理解 Databend Cluster key 原理及使用

Databend Cluster Key 是指 Databend 可以按声明的 key 排序存储,主要用于用户对时间响应比较高,同时愿意为这个 cluster key 进行额排序操作的用户。 Databend 只支持一个 Cluster key,Cluster key中可以包含多列及表达式。
基本语法
-- 语法:
alter table T cluster by(c1, fun(c2));-- 例如:
alter table T cluster by(user_id); -- 指定数据按 user_id 排序存储-- 日志场景 按 msg_id, 小时 排序存储
alter table T cluster by(msg_id, to_yyyymmddhh(c_timestamp));-- 强制数据排序
optimize table T compact;
alter table T recluster final; -- 全局排序, 建议第一次创建 Cluster key 后使用,后期如果遇到性能退化,也可以再次使用更多关于 Databend Cluster key 语法参考:
Understanding Cluster Key | Databend
使用注意事项
目前 Databend 在表有 cluster key 的情况下,使用
- copy into
- replace into
这两种方式写入数据时,会自动执行 compact 和 recluster 操作。
关于 Databend Cluster Key 你需要了解的:
- Databend 中数据分区按: block_size_threshold (default: 100M ) or row_per_block(default 100万) 组织,两者任意达到之一就会生成新的 Block
- 新生成的 Block 中会按定义的 cluster key 排序存储,当该key的 min = max 时,该 block 为 constant_block, 同时 cluster key 不保证全局有序
- 多个 block 之间可能有重叠区间,如,cluster by (age)
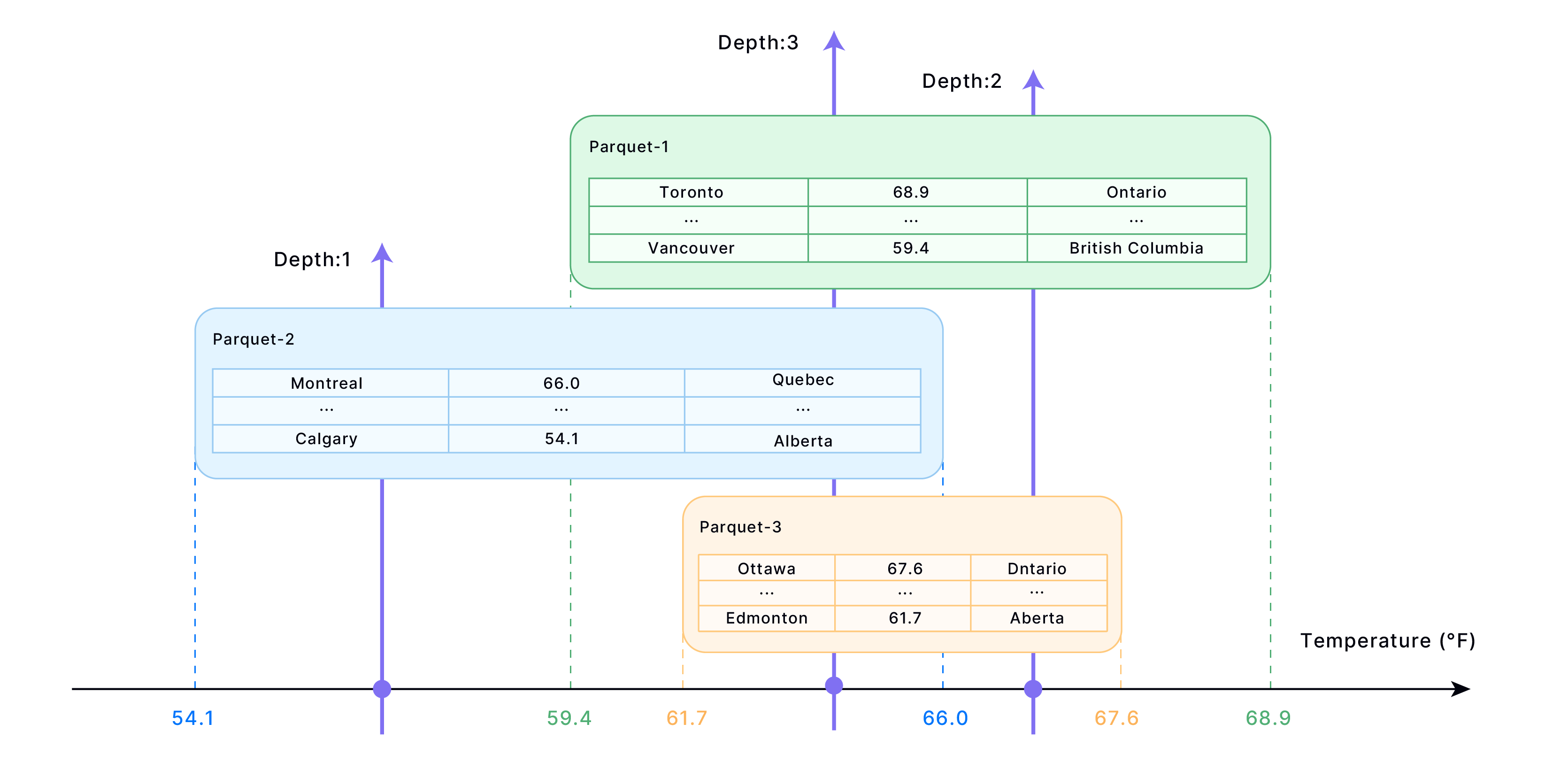
不同区间的重叠形成了不同的深度,例如上图:
select * from T where age >30 and age <35; 这样一个查询,需要查找到的深度为 3 ,即为 3 个 Block。
所以表中指定列的重叠block-partitions的平均深度,越小越好。如下所示:
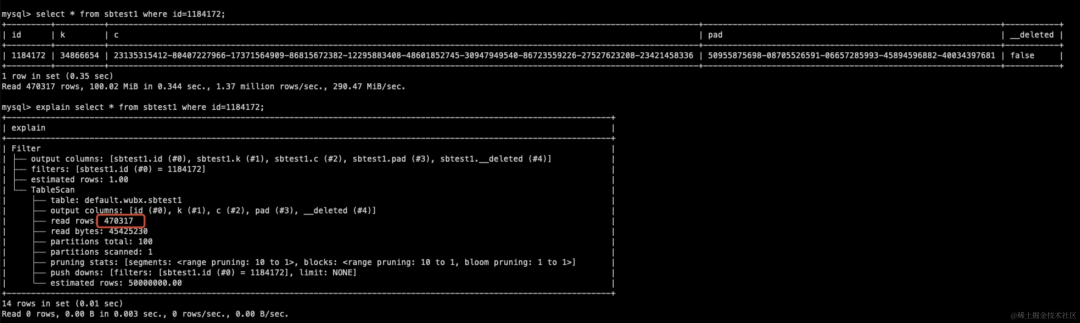
-- 可以通过 clustering_information('db','tbname') 查看该表的 Cluster 信息select * from clustering_information('wubx','sbtest10w')\G;
*************************** 1. row ***************************cluster_by_keys: (id) -- 定义的 Cluster keytotal_block_count: 451 -- 当前有多少的 blockconstant_block_count: 0 -- min/max 相等 block, 也就说 block 中只包括一个(组) cluster_key 的值
unclustered_block_count: 0 -- 还没 Cluster 的 Blockaverage_overlaps: 2.1774 -- 在一个 Range 范围内,有多少个 block有重叠比率average_depth: 2.4612 -- cluster key 在分区的重叠分区数的平均深度block_depth_histogram: {"00001":32,"00002":217,"00003":164,"00004":38}
1 row in set (0.02 sec)
Read 1 rows, 448.00 B in 0.015 sec., 67.92 rows/sec., 29.71 KiB/sec.结果中最重要信息是“average_depth”,数字越小, 表的clustering效果越好,上图为: 2.46,属于比较好的状态(小于 total_block_count * 0.1 ) 。block_depth_histogram 告诉更多关于每个深度有多少个分区的详细信息。 如果在较低深度中的分区数更多,则表的聚类效果更好。 例如"00004" :38 表示 (3,4] 有 38 个 block 有 4 个深度。
其它优化建议
- 一般来讲声明 Cluster key 后对于区间查询和点查都有较大的优化
- 如果声明 cluster key 后,还想进一步的提升点查或是区间查询的能力,可以通过调整 block 大小
-- 把 Block 的大小修改为压缩前 50M ,行数不超过 10 万行
alter table T set options(row_per_block=100000,block_size_threshold=52428800);关于 options 查看: Fuse Engine | Databend
默认数据分布:
优化数据在 Block 中的分布
create table sbtest10w like sbtest1;
alter table sbtest10w set options(row_per_block=100000,block_size_threshold=52428800);
insert into sbtest10w select * from sbtest1;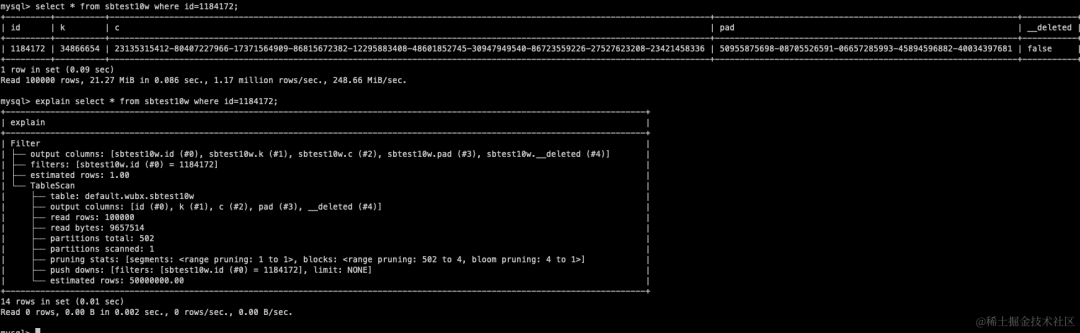
- 对于特别宽的表,建议查询中只访问需要的列来减少时间开销
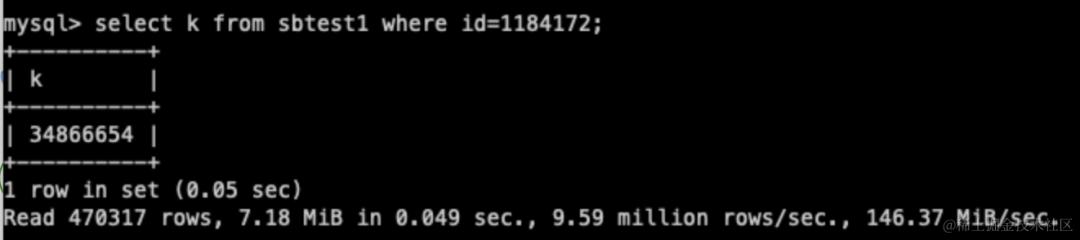

- 对于复杂的 SQL 里面有大量聚合的操作还是推荐大一点的 Block 及行数
参考
- CLUSTERING_INFORMATION | Databend
- RECLUSTER TABLE | Databend
相关文章:
理解 Databend Cluster key 原理及使用
Databend Cluster Key 是指 Databend 可以按声明的 key 排序存储,主要用于用户对时间响应比较高,同时愿意为这个 cluster key 进行额排序操作的用户。 Databend 只支持一个 Cluster key,Cluster key中可以包含多列及表达式。 基本语法 -- 语…...
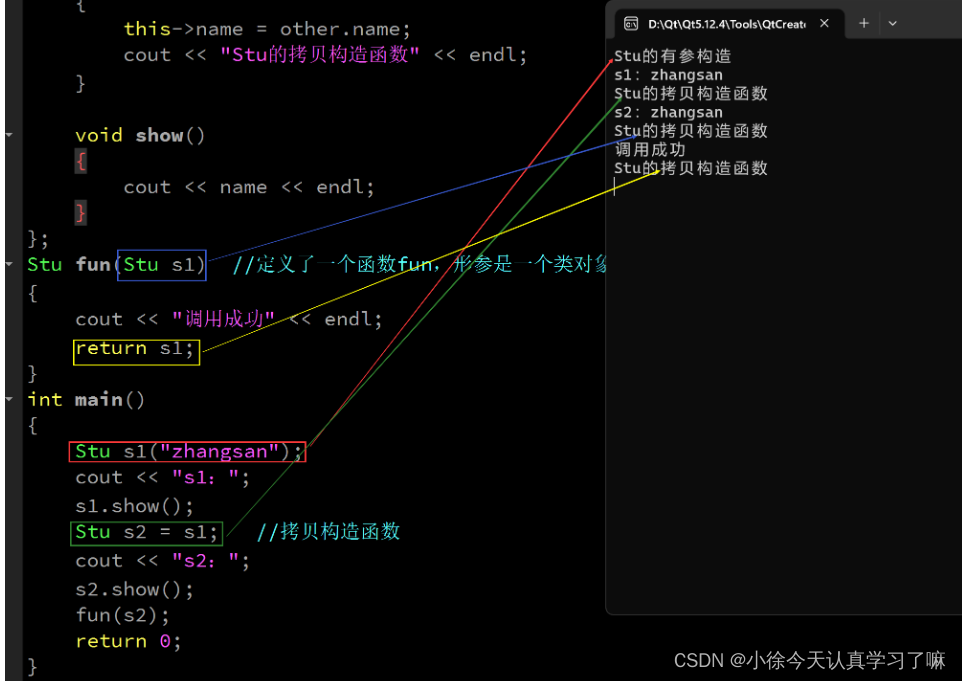
C++day3(类、this指针、类中的特殊成员函数)
一、Xmind整理: 二、上课笔记整理: 1.类的应用实例 #include <iostream> using namespace std;class Person { private:string name; public:int age;int high;void set_name(string n); //在类内声明函数void show(){cout << "na…...

Qt中的配置文件:实现个性化应用程序配置与保存加载
一、前言 在现代软件开发中,用户对于应用程序的个性化配置和设置变得越来越重要。为了满足用户需求并提供更好的用户体验,开发人员常常需要实现一种机制,以便在每次启动应用程序时能够记住用户上次的配置。这样用户就可以方便地恢复到他们熟悉的环境,无需重新进行所有设置…...

Navicat激活时出现rsa public key not find错误
Navicat激活时出现rsa public key not find错误 在激活时,先不打开应用,先用管理员身份打开注册机Navicat_Keygen_Patch_v5.6_By_DFoX.exe,Navicat v15——>MySql——>Simplified Chinese——>Patch,执行完这些步骤之后…...

FFmpeg5.0源码阅读——URLContext和URLProtocol
摘要:本文描述FFmpeg中URLContext和URLProtocal的实现。 关键字:URLContext、URLProtocal FFmpeg中URLProtocol是具体的协议的抽象,其中定义了对应协议的抽象,其中包含了具体协议的操作函数指针。而URLContext是对协议操作的抽…...

Qt的输出
目录 基本分类 C风格输出 C风格 可以抑制输出 方法一 方法二 在Qt中进行log输出, 一般不使用c中的printf, 也不是使用C中的cout, Qt框架提供了专门用于日志输出的类, 头文件名为 QDebug。 基本分类 qDebug:调试信息提示 qInfo :输出信息 qWarnin…...

长胜证券:久违普涨再现 大盘回升有望加速
获得利好支撑后,大盘开始继续反弹。 沪指周二一路震动反弹,站上3100点整数关口后继续上攻并打破10日均线限制。深成指同样低开高走,全日体现明显强于沪指。 到收盘,沪指报收3135.89点,上涨1.2%;深成指报收…...
)
WPF .NET 7.0学习整理(一)
参照文档进行不系统的整理,看到那写到那O.o 依赖属性 DependencyProperty:使用专有字段支持属性的标准模式的替代方法。 DependencyObject:定义了可以注册和拥有依赖属性的基类。 public static readonly DependencyProperty IsSpinningPr…...

数据分析简介
判断采集数据的有效性和进行数据校准是数据处理中重要的步骤。以下是一些常见的方法和步骤可以帮助你进行数据有效性的判断和数据校准: 数据有效性判断: 数据范围:检查数据是否落在合理的范围内。根据具体情况,确定真实数据的上下限ÿ…...

解读未知:文本识别算法的突破与实际应用
解读未知:文本识别算法的突破与实际应用 1.文本识别算法理论 背景介绍 文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面…...
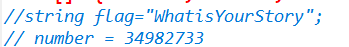
[第七届蓝帽杯全国大学生网络安全技能大赛 蓝帽杯 2023]——Web方向部分题 详细Writeup
Web LovePHP 你真的熟悉PHP吗? 源码如下 <?php class Saferman{public $check True;public function __destruct(){if($this->check True){file($_GET[secret]);}}public function __wakeup(){$this->checkFalse;} } if(isset($_GET[my_secret.flag]…...
el-backtop返回顶部的使用
2023.8.26今天我学习了如何使用el-backtop组件进行返回页面顶部的效果,效果如: <el-backtop class"el-backtop"style"right: 20px; bottom: 150px;"><i class"el-icon-caret-top"></i></el-backtop&…...

Go 官方标准编译器中所做的优化
本文是对#102 Go 官方标准编译器中实现的优化集锦汇总[1] 内容的记录与总结. 优化1-4: 字符串和字节切片之间的转化 1.紧跟range关键字的 从字符串到字节切片的转换; package mainimport ( "fmt" "strings" "testing")var cs10086 s…...
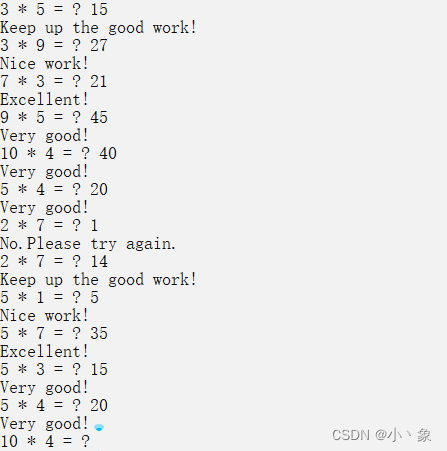
C语言程序设计——小学生计算机辅助教学系统
题目:小学生计算机辅助教学系统 编写一个程序,帮助小学生学习乘法。然后判断学生输入的答案对错与否,按下列任务要求以循序渐进的方式分别编写对应的程序并调试。 任务1 程序首先随机产生两个1—10之间的正整数,在屏幕上打印出问题…...

SQL自动递增的列恢复至从0开始
在许多数据库管理系统中,当你删除表格中的所有数据时,自动递增的列(也称为自增列、标识列或序列)的计数器通常不会重置为 0。这是出于性能和数据完整性方面的考虑,以避免因删除数据而导致的自增列值冲突。即使你删除了…...

介绍一下CDN
CDN(内容分发网络,Content Delivery Network)是一个由多个服务器组成的分布式网络,它的目的是将内容高效地传送到用户。下面是CDN的工作原理及其主要特点: 内容分发:当用户首次请求某一特定内容时ÿ…...
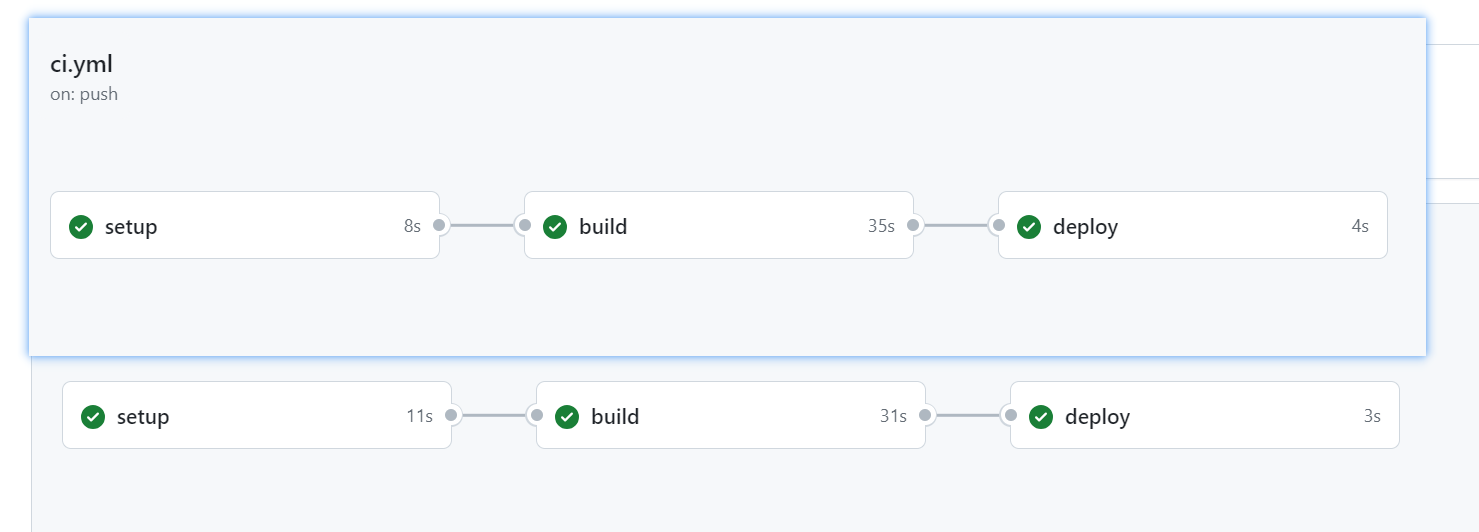
2023年最新 Github Pages 使用手册
参考:GitHub Pages 快速入门 1、什么是 Github Pages GitHub Pages 是一项静态站点托管服务,它直接从 GitHub 上的仓库获取 HTML、CSS 和 JavaScript 文件,(可选)通过构建过程运行文件,然后发布网站。 可…...
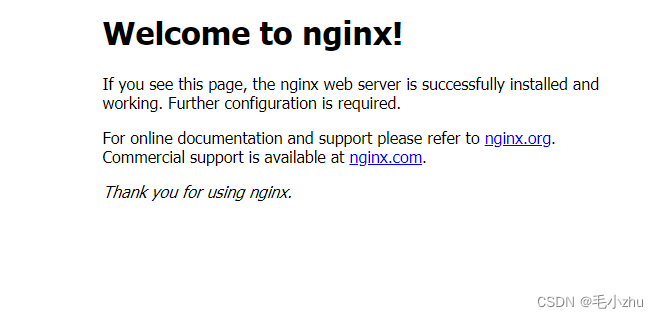
docker 安装 Nginx
1、下载 docker pull nginx:latest 2、本地创建管理目录 mkdir -p /var/docker/nginx/conf mkdir -p /var/docker/nginx/log mkdir -p /var/docker/nginx/html 3、将容器中的相应文件复制到管理目录中 /usr/docker/nginx docker run --name nginx -p 80:80 -d nginxdocke…...
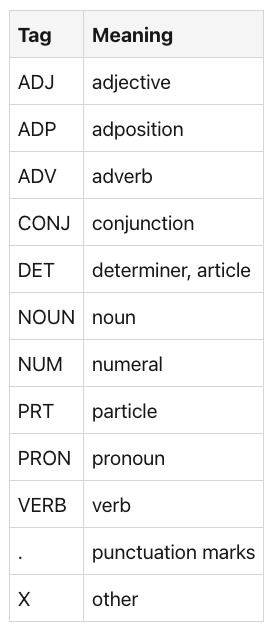
【NLP的python库(01/4) 】: NLTK
一、说明 NLTK是一个复杂的库。自 2009 年以来不断发展,它支持所有经典的 NLP 任务,从标记化、词干提取、词性标记,包括语义索引和依赖关系解析。它还具有一组丰富的附加功能,例如内置语料库,NLP任务的不同模型以及与S…...
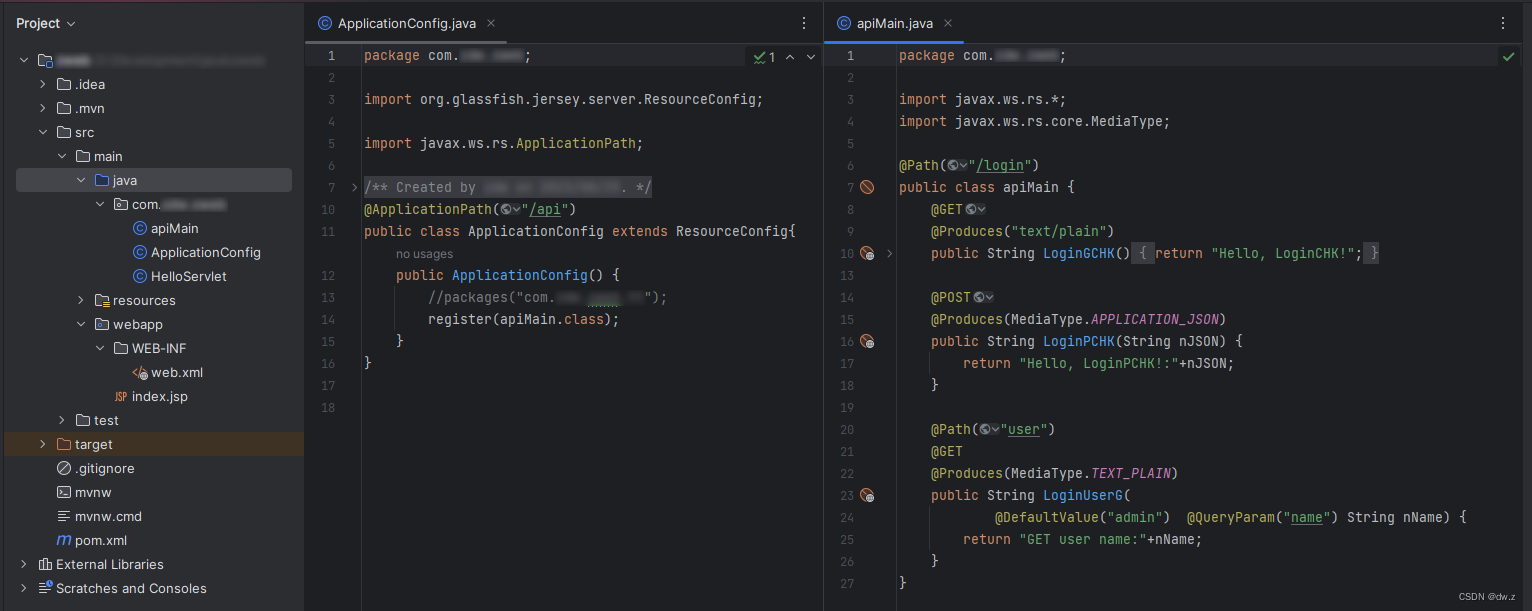
Java IDEA Web 项目 1、创建
环境: IEDA 版本:2023.2 JDK:1.8 Tomcat:apache-tomcat-9.0.58 maven:尚未研究 自行完成 IDEA、JDK、Tomcat等安装配置。 创建项目: IDEA -> New Project 选择 Jakarta EE Template:选择…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

Arduino打地鼠游戏机:从74HC595矩阵驱动到状态机编程全解析
1. 项目概述:用Arduino复刻经典打地鼠游戏作为一个电子爱好者,我总想把手头的Arduino和各种元器件玩出点新花样。这次,我决定挑战一个经典街机项目——电子打地鼠。市面上虽然有现成的玩具,但自己从头设计、画板、编程,…...

LinkSwift:九大网盘直链下载助手终极指南,告别限速烦恼
LinkSwift:九大网盘直链下载助手终极指南,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...