机器学习深度学习——NLP实战(自然语言推断——微调BERT实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——针对序列级和词元级应用微调BERT
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
NLP实战(自然语言推断——微调BERT实现)
- 引入
- 加载预训练的BERT
- 微调BERT的数据集
- 微调BERT
- 小结
引入
在之前,已经为SNLI数据集上的自然语言推断任务设计了一个基于注意力的结构,文章链接:
机器学习&&深度学习——NLP实战(自然语言推断——注意力机制实现)
现在,我们通过微调BERT来重新审视这项任务。正如上一节讨论的那样,自然语言推断是一个序列级别的文本对分类问题,而微调BERT只需要一个额外的基于多层感知机的架构,如下图所示:
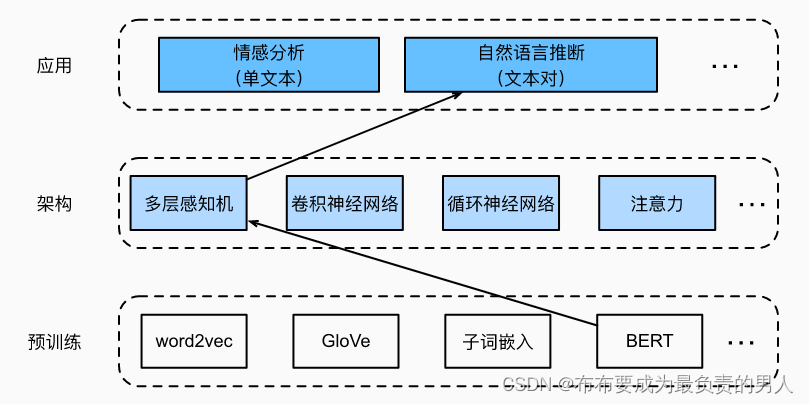
这边将下载一个已经预训练好的小版本BERT,然后对其进行微调,一遍在SNLI数据集上进行自然语言推断。
import json
import multiprocessing
import os
import torch
from torch import nn
from d2l import torch as d2l
加载预训练的BERT
原始的BERT模型有数以亿计的参数。在下面,我们提供了两个版本的预训练BERT:“bert.base”与原始BERT基础模型一样大,需要大量计算资源才能进行微调,而“bert.small”是一个小版本,以便于演示。
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip','225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip','c72329e68a732bef0452e4b96a1c341c8910f81f')
两个预训练好的BERT模型都包含一个定义词表的“vocab.json”文件和一个预训练参数的“pretrained.params”文件。我们实现了以下load_pretrained_model函数来加载预先训练好的BERT参数。
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,num_heads, num_layers, dropout, max_len, devices):data_dir = d2l.download_extract(pretrained_model)# 定义空词表以加载预定义词表vocab = d2l.Vocab()vocab.idx_to_token = json.load(open(os.path.join(data_dir,'vocab.json')))vocab.token_to_idx = {token: idx for idx, token in enumerate(vocab.idx_to_token)}bert = d2l.BERTModel(len(vocab), num_hiddens, norm_shape=[256],ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens,num_heads=4, num_layers=2, dropout=0.2,max_len=max_len, key_size=256, query_size=256,value_size=256, hid_in_features=256,mlm_in_features=256, nsp_in_features=256)# 加载预训练BERT参数bert.load_state_dict(torch.load(os.path.join(data_dir,'pretrained.params')))return bert, vocab
为了便于在大多数机器上演示,我们将在本节中加载和微调经过预训练BERT的小版本(“bert.small”)。在练习中,我们将展示如何微调大得多的“bert.base”以显著提高测试精度。
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model('bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,num_layers=2, dropout=0.1, max_len=512, devices=devices)
微调BERT的数据集
对于SNLI数据集的下游任务自然语言推断,我们定义了一个定制的数据集类SNLIBERTDataset。在每个样本中,前提和假设形成一对文本序列,并被打包成一个BERT输入序列。片段索引用于区分BERT输入序列中的前提和假设。利用预定义的BERT输入序列的最大长度(max_len),持续移除输入文本对中较长文本的最后一个标记,直到满足max_len。为了加速生成用于微调BERT的SNLI数据集,我们使用4个工作进程并行生成训练或测试样本。
class SNLIBERTDataset(torch.utils.data.Dataset):def __init__(self, dataset, max_len, vocab=None):all_premise_hypothesis_tokens = [[p_tokens, h_tokens] for p_tokens, h_tokens in zip(*[d2l.tokenize([s.lower() for s in sentences])for sentences in dataset[:2]])]self.labels = torch.tensor(dataset[2])self.vocab = vocabself.max_len = max_len(self.all_token_ids, self.all_segments,self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)print('read ' + str(len(self.all_token_ids)) + ' examples')def _preprocess(self, all_premise_hypothesis_tokens):pool = multiprocessing.Pool(4) # 使用4个进程out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)all_token_ids = [token_ids for token_ids, segments, valid_len in out]all_segments = [segments for token_ids, segments, valid_len in out]valid_lens = [valid_len for token_ids, segments, valid_len in out]return (torch.tensor(all_token_ids, dtype=torch.long),torch.tensor(all_segments, dtype=torch.long),torch.tensor(valid_lens))def _mp_worker(self, premise_hypothesis_tokens):p_tokens, h_tokens = premise_hypothesis_tokensself._truncate_pair_of_tokens(p_tokens, h_tokens)tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \* (self.max_len - len(tokens))segments = segments + [0] * (self.max_len - len(segments))valid_len = len(tokens)return token_ids, segments, valid_lendef _truncate_pair_of_tokens(self, p_tokens, h_tokens):# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置while len(p_tokens) + len(h_tokens) > self.max_len - 3:if len(p_tokens) > len(h_tokens):p_tokens.pop()else:h_tokens.pop()def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx]), self.labels[idx]def __len__(self):return len(self.all_token_ids)
读取完SNLI数据集后,我们通过实例化SNLIBERTDataset类来生成训练和测试样本。这些样本将在自然语言推断的训练和测试期间进行小批量读取。
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = "D:\Python\pytorch\data\snli_1.0\snli_1.0"
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,num_workers=num_workers)
微调BERT
用于自然语言推断的微调BERT只需要一个额外的多层感知机,该多层感知机由两个全连接层组成(下面代码的self.hidden和self.output)。这个多层感知机将特殊的“<cls>”词元的BERT表示进行了转换,该词元同时编码前提和假设的信息为自然语言推断的三个输出:蕴涵、矛盾和中性。
class BERTClassifier(nn.Module):def __init__(self, bert):super(BERTClassifier, self).__init__()self.encoder = bert.encoderself.hidden = bert.hiddenself.output = nn.Linear(256, 3)def forward(self, inputs):tokens_X, segments_X, valid_lens_x = inputsencoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)return self.output(self.hidden(encoded_X[:, 0, :]))
在下文中,预训练的BERT模型bert被送到用于下游应用的BERTClassifier实例net中。在BERT微调的常见实现中,只有额外的多层感知机(net.output)的输出层的参数将从零开始学习。预训练BERT编码器(net.encoder)和额外的多层感知机的隐藏层(net.hidden)的所有参数都将进行微调。
net = BERTClassifier(bert)
回想一下,在之前的文章:
机器学习&&深度学习——BERT(来自transformer的双向编码器表示)
其中,我们的MaskLM类和NextSentencePred类在其使用的多层感知机中都有一些参数。这些参数是预训练BERT模型bert中参数的一部分,因此是net中参数的一部分。然而,这些参数仅用于计算预训练过程中的遮蔽语言模型损失和下一句预测损失。这两个损失函数与微调下游应用无关,因此当BERT微调时,MaskLM和NextSentencePred中采用的多层感知机的参数不会更新(陈旧的,staled)。
为了允许具有陈旧梯度的参数,标志ignore_stale_grad=True在step函数d2l.train_batch_ch13中被设置。我们通过该函数使用SNLI的训练集(train_iter)和测试集(test_iter)对net模型进行训练和评估。
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
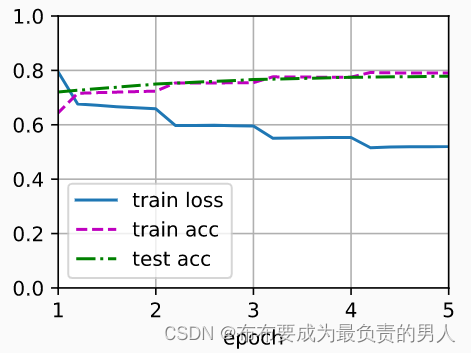
运行结果:
loss 0.520, train acc 0.790, test acc 0.779
446.5 examples/sec on [device(type=‘cpu’)]
运行图片:
如果计算资源允许,比如咱们去autodl平台上租借GPU以后,可以微调一个更大的预训练BERT模型,修改load_pretrained_model函数中的参数设置:将“bert.small”替换为“bert.base”,将num_hiddens=256、ffn_num_hiddens=512、num_heads=4和num_layers=2的值分别增加到768、3072、12和12。这样的测试精度应该是会高于0.86的。
小结
1、我们可以针对下游应用对预训练的BERT模型进行微调,例如在SNLI数据集上进行自然语言推断。
2、在微调过程中,BERT模型成为下游应用模型的一部分。仅与训练前损失相关的参数在微调期间不会更新。
相关文章:
机器学习深度学习——NLP实战(自然语言推断——微调BERT实现)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——针对序列级和词元级应用微调BERT 📚订阅专栏:机器学习&&深度学习 希望文…...
如何在windows下使用masm和link对汇编文件进行编译
前言 32位系统带有debug程序,可以进行汇编语言和exe的调试。但真正的汇编编程是“编辑汇编程序文件(.asm)->编译生成obj文件->链接生成exe文件”。下面,我就来说一下如何在windows下使用masm调试,使用link链接。 1、下载相应软件 下载…...

Golang字符串基本处理方法
Golang的字符串处理 字符串拼接 两种方法:strings.Join方法和’方法 package mainimport ("fmt""strings" )func main() {num : 20strs : make([]string, 0)for i : 0; i < num; i {strs append(strs, "fht")}//string.join拼…...
| 动态规划Part09:购买股票)
算法训练营第三十九天(8.30)| 动态规划Part09:购买股票
Leecode 123.买卖股票的最佳时机 III 123.买卖股票的最佳时机III 123.买卖股票的最佳时机III 题目地址:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目类型:股票问题 class Solution { public:int maxProfit(vector<…...

renren-fast-vue环境升级后,运行正常打包后,访问页面空白
网上各种环境,路径都找了一遍,也没成功。后来发现升级后打包的dist文件结构发生了变化, 1.最开始正常版本是这样 2.升级后是这样,少了日期文件夹 3.问题:打包后的index.html中引入的是config文件夹,而打…...
uniapp语法2)
Uniapp笔记(三)uniapp语法2
一、本节项目预备知识 1、组件生命周期 1.1、什么是生命周期 生命周期(Life Cycle)是指一个对象从创建-->运行-->销毁的整个阶段,强调的是一个时间段 我们可以把每个uniapp应用运行的过程,也概括为生命周期 小程序的启动,表示生命周…...
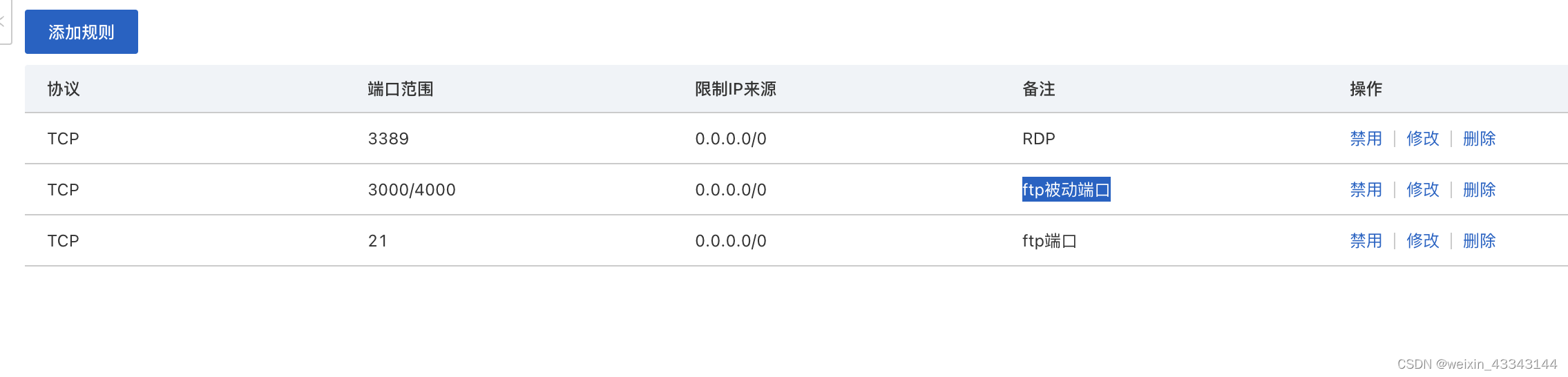
windows【ftp-FTP】添加配置流程【iis服务】
第一步:自己安装iis服务和ftp服务【自己百度搜索】 第二步:添加ftp站点【配置主动端口默认为21】 第三方配置:ftp被动端口【这里设置为3000-4000】请在防火墙开放此端口【如果是阿里云请在阿里云的后天也开通此端口】【护卫神一般使用55000…...

mysql视图的创建和选项配置详解
在 MySQL 中,可以使用 CREATE VIEW 语句来创建视图。基本的语法如下: CREATE[OR REPLACE][ALGORITHM {UNDEFINED | MERGE | TEMPTABLE}][DEFINER {user | CURRENT_USER}][SQL SECURITY { DEFINER | INVOKER }]VIEW view_name [(column_list)]AS selec…...

Python正则表达式中re.sub自定义替换方法正确使用方法
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 话不多说,直接开搞,如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 在使用正则替换时,有时候需要将匹配的结果做对应处理,便可以使用自定义替换方法。 re.sub的用法为&…...

hyperf 十五 验证器
官方文档:Hyperf 验证器报错需要配合多语言使用,创建配置自动生成对应的语言文件。 一 安装 composer require hyperf/validation:v2.2.33 composer require hyperf/translation:v2.2.33php bin/hyperf.php vendor:publish hyperf/translation php bi…...

ssh访问远程宿主机的VMWare中NAT模式下的虚拟机
1.虚拟机端配置 1.1设置虚拟机的网络为NAT模式 1.2设置虚拟网络端口映射(NAT) 点击主菜单的编辑-虚拟网络编辑器: 启动如下对话框,选中NAT模式的菜单项,并点击NAT设置: 点击添加,为我们的虚拟机添加一个端口映射。…...
【一等奖方案】大规模金融图数据中异常风险行为模式挖掘赛题「NUFE」解题思路
第十届CCF大数据与计算智能大赛(2022 CCF BDCI)已圆满结束,大赛官方竞赛平台DataFountain(简称DF平台)正在陆续释出各赛题获奖队伍的方案思路,欢迎广大数据科学家交流讨论。 本方案为【大规模金融图数据中…...

npm install 报错
npm install 报错 npm install 报错 npm ERR! code ERESOLVE npm ERR! ERESOLVE unable to resolve dependency tree npm ERR! npm ERR! While resolving: yudao-ui-admin1.8.0-snapshot npm ERR! Found: eslint7.15.0 npm ERR! node_modules/eslint npm ERR! dev eslint&q…...

专业人士使用的3个好用的ChatGPT提示
AI正在席卷世界。从自动化各个领域的任务到几秒钟内协助我们的日常生活,它有着了公众还未理解的巨大价值……除非你是专业人士。 专业人士一般都使用什么提示以及如何使用的?这里是经验丰富的懂ChatGPT的专业人士才知道的3个提示。好用请复制收藏。 为…...

doris系列2: doris分析英国房产数据集
1.准备数据 2.doris建表 CREATE TABLE `uk_price_paid` (`id` varchar(50) NOT NULL,`price` int(20),`date` date...

精准运营,智能决策!解锁天翼物联水利水务感知云
面向智慧水利/水务数字化转型需求,天翼物联基于感知云平台创新能力,提供涵盖水利水务泛协议接入、感知云水利/水务平台、水利/水务感知数据治理、数据看板在内的水利水务感知云服务,构建水利水务感知神经系统新型数字化底座,实现智…...

CleanMyMac最新版4.14Mac清理软件下载安装使用教程
苹果电脑是很多人喜欢使用的一种电脑,它有着优美的外观,流畅的操作系统,丰富的应用程序和高效的性能。但是,随着时间的推移,苹果电脑也会产生一些不必要的文件和数据,这些文件和数据就是我们常说的垃圾。那…...

String.Format方法详解
在Java中,String.format() 方法可以用于将格式化的字符串写入输出字符串中。该方法将根据指定的格式字符串生成一个新的字符串,并使用可选的参数填充格式字符串中的占位符。以下是有关 String.format() 方法的更详细信息: 语法 public stati…...

【Mysql】关联查询1对多处理
关联查询1对多返回 遇见的问题 审批主表,和审批明细表,一张审批对应多张明细数据,每条明细数据的状态是不一样的,现在需要根据明细的状态获取到主单子的状态,状态返回矩阵如下 明细状态返回总状态都是已完成已完成都…...

vue 入门案例模版
vue 入门案例1 01.html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> &l…...

【K8s】解惑:K8s 与 Docker 的关系
目录 引言:一个绕不开的问题 一句话说清K8s与Docker的关系 澄清三个误解 从命令的角度,直观对比 引言:一个绕不开的问题 在学习云原生技术的路上,几乎每个人都会遇到这样一个困惑: “有了 Kubernetes(…...

全志T113-i平台UB37三模无线模组驱动移植与调试实战
1. 项目概述:当国产工业芯遇上新一代无线技术最近在做一个挺有意思的项目,客户想在一块国产的工业级核心板上,集成最新的星闪(NearLink)无线通信功能。核心板用的是全志的T113-i,无线模组是支持Wi-Fi 6、蓝…...

【专利视点】某抗病毒药物领域明星企业上市进程知产问题分析
医药领域IPO,正在随着证券市场监管新形势而发生变化,并从CXO板块向更多细分赛道延伸。知识产权问题是影响企业IPO上市的重要因素之一。从上海证券交易所官网统计得知,截至2024年10月14日,有102家医药制造业企业终止科创板IPO申请&…...

【软考高级架构】论文预测——论基于ATAM的架构评估方法
论基于ATAM的架构评估方法 摘要 软件架构评估是保障系统质量属性满足业务目标的关键环节。架构权衡分析方法(Architecture Trade-off Analysis Method,ATAM)作为一种系统化的架构评估方法,通过场景捕获、质量属性分析、敏感点与权衡点识别、风险与非风险决策分类等结构化…...

抖音无水印下载器:高效保存高清视频与图集的完整解决方案
抖音无水印下载器:高效保存高清视频与图集的完整解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Octree-GS终极指南:如何用LOD结构化3D高斯实现实时大规模场景渲染
Octree-GS终极指南:如何用LOD结构化3D高斯实现实时大规模场景渲染 【免费下载链接】Octree-GS [TPAMI 2025] Octree-GS: Towards Consistent Real-time Rendering with LOD-Structured 3D Gaussians 项目地址: https://gitcode.com/GitHub_Trending/oc/Octree-GS …...
】)
【项目实训(个人8)】
继续进行法律文书智能摘要系统的开发,新增了几个功能,并优化了用户体验概述本次开发为法律文书智能摘要系统新增了两项核心功能。其一是摘要版本管理,支持同一文档的多版本摘要生成、存储、对比和回滚。用户在生成摘要时,系统自动…...

蒙古语TTS准确率仅73%?ElevenLabs 2024Q2基准测试报告曝光:词级准确率91.4%,但需绕过这2个API默认参数坑
更多请点击: https://codechina.net 第一章:蒙古语TTS准确率争议的真相还原 近年来,多款商用及开源蒙古语文本转语音(TTS)系统在公开评测中报告了92%–97%的词级准确率,但一线教育机构与本地化团队反馈的实…...

TMS320VC5502PGF300:TI TMS320C55x系列定点DSP,300MHz,176-LQFP封装
TMS320VC5502PGF300:C55x低功耗DSP的300MHz经典音频处理方案在语音识别、音频编解码和通信基带处理等实时信号处理应用中,处理器的能效比(单位功耗下的算力)往往是系统设计的核心约束。高性能处理器虽然算力强劲,但较高…...

告别小屏幕!5个专业技巧让你在Windows大屏上高效刷酷安
告别小屏幕!5个专业技巧让你在Windows大屏上高效刷酷安 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在忍受手机小屏幕刷酷安的酸涩感吗?想象一下,…...