高基数类别特征预处理:平均数编码 | 京东云技术团队
一 前言
对于一个类别特征,如果这个特征的取值非常多,则称它为高基数(high-cardinality)类别特征。在深度学习场景中,对于类别特征我们一般采用Embedding的方式,通过预训练或直接训练的方式将类别特征值编码成向量。在经典机器学习场景中,对于有序类别特征,我们可以使用LabelEncoder进行编码处理,对于低基数无序类别特征(在lightgbm中,默认取值个数小于等于4的类别特征),可以采用OneHotEncoder的方式进行编码,但是对于高基数无序类别特征,若直接采用OneHotEncoder的方式编码,在目前效果比较好的GBDT、Xgboost、lightgbm等树模型中,会出现特征稀疏性的问题,造成维度灾难, 若先对类别取值进行聚类分组,然后再进行OneHot编码,虽然可以降低特征的维度,但是聚类分组过程需要借助较强的业务经验知识。本文介绍一种针对高基数无序类别特征非常有效的预处理方法:平均数编码(Mean Encoding)。在很多数据挖掘类竞赛中,有许多人使用这种方法取得了非常优异的成绩。
二 原理
平均数编码,有些地方也称之为目标编码(Target Encoding),是一种基于目标变量统计(Target Statistics)的有监督编码方式。该方法基于贝叶斯思想,用先验概率和后验概率的加权平均值作为类别特征值的编码值,适用于分类和回归场景。平均数编码的公式如下所示:
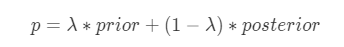
其中:
1. prior为先验概率,在分类场景中表示样本属于某一个_y__i_的概率
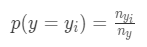
其中_n__y__i_表示y =_y__i_时的样本数量,_n__y_表示y的总数量;在回归场景下,先验概率为目标变量均值:

2. posterior为后验概率,在分类场景中表示类别特征为k时样本属于某一个_y__i_的概率
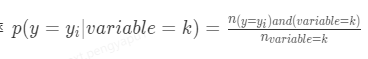
在回归场景下表示 类别特征为k时对应目标变量的均值。
3. _λ_为权重函数,本文中的权重函数公式相较于原论文做了变换,是一个单调递减函数,函数公式:
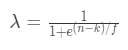
其中 输入是特征类别在训练集中出现的次数n,权重函数有两个参数:
① k:最小阈值,当n = k时,λ= 0.5,先验概率和后验概率的权重相同;当n < k时,λ> 0.5, 先验概率所占的权重更大。
② f:平滑因子,控制权重函数在拐点处的斜率,f越大,曲线坡度越缓。下面是k=1时,不同f对于权重函数的影响:
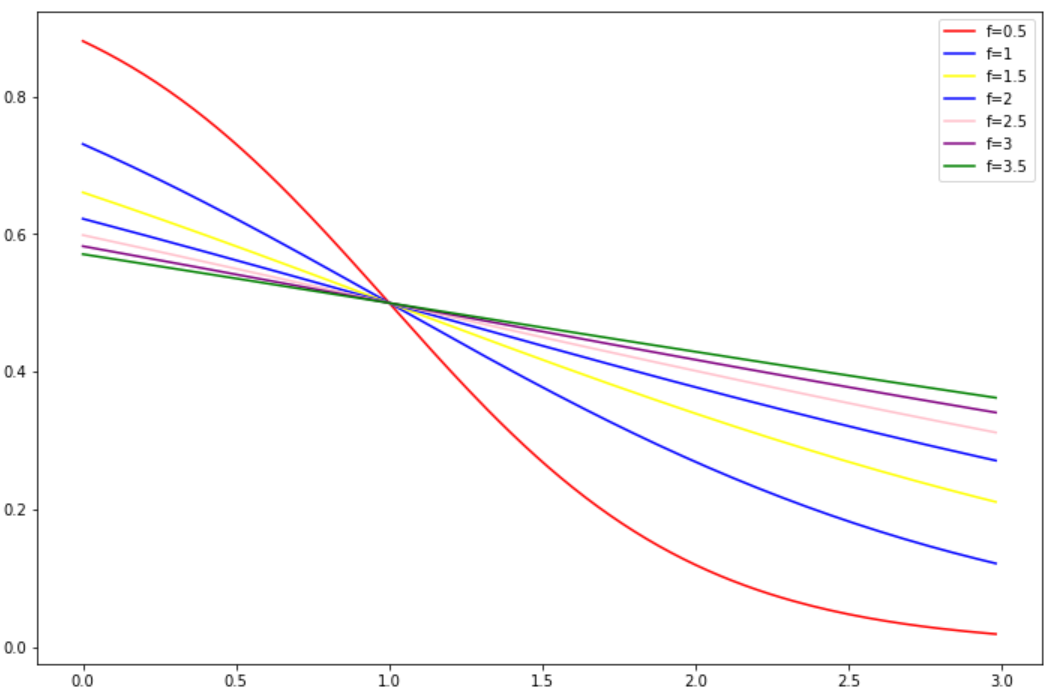
由图可知,f越大,权重函数S型曲线越缓,正则效应越强。
对于分类问题,在计算后验概率时,目标变量有C个类别,就有C个后验概率,且满足

一个 _y__i_ 的概率值必然和其他 _y__i_ 的概率值线性相关,因此为了避免多重共线性问题,采用平均数编码后数据集将增加C-1列特征。对于回归问题,采用平均数编码后数据集将增加1列特征。
三 实践
平均数编码不仅可以对单个类别特征编码,也可以对具有层次结构的类别特征进行编码。比如地区特征,国家包含了省,省包含了市,市包含了街区,对于街区特征,每个街区特征对应的样本数量很少,以至于每个街区特征的编码值接近于先验概率。平均数编码通过加入不同层次的先验概率信息解决该问题。下面将以分类问题对这两个场景进行展开:
1. 单个类别特征编码:

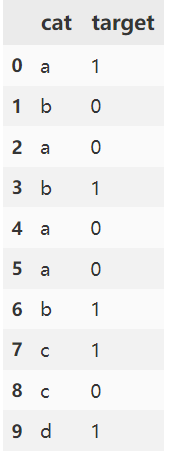
在具体实践时可以借助category_encoders包,代码如下:
import pandas as pd
from category_encoders import TargetEncoderdf = pd.DataFrame({'cat': ['a', 'b', 'a', 'b', 'a', 'a', 'b', 'c', 'c', 'd'], 'target': [1, 0, 0, 1, 0, 0, 1, 1, 0, 1]})
te = TargetEncoder(cols=["cat"], min_samples_leaf=2, smoothing=1)
df["cat_encode"] = te.transform(df)["cat"]
print(df)
# 结果如下:cat target cat_encode
0 a 1 0.279801
1 b 0 0.621843
2 a 0 0.279801
3 b 1 0.621843
4 a 0 0.279801
5 a 0 0.279801
6 b 1 0.621843
7 c 1 0.500000
8 c 0 0.500000
9 d 1 0.6344712. 层次结构类别特征编码:
对以下数据集,方位类别特征具有{‘N’: (‘N’, ‘NE’), ‘S’: (‘S’, ‘SE’), ‘W’: ‘W’}层级关系,以compass中类别NE为例计算_y__i_=1,k = 2 f = 2时编码值,计算公式如下:
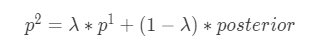
其中_p_1为HIER_compass_1中类别N的编码值,计算可以参考单个类别特征编码: 0.74527,posterior=3/3=1,λ= 0.37754 ,则类别NE的编码值:0.37754 * 0.74527 + (1 - 0.37754)* 1 = 0.90383。
代码如下:
from category_encoders import TargetEncoder
from category_encoders.datasets import load_compassX, y = load_compass()
# 层次参数hierarchy可以为字典或者dataframe
# 字典形式
hierarchical_map = {'compass': {'N': ('N', 'NE'), 'S': ('S', 'SE'), 'W': 'W'}}
te = TargetEncoder(verbose=2, hierarchy=hierarchical_map, cols=['compass'], smoothing=2, min_samples_leaf=2)
# dataframe形式,HIER_cols的层级顺序由顶向下
HIER_cols = ['HIER_compass_1']
te = TargetEncoder(verbose=2, hierarchy=X[HIER_cols], cols=['compass'], smoothing=2, min_samples_leaf=2)
te.fit(X.loc[:,['compass']], y)
X["compass_encode"] = te.transform(X.loc[:,['compass']])
X["label"] = y
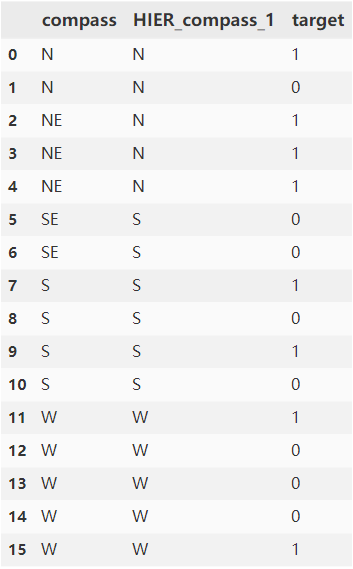
print(X)# 结果如下,compass_encode列为结果列:index compass HIER_compass_1 compass_encode label
0 1 N N 0.622636 1
1 2 N N 0.622636 0
2 3 NE N 0.903830 1
3 4 NE N 0.903830 1
4 5 NE N 0.903830 1
5 6 SE S 0.176600 0
6 7 SE S 0.176600 0
7 8 S S 0.460520 1
8 9 S S 0.460520 0
9 10 S S 0.460520 1
10 11 S S 0.460520 0
11 12 W W 0.403328 1
12 13 W W 0.403328 0
13 14 W W 0.403328 0
14 15 W W 0.403328 0
15 16 W W 0.403328 1注意事项:
采用平均数编码,容易引起过拟合,可以采用以下方法防止过拟合:
- 增大正则项f
- k折交叉验证
以下为自行实现的基于k折交叉验证版本的平均数编码,可以应用于二分类、多分类、回归场景中对单一类别特征或具有层次结构类别特征进行编码,该版本中用prior对unknown类别和缺失值编码。
from itertools import product
from category_encoders import TargetEncoder
from sklearn.model_selection import StratifiedKFold, KFoldclass MeanEncoder:def __init__(self, categorical_features, n_splits=5, target_type='classification', min_samples_leaf=2, smoothing=1, hierarchy=None, verbose=0, shuffle=False, random_state=None):"""Parameters----------categorical_features: list of strthe name of the categorical columns to encode.n_splits: intthe number of splits used in mean encoding.target_type: str,'regression' or 'classification'.min_samples_leaf: intFor regularization the weighted average between category mean and global mean is taken. The weight isan S-shaped curve between 0 and 1 with the number of samples for a category on the x-axis.The curve reaches 0.5 at min_samples_leaf. (parameter k in the original paper)smoothing: floatsmoothing effect to balance categorical average vs prior. Higher value means stronger regularization.The value must be strictly bigger than 0. Higher values mean a flatter S-curve (see min_samples_leaf).hierarchy: dict or dataframeA dictionary or a dataframe to define the hierarchy for mapping.If a dictionary, this contains a dict of columns to map into hierarchies. Dictionary key(s) should be the column name from Xwhich requires mapping. For multiple hierarchical maps, this should be a dictionary of dictionaries.If dataframe: a dataframe defining columns to be used for the hierarchies. Column names must take the form:HIER_colA_1, ... HIER_colA_N, HIER_colB_1, ... HIER_colB_M, ...where [colA, colB, ...] are given columns in cols list. 1:N and 1:M define the hierarchy for each column where 1 is the highest hierarchy (top of the tree). A single column or multiple can be used, as relevant.verbose: intinteger indicating verbosity of the output. 0 for none.shuffle : bool, default=Falserandom_state : int or RandomState instance, default=NoneWhen `shuffle` is True, `random_state` affects the ordering of theindices, which controls the randomness of each fold for each class.Otherwise, leave `random_state` as `None`.Pass an int for reproducible output across multiple function calls."""self.categorical_features = categorical_featuresself.n_splits = n_splitsself.learned_stats = {}self.min_samples_leaf = min_samples_leafself.smoothing = smoothingself.hierarchy = hierarchyself.verbose = verboseself.shuffle = shuffleself.random_state = random_stateif target_type == 'classification':self.target_type = target_typeself.target_values = []else:self.target_type = 'regression'self.target_values = Nonedef mean_encode_subroutine(self, X_train, y_train, X_test, variable, target):X_train = X_train[[variable]].copy()X_test = X_test[[variable]].copy()if target is not None:nf_name = '{}_pred_{}'.format(variable, target)X_train['pred_temp'] = (y_train == target).astype(int) # classificationelse:nf_name = '{}_pred'.format(variable)X_train['pred_temp'] = y_train # regressionprior = X_train['pred_temp'].mean()te = TargetEncoder(verbose=self.verbose, hierarchy=self.hierarchy, cols=[variable], smoothing=self.smoothing, min_samples_leaf=self.min_samples_leaf)te.fit(X_train[[variable]], X_train['pred_temp'])tmp_l = te.ordinal_encoder.mapping[0]["mapping"].reset_index()tmp_l.rename(columns={"index":variable, 0:"encode"}, inplace=True)tmp_l.dropna(inplace=True)tmp_r = te.mapping[variable].reset_index()if self.hierarchy is None:tmp_r.rename(columns={variable: "encode", 0:nf_name}, inplace=True)else:tmp_r.rename(columns={"index": "encode", 0:nf_name}, inplace=True)col_avg_y = pd.merge(tmp_l, tmp_r, how="left",on=["encode"])col_avg_y.drop(columns=["encode"], inplace=True)col_avg_y.set_index(variable, inplace=True)nf_train = X_train.join(col_avg_y, on=variable)[nf_name].valuesnf_test = X_test.join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name].valuesreturn nf_train, nf_test, prior, col_avg_ydef fit(self, X, y):""":param X: pandas DataFrame, n_samples * n_features:param y: pandas Series or numpy array, n_samples:return X_new: the transformed pandas DataFrame containing mean-encoded categorical features"""X_new = X.copy()if self.target_type == 'classification':skf = StratifiedKFold(self.n_splits, shuffle=self.shuffle, random_state=self.random_state)else:skf = KFold(self.n_splits, shuffle=self.shuffle, random_state=self.random_state)if self.target_type == 'classification':self.target_values = sorted(set(y))self.learned_stats = {'{}_pred_{}'.format(variable, target): [] for variable, target inproduct(self.categorical_features, self.target_values)}for variable, target in product(self.categorical_features, self.target_values):nf_name = '{}_pred_{}'.format(variable, target)X_new.loc[:, nf_name] = np.nanfor large_ind, small_ind in skf.split(y, y):nf_large, nf_small, prior, col_avg_y = self.mean_encode_subroutine(X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, target)X_new.iloc[small_ind, -1] = nf_smallself.learned_stats[nf_name].append((prior, col_avg_y))else:self.learned_stats = {'{}_pred'.format(variable): [] for variable in self.categorical_features}for variable in self.categorical_features:nf_name = '{}_pred'.format(variable)X_new.loc[:, nf_name] = np.nanfor large_ind, small_ind in skf.split(y, y):nf_large, nf_small, prior, col_avg_y = self.mean_encode_subroutine(X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, None)X_new.iloc[small_ind, -1] = nf_smallself.learned_stats[nf_name].append((prior, col_avg_y))return X_newdef transform(self, X):""":param X: pandas DataFrame, n_samples * n_features:return X_new: the transformed pandas DataFrame containing mean-encoded categorical features"""X_new = X.copy()if self.target_type == 'classification':for variable, target in product(self.categorical_features, self.target_values):nf_name = '{}_pred_{}'.format(variable, target)X_new[nf_name] = 0for prior, col_avg_y in self.learned_stats[nf_name]:X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name]X_new[nf_name] /= self.n_splitselse:for variable in self.categorical_features:nf_name = '{}_pred'.format(variable)X_new[nf_name] = 0for prior, col_avg_y in self.learned_stats[nf_name]:X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name]X_new[nf_name] /= self.n_splitsreturn X_new四 总结
本文介绍了一种对高基数类别特征非常有效的编码方式:平均数编码。详细的讲述了该种编码方式的原理,在实际工程应用中有效避免过拟合的方法,并且提供了一个直接上手的代码版本。
作者:京东保险 赵风龙
来源:京东云开发者社区 转载请注明来源
相关文章:
高基数类别特征预处理:平均数编码 | 京东云技术团队
一 前言 对于一个类别特征,如果这个特征的取值非常多,则称它为高基数(high-cardinality)类别特征。在深度学习场景中,对于类别特征我们一般采用Embedding的方式,通过预训练或直接训练的方式将类别特征值编…...

高效利用隧道代理实现无阻塞数据采集
在当今信息时代,大量的有价值数据分散于各个网站和平台。然而,许多网站对爬虫程序进行限制或封禁,使得传统方式下的数据采集变得困难重重。本文将向您介绍如何通过使用隧道代理来解决这一问题,并帮助您成为一名高效、顺畅的数据采…...

图论岛屿问题DFS+BFS
leetcode 200 岛屿问题 class Solution {//定义对应的方向boolean [][] visited;int dir[][]{{0,1},{1,0},{-1,0},{0,-1}};public int numIslands(char[][] grid) {//对应的二维数组int count0;visitednew boolean[grid.length][grid[0].length];for (int i 0; i < grid.l…...
Cypress web自动化windows环境npm安装Cypress
前言 web技术已经进化了,web的测试技术最终还是跟上了脚步,新一代的web自动化技术出现了? Cypress可以对在浏览器中运行的任何东西进行快速、简单和可靠的测试。 官方地址https://www.cypress.io/,详细的文档介绍https://docs.cypress.io/g…...

CentOS7.9设置ntp时间同步
文章目录 应用场景基础知识操作步骤 应用场景 我们公司是做智慧交通的,主要卖交通相关的硬件和软件。硬件包括信号机、雷达、雷视、边缘盒子等,软件包括信控平台、管控平台等信号机设备、雷达设备、边缘计算单元等,还有一些第三方的卡口设备…...
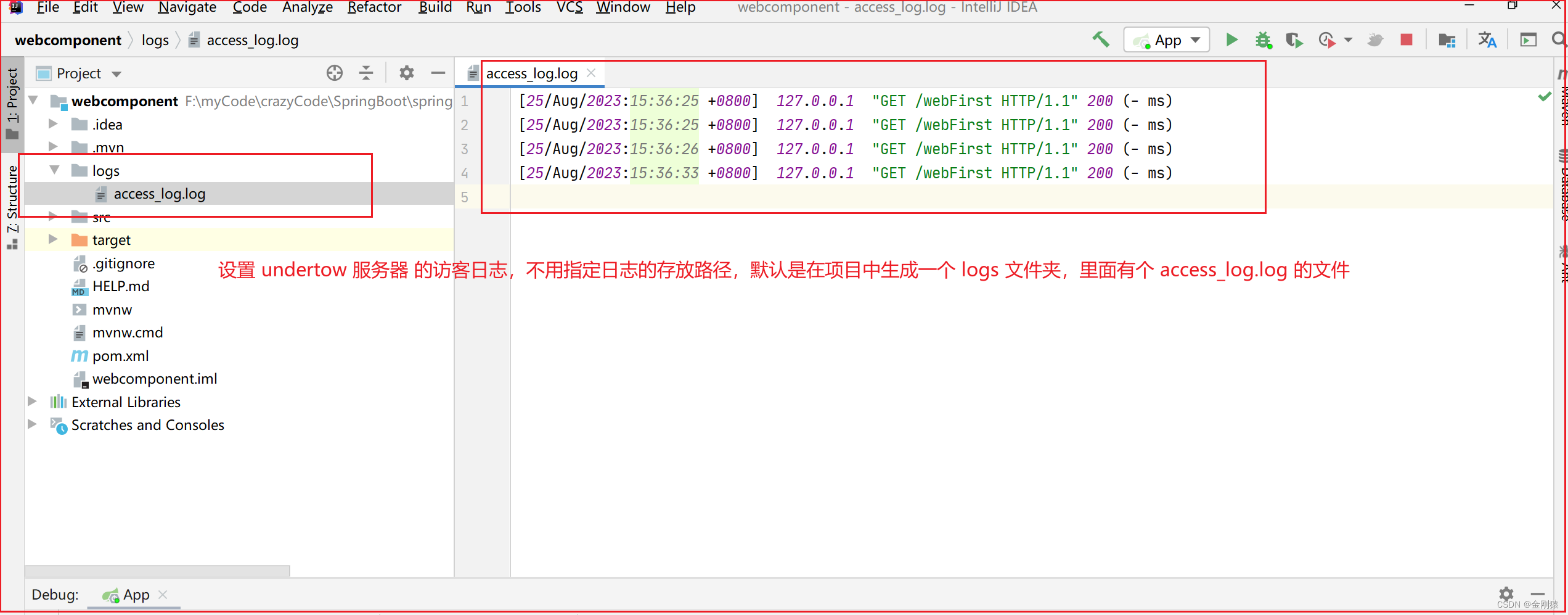
36、springboot --- 对 tomcat服务器 和 undertow服务器 配置访客日志
springboot 配置访客日志 ★ 配置访客日志: 访客日志: Web服务器可以将所有访问用户的记录都以日志的形式记录下来,主要就是记录来自哪个IP的用户、在哪个时间点、访问了哪个资源。 Web服务器可将所有访问记录以日志形式记录下来ÿ…...
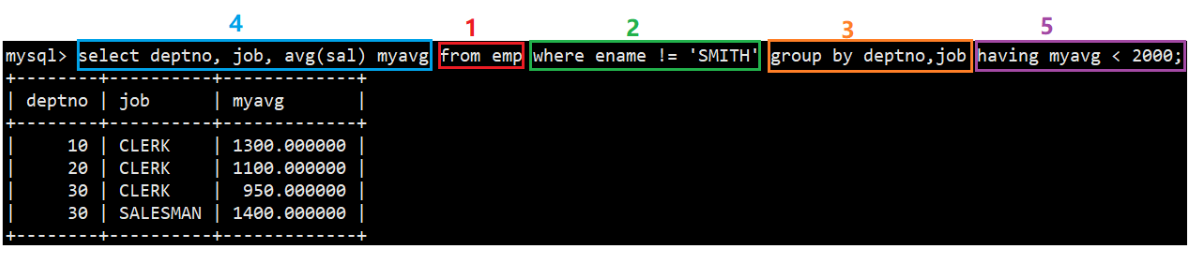
MySQL表的增删改查
文章目录 MySQL表的增删改查1. Create1.1 单行数据插入1.2 多行数据插入1.3 插入否则更新1.4 替换 2. Retrieve2.1 SELECT 列2.1.1 全列查询2.1.2 指定列查询2.1.3 查询字段为表达式2.1.4 为查询结果指定别名2.1.5 结果去重 2.2 WHERE 条件2.2.1 英语不及格的同学及英语成绩(&l…...

yolov3
yolov1 传统的算法 最主要的是先猜很多候选框,然后使用特征工程来提取特征(特征向量),最后使用传统的机器学习工具进行训练。然而复杂的过程可能会导致引入大量的噪声,丢失很多信息。 从传统的可以总结出目标检测可以分为两个阶…...

基于低代码/无代码工具构建 BI 应用程序
一、前言 随着数字化推进,越来越多的企业开始重视数据分析,希望通过BI(商业智能)技术提高业务决策的效率和准确性。 传统的BI解决方案往往需要大量的定制开发和数据准备,不仅周期长、成本高,还需要专业的数…...

Servlet与过滤器
目录 Servlet 过滤器 Servlet Servlet做了什么 本身不做任何业务处理,只是接收请求并决定调用哪个JavaBean去处理请求,确定用哪个页面来显示处理返回的数据 Servlet是什么 ServerApplet,是一种服务器端的Java应用程序 只有当一个服务器端的程序使用了Servlet…...

微信小程序开发实战记录
近期公司需要开发一个小程序项目,时间非常紧急,在开发过程中遇到几个困扰的问题及解决方案,记录如下:小程序框架选择 基础框架:小程序原生框架 sassui: 采用 vant weapp图表:采用 ec-echarts …...
防破解暗桩思路:检查菜单是否被非法修改过源码
本篇文章属于《518抽奖软件开发日志》系列文章的一部分。 我在开发《518抽奖软件》(www.518cj.net)的时候,为了防止被破解,需用添加一些暗桩,在合适的时机检查软件是否被非法修改过,如果被非法修改就做出提…...

IDEA使用Docker插件
修改Docker配置 1.执行命令vim /usr/lib/systemd/system/docker.service,在ExecStart配置的后面追加 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock ExecStart/usr/bin/dockerd -H fd:// --containerd/run/containerd/containerd.sock -H tcp://0.0.0.0:…...

[前端] vue使用Mousetrap.js实现快捷键
Mousetrap.js介绍 Mousetrap.js 是一个处理键盘快捷键的 JavaScript 库,它允许您定义复杂的键盘快捷键并在浏览器中使用。 官方地址 代码仓库 安装库 在命令行中运行以下命令安装 mousetrap 模块: npm install mousetrap再次运行命令行,安…...

如何查询Oracle的字符集
如何查询Oracle的字符集 很多人都碰到过因为字符集不同而使数据导入失败的情况。这涉及三方面的字符集,一是oracel server端的字符集,二是oracle client端的字符集;三是dmp文件的字符集。在做数据导入的时候,需要这三个字符集都一致才能正确…...
C语言每日一练------------Day(7)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今日练习题关键字:两个数组的交集 双指针 💓博主csdn个人主页…...

Meta语言模型LLaMA解读:模型的下载部署与运行代码
文章目录 llama2体验地址模型下载下载步骤准备工作什么是Git LFS下载huggingface模型 模型运行代码 llama2 Meta最新语言模型LLaMA解读,LLaMA是Facebook AI Research团队于2023年发布的一种语言模型,这是一个基础语言模型的集合。 体验地址 体验地址 …...

人生中的孤独
孤独是一种深刻而痛苦的情感状态,在这个喧嚣而充满人群的世界中,许多人都曾经或正在经历孤独的阶段。 孤独并不仅仅是身边缺乏他人的陪伴,更是一种内心的空虚和失落。 孤独的人生可能来源于各种原因。 有些人可能因为缺乏亲密的人际关系&…...

掌握Spring框架核心组件:深入探讨IOC、AOP、MVC及注解方式面试指南【经验分享】
目录 引言 一、Spring IOC篇 1.什么是Spring 2.核心概念 3.核心架构 4.什么是控制反转(IOC) 5.依赖注入(DI) 二、Spring AOP篇 1.什么是AOP 2.Spring AOP代理机制 3.核心概念 4.通知分类 三、Spring MVC篇 1.什么…...

代码随想录算法训练营第37天 | ● 738.单调递增的数字 ● 968.监控二叉树 ● 总结
文章目录 前言一、738.单调递增的数字二、968.监控二叉树总结 前言 可以吗? 一、738.单调递增的数字 本题只要想清楚个例,例如98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum…...
)
导师认可的AI论文软件榜单(2026 最新实测)
基于学术严谨性、写作效率、功能全面性及用户反馈,以下是2026年最新实测中表现突出的AI论文写作工具权威榜单,按综合使用价值从高到低排列,并附上各工具的核心优势与适用人群。🏆 第一梯队:全流程学术解决方案…...

3分钟快速上手:Tsukimi打造你的个人Jellyfin媒体中心
3分钟快速上手:Tsukimi打造你的个人Jellyfin媒体中心 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 还在为复杂的媒体播放器设置而烦恼吗?Tsukimi这款简单易用…...

零成本获取全球股票数据:AKShare开源金融数据接口完整指南
零成本获取全球股票数据:AKShare开源金融数据接口完整指南 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/ak…...

政务许可场景钓鱼邮件攻击机理与防御体系研究 —— 基于美国克恩县预警事件
摘要 2026 年 5 月,美国加利福尼亚州克恩县(Kern County)官方发布安全预警,披露针对Accela 政务许可申报平台用户的定向钓鱼邮件攻击。攻击者伪装成县政务部门,以 “许可审核费”“紧急支付” 等名义发送伪造账单邮件&…...
)
DeepSeek SSO性能压测实录:单集群支撑5000+并发登录的4大调优阈值(含Prometheus监控指标基线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek SSO单点登录性能压测全景概览 DeepSeek SSO 作为企业级统一身份认证中枢,其在高并发场景下的响应延迟、会话稳定性与令牌签发吞吐能力直接决定下游所有业务系统的可用性边界。本章…...

ROS Topic通讯实战:拆解`/turtle1/cmd_vel`,理解速度指令如何驱动小乌龟运动
ROS Topic通讯实战:拆解/turtle1/cmd_vel,理解速度指令如何驱动小乌龟运动 在机器人操作系统(ROS)的学习过程中,控制小乌龟(turtlesim)画圆是一个经典案例。这个看似简单的任务背后,…...

如何在Windows11中配置家长控制?限制使用时间与内容访问
如何在Windows11中配置家长控制?限制使用时间与内容访问 【免费下载链接】windows11 🌎 Windows 11 Settings, Tweaks, Scripts 项目地址: https://gitcode.com/GitHub_Trending/wi/windows11 Windows 11家长控制是保护孩子健康使用电脑的重要功能…...
)
Mentor DFT实战:手把手教你搞定Wrapped Core的Scan Insertion(附完整TCL脚本)
Mentor DFT实战:Wrapped Core的Scan Insertion全流程解析与TCL脚本精讲 在芯片测试设计领域,Wrapped Core的Scan Insertion一直是工程师们面临的棘手难题。当设计规模不断扩大,核心间交互日益复杂时,传统的扫描链插入方法往往显得…...

2025_NIPS_TradeMaster: A Holistic Quantitative Trading Platform Empowered by Reinforcement Learning
TradeMaster 论文总结与核心内容翻译 一、文章主要内容 TradeMaster 是一款面向强化学习量化交易(RLFT)的全栈开源平台,旨在解决 RL 技术在实际金融市场部署中面临的工程实现难、基准对比难、易用性差三大核心挑战。文章围绕该平台展开全面阐述,核心内容包括: 1. 平台定…...

3个步骤,在VSCode中实现Mermaid图表实时预览的终极工作流
3个步骤,在VSCode中实现Mermaid图表实时预览的终极工作流 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 你是否曾在编写技术文档时,为了一个简单的流…...