL的结果集进行整合而来
# TODO 排序窗口
spark.sql("""
SELECT *, ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,
DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank,
RANK() OVER(ORDER BY score) AS rank
FROM stu
""").show()
# TODO NTILE
spark.sql("""
SELECT *, NTILE(6) OVER(ORDER BY score DESC) FROM stu
""").show()SparkSQL支持UDF和UDAF定义,但在Python中,暂时只能定义UDF
UDF定义支持2种方式, 1:使用SparkSession对象构建. 2: 使用functions包中提供的UDF API构建. 要注意, 方式1可用DSL和SQL风格, 方式2 仅可用于DSL风格
SparkSQL支持窗口函数使用, 常用SQL中的窗口函数均支持, 如聚合窗口\排序窗口\NTILE分组窗口等
相关文章:
Spark 7:Spark SQL 函数定义
SparkSQL 定义UDF函数 方式1语法: udf对象 sparksession.udf.register(参数1,参数2,参数3) 参数1:UDF名称,可用于SQL风格 参数2:被注册成UDF的方法名 参数3:声明UDF的返回值类型 ud…...
ThinkPHP 文件上传 fileSystem 扩展的使用
ThinkPHP 文件上传 ThinkPHP 文件上传 扩展 filesystem一、安装 FileSystem 扩展二、认识 filesystem 配置文件 config/filesystem.php三、上传验证(涉及到验证器的知识点)四、文件上传demo ThinkPHP 文件上传 扩展 filesystem ThinkPHP 为我们 提供了 …...
液体神经网络LLN:通过动态信息流彻底改变人工智能
巴乌米克泰吉 一、说明 在在人工智能领域,神经网络已被证明是解决复杂问题的非常强大的工具。多年来,研究人员不断寻求创新方法来提高其性能并扩展其能力。其中一种方法是液体神经网络(LNN)的概念,这是一个利用动态计算…...

2023年的今天,PMP项目管理认证还值得考吗?
首先我肯定它值得考,PMP认证的教材和考纲都会随着项目管理工具和市场趋势而更新,不用担心会过时。 PMP项目管理认证是什么? 英文全称是Project Management Professional,中文全称叫做项目管理专业人士资格认证。它是由美国项目管…...

【JavaSE专栏91】Java如何主动发起Http、Https请求?
作者主页:Designer 小郑 作者简介:3年JAVA全栈开发经验,专注JAVA技术、系统定制、远程指导,致力于企业数字化转型,CSDN学院、蓝桥云课认证讲师。 主打方向:Vue、SpringBoot、微信小程序 本文讲解了如何使用…...

给oracle逻辑导出clob大字段、大数据量表提提速
文章目录 前言一、大表数据附:查询大表 二、解题思路1.导出排除大表的数据2.rowid切片导出大表数据Linux代码如下(示例):Windows代码如下(示例):手工执行代码如下(示例)&…...

研发规范第九讲:通用类命名规范(重点)
研发规范第九讲:通用类命名规范(重点) 无规范不成方圆。我自己非常注重搭建项目结构的起步过程,应用命名规范、模块的划分、目录(包)的命名,我觉得非常重要,如果做的足够好ÿ…...
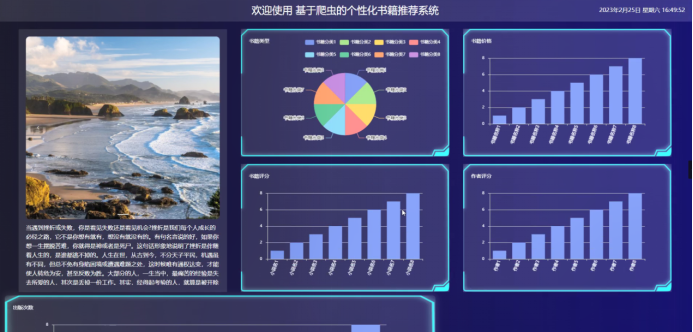
python+django+协同过滤算法-基于爬虫的个性化书籍推荐系统(包含报告+源码+开题)
为了提高个性化书籍推荐信息管理的效率;充分利用现有资源;减少不必要的人力、物力和财政支出来实现管理人员更充分掌握个性化书籍推荐信息的管理;开发设计专用系统--基于爬虫的个性化书籍推荐系统来进行管理个性化书籍推荐信息,以…...

系统架构:软件工程
文章目录 资源知识点自顶向下与自底向上形式化方法结构化方法敏捷方法净室软件工程面向服务的方法面向对象的方法快速应用开发螺旋模型软件过程和活动开放式源码开发方法功用驱动开发方法统一过程模型RUP基于构件的软件开发UML 资源 信息系统开发方法 知识点 自顶向下与自底…...
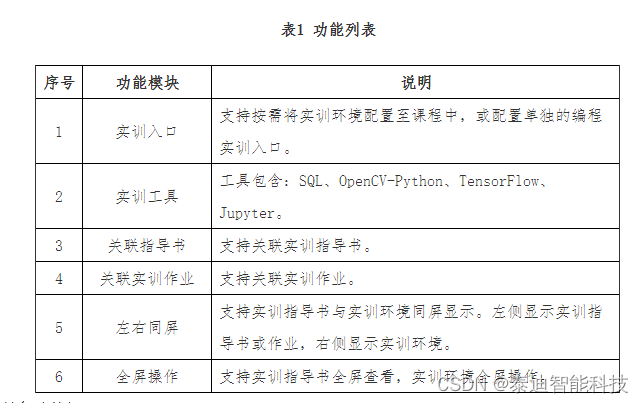
泰迪大数据实训平台产品介绍
大数据产品包括:大数据实训管理平台、大数据开发实训平台、大数据编程实训平台等 大数据实训管理平台 泰迪大数据实训平台从课程管理、资源管理、实训管理等方面出发,主要解决现有实验室无法满足教学需求、传统教学流程和工具低效耗时和内部教学…...

Linux- 文件夹相关的常用指令
1. 统计文件夹下的文件数量 在 Linux 下,有几种方法可以统计文件夹下的文件数量: 使用 ls 和 wc 命令: 这种方式可以统计目录下的直接子文件(不包括子目录里的文件)。 ls -l <目录路径> | wc -l注意:…...
在 macOS 中安装 TensorFlow 1g
tensorflow 需要多大空间 pip install tensorflow pip install tensorflow Looking in indexes: https://pypi.douban.com/simple/ Collecting tensorflowDownloading https://pypi.doubanio.com/packages/1a/c1/9c14df0625836af8ba6628585c6d3c3bf8f1e1101cafa2435eb28a7764…...

数学建模:CRITIC赋权法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 CRITIC赋权法 算法流程 构建原始数据矩阵 X X X,他是一个 m ∗ n m * n m∗n 的矩阵, m m m 表示评价对象个数, n n n 表示指标个数对原始数据矩阵进行正向化处理计算…...

Facebook message tag 使用攻略
Messenger 讯息传不出去?无法发送FB 讯息给非好友? 2020年3月,Facebook 为了防止用户被过多的推广或垃圾讯息困扰而更新使用条款,现在商家要用FB传讯息给所有人(包括非好友),应该使用 Facebook …...

气传导耳机哪个品牌比较好?综合表现很不错的气传导耳机推荐
气传导耳机不仅能够提升幸福感还能听到周围环境声,大大提高安全性。如果你在寻找一款高品质的气传导耳机,又不知从何入手时,不要担心,我已经为你精心挑选了四款市面上综合表现很不错的气传导耳机,让你享受更好的音质…...

Rabbitmq的消息转换器
Spring会把你发送的消息序列化为字节发送给MQ,接收消息的时候,还会把字节反序列化为Java对象 ,只不过,默认情况下Spring采用的序列化方式是JDK序列化。众所周知,JDK序列化存在下列问题: 数据体积过大 有安全漏洞 可读…...

nvidia-docker的使用
拉取镜像 docker pull nvidia/cuda可能出现的问题 问题描述 Error response from daemon: manifest for nvidia/cuda:latest not found: manifest unknown: manifest解决方法: 为找到正确且合适的docker镜像版本 在supported-tags中找到与自己系统对应的cuda版本…...
C++新经典 | C语言
目录 一、基础之查漏补缺 1.float精度问题 2.字符型数据 3.变量初值问题 4.赋值&初始化 5.头文件之<> VS " " 6.逻辑运算 7.数组 7.1 二维数组初始化 7.2 字符数组 8.字符串处理函数 8.1 strcat 8.2 strcpy 8.3 strcmp 8.4 strlen 9.函数 …...
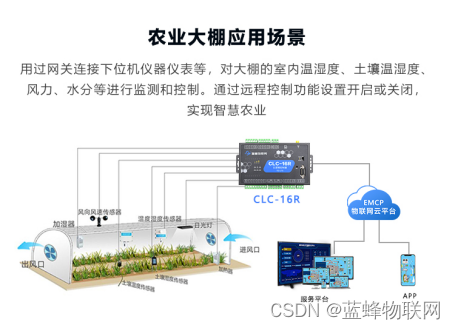
物联网智慧种植农业大棚系统
一、项目背景 智慧农业是是将物联网技术和农业生产箱管理的新型农业,依托部署在农业生产现场的各种传感节点,以物联网网关为通道形成数据传输网络,可以实现控制柜、环境监测传感器、气象监测机器等设备的远程监控,达到及时高校的…...

TabBar组件如何跳转页面?
1、先引入 2、假数据 const tabs [{key: home,title: 首页,icon: <AppOutline />,badge: Badge.dot,},{key: todo,title: 待办,icon: <UnorderedListOutline />,badge: 5,},{key: message,title: 消息,icon: (active: boolean) >active ? <MessageFill /&…...

用Python实战脑电分析:手把手教你计算PLV、MVL、MI跨频耦合指标
Python脑电分析实战:PLV、MVL、MI跨频耦合指标全流程解析 神经振荡的跨频耦合(Cross-Frequency Coupling, CFC)分析正在成为探索大脑信息处理机制的重要工具。想象一下,当你面对一组EEG数据时,如何从复杂的波形中提取出…...

【热门开源项目下载】yolo-onnx-java
【热门开源项目下载】yolo-onnx-java 1. 项目基础介绍与编程语言 yolo-onnx-java 是一个基于Java语言开发的轻量级AI模型调用框架,专注于为Java开发者提供高效、便捷的深度学习模型推理能力。项目通过ONNX(Open Neural Network Exchange)格式…...
)
Midjourney年度订阅最后上车机会:官方邮件暗藏“早鸟密钥”,输入即解锁终身$129→$79(已验证有效期至2024-12-15)
更多请点击: https://kaifayun.com 第一章:Midjourney年度订阅优惠的官方政策与背景解析 Midjourney自2023年起正式将年度订阅(Annual Plan)纳入其核心付费体系,旨在为长期用户降低平均月成本并强化服务稳定性。该政策…...
保姆级教程:从单文件到多选的完整配置流程)
MATLAB文件选择对话框uigetfile()保姆级教程:从单文件到多选的完整配置流程
MATLAB文件选择对话框uigetfile()实战指南:从基础配置到高级技巧 在MATLAB日常开发中,文件选择对话框是用户交互的重要组成部分。uigetfile()函数作为MATLAB内置的文件选择工具,其灵活性和可定制性往往被初学者低估。本文将带您深入探索这个看…...

FreeRTOS互斥锁的‘坑’与‘宝’:优先级翻转那些事儿,用ESP32实测给你看
FreeRTOS互斥锁的‘坑’与‘宝’:优先级翻转那些事儿,用ESP32实测给你看 在嵌入式实时系统中,任务调度和资源管理是核心挑战。当你开始设计多任务系统时,很快会遇到一个经典问题:多个任务需要访问共享资源(…...

无人机开发平台全解析:从开源飞控到厂商SDK的选型与应用实战
1. 项目概述:为什么无人机开发平台变得如此重要?几年前,当我第一次尝试给一台消费级无人机增加一个简单的自动航线功能时,我发现自己面对的是一个完全封闭的“黑箱”。飞控固件是加密的,传感器数据无法实时获取&#x…...

案例之 ANN案例_手机价格分类
案例之 ANN案例_手机价格分类...

从零构建:基于YOLOv8/YOLOv10的智能游戏瞄准系统深度解析
从零构建:基于YOLOv8/YOLOv10的智能游戏瞄准系统深度解析 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot 你是否曾经好奇,人工智能技术如何精准识别游戏中的…...

怎么远程操作另一台手机 手机能远程控制别的手机吗
想远程操作另一台手机应急?不管是忘带工作机需回复客户消息,还是手游玩家用备用机远程控制主力机挂机领福利,都需要好用的工具。市面上能远程操作另一台手机的软件不少,但是却多有短板,难以适配需求。推荐无界趣连2.0&…...

基于8ms平台的嵌入式GUI开发实践:智能家居86盒UI设计与实现
1. 项目概述:当智能家居遇上8ms,一个86盒的UI革命 最近在折腾一个智能家居的改造项目,核心是想把家里那些老旧的开关面板,换成能联网、能自定义、还能显示点信息的“智能大脑”。市面上现成的智能开关要么功能固化,要么…...