python 笔记(1)——基础和常用部分
目录
1、print 输出不换行
2、格式化输出字符串
3、浮点数的处理
4、进制转换和ASCII与字符间的转换
5、随机数
6、字符串截取和内置方法
6-1)字符串截取
6-2)字符串内置方法
7、元组、列表,及其遍历方式
7-1)列表常用内容
7-2)元组
7-3)几种遍历方式:
7-4)列表与元组之间的转化
8、字典即其遍历方法
8-1)字典的基本操作
8-2)字典的遍历
9、函数
9-1)默认参数
9-2)可变长参数
9-3)字典参数(关键字参数)
9-4)多种返回值
9-5)匿名函数(lambda 表达式)
10、包和模块
10-1)导入整个模块:
10-2)从模块中导入指定的内容:
10-3)从包中导入模块等:
1、print 输出不换行
''' 让第一次的输出不换行 '''
string = 'hello '
str = 'world.'
print(string, end='')
print(str, end='\n\n\n') # 结尾空两行
print('goodbye world')
2、格式化输出字符串
phone = input('请输入电话号码: ') # 命令行输入
string = 'your phone is : 'print(string + phone)print('%s%d' % (string, int(phone)))print(f"{string}{phone}")print('{}{}'.format(string, phone))
3、浮点数的处理
import math
num = 123.745print('舍去小数取整:', int(num))
print('返回两位小数:', '%.2f' % num)
print('返回两位小数:', '{:.2f}'.format(num))
print('向上取整:', math.ceil(num))
print('向下取整:', math.floor(num))
print('舍去小数取整:', math.trunc(num))
print('舍去小数取整:', int(num))
print('四舍五入取整:', round(num))4、进制转换和ASCII与字符间的转换
ord():字符转ASCII
chr():ASCII转字符
bin():十进制转二进制
oct():十进制转八进制
hex():十进制转十六进制
'''字符与ASCII码之间的转换'''
print(ord('A')) # 字符转ASCII码 65
print(chr(48)) # ASCII码转字符 0'''进制转换'''
print(bin(78)) # 十进制转二进制 0b1001110
print(oct(78)) # 十进制转八进制 0o116
print(hex(78)) # 十进制转十六进制 0x4e5、随机数
'''随机数'''
import randomr = random.randint(1, 10) # 闭区间内生成随机数
print(r)
r2 = random.randrange(1, 10, 2) # 左闭右开区间生成随机数,步长为2
print(r2)
r3 = random.uniform(1, 5) # 生成随机小数 左闭
print(r3)
r4 = random.choice("ABSCD") # 取随机的一个元素
print(r4)
r5 = random.choice([1,3,4,5,6,2])
print(r5)
6、字符串截取和内置方法
6-1)字符串截取
source = 'Hello_World'
print(source[0:5]) # 取[0,5) Hello
print(source[:5]) # 取[0,5) Hello
print(source[2]) # 取下标 l
print(source[-5:-1]) # 取倒数第5到倒数第2个字符 Worl
print(source[5:]) # 第5个到最后一个字符 _World
print(source[-1]) # 取最后一个字符 d
print(source[0:5:2]) # 从范围[0,5)中取,设置步长为2,取下标为 0 2 4拼接 Hlo6-2)字符串内置方法
source = 'HelloWorld'
print(source.count('l')) # 字符 l 在字符串中出现的次数
print(len(source)) # 字符串的长度
print(source.split('o')) # 按照o来拆分 ['Hell', 'W', 'rld']list = ['zhang','hou','wu','wang']
print('#'.join(list)) # 数组合并成字符串 zhang#hou#wu#wang# 编码和解码
source = '你好啊我是张三'
target = source.encode() # 将字符串按照指定的编码格式转换成字节类型,默认编码格式为utf-8
print(target, target == source) # b'HelloWorld' False
print(target.decode() == source) # True
# utf-8编码每 3个字节表示一个中文,而 gbk每 2个字节表示一个中文source = '\n\t hello world \n\n'
print(source.strip()) # 将字符串左右的换行符和空格都清理掉7、元组、列表,及其遍历方式
7-1)列表常用内容
.append(x):往列表最后添加一个元素;
.pop():移除第一个元素;
.reverse():翻转列表;
.remove(x):从列表中移除指定的元素;
(以上四个方法都会改变原数组)
.count(x):统计x在列表中出现的次数;
.index(x):x再列表中第一次出现的位置
.max()、.min()方法分别返回列表中的最大、最小值;
mylist = [1, 6, 234.23, 'adf', '张三']
print(mylist) # [1, 6, 234.23, 'adf', '张三']
print(mylist[2]) # 234.23
print(mylist[-1]) # 张三
print(mylist[:2]) # [1, 6]
print(6 in mylist) # True
print(mylist + ['哈哈']) # [1, 6, 234.23, 'adf', '张三', '哈哈']a,b,c = mylist[:3]
print(a, b, c) # 1 6 234.23print(len(mylist)) # 5mylist.append('end')
print(mylist) # [1, 6, 234.23, 'adf', '张三', 'end']
print(mylist.index('张三')) # 4mylist.pop()
print(mylist) # [1, 6, 234.23, 'adf', '张三']mylist.reverse()
print(mylist) # ['张三', 'adf', 234.23, 6, 1]7-2)元组
元组是不可改变的,因此元组没有列表中的append、pop、remove等的方法。
tup_1 = (1, 234.23, 'adf', '张三')
print(tup_1[2]) # adf
print(tup_1[:3]) # (1, 234.23, 'adf')tup_2 = (1)
print(tup_2, type(tup_2)) # 1 <class 'int'>tup_3 = (1,)
print(tup_3, type(tup_3)) # (1,) <class 'tuple'>7-3)几种遍历方式:
遍历元组和遍历列表基本一致。
mylist = [1,2,3,4,5,6]
for e in mylist: # 遍历,e是mylist中的元素print(e)for i in range(0, len(mylist)): # 遍历,左闭右开 i 是索引print(i, end='\t')print(mylist[i])''' for——else 结构 '''
for item in mylist:print(item)
else:print("循环结束")''' while——else 结构 '''
i = 0
while i < len(mylist):print(list[i])i += 1
else:print('循环结束')
7-4)列表与元组之间的转化
tuple(list):列表转换成元组
list(tuple) :元组转换成列表
list1 = [1,2,3,4,5]
tup1 = tuple(list1) # 列表转换成元组
print(tup1) # (1, 2, 3, 4, 5)
list2 = list(tup1) # 元组转换成列表
print(list2) # [1, 2, 3, 4, 5]8、字典即其遍历方法
8-1)字典的基本操作
student = {"name":'张三',"age":24,"gender":'男'
}# 两种获取方法
print(student["name"]) # 张三
print(student.get("name")) # 张三# 两种修改的方式
student["age"] += 1
print(student) # {'name': '张三', 'age': 25, 'gender': '男'}
student.update({"name":'王五', "age":18})
print(student) # {'name': '王五', 'age': 18, 'gender': '男'}student["phone"] = "12312344212" # 新增
print(student) # {'name': '王五', 'age': 18, 'gender': '男', 'phone': '12312344212'}student.pop('gender') # 删除某一项
print(student) # {'name': '王五', 'age': 18, 'phone': '12312344212'}8-2)字典的遍历
for i in student: # 得到的 i 是 keyprint(f"key:{i}, value:{student[i]}")
'''
key:name, value:王五
key:age, value:18
key:phone, value:12312344212
'''for k in student.keys(): # 直接遍历键print(k)
'''
name
age
phone
'''for v in student.values(): # 直接遍历值print(v)
'''
王五
18
12312344212
'''for kv in student.items(): # 遍历出由键和值构造出来的元组print(kv)
'''
('name', '王五')
('age', 18)
('phone', '12312344212')
'''for k,v in student.items(): # 同时遍历键和值print(k, v)
'''
name 王五
age 18
phone 12312344212
'''9、函数
python 中的参数分为4类 1、必须参数(位置参数,positional argument) 2、默认参数(定义形参时可以指定一个默认值 3、可变长参数,可选参数 加 * 在前面来说明 接收到的数据将组成元组的形式可变长参数必须放到必须参数后,同时建议放到默认参数后 4、字典参数,关键字参数, 字典参数需要在可变长参数之后 加 ** 在前面来说明
9-1)默认参数
def test_args_1(a, b, c = 100): # a、b是必须参数,c是默认参数,如果不传c,则c默认为100print(a * b + c)test_args_1(1, 2, 3) # 5
test_args_1(2, 3) # 106
test_args_1(c=12, a=3, b=4) # 能够正常工作,不必关心顺序问题 结果为 249-2)可变长参数
def test_args_2(a, b, *args):print(args) # 可变长参数,以元组的形式存在 (3, 4)print(*args) # 在元组或列表前面加 * 号,把元组和列表展开 3 4res = 0for item in args:res += itemres += a + bprint(res) # 10test_args_2(1, 2, 3, 4)9-3)字典参数(关键字参数)
def test_args_3(a, b, *args, **kwargs):result = a + bprint(result) # 3print(args) # (3,4,5)print(kwargs) # {'name': '张三', 'age': 64}# 字典参数中的键名不能与函数的形参名相同
test_args_3(1, 2, 3, 4, 5, name="张三", age=64)9-4)多种返回值
def test_func_1(a,b,c):return a, [b, a], {"sum":a+b+c}res = test_func_1(1,6,3)
print(res) # (1, [6, 1], {'sum': 10})x,y,z = test_func_1(1,6,3)
print(x,y,z) # 1 [6, 1] {'sum': 10}9-5)匿名函数(lambda 表达式)
lambda 参数:返回值
lamb = lambda a, b : a + b
res = lamb(1, 2)
print(res) # 3lamb_1 = lambda *args : sum(args)
res = lamb_1(1,2,3,4,5)
print(res) # 15
10、包和模块
模块 是包含python定义和语句的文件,每一个以.py后缀结尾的文件都可以看成是一个模块;
包 可以看成是包含若干个python模块的文件夹(目录),但是该目录下需要有一个 __init__.py 文件才能被识别为一个包(可以在需要的时候在目录下直接创建一个__init__.py 文件);
在导入一个模块的时候,实际上是把该模块的代码重新执行了一遍;一个模块不管import了多少遍,只会执行一次;可以在任何需要的地方导入模块;
10-1)导入整个模块:
# 第一中方式
import math, re, osprint(math.sin(math.pi / 2)) # 需要 模块名.函数 或 模块名.变量名 这样的形式来使用# 第二种方式
from math import *print(sin(pi / 2)) # 可以直接使用10-2)从模块中导入指定的内容:
# 从 math 模块中导入 sin 函数和 pi 模块变量
from math import sin,piprint(sin(pi / 2))10-3)从包中导入模块等:
# 1
from parent_modules.child_modules.package_1 import testFunc
res = testFunc(1,2)
print(res)# 2
from parent_modules.child_modules.package_1 import *
res = testFunc(1,2)
test('你好')
print(res)# 3
from parent_modules.child_modules import package_1
package_1.test('你好啊')相关文章:
python 笔记(1)——基础和常用部分
目录 1、print 输出不换行 2、格式化输出字符串 3、浮点数的处理 4、进制转换和ASCII与字符间的转换 5、随机数 6、字符串截取和内置方法 6-1)字符串截取 6-2)字符串内置方法 7、元组、列表,及其遍历方式 7-1)列表常用内…...
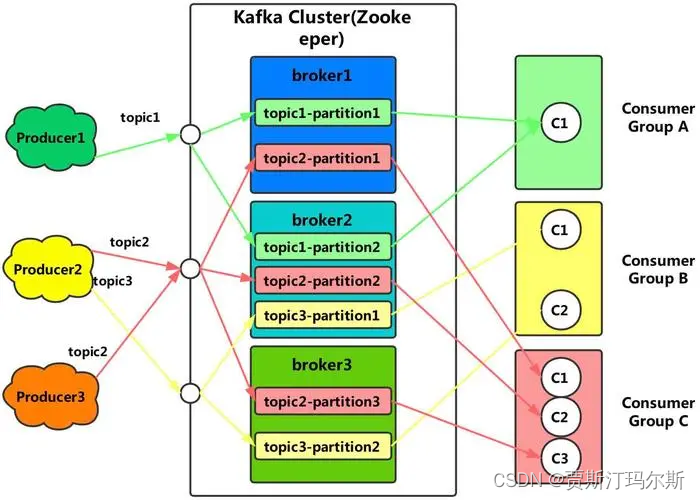
kafka架构和原理详解
Apache Kafka 是一个分布式流数据平台,用于高吞吐量、持久性、可扩展的发布和订阅消息。它具有高度的可靠性,被广泛用于构建实时数据流处理、日志收集和数据管道等应用。 基本架构 1. 主题(Topic): 主题是消息的逻辑分类生产者将消息发布到特定的主题中,而消费者可以订阅…...

wsl Ubuntu中非root的普通用户怎么直接执行docker命令
docker需要root权限,如果希望非root用户直接使用docker命令,而不是使用sudo,可以选择将该用户加入到docker用户组。 sudo groupadd docker:添加到groupadd用户组(已经有docker用户组,所以可以不用再新增do…...
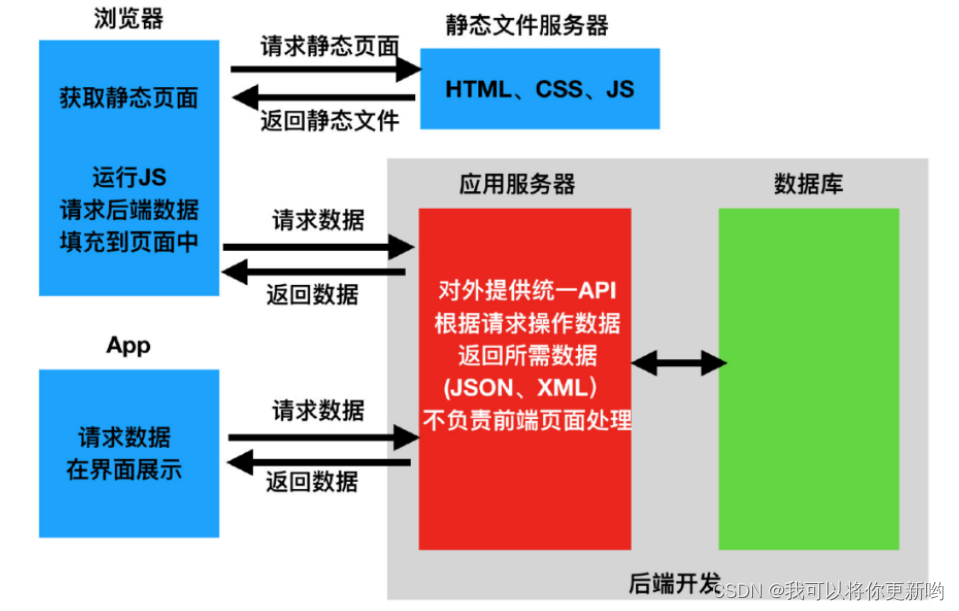
Web开发模式、API接口、restful规范、序列化和反序列化、drf安装和快速使用、路由转换器(复习)
一 Web开发模式 1. 前后端混合开发模式 前后端混合开发模式是一种开发方式,将前端和后端的开发工作结合在一起,以加快项目的开发速度和 提高协作效率。这种模式通常用于快速原型开发、小型项目或敏捷开发中。在前后端混合开发模式中,前端和…...
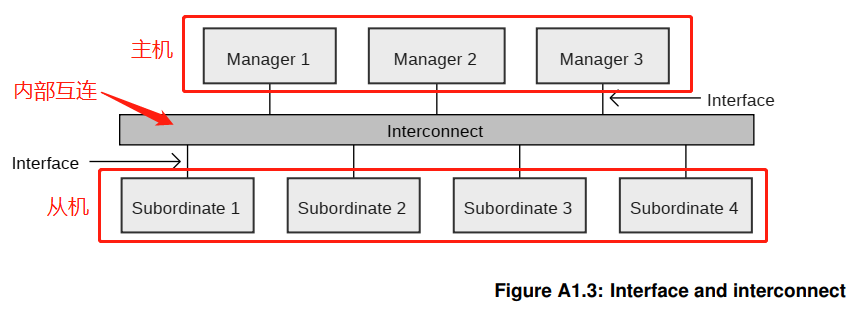
<AMBA总线篇> AXI总线协议介绍
目录 01 AXI协议简介 AXI协议特性 AXI协议传输特性 02 AXI协议架构 AXI协议架构 write transaction(写传输) read tramsaction(读传输) Interface and interconnect 典型的AXI系统拓扑 03 文章总结 大家好,这里是程序员杰克。一名平平无奇的嵌入式软件工程…...

一个简单的Python网络爬虫教程
网络爬虫是一种自动获取网页内容的程序,它可以从互联网上的网站中提取数据并进行分析。本教程将带您逐步了解如何使用 Python 构建一个简单的网络爬虫。 注意:在进行网络爬虫时,请遵守网站的使用条款和法律法规,避免对目标网站造…...
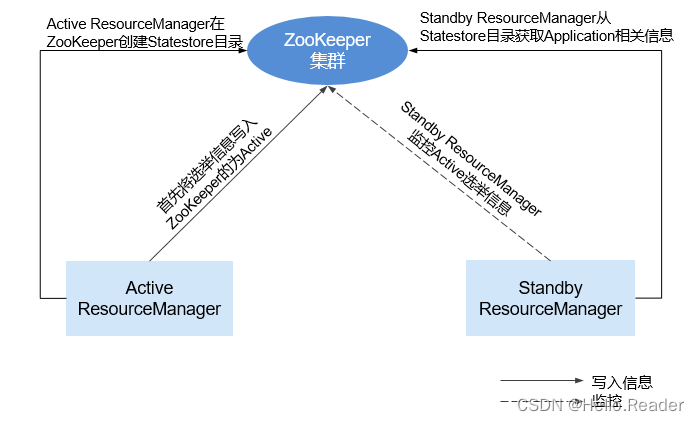
YARN资源管理框架论述
一、简介 为了实现一个Hadoop集群的集群共享、可伸缩性和可靠性,并消除早期MapReduce框架中的JobTracker性能瓶颈,开源社区引入了统一的资源管理框架YARN。 YARN是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离&…...

Unity查找资源依赖关系
这个方法主要是发现资源乱用的情况,对应的逻辑可能要改一个才能用到自己的项目里面 [MenuItem("Tools/Prefab/查找选中资源依赖关系", false, 0)] public static void FindDependencies() { foreach (var guid in Selection.assetGUIDs…...
【操作系统】聊聊局部性原理是如何提升性能的
对于目前数据主导的系统,大多数都是Java/Go 技术栈MySQL,但是随着时间的推移,数据库数据的数据量过多,并且会频繁访问热点数据,为了提升系统的性能,一般都是加入缓存中间件、Redis。 局部性原理 我们知道…...
多线程应用——单例模式
单例模式 文章目录 单例模式一.什么是单例模式二.如何实现1.口头实现2.利用语法特性 三.实现方式(饿汉式懒汉式)1.饿汉式2.懒汉式3.线程安全的单例模式4.双重检查锁5.禁止指令重排序 一.什么是单例模式 单例模式(Singleton Patternÿ…...

几种在JavaScript中创建对象的方式!
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 字面量方式⭐ 构造函数方式⭐ Object.create()方式⭐ 工厂函数方式⭐ ES6类方式⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门…...

java项目mysql转postgresql
特殊函数 : mysql: find_in_set(?, ancestors) postgresql: ? ANY (string_to_array(ancestors,,)) mysql: date_format(t1.oper_time, %Y-%m-%d) postgresql: rksj::date to_char(inDate,YYYY-MM-DD) mysql&am…...
SpringBoot Mybatis 多数据源 MySQL+Oracle
一、背景 在SpringBoot Mybatis 项目中,需要连接 多个数据源,连接多个数据库,需要连接一个MySQL数据库和一个Oracle数据库 二、依赖 pom.xml <dependencies><dependency><groupId>org.springframework.boot</groupId&…...
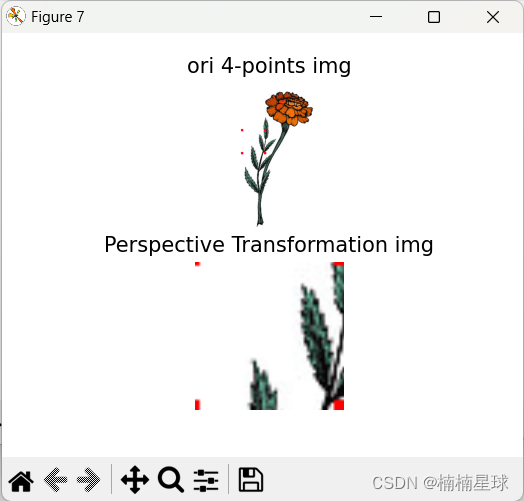
(笔记五)利用opencv进行图像几何转换
参考网站:https://docs.opencv.org/4.1.1/da/d6e/tutorial_py_geometric_transformations.html (1)读取原始图像和标记图像 import cv2 as cv import numpy as np from matplotlib import pyplot as pltpath r"D:\data\flower.jpg&qu…...
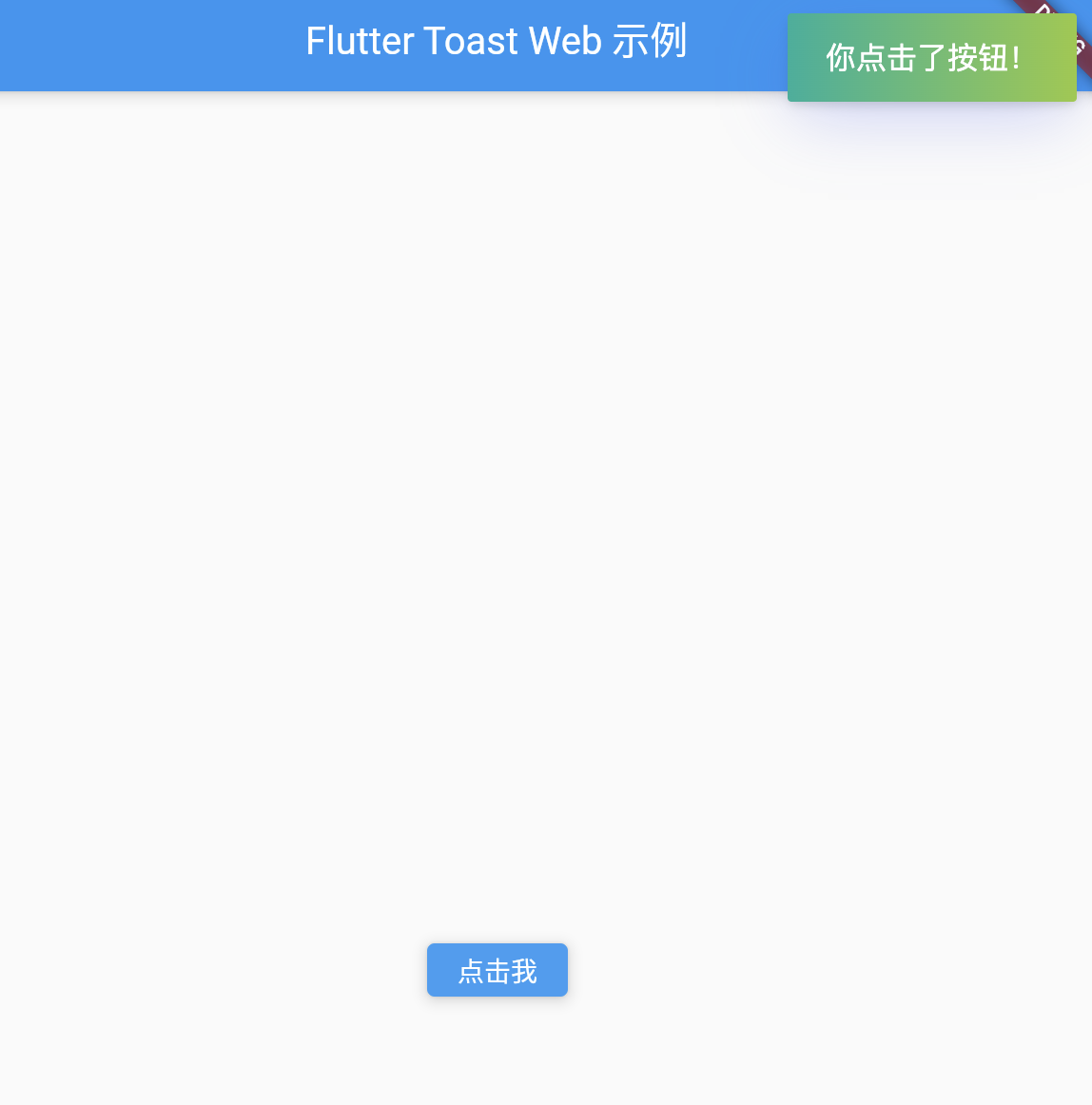
【Flutter】Flutter 使用 fluttertoast 实现显示 Toast 消息
【Flutter】Flutter 使用 fluttertoast 实现显示 Toast 消息 文章目录 一、前言二、安装和基础使用三、不同平台的支持情况四、如何自定义 Toast五、在实际业务中的应用六、完整的业务代码示例(基于 Web 端)七、总结 一、前言 在这篇文章中,…...
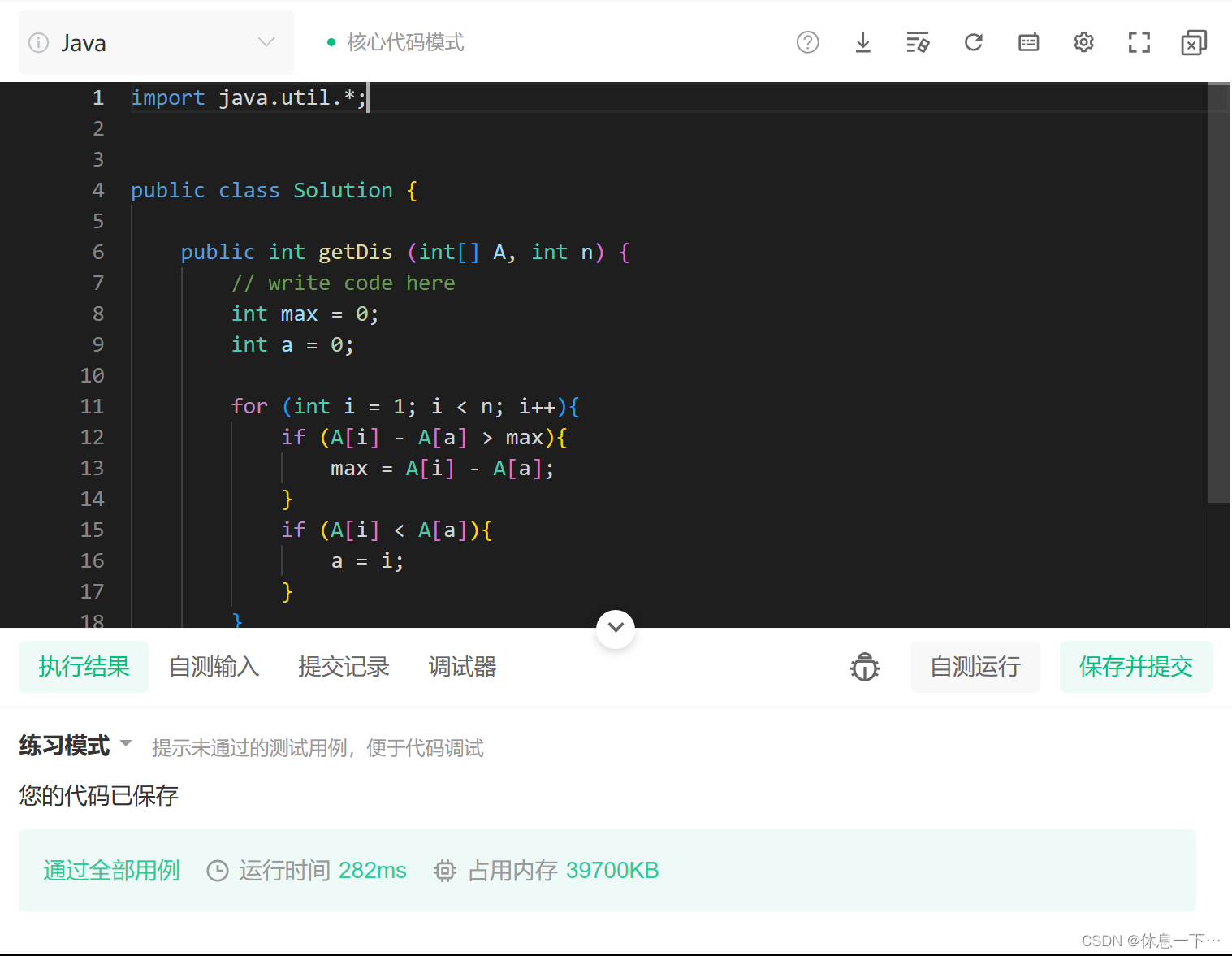
nowcoder NC236题 最大差值
目录 题目描述: 示例1 示例2 题干解析: 暴力求解: 代码展示: 优化: 代码展示: 题目跳转https://www.nowcoder.com/practice/a01abbdc52ba4d5f8777fb5dae91b204?tpId128&tqId33768&ru/exa…...
TCP/IP五层模型、封装和分用
1.网络通信基础2.协议分层OSI七层协议模型TCP/IP五层/四层协议模型【重点】 3. 封装&分用 1.网络通信基础 IP地址:表示计算机的位置,分源IP和目标IP;举个例子:买快递,商家从上海发货,上海就是源IP&…...

LeetCode 面试题 01.08. 零矩阵
文章目录 一、题目二、C# 题解 一、题目 编写一种算法,若M N矩阵中某个元素为0,则将其所在的行与列清零。 点击此处跳转题目。 示例 1: 输入: [ [1,1,1], [1,0,1], [1,1,1] ] 输出: [ [1,0,1], [0,0,0], [1,0,1] ] 示…...

Qt应用开发(基础篇)——进度条 QProgressBar
一、前言 QProgressBar类继承于QWidget,是一个提供了横向或者纵向进度条的小部件。 QProgressBar进度条一般用来显示用户某操作的进度,比如烧录、导入、导出、下发、上传、加载等这些需要耗时和分包的概念,让用户知道程序还在正常的执行中。 …...
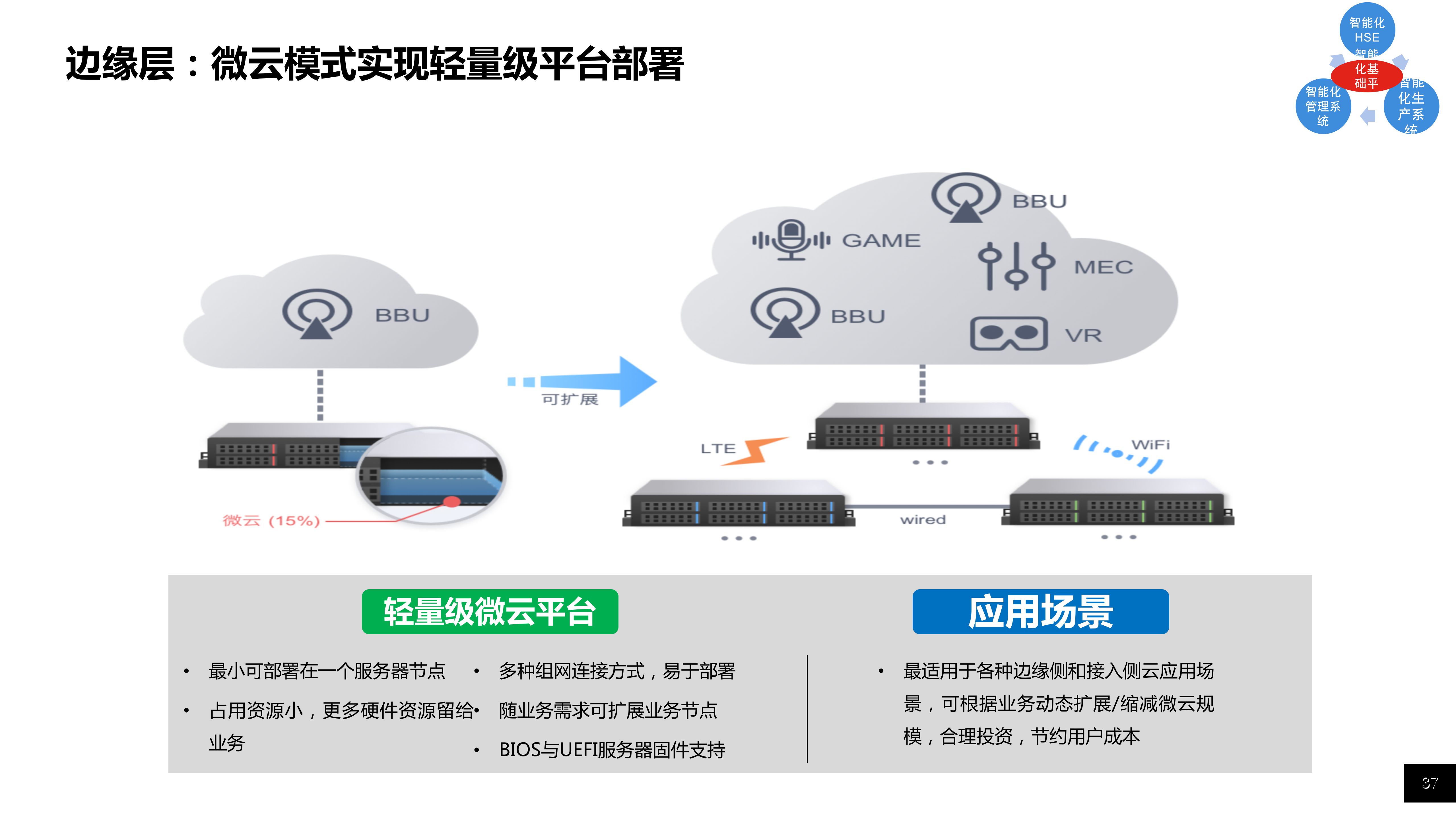
108页石油石化5G智慧炼化厂整体方案PPT
导读:原文《108页石油石化5G智慧炼化厂整体方案PPT》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。以下是部分内容,...

2026年,本地精准营销高性价比服务商来袭,你还不了解一下?
在本地商业竞争日益激烈的2026年,实体店面临着诸多挑战,引流难、成本高、复购率低等问题困扰着众多商家。而中粤(广州)信息科技有限公司作为本地精准营销的高性价比服务商,正以其独特的优势和卓越的服务,为…...

浏览器 Profile 环境排查:Cookie、LocalStorage、网络出口与自动化任务配置清单
一、为什么浏览器环境经常“今天能用,明天失效”很多团队遇到登录状态丢失、页面配置异常、自动化任务失败时,会先怀疑网络、脚本或系统本身。但在实际项目里,问题经常不是单点故障,而是浏览器环境缺少稳定管理:对象常…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构
深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-…...

SpringBoot WebClient 介绍
目录一、什么是 WebClient?二、 WebClient 能解决什么问题?三、WebClient 和 RestTemplate 的区别四、WebClient 的核心优势1. 非阻塞(Non-Blocking)2. 支持异步3. 链式 API 更现代五、WebClient 的核心对象六、Mono 和 Flux 是什…...
)
【独家首发】DeepSeek边缘计算白皮书未公开章节:3类典型场景QoS SLA保障公式(含实测RTT抖动衰减模型)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek边缘计算架构全景概览 DeepSeek边缘计算架构以“轻量、协同、自治”为核心设计理念,面向AI推理密集型场景构建端—边—云三级协同的分布式智能执行体。该架构并非传统云中心化模型的…...

UE5 UMG界面开发避坑指南:WidgetComponent的ZOrder和图层管理到底怎么用?
UE5 UMG界面开发避坑指南:WidgetComponent的ZOrder和图层管理实战解析在虚幻引擎5的UMG界面开发中,WidgetComponent的渲染层级管理是一个看似简单却暗藏玄机的技术点。许多开发者在处理复杂UI系统时,常常会遇到控件遮挡混乱、图层顺序失控的问…...

终极指南:如何在macOS上使用eqMac专业音频均衡器提升音质体验
终极指南:如何在macOS上使用eqMac专业音频均衡器提升音质体验 【免费下载链接】eqMac macOS System-wide Audio Equalizer & Volume Mixer 🎧 项目地址: https://gitcode.com/gh_mirrors/eq/eqMac 你是否厌倦了macOS系统单调的音频效果&#…...
)
别再只用JSON了!用Protobuf给Go微服务接口性能提升10倍(附完整代码)
别再只用JSON了!用Protobuf给Go微服务接口性能提升10倍(附完整代码) 在微服务架构中,接口性能往往是决定系统吞吐量的关键因素。许多开发者习惯性地使用JSON作为数据交换格式,却不知道这可能在无形中成为性能瓶颈。本…...