Python 操作 Redis 数据库介绍
Redis 作为常用的 NoSql 数据库,主要用于缓存数据,提高数据读取效率,那在 Python 中应该如果连接和操作 Redis 呢?今天就为大概简单介绍下,在 Python 中操作 Redis 常用命令。
安装 redis
首先还是需要先安装 redis 模块,使用如下命令:
$ pip3 install redis创建 redis 连接池
安装成功后就可以在代码中导入模块,然后通过创建连接池的方式,连接到 Redis 服务器,创建代码如下:
import redis #导入redis模块# 建议使用以下连接池的方式# 设置decode_responses=True,写入的KV对中的V为string类型,不加则写入的为字节类型。pool = redis.ConnectionPool(host='127.0.0.1', port=6379, db=0, decode_responses=True)rs = redis.Redis(connection_pool=pool)
需要注意的是,设置
decode_responses=True,写入的 Key/Value 对中的 Value 为 string 类型,不加则写入的为字节类型。
Redis 操作方法
Redis 支持五种类型的数据操作,分别为字符串、 List、 Hash、 Set、 zSet类型,还有一些方法是不区分类型操作的。上面我们已经连接到 Redis 服务器,接下来为大家介绍各类型基本的操作方法。
字符串类型方法
-
单键值操作
set(name, value, ex=None, px=None, nx=False, xx=False)
参数说明:
ex:过期时间(秒)
px:过期时间(毫秒)
nx:如果设置为True,则只有name不存在时,当前set操作才执行
xx:如果设置为True,则只有name存在时,当前set操作才执行
使用方法如下:
# key="color",value="red",设置过期时间5秒rs.set('color', 'red', ex=5# 与rs.set('color', 'red', ex=5)相同rs.setex('color', 5, 'red')# 打印获取color键对应的值,超时后获取值为Noneprint(rs.get('color'))# 如果color存在输出None,如果不存在,则输出Trueprint(rs.set('color', 'green', nx=True))# 如果color存在输出True,如果不存在,则输出Noneprint(rs.set('color', 'yellow', xx=True))
-
批量键值操作
可以批量对多个 key 赋值,也可以同时获取多个 key 的值,使用方法如下:
# 批量赋值rs.mset({'key1':'value1', 'key2':'value2', 'key3':'value3'})# 批量获取值rs.mget('key1', 'key2', 'key3')
-
其他操作
除了基础的赋值和取值,可以在赋新值时返回旧值,还可将返回值通过索引来截取,也可以在 key 对应值后追回值等,具体使用可见以下代码:
# 设置新值为blue,同时返回设置前的值print(rs.getset('color', 'blue'))rs.set('lang', 'Chinese')# 取索引为1-3字符print(rs.getrange('lang', 1, 3)) #返回结果:hin# 从索引号为4字符开始向后替换rs.setrange('lang', 4, 'a is great') #返回结果:14# 在lang对应值后面追加字符 "!"rs.append('lang', '!') #返回结果:15print(rs.get('lang')) #返回结果:China is great!# 返回lang对应值的长度print(rs.strlen('lang')) #返回结果:15# 如果total对应值不存在,则total当前值设置为10rs.incr('total', amount=10)# 当前total对应值增加1rs.incr('total') #结果为11# 当前total对应值减少1rs.decr('total') #结果为10
list 类型方法
list 的特点:一个有序的列表,列表中的元素可以重复,并且可以在列表前后或中间任意位置插入新元素,具体使用方式见如下代码:
# 每个新增元素都插入到list最左边,如果list不存在则会新建rs.lpush('leftList', 1,2,3,4,5)print(rs.lrange('leftList', 0, -1)) #返回结果:['5', '4', '3', '2', '1']# 新插入元素在右侧,如果list不存在则新建rs.rpush('rightList', 6,7,8,9,10)print(rs.lrange('rightList', 0, -1)) #返回结果:['6', '7', '8', '9', '10']# 在list左边新增元素,如果list不存在则不创建rs.lpushx('noList', 'apple')print(rs.llen('noList')) #返回结果:0# 在list中从左遍历出第一个为'7'的元素,在它后面(如果是在前面插入则用'before')插入元素'08'rs.linsert('rightList', 'after', '7', '08')print(rs.lrange('rightList', 0, -1)) #返回结果:['6', '7', '08', '8', '9', '10']# 将list中索引号为1的元素修改为'-7'rs.lset('rightList', 1, '-7')print(rs.lrange('rightList', 0, -1)) #返回结果:['6', '-7', '08', '8', '9', '10']# 删除list中从左遍历第一个为'8'的元素rs.lrem('rightList', '8', 1)print(rs.lrange('rightList', 0, -1)) #返回结果:['6', '-7', '08', '9', '10']# 弹出左侧第一个元素rs.lpop('rightList') #返回值为:'6'print(rs.lrange('rightList', 0, -1)) #返回结果:['-7', '08', '9', '10']#取出list中索引编号为1的值print(rs.lindex('rightList', 1)) #返回结果:08
hash 类型方法
hash 的特点:一个 key 对应一个 value,并且 key 不允许重复,可以单个操作,也可以批量键值操作,下面列举了常用方法的使用方法:
# 单键值操作# 设置hash名为hName的键和值rs.hset('hName', 'key1', 'value1')rs.hset('hName', 'key2', 'value2')# 取hName的key1对应的值print(rs.hget('hName', 'key1')) #返回结果:value1#批量键值操作rs.hmset('hName', {'key3': 'value3', 'key5': 'value5'})print(rs.hmget('hName', 'key1', 'key2', 'key3')) #返回结果:['value1', 'value2', 'value3']# 取出hName所有键值print(rs.hgetall('hName')) #返回结果:{'key1': 'value1', 'key2': 'value2', 'key3': 'value3', 'key5': 'value5'}# 取hName中所有的keysprint(rs.hkeys('hName')) #返回结果:['key1', 'key2', 'key3', 'key5']# 取hName中所有的valuesprint(rs.hvals('hName')) #返回结果:['value1', 'value2', 'value3', 'value5']# 获取hName对应hash键值对个数print(rs.hlen('hName')) #返回结果:4# 判断key2是否存在print(rs.hexists('hName', 'key2')) #返回结果:True# 删除key2对应键值对rs.hdel('hName', 'key2')# 再次判断key2是否存在print(rs.hexists('hName', 'key2')) #返回结果:False
set 类型方法
set 的特点:一个无序的元素集合,集合中元素不能重复,可以随机 pop 元素,两个集合可以取交集,并集,差集运算。
# 增加集合元素,如集合不存在则新建rs.sadd('mySet', 'one', 'two', 3)# 返回集合元素个数print(rs.scard('mySet'))# 返回所有元素print(rs.smembers('mySet')) #结果:{'two', 'one', '3'}# 返回所有成员print(rs.sscan('mySet')) #结果:(0, ['3', 'one', 'two'])# 再次创建一个集合mySet2rs.sadd('mySet2', 3, 5, 7)# 获取两个集合交集print(rs.sinter('mySet', 'mySet2')) #返回结果:{'3'}# 获取两个集合并集print(rs.sunion('mySet', 'mySet2')) #返回结果:{'5', 'two', 'one', '7', '3'}# 获取两个集合差集print(rs.sdiff('mySet', 'mySet2')) #返回结果:{'two', 'one'# 取mySet和mySet2的并集,将结果存到storeSet集合中print(rs.sunionstore('sotreSet', 'mySet', 'mySet2'))print(rs.smembers('sotreSet')) #返回结果:{'5', 'two', 'one', '7', '3'}# 判断one元素是否存在集合中print(rs.sismember('sotreSet', 'one'))# 随机删除并返回集合中的一个元素print(rs.spop('sotreSet'))# 删除集合中元素值为5的元素print(rs.srem('sotreSet', 5))
zset 类型方法
zset 的特点:一个不允许重复的集合,集合中元素是有序的,每个元素有两个值:值和分数,分数专门用来做排序。
# 增加集合元素,如集合不存在则新建rs.zadd('fruits', {'apple':1, 'banana':3, 'orange':5})# 遍历所有元素print(rs.zrange("fruits", 0, -1)) #结果:['apple', 'banana', 'orange']# withscores=True指带上分数print(rs.zrange("fruits", 0, -1, withscores=True)) #结果:[('apple', 1.0), ('banana', 3.0), ('orange', 5.0)]# 根据分数由大到小遍历所有元素print(rs.zrevrange("fruits", 0, -1)) #结果:['orange', 'banana', 'apple']# 获取orange元素对应的分数rs.zscore('fruits', 'orange') #结果:5.0# 取出分数>=3 and 分数<=5的元素print(rs.zrangebyscore('fruits', 3, 5))# 取出分数<=5 and 分数>=3的元素,根据分数从大到小排序print(rs.zrevrangebyscore('fruits', 5, 3))# 遍历所有元素,返回一个元组print(rs.zscan('fruits')) #结果:(0, [('apple', 1.0), ('banana', 3.0), ('orange', 5.0)])# 打印集合元素个数print(rs.zcard('fruits')) #结果:3# 返回集合中分数>=1 and 分数<=3元素个数print(rs.zcount('fruits', 1, 3))# 将集合中apple元素的分数+5rs.zincrby('fruits', 5, 'apple')print(rs.zrange("fruits", 0, -1, withscores=True)) #返回结果:[('banana', 3.0), ('orange', 5.0), ('apple', 6.0)]# 返回orange元素在集合中的索引号rs.zrank('fruits', 'orange') #结果:1# 按分数从大到小排序,取出banana元素索引号rs.zrevrank('fruits', 'banana') #结果:2# #删除集合中apple元素rs.zrem('fruits', 'apple')print(rs.zrange("fruits", 0, -1)) #返回结果:['banana', 'orange']# #删除集合索引号>=0 and 索引号<=2的元素rs.zremrangebyrank('fruits', 0, 2)# 删除集合分数>=1 and 分数<=5的元素rs.zremrangebyscore('fruits', 1, 5)
其他操作方法
以下操作方法针对 redis 任意数据类型(字符串,list,hash,set,zset),可以删除 key ,查询 key 是否存在,还可设置超时,重命名 key 的名称等:
# 删除key为color的对象rs.delete('color')# 查询key为color的对象是否存在print(rs.exists('color')) #结果:Falsers.sadd('mySet5', 'one', 'two')# 设置key的超时时间rs.expire('mySet5', time=5) #单位:秒# 重命名key的值rs.rename('mySet5', 'set5')# 随机返回当前库中一个key,但不会删除print(rs.randomkey())# 查看某个key对应值的类型print(rs.type('mySet')) #返回结果:set# 通过模糊匹配出满足条件的keyprint(rs.keys('my*')) #返回结果:['mySet', 'mySet2']#各类型元素迭代方式#hash类型迭代for i in rs.hscan_iter("hName"):print(i)#set类型迭代for j in rs.sscan_iter("mySet"):print(j)#zset类型迭代for k in rs.zscan_iter("fruits"):print(k)
总结
本文为大家介绍了 Python 中如何创建连接 Redis 数据库,并通过代码的方式展示了 Redis 支持的各数据类型的操作方法,通过学习发现操作起来还是很方便的,接下来还会为大家介绍其他数据库的操作。
相关文章:

Python 操作 Redis 数据库介绍
Redis 作为常用的 NoSql 数据库,主要用于缓存数据,提高数据读取效率,那在 Python 中应该如果连接和操作 Redis 呢?今天就为大概简单介绍下,在 Python 中操作 Redis 常用命令。 安装 redis 首先还是需要先安装 redis …...

十年JAVA搬砖路——软件工程概述
软件工程是一门关注软件开发过程的学科,它涉及到软件的设计、开发、测试、部署和维护等方面。软件工程的目标是通过系统化的方法和工具,以确保软件项目能够按时、按预算和按要求完成。 • 软件工程的7个基本概念: 软件生命周期:软…...
前后端项目部署上线详细笔记
部署 参考文章:如何部署网站?来比比谁的方法多 - 哔哩哔哩大家好,我是鱼皮,不知道朋友们有没有试着部署过自己开发的网站呢?其实部署网站非常简单,而且有非常多的花样。这篇文章就给大家分享几种主流的前端…...
Android 蓝牙开发( 二 )
前言 上一篇文章给大家分享了Android蓝牙的基础知识和基础用法,不过上一篇都是一些零散碎片化的程序,这一篇给大家分享Android蓝牙开发实战项目的初步使用 效果演示 : Android蓝牙搜索,配对,连接,通信 Android蓝牙实…...
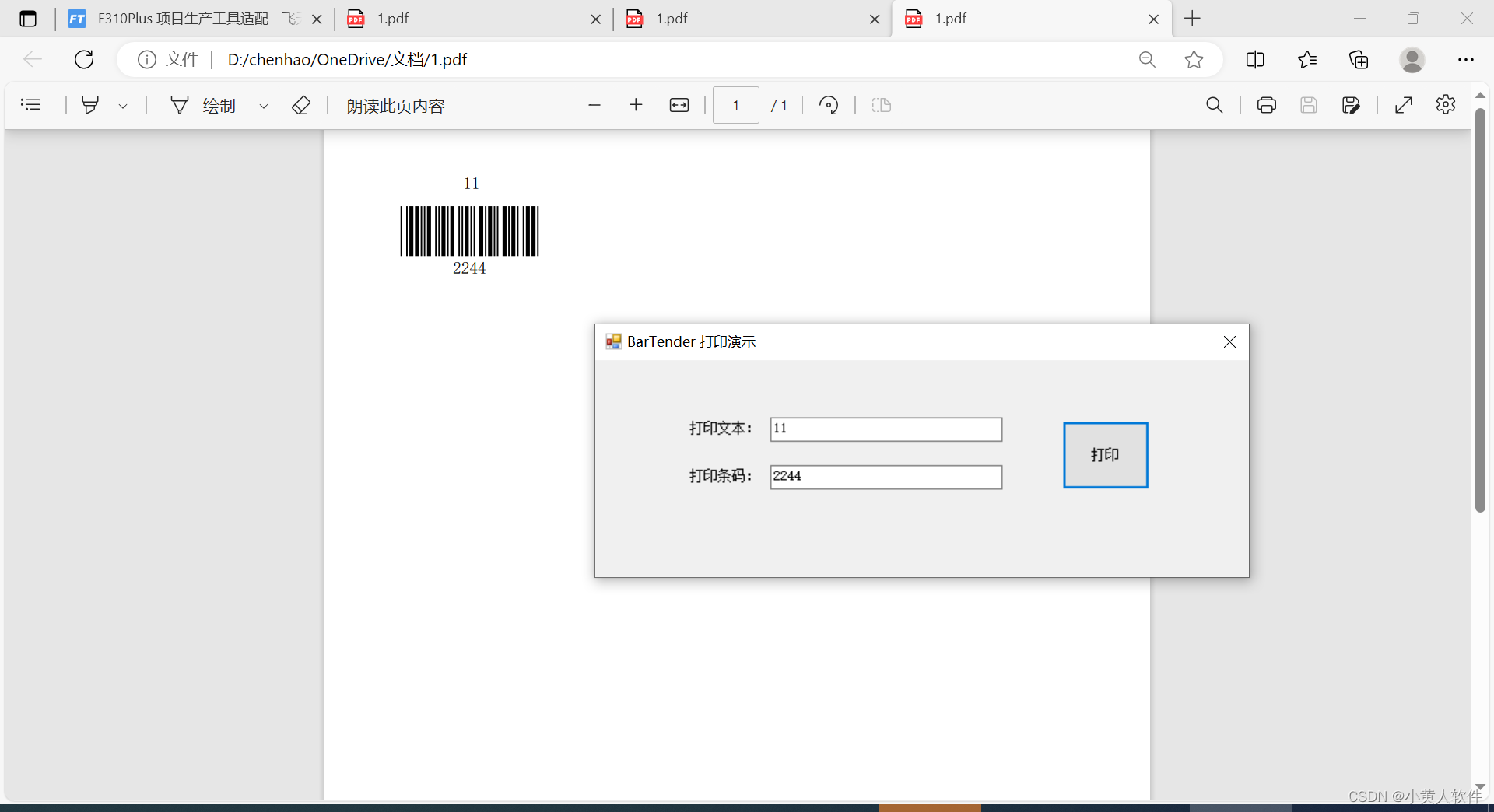
C#调用barTender打印标签示例
使用的电脑需要先安装BarTender 我封装成一个类 using System; using System.Windows.Forms;namespace FT_Tools {public class SysContext{public static BarTender.Application btapp new BarTender.Application();public static BarTender.Format btFormat;public void Q…...
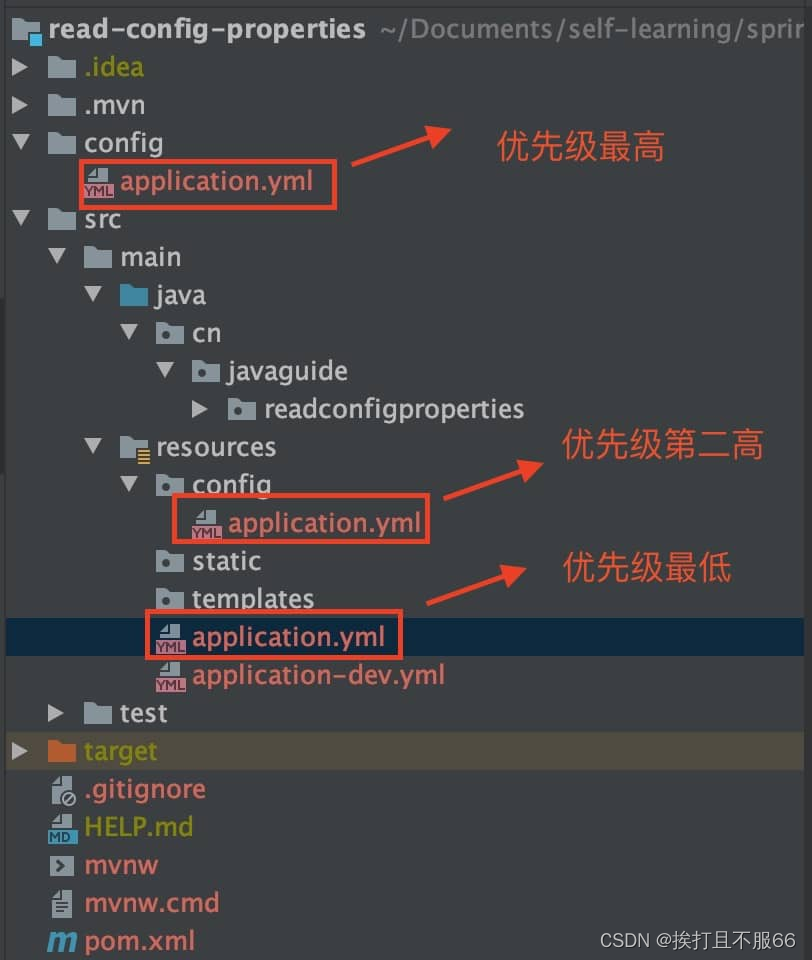
Spring——Spring读取文件
文章目录 1.通过 value 读取比较简单的配置信息2.通过ConfigurationProperties读取并与 bean 绑定3.通过ConfigurationProperties读取并校验4. PropertySource 读取指定 properties 文件5.题外话:Spring加载配置文件的优先级 很多时候我们需要将一些常用的配置信息比如阿里云os…...

这是一条求助贴(postman测试的时候一直是404)
看到这个问题是404的时候总感觉不该求助大家,404多常见一看就是简单的路径问题,我的好像不是,我把我的问题奉上。 首先我先给出我的url http://10.3.22.195:8080/escloud/rest/escloud_contentws/permissionStatistics/jc-haojl/sz 这是我…...
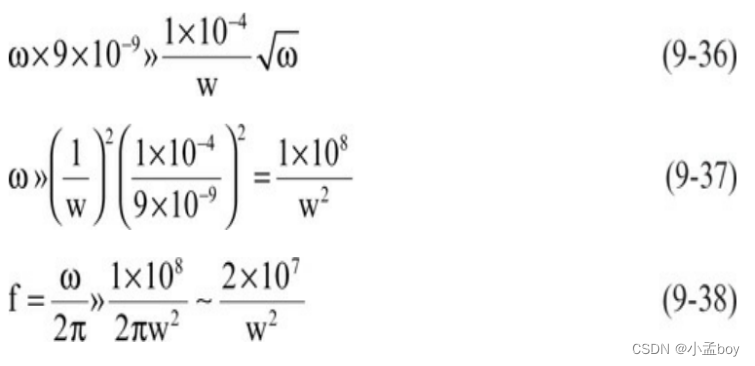
信号完整性分析基础知识之有损传输线、上升时间衰减和材料特性(四):有损传输线建模
传输线中信号衰减的两个损耗过程是通过信号和返回路径导体的串联电阻以及通过有损耗介电材料的分流电阻。这两个电阻器的电阻都与频率相关。 值得注意的是,理想电阻器的电阻随频率恒定。我们已经证明,在理想的有损传输线中,用于描述损耗的两个…...
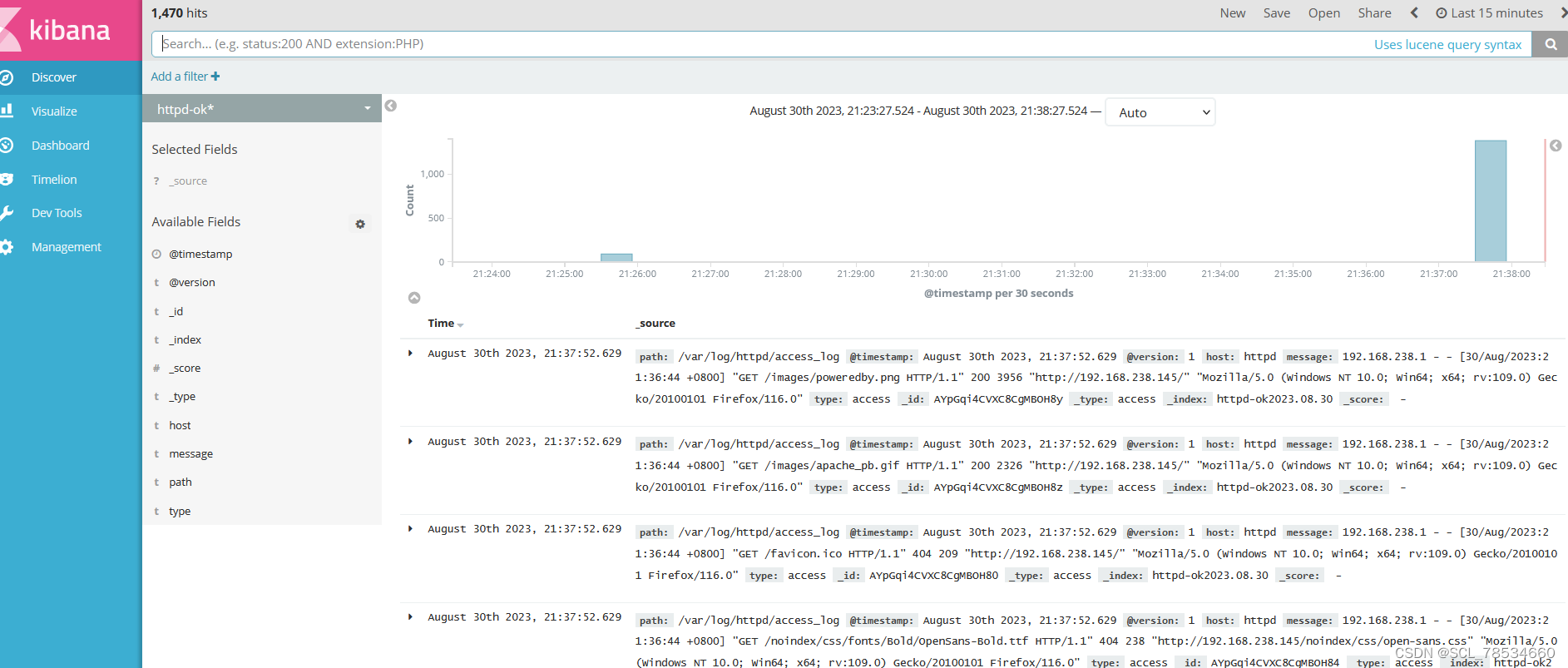
elk日志收集系统
目录 前言 一、概述 二、案例 (一)、环境配置 安装node1与node2节点的elasticsearch node1的elasticsearch-head插件 (二)、node1服务器安装logstash 测试1: 标准输入与输出 测试2:使用rubydebug解…...

perl 语言中 AUTOLOAD 的用法
这里的 AUTOLOAD可以理解为自动加载。具体来说就是,在正常情况下,我们不能调用一个尚未定义的函数(子例程)。不过,如果在未定义函数的包中有一个名为 AUTOLOAD的函数,那么对未定义函数的调用都会路由至这个…...
服务器放在香港好用吗?
相较于国内服务器,将网站托管在香港服务器上最直观的好处是备案层面上的。香港服务器上的网站无需备案,因此更无备案时限,购买之后即可使用。 带宽优势 香港服务器的带宽一般分为香港本地带宽和国际带宽、直连中国骨干网 CN2三种。香港…...

C++设计模式_01_设计模式简介(多态带来的便利;软件设计的目标:复用)
文章目录 本栏简介1. 什么是设计模式2. GOF 设计模式3. 从面向对象谈起4. 深入理解面向对象5. 软件设计固有的复杂性5.1 软件设计复杂性的根本原因5.2 如何解决复杂性 ? 6. 结构化 VS. 面向对象6.1 同一需求的分解写法6.1.1 Shape1.h6.1.2 MainForm1.cpp 6.2 同一需求的抽象的…...

Docker技术--WordPress博客系统部署初体验
如果使用的是传统的项目部署方式,你要部署WordPress博客系统,那么你需要装备一下的环境,才可以部署使用。 -1:操作系统linux -2:PHP5.6或者是更高版本环境 -3:MySQL数据环境 -4:Apache环境 但是如果使用Docker技术,那么就只需要进行如下的几行简单的指令: docker run …...

提高代码可读性和可维护性的命名建议
当进行接口自动化测试时,良好的命名可以提高代码的可读性和可维护性。以下是一些常用的命名建议: 变量和函数命名: 使用具有描述性的名称,清晰地表达变量或函数的用途和含义。使用小写字母和下划线来分隔单词,例如 log…...
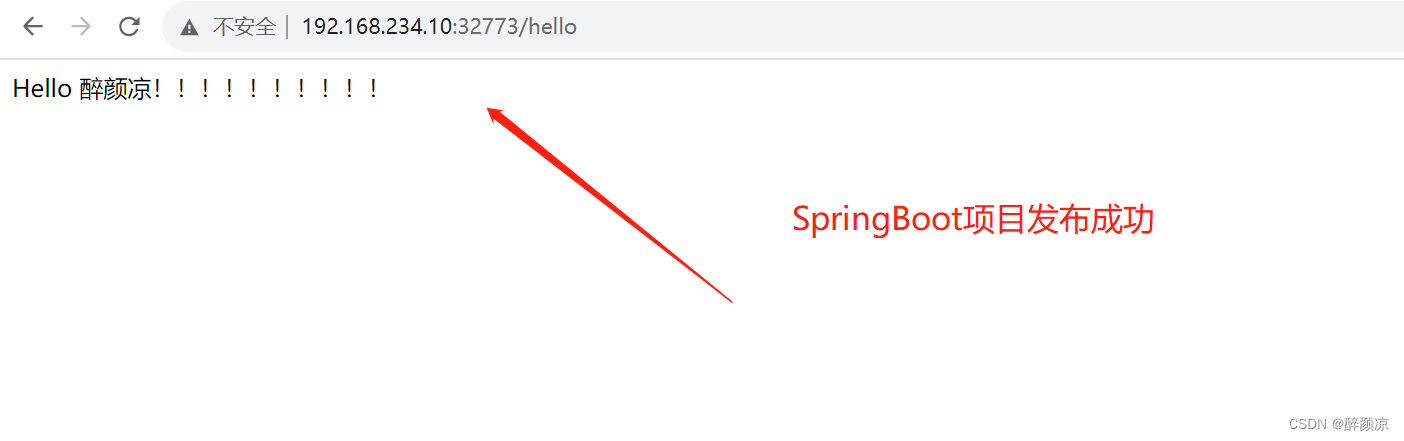
Docker基础入门:Docker网络与微服务项目发布
Docker基础入门:Docker网络与微服务项目发布 一、前言二、Docker0理解2.1 ip a查看当前网络环境2.2 实战--启动一个tomact01容器(查看网络环境)2.3 实战--启动一个tomact02容器(查看网络环境)2.4 容器与容器之间的通信…...
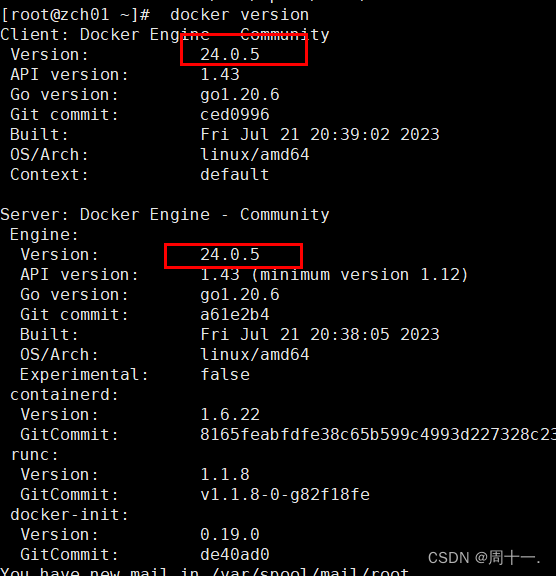
Docker安装详细步骤
Docker安装详细步骤 1、安装环境准备 主机:192.168.40.5 zch01 设置主机名 # hostnamectl set-hostname zch01 && bash 配置hosts文件 [root ~]# vi /etc/hosts 添加如下内容: 192.168.40.5 zch01 关闭防火墙 [rootzch01 ~]# systemct…...

十六、pikachu之SSRF
文章目录 1、SSRF概述2、SSRF(URL)3、SSRF(file_get_content) 1、SSRF概述 SSRF(Server-Side Request Forgery:服务器端请求伪造):其形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能&…...
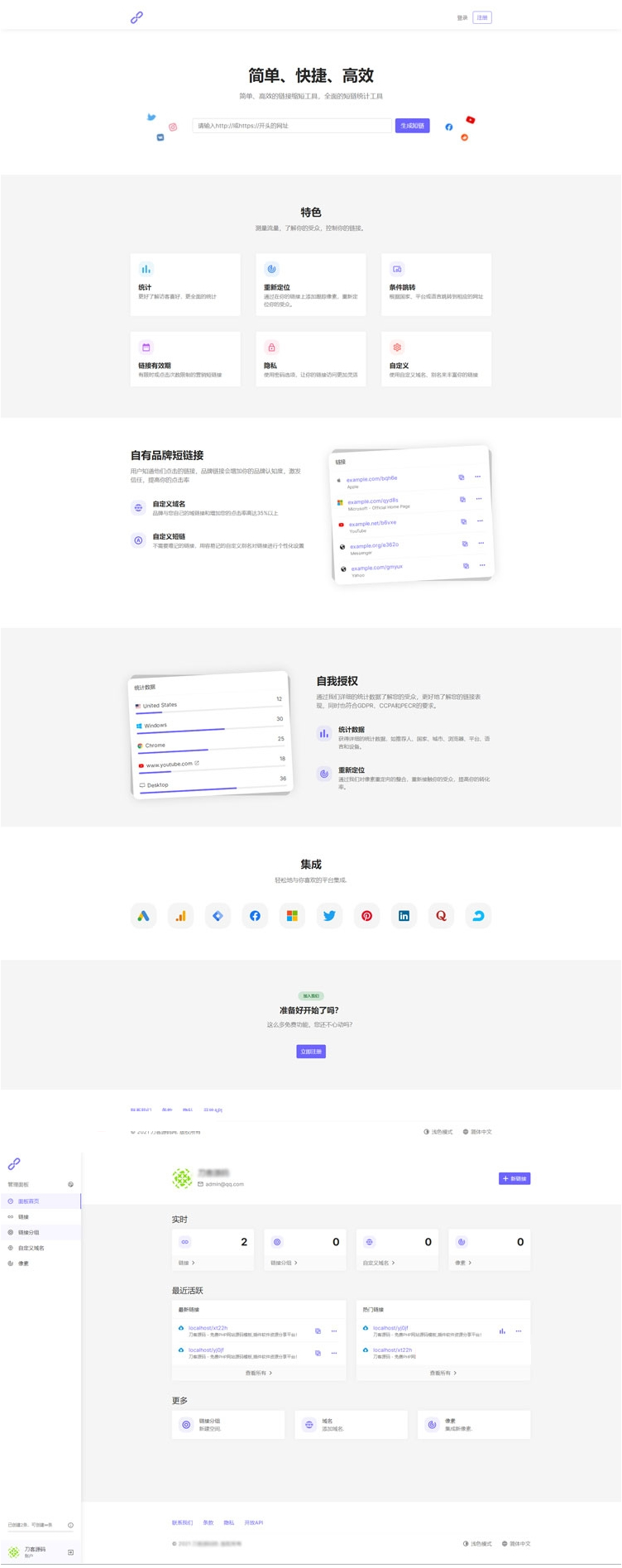
最新PHP短网址生成系统/短链接生成系统/URL缩短器系统源码
全新PHP短网址系统URL缩短器平台,它使您可以轻松地缩短链接,根据受众群体的位置或平台来定位受众,并为缩短的链接提供分析见解。 系统使用了Laravel框架编写,前后台双语言使用,可以设置多域名,还可以开设套…...

漱玉平民大药房:多元化药店变革的前夜
作者 | 王聪彬 编辑 | 舞春秋 来源 | 至顶网 本文介绍了漱玉平民大药房在药品零售领域的数字化转型和发展历程。通过技术创新, 漱玉平民 建设了覆盖医药全生命周期的大健康生态圈,采用混合云架构和国产分布式数据库 TiDB,应对庞大的会员数据处…...
如何实现AI的矢量数据库
推荐:使用 NSDT场景编辑器 助你快速搭建3D应用场景 然而,人工智能模型有点像美食厨师。他们可以创造奇迹,但他们需要优质的成分。人工智能模型在大多数输入上都做得很好,但如果它们以最优化的格式接收输入,它们就会真正…...

Crypto-JS WordArray 数据结构终极指南:深入解析加密算法的核心基石
Crypto-JS WordArray 数据结构终极指南:深入解析加密算法的核心基石 【免费下载链接】crypto-js JavaScript library of crypto standards. 项目地址: https://gitcode.com/gh_mirrors/cr/crypto-js 你是否曾在使用 Crypto-JS 进行加密操作时,困惑…...

GBase 8c存储过程调试接口使用指南
本文针对南大通用 GBase 8c 数据库,围绕存储过程的使用与问题定位,基于 DBE_PLDEBUGGER 调试接口,详细说明存储过程调试的核心接口、标准流程、常用命令与完整实战操作步骤,帮助用户快速掌握调试方法,高效定位与解决存…...

抖音直播弹幕实时采集:基于Golang的高性能解决方案
抖音直播弹幕实时采集:基于Golang的高性能解决方案 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作蓬勃发展的今天,实时获取抖音直播间的弹幕…...

如何实现快速排名?老站降权后恢复收录的4步挽救法
企业站点日常维护期间,可能遭遇搜索访问量大面积滑坡。周一早晨九点登录系统,常会看到令人震惊的数据:原先稳定排在搜索结果前十名的50个主商业名词,在一夜之间完全不见踪迹。管理控制台页面显示的单日整体曝光量从25000次骤然缩减…...

Taotoken API Key管理与访问控制功能在团队大赛中的协作应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key管理与访问控制功能在团队大赛中的协作应用 1. 场景概述:团队协作中的API资源管理需求 当团队共同参…...

机器人仿真创新方案:基于ROS的工业级虚拟测试平台
机器人仿真创新方案:基于ROS的工业级虚拟测试平台 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人技术快速发展的今天,硬件成本高昂、测试周期漫长、算法验证困难已成为制约机器人产业发…...

六自由度并联无人机自适应起降平台设计——从构型选型到运动学仿真全流程
六自由度并联无人机自适应起降平台设计——从构型选型到运动学仿真全流程 摘要 随着无人机物流配送、海上作业、灾害救援等场景的快速发展,无人机在动态环境下的安全起降成为制约其大规模应用的瓶颈问题。传统的固定起降平台无法适应舰船摇摆、车辆运动等动态条件,而串联机…...

深入浅出讲解Taotoken多模型聚合API在Python项目中的集成方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 深入浅出讲解Taotoken多模型聚合API在Python项目中的集成方法 对于正在探索大模型能力的Python开发者而言,直接对接多家…...

2025-2026年儿童护眼灯品牌推荐:TOP5评测口碑市场份额AI自动调光选择指南
摘要 在儿童青少年近视率持续攀升的今天,为孩子选择一盏真正懂得保护视力的学习灯,已成为众多家长的核心关切。然而,面对市场上琳琅满目的品牌与复杂的技术参数,家长们往往陷入“如何选、看什么、信谁”的决策困境。据世界卫生组织…...

Blender-Armatures
导航 (返回顶部) 1. Blender-Armatures 1.1 骨架位置1.2 分类1.3 骨骼结构 2. 编辑 2.1 骨骼扭转2.2 拆分 split2.3 分离骨骼 separate2.4 切换方向 3. 镜像编辑 3.1 镜像挤出3.2 命名惯例3.3 对称 4. 属性 4.1 属性结构表4.2 柔性骨骼 Bendy Bones4.3 姿态4.4 关系 5. 骨骼约束…...