yolov3
yolov1
传统的算法 最主要的是先猜很多候选框,然后使用特征工程来提取特征(特征向量),最后使用传统的机器学习工具进行训练。然而复杂的过程可能会导致引入大量的噪声,丢失很多信息。
从传统的可以总结出目标检测可以分为两个阶段:候选框生成、回归分类。
yolov1是单阶段的目标检测算法。
yolov1的算法流程:
- 每一张图片分为s*s的网格大小,物体中心点落在哪一个格子上,则那个格子就负责预测那个物体。 也就是说yolov1就一幅图像经过卷积之后变成了特征图大小为7*7,特征图上的每一个点对应与原始图像的某一个区域,每一个点都是一个向量,每个向量包含了这片区域是否包含物体的信息。 这里最后的特征图太小,会出现多个物体落在一个格子上的现象。
- 卷积之后特征图大小为s*s,最终输出的张量是s*s*(5*B+C). 每个bounding box的置信度其实是两个信息的耦合,包含了这个边界框是否含有信息且含有信息的可靠性。
- 损失函数:边界框的回归。宽高带根号。
yolov1特征总结:
1 优势:
one-stage,非常快
2 缺点:
对拥挤情况不好,7*7网格太小(一个网格检测一个物体),对于稠密物体效果不好
对小物体检测不好
对形状变化大的物体不好
没有用BN
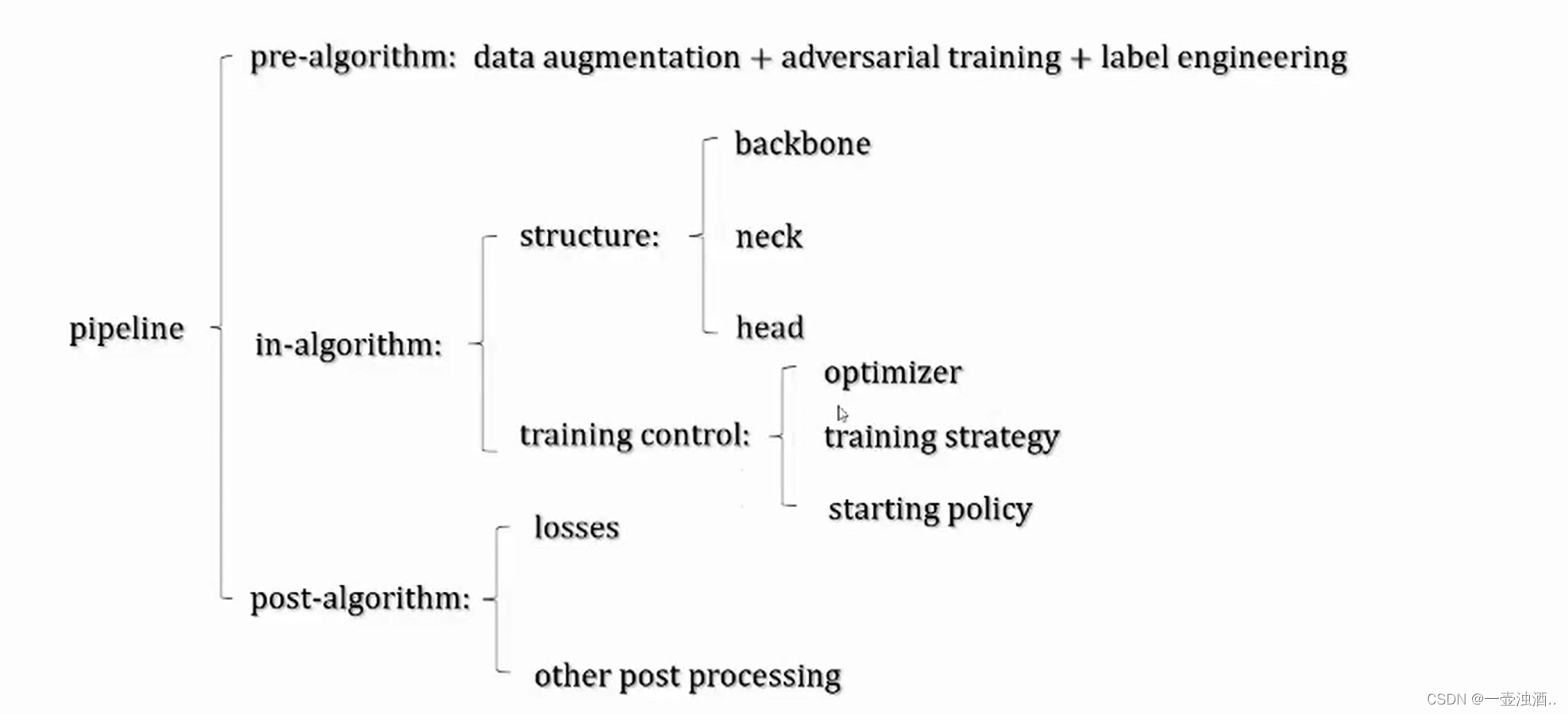
yolov2
yovov2算法改进:
1、引入BN
2、更高精度的classifier ,yolov1分为7*7网格(对稠密物体不友好),yolov2则分为13*13的网格
3、多尺度训练
- 移除了FC层可以接收任意尺度
- 从320*320,352*352 训练至680*680
4、细粒度(fine-grained)特征
- 浅层特征直连深层 (浅层特征主要学物体的边缘特征,深层特征主要学习物体的语义信息)
- 引入新层“reorg”(即“slice”层) (后续被抛弃,在yolov7中又被重新引入)
5、YOLO系列首次使用了Anchor(非常重要)
- Anchor 是什么
- 为什么要用Anchor
anchor机制
Anchor的含义:
- 预设好的虚拟边框
- 生成框由Anchor回归而来
yolov3

1 新的网络模块
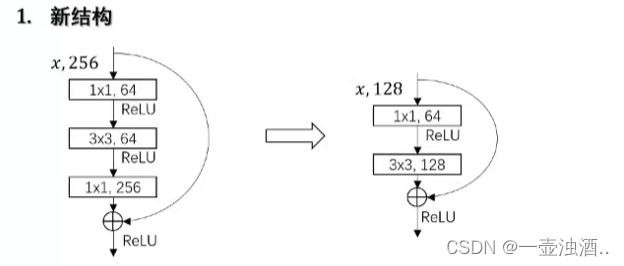
2 多尺度结构

3 Multi-class loss
softmax loss (one hot ) -> logistic regression loss
yolo-head部分会含有anchor,也就是说yolo-head 输出的其实就是真实框和anchor的偏移量
yolo的众多改良
1 数据改良(各种数据增广方案)
2 网络框架改良
激活函数
正则化改良
现代框架:解耦与第三分支
3 损失函数改良
Focal Loss
IOU/GIOU/
4 yolo后续
voctoyolo
生成train.txt文件 文件名+边界框坐标+类别
import os
import xml.etree.ElementTree as ETdef convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def xml2txt(xml_file, f, classes):"""xml_file:xml 文件f: 读取的信息以追加的方式追加到txt_file文件中classes:所有的类别"""# 解析 xml 文件tree = ET.parse(xml_file)root = tree.getroot()# 读取高宽等信息size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)# 遍历 xml 中的目标for obj in root.iter('object'):difficult = obj.find('difficult').text # 跳过困难样本cls = obj.find('name').text # 获取目标类别# 跳过无需转换的类别if cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls) # 转换为对应索引 从 0 开始xmlbox = obj.find('bndbox') # 读取标注信息 [xmin, ymin, xmax, ymax]b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text))) # 字符型转换为float# b = convert((w, h), b) # 转换为yolo格式 [xcenter, ycenter, box_w, box_h]f.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))f.write('\n')if __name__ == '__main__':classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair','cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train','tvmonitor']def create_txt(img_dir,xml_dir,txt_file,classes):img_total = os.listdir(img_dir)with open(txt_file, mode='w', encoding='utf-8') as f:for img in img_total:if not img.endswith(('jpg')):continueimg_path = os.path.join(img_dir, img)xml_path = os.path.join(xml_dir, img.split('.')[0] + '.xml')f.write(img_path)xml2txt(xml_path, f, classes)create_txt(img_dir='./VOCdevkit/VOC2007/JPEGImages',xml_dir='./VOCdevkit/VOC2007/Annotations',txt_file='./train.txt',classes=classes)
import os
import shutillabel_total=os.listdir('./Anonations')for label in label_total:print(label)label_name=label.split('.')[0]shutil.move(os.path.join('./1/',label_name+'.bmp'),os.path.join('./2/',label_name+'.bmp'))读取标注并且画出方框
import os
import shutil
import cv2
import xml.etree.ElementTree as ETannoation=os.listdir('./Anonations')for label in annoation:name=label.split('.')[0]# print(name)# shutil.move(os.path.join('./image',name+'.bmp'),os.path.join('img1',name+'.bmp'))image_name=os.path.join('image',name+'.bmp')image=cv2.imread(image_name)annoation_path=os.path.join('./Anonations',label)# print(annoation_path)#画候选框#提取候选框tree=ET.parse(annoation_path)root=tree.getroot()for obj in root.iter('object'):cls=obj.find('name').textprint('类别',cls)xmlbox=obj.find('bndbox') #读取标注信息 [xmin,ymin,xmax,yamx]b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))cv2.rectangle(image,(b[0],b[1]),(b[2],b[3]),(255,255,2552),thickness=1)cv2.putText(image,text=cls,org=(b[0],b[1]),fontFace=cv2.FONT_HERSHEY_SIMPLEX,fontScale=0.5,color=(255,0,0))cv2.imshow('image',image)cv2.waitKey(0)create_list.py 用于创建train.txt 和 val.txt文件
import random
import os
#生成train.txt和val.txt
random.seed(8888)
#---------------------修改为自己的路径----------------------------------------------------
xml_dir = './annotations'#标签文件地址
img_dir = './images'#图像文件地址
#---------------------修改为自己的路径----------------------------------------------------path_list = list()
for img in os.listdir(img_dir):img_path = os.path.join(img_dir,img)xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml')) ##这里将图片后缀替换为xmlpath_list.append((img_path, xml_path))
random.shuffle(path_list)
#这里用于测试,因为数据量比较大,cpu带不动
test_data_lenth=50
path_list=path_list[:test_data_lenth]ratio = 0.9
#---------------------train/val之前修改为自己的路径----------------------------------------------------
train_f = open('./train.txt','w') #生成训练文件
val_f = open('./val.txt' ,'w')#生成验证文件
#---------------------修改为自己的路径----------------------------------------------------for i ,content in enumerate(path_list):img, xml = contenttext = img + ' ' + xml + '\n'if i < len(path_list) * ratio:train_f.write(text)else:val_f.write(text)
train_f.close()
val_f.close()#生成标签文档
label = ['speedlimit','crosswalk','trafficlight'] #设置你想检测的类别#---------------------label_list之前修改为自己的路径----------------------------------------------------
with open('./label_list.txt', 'w',encoding='utf-8') as f:
# ---------------------label_list之前修改为自己的路径----------------------------------------------------for text in label:f.write(text+'\n')
【目标检测】将xml标注文件转换为txt格式,voc标注格式转为yolo的txt格式_voc转txt_悠悠青青的博客-CSDN博客
yolodataset
对图像进行变换时也需要对真实框进行变换
import cv2
import numpy as np
import torch
from PIL import Image
from torch.utils.data.dataset import Dataset# ---------------------------------------------------------#
# 将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
# ---------------------------------------------------------#
def cvtColor(image):if len(np.shape(image)) == 3 and np.shape(image)[2] == 3:return imageelse:image = image.convert('RGB')return imagedef preprocess_input(image):image /= 255.0return imageclass YoloDataset(Dataset):def __init__(self, annotation_lines, input_shape=[416, 416], num_classes=20, train=False):super(YoloDataset, self).__init__()self.annotation_lines = annotation_linesself.input_shape = input_shapeself.num_classes = num_classesself.length = len(self.annotation_lines)self.train = traindef __len__(self):return self.lengthdef __getitem__(self, index):index = index % self.length# ---------------------------------------------------## 训练时进行数据的随机增强# 验证时不进行数据的随机增强# ---------------------------------------------------#image, box = self.get_random_data(self.annotation_lines[index], self.input_shape[0:2], random=self.train)image = np.transpose(preprocess_input(np.array(image, dtype=np.float32)), (2, 0, 1))box = np.array(box, dtype=np.float32)if len(box) != 0:box[:, [0, 2]] = box[:, [0, 2]] / self.input_shape[1]box[:, [1, 3]] = box[:, [1, 3]] / self.input_shape[0]box[:, 2:4] = box[:, 2:4] - box[:, 0:2]box[:, 0:2] = box[:, 0:2] + box[:, 2:4] / 2return image, boxdef rand(self, a=0, b=1):return np.random.rand() * (b - a) + adef get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=0.7, val=0.4, random=True):line = annotation_line.split()# ------------------------------## 读取图像并转换成RGB图像# ------------------------------#image = Image.open(line[0])image = cvtColor(image)# ------------------------------## 获得图像的高宽与目标高宽# ------------------------------#iw, ih = image.size #iw表示原始图片的宽,ih表示原始图片的高h, w = input_shape #模型输入的高和宽# ------------------------------## 获得预测框# ------------------------------#box = np.array([np.array(list(map(int, box.split(',')))) for box in line[1:]])if not random:##random=False 时,即验证时,不需要进行数据增强scale = min(w / iw, h / ih) ##输入图片大小跟算法处理的大小不一致,需要进行变换nw = int(iw * scale) #这是因为图片必须同一比例进行缩放nh = int(ih * scale)dx = (w - nw) // 2 #这里因为使用同一比例进行缩放时 可能会导致有些图片变小,所以这时需要进行填充,//2,两边填充dy = (h - nh) // 2# ---------------------------------## 将图像多余的部分加上灰条# ---------------------------------#image = image.resize((nw, nh), Image.BICUBIC)new_image = Image.new('RGB', (w, h), (128, 128, 128))new_image.paste(image, (dx, dy))image_data = np.array(new_image, np.float32)# ---------------------------------## 对真实框进行调整# ---------------------------------#if len(box) > 0:np.random.shuffle(box)box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dxbox[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dybox[:, 0:2][box[:, 0:2] < 0] = 0box[:, 2][box[:, 2] > w] = wbox[:, 3][box[:, 3] > h] = hbox_w = box[:, 2] - box[:, 0]box_h = box[:, 3] - box[:, 1]box = box[np.logical_and(box_w > 1, box_h > 1)] # discard invalid boxreturn image_data, box# ------------------------------------------## 对图像进行缩放并且进行长和宽的扭曲# ------------------------------------------#new_ar = iw / ih * self.rand(1 - jitter, 1 + jitter) / self.rand(1 - jitter, 1 + jitter)scale = self.rand(.25, 2)if new_ar < 1:nh = int(scale * h)nw = int(nh * new_ar)else:nw = int(scale * w)nh = int(nw / new_ar)image = image.resize((nw, nh), Image.BICUBIC)# ------------------------------------------## 将图像多余的部分加上灰条# ------------------------------------------#dx = int(self.rand(0, w - nw))dy = int(self.rand(0, h - nh))new_image = Image.new('RGB', (w, h), (128, 128, 128))new_image.paste(image, (dx, dy))image = new_image# ------------------------------------------## 翻转图像# ------------------------------------------#flip = self.rand() < .5if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)image_data = np.array(image, np.uint8)# ---------------------------------## 对图像进行色域变换# 计算色域变换的参数# ---------------------------------#r = np.random.uniform(-1, 1, 3) * [hue, sat, val] + 1# ---------------------------------## 将图像转到HSV上# ---------------------------------#hue, sat, val = cv2.split(cv2.cvtColor(image_data, cv2.COLOR_RGB2HSV))dtype = image_data.dtype# ---------------------------------## 应用变换# ---------------------------------#x = np.arange(0, 256, dtype=r.dtype)lut_hue = ((x * r[0]) % 180).astype(dtype)lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)lut_val = np.clip(x * r[2], 0, 255).astype(dtype)image_data = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))image_data = cv2.cvtColor(image_data, cv2.COLOR_HSV2RGB)# ---------------------------------## 对真实框进行调整# ---------------------------------#if len(box) > 0:np.random.shuffle(box)box[:, [0, 2]] = box[:, [0, 2]] * nw / iw + dxbox[:, [1, 3]] = box[:, [1, 3]] * nh / ih + dyif flip: box[:, [0, 2]] = w - box[:, [2, 0]]box[:, 0:2][box[:, 0:2] < 0] = 0box[:, 2][box[:, 2] > w] = wbox[:, 3][box[:, 3] > h] = hbox_w = box[:, 2] - box[:, 0]box_h = box[:, 3] - box[:, 1]box = box[np.logical_and(box_w > 1, box_h > 1)]return image_data, boxif __name__=='__main__':with open('train.txt',mode='r',encoding='utf-8') as f:annotation_lines=f.readlines()print(annotation_lines)dataset=YoloDataset(annotation_lines=annotation_lines)image_data,box=dataset[0]print(image_data.shape,box)kmeans anchors聚类
# -------------------------------------------------------------------------------------------------------#
# kmeans虽然会对数据集中的框进行聚类,但是很多数据集由于框的大小相近,聚类出来的9个框相差不大,
# 这样的框反而不利于模型的训练。因为不同的特征层适合不同大小的先验框,shape越小的特征层适合越大的先验框
# 原始网络的先验框已经按大中小比例分配好了,不进行聚类也会有非常好的效果。
# -------------------------------------------------------------------------------------------------------#
import glob
import xml.etree.ElementTree as ETimport matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdmdef cas_iou(box, cluster):x = np.minimum(cluster[:, 0], box[0])y = np.minimum(cluster[:, 1], box[1])intersection = x * yarea1 = box[0] * box[1]area2 = cluster[:, 0] * cluster[:, 1]iou = intersection / (area1 + area2 - intersection)return ioudef avg_iou(box, cluster):return np.mean([np.max(cas_iou(box[i], cluster)) for i in range(box.shape[0])])def kmeans(box, k):# -------------------------------------------------------------## 取出一共有多少框# -------------------------------------------------------------#row = box.shape[0]# -------------------------------------------------------------## 每个框各个点的位置# -------------------------------------------------------------#distance = np.empty((row, k))# -------------------------------------------------------------## 最后的聚类位置# -------------------------------------------------------------#last_clu = np.zeros((row,))np.random.seed()# -------------------------------------------------------------## 随机选k个当聚类中心# -------------------------------------------------------------#cluster = box[np.random.choice(row, k, replace=False)]iter = 0while True:# -------------------------------------------------------------## 计算当前框和先验框的宽高比例# -------------------------------------------------------------#for i in range(row):distance[i] = 1 - cas_iou(box[i], cluster)# -------------------------------------------------------------## 取出最小点# -------------------------------------------------------------#near = np.argmin(distance, axis=1) #求每一个框距离哪一个中心点的位置最近if (last_clu == near).all():break# -------------------------------------------------------------## 求每一个类的中位点# -------------------------------------------------------------#for j in range(k):cluster[j] = np.median(box[near == j], axis=0) #near==j 说明这些框是一个类别的last_clu = nearif iter % 5 == 0:print('iter: {:d}. avg_iou:{:.2f}'.format(iter, avg_iou(box, cluster)))iter += 1return cluster, near #cluster是最后的聚类中心,near是每一个框属于哪一个聚类中心def load_data(path):data = []# -------------------------------------------------------------## 对于每一个xml都寻找box# -------------------------------------------------------------#for xml_file in tqdm(glob.glob('{}/*xml'.format(path))):tree = ET.parse(xml_file)height = int(tree.findtext('./size/height'))width = int(tree.findtext('./size/width'))if height <= 0 or width <= 0:continue# -------------------------------------------------------------## 对于每一个目标都获得它的宽高# -------------------------------------------------------------#for obj in tree.iter('object'):xmin = int(float(obj.findtext('bndbox/xmin'))) / widthymin = int(float(obj.findtext('bndbox/ymin'))) / heightxmax = int(float(obj.findtext('bndbox/xmax'))) / widthymax = int(float(obj.findtext('bndbox/ymax'))) / heightxmin = np.float64(xmin)ymin = np.float64(ymin)xmax = np.float64(xmax)ymax = np.float64(ymax)# 得到宽高data.append([xmax - xmin, ymax - ymin])return np.array(data)if __name__ == '__main__':np.random.seed(0)input_shape = [200, 200] #图片的大小anchors_num = 9# -------------------------------------------------------------## 载入数据集,可以使用VOC的xml# -------------------------------------------------------------#path = './anonations'# -------------------------------------------------------------## 载入所有的xml# 存储格式为转化为比例后的width,height# -------------------------------------------------------------#print('Load xmls.')data = load_data(path)print('Load xmls done.')# -------------------------------------------------------------## 使用k聚类算法# -------------------------------------------------------------#print('K-means boxes.')cluster, near = kmeans(data, anchors_num)print('K-means boxes done.')data = data * np.array([input_shape[1], input_shape[0]])cluster = cluster * np.array([input_shape[1], input_shape[0]])# -------------------------------------------------------------## 绘图# -------------------------------------------------------------#for j in range(anchors_num):plt.scatter(data[near == j][:, 0], data[near == j][:, 1]) #画出所有框的散点图plt.scatter(cluster[j][0], cluster[j][1], marker='x', c='black') #cluster 表示聚类中心plt.savefig("kmeans_for_anchors.jpg")plt.show()print('Save kmeans_for_anchors.jpg in root dir.')hh=np.argsort(cluster[:, 0] * cluster[:, 1])cluster = cluster[np.argsort(cluster[:, 0] * cluster[:, 1])]print('avg_ratio:{:.2f}'.format(avg_iou(data, cluster)))print('聚类中心',cluster)f = open("yolo_anchors.txt", 'w')row = np.shape(cluster)[0]for i in range(row):if i == 0:x_y = "%d,%d" % (cluster[i][0], cluster[i][1])else:x_y = ", %d,%d" % (cluster[i][0], cluster[i][1])f.write(x_y)f.close()
相关文章:
yolov3
yolov1 传统的算法 最主要的是先猜很多候选框,然后使用特征工程来提取特征(特征向量),最后使用传统的机器学习工具进行训练。然而复杂的过程可能会导致引入大量的噪声,丢失很多信息。 从传统的可以总结出目标检测可以分为两个阶…...

基于低代码/无代码工具构建 BI 应用程序
一、前言 随着数字化推进,越来越多的企业开始重视数据分析,希望通过BI(商业智能)技术提高业务决策的效率和准确性。 传统的BI解决方案往往需要大量的定制开发和数据准备,不仅周期长、成本高,还需要专业的数…...

Servlet与过滤器
目录 Servlet 过滤器 Servlet Servlet做了什么 本身不做任何业务处理,只是接收请求并决定调用哪个JavaBean去处理请求,确定用哪个页面来显示处理返回的数据 Servlet是什么 ServerApplet,是一种服务器端的Java应用程序 只有当一个服务器端的程序使用了Servlet…...

微信小程序开发实战记录
近期公司需要开发一个小程序项目,时间非常紧急,在开发过程中遇到几个困扰的问题及解决方案,记录如下:小程序框架选择 基础框架:小程序原生框架 sassui: 采用 vant weapp图表:采用 ec-echarts …...
防破解暗桩思路:检查菜单是否被非法修改过源码
本篇文章属于《518抽奖软件开发日志》系列文章的一部分。 我在开发《518抽奖软件》(www.518cj.net)的时候,为了防止被破解,需用添加一些暗桩,在合适的时机检查软件是否被非法修改过,如果被非法修改就做出提…...

IDEA使用Docker插件
修改Docker配置 1.执行命令vim /usr/lib/systemd/system/docker.service,在ExecStart配置的后面追加 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock ExecStart/usr/bin/dockerd -H fd:// --containerd/run/containerd/containerd.sock -H tcp://0.0.0.0:…...

[前端] vue使用Mousetrap.js实现快捷键
Mousetrap.js介绍 Mousetrap.js 是一个处理键盘快捷键的 JavaScript 库,它允许您定义复杂的键盘快捷键并在浏览器中使用。 官方地址 代码仓库 安装库 在命令行中运行以下命令安装 mousetrap 模块: npm install mousetrap再次运行命令行,安…...

如何查询Oracle的字符集
如何查询Oracle的字符集 很多人都碰到过因为字符集不同而使数据导入失败的情况。这涉及三方面的字符集,一是oracel server端的字符集,二是oracle client端的字符集;三是dmp文件的字符集。在做数据导入的时候,需要这三个字符集都一致才能正确…...
C语言每日一练------------Day(7)
本专栏为c语言练习专栏,适合刚刚学完c语言的初学者。本专栏每天会不定时更新,通过每天练习,进一步对c语言的重难点知识进行更深入的学习。 今日练习题关键字:两个数组的交集 双指针 💓博主csdn个人主页…...

Meta语言模型LLaMA解读:模型的下载部署与运行代码
文章目录 llama2体验地址模型下载下载步骤准备工作什么是Git LFS下载huggingface模型 模型运行代码 llama2 Meta最新语言模型LLaMA解读,LLaMA是Facebook AI Research团队于2023年发布的一种语言模型,这是一个基础语言模型的集合。 体验地址 体验地址 …...

人生中的孤独
孤独是一种深刻而痛苦的情感状态,在这个喧嚣而充满人群的世界中,许多人都曾经或正在经历孤独的阶段。 孤独并不仅仅是身边缺乏他人的陪伴,更是一种内心的空虚和失落。 孤独的人生可能来源于各种原因。 有些人可能因为缺乏亲密的人际关系&…...

掌握Spring框架核心组件:深入探讨IOC、AOP、MVC及注解方式面试指南【经验分享】
目录 引言 一、Spring IOC篇 1.什么是Spring 2.核心概念 3.核心架构 4.什么是控制反转(IOC) 5.依赖注入(DI) 二、Spring AOP篇 1.什么是AOP 2.Spring AOP代理机制 3.核心概念 4.通知分类 三、Spring MVC篇 1.什么…...

代码随想录算法训练营第37天 | ● 738.单调递增的数字 ● 968.监控二叉树 ● 总结
文章目录 前言一、738.单调递增的数字二、968.监控二叉树总结 前言 可以吗? 一、738.单调递增的数字 本题只要想清楚个例,例如98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum…...
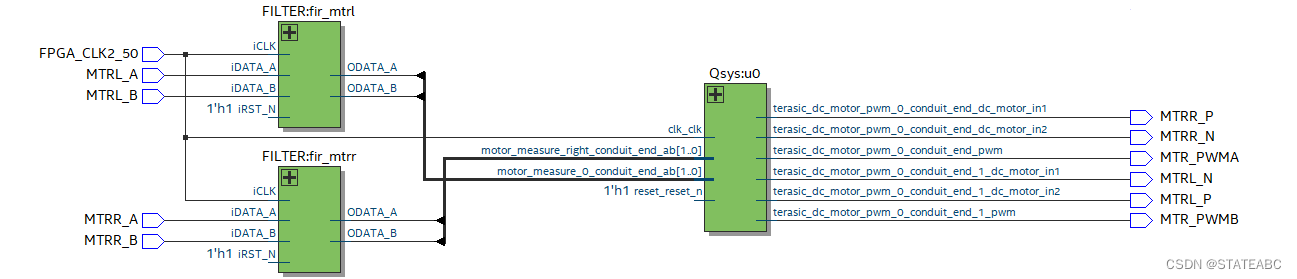
SOPC之NIOS Ⅱ实现电机转速PID控制(调用中断函数)
通过FPGA开发板上的NIOS Ⅱ搭建电机控制的硬件平台,包括电机正反转、编码器的读取,再通过软件部分实现PID算法对电机速度进行控制,使其能够渐近设定的编码器目标值。 一、问题与改进 SOPC之NIOS Ⅱ实现电机转速PID控制_STATEABC的博客-CSDN…...
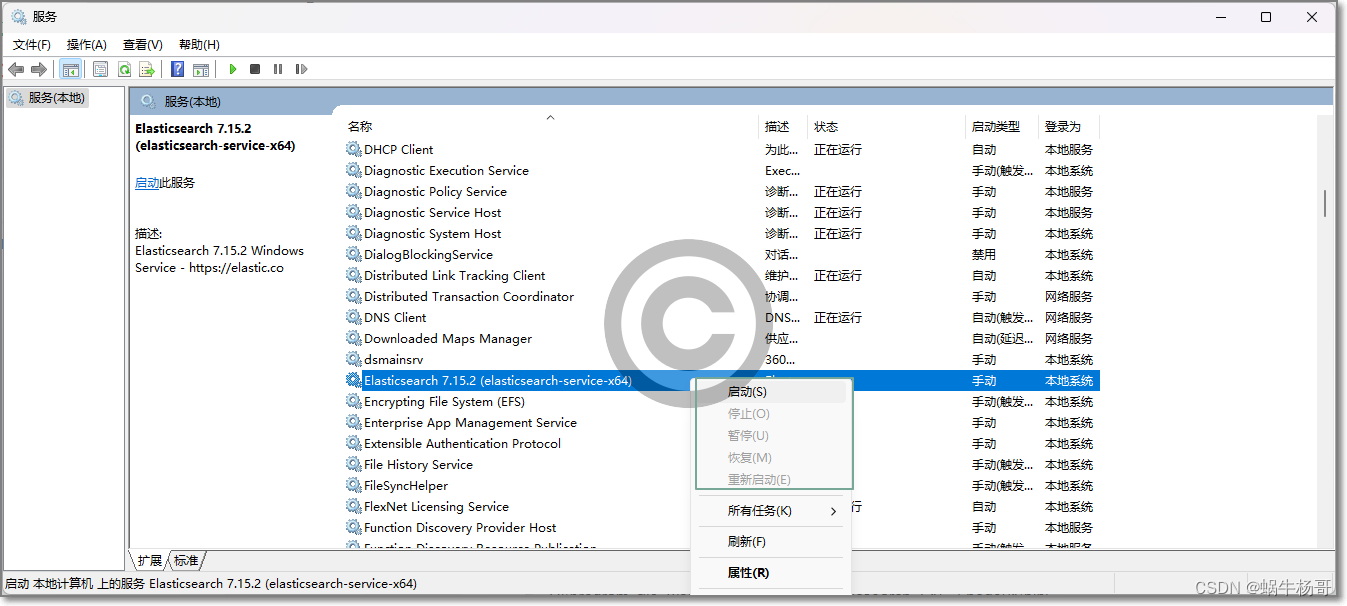
ElasticSearch安装为Win11服务
在windows的环境下操作是Elasticsearch,并且喜欢使用命令行 ,启动时通过cmd直接在elasticsearch的bin目录下执行elasticsearch ,这样直接启动的话集群名称会默elasticsearch,节点名称会随机生成。 停止就直接在cmd界面按CtrlC 其实我们也可以将elasticse…...

ransac拟合平面,代替open3d的segment_plane
0.open3d打包太大了,所以决定网上找找代码 使用open3d拟合平面并且求平面的法向量,open3d打包大概1个g的大小。 import open3d as o3dpcd o3d.geometry.PointCloud()pcd.points o3d.utility.Vector3dVector(points)## 使用RANSAC算法拟合平面plane_m…...

Docker技术--Docker镜像管理
1.Docker镜像特性 ①.镜像创建容器的特点 Docker在创建容器的时候需要指定镜像,每一个镜像都有唯一的标识:image_id,也可也使用镜像名称和版本号做唯一的标识,如果不指定版本号,那么默认使用的是最新的版本标签(laster)。 ②.镜像分层机制 Docker镜像是分层构建的,并通过…...

生态环境保护3D数字展厅提供了一个线上环保知识学习平台
在21世纪的今天,科技与环保的交汇点提供了无数令人兴奋的可能性。其中,生态环境保护3D数字展厅就是一个绝佳的例子。这个展厅以其独特的3D技术,为我们带来了一个全新的、互动的学习环境,让我们能够更直观地了解和理解我们的环境。…...

OPENCV实现计算描述子
1、计算描述子 kp,des = sift.computer(img,kp) 2、其作用是进行特征匹配 3、同时计算关键点和描述 3.1、kp,des = sift.detectAnd Computer(img,...)...
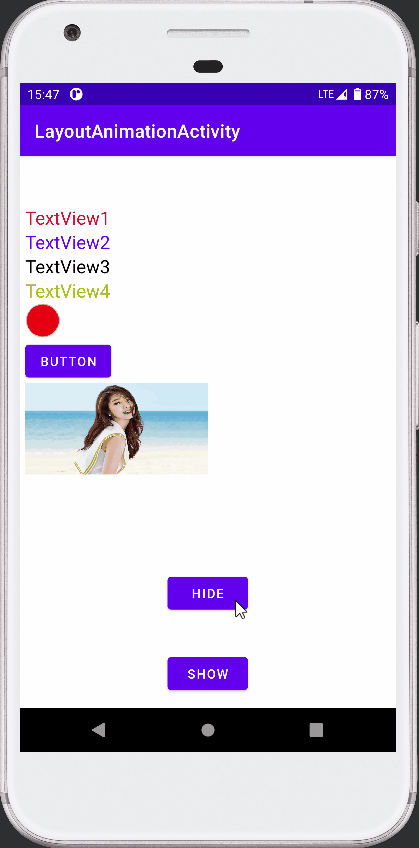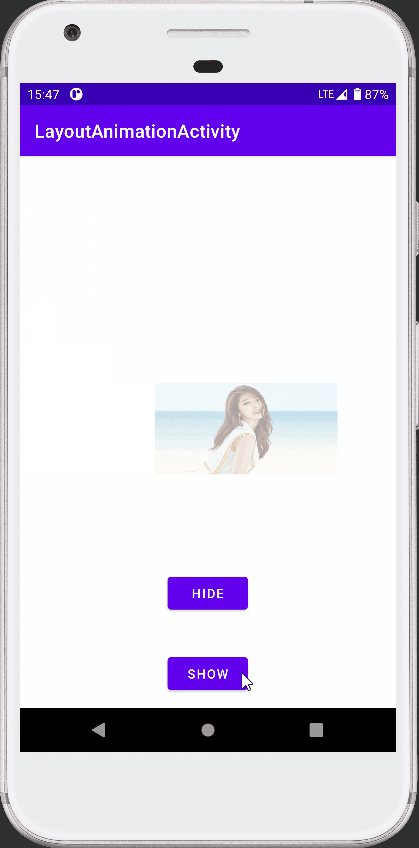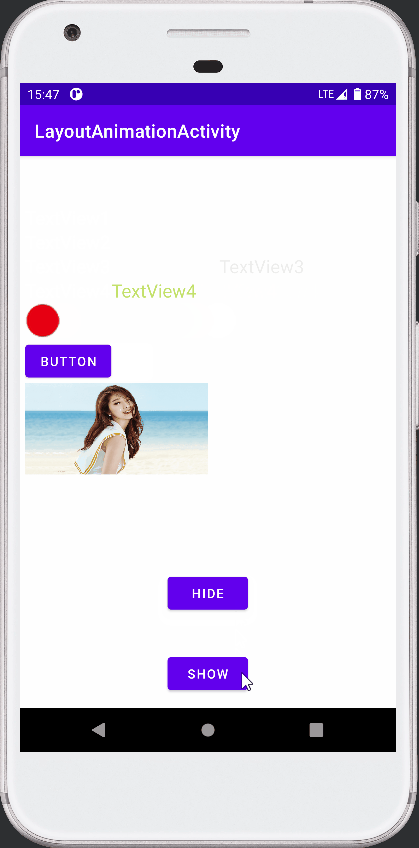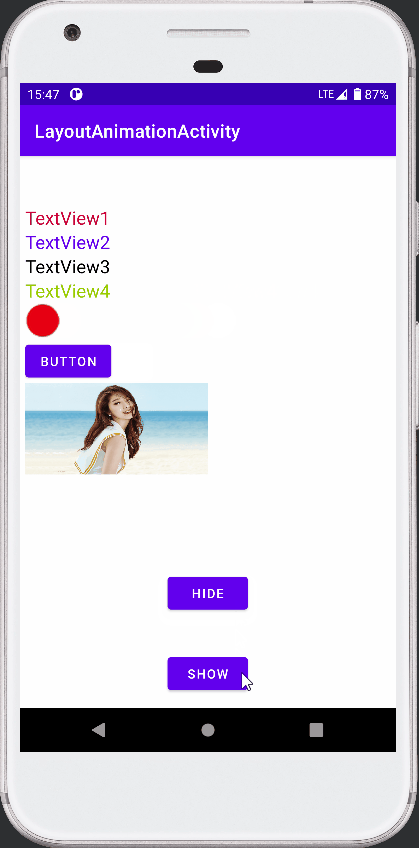
Android View动画之LayoutAnimation的使用
接前篇 Android View动画整理 ,本篇介绍 LayoutAnimation 的使用。 参考《安卓开发艺术探索》。 View 动画作用于 View 。 LayoutAnimation 则作用于 ViewGroup , 为 ViewGoup 指定一个动画,ViewGoup 的子 View 出场时就具体动画效果。 简言…...
)
告别CentOS!Debian 11 + VMware 保姆级教程:搞定那些只支持国产系统的Linux客户端(以aTrust为例)
Debian 11 VMware 全栈解决方案:无缝运行国产Linux客户端软件 在开源世界的版图中,CentOS曾经是企业级Linux的代名词,但随着Red Hat战略调整和CentOS Stream的转型,许多传统解决方案正在面临前所未有的兼容性挑战。特别是在需要对…...
)
别再只怪外力了!手把手教你用砂纸“解剖”MLCC,排查电容失效真凶(附打磨实操图)
低成本破解MLCC失效之谜:砂纸打磨法的实战指南 当产线上突然出现大批量MLCC失效时,硬件工程师们常常陷入两难——既没有价值百万的金相显微镜,也无法承受将样品送往专业实验室的高昂成本和时间延误。这时,一套简单粗暴却行之有效的…...

别再被CAPL路径搞懵了!getAbsFilePath、setFilePath这几个函数到底怎么用?
CAPL文件路径操作全解析:从函数原理到实战避坑指南 在CANoe自动化测试开发中,文件路径操作堪称最基础却又最容易出错的环节之一。许多工程师都经历过这样的场景:精心编写的CAPL脚本在本地测试一切正常,换到同事电脑上却频频报错&a…...
)
Unity3D RPG游戏开发实战:从零搭建角色与场景交互系统(含源码)
1. Unity3D RPG游戏开发基础准备 第一次打开Unity3D时,很多人会被复杂的界面吓到。别担心,我们先从最基础的设置开始。我建议使用2021 LTS版本,这个版本稳定性好,社区支持也完善。安装完成后,记得在Hub里勾选"Wi…...

从蓝图到落地:基于IEEE 830标准构建数字化车间需求规格说明书
1. 为什么数字化车间需要IEEE 830标准? 在汽车制造车间推进数字化转型时,我见过太多团队一上来就急着写代码、买设备,结果系统上线后才发现功能与业务脱节。这时候IEEE 830标准就像一份施工蓝图,它能帮我们把模糊的"数字化愿…...

LabVIEW虚拟仪表开发:从图形化编程到工业测控系统实战
1. 虚拟仪表:从概念到实践的革新 作为一名在工业自动化领域摸爬滚打了十多年的硬件工程师,我经历过从纯硬件调试到软硬件结合的漫长过程。早期,面对一个复杂的测试系统,我们往往需要堆满一桌子的真实仪器——示波器、信号发生器、…...

【技术解读】xNIDS:如何为深度学习入侵检测系统“翻译”可执行的主动防御规则?
1. 深度学习入侵检测的"黑盒困境":为什么需要翻译器? 第一次接触深度学习入侵检测系统(DL-NIDS)时,我被它的检测准确率惊艳到了——某些场景下能达到99%以上的识别率。但当我试图把它部署到实际生产环境时&a…...

从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路
从Pikachu靶场看CSRF Token防护:为什么你的Token机制可能被绕过?聊聊设计缺陷与加固思路 在Web安全领域,CSRF(跨站请求伪造)攻击一直是开发者需要重点防范的威胁之一。而CSRF Token作为最常用的防护手段,其…...

CH340G模块除了下载程序,还能这么玩?一个硬件调试小技巧分享
CH340G模块的隐藏技能:用串口调试提升硬件开发效率 当你拿到一片CH340G模块时,第一反应可能是"这是个下载程序的好工具"。确实,这个价格亲民的小模块在51单片机开发中扮演着重要角色。但今天,我要分享的是它另一个被低估…...

从STM32转战合泰HT32F52352:手把手教你用GPTM定时器搞定四路舵机PWM控制
从STM32到HT32F52352的平滑迁移:GPTM定时器实现四路舵机PWM控制实战 对于习惯了STM32生态的开发者而言,初次接触合泰HT32系列MCU时往往面临两个挑战:如何快速理解新芯片的架构设计,以及如何将已有的STM32开发经验有效迁移。HT32F…...