谷歌发布Gemini以5倍速击败GPT-4

在Covid疫情爆发之前,谷歌发布了MEENA模型,短时间内成为世界上最好的大型语言模型。谷歌发布的博客和论文非常可爱,因为它特别与OpenAI进行了比较。
相比于现有的最先进生成模型OpenAI GPT-2,MEENA的模型容量增加了1.7倍,并且训练数据增加了8.5倍。
这个模型的训练所需的浮点运算量(FLOPS)超过了GPT-2的14倍,但这在很大程度上是无关紧要的,因为仅仅几个月后,OpenAI推出了GPT-3,它的参数是GPT-2的65倍多,令牌数量是GPT-2的60倍多,FLOPS更是增加了超过4,000倍。这两个模型之间的性能差异巨大。
MEENA模型引发了Noam Shazeer撰写的名为“MEENA吞噬世界”的内部备忘录。在这个备忘录中,他预测了在ChatGPT发布之后世界上其他人在意识到的事情。主要观点是语言模型会在各种方式下越来越多地融入我们的生活,并且它们会主导全球部署的FLOPS。当他写这篇备忘录时,他的观点超前于时代,但大多数关键决策者当时都忽视了或甚至嘲笑了这些观点。
让我们稍微偏离一下,看看Noam真的有多先见之明。他曾是撰写原始的Transformer论文“Attention is All You Need”的团队成员。他还参与了第一篇现代Mixture of Experts论文、Switch Transformer、Image Transformer,以及LaMDA和PaLM的各个方面。他尚未在更广泛的范围内获得广泛认可的一个想法是2018年的,即我们在关于GPT-4的独家披露中详细介绍的“推测解码”。推测解码可以将推理成本降低多倍。
这里的重点是,谷歌拥有所有成功的因素,但他们却错误地处理了。这是大家都明显看到的情况。
可能不太明显的是,沉睡的巨人谷歌已经醒来,他们正在以超越GPT-4的总预训练FLOPS速度5倍的步伐迭代,预计在年底之前。根据他们目前的基础设施建设,到明年年底他们的路径清晰可见,可能达到100倍。至于谷歌是否有胆量在不削弱其创造力或现有商业模式的情况下公开发布这些模型,这是一个不同的讨论。
今天,我们想要讨论谷歌的双子座训练系统,双子座模型的迭代速度,谷歌的Viperfish(TPUv5)推出,谷歌与其他前沿实验室在未来的竞争力,以及一个我们称之为“显卡穷人”的群体。
GPU-Rich显卡富人
计算资源的获取是一个双峰分布。只有少数几家公司拥有20,000个以上的A/H100显卡,个人研究人员可以为小项目获得数百或数千个显卡。其中主要的公司包括OpenAI、谷歌、Anthropic、Inflection、X和Meta,它们的计算资源与研究人员的比例最高。上述一些公司以及多家中国公司,到明年底将拥有10万个以上的显卡,尽管我们不确定中国的研究人员比例,只知道显卡数量。
在湾区,我们看到的最有趣的趋势之一是顶尖机器学习研究人员吹嘘他们有多少显卡,或者即将拥有多少显卡的机会。事实上,在过去的大约4个月里,这种现象变得如此普遍,以至于它已经成为一个直接影响顶尖研究人员决定去哪里的竞争。Meta,将拥有世界上第二多的H100显卡的公司,正在将这一点作为一种招聘策略。
GPU-Poor显卡穷人
然后,还有许多初创公司和开源研究人员,他们面临着更少显卡的困境。他们在试图做一些根本没有帮助或实际上无关紧要的事情上花费了大量的时间和精力。例如,许多研究人员花费了无数个小时在使用没有足够VRAM的显卡上对模型进行微调,这是对他们的技能和时间的极其低效的利用。
这些初创公司和开源研究人员正在使用更大的语言模型对较小的模型进行微调,用于排行榜样式的基准测试,而这些基准测试使用了有缺陷的评估方法,更强调样式而不是准确性或有用性。他们通常并不知道,为了使较小的开放模型在实际工作负载中改进,预训练数据集和IFT数据需要更大/更高质量。
是的,高效使用显卡是非常重要的,但在很多方面,显卡穷人们却忽略了这一点。他们不关心规模效率,他们的时间没有得到有效利用。对于即将在明年底之前拥有超过350万个H100显卡的世界来说,在他们的显卡穷人环境中商业上可以做的事情在很大程度上是无关紧要的。对于学习、尝试,更小、更弱的游戏显卡完全足够。
显卡穷人们仍然主要使用稠密模型,因为这就是Meta优雅地放在他们手上的LLAMA系列模型。如果没有上帝扎克的恩惠,大多数开源项目可能会更糟。如果他们真的关心效率,特别是在客户端方面,他们会运行像MoE这样的稀疏模型架构,在这些更大的数据集上进行训练,并像前沿的LLM实验室(OpenAI、Anthropic、Google Deepmind)那样实现推测解码。
这些处于劣势地位的人应该关注通过提高计算和内存容量要求以改善模型性能或令牌到令牌的延迟来平衡,以换取较低的内存带宽,因为这是边缘需要的。他们应该专注于在共享基础设施上高效地提供多个微调模型,而不用支付小批量大小的可怕成本。然而,他们一直关注内存容量限制或过度量化,而对真实质量下降视而不见。
稍微偏离一下,总体上,模型评估是有问题的。尽管在封闭的世界中有很多努力来改进这一点,但开放基准测试领域几乎没有意义,几乎没有衡量任何有用的东西。由于某种原因,对于LLM的排行榜化存在一种不健康的痴迷,以及对于无用模型的愚蠢名称的模因化。希望开源努力能够重新引导到评估、推测解码、MoE、开放的IFT数据和具有超过1万亿标记的干净预训练数据集,否则,开源将无法与商业巨头竞争。
虽然美国和中国将能够继续领先,但欧洲的初创公司和政府支持的超级计算机(如朱尔斯·凡尔纳)也完全无法竞争。由于缺乏进行大规模投资的能力,并选择保持显卡穷人的状态,欧洲在这场比赛中将落后。甚至多个中东国家也在为推动AI的大规模基础设施投资更多资金。
然而,显卡穷人并不仅限于初创公司。一些最知名的人工智能公司,如HuggingFace、Databricks(MosaicML)和Together,也是显卡穷人的一部分。实际上,从每个GPU的世界级研究人员数量,到GPU数量与雄心/潜在客户需求之间的关系,他们可能是最穷的一群。这些公司拥有世界级的研究人员,但由于他们使用的系统的能力相对较低,他们的发展受到了限制。这些公司在培训实际模型方面受到了企业的巨大需求,成千上万个H100显卡已经陆续到来,但这并不足以占据大部分市场份额。
Nvidia凭借其在DGX Cloud服务和各种内部超级计算机中拥有的多倍显卡数量正在蚕食它们的市场份额。Nvidia的DGX Cloud提供了预训练模型、数据处理框架、矢量数据库和个性化、优化的推理引擎、API以及来自NVIDIA专家的支持,以帮助企业调整模型以适应其自定义用途。该服务还已经为来自SaaS、保险、制造业、制药、生产软件和汽车等行业的多个大型企业提供了支持。虽然并非所有客户都已宣布,但即使是Amgen、Adobe、CCC、ServiceNow、Accenture、AstraZeneca、Getty Images、Shutterstock、Morningstar、Evozyne、Insilico Medicine、Quantiphi、InstaDeep、Oxford Nanopore、Peptone、Relation Therapeutics、ALCHEMAB Therapeutics和Runway这样的公开客户列表也相当令人印象深刻。
这是一个比其他玩家更长的列表,Nvidia还有许多其他未公开的合作伙伴关系。需要明确的是,来自Nvidia的DGX云服务这些宣布客户的收入是未知的,但考虑到Nvidia的云计算支出和内部超级计算机建设的规模,似乎更多的服务可以/将从Nvidia的云中购买,而不仅仅是HuggingFace、Together和Databricks所能提供的。
HuggingFace和Together共筹集的几亿资金意味着他们将保持显卡穷人的状态,他们将无法培训N-1个LLM,这些LLM可以作为基础模型供客户微调。这意味着他们最终将无法在今天就可以访问Nvidia的服务的企业中占据很高的份额。
特别是HuggingFace在行业中有着最大的声誉,他们需要利用这一点来投资大量资金,并构建更多的模型、定制和推理能力。他们最近的融资轮次在估值过高,无法获得他们需要的投资来竞争。HuggingFace的排行榜表明他们有多么盲目,因为他们正在误导开源运动,让其创造出一堆在实际使用中毫无用处的模型。
Databricks(MosaicML)可能至少可以通过其数据和企业连接赶上,问题是如果他们想有希望为超过7,000名客户提供服务,他们需要加快支出的速度。对MosaicML的13亿美元收购是对这一垂直领域的重大赌注,但他们还需要在基础设施上投入类似的资金。不幸的是,对于Databricks来说,他们不能用股票支付显卡的费用。他们需要通过即将进行的私募轮/首次公开募股来进行大规模的发行,并使用那些冷硬现金来大幅度增加硬件投入。
经济论点在这里不成立,因为他们必须在客户到来之前建设,因为Nvidia正在向他们的服务投入资金。需要明确的是,许多人购买了大量计算资源,但并没有赚回他们的钱(Cohere、沙特阿拉伯、阿联酋),但这是竞争的先决条件。
训练和推理运营公司(Databricks、HuggingFace和Together)在其主要竞争对手之后,而这些竞争对手同时也是他们的计算资源的主要来源。下一个最大的定制模型运营商只是来自OpenAI的微调API。
关键在于,从Meta到Microsoft再到初创公司,他们只是作为向Nvidia的银行账户输送资金的通道。
有没有人能够拯救我们免于Nvidia的奴役?
是的,有一个潜在的救星。
谷歌 - 全球最富有计算资源的公司
虽然谷歌在内部使用显卡,同时也通过GCP销售了大量显卡,但他们还有一些王牌。其中包括Gemini和已经开始训练的下一代模型。他们最重要的优势是无与伦比的高效基础设施。谷歌将会拥有比OpenAI、Meta、CoreWeave、Oracle和亚马逊的显卡总数加起来还要多的TPUv5。
相关文章:
谷歌发布Gemini以5倍速击败GPT-4
在Covid疫情爆发之前,谷歌发布了MEENA模型,短时间内成为世界上最好的大型语言模型。谷歌发布的博客和论文非常可爱,因为它特别与OpenAI进行了比较。 相比于现有的最先进生成模型OpenAI GPT-2,MEENA的模型容量增加了1.7倍…...
力扣92. 局部反转链表
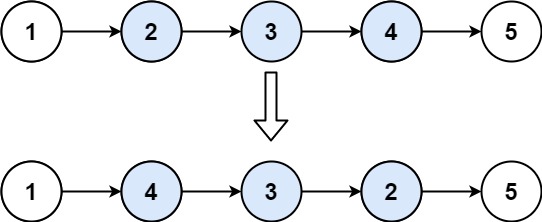
92. 反转链表 II 给你单链表的头指针 head 和两个整数 left 和 right ,其中 left < right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。 示例 1: 输入:head [1,2,3,4,5], left 2, right 4 输出&am…...

九、适配器模式
一、什么是适配器模式 适配器模式(Adapter)的定义如下:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。 适配器模式(Adapter)包含以下主要角色&…...
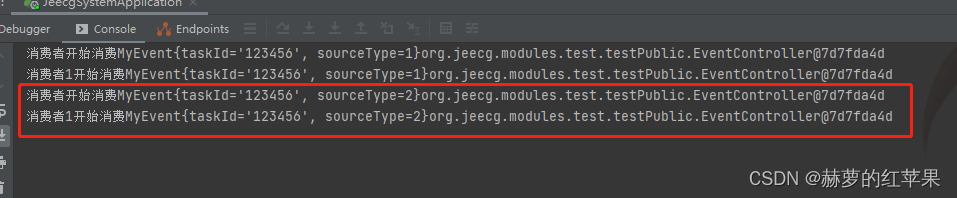
使用spring自带的发布订阅来实现发布订阅
背景 公司的项目以前代码里面有存在使用spring自带发布订阅的代码,因此稍微学习一下如何使用,并了解一下这种实现方式的优缺点。 优点 实现方便,代码方面基本只需要定义消息体和消费者,适用于小型应用程序。不依赖外部中间件&a…...
Walmart电商促销活动即将开始,如何做促销活动?需要注意什么?
近日,沃尔玛官宣Baby Days优惠活动将于9月1日正式开始!卖家可以把握机会,通过设置促销定价,以最优惠的婴儿相关产品价格吸引消费者,包括汽车座椅、婴儿车、尿布袋、家具、床上用品、消耗品、婴儿服装、孕妇装等。注意本…...
Matlab(画图进阶)
目录 大纲 1.特殊的Plots 1.1 loglog(双对数刻度图) 1.3 plotyy(创建具有两个y轴的图形) 1.4yyaxis(创建具有两个y轴的图) 1.5 bar 3D条形图(bar3) 1.6 pie(饼图) 3D饼图 1.7 polar 2.Stairs And Ste阶梯图 3.Boxplot 箱型图和Error Bar误差条形图 3.1 boxplot 3.2 …...

人生的回忆
回忆是人类宝贵的精神财富,它们像一串串珍珠,串联起我们生活中的每一个片段。 回忆是时间的见证者,它们承载着我们成长、经历、悲欢离合的点点滴滴。 回忆让我们重温过去的欢笑与眼泪,感受那些已经逝去的时光。它们就像一本翻开的…...

Spring之依赖注入源码解析
Spring之依赖注入源码解析 Spring依赖注入的方式 手动注入 在XML中定义Bean时,即为手动注入,因为是程序员手动给某个属性指定了值。 通过set方式进行注入 <bean name"userService" class"com.luban.service.UserService">…...
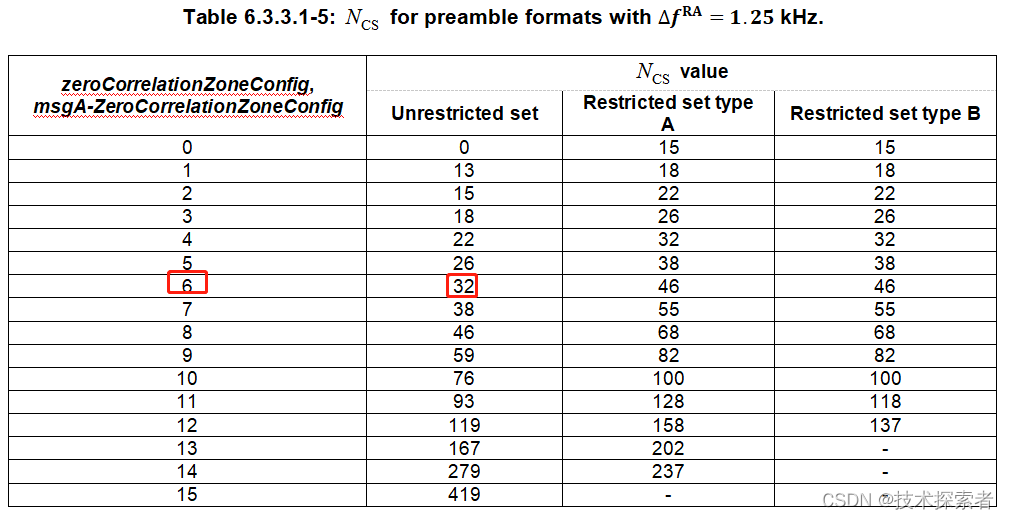
5G NR:RACH流程-- Msg1之生成PRACH Preamble
随机接入流程中的Msg1,即在PRACH信道上发送random access preamble。涉及到两个问题: 一个是如何产生preamble?一个是如何选择正确的PRACH时频资源发送所选的preamble? 一、PRACH Preamble是什么 PRACH Preamble从数学上来讲是一个长度为…...
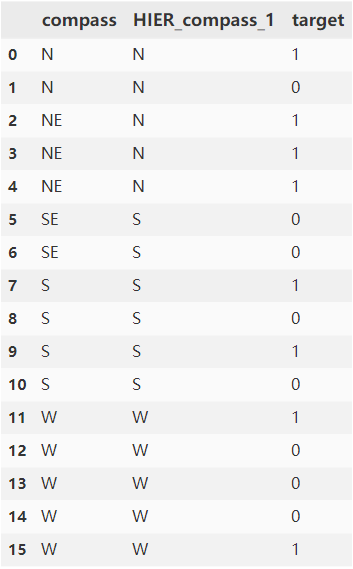
高基数类别特征预处理:平均数编码 | 京东云技术团队
一 前言 对于一个类别特征,如果这个特征的取值非常多,则称它为高基数(high-cardinality)类别特征。在深度学习场景中,对于类别特征我们一般采用Embedding的方式,通过预训练或直接训练的方式将类别特征值编…...

高效利用隧道代理实现无阻塞数据采集
在当今信息时代,大量的有价值数据分散于各个网站和平台。然而,许多网站对爬虫程序进行限制或封禁,使得传统方式下的数据采集变得困难重重。本文将向您介绍如何通过使用隧道代理来解决这一问题,并帮助您成为一名高效、顺畅的数据采…...

图论岛屿问题DFS+BFS
leetcode 200 岛屿问题 class Solution {//定义对应的方向boolean [][] visited;int dir[][]{{0,1},{1,0},{-1,0},{0,-1}};public int numIslands(char[][] grid) {//对应的二维数组int count0;visitednew boolean[grid.length][grid[0].length];for (int i 0; i < grid.l…...
Cypress web自动化windows环境npm安装Cypress
前言 web技术已经进化了,web的测试技术最终还是跟上了脚步,新一代的web自动化技术出现了? Cypress可以对在浏览器中运行的任何东西进行快速、简单和可靠的测试。 官方地址https://www.cypress.io/,详细的文档介绍https://docs.cypress.io/g…...

CentOS7.9设置ntp时间同步
文章目录 应用场景基础知识操作步骤 应用场景 我们公司是做智慧交通的,主要卖交通相关的硬件和软件。硬件包括信号机、雷达、雷视、边缘盒子等,软件包括信控平台、管控平台等信号机设备、雷达设备、边缘计算单元等,还有一些第三方的卡口设备…...
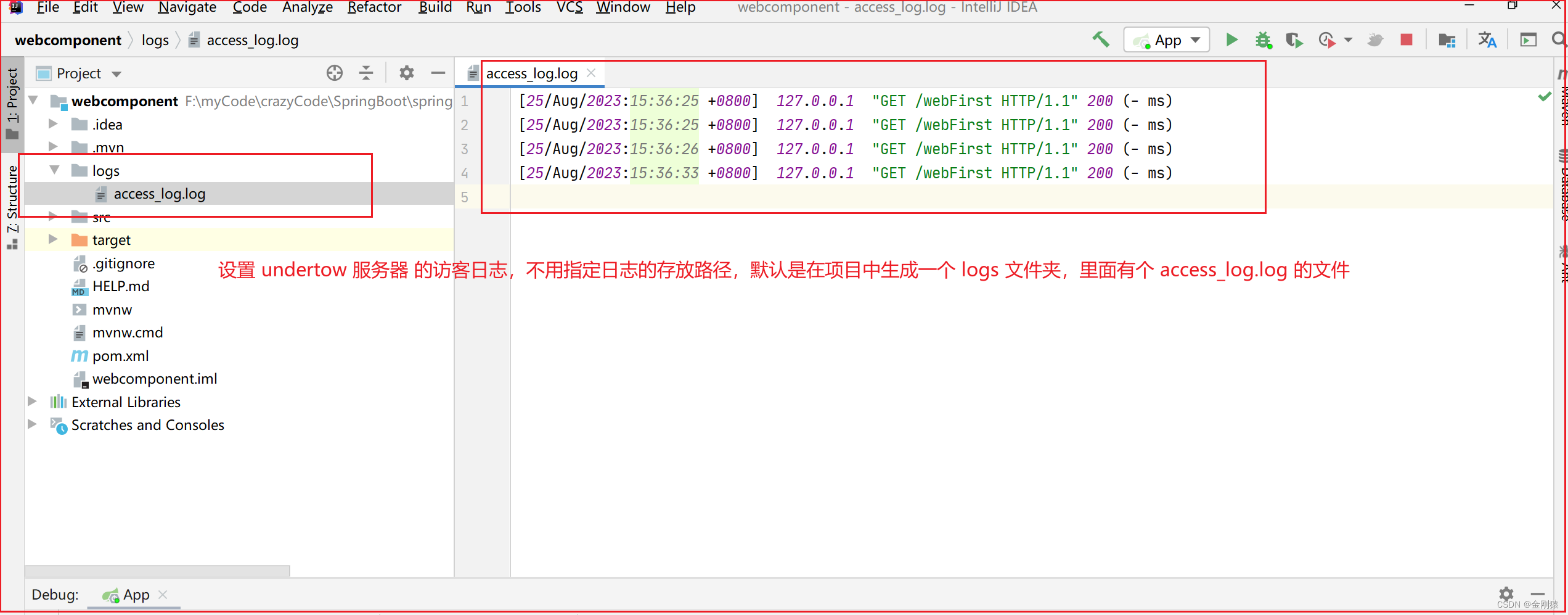
36、springboot --- 对 tomcat服务器 和 undertow服务器 配置访客日志
springboot 配置访客日志 ★ 配置访客日志: 访客日志: Web服务器可以将所有访问用户的记录都以日志的形式记录下来,主要就是记录来自哪个IP的用户、在哪个时间点、访问了哪个资源。 Web服务器可将所有访问记录以日志形式记录下来ÿ…...
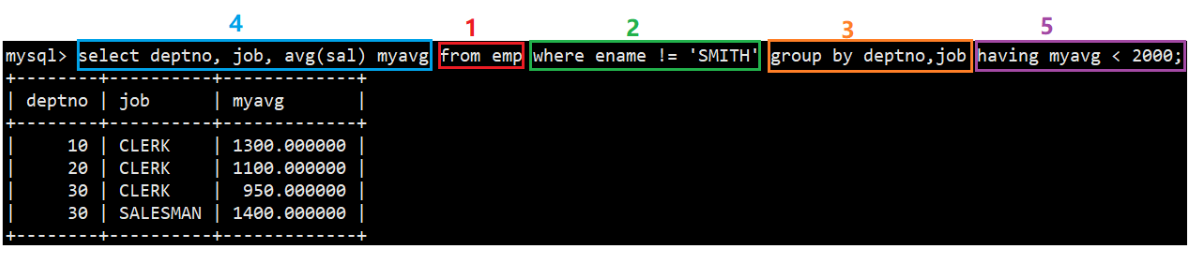
MySQL表的增删改查
文章目录 MySQL表的增删改查1. Create1.1 单行数据插入1.2 多行数据插入1.3 插入否则更新1.4 替换 2. Retrieve2.1 SELECT 列2.1.1 全列查询2.1.2 指定列查询2.1.3 查询字段为表达式2.1.4 为查询结果指定别名2.1.5 结果去重 2.2 WHERE 条件2.2.1 英语不及格的同学及英语成绩(&l…...

yolov3
yolov1 传统的算法 最主要的是先猜很多候选框,然后使用特征工程来提取特征(特征向量),最后使用传统的机器学习工具进行训练。然而复杂的过程可能会导致引入大量的噪声,丢失很多信息。 从传统的可以总结出目标检测可以分为两个阶…...

基于低代码/无代码工具构建 BI 应用程序
一、前言 随着数字化推进,越来越多的企业开始重视数据分析,希望通过BI(商业智能)技术提高业务决策的效率和准确性。 传统的BI解决方案往往需要大量的定制开发和数据准备,不仅周期长、成本高,还需要专业的数…...

Servlet与过滤器
目录 Servlet 过滤器 Servlet Servlet做了什么 本身不做任何业务处理,只是接收请求并决定调用哪个JavaBean去处理请求,确定用哪个页面来显示处理返回的数据 Servlet是什么 ServerApplet,是一种服务器端的Java应用程序 只有当一个服务器端的程序使用了Servlet…...

微信小程序开发实战记录
近期公司需要开发一个小程序项目,时间非常紧急,在开发过程中遇到几个困扰的问题及解决方案,记录如下:小程序框架选择 基础框架:小程序原生框架 sassui: 采用 vant weapp图表:采用 ec-echarts …...

从ADC采样到FFT分析:手把手教你用STM32F407的DSP库搞定频谱计算
从ADC采样到FFT分析:手把手教你用STM32F407的DSP库搞定频谱计算 在工业振动监测、音频信号处理和电源质量分析等场景中,频谱分析是理解信号特征的关键技术。STM32F407凭借其Cortex-M4内核和硬件FPU,配合CMSIS-DSP库,能够高效实现实…...

CANN/asc-devkit Erfc接口文档
Erfc 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

华为HCIA-Datacom认证 第七章第八章 案例教程
华为HCIA-Datacom认证 第七章&第八章 案例教程 一、背景延续:小明的网络运维新课题 前几次网络改造完成后,公司的办公网络已经稳定运行了一阵子。小明也从当初的手忙脚乱成长为一名能独立处理基础网络问题的工程师。然而,随着公司网络的不断扩展,新的管理需求随之而来…...

租房避坑|在成都,我从“凑合住”到“安心住”经历了什么
姐妹们,千万别被“凤凰大街包租”几个字骗了!我的真实租房血泪史是不是最近总刷到那种“凤凰大街包租”“拎包入住”的宣传?说实话,刚来成都那会儿,我也被这些词儿晃花了眼。想着省心省力,结果踩的坑一个接…...

储能BMS HiL测试:原理、价值与工程实践全解析
1. 储能BMS HiL测试:为什么它是研发验证的“必选项”?在储能系统,尤其是大规模电池储能电站的研发过程中,电池管理系统(BMS)的可靠性与安全性是决定整个项目成败的基石。然而,传统的BMS测试方法…...
3步掌握TransNet V2:从零开始实现智能视频镜头检测
3步掌握TransNet V2:从零开始实现智能视频镜头检测 【免费下载链接】TransNetV2 TransNet V2: Shot Boundary Detection Neural Network 项目地址: https://gitcode.com/gh_mirrors/tr/TransNetV2 想要快速分析视频内容结构,自动识别镜头切换点吗…...
)
告别AT指令恐惧:用STM32F407驱动SIM800C实现短信报警(附完整代码)
STM32F407与SIM800C实战:构建工业级短信报警系统的完整指南 在工业自动化、智能家居和远程监控领域,可靠的异常通知机制往往决定着系统响应速度与故障处理效率。传统有线报警方式受限于物理距离,而基于Wi-Fi的解决方案又面临网络覆盖的挑战。…...

Rust编程学习.0-安装及环境搭建
目录 前言 一、Rust是什么? 二、Rust安装及环境搭建 1.安装 2.环境搭建 总结 前言 本人借助工作的机会准备好好学习语言编程以及深造嵌入式开发方向,更加系统深入网络,为了不再和之前一样做完再花时间回忆并记录,0帧起手开始…...
)
别再手动调相机了!用CinemachineFreeLook快速搞定Unity第三人称视角(附完整配置流程)
告别繁琐调试:用CinemachineFreeLook打造专业级Unity第三人称视角 在游戏开发中,第三人称视角的实现往往让开发者头疼不已。传统的手动摄像机控制不仅需要编写大量代码来处理跟随、旋转和碰撞检测,还容易产生抖动、穿模等恼人的问题。而Unity…...

终极指南:如何用免费C工具快速管理天龙八部单机版游戏数据
终极指南:如何用免费C#工具快速管理天龙八部单机版游戏数据 【免费下载链接】TlbbGmTool 某网络游戏的单机版本GM工具 项目地址: https://gitcode.com/gh_mirrors/tl/TlbbGmTool 还在为《天龙八部》单机版的数据管理而烦恼吗?TlbbGmTool是一款专为…...