Grounded Language-Image Pre-training论文笔记
| Title:Grounded Language-Image Pre-training |
| Code |
文章目录
- 1. 背景
- 2. 方法
- (1)Unified Formulation
- 传统目标检测
- grounding目标检测
- (2)Language-Aware Deep Fusion
- (3)Pre-training with Scalable Semantic-Rich Data
- 3. 实验
- (1)数据集简介
- (2)GLIP消融实验
- 参考
1. 背景
目前的视觉识别任务通常是在一个预先定义好的类别范围内进行的,这样限制了其在真实场景中的扩展。CLIP的出现打破了这一限制,CLIP利用image-text对进行训练,从而使得模型可以根据文字prompt识别任意类别。CLIP适用于分类任务,而GLIP尝试将这一技术应用于目标检测等更加复杂的任务中。
在本文中,作者提出了phrase grounding的概念,意思是让模型去学习图片和句子短语之间更加精细的联系。
GLIP的主要贡献如下:
- 将phrase grounding和目标检测任务统一,将image和text prompt同时输入到目标检测网络中,prompt中带有图片中所有类别的详细描述。
- GLIP采用了丰富的预训练数据,使得它的预训练模型可以更轻松地迁移到下游任务中。预训练的GLIP在COCO数据集上finetune之后达到了60.8 AP(2017val)和61.5AP(test-dev),超过了目前的SOTA模型。
- One model for all,GLIP可以迁移到多样化的任务中。它在不使用额外标注的情况下,在coco val2017和LVIS数据集上分别达到了49.8AP和26.9AP。
2. 方法

(1)Unified Formulation
传统目标检测
一个典型的目标检测网络的结构如下:
- 将图片输入到visual encoder E n c I Enc_I EncI 中提取特征 O O O,visual encoder通常是CNN、Transformer等backbone;
- 将特征 O O O 输入到classifier C C C 和bbox regressor R R R 中得到分类结果和bbox回归结果;
- 分别计算分类损失和框回归损失,整体Loss公式: L = L c l s + L l o c L=L_{cls}+L_{loc} L=Lcls+Lloc
上述计算分类Loss的流程可以用公式表达为:

其中 T T T 代表target; W W W 是分类器参数。
grounding目标检测
与上述分类器不同,GLIP将目标检测任务与phrash grounding统一,将目标检测中的每个region/bbox与text prompt进行匹配以实现分类效果。
举例来说,假设我们有[person, bicycle, car, ..., toothbrush]等类别,我们可以设计一个这样的prompt,其中每一个类别名字都是一个phrase:

grounding模型中的分类流程可以用公式表示为:

其中 P P P 是language encoder得到的文字特征, S g r o u n d S_{ground} Sground 的计算过程如下如图示:计算图像的region和prompt中的word之间的对齐分数:

然而,在计算对齐分数时,一个短语(phrase)可能包含多个word tokens,这就导致一个类别可能对应多个子单词(sub-words)。针对这个问题,本文是这样做的:当这些sub-words的phrase与目标region匹配时,每个positive sub-word都与目标region所匹配。**例如,吹风机的phrase是“Hair dryer”,那么吹风机的region就会与“Hair”和“dryer”这两个词都匹配,**如下图所示:

(2)Language-Aware Deep Fusion
在CLIP等算法中,image和text特征通常只在最后用于计算对比学习的loss,我们称这样的算法为late-fusion model。在本文中,作者在image和text特征之间引入了更深层次的融合(deep fusion),在最后几个encoder layer中进行了image和text的信息融合,如下图所示:

deep-fused encoder可以用以下公式来表示:

其中, X-MHA代表跨模态多头注意力模块(multi-head attention module),L代表DyHead中DyHeadModule的个数,BERTLayer是额外添加在预训练BERT模型之上的层, O 0 O^0 O0 是vision backbone提取的图像特征, P 0 P^0 P0 是language backbone提取的文字特征。
X-MHA是用于跨模态信息融合的关键模块 (cross attention) ,它的公式如下所示:

deep-fused有两个优点:
- 提升了phrase grounding的表现;
- 使得图像特征的学习与文字特征产生关联,从而让text prompt可以影响到检测模型的预测。
(3)Pre-training with Scalable Semantic-Rich Data
- 同时使用目标检测和grounding数据;
- 另外通过利用gold data训练教师GLIP,使用这个教师模型来预测24M web image-text数据,为image caption数据得到了检测伪标签;
- 也就是说,GLIP可以同时利用目标检测数据集,grounding数据集,image caption数据集,极大丰富了训练数据量;
3. 实验
(1)数据集简介

- COCO:目标检测数据集,包含80个常见对象类别;
- LVIS:目标检测和实例分割数据集,涵盖1203个对象类别;
- Object365:是一个大规模的目标检测数据集,总共包含63万张图像,覆盖365个类别,高达1000万框数;
Microsoft COCO Captions 数据集:该数据集为超过 33 万张图片提供了超过 150 万条人工生成的图片描述。- Flickr30k:给定了31783张图像以及158915个文本注释,一张图片对应5个注释,并将它们与 276K 个手动标注的边界框关联起来。
- Visual Genome(VG)是斯坦福大学李飞飞组于2016年发布的大规模图片语义理解数据集,数据集汇总最主要的构成是Region Description,每个region/bbox都有与其对应的一句自然语言描述。
- GQA数据集包含22,669,678个问题和113,018张图片,数据集中覆盖的词汇量有3,097个,答案类型有1,878个,同时也包含对应的bbox注释;
- Conceptual Captions (CC)是一个数据集,由约 330 万张带有字幕注释的图像组成。
- SBU Captions数据集最初将图像字幕作为一个检索任务,包含 100 万个图片网址 + 标题对。
最后使用的数据集有:
- FourODs (2.66M data): 4 detection datasets including Objects365, OpenImages, Visual Genome (excluding COCO images), and ImageNetBoxes
- GoldG (0.8M): human-annotated gold grounding data curated by
MDETR, including Flickr30K, VG Caption and GQA. - Cap4M / Cap24M
(2)GLIP消融实验
作者设计了多个版本的GLIP用于对比试验:
- GLIP-T(A):基于SoTA模型Dynamic Head,将其中的分类损失替换为GLIP的alignment loss,预训练数据为Objects365(66万人工标注数据);
- GLIP-T(B):在GLIP-T(A)的基础上加入deep fusion;
- GLIP-T©:在预训练数据中加入GoldG(80万人工标注数据);
- GLIP-T:加入更多数据:Cap4M(400万网上爬取的数据);
- GLIP-L:基于Swin-Large,并采用更大量的数据集,包含:FourODs(2.66M)、GoldG(0.8M)、Cap24M(24M);

由于 Objects365 覆盖了 COCO 中的所有类别,因此Objects365 预训练的 DyHead-T 在COCO上表现优异,达到了43.6AP; 若将模型重新构建为grounding模型,性能略有下降 (GLIP-T (A)); 添加深度融合将性能提升 2AP (GLIP-T (B)); GoldG数据对性能的提升贡献最大,GLIP-T © 达到 46.7 AP。 虽然添加图像-文本数据对 COCO 有轻微或没有改进(GLIP-T 与 GLIP-T ©),作者发现它对于推广到稀有种类至关重要,并在LVIS 实验中进一步展示了这一现象。
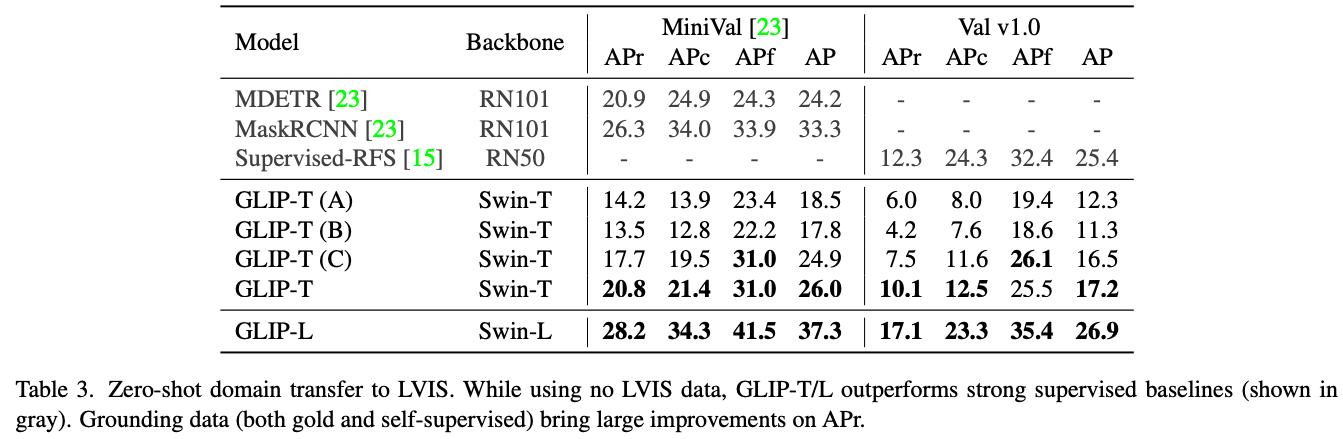
Gold grounding数据使 Mini-Val APr (GLIP-T© 与 GLIP-T (B)) 相比提高了 4.2 个点。这进一步表明grounding数据对性能的提升有显著的贡献。另外,添加图像-文本数据进一步提高了 3.1 个点的性能。因此,基础数据的语义丰富性可能有助于模型识别稀有物体。
参考
- 如何看待微软的Grounded Language-Image Pre-training(GLIP)?
相关文章:
Grounded Language-Image Pre-training论文笔记
Title:Grounded Language-Image Pre-training Code 文章目录 1. 背景2. 方法(1)Unified Formulation传统目标检测grounding目标检测 (2)Language-Aware Deep Fusion(3)Pre-training with Scala…...
成集云 | 钉钉财务费用单同步至畅捷通 | 解决方案
源系统成集云目标系统 方案介绍 财务管理作为企业管理中重要的组成部分,在企业的发展和成长中扮演着重要角色,成集云以钉钉费用单OA审批与畅捷通TCloud系统为例,与钉钉连接器深度融合,通过数据处理和字段匹配实现了费用…...

Redis——》死锁
推荐链接: 总结——》【Java】 总结——》【Mysql】 总结——》【Redis】 总结——》【Kafka】 总结——》【Spring】 总结——》【SpringBoot】 总结——》【MyBatis、MyBatis-Plus】 总结——》【Linux】 总结——》【MongoD…...

URL重定向漏洞
URL重定向漏洞 1. URL重定向1.1. 漏洞位置 2. URL重定向基础演示2.1. 查找漏洞2.1.1. 测试漏洞2.1.2. 加载完情况2.1.3. 验证漏洞2.1.4. 成功验证 2.2. 代码修改2.2.1. 用户端代码修改2.2.2. 攻击端代码修改 2.3. 利用思路2.3.1. 用户端2.3.1.1. 验证跳转 2.3.2. 攻击端2.3.2.1…...
JavaScript(函数,作用域和闭包)
目录 一,什么是函数1.1,常用系统函数1.2,函数声明 1.3,函数表达式二,预解析2.1,函数自调用 2.2,回调函数三,变量的作用域3.1,隐式全局变量 四,作用域与块级作…...
C# 实现 国密SM4/ECB/PKCS7Padding对称加密解密
C# 实现 国密SM4/ECB/PKCS7Padding对称加密解密,为了演示方便本问使用的是Visual Studio 2022 来构建代码的 1、新建项目,之后选择 项目 鼠标右键选择 管理NuGet程序包管理,输入 BouncyCastle 回车 添加BouncyCastle程序包 2、代码如下&am…...

【docker-compose】【nginx】动态配置
需求:部署前端镜像时需要动态修改nginx反向代理的后端服务的ip地址 原.conf配置调整,改为嵌入变量的文件模版Dockerfile 修改,通过envsubst将换将变量注入模版后再运行nginxdocker-compose配置,通过environment动态修改变量 defau…...
ExpressLRS开源之接收机固件编译烧录步骤
ExpressLRS开源之接收机固件编译烧录步骤 1. 源由2. 编译步骤2.1 推荐源代码指定方案2.2 方法一:ELRS Configurator步骤一:下载ELRS Configurator工具步骤二:安装ELRS Configurator工具步骤三:使用ELRS Configurator工具进行配置步…...

提取视频文件里的音频和无声视频
一、提取视频文件里的音频: public static void generateMediaRadio(){// 视频提取器MediaExtractor extractor new MediaExtractor();try {//本地视频文件extractor.setDataSource("/storage/emulated/0/mjyyfep/alpha.mp4");//网络视频文件 // …...

SpringBoot原理
一、Bean原理 1、配置文件的优先级 SpringBoot项目当中支持的三类配置文件: - application.properties - application.yml - application.yaml 配置文件优先级排名(从高到低): 1. properties配置文件 2. yml配置文件 3. yaml…...
MySQL事务原理、MVCC详解
事务原理 1 事务基础 1). 事务 事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系 统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。 2). 特性 原子性(Atomi…...

在Windows操作系统上安装Neo4j数据库
在Windows操作系统上安装Neo4j数据库 一、在Windows操作系统上安装Neo4j数据库 一、在Windows操作系统上安装Neo4j数据库 点击 MySQL可跳转至MySQL的官方下载地址。 在VUE3项目的工程目录中,通过以下命令可生成node_modules文件夹。 npm install(1&am…...

国民八路参考文献:[8]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑工业出版社,2022.
国民八路参考文献:[8]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑工业出版社,2022࿰…...

24 Linux高级篇-备份与恢复
24 Linux高级篇-备份与恢复 文章目录 24 Linux高级篇-备份与恢复24.1 安装dump和restore24.2 使用dump备份24.4 使用restore恢复 学习视频来自于B站【小白入门 通俗易懂】2021韩顺平 一周学会Linux。可能会用到的资料有如下所示,下载链接见文末: 《鸟哥的…...

微信小程序的图书馆预约系统设计与实现
摘 要 近年来随着社会竞争压力的不断加剧,人们需要不断充实自己的学识来提升自己的竞争力,对于在校的大学生而言需要利用在校期间实现考研考编的内容,职场的上班族需要通过考取职业技能资格证书来实现升职加薪,各行各业的人们都在…...

《2023年网信人才培训-网络安全从业人员能力素养提升培训》第一期成功举办
随着网络强国和数字中国建设的步伐加快,建设规模宏大、结构合理、素质优良的人才队伍成为一项重要工作。知了汇智作为数字产教融合基地,通过与高校、企业等多方合作,建立了完整的网络安全人才培养生态链。凭借自身技术优势和丰富的产业资源&a…...

WebGpu VS WebGL
推荐:使用 NSDT场景编辑器 助你快速搭建3D应用场景 WEBGPU VS. WEBGL 粗略地概述一下WebGPU与WebGL的不同之处是很有用的。在不涉及太多复杂的技术细节的情况下,两者的整体设计大致如下: WebGL和OpenGL一样,涉及许多单独的函数调…...

HTML <tfoot> 标签
实例 带有 thead、tbody 以及 tfoot 元素的 HTML 表格: <table border="1"><thead><tr><th>Month</th><th>Savings</th></tr></thead><tfoot><tr><td>Sum</td><td>$180<…...

VScode的PHP远程调试模式Xdebug
目录 第一步、安装VScode中相应插件 remote-ssh的原理 ssh插件: PHP相关插件: 第二步、安装对应PHP版本的xdebug 查看PHP具体配置信息的phpinfo页面 1、首先,打开php编辑器,新建一个php文件,例如:inde…...

HTML5-2-链接
HTML使用标签 <a>来设置超文本链接。 超链接可以是一个字,一个词,或者一组词,也可以是一幅图像,您可以点击这些内容来跳转到新的文档或者当前文档中的某个部分。 默认情况下,链接将以以下形式出现在浏览器中&am…...

AI量化交易实战:从机器学习模型到加密货币对冲基金系统构建
1. 项目概述:一个面向加密货币的AI对冲基金框架最近几年,AI在量化交易领域的应用已经从实验室走向了实战,尤其是在波动性极高的加密货币市场。如果你对量化交易和机器学习感兴趣,并且想找一个能直接上手、结构清晰的实战项目来学习…...

ViewTurbo:基于响应式依赖追踪的前端渲染优化方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ViewTurbo。这名字听起来就带点“涡轮增压”的劲儿,事实上,它也确实是一个旨在为视图渲染“加速”的工具。简单来说,ViewTurbo 的核心目标,是解决在复杂前端…...

如何让Photoshop图层批量导出速度提升3倍?这个开源脚本做到了!
如何让Photoshop图层批量导出速度提升3倍?这个开源脚本做到了! 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ado…...

基于AW9523与CircuitPython的互动LED灯带硬件开发实践
1. 项目概述:一个会“动”的LED灯带如果你玩过嵌入式开发,尤其是用Adafruit的板子做点小玩意儿,那你肯定对“快速原型”这个词不陌生。CircuitPython的出现,让写代码控制硬件变得像在电脑上写脚本一样简单。但有时候,板…...

Node.js后端框架Hereetria:平衡灵活性与约定,构建现代化Web应用
1. 项目概述与核心价值 最近在折腾一个挺有意思的开源项目,叫“Hereetria”。这个名字听起来有点陌生,但如果你对构建现代化的、可扩展的Web应用后端架构感兴趣,那它绝对值得你花时间研究一下。简单来说,Hereetria是一个基于Node.…...

CircuitPython串口调试与REPL交互:嵌入式开发的效率倍增器
1. 项目概述:为什么串口交互是嵌入式开发的“生命线”如果你刚开始接触CircuitPython或者任何基于微控制器的嵌入式开发,可能会觉得写代码、上传、看结果这个过程有点“黑盒”。代码上传后,板子默默运行,除了闪烁的LED,…...

AI驱动Figma设计自动化:Claude插件实现自然语言到UI生成
1. 项目概述:当设计工具遇上AI助手最近在和一些资深UI/UX设计师朋友交流时,大家不约而同地提到了一个痛点:在Figma这类设计工具里,从概念到高保真原型的转化过程,依然充满了大量重复、机械的劳动。比如,我需…...
)
2026中级注册安全工程师全套备考资料|零基础直接上岸(讲义+视频+真题+押题)
很多备考注安的同学都踩过坑:资料杂乱、版本老旧、视频断断续续、考点找不到重点、整理资料耗费大量时间!为了帮大家省去筛选、找资源、整理笔记的时间,我全套整理好了2026最新中级注安备考大礼包,四科全覆盖、零基础可用、直接打…...

百度网盘Mac版破解插件:免费解锁SVIP高速下载的终极指南
百度网盘Mac版破解插件:免费解锁SVIP高速下载的终极指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘Mac版的龟速下载而烦…...
表面吸附模型的构建与可视化)
从DFT计算到论文插图:一条龙搞定Pt(111)表面吸附模型的构建与可视化
从DFT计算到论文插图:Pt(111)表面吸附模型的完整构建与可视化指南 在计算材料科学领域,构建精确的表面吸附模型是研究催化反应机理、表面化学过程的第一步。对于刚入门的研究者来说,如何快速构建一个符合物理实际的Pt(111)表面吸附模型&#…...