spark支持深度学习批量推理
背景
在数据量较大的业务场景中,spark在数据处理、传统机器学习训练、
深度学习相关业务,能取得较明显的效率提升。
本篇围绕spark大数据背景下的推理,介绍一些优雅的使用方式。
spark适用场景
- 大数据量自定义方法处理、类sql处理
- 传统机器学习方法(k-means、xgboost、lr…)
- 分布式深度学习推理

目前在10亿+数据量的推理场景中使用,需要用户自己实现批数据准备,基于RDD的方法完成模型推理输出。
业务使用中的问题:
- 模型文件重复导入加载
- 自定义批数据准备,脱离深度学习dataloader框架,操作略显麻烦,有性能和内存oom等问题。
实践
spark加速深度学习推理
spark加速深度学习推理,基本思路为:
- 开启不定量worker并行执行(cpu或gpu)推理任务
- 所有worker共享同一份模型参数
- 依赖spark pandas udf功能,方便并行处理 dataframe 数据
- 依赖深度学习框架,方便实现最优批数据划分
下面以pytorch resnet 为实践demo
加载&&广播模型参数
广播模型参数,不仅能减少模型重复加载带来的流量和io,而且能加速推理前模型加载的速度。
driver广播模型参数:
# Load ResNet50 on driver node and broadcast its state.
model_state = models.resnet50(pretrained=True).state_dict()
bc_model_state = sc.broadcast(model_state)
worker读取模型参数:
def get_model_for_eval():"""Gets the broadcasted model."""model = models.resnet50(pretrained=True)model.load_state_dict(bc_model_state.value)model.eval()return model
实现基于dataframe的dataset
目前主流的深度学习框架,dataset的实现大多基于本地存储,在读取分布式存储的场景 需要用户自定义实现。
自定义实现有2个方法:
- 使用分布式存储的api接口读取文件内容
- dataset读取dataframe二进制文件内容
方法一迭代与使用的存储类型会保持同步,且每次使用前需要明确使用的分布式存储,虽然实现方法容易但是使用流程略显麻烦。
方法二不需要关心分布式存储类型,只要需要获取并解析spark dataframe列传入内容即可。
本文采用方法二实现dataset:
# 从二进制流中解析图片信息
def pil_loader(binary_file):# open path as file to avoid ResourceWarning (https://github.com/python-pillow/Pillow/issues/835)image_io = io.BytesIO(binary_file)img = Image.open(image_io)return img.convert('RGB')# Create a custom PyTorch dataset class.
class ImageDataset(Dataset):def __init__(self, data, transform=None):self.data = dataself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):image = pil_loader(self.data[index])if self.transform is not None:image = self.transform(image)return image
实现批量推理的pandas udf
Pandas udf是基于RDD的一个低门槛高性能的实现方法,pandas udf能自定义处理逻辑,以列的方式操作datafrme内容。
这是社区目前推荐的自定义处理方式。
# Define the function for model inference.
# PyArrow >= 1.0.0 must be installed;
@pandas_udf(ArrayType(FloatType()))
def predict_batch_udf(binaray_data: pd.Series) -> pd.Series:transform = transforms.Compose([transforms.Resize(224),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])images = ImageDataset(binaray_data, transform=transform)loader = torch.utils.data.DataLoader(images, batch_size=500, num_workers=8)model = get_model_for_eval()model.to(device)all_predictions = []with torch.no_grad():for batch in loader:predictions = list(model(batch.to(device)).cpu().numpy())for prediction in predictions:all_predictions.append(prediction)return pd.Series(all_predictions)
# 调用pandas udf
predictions_df = df. \select(col("filename"), predict_batch_udf(col("data")).alias("prediction"))
更多代码细节:
https://github.com/Crazybean-lwb/deeplearning-pyspark/blob/master/examples/pytorch-inference.py
模型仓加速推理
打通到模型仓mlflow功能:
- 模型存储和版本管理
- 便捷取用
- 适用spark datarame更高阶的pandas udf实现

# Create the PySpark UDF
import mlflow.pyfunc
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)# 调用pandas udf
df = spark_df.withColumn("prediction", pyfunc_udf(struct([...])))
参考信息:
- pytorch分布式批量推理
- tensorflow分布式批量推理
- 模型仓mlflow协助分布式批量推理
相关文章:
spark支持深度学习批量推理
背景 在数据量较大的业务场景中,spark在数据处理、传统机器学习训练、 深度学习相关业务,能取得较明显的效率提升。 本篇围绕spark大数据背景下的推理,介绍一些优雅的使用方式。 spark适用场景 大数据量自定义方法处理、类sql处理传统机器…...

代码随想录打卡—day52—【子序列问题】— 8.31 最大子序列
共性 做完下面三题,发现三个的dp数组中i都是以 i 为结束的字串。 1 300. 最长递增子序列 300. 最长递增子序列 AC: class Solution { public:int dp[10010]; // 表示以i结束的子序列最大的长度/*if(nums[j] > nums[i])dp[j] max(dp[j],dp[i] …...

gcc4.8.5升级到gcc4.9.2
第1步:获取repo [rootlocalhost SPECS]# wget --no-check-certificate https://copr.fedoraproject.org/coprs/rhscl/devtoolset-3/repo/epel-6/rhscl-devtoolset-3-epel-6.repo -O /etc/yum.repos.d/devtoolset-3.repo --2021-12-07 20:53:26-- https://copr.fedo…...
:常用函数)
Golang 中的 archive/zip 包详解(三):常用函数
Golang 中的 archive/zip 包用于处理 ZIP 格式的压缩文件,提供了一系列用于创建、读取和解压缩 ZIP 格式文件的函数和类型,使用起来非常方便,本文讲解下常用函数。 zip.OpenReader 定义如下: func OpenReader(name string) (*R…...

微服务架构七种模式
微服务架构七种模式 目录概述需求: 设计思路实现思路分析 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wait for change,challenge Survive.…...
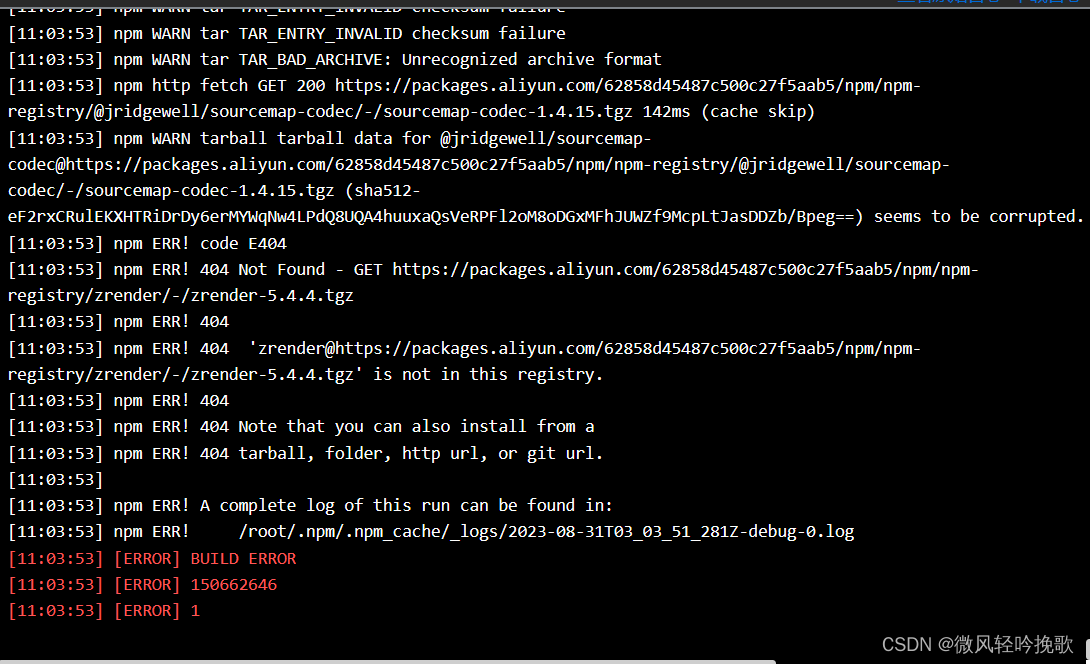
关于CICD流水线的前端项目运行错误,npm项目环境配置时出现报错:Not Found - GET https://registry.npm...
关于CICD流水线的前端项目运行错误,npm项目环境配置时出现报错:Not Found - GET https://registry.npm… 原因应该是某些jar包缓存中没有需要改变镜像将包拉下来 npm config set registry http://registry.npm.taobao.org npm install npm run build...

element-plus的周选择器 一周从周一开始
1、代码 1)、template中 <el-date-picker v-model"value1" type"week" format"[Week] ww" placeholder"巡访周" change"change"value-format"YYYY-MM-DD" /> 2)、方法中 import…...

Android 9.0 pms获取应用列表时过滤掉某些app功能实现
1.前言 在9.0的系统rom定制化开发中,对系统定制的功能也是很多的,在一次产品开发中,要求在第三方app获取应用列表的时候,需要过滤掉某些app,就是不显示在app应用列表中,这就需要在pms查询app列表时过滤掉这些app就可以了,接下来就实现这些功能 2.pms获取应用列表时过滤掉…...

HTML <thead> 标签
实例 带有 thead、tbody 以及 tfoot 元素的 HTML 表格: <table border="1"><thead><tr><th>Month</th><th>Savings</th></tr></thead><tfoot><tr><td>Sum</td><td>$180<…...

谷歌发布Gemini以5倍速击败GPT-4
在Covid疫情爆发之前,谷歌发布了MEENA模型,短时间内成为世界上最好的大型语言模型。谷歌发布的博客和论文非常可爱,因为它特别与OpenAI进行了比较。 相比于现有的最先进生成模型OpenAI GPT-2,MEENA的模型容量增加了1.7倍…...
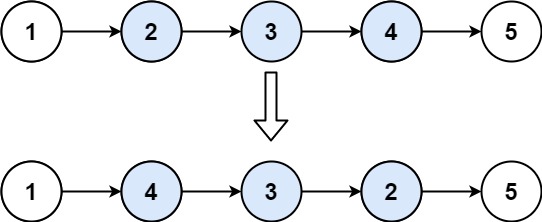
力扣92. 局部反转链表
92. 反转链表 II 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出&am…...

九、适配器模式
一、什么是适配器模式 适配器模式(Adapter)的定义如下:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。 适配器模式(Adapter)包含以下主要角色&…...
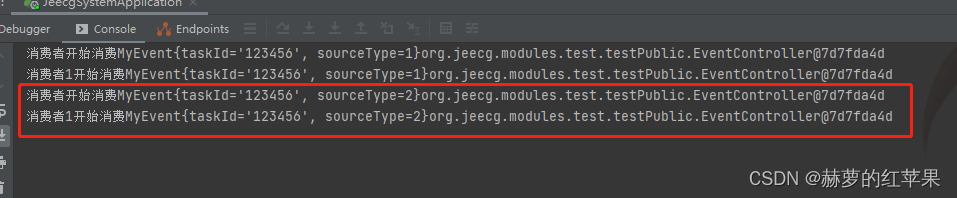
使用spring自带的发布订阅来实现发布订阅
背景 公司的项目以前代码里面有存在使用spring自带发布订阅的代码,因此稍微学习一下如何使用,并了解一下这种实现方式的优缺点。 优点 实现方便,代码方面基本只需要定义消息体和消费者,适用于小型应用程序。不依赖外部中间件&a…...
Walmart电商促销活动即将开始,如何做促销活动?需要注意什么?
近日,沃尔玛官宣Baby Days优惠活动将于9月1日正式开始!卖家可以把握机会,通过设置促销定价,以最优惠的婴儿相关产品价格吸引消费者,包括汽车座椅、婴儿车、尿布袋、家具、床上用品、消耗品、婴儿服装、孕妇装等。注意本…...
Matlab(画图进阶)
目录 大纲 1.特殊的Plots 1.1 loglog(双对数刻度图) 1.3 plotyy(创建具有两个y轴的图形) 1.4yyaxis(创建具有两个y轴的图) 1.5 bar 3D条形图(bar3) 1.6 pie(饼图) 3D饼图 1.7 polar 2.Stairs And Ste阶梯图 3.Boxplot 箱型图和Error Bar误差条形图 3.1 boxplot 3.2 …...

人生的回忆
回忆是人类宝贵的精神财富,它们像一串串珍珠,串联起我们生活中的每一个片段。 回忆是时间的见证者,它们承载着我们成长、经历、悲欢离合的点点滴滴。 回忆让我们重温过去的欢笑与眼泪,感受那些已经逝去的时光。它们就像一本翻开的…...

Spring之依赖注入源码解析
Spring之依赖注入源码解析 Spring依赖注入的方式 手动注入 在XML中定义Bean时,即为手动注入,因为是程序员手动给某个属性指定了值。 通过set方式进行注入 <bean name"userService" class"com.luban.service.UserService">…...
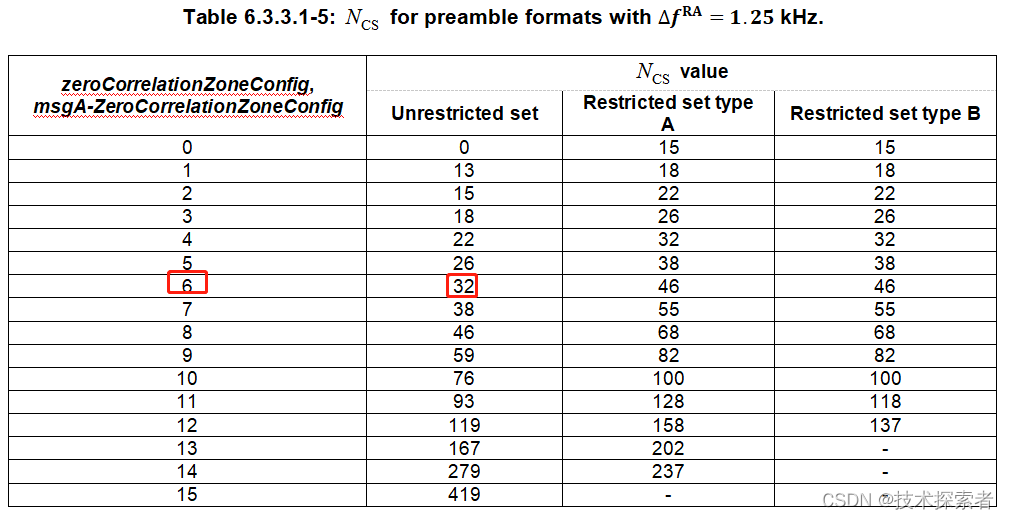
5G NR:RACH流程-- Msg1之生成PRACH Preamble
随机接入流程中的Msg1,即在PRACH信道上发送random access preamble。涉及到两个问题: 一个是如何产生preamble?一个是如何选择正确的PRACH时频资源发送所选的preamble? 一、PRACH Preamble是什么 PRACH Preamble从数学上来讲是一个长度为…...
高基数类别特征预处理:平均数编码 | 京东云技术团队
一 前言 对于一个类别特征,如果这个特征的取值非常多,则称它为高基数(high-cardinality)类别特征。在深度学习场景中,对于类别特征我们一般采用Embedding的方式,通过预训练或直接训练的方式将类别特征值编…...

高效利用隧道代理实现无阻塞数据采集
在当今信息时代,大量的有价值数据分散于各个网站和平台。然而,许多网站对爬虫程序进行限制或封禁,使得传统方式下的数据采集变得困难重重。本文将向您介绍如何通过使用隧道代理来解决这一问题,并帮助您成为一名高效、顺畅的数据采…...

深度解析Linux内核task_struct:从进程管理到性能调优
1. 项目概述:从一行代码到操作系统的心脏 如果你写过C语言程序,一定用过 int main() ,程序启动后,操作系统会为它创建一个“进程”。在Linux的世界里,这个进程在操作系统内核眼中,到底是什么样子的&#…...

LabVIEW TCP通讯实战:从零搭建一个工业数据采集服务器
1. LabVIEW TCP通讯在工业数据采集中的应用价值 工业现场的数据采集系统对通讯稳定性有着近乎苛刻的要求。记得我第一次参与某汽车生产线改造项目时,产线上的PLC和传感器每分钟要上传近万条数据,传统的串口通讯根本吃不消。当时团队尝试了多种方案&#…...

告别Resources.Load!Unity动态加载材质资源的最佳实践与性能优化指南
Unity材质资源动态加载:从基础实现到架构级优化方案 在AR涂鸦、实时换装、用户自定义皮肤等现代游戏交互场景中,动态材质加载已成为核心需求。传统Resources.Load虽简单直接,但在大型项目中常引发资源管理混乱、内存泄漏和热更新障碍。本文将…...

终极TFTP服务器解决方案:Tftpd64网络服务一体化配置完全指南 [特殊字符]
终极TFTP服务器解决方案:Tftpd64网络服务一体化配置完全指南 🚀 【免费下载链接】tftpd64 The working repository of the famous TFTP server. 项目地址: https://gitcode.com/gh_mirrors/tf/tftpd64 Tftpd64是一款轻量级、多线程的网络服务套件…...

CXPatcher:让Mac上的CrossOver性能飞升的终极指南
CXPatcher:让Mac上的CrossOver性能飞升的终极指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 你是否曾经在Mac上尝试运行Windows游戏时感到…...

免费开源游戏串流方案Sunshine:5分钟打造家庭游戏共享中心
免费开源游戏串流方案Sunshine:5分钟打造家庭游戏共享中心 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 还在为无法在客厅大屏上畅玩书房电脑里的3A大作而烦恼&#…...
)
TVA智能体范式的工业视觉革命(2)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

WPF-Control核心架构思想
WPF-Control 项目架构详解 一、核心架构思想 这个项目的架构可以用一句话概括:控件负责显示,服务负责能力,模块负责组合,主题负责外观,ApplicationBase 负责生命周期,IOC 负责连接所有对象。这是一种典型的…...

从游戏画面Bug到图形学原理:一次深度测试失败的排查与透视矫正插值的深度理解
从游戏画面Bug到图形学原理:深度测试失败的排查与透视矫正插值解析 深夜调试游戏引擎时,屏幕上的三角形边缘突然出现诡异的闪烁——这种被称为"深度冲突"的现象,往往让开发者陷入漫长的调试循环。本文将以一个实际开发中的深度测试…...

DayZ单机模组终极指南:打造专属末日世界的5个关键步骤
DayZ单机模组终极指南:打造专属末日世界的5个关键步骤 【免费下载链接】DayZCommunityOfflineMode A community made offline mod for DayZ Standalone 项目地址: https://gitcode.com/gh_mirrors/da/DayZCommunityOfflineMode 厌倦了DayZ在线服务器中的网络…...