plumelog介绍与应用-一个简单易用的java分布式日志系统
官方文档:http://www.plumelog.com/zh-cn/docs/FASTSTART.html
简介
- 无代码入侵的分布式日志系统,基于log4j、log4j2、logback搜集日志,设置链路ID,方便查询关联日志
- 基于elasticsearch作为查询引擎
- 高吞吐,查询效率高
- 全程不占应用程序本地磁盘空间,免维护;对于项目透明,不影响项目本身运行
- 无需修改老项目,引入直接使用,支持dubbo,支持springcloud
架构

- 应用服务通过整合plumelog客户端,搜集日志并推送kafka,redis等队列
- plumelog-server 负责把队列中的日志日志异步写入到elasticsearch
- plumelog_ui为操作界面客户端,用于查询日志,使用各种定制功能
常见部署模型
- 单redis小集群模式,大部分中小规模项目

- kafka集群模式,每个项目量都很大

功能
日志查询

扩展字段
-
在系统扩展字段里添加扩展字段,字段值为 orderid 显示值为 订单编号
-
查询的时候选择应用名,下面会显示扩展字段,可以通过扩展字段查询
MDC.put("orderid","1");
MDC.put("userid","4");
logger.info("扩展字段");
链路追踪
设置追踪码后,支持注解手动打点和切面全局打点
滚动日志
可以连接到机器上,查看实时日志
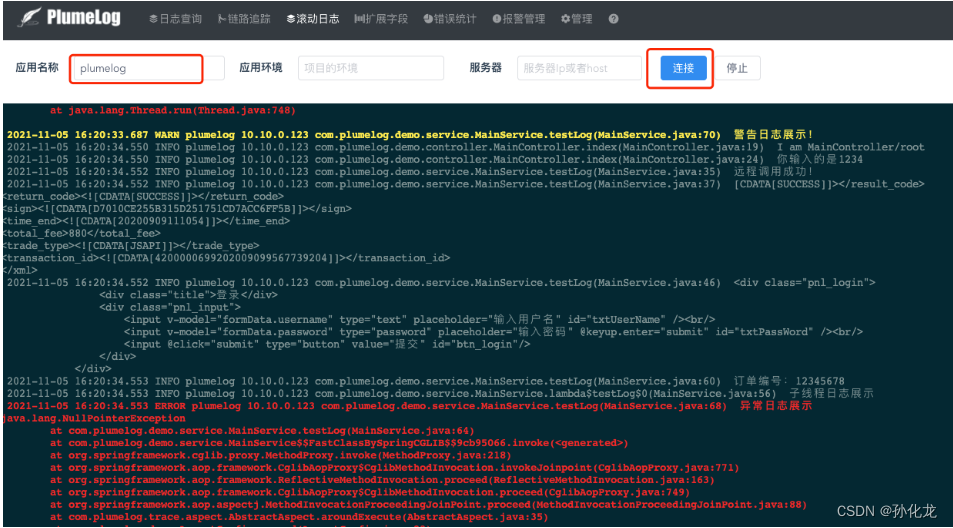
错误统计
错误报警
支持通过webhook自定义报警
索引管理
查看和操作ES索引
plumelog&ELK
- plumelog日志是客户端上报的方式,客户端配置极其简单,不需要像logstash一样去解析日志的格式,因为plumelog客户端已经格式化好了,traceid的设计都是内置的,这些用户都不用刻意去管,跨线程跨应用链路传递都是内置的组件
- 部署简单,你只要个有redis,就行了,ELK组合要完成完整部署,可能还需要配置kafka,filebeat之类的组件,而且版本需统一
- 日志的查询速度大于ELK,因为plumelog查询是优化过的,比kibanna通用查询快很多,plumelog的查询界面就是专门按照国人习惯设计的
- 很多人用ELK到了大量日志的时候发现,检索效率极其下降,那是因为ES的索引等设计不合理造成的,plumelog专业处理日志,索引的设置都已经早就设计好了,不需要使用者自己去优化
- ELK不是专业处理日志的,plumelog在日志上功能就很多,例如扩展字段,链路追踪,错误报警,错误统计后续还有QPS统计等功能,ELK都是没有的
多大体量
根据用户反馈,目前搜集到最大的用户每日日志量已经到达3TB,并稳定运行
部署应用
第一步:安装 redis 或者 kafka(一般公司redis足够) redis 官网:https://redis.io kafka:http://kafka.apache.org
第二步:安装 elasticsearch 官网下载地址:https://www.elastic.co/cn/downloads/past-releases
第三步:下载安装包,plumelog-server 下载地址:https://gitee.com/plumeorg/plumelog/releases
第四步:配置plumelog-server,并启动,redis和kafka作为队列模式下可以部署多个plumelog-server达到高可用,配置一样即可
第五步:后台查询语法详见plumelog使用指南
应用案例
以mservice为例,查询线上问题时,提供的是用户Id或订单号
之前查日志:
- 根据custId找到udid,根据订单号找到custId再找到udid。
- 到kibana根据udid和时间点找到对应的请求记录,找到对应的机器,找到请求的唯一标识“tc”
- 登录机器,根据“tc”参数查询elk日志,找到对应的线程号。
- 根据线程号和时间范围过滤default日志。
现在查询日志:
- 登录plumeLog页面,根据用户Id或订单号查询,即可查询到关键日志,大致定位问题。
- 根据日志的hostIp参数登录到机器根据追踪码过滤即可得到详细日志。
整合过程
-
pom添加依赖
<dependency><groupId>com.plumelog</groupId><artifactId>plumelog-logback</artifactId><version>3.5.2</version> </dependency> -
logback.xml添加appender,注意区分测试和线上环境
<appenders><!--使用redis启用下面配置--><appender name="plumelog" class="com.plumelog.logback.appender.RedisAppender"><appName>plumelog</appName><redisHost>172.16.249.72:6379</redisHost><redisAuth>123456</redisAuth></appender><!-- 使用kafka启用下面配置 --><appender name="plumelog" class="com.plumelog.logback.appender.KafkaAppender"><appName>plumelog</appName><kafkaHosts>172.16.247.143:9092,172.16.247.60:9092,172.16.247.64:9092</kafkaHosts></appender><!-- 使用lite模式启用下面配置 --><appender name="plumelog" class="com.plumelog.logback.appender.LiteAppender"><appName>worker</appName><plumelogHost>localhost:8891</plumelogHost></appender> </appenders><!--使用上面三个三选一加入到root下面--> <root level="INFO"><appender-ref ref="plumelog"/> </root><!-- 结合环境配置案例--> <springProfile name="dev"><root level="INFO"><appender-ref ref="plumelog" /></root> </springProfile> <springProfile name="test"><root level="INFO"><appender-ref ref="plumelog" /></root> </springProfile> <springProfile name="prod"><root level="INFO"><appender-ref ref="plumelog" /></root> </springProfile> -
代码调整输出日志
- 当前只把部分关键日志输出到plumeLog,可以解决大部分问题,每条日志都有机器IP
- 把用户Id作为扩展字段,方便搜索。
- 链路追踪:将“tc”参数作为追踪码,调用交易时,将其放到head中传给交易,可以直接根据追踪码搜索,串联mservice和交易系统。
- 将“tc”参数放到MDC中,输出到日志头,可以直接根据“tc”参数过滤日志
-
下载server包,调整server配置文件
spring.application.name=plumelog_serverspring.profiles.active=test-confidentialserver.port=8891spring.thymeleaf.mode=LEGACYHTML5spring.mvc.view.prefix=classpath:/templates/spring.mvc.view.suffix=.htmlspring.mvc.static-path-pattern=/plumelog/**spring.boot.admin.context-path=admin#值为4种 redis,kafka,rest,restServer#redis 表示用redis当队列#kafka 表示用kafka当队列#rest 表示从rest接口取日志#restServer 表示作为rest接口服务器启动#ui 表示单独作为ui启动#lite 简易模式启动不需要配置redis等plumelog.model=kafka#plumelog.lite.log.path=/Users/chenlongfei/lucene# 如果使用kafka,启用下面配置plumelog.kafka.kafkaHosts=broker.kafka.mid:443,broker.kafka.mid:443plumelog.kafka.kafkaGroupName=logConsumer#队列redis地址,model配置redis集群模式,哨兵模式用逗号隔开,队列redis不支持集群模式#plumelog.queue.redis.redisHost=127.0.0.1:6379#如果使用redis有密码,启用下面配置#plumelog.queue.redis.redisPassWord=123456#plumelog.queue.redis.redisDb=0#哨兵模式需要配置的#plumelog.queue.redis.sentinel.masterName=myMaster#管理端redis地址 ,集群用逗号隔开,不配置将和队列公用plumelog.redis.redisHost=127.0.0.1:8389,127.0.0.1:8388#如果使用redis有密码,启用下面配置#plumelog.redis.redisPassWord=123456#plumelog.redis.redisDb=0#哨兵模式需要配置的#plumelog.redis.sentinel.masterName=myMaster#如果使用rest,启用下面配置#plumelog.rest.restUrl=http://127.0.0.1:8891/getlog#plumelog.rest.restUserName=plumelog#plumelog.rest.restPassWord=123456#redis解压缩模式,开启后不消费非压缩的队列#plumelog.redis.compressor=true#elasticsearch相关配置,Hosts支持携带协议,如:http、httpsplumelog.es.esHosts=127.0.0.1:9200plumelog.es.shards=5plumelog.es.replicas=0plumelog.es.refresh.interval=30s#日志索引建立方式day表示按天、hour表示按照小时plumelog.es.indexType.model=day#plumelog.es.maxShards=100000#ES设置密码,启用下面配置#plumelog.es.userName=elastic#plumelog.es.passWord=elastic#是否信任自签证书#plumelog.es.trustSelfSigned=true#是否hostname验证#plumelog.es.hostnameVerification=false#单次拉取日志条数plumelog.maxSendSize=100#拉取时间间隔,kafka不生效plumelog.interval=100#plumelog-ui的地址 如果不配置,报警信息里不可以点连接plumelog.ui.url=http://plumelog.ck.api:8891#管理密码,手动删除日志的时候需要输入的密码admin.password=123456#日志保留天数,配置0或者不配置默认永久保留admin.log.keepDays=30#链路保留天数,配置0或者不配置默认永久保留admin.log.trace.keepDays=30#登录配置,配置后会有登录界面#login.username=admin#login.password=admin
- 部署server,当前已部署6个pod。
- 当前实际应用中,日常每天日志总量200多万条。2G左右。
相关文章:
plumelog介绍与应用-一个简单易用的java分布式日志系统
官方文档:http://www.plumelog.com/zh-cn/docs/FASTSTART.html 简介 无代码入侵的分布式日志系统,基于log4j、log4j2、logback搜集日志,设置链路ID,方便查询关联日志基于elasticsearch作为查询引擎高吞吐,查询效率高全…...

百度网盘删除“我的应用数据”文件夹
百度网盘删除“我的应用数据”文件夹电脑端方法-2023.2.27成功 - 哔哩哔哩 (bilibili.com) 百度网盘怎样删除我的应用数据文件夹-手机端方法-2023.3.24日成功 - 哔哩哔哩 (bilibili.com)...

多店铺智能客服,助力店铺销量倍增
近年来电商发展得非常快速,市场竞争也是愈发激烈了。商家不仅需要提高产品和服务的质量,还要争取为自己获取更多的曝光,以此来分散运营的风险和降低经营的成本,所以越来越多的商家也开始转向多平台多店铺运营。但即使运营多个平台…...

会话跟踪技术
cookie 是通过在浏览器第一次请求服务器时,在响应中放入cookie,浏览器接收到cookie后保存在本地,之后每次请求服务器时都将cookie携带到请求头中,用来验证用户身份与状态等。 缺点: 移动端app没有cookiecookie保存在…...
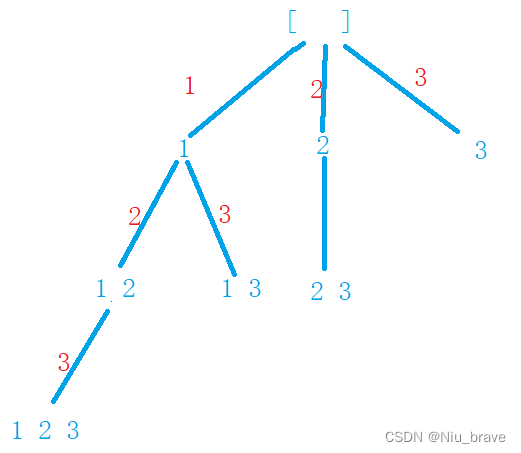
递归算法学习——子集
目录 一,题目解析 二,例子 三,题目接口 四,解题思路以及代码 1.完全深度搜索 2.广度搜索加上深度优先搜索 五,相似题 1.题目 2.题目接口 3.解题代码 一,题目解析 给你一个整数数组 nums ,…...
)
学习笔记:ROS使用经验(ROS报错)
报错:进程崩溃 ] process has died [pid 734, exit code -5, cmd /root/catkin_ws/devel/lib/pose_graph/pose_graph __name:pose_graph __log:/root/.ros/log/31b0ae1c-3295-11ee-bda9-02429b5737dc/pose_graph-5.log]. log file: /root/.ros/log/31b0ae1c-3295-11…...
)
设计模式二十四:访问者模式(Visitor Pattern)
用于将数据结构与数据操作分离,使得可以在不修改数据结构的情况下,定义新的操作。访问者模式的核心思想是,将数据结构和操作进行解耦,从而使得新增操作时不必修改数据结构,只需添加新的访问者。主要目的是在不改变数据…...
使用gn+Ninja构建项目
使用下载编译好的gn和ninja报错 先下载了gn的源码[gn.googlesource.com/gn],然后编译报错,就直接下载了了编译号的gn和Ninja,然后写了Helloworld应用的BUILD.gn,然后将"gn\examples\simple_build\build"拷贝至当前目录…...
VMware虚拟机连不上网络
固定ip地址 进入网络配置文件 cd /etc/sysconfig/network-scripts 打开文件 vi ifcfg-ens33 编辑 BOOTPROTO设置为static,有3个值(decp、none、static) BOOTPROTO"static" 打开网络 ONBOOT"yes" 固定ip IPADDR1…...
安防视频监控/视频集中存储/云存储平台EasyCVR平台无法取消共享通道该如何解决?
视频汇聚/视频云存储/集中存储/视频监控管理平台EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,实现视频资源的鉴权管理、按需调阅、全网分发、云存储、智能分析等,视频智能分析平台EasyCVR融合性强、开放度…...

算法通关村-----如何基于数组和链表实现栈
实现栈的基本方法 push(T t)元素入栈 T pop() 元素出栈 Tpeek() 查看栈顶元素 boolean isEmpty() 栈是否为空 基于数组实现栈 import java.util.Arrays;public class ArrayStack<T> {private Object[] stack;private int top;public ArrayStack() {this.stack new…...
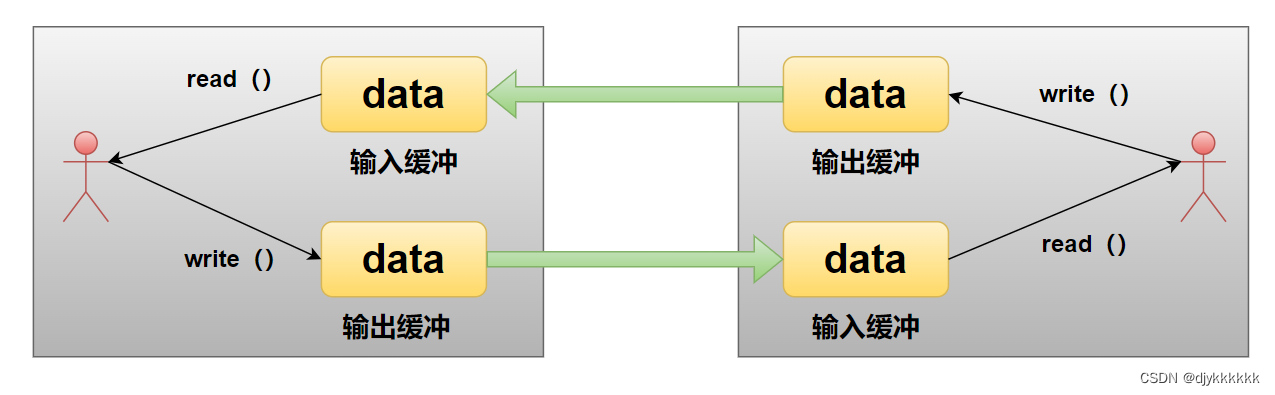
day-05 TCP半关闭 ----- DNS ----- 套接字的选项
一、优雅的断开套接字连接 之前套接字的断开都是单方面的。 (一)基于TCP的半关闭 Linux的close函数和windows的closesocket函数意味着完全断开连接。完全断开不仅不能发送数据,从而也不能接收数据。在某些情况下,通信双方的某一方…...

区块链金融项目怎么做?
区块链技术的兴起引发了金融领域的变革,为金融行业带来了前所未有的机遇与挑战。在这个快速发展的领域中,如何在区块链金融领域做出卓越的表现?本文将从专业性和思考深度两个方面,探讨区块链金融的发展路径,并为读者提…...

Redis与数据库保持一致
参考链接 先更新数据库,再更新redis 存在漏洞,如果更新Redis失败,仍然会导致不一致 先删Redis,再更新数据库并同步数据到Redis 存在漏洞,多线程情况下,线程1删除redis后,还是有可能被其他线程读取旧的数据…...
idea中vue项目 npm安装插件后node modules中找不到
从硬盘中重新加载一下...

已知两地经纬度,计算两地直线距离
文章目录 1 原理公式2 代码实现2.1 JavaScript2.2 C2.3 Python2.4 MATLAB 1 原理公式 在地球上,计算两点之间的直线距离通常使用地理坐标系(例如WGS84)。计算两地直线距离的公式是根据经纬度之间的大圆距离(Great Circle Distanc…...

我想开通期权?如何开通期权账户?
场内期权的合约由交易所统一标准化定制,大家面对的同一个合约对应的价格都是一致的,比较公开透明,期权开户当天不能交易的,期权开户需要满足20日日均50万及半年交易经验即可操作,下文科普我想开通期权?如何…...

ChatGPT对软件测试的影响
ChatGPT 是一个经过预训练的 AI 语言模型,可以通过聊天的方式回答问题,或者与人闲聊。它能处理的是文本类的信息,输出也只能是文字。它从我们输入的信息中获取上下文,结合它被训练的大模型,进行分析总结,给…...
minion在ubuntu上的搭建步骤
在Ubuntu上搭建MinIO可以按照以下步骤进行: 下载MinIO服务器二进制文件: 通过浏览器访问 https://min.io/download 或使用以下命令获取最新的MinIO二进制文件:wget https://dl.min.io/server/minio/release/linux-amd64/minio赋予二进制文件…...
Leetcode刷题笔记--Hot31-40
1--颜色分类(75) 主要思路: 快排 #include <iostream> #include <vector>class Solution { public:void sortColors(std::vector<int>& nums) {quicksort(nums, 0, nums.size()-1);}void quicksort(std::vector<int…...

忙碌”幻觉:你以为在推进项目,其实只是在逃避
时序收敛没过、功耗超了、验证卡住了——每一个问题都是真实的,每一项任务都是紧迫的。但有时候停下来想想,这些忙碌背后,到底有多少是真正在解决问题,有多少只是在用”我还在干活”这件事本身,来麻醉自己?…...
)
【编号884】江西省各城市-春节人口迁徙规模数据(2019-2025)
今天分享的是 江西省各城市-春节人口迁徙规模数据(2019-2025)数据概况 江西省各城市-春节人口迁徙规模数据(2019-2025) 春节地级市人口迁徙指数(2019-2025)迁徙指数依托位置时空大数据构建,形…...

RAG 和 NotebookLM 都试过后,我才发现数据库知识库真正缺的不是搜索
很多数据库知识库不好用,不是模型不会答,而是知识没有被整理成可调用、可校验、可维护的资产。 前面几篇一直在聊 DB Agent。 聊 Skill,聊记忆,聊告警风暴,聊编排,也聊到了系统画像、历史案例和当前证据。…...

NY379固态MT29F32T08GSLBHL8-36QA:B
NY379固态MT29F32T08GSLBHL8-36QA:B在数据爆炸的时代,企业级存储对性能与可靠性的要求不断攀升。作为核心存储元件,NAND Flash 的选型直接决定系统的稳定性与寿命。美光 MT29F32T08GSLBHL8-36QA:B,以其32Tb(约4TB)的大…...

抖音批量下载解决方案:模块化架构与智能降级策略
抖音批量下载解决方案:模块化架构与智能降级策略 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖…...
)
Array作为顶层参数-优化设计(二)
一、核心代码#include "array_FIFO.h"void array_FIFO (dout_t d_o[4], din_t d_i[4], didx_t idx[4]) { //void array_FIFO (dout_t d_o[4], din_t *d_i, didx_t idx[4]) { #pragma HLS INTERFACE s_axilite register depth4 portd_i //#pragma HLS INTERFACE s_axi…...

fltk-rs常见问题解决方案:从编译错误到运行时问题的全面排查
fltk-rs常见问题解决方案:从编译错误到运行时问题的全面排查 【免费下载链接】fltk-rs Rust bindings for the FLTK GUI library. 项目地址: https://gitcode.com/gh_mirrors/fl/fltk-rs fltk-rs是Rust语言的FLTK GUI库绑定,为开发者提供了轻量级…...

算法实例分析:使数组相等的最小开销
使数组相等的最小开销通过题意分析可知要让所有值相等,必然不需要超出数据的最大最小值,因此左右边界可以预先缩小范围。然后根据我们上面的分析不断缩小搜索边界范围。关于函数的计算,只要统计所有数据与的差值再乘上权重即可。最后注意&…...

避开DSP28335内存管理的坑:堆、栈、CMD文件配置全解析与最佳实践
DSP28335内存管理深度优化:从堆栈原理到CMD文件实战配置 在嵌入式系统开发中,内存管理往往是决定项目成败的关键因素之一。对于基于TI C2000系列DSP28335的开发者而言,合理规划有限的内存资源不仅能提升系统性能,更能避免那些难以…...

2026年双语论文降AI攻略:中英文双语毕业论文AIGC超标免费4.8元达标完整指南
2026年双语论文降AI攻略:中英文双语毕业论文AIGC超标免费4.8元达标完整指南 双语论文降AI这件事,踩过坑的人都知道:工具选错、操作方式错,钱白花还耽误时间。 直接给结论:嘎嘎降AI(www.aigcleaner.com&am…...