无涯教程-分类算法 - 随机森林
随机森林是一种监督学习算法,可用于分类和回归,但是,它主要用于分类问题,众所周知,森林由树木组成,更多树木意味着更坚固的森林。同样,随机森林算法在数据样本上创建决策树,然后从每个样本中获取预测,最后通过投票选择最佳解决方案。它是一种集成方法,比单个决策树要好,因为它可以通过对输出求平均值来减少过度拟合。
随机森林算法
无涯教程可以通过以下步骤来了解随机森林算法的工作原理-
步骤1 - 首先,从给定的数据集中选择随机样本。
步骤2 - 接下来,该算法将为每个样本构造一个决策树。然后它将从每个决策树中获得预测输出。
步骤3 - 在此步骤中,将对每个预测输出进行投票。
步骤4 - 最后,选择投票最多的预测输出作为最终预测输出。
下图将说明其工作方式-

代码实现
首先,从导入必要的Python包开始-
import numpy as np import matplotlib.pyplot as plt import pandas as pd
接下来,如下所示从其网络链接下载iris数据集:
path="https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
接下来,需要为数据集分配列名称,如下所示:
headernames=[sepal-length, sepal-width, petal-length, petal-width, Class]
现在,需要将数据集读取为pandas数据框,如下所示:
dataset=pd.read_csv(path, names=headernames) dataset.head()
| 分隔长度 | 分隔宽度 | 花瓣长度 | 花瓣宽度 | 类 | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
数据预处理将在以下脚本行的帮助下完成。
X=dataset.iloc[:, :-1].values y=dataset.iloc[:, 4].values
接下来,无涯教程将数据分为训练和测试拆分。以下代码将数据集分为70%的训练数据和30%的测试数据-
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.30)
接下来,借助sklearn的 RandomForestClassifier 类训练模型,如下所示:
from sklearn.ensemble import RandomForestClassifier classifier=RandomForestClassifier(n_estimators=50) classifier.fit(X_train, y_train)
最后,需要进行预测。可以在以下脚本的帮助下完成-
y_pred=classifier.predict(X_test)
接下来,按如下所示打印输出-
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2)
运行上面代码输出
Confusion Matrix: [[14 0 0][ 0 18 1][ 0 0 12]] Classification Report:precision recall f1-score supportIris-setosa 1.00 1.00 1.00 14 Iris-versicolor 1.00 0.95 0.97 19Iris-virginica 0.92 1.00 0.96 12micro avg 0.98 0.98 0.98 45macro avg 0.97 0.98 0.98 45weighted avg 0.98 0.98 0.98 45Accuracy: 0.9777777777777777
分类算法 - 随机森林 - 无涯教程网无涯教程网提供随机森林是一种监督学习算法,可用于分类和回归,但是,它主要用于分类问题,众所周知... https://www.learnfk.com/python-machine-learning/machine-learning-with-python-classification-algorithms-random-forest.html
https://www.learnfk.com/python-machine-learning/machine-learning-with-python-classification-algorithms-random-forest.html
相关文章:
无涯教程-分类算法 - 随机森林
随机森林是一种监督学习算法,可用于分类和回归,但是,它主要用于分类问题,众所周知,森林由树木组成,更多树木意味着更坚固的森林。同样,随机森林算法在数据样本上创建决策树,然后从每…...

c#常见的排序算法
在C#中,常见的排序算法包括以下几种: 1. 冒泡排序(Bubble Sort):比较相邻的元素,如果顺序不对就交换它们,重复多次直到排序完成。 2. 插入排序(Insertion Sort)…...
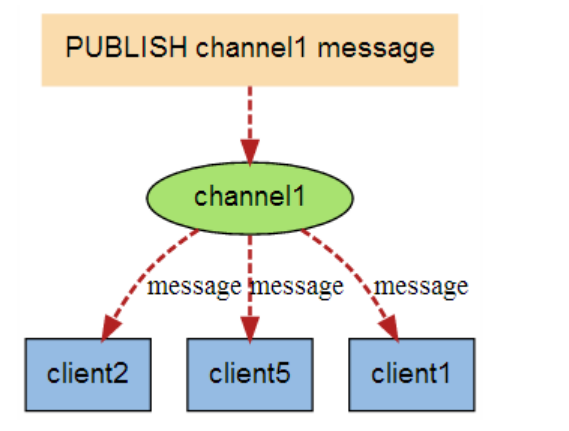
Redis 持久化和发布订阅
一、持久化 Redis 是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以 Redis 提供了持久化功能! 1.1、RDB(Redis DataBase) 1.1.1 …...
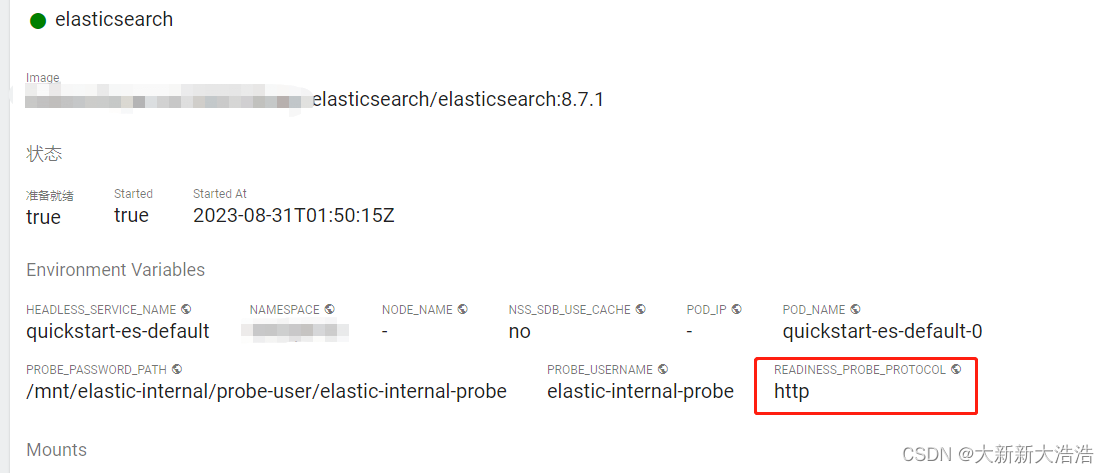
k8s使用ECK(2.4)形式部署elasticsearch+kibana-http协议
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、准备elasticsearch-cluster.yaml二、部署并测试总结 前言 之前写了eck2.4部署eskibana,默认的话是https协议的,这里写一个使用http…...
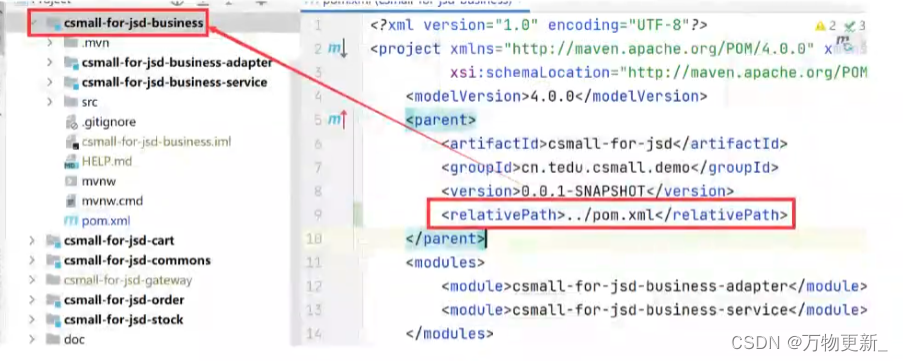
[maven]关于pom文件中的<relativePath>标签
关于pom文件中的<relativePath>标签 为什么子工程要使用relativePath准确的找到父工程pom.xml.因为本质继承就是pom的继承。父工程pom文件被子工程复用了标签。(可以说只要我在父工程定义了标签,子工程就可以没有,因为他继承过来了&…...
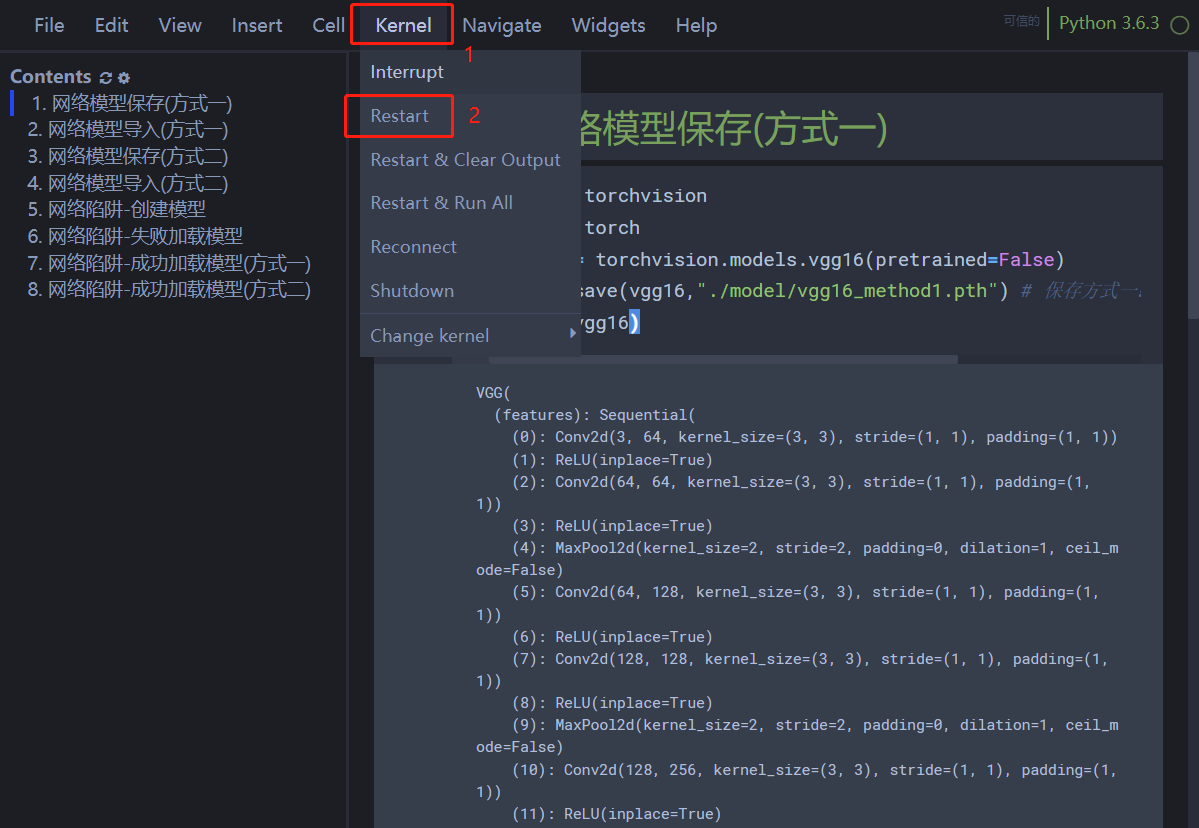
11. 网络模型保存与读取
11.1 网络模型保存(方式一) import torchvision import torch vgg16 torchvision.models.vgg16(pretrainedFalse) torch.save(vgg16,"./model/vgg16_method1.pth") # 保存方式一:模型结构 模型参数 print(vgg16) 结果: VGG((feature…...

新SDK平台下载开源全志V853的SDK
获取SDK SDK 使用 Repo 工具管理,拉取 SDK 需要配置安装 Repo 工具。 Repo is a tool built on top of Git. Repo helps manage many Git repositories, does the uploads to revision control systems, and automates parts of the development workflow. Repo is…...

多图详解VSCode搭建Java开发环境
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
基于JavaWeb和mysql实现网上书城前后端管理系统(源码+数据库+开题报告+论文+答辩技巧+项目功能文档说明+项目运行指导)
一、项目简介 本项目是一套基于JavaWeb和mysql实现网上书城前后端管理系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。 包含:项目源码、项目文档、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都…...

Swift创建单例
Objective-C使用GCD 中的dispatch_once_t 可以保证里面的代码只被调用一次,以此保证单例在线程上的安全。 但是在Swift 中由于废弃了原有的Dispatch once方法,因此无法使用once 进行单例的创建。 我们可以使用struct 存储类型变量,并且使用…...

问道管理:市盈率怎么计算?
市盈率是衡量一家公司股票价格是否合理的重要目标之一,核算市盈率的公式是将一家公司的股票价格除以每股收益,也便是市盈率 股票价格 每股收益。市盈率能够告诉你一个公司的股票价格是否高估或轻视,是投资者在买入或卖出一家公司股票时需求…...

Ansible File模块,Ansible File模块详解,文件管理的自动化利器
Ansible是一款强大的自动化工具,用于管理和配置IT基础设施。在Ansible中,File模块(File Module)是一个重要的组件,用于文件管理和操作。本文将深入探讨Ansible File模块,了解它如何成为文件管理的自动化利器…...

记录http与mqtt的区别
HTTP是最流行和最广泛使用的协议。但在过去几年中,MQTT迅速获得了牵引力。当我们谈论物联网开发时,开发人员必须在它们之间做出选择。 设计和消息传递 MQTT以数据为中心,而HTTP是以文档为中心的。HTTP是用于客户端 – 服务器计算的请求 – …...
导入excel数据给前端Echarts实现中国地图-类似热力图可视化
导入excel数据给前端Echarts实现中国地图-类似热力图可视化 程序文件: XinqiDaily/frontUtils-showSomeDatabaseonMapAboutChina/finalproject xin麒/XinQiUtilsOrDemo - 码云 - 开源中国 (gitee.com) https://gitee.com/flowers-bloom-is-the-sea/XinQiUtilsOr…...
【MySQL系列】MySQL复合查询的学习 _ 多表查询 | 自连接 | 子查询 | 合并查询
「前言」文章内容大致是对MySQL复合查询的学习。 「归属专栏」MySQL 「主页链接」个人主页 「笔者」枫叶先生(fy) 目录 一、基本查询回顾二、多表查询三、自连接四、子查询4.1 单行子查询4.2 多行子查询4.3 多列子查询4.4 在from子句中使用子查询 五、合并查询 一、基本查询回顾…...

微信小程序使用本地图片在真机预览不显示的问题解决
开发工具上本地图片可以显示,但是在真机上预览的时候不能显示 通常我们代码路径是代码是这样写的: <view class"logo"><image src"../../img/e8591fd7b1043bd3b4eb07d86243b5b.png"></image> </view> 最…...
Texlive2023与Texstudio2023卸载与安装(详细全程)
早在两年前安装了texlive2020,最近重新使用总是报错,好像是因为版本过低。我就找了个时间更新一下texlive版本,全程如下。 1、卸载texlive老版本 1)找到texlive目录,比如我的是D:\texlive\2022\tlpkg\installer&…...

塞浦路斯公司注册 塞浦路斯公司开户 塞浦路斯公司年审
一、为什么选择塞浦路斯 1、没有外汇管制; 2、注册公司无需验资实缴; 3、塞浦路斯公司分红没有税收; 4、塞浦路斯拥有欧洲蕞低的企业所得税,为净利润的 12.5%; 5、除某些特定业务要在经营前获得许可,基…...

XSS盲打练习(简单认识反射型、存储型XSS和cookie欺骗)
文章目录 挖掘cms网站XSS漏洞利用XSS平台盲打CMS,获取后台管理cookiecookie欺骗登录管理员账户 挖掘cms网站XSS漏洞 来到cms网站主页,发现有一个搜索框,输入任意内容后搜索,发现内容会回显,这里可能存在反射型XSS漏洞…...

Shell脚本:基础知识和使用指南
Shell脚本是一种用于自动化任务和进程的强大工具。它们允许你编写一系列的命令,这些命令可以在shell环境中执行,从而避免了手动输入每个命令的需要。Shell脚本对于减少重复的工作、提高效率以及构建复杂的自动化过程非常有用。 什么是Shell?…...
)
告别串口线!用STM32CubeMX配置USB-CDC虚拟串口,实现与电脑免驱动通信(附Win7驱动安装指南)
STM32虚拟串口革命:USB-CDC免驱动通信全实战指南 嵌入式开发调试过程中,最令人头疼的莫过于频繁插拔串口线导致的接口松动、接触不良问题。传统串口调试不仅占用宝贵的UART资源,还常常因为物理连接问题浪费大量调试时间。本文将彻底改变这一局…...

深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书
深部空间专属孪生,打造密闭硐室独有不可替代透明体系技术白皮书副标题:井下专用暗光算法实现三维实时重建,搭配地下专属无感定位、多盲区跨镜穿透追踪、身体指纹特征识别,场景适配独一无二,行业无同类对标方案前言矿山…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

Go语言缓存雪崩:防止缓存失效
Go语言缓存雪崩:防止缓存失效 1. 雪崩防护 type CacheWithProtection struct {cache *RedisCachemu sync.Mutexlocks map[string]*sync.Mutex }func NewCacheWithProtection(cache *RedisCache) *CacheWithProtection {return &CacheWithProtect…...
、连读规则注入与敬语语调开关(内测白名单已开放))
仅限菲律宾本地团队使用的ElevenLabs隐藏功能:Tagalog重音标记语法(`[ˈba.ka]`)、连读规则注入与敬语语调开关(内测白名单已开放)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs菲律宾文语音能力的本地化演进背景 菲律宾语(Filipino)作为以他加禄语(Tagalog)为基础的国家官方语言,拥有约1.05亿母语及第二语言…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

【仅限前200名】Midjourney铂金印相专属Prompt库泄露:含17组经暗房验证的--v 6.2参数矩阵与胶片光谱校准模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney铂金印相的光学本质与历史语境 铂金印相(Platinum Print)并非数字时代的产物,而是一种诞生于1873年的古典摄影工艺——其影像由铂族金属(主要是…...
架构与实现)
基于RAG与向量数据库的智能信息管理系统(IIMS)架构与实现
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的项目,叫“IIMS-By-AI”。乍一看这个标题,可能有点摸不着头脑,但拆解一下就能明白它的野心:IntelligentInformationManagementSystem, By AI。…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

3分钟快速上手:ESP32 Arduino开发环境完整配置指南
3分钟快速上手:ESP32 Arduino开发环境完整配置指南 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 想在熟悉的Arduino环境中开发强大的ESP32物联网项目吗&…...